Spring Boot多级缓存实现方案
1.背景
缓存,就是让数据更接近使用者,让访问速度加快,从而提升系统性能。工作机制大概是先从缓存中加载数据,如果没有,再从慢速设备(eg:数据库)中加载数据并同步到缓存中。
所谓多级缓存,是指在整个系统架构的不同系统层面进行数据缓存,以提升访问速度。主要分为三层缓存:网关nginx缓存、分布式缓存、本地缓存。这里的多级缓存就是用redis分布式缓存+caffeine本地缓存整合而来。
平时我们在开发过程中,一般都是使用redis实现分布式缓存、caffeine操作本地缓存,但是发现只使用redis或者是caffeine实现缓存都有一些问题:
- 一级缓存:Caffeine是一个一个高性能的 Java 缓存库;使用 Window TinyLfu 回收策略,提供了一个近乎最佳的命中率。优点数据就在应用内存所以速度快。缺点受应用内存的限制,所以容量有限;没有持久化,重启服务后缓存数据会丢失;在分布式环境下缓存数据数据无法同步;
- 二级缓存:redis是一高性能、高可用的key-value数据库,支持多种数据类型,支持集群,和应用服务器分开部署易于横向扩展。优点支持多种数据类型,扩容方便;有持久化,重启应用服务器缓存数据不会丢失;他是一个集中式缓存,不存在在应用服务器之间同步数据的问题。缺点每次都需要访问redis存在IO浪费的情况。
综上所述,我们可以通过整合redis和caffeine实现多级缓存,解决上面单一缓存的痛点,从而做到相互补足。
项目推荐:基于SpringBoot2.x、SpringCloud和SpringCloudAlibaba企业级系统架构底层框架封装,解决业务开发时常见的非功能性需求,防止重复造轮子,方便业务快速开发和企业技术栈框架统一管理。引入组件化的思想实现高内聚低耦合并且高度可配置化,做到可插拔。严格控制包依赖和统一版本管理,做到最少化依赖。注重代码规范和注释,非常适合个人学习和企业使用
Github地址:https://github.com/plasticene/plasticene-boot-starter-parent
Gitee地址:https://gitee.com/plasticene3/plasticene-boot-starter-parent
微信公众号:Shepherd进阶笔记
交流探讨qun:Shepherd_126
2.整合实现
2.1思路
Spring 本来就提供了Cache的支持,最核心的就是实现Cache和CacheManager接口。但是Spring Cache存在以下问题:
- Spring Cache 仅支持单一的缓存来源,即:只能选择 Redis 实现或者 Caffeine 实现,并不能同时使用。
- 数据一致性:各层缓存之间的数据一致性问题,如应用层缓存和分布式缓存之前的数据一致性问题。
由此我们可以通过重新实现Cache和CacheManager接口,整合redis和caffeine,从而实现多级缓存。在讲实现原理之前先看看多级缓存调用逻辑图:
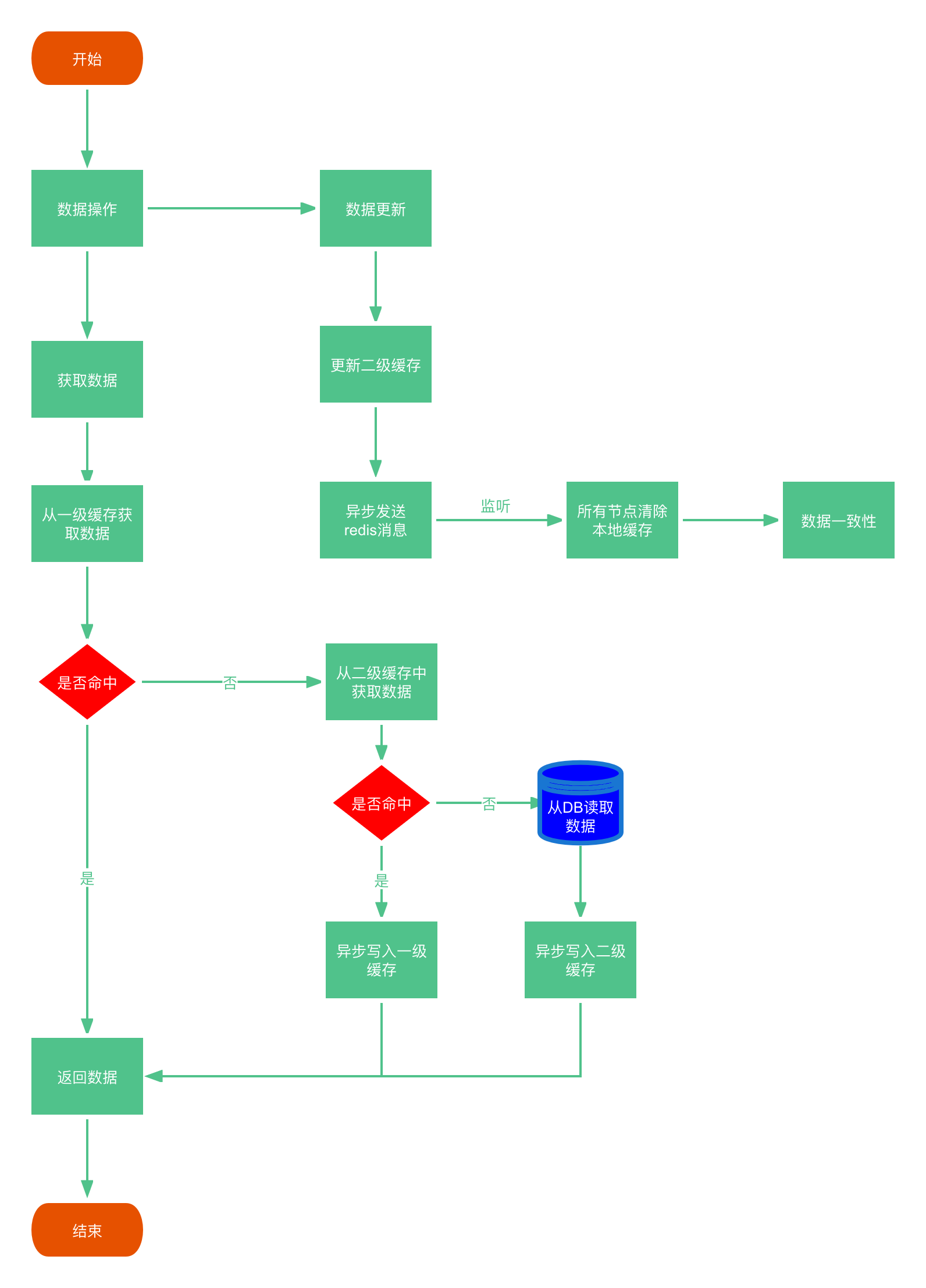
2.2实现
首先,我们需要一个多级缓存配置类,方便对缓存属性的动态配置,通过开关做到可插拔。
@ConfigurationProperties(prefix = "multilevel.cache")
@Data
public class MultilevelCacheProperties {/*** 一级本地缓存最大比例*/private Double maxCapacityRate = 0.2;/*** 一级本地缓存与最大缓存初始化大小比例*/private Double initRate = 0.5;/*** 消息主题*/private String topic = "multilevel-cache-topic";/*** 缓存名称*/private String name = "multilevel-cache";/*** 一级本地缓存名称*/private String caffeineName = "multilevel-caffeine-cache";/*** 二级缓存名称*/private String redisName = "multilevel-redis-cache";/*** 一级本地缓存过期时间*/private Integer caffeineExpireTime = 300;/*** 二级缓存过期时间*/private Integer redisExpireTime = 600;/*** 一级缓存开关*/private Boolean caffeineSwitch = true;}
在自动配置类使用@EnableConfigurationProperties(MultilevelCacheProperties.class)注入即可使用。
接下来就是重新实现spring的Cache接口,整合caffeine本地缓存和redis分布式缓存实现多级缓存
package com.plasticene.boot.cache.core.manager;import com.plasticene.boot.cache.core.listener.CacheMessage;
import com.plasticene.boot.cache.core.prop.MultilevelCacheProperties;
import com.plasticene.boot.common.executor.plasticeneThreadExecutor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cache.caffeine.CaffeineCache;
import org.springframework.cache.support.AbstractValueAdaptingCache;
import org.springframework.data.redis.cache.RedisCache;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.lang.NonNull;
import org.springframework.util.Assert;import javax.annotation.Resource;
import java.util.Objects;
import java.util.concurrent.*;/*** @author fjzheng* @version 1.0* @date 2022/7/20 17:03*/
@Slf4j
public class MultilevelCache extends AbstractValueAdaptingCache {@Resourceprivate MultilevelCacheProperties multilevelCacheProperties;@Resourceprivate RedisTemplate redisTemplate;ExecutorService cacheExecutor = new plasticeneThreadExecutor(Runtime.getRuntime().availableProcessors() * 2,Runtime.getRuntime().availableProcessors() * 20,Runtime.getRuntime().availableProcessors() * 200,"cache-pool");private RedisCache redisCache;private CaffeineCache caffeineCache;public MultilevelCache(boolean allowNullValues,RedisCache redisCache, CaffeineCache caffeineCache) {super(allowNullValues);this.redisCache = redisCache;this.caffeineCache = caffeineCache;}@Overridepublic String getName() {return multilevelCacheProperties.getName();}@Overridepublic Object getNativeCache() {return null;}@Overridepublic <T> T get(Object key, Callable<T> valueLoader) {Object value = lookup(key);return (T) value;}/*** 注意:redis缓存的对象object必须序列化 implements Serializable, 不然缓存对象不成功。