flink读取kafka数据存储iceberg
1、说明
使用flink实时的读取kafka的数据,并且实时的存储到iceberg中。好处是可以一边存数据,一边查询数据。当然使用clickhouse也可以实现数据的既存既取。而hive数据既存既读则会有问题。iceberg中数据读写数据都是从快照中开始的,读和写对应的不同快照,所以读写互不影响。而hive中写的时候数据就不能读。
下面是使用flink读取kafka数据存储到iceberg的例子。本案例,可以直接在本地直接运行,无需搭建hadoop,hive集群。其中遇到的问题及解决思路。用到kafka,可以直接使用docker,来搞一个,跑起来。
2、实现步骤
1)确保flink和iceberg的版本对应
这里使用的是(flink:1.13.5,iceberg: 0.12.1 )
2) 创建流式执行环境
-
使用getExecutionEnvironment()的静态方法可以自动识别是本地环境还是集群服务环境。当然也可以使用createLocalEnvironment()方法创建本地环境。
该环境变量类似于上下文,可以配置一些基本的信息,如并行度(默认是CPU数)、检查时间间隔(默认不检查)。
-
这里设置检查为5000毫秒,到检查时间的时候 ,Flink向Iceberg中写入数据时当checkpoint发生后,才会commit数据(必须设置checkpoint)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);
3)指定kafka数据源创建数据流
-
设置读取kafka的一些参数,值的序列化使用的是字符串序列化模式(SimpleStringSchema);开始读取kafka数据,偏移量设置,则从最新的数据开始读取(latest)。
-
从指定的
source(源)中创建一个数据流。这里的source可能是Kafka读取数据,当然还可以从其他外部源如socket、Kinesis或其他数据源读取的数据。WatermarkStrategy.noWatermarks(),这是一个水印策略。用于处理事件时间(event-time)和处理有延迟或乱序的数据。WatermarkStrategy.noWatermarks()表示我们不想为这个数据流生成任何水印。这意味着我们可能是在做纯粹的基于处理时间(processing-time)的流处理,或者我们不关心事件时间的顺序。"kafka_source",这是给这个数据源分配的名称,主要用于日志记录和调试。
KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("node1:9094,node2:9094").setTopics("topic_users").setGroupId("flink-test-1").setValueOnlyDeserializer(new SimpleStringSchema()).setStartingOffsets(OffsetsInitializer.latest()).build();DataStreamSource<String> kafkaDs = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka_source");
4)流式数据转换器
- 上一步获取到的数据流,将数据流中的json字符串转为
RowData. 当然输入的数据格式可能是其它格式,根据实际情况进行修改。 - 注意
GenericRowData中字符串格式必须使用StringData.fromString(session.userId)来转换一下,否则无法存储到iceberg表中。
SingleOutputStreamOperator<RowData> dataStream = kafkaDs.map((MapFunction<String, RowData>) value -> {Gson gson = new Gson();Sessions session = gson.fromJson(value, Sessions.class);GenericRowData row = new GenericRowData(9);row.setField(0, session.version);row.setField(1, StringData.fromString(session.userId));row.setField(2, StringData.fromString(session.appType));row.setField(3, session.loginTime);row.setField(4, StringData.fromString(session.clientIp));row.setField(5, StringData.fromString(session.service));row.setField(6, session.status);row.setField(7, StringData.fromString(session.channel));row.setField(8, StringData.fromString(timeStamp2DateStr(session.loginTime)));return row;});
5)创建表(创建Catalog、表Id,表Schema、表分区、表文件存储格式等)
这里内容看起来比较多,但也就是一件事,建表。
-
创建 Hadoop 配置: 加载系统默认配置(core-default.xml, core-site.xml, mapred-default.xml, mapred-site.xml, yarn-default.xml, yarn-site.xml, hdfs-default.xml, hdfs-site.xml)
-
创建 Iceberg 的 Hadoop Catalog: 用来管理表创建、删除,以及元数据存储位置。这里使用hadoop存储元数据和实际数据。
-
指定表标识符: 对应数据库名称和表的名称。对应的数据也会存在
iceberg_db/flink_iceberg_tbl目录下。 -
定义表的 Schema:
这部分代码定义了表的结构,指定了每个字段的名称和类型。 -
定义分区:
PartitionSpec.builderFor(schema).identity("hour_p").build();按照hour_p字段来分区数据. 如果不见分许则使用PartitionSpec.unpartitioned()
PartitionSpec spec = PartitionSpec.builderFor(schema).identity("hour_p").build();
-
设置表属性: 设置了默认的文件格式为
PARQUET。 -
检查表是否存在,如果不存在则创建
-
创建 TableLoader:
TableLoader是用于加载Iceberg表的工具,这个目录是本地的数据存储的目录,以及数据库、数据表对应的名称。如果使用hdfs,则改为相应目录结构即可。
TableLoader tableLoader = TableLoader.fromHadoopTable("data/flinkwarehouse/iceberg_db/flink_iceberg_tbl");
// 创建默认的配置类,会自动加载hadoop相关的配置文件Configuration hadoopConf = new Configuration();// 设置Catalog的存储位置Catalog catalog = new HadoopCatalog(hadoopConf, "data/flinkwarehouse");// iceberg 数据库名称,数据表名称TableIdentifier name = TableIdentifier.of("iceberg_db", "flink_iceberg_tbl");// 数据表明模式,以及字段名称,字段类型Schema schema = new Schema(Types.NestedField.required(1, "version", Types.IntegerType.get()),Types.NestedField.required(2, "userId", Types.StringType.get()),Types.NestedField.required(3, "appType", Types.StringType.get()),Types.NestedField.required(4, "loginTime", Types.LongType.get()),Types.NestedField.required(5, "clientIp", Types.StringType.get()),Types.NestedField.required(6, "service", Types.StringType.get()),Types.NestedField.required(7, "status", Types.IntegerType.get()),Types.NestedField.required(8, "channel", Types.StringType.get()),Types.NestedField.required(9, "hour_p", Types.StringType.get()));// 设置分区 PartitionSpec spec = PartitionSpec.unpartitioned();PartitionSpec spec = PartitionSpec.builderFor(schema).identity("hour_p").build();// 设置 默认文件存储格式 parquet格式Map<String, String> props = ImmutableMap.of(TableProperties.DEFAULT_FILE_FORMAT, FileFormat.PARQUET.name());Table table = null;if (!catalog.tableExists(name)) {table = catalog.createTable(name, schema, spec, props);} else {table = catalog.loadTable(name);}TableLoader tableLoader = TableLoader.fromHadoopTable("data/flinkwarehouse/iceberg_db/flink_iceberg_tbl");6)创建FlinkSink读取流式数据存储到表中
