python爬虫实战(1)——网站小说
整本小说的爬取保存
- 目标
- 大致思路
- 页面的爬取解析—XPath
- 请求网页内容
- 解析网页内容
- 正文爬取与解析
- 单个页面数据获取
- 爬取所有页面
- 数据清洗
经过学习基础,我们学以致用一下子,爬取小说,注意这个小说本身是免费的哦,以后再进阶。
本次为实战记录,笔者很多碎碎念可忽略
目标
基于requests库和lxml中的xpath编写的爬虫,目标小说网站域名http://www.365kk.cc/
这是网上找的,小说网址很多,而且没有很多反扒机制,新手友好!
大致思路
其实也可以不写,梳理一下吧,虽然是空话
主要分三步(如同大象进冰箱hh)
- 获取网页内容,通过requests库实现;
- 解析网页内容,得到其中我们想要的部分,通过xpath实现;
- 将解析出的内容储存到文本文档中;
我们把要做的具体化,首先选取一本自己喜欢的小说,笔者以此为例,是的就是这么重口。
《我是一具尸体》

页面的爬取解析—XPath
要干嘛明确一下:
- 获取目标书籍的基本信息,包括书籍的书名、作者、简介——这些信息应该都在同一个页面中获取,即上面展示的页面;
- 获取目标书籍每一章节的标题和内容——不同章节在不同的页面,不同页面之间可以通过下一页按序跳转;
- 正文部分的存储格式应便于阅读,不能把所有文字都堆积在一起,也不能包括除了正文之外的其他无关内容;
因此,我们首先尝试请求书籍的主页,获取基本信息;紧接着再从书籍的第一章开始,不断地请求“下一页”,直到爬取整本书,并将它们以合适的格式储存在文本文档中。
笔者是用Google Chrome,在首页点击右键 —> 检查:

可以看出,浏览器下方弹出了一个窗口,这里显示的就是该页面的源代码,我们选中的内容位于一个<h1>标签中。点击右键 -> 复制 -> 复制 XPath,即可得到书名的XPath路径,也就是书名在网页中的位置。
书名:/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1
从书籍的首页中,同理我们可以获取的信息主要包括:
- 书名 作者 最后更新时间
作者:/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]
最后更新时间:/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]
简介:/html/body/div[4]/div[1]/div/div/div[2]/div[2]
请求网页内容
使用基础的python爬虫网页请求方法: requests 库直接请求。
在请求网页时,我们需要将我们的爬虫伪装成浏览器,具体通过添加请求头 headers 实现。
请求头以字典的形式创建,可以包括很多内容,这里只设置四个字段:User-Agent, Cookie, Host 和 Conection。
在刚才打开的页面中,点击 网络(英文版是Network),刷新页面,找到其中的第一个文件 1053/ ,打开 标头 -> 请求标头 ,即可得到想要的字段数据。

import requests# 请求头,添加你的浏览器信息后才可以正常运行
headers= {'User-Agent': '...','Cookie': '...','Host': 'www.365kk.cc','Connection': 'keep-alive'
}
# 小说主页
main_url = "http://www.365kk.cc/1/1053/"
# 使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)
# 将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')
print(main_text)可以看出,我们成功请求到了网站内容,接下来只需对其进行解析,即可得到我们想要的部分。
解析网页内容
我们使用 lxml 库来解析网页内容,具体方法为将文本形式的网页内容创建为可解析的元素,再按照XPath路径访问其中的内容,代码如下:
import requests
from lxml import etree# 请求头
headers= {'User-Agent': '...','Cookie': '...','Host': 'www.365kk.cc','Connection': 'keep-alive'
}# 小说主页
main_url = "http://www.365kk.cc/1/1053/"
# 使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)
# 将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')# 将文本内容创建为可解析元素
main_html = etree.HTML(main_text)# 依次获取书籍的标题、作者、最近更新时间
# main_html.xpath返回的是列表,因此需要加一个[0]来表示列表中的首个元素
# /text() 表示获取文本
bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()')[0]
author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()')[0]
update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()')[0]
introduction = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()')[0]
# 输出结果以验证
print(bookTitle)
print(author)
print(update)
print(introduction)
输出结果如下:

至此,使用基本的网页请求get方法获取目标页面中的特定内容结束,接下来就是正文解析了,
go go go
正文爬取与解析
开始爬取正文。首先尝试获取单个页面的数据,再尝试设计一个循环,依次获取所有正文数据
单个页面数据获取
打开第一章,获取章节标题和正文的XPath路径如下:

书名://*[@id="container"]/div/div/div[2]/h1
内容://*[@id="content"]
按照与上文一致的方法请求并解析网页内容,代码如下:
注意到在用这个xpath路径的时候我们是只要里面的文字部分所以要多加一个/text()
import requests
from lxml import etree# 请求头
headers= {'User-Agent': '...','Cookie': '...','Host': 'www.365kk.cc','Connection': 'keep-alive'
}# 当前页面链接
url = 'http://www.365kk.cc/1/1053/10094192.html'
resp = requests.get(url, headers)
text = resp.content.decode('utf-8')html = etree.HTML(text)title = html.xpath('//*[@id="container"]/div/div/div[2]/h1/text()')[0]
contents = html.xpath('//*[@id="content"]/text()')print(title)
for content in contents:print(content)
可以看出,我们成功获取了小说第一章第一页的标题和正文部分

接下来我们将它储存在一个txt文本文档中,关于文件读取类型主要有(并不全,只是本代码用到的)
'w': 清空原文档,重新写入文档 open(filename, ‘w’)'r': 仅读取文档,不改变其内容 open(filename, ‘r’)'a': 在原文档之后追加内容 open(filename, ‘a’)
文档命名为之前获取的书名 bookTitle.txt,完整的代码如下:
import requests
from lxml import etree# 请求头
headers= {'User-Agent': '...','Cookie': '...','Host': 'www.365kk.cc','Connection': 'keep-alive'
}# 小说主页
main_url = "http://www.365kk.cc/1/1053/"# 使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)# 将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')# 将文本内容创建为可解析元素
main_html = etree.HTML(main_text)bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()')[0]
author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()')[0]
update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()')[0]
introduction = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()')[0]# 第一章页面链接
url = 'http://www.365kk.cc/1/1053/10094192.html'resp = requests.get(url, headers)
text = resp.content.decode('utf-8')
html = etree.HTML(text)
title = html.xpath('//*[@id="container"]/div/div/div[2]/h1/text()')[0]
contents = html.xpath('//*[@id="content"]/text()')with open(bookTitle + '.txt', 'w', encoding='utf-8') as f:f.write(title)for content in contents:f.write(content)# 在储存文件时,每储存一段,就写入两个换行符 `\n`,避免大段文字堆积使格式更便于阅读f.write('\n\n')f.close()
运行结束后,可以看到在代码文件的同路径中,已经生成了一个文本文档。至此,我们已经完成了单个页面的数据爬取和存储,接下来只要设计循环,实现顺序爬取所有页面即可。

爬取所有页面
我们注意到,正文的每个页面底部,都有一个按钮下一页,其在网页中的结构为:

在XPath路径的末尾添加 @href 用于获取属性 href 的值:
//*[@id="container"]/div/div/div[2]/div[3]/a[3]/@href
注意到如果一章结束,下一页和下一章的链接就会有些差别

观察不同页面的链接,可以看出前缀是一致的,区别仅在后缀上,比如第一章第一页和第一章第二页的链接分别为:
http://www.365kk.cc/1/1053/10094192.html
http://www.365kk.cc/1/1053/10094192_2.html
因此,我们只需要获取下一页的链接后缀,再与前缀拼接,即可获得完整的访问链接。代码如下:
# 获取下一页链接的函数
def next_url(next_url_element):nxturl = 'http://www.365kk.cc/1/1053/'# rfind('/') 获取最后一个'/'字符的索引index = next_url_element.rfind('/') + 1nxturl += next_url_element[index:]return nxturlurl1 = '/1/1053/10094192_2.html'
url2 = '10094193.html'print(next_url(url1))
print(next_url(url2))在爬取某一页面的内容后,我们获取下一页的链接,并请求该链接指向的网页,重复这一过程直到全部爬取完毕为止,即可实现正文的爬取。