* 注意:这里asyncPublish()方法是异步发布消息,然后让分布式其他节点清除本地缓存,防止当前节点因更新覆盖数据而其他节点本地缓存保存是脏数据* 这样本地缓存数据才能成功存入* @param key* @param value*/@Overridepublic void put(@NonNull Object key, Object value) {redisCache.put(key, value);// 异步清除本地缓存if (multilevelCacheProperties.getCaffeineSwitch()) {asyncPublish(key, value);}}/*** key不存在时,再保存,存在返回当前值不覆盖* @param key* @param value* @return*/@Overridepublic ValueWrapper putIfAbsent(@NonNull Object key, Object value) {ValueWrapper valueWrapper = redisCache.putIfAbsent(key, value);// 异步清除本地缓存if (multilevelCacheProperties.getCaffeineSwitch()) {asyncPublish(key, value);}return valueWrapper;}@Overridepublic void evict(Object key) {// 先清除redis中缓存数据,然后通过消息推送清除所有节点caffeine中的缓存,// 避免短时间内如果先清除caffeine缓存后其他请求会再从redis里加载到caffeine中redisCache.evict(key);// 异步清除本地缓存if (multilevelCacheProperties.getCaffeineSwitch()) {asyncPublish(key, null);}}@Overridepublic boolean evictIfPresent(Object key) {return false;}@Overridepublic void clear() {redisCache.clear();// 异步清除本地缓存if (multilevelCacheProperties.getCaffeineSwitch()) {asyncPublish(null, null);}}@Overrideprotected Object lookup(Object key) {Assert.notNull(key, "key不可为空");ValueWrapper value;if (multilevelCacheProperties.getCaffeineSwitch()) {// 开启一级缓存,先从一级缓存缓存数据value = caffeineCache.get(key);if (Objects.nonNull(value)) {log.info("查询caffeine 一级缓存 key:{}, 返回值是:{}", key, value.get());return value.get();}}value = redisCache.get(key);if (Objects.nonNull(value)) {log.info("查询redis 二级缓存 key:{}, 返回值是:{}", key, value.get());// 异步将二级缓存redis写到一级缓存caffeineif (multilevelCacheProperties.getCaffeineSwitch()) {ValueWrapper finalValue = value;cacheExecutor.execute(()->{caffeineCache.put(key, finalValue.get());});}return value.get();}return null;}/*** 缓存变更时通知其他节点清理本地缓存* 异步通过发布订阅主题消息,其他节点监听到之后进行相关本地缓存操作,防止本地缓存脏数据*/void asyncPublish(Object key, Object value) {cacheExecutor.execute(()->{CacheMessage cacheMessage = new CacheMessage();cacheMessage.setCacheName(multilevelCacheProperties.getName());cacheMessage.setKey(key);cacheMessage.setValue(value);redisTemplate.convertAndSend(multilevelCacheProperties.getTopic(), cacheMessage);});}}缓存消息监听:我们通监听caffeine键值的移除、打印日志方便排查问题,通过监听redis发布的消息,实现分布式集群多节点本地缓存清除从而达到数据一致性。
消息体
@Data
public class CacheMessage implements Serializable {private String cacheName;private Object key;private Object value;private Integer type;
}
caffeine移除监听:
@Slf4j
public class CaffeineCacheRemovalListener implements RemovalListener<Object, Object> {@Overridepublic void onRemoval(@Nullable Object k, @Nullable Object v, @NonNull RemovalCause cause) {log.info("[移除缓存] key:{} reason:{}", k, cause.name());// 超出最大缓存if (cause == RemovalCause.SIZE) {}// 超出过期时间if (cause == RemovalCause.EXPIRED) {// do something}// 显式移除if (cause == RemovalCause.EXPLICIT) {// do something}// 旧数据被更新if (cause == RemovalCause.REPLACED) {// do something}}
}redis消息监听:
@Slf4j
@Data
public class RedisCacheMessageListener implements MessageListener {private CaffeineCache caffeineCache;@Overridepublic void onMessage(Message message, byte[] pattern) {log.info("监听的redis message: {}" + message.toString());CacheMessage cacheMessage = JsonUtils.parseObject(message.toString(), CacheMessage.class);if (Objects.isNull(cacheMessage.getKey())) {caffeineCache.invalidate();} else {caffeineCache.evict(cacheMessage.getKey());}}
}
最后,通过自动配置类,注入相关bean:
*** @author fjzheng* @version 1.0* @date 2022/7/20 17:24*/
@Configuration
@EnableConfigurationProperties(MultilevelCacheProperties.class)
public class MultilevelCacheAutoConfiguration {@Resourceprivate MultilevelCacheProperties multilevelCacheProperties;ExecutorService cacheExecutor = new plasticeneThreadExecutor(Runtime.getRuntime().availableProcessors() * 2,Runtime.getRuntime().availableProcessors() * 20,Runtime.getRuntime().availableProcessors() * 200,"cache-pool");@Bean@ConditionalOnMissingBean({RedisTemplate.class})public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory factory) {RedisTemplate<Object, Object> template = new RedisTemplate<Object, Object>();template.setConnectionFactory(factory);template.setKeySerializer(new StringRedisSerializer());template.setHashKeySerializer(new StringRedisSerializer());template.setDefaultSerializer(new Jackson2JsonRedisSerializer<>(Object.class));template.setHashValueSerializer(new Jackson2JsonRedisSerializer<>(Object.class));return template;}@Beanpublic RedisCache redisCache (RedisConnectionFactory redisConnectionFactory) {RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory);RedisCacheConfiguration redisCacheConfiguration = defaultCacheConfig();redisCacheConfiguration = redisCacheConfiguration.entryTtl(Duration.of(multilevelCacheProperties.getRedisExpireTime(), ChronoUnit.SECONDS));redisCacheConfiguration = redisCacheConfiguration.