- 接收一个数据流
- 指定相应的表
- 数据写入加载器中
7)执行环境开始执行任务
这里给任务一个简短的描述。
env.execute("iceberg api and flink ");
3、全部代码如下
1)build.gradle依赖如下配置
def flink = [version: '1.13.5'
]
def hadoop = [version: '3.2.2'
]def iceberg = [version: '0.12.1'
]dependencies {implementation 'com.alibaba.ververica:ververica-connector-iceberg:1.13-vvr-4.0.7'implementation "org.apache.iceberg:iceberg-flink-runtime:${iceberg.version}"implementation "org.apache.flink:flink-java:${flink.version}"implementation "org.apache.flink:flink-streaming-java_2.11:${flink.version}"implementation "org.apache.flink:flink-clients_2.11:${flink.version}"implementation "org.apache.flink:flink-streaming-scala_2.11:${flink.version}"implementation "org.apache.flink:flink-connector-kafka_2.11:${flink.version}"implementation "org.apache.flink:flink-connector-base:${flink.version}"implementation "org.apache.hadoop:hadoop-client:${hadoop.version}"implementation "org.apache.flink:flink-table-runtime-blink_2.11:${flink.version}"implementation "org.apache.flink:flink-table:${flink.version}"implementation "org.apache.flink:flink-table-common:${flink.version}"implementation "org.apache.flink:flink-table-api-java:${flink.version}"implementation "org.apache.flink:flink-table-api-java-bridge_2.11:${flink.version}"implementation "org.apache.flink:flink-table-planner_2.11:${flink.version}"implementation "org.apache.flink:flink-table-planner-blink_2.11:${flink.version}"testImplementation 'junit:junit:4.11'// log4j and slf4j dependencies testImplementation 'org.slf4j:slf4j-log4j12:1.7.25'testImplementation 'log4j:log4j:1.2.17'implementation 'org.slf4j:slf4j-api:1.7.25'testImplementation 'org.slf4j:slf4j-nop:1.7.25'testImplementation 'org.slf4j:slf4j-simple:1.7.5'implementation 'com.google.code.gson:gson:2.3.1'// 没有这个会出现报错,使用compilecompile 'com.google.guava:guava:28.2-jre'}
2)案例代码
package com.subao.flink;import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.data.StringData;
import org.apache.hadoop.conf.Configuration;
import org.apache.iceberg.*;
import org.apache.iceberg.catalog.Catalog;
import org.apache.iceberg.catalog.TableIdentifier;
import org.apache.iceberg.flink.TableLoader;
import org.apache.iceberg.flink.sink.FlinkSink;
import org.apache.iceberg.hadoop.HadoopCatalog;
import org.apache.iceberg.types.Types;import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.Map;public class FlinkIceberg {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// Flink向Iceberg中写入数据时当checkpoint发生后,才会commit数据(必须设置checkpoint)env.enableCheckpointing(5000);KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("124.70.194.33:9094,124.71.180.217:9094").setTopics("sessions").setGroupId("flink-test-1").setValueOnlyDeserializer(new SimpleStringSchema()).setStartingOffsets(OffsetsInitializer.latest()).build();DataStreamSource<String> kafkaDs = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka_source");SingleOutputStreamOperator<RowData> dataStream = kafkaDs.map((MapFunction<String, RowData>) value -> {Gson gson = new Gson();Sessions session = gson.fromJson(value, Sessions.class);GenericRowData row = new GenericRowData(9);row.setField(0, session.version);row.setField(1, StringData.fromString(session.userId));row.setField(2, StringData.fromString(session.appType));row.setField(3, session.loginTime);row.setField(4, StringData.fromString(session.clientIp));row.setField(5, StringData.fromString(session.service));row.setField(6, session.status);row.setField(7, StringData.fromString(session.channel));row.setField(8, StringData.fromString(timeStamp2DateStr(session.loginTime)));System.out.println(row);return row;});// 创建默认的配置类,会自动加载hadoop相关的配置文件Configuration hadoopConf = new Configuration();// 设置Catalog的存储位置Catalog catalog = new HadoopCatalog(hadoopConf, "data/flinkwarehouse");// iceberg 数据库名称,数据表名称TableIdentifier name = TableIdentifier.of("iceberg_db", "flink_iceberg_tbl");// 数据表明模式,以及字段名称,字段类型Schema schema = new Schema(Types.NestedField.required(1, "version", Types.IntegerType.get()),Types.NestedField.required(2, "userId", Types.StringType.get()),Types.NestedField.required(3, "appType", Types.StringType.get()),Types.NestedField.required(4, "loginTime", Types.LongType.get()),Types.NestedField.required(5, "clientIp", Types.StringType.get()),Types.NestedField.required(6, "service", Types.StringType.get()),Types.NestedField.required(7, "status", Types.IntegerType.get()),Types.NestedField.required(8, "channel", Types.StringType.get()),Types.NestedField.required(9, "hour_p", Types.StringType.get()));// 