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));redisCacheConfiguration = redisCacheConfiguration.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));RedisCache redisCache = new CustomRedisCache(multilevelCacheProperties.getRedisName(), redisCacheWriter, redisCacheConfiguration);return redisCache;}/*** 由于Caffeine 不会再值过期后立即执行清除,而是在写入或者读取操作之后执行少量维护工作,或者在写入读取很少的情况下,偶尔执行清除操作。* 如果我们项目写入或者读取频率很高,那么不用担心。如果想入写入和读取操作频率较低,那么我们可以通过Cache.cleanUp()或者加scheduler去定时执行清除操作。* Scheduler可以迅速删除过期的元素,***Java 9 +***后的版本,可以通过Scheduler.systemScheduler(), 调用系统线程,达到定期清除的目的* @return*/@Bean@ConditionalOnClass(CaffeineCache.class)@ConditionalOnProperty(name = "multilevel.cache.caffeineSwitch", havingValue = "true", matchIfMissing = true)public CaffeineCache caffeineCache() {int maxCapacity = (int) (Runtime.getRuntime().totalMemory() * multilevelCacheProperties.getMaxCapacityRate());int initCapacity = (int) (maxCapacity * multilevelCacheProperties.getInitRate());CaffeineCache caffeineCache = new CaffeineCache(multilevelCacheProperties.getCaffeineName(), Caffeine.newBuilder()// 设置初始缓存大小.initialCapacity(initCapacity)// 设置最大缓存.maximumSize(maxCapacity)// 设置缓存线程池.executor(cacheExecutor)// 设置定时任务执行过期清除操作
// .scheduler(Scheduler.systemScheduler())// 监听器(超出最大缓存).removalListener(new CaffeineCacheRemovalListener())// 设置缓存读时间的过期时间.expireAfterAccess(Duration.of(multilevelCacheProperties.getCaffeineExpireTime(), ChronoUnit.SECONDS))// 开启metrics监控.recordStats().build());return caffeineCache;}@Bean@ConditionalOnBean({CaffeineCache.class, RedisCache.class})public MultilevelCache multilevelCache(RedisCache redisCache, CaffeineCache caffeineCache) {MultilevelCache multilevelCache = new MultilevelCache(true, redisCache, caffeineCache);return multilevelCache;}@Beanpublic RedisCacheMessageListener redisCacheMessageListener(@Autowired CaffeineCache caffeineCache) {RedisCacheMessageListener redisCacheMessageListener = new RedisCacheMessageListener();redisCacheMessageListener.setCaffeineCache(caffeineCache);return redisCacheMessageListener;}@Beanpublic RedisMessageListenerContainer redisMessageListenerContainer(@Autowired RedisConnectionFactory redisConnectionFactory,@Autowired RedisCacheMessageListener redisCacheMessageListener) {RedisMessageListenerContainer redisMessageListenerContainer = new RedisMessageListenerContainer();redisMessageListenerContainer.setConnectionFactory(redisConnectionFactory);redisMessageListenerContainer.addMessageListener(redisCacheMessageListener, new ChannelTopic(multilevelCacheProperties.getTopic()));return redisMessageListenerContainer;}}3.使用
使用非常简单,只需要通过multilevelCache操作即可:
@RestController
@RequestMapping("/api/data")
@Api(tags = "api数据")
@Slf4j
public class ApiDataController {@Resourceprivate MultilevelCache multilevelCache;@GetMapping("/put/cache")public void put() {DataSource ds = new DataSource();ds.setName("多级缓存");ds.setType(1);ds.setCreateTime(new Date());ds.setHost("127.0.0.1");multilevelCache.put("test-key", ds);}@GetMapping("/get/cache")public DataSource get() {DataSource dataSource = multilevelCache.get("test-key", DataSource.class);return dataSource;}}
4.总结
以上全部就是关于多级缓存的实现方案总结,多级缓存就是为了解决项目服务中单一缓存使用不足的缺点。应用场景有:接口权限校验,每次请求接口都需要根据当前登录人有哪些角色,角色有哪些权限,如果每次都去查数据库性能开销比较严重,再加上权限一般不怎么会频繁变更,所以使用多级缓存是最合适不过了;还有就是很多管理系统列表界面都有组织架构信息(所属部门、小组等),这些信息同样可以使用多级缓存来完美提升性能。
相关文章:
Spring Boot多级缓存实现方案
1.背景 缓存,就是让数据更接近使用者,让访问速度加快,从而提升系统性能。工作机制大概是先从缓存中加载数据,如果没有,再从慢速设备(eg:数据库)中加载数据并同步到缓存中。 所谓多级缓存,是指在整个系统架…...
机器学习笔记:李宏毅chatgpt 大模型 大资料
1 大模型 1.1 大模型的顿悟时刻 Emergent Abilities of Large Language Models,Transactions on Machine Learning Research 2022 模型的效果不是随着模型参数量变多而慢慢变好,而是在某一个瞬间,模型“顿悟”了 这边举的一个例子是&#…...

2023年中国智慧公安行业发展现况及发展趋势分析:数据化建设的覆盖范围不断扩大[图]
智慧公安基于互联网、物联网、云计算、智能引擎、视频技术、数据挖掘、知识管理为技术支撑,公安信息化为核心,通过互联互通、物联化、智能方式促进公安系统各功能模块的高度集成、协同作战实现警务信息化“强度整合、高度共享、深度应用”警察发展的新概…...

Apache Dubbo概述
一、课程目标 1. 【了解】软件架构的演进过程 2. 【理解】什么是RPC 3. 【掌握】Dubbo架构 4. 【理解】注册中心Zookeeper 5. 【掌握】Zookeeper的安装和使用 6. 【掌握】Dubbo入门程序 7. 【掌握】Dubbo管理控制台的安装和使用 8. 【理解】Dubbo配置二、分布式RPC框架Apache …...
React UI组件库
1 流行的开源React UI组件库 1 material-ui(国外) 官网: Material UI: React components based on Material Design github: GitHub - mui/material-ui: MUI Core: Ready-to-use foundational React components, free forever. It includes Material UI, which implements Go…...
计算机科学的伟大变革:从机械计算到人工智能
摘要 计算机科学作为一门学科,经历了几十年的发展和演变。本论文旨在探讨计算机科学领域的伟大变革,从最早的机械计算设备到如今的人工智能系统。通过回顾历史、分析技术进步以及展望未来,我们可以清晰地看到计算机科学如何塑造了现代社会&a…...