设置分区 PartitionSpec spec = PartitionSpec.unpartitioned();PartitionSpec spec = PartitionSpec.builderFor(schema).identity("hour_p").build();// 设置 默认文件存储格式 parquet格式Map<String, String> props = ImmutableMap.of(TableProperties.DEFAULT_FILE_FORMAT, FileFormat.PARQUET.name());Table table = null;if (!catalog.tableExists(name)) {table = catalog.createTable(name, schema, spec, props);} else {table = catalog.loadTable(name);}TableLoader tableLoader = TableLoader.fromHadoopTable("data/flinkwarehouse/iceberg_db/flink_iceberg_tbl");FlinkSink.forRowData(dataStream).table(table).tableLoader(tableLoader).overwrite(false).build();env.execute("iceberg api and flink ");}private static String timeStamp2DateStr(long timestamp) {// 将时间戳转为LocalDateTime对象LocalDateTime dateTime = LocalDateTime.ofInstant(Instant.ofEpochMilli(timestamp * 1000), ZoneId.systemDefault());// 定义日期时间格式DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyyMMddHH");// 格式化日期时间return dateTime.format(formatter);}class Sessions {private int version;private String userId;private String appType;private long loginTime;private String clientIp;private String service;private int status;private String channel;public Sessions(int version, String userId, String appType, long loginTime, String clientIp, String service, int status, String channel) {this.version = version;this.userId = userId;this.appType = appType;this.loginTime = loginTime;this.clientIp = clientIp;this.service = service;this.status = status;this.channel = channel;}public int getVersion() {return version;}public void setVersion(int version) {this.version = version;}public String getUserId() {return userId;}public void setUserId(String userId) {this.userId = userId;}public String getAppType() {return appType;}public void setAppType(String appType) {this.appType = appType;}public long getLoginTime() {return loginTime;}public void setLoginTime(long loginTime) {this.loginTime = loginTime;}public String getClientIp() {return clientIp;}public void setClientIp(String clientIp) {this.clientIp = clientIp;}public String getService() {return service;}public void setService(String service) {this.service = service;}public int getStatus() {return status;}public void setStatus(int status) {this.status = status;}public String getChannel() {return channel;}public void setChannel(String channel) {this.channel = channel;}@Overridepublic String toString() {return "Sessions{" +"version=" + version +", userId='" + userId + '\'' +", appType='" + appType + '\'' +", loginTime=" + loginTime +", clientIp='" + clientIp + '\'' +", service='" + service + '\'' +", status=" + status +", channel='" + channel + '\'' +'}';}}
}4、遇到的问题
1)找不到方法 java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkState。
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkState(ZLjava/lang/String;I)V
这个主要是相应的com.google.guava的版本不兼容,在build.gradle中加入如下即可
compile 'com.google.guava:guava:28.2-jre'
排查思路:
a) 看到这个我就想应该是相应的包没有正常添加到依赖中。
可以百度一下看看是哪个包,发现是com.google.guava包。
b) 检查现有依赖中是否包含该包
因为使用的是gradle,所以使用gradle的命令:gradle dependencies,从结果中查看,发现使用的hadoop中有多个包,版本不同,最大的是27.0的包。
c) 尝试使用高版本的guava的包
compile 'com.google.guava:guava:28.2-jre'
经测试是可以的。但这里主要要使用compile关键字。
compile和implementation都表示依赖文件在引入项目的编译期、运行期和测试期使用。但是compile标识的包可被其它依赖包使用,implementation则不可以。
compile关键字会将依赖项传递到项目的所有模块和依赖项中。这意味着如果模块 A 依赖于模块 B,并且模块 B 使用了compile关键字引入了一些依赖项,那么这些依赖项也会传递给模块 A。
implementation关键字只将依赖项传递到当前模块中,不会传递给依赖模块。这意味着如果模块 A 依赖于模块 B,并且模块 B 使用了implementation关键字引入了一些依赖项,那么这些依赖项不会传递给模块 A。由于
compile关键字会引入依赖的传递性,可能导致不可预期的副作用和冲突。为了解决这个问题,从 Gradle 3.4 版本开始,建议使用implementation关键字代替compile关键字,以减少依赖项传递引起的问题。
2) 数据文件为空
flink能够读取kafka的数据,但是不能将数据写到文件中。怎么办?于是问了问GPT,它说看看日志。我没有配置log4j的日志配置,当然看不到错误日志了。于是我就加上log4j.properties的配置文件。然后发现了如下错误:
2023-08-08 19:38:16 DEBUG JobMaster:658 - Archive local failure causing attempt 8d8beb11aa845d873ebbc317b21bf435 to fail: java.lang.ClassCastException: java.lang.String cannot be cast to org.apache.flink.table.data.StringDataat org.apache.flink.table.data.GenericRowData.getString(GenericRowData.java:169)at org.apache.flink.table.data.RowData.lambda$createFieldGetter$245ca7d1$1(RowData.java:221)at org.apache.iceberg.flink.data.FlinkParquetWriters$RowDataWriter.get(FlinkParquetWriters.java:453)
原来是数据格式不兼容的问题,对于Flink中的RowData中使用的是StringData表示字符串,因此在存入的时候需要把String类型转为StringData即可。如:
row.setField(2, StringData.fromString(session.appType));
总结:flink读取kafak数据用户的应该是比较多的,但是保存到iceberg中,这个相对用的比较少。flink中比较常用flink-sql来处理和数据表相关的数据。
相关文章:

flink读取kafka数据存储iceberg
1、说明 使用flink实时的读取kafka的数据,并且实时的存储到iceberg中。好处是可以一边存数据,一边查询数据。当然使用clickhouse也可以实现数据的既存既取。而hive数据既存既读则会有问题。iceberg中数据读写数据都是从快照中开始的,读和写对…...

文章二:分支管理策略 - 分支玩转:Git分支管理实战
开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun 概述 在软件开发中,版本控制是一项至关重要的工作。Git作为目前最受欢迎的分布式版本控制系统&…...

JS dom元素和鼠标位置之间的一系列属性快速参考
clientHeight 获取对象的高度,不计算任何边距、边框、滚动条,但包括该对象的补白。 clientLeft 获取 offsetLeft 属性和客户区域的实际左边之间的距离。 clientTop 获取 offsetTop 属性和客户区域的实际顶端之间的距离。 clie…...

【剑指 Offer 39】数组中超过一半的数字
题目: 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例: 输入: [1, 2, 3, 2, 2, 2, 5, 4, 2] 输出: 2 思考: 方法一:投…...

list.stream.filter,List<List>转换为List
1.filter过滤 返回符合查询条件的集合//过滤所有deviceType为1的List<DeviceWorkTimeEntity> list entities.stream().filter(a -> "1".equals(a.getDeviceType())).toList(); 2.List<List>转换为List 可以使用流(Stream)的flatMap操作 public cl…...

手机里视频太大怎么压缩?压缩教程分享
现在视频文件的体积越来越大了,动不动就是几个GB起步,如果后期再剪辑处理一下,更是会占据更多的设备空间了,还会导致我们传输受到限制,这时候就需要我们对视频进行压缩处理,下面给大家分享几个简单的方法&a…...