微服务详解
微服务 什么是微服务? 微:单个服务的设计,所有参与人从设计、开发、测试、运维所有人加起来只需要两个披萨就够了 服务:一定要区别于系统,服务一个或者一组相对较小且独立的功能单元,是用户可以感知的最…...
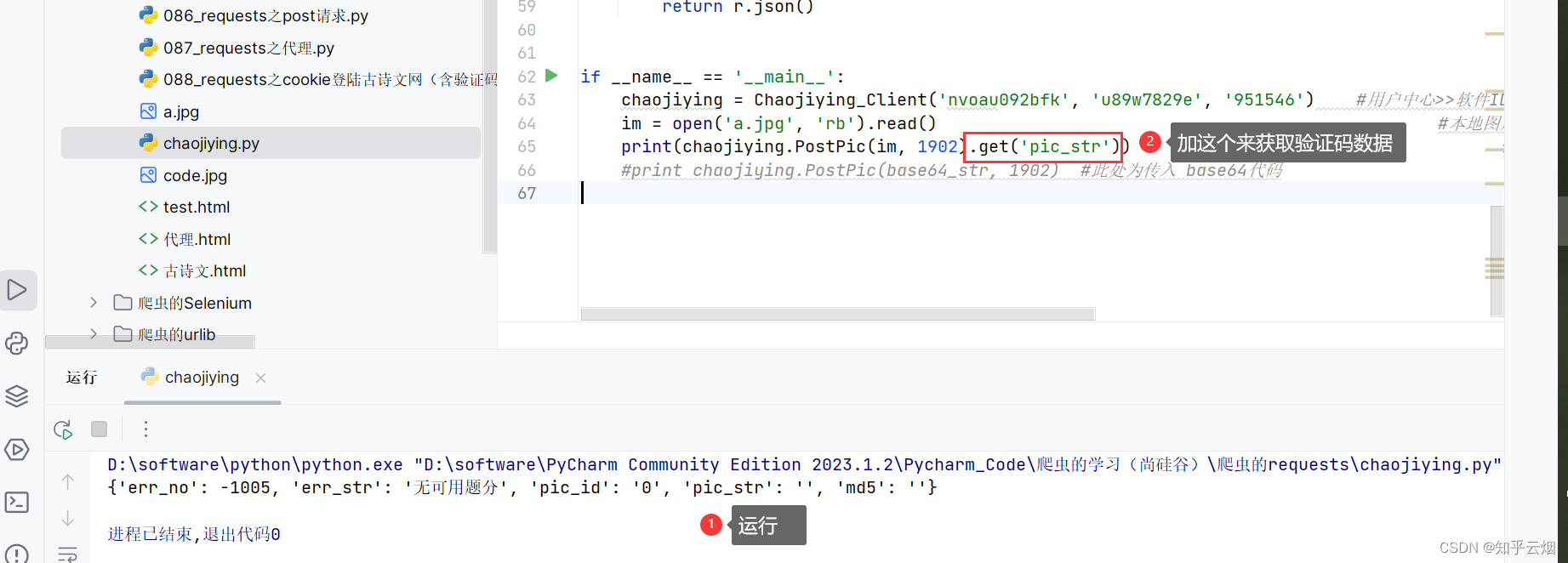
Python爬虫的requests(学习于b站尚硅谷)
目录 一、requests 1. requests的基本使用 (1)文档 (2)安装 (3)响应response的属性以及类型 (4)代码演示 2.requests之get请求 3. requests之post请求 &#x…...