Spring-Cloud-Loadblancer详细分析_3
前两篇文章介绍了加载过程,本文从Feign的入口开始分析执行过程,还是从FeignBlockingLoadBalancerClient.execute来入手 public class FeignBlockingLoadBalancerClient implements Client {private static final Log LOG LogFactory.getLog(FeignBlock…...
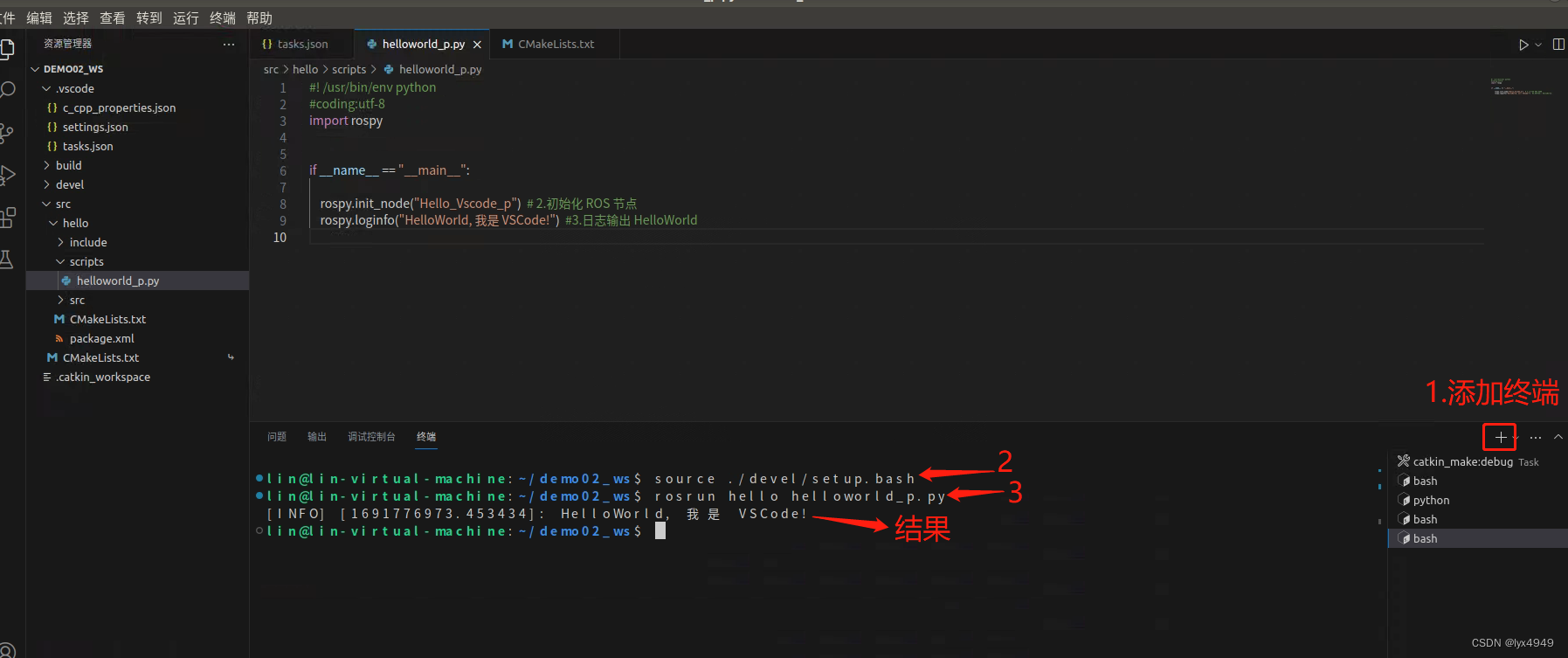
使用 VScode 开发 ROS 的Python程序(简例)
一、任务介绍 本篇作为ROS学习的第二篇,是关于如何在Ubuntu18.04中使用VSCode编写一个Python程序,输出“Hello!”的内容介绍。 首先我们来了解下ROS的文件系统,ROS文件系统级指的是在硬盘上ROS源代码的组织形式,其结构…...

2022年03月 C/C++(一级)真题解析#中国电子学会#全国青少年软件编程等级考试
第1题:双精度浮点数的输入输出 输入一个双精度浮点数,保留8位小数,输出这个浮点数。 时间限制:1000 内存限制:65536 输入 只有一行,一个双精度浮点数。 输出 一行,保留8位小数的浮点数。 样例输…...