PHP最简单自定义自己的框架view使用引入smarty(8)--自定义的框架完成
1、实现效果。引入smarty, 实现assign和 display 2、下载smarty,创建缓存目录cache和扩展extend 点击下面查看具体下载使用,下载改名后放到extend PHP之Smarty使用以及框架display和assign原理_PHP隔壁老王邻居的博客-CSDN博客 3、当前控…...

字符串的常用操作
1.拼接字符串 使用运算符""可以对多个字符串进行拼接将几个字符串拼成一个字符串。 2.计算字符串的长度 使用len()函数计算字符串的长度 len(string) 其中string用于指定要进行长度统计的字符串。 3.截取字符串 由于字符串也属于序列,所以要截取字…...
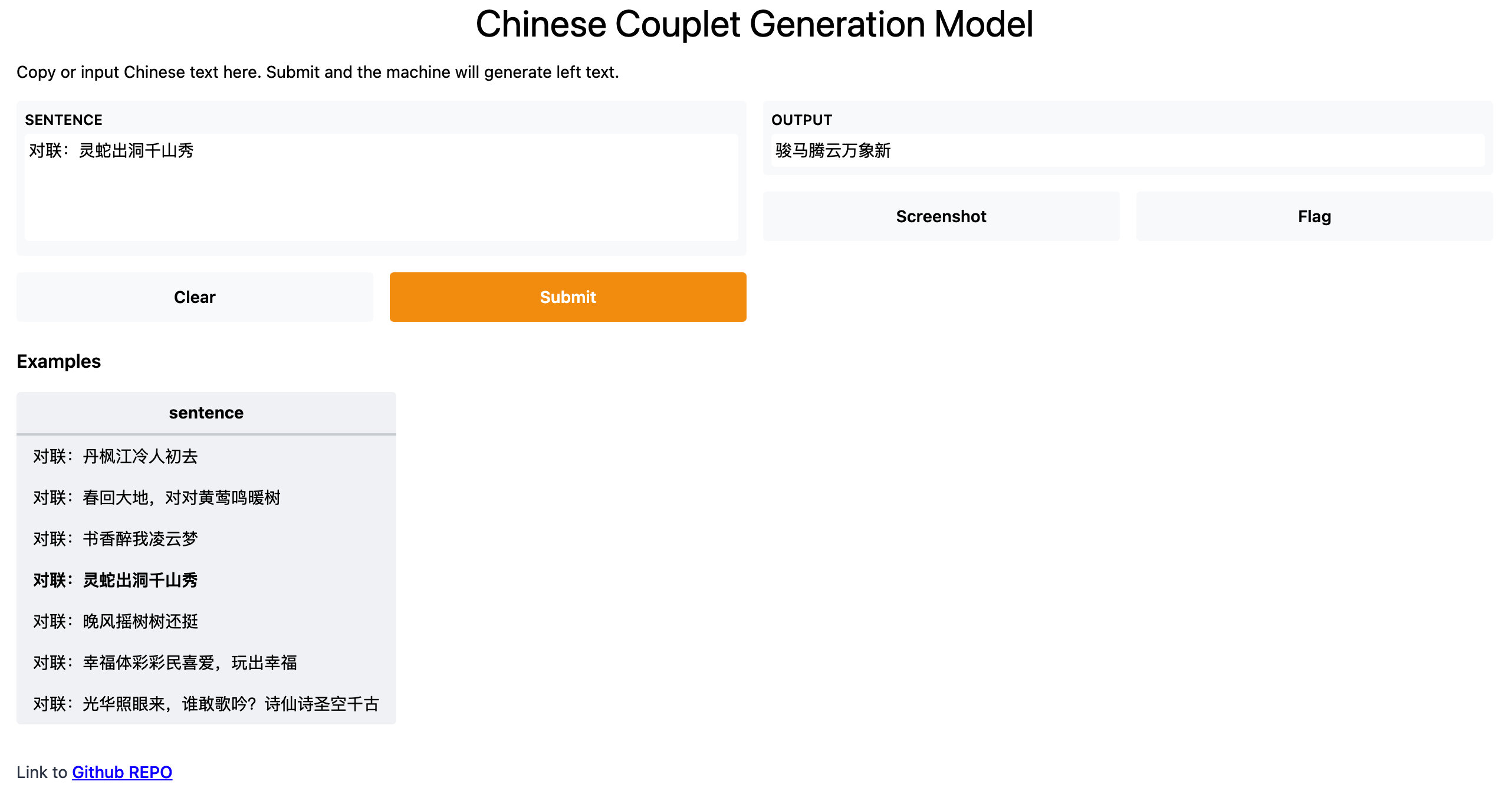
开启想象翅膀:轻松实现文本生成模型的创作应用,支持LLaMA、ChatGLM、UDA、GPT2、Seq2Seq、BART、T5、SongNet等模型,开箱即用
开启想象翅膀:轻松实现文本生成模型的创作应用,支持LLaMA、ChatGLM、UDA、GPT2、Seq2Seq、BART、T5、SongNet等模型,开箱即用 TextGen: Implementation of Text Generation models 1.介绍 TextGen实现了多种文本生成模型,包括&a…...