HarmonyOS/OpenHarmony应用开发-ArkTSAPI系统能力SystemCapability列表
SysCap,全称SystemCapability,即系统能力,指操作系统中每一个相对独立的特性。 开发者使用某个接口进行开发前,建议先阅读系统能力使用说明,了解Syscap的定义和使用指导。 说明 当前列表枚举出3.1 Beta版本中支持的…...
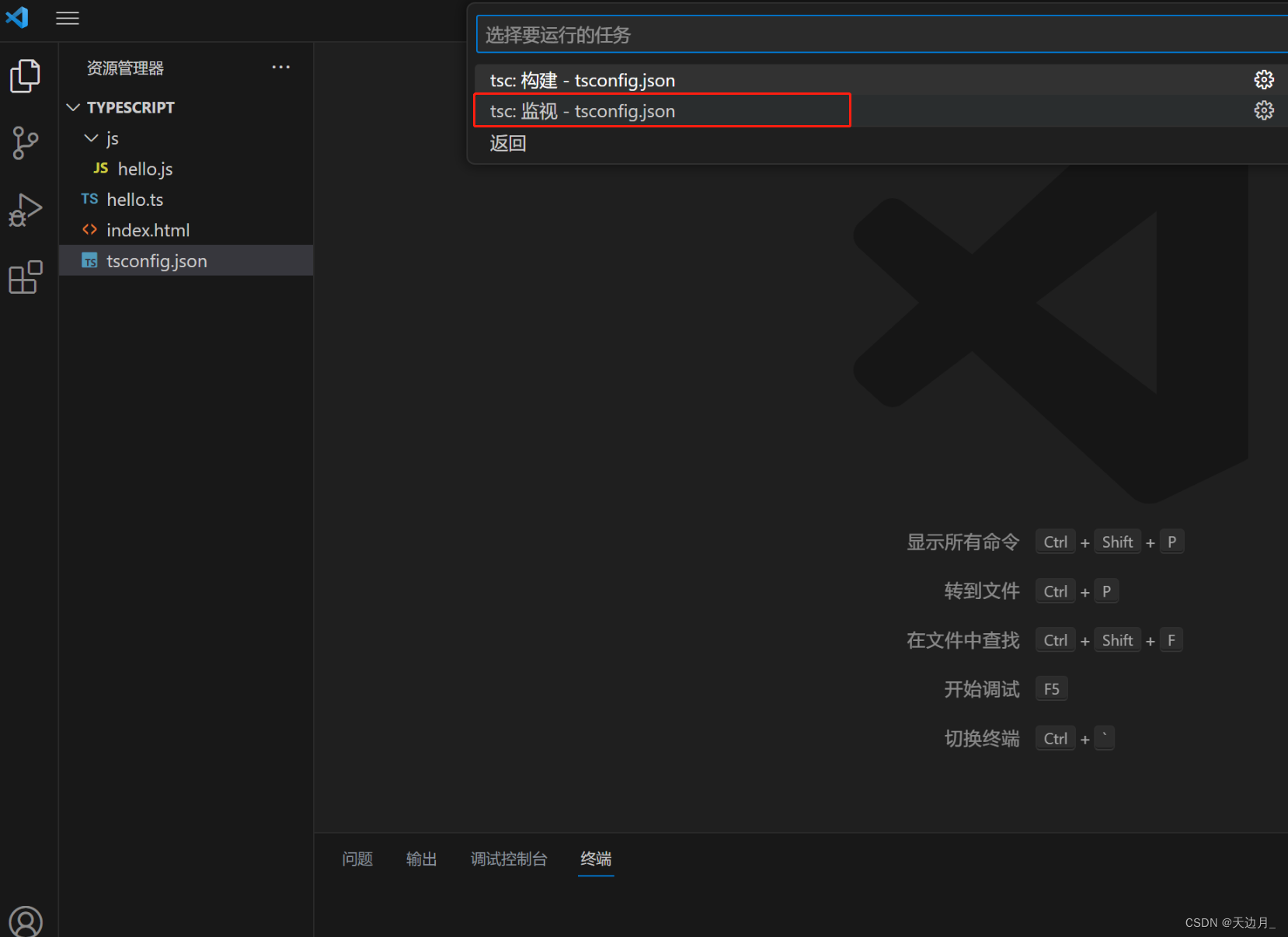
【01】基础知识:typescript安装及使用,开发工具vscode配置
一、typescript 了解 typeScript 是由微软开发的一款开源的编程语言。 typeScript 是 javascript 的超级,遵循最新的 es6、es5规范。 typeScript 扩展了 javaScript 的语法。 typeScript 更像后端 java、C# 这样的面向对象语言,可以让 js 开发大型企…...
)
用C++实现的RTS游戏的路径查找算法(A*、JPS、Wall-tracing)
在实时策略(RTS)游戏中,路径查找是一个关键的问题。游戏中的单位需要能够找到从一个地方到另一个地方的最佳路径。这个问题在计算机科学中被广泛研究,有许多已经存在的算法可以解决这个问题。在本文中,我们将探讨三种在…...

helm 制作应用的离线安装包
helm 制作应用的离线安装包 1、安装helm 到helm下载对应的压缩包:https://github.com/helm/helm/releases 解压,将helm文件cp到/usr/local/bin/ 文件夹下,查看helm版本;不同的k8s对应不同的helm版本,下载时留心注意…...

RN实现混合式开发-内嵌html
介绍 React Native WebView是一个用于在React Native应用中嵌入Web内容的组件。它允许你在应用中显示网页、加载HTML字符串、运行JavaScript代码等。 使用 首先,你需要在你的React Native项目中安装React Native WebView库。可以使用以下命令进行安装:…...

2000-2022年全国各地级市绿色金融指数数据
2000-2022年全国各地级市绿色金融指数数据 1、时间:2000-2022年 2、来源:来源:统计局、科技部、中国人民银行等权威机构网站及各种权威统计年鉴,包括全国及各省市统计年鉴、环境状况公报及一些专业统计年鉴,如 《中国…...
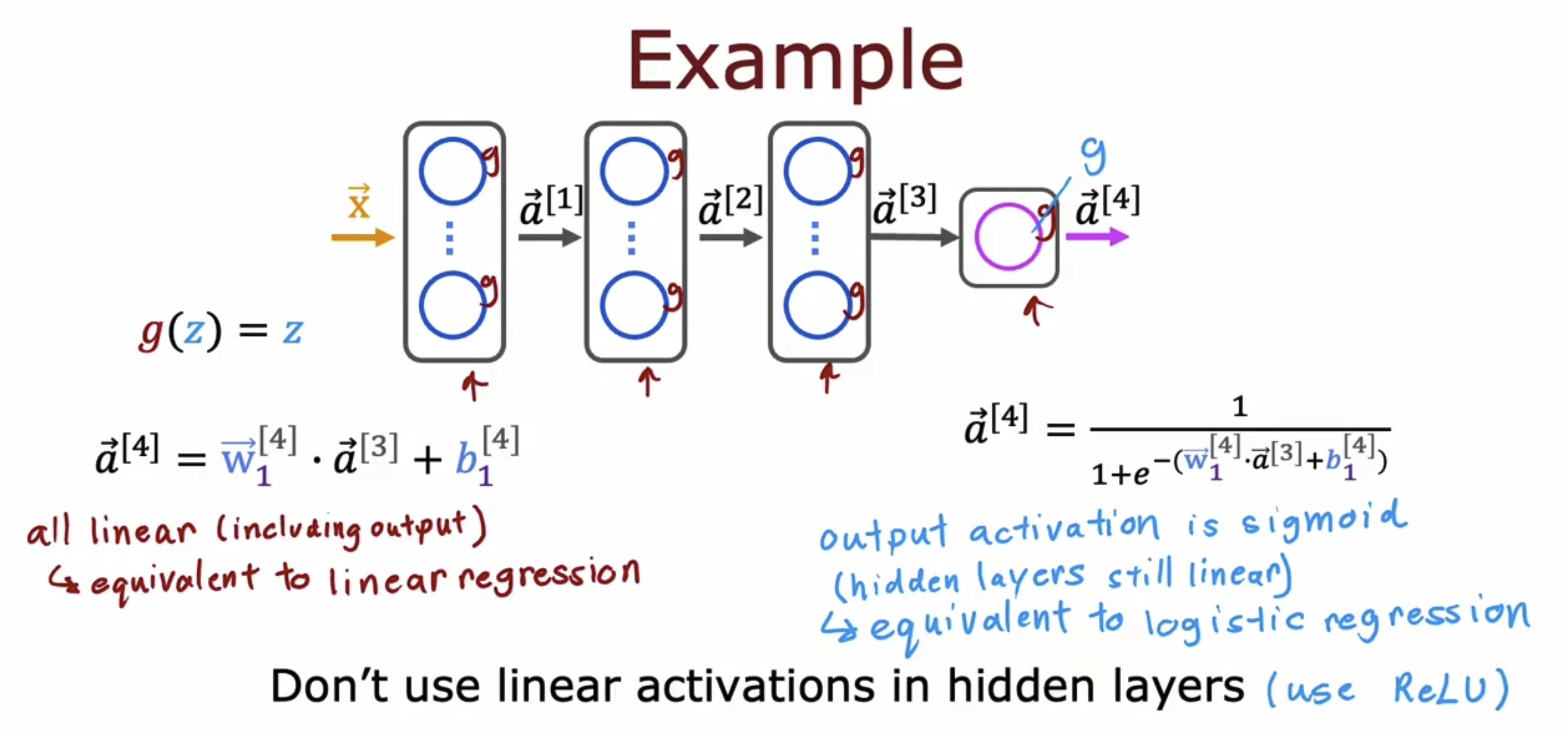
MachineLearningWu_13/P60-P64_Tensorflow
P60-P64的学习目录如下, x.1 TF网络模型实现 以一个简单的TF的分类网络为例,将模型翻译成框架下的语义,即如右侧所表达的。 当然上面对于分类网络的解释是一个简洁的解释,我们来进行更加具象的了解一下。左边是机器学习的三步骤&…...

centos7实现负载均衡
目录 一、基于 CentOS 7 构建 LVS-DR 集群。 1.1 配置lvs负载均衡服务 1.1.1 下载ipvsadm 1.1.2 增加vip 1.1.3 配置ipvsadm 1.2 配置rs1 1.2.1 编写测试页面 1.2.2 手工在RS端绑定VIP、添加路由 1.2.3 抑制arp响应 1.3 配置rs2 1.4 测试 二、配置nginx负载…...
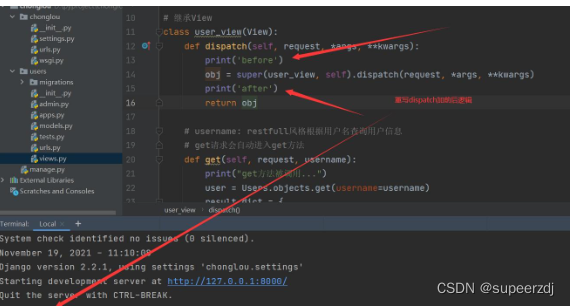
Django笔记之数据库函数之日期函数
日期函数主要介绍两个大类,Extract() 和 Trunc() Extract() 函数作用是提取日期,比如我们可以提取一个日期字段的年份,月份,日等数据 Trunc() 的作用则是截取,比如 2022-06-18 12:12:12,我们可以根据需求…...