文心一言 VS 讯飞星火 VS chatgpt (74)-- 算法导论7.2 2题
二、如果用go语言,当数组A的所有元素都具有相同值时,QUICKSORT的时间复杂度是什么? 文心一言: 在Go语言中,对一个所有元素都相等的数组进行快速排序(QuickSort)的时间复杂度是O(n log n)。 快速排序是一…...

大数据第二阶段测试
大数据第二阶段测试 一、简答题 Flume 采集使用上下游的好处是什么? 参考答案一 -上游和下游可以实现解耦,上游不需要关心下游的处理逻辑,下游不需要关心上游的数据源。 -上游和下游可以并行处理,提高整体处理效率。 -可以实现…...
06 为什么需要多线程;多线程的优缺点;程序 进程 线程之间的关系;进程和线程之间的区别
为什么需要多线程 CPU、内存、IO之间的性能差异巨大多核心CPU的发展线程的本质是增加一个可以执行代码工人 多线程的优点 多个执行流,并行执行。(多个工人,干不一样的活) 多线程的缺点 上下文切换慢,切换上下文典型值…...

datax-web报错收集
在查看datax时发现日志出现了如上错误,因为项目是部署在本地linux虚拟机上的,使用的是nat网络地址转换,不知道为什么虚拟机的端口号发生了变化,导致数据库根本连接不进去,更新linux虚拟机的ip地址就好...
YOLO相关原理(文件结构、视频检测等)
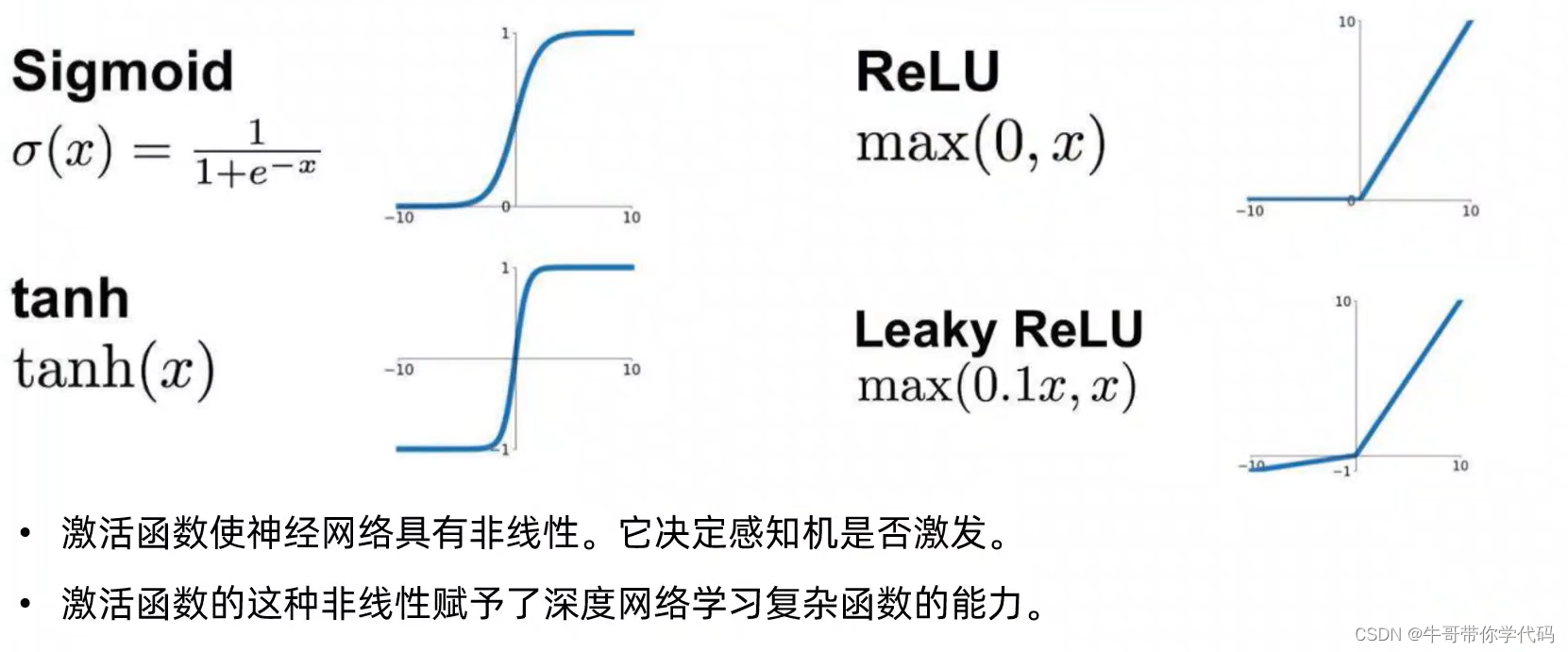
超参数进化(hyperparameter evolution) 超参数进化是一种使用了genetic algorithm(GA)遗传算法进行超参数优化的一种方法。 YOLOv5的文件结构 images文件夹内的文件和labels中的文件存在一一对应关系 激活函数:非线性处理单元 activation f…...

深入解析Spring Boot的核心特性与示例代码
系列文章目录 文章目录 系列文章目录前言一、自动配置(Auto-Configuration)二、起步依赖(Starter Dependencies)三、命令行界面(CLI)四、微服务支持五、内嵌Web服务器六、配置文件管理七、简化的日志配置八、健康检查与监控九、注解驱动开发十、外部化配置总结前言 Spri…...

什么是Java中的观察者模式?
Java中的观察者模式是一种设计模式,它允许一个对象在状态发生改变时通知它的所有观察者。这种模式在许多情况下都非常有用,例如在用户界面中,当用户与界面交互时,可能需要通知其他对象。 下面是一个简单的Java代码示例࿰…...

无涯教程-Perl - endhostent函数
描述 此函数告诉系统您不再希望使用gethostent从hosts文件读取条目。 语法 以下是此函数的简单语法- endhostent返回值 此函数不返回任何值。 例 以下是显示其基本用法的示例代码- #!/usr/bin/perlwhile( ($name, $aliases, $addrtype, $length, addrs)gethostent() ) …...

Vue2使用easyplayer
说一下easyplayer在vue2中的使用,vue3中没测试,估计应该差不多,大家可自行验证。 安装: pnpm i easydarwin/easyplayer 组件封装 习惯性将其封装为单独的组件 <template><div class"EasyPlayer"><e…...
)
远程桌面复制粘贴用不了?可能是组策略在‘捣鬼’,教你一键检查和修复(附GPUpdate命令)
企业级远程桌面剪贴板故障排查:从策略配置到进程管理的深度指南 当你作为企业IT管理员,在跨部门协作或远程支持时,突然发现无法通过远程桌面共享剪贴板内容,这种中断不仅影响效率,还可能延误关键业务流程。不同于个人用…...

Java的java.util.random测试使用
Java随机数生成实战:探索java.util.Random的奥秘在软件开发中,随机数生成是不可或缺的功能,无论是游戏开发、密码学还是模拟测试,都需要可靠的随机数支持。Java提供了强大的java.util.Random类,它不仅是生成随机数的利…...

FigmaCN:3分钟让Figma界面变中文,设计师工作效率提升50%
FigmaCN:3分钟让Figma界面变中文,设计师工作效率提升50% 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 你是否曾因Figma的全英文界面而感到困惑?是否…...

Xbyak跨平台开发:Windows/Linux/macOS三大系统部署教程
Xbyak跨平台开发:Windows/Linux/macOS三大系统部署教程 【免费下载链接】xbyak A JIT assembler for x86/x64 architectures supporting FPU, MMX, SSE (1-4), AVX (1-2, 512), APX, and AVX10.2 项目地址: https://gitcode.com/gh_mirrors/xb/xbyak Xbyak是…...
)
YOLOv11改进 | Neck篇 | CVPR最新低照度图像增强模块HVI改进YOLOv11(有效涨点)
一、本文介绍 本文给大家带来的最新改进机制是CVPR顶会中的一种新型颜色空间HVI机制,针对低照度图像增强任务中的红色区域断裂和暗区噪声问题。HVI通过极化映射重构色相表示,解决HSV中红色不连续问题,并引入可学习的强度塌缩机制稳定暗区几何分布。核心设计包括:1) 极坐标…...

DLSS Swapper:5分钟掌握游戏画质与性能双重提升秘籍
DLSS Swapper:5分钟掌握游戏画质与性能双重提升秘籍 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 还在为游戏画质模糊而烦恼?是否遇到过游戏帧率不稳定的困扰?DLSS Swapper正是为你…...

md 03号 测试文章A
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注…...

Flutter 翻页动画:前后翻页实现
在现代移动应用开发中,用户体验至关重要。一个好的阅读体验不仅需要内容丰富,还需要流畅的界面交互。今天,我们将探讨如何在 Flutter 中实现一个可以前后翻页的图书阅读页面。 背景 在 Flutter 中实现翻页效果,通常会使用第三方库,如 flip_widget 或 page_flip。这些库提…...

2026工业级实战:YOLO模型从200MB无损压缩到20MB,边缘部署帧率暴涨10倍全方案
在工业视觉、智能安防、移动机器人等端侧落地场景中,YOLO早已成为目标检测的绝对主流。但我们始终面临一个无解的矛盾:高精度的大模型(如YOLOv8x、YOLOv11x)动辄200MB,在Jetson Nano、瑞芯微RK3588、嵌入式工控机等边缘…...

生成式AI文档项目中的5个精彩演示应用深度解析
生成式AI文档项目中的5个精彩演示应用深度解析 【免费下载链接】generative-ai-docs This repository is deprecated and will be archived 项目地址: https://gitcode.com/gh_mirrors/ge/generative-ai-docs 生成式AI文档项目(generative-ai-docs࿰…...