系统架构师---开发方法---敏捷开发
目录 前言 极限编程 四大价值观 沟通 简单 反馈 勇气 尊重: 十二个最佳实践 计划游戏 小型发布 隐喻 简单设计 测试先行 重构 结对编程 集体代码所所有制 持续集成 每周工作40小时 现场客户 编码标准 前言 2001年2月,在美国的犹他州…...

数据中心液冷技术:规模扩张的新里程碑
数据中心液冷技术:规模扩张的新里程碑 数据中心的液冷技术正处在规模扩张的关键阶段。这篇文章将深入探讨液冷技术的发展历程,当前的应用状况,以及未来的发展趋势。 目录 液冷技术的发展历程液冷技术的当前应用状况液冷技术的优势与挑战数据…...

Linux CH341SER驱动终极指南:5个步骤解决USB转串口连接问题
Linux CH341SER驱动终极指南:5个步骤解决USB转串口连接问题 【免费下载链接】CH341SER CH341SER driver with fixed bug 项目地址: https://gitcode.com/gh_mirrors/ch/CH341SER 想要在Linux系统中使用Arduino、ESP8266等开发板,却发现USB设备无法…...

必看!北京别墅改造公司专业深度测评,排名前五之首竟是它!
《【北京别墅改造】哪家好:专业深度测评排名前五》开篇:定下基调在当今社会,越来越多的人希望对自己的别墅进行改造,以满足个性化的居住需求。为了帮助大家在众多的别墅改造公司中选出最适合自己的,我们展开了本次测评…...

认识 DeerFlow:一个跑在 LangGraph 上的 Super Agent Harness
DeerFlow 给自己的定位不是"又一个 Agent 框架",而是 Super Agent Harness。这个词不是随便用的——它意味着 DeerFlow 要解决的不是"Agent 能不能跑",而是"Agent 能不能跑得住"。它和 Harness Engineering、Agent Team、…...

LLM在RTL设计规范生成中的技术突破与实践
1. 大型语言模型在RTL设计规范生成中的技术突破作为一名在EDA行业深耕多年的硬件工程师,我见证了从手工编写设计文档到AI辅助生成的整个技术演进过程。RTL(Register-Transfer Level)作为数字电路设计的关键抽象层,其规范文档需要精…...

PHP函数是否支持调用FPGA设备_PHP与FPGA硬件交互的实现方式【教程】
PHP无法直接调用FPGA设备,必须通过C编写的命令行工具(如fpga_ctl)间接操作,依赖正确权限配置、固件加载及稳定外围机制。PHP 本身不能直接调用 FPGA 设备PHP 是用户态脚本语言,没有内核权限,也不提供硬件寄…...

告别Qt Creator,在VS2019里丝滑开发Qt5.14.2项目:保姆级插件配置与项目迁移指南
在VS2019中高效开发Qt5.14.2项目的终极指南 对于习惯使用Visual Studio的C开发者来说,Qt Creator虽然功能完善,但总有些不够顺手。本文将带你彻底摆脱Qt Creator的束缚,在熟悉的VS2019环境中实现Qt项目的无缝开发和调试。 1. 环境准备与工具配…...

巴法云图片上传踩坑实录:ESP32的HTTP POST请求,为什么你的图片超过35KB就显示失败?
ESP32图片上传35KB限制全解析:从内存分配到HTTP优化的完整解决方案 在物联网项目中,ESP32因其出色的性价比和丰富的功能库成为硬件开发的热门选择。但当涉及到图片上传这类资源密集型操作时,许多开发者都会遇到一个看似简单却令人困惑的问题—…...

Steam成就管理器终极指南:5分钟掌握游戏成就修改完整方案
Steam成就管理器终极指南:5分钟掌握游戏成就修改完整方案 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Managerÿ…...
)
仅限首批200家三甲医院技术科获取的VSCode医疗校验配置包(含NMPA审评要点映射表)
更多请点击: https://intelliparadigm.com 第一章:VSCode医疗校验配置包的权威性与临床合规价值 VSCode医疗校验配置包并非通用开发插件,而是由国家药品监督管理局(NMPA)认证医疗器械软件质量评估机构联合HL7 China工…...

从零搭建VSCode下的PyQt5桌面开发工作流:集成Python、Qt Designer与高效调试
1. 为什么选择VSCodePyQt5开发桌面应用? 作为一个长期使用PyQt5开发桌面应用的老手,我尝试过各种开发环境组合,最终发现VSCodePyQt5是最适合个人开发者和小型团队的方案。你可能会有疑问:为什么不用PyCharm这样的专业Python IDE&…...