在这一过程中,需要注意的问题有:
某一章节的内容可能分布在多个页面中,每个页面的章节标题是一致的,这一标题只需存储一次;
请求网页内容的频率不宜过高,频繁地使用同一IP地址请求网页,会触发站点的反爬虫机制,禁止你的IP继续访问网站;
爬取一次全文耗时较长,为了便于测试,我们需要先尝试爬取少量内容,代码调试完成后再爬取全文;
爬取的起点为第一章第一页,爬取的终点可以自行设置;
按照上述思想,爬取前4个页面作为测试,完整的代码如下:
import requests
from lxml import etree
import time
import random# 获取下一页链接的函数
def next_url(next_url_element):nxturl = 'http://www.365kk.cc/1/1053/'# rfind('/') 获取最后一个'/'字符的索引index = next_url_element.rfind('/') + 1nxturl += next_url_element[index:]return nxturl# 请求头,需要添加你的浏览器信息才可以运行
headers= {'User-Agent': '...','Cookie': '...','Host': 'www.365kk.cc','Connection': 'keep-alive'
}# 小说主页
main_url = "http://www.365kk.cc/1/1053/"# 使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)# 将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')# 将文本内容创建为可解析元素
main_html = etree.HTML(main_text)bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()')[0]
author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()')[0]
update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()')[0]# 调试期间仅爬取4个页面
maxPages = 4
cnt = 0
# 记录上一章节的标题
lastTitle = ''# 爬取起点
url = 'http://www.365kk.cc/1/1053/10094192.html'
# 爬取终点
endurl = 'http://www.365kk.cc/1/1053/10094194.html'while url != endurl:cnt += 1 # 记录当前爬取的页面if cnt > maxPages:break # 当爬取的页面数超过maxPages时停止resp = requests.get(url, headers)text = resp.content.decode('utf-8')html = etree.HTML(text)title = html.xpath('//*[@class="title"]/text()')[0]contents = html.xpath('//*[@id="content"]/text()')# 输出爬取进度信息print("cnt: {}, title = {}, url = {}".format(cnt, title, url))with open(bookTitle + '.txt', 'a', encoding='utf-8') as f:if title != lastTitle: # 章节标题改变f.write(title) # 写入新的章节标题lastTitle = title # 更新章节标题for content in contents:f.write(content)f.write('\n\n')f.close()# 获取"下一页"按钮指向的链接next_url_element = html.xpath('//*[@class="section-opt m-bottom-opt"]/a[3]/@href')[0]# 传入函数next_url得到下一页链接url = next_url(next_url_element)sleepTime = random.randint(2, 5) # 产生一个2~5之间的随机数time.sleep(sleepTime) # 暂停2~5之间随机的秒数print("complete!")
运行结果如下:

数据清洗
观察我们得到的文本文档,可以发现如下问题:
- 缺乏书籍信息,如之前获取的书名、作者、最后更新时间;
- 切换页面时,尤其是同一章节的不同页面之间空行过多;
- 每章节第一段缩进与其他段落不一致;
- 不同章节之间缺乏显眼的分隔符;
为了解决这些问题,我们编写一个函数 clean_data() 来实现数据清洗,清洗后的文档中,每段段首无缩进,段与段之间仅空一行,不同章节之间插入20个字符 - 用以区分,问题得以解决。
完整代码,需要自取哦
小说爬虫
相关文章:
python爬虫实战(1)——网站小说
整本小说的爬取保存 目标大致思路页面的爬取解析—XPath请求网页内容解析网页内容正文爬取与解析单个页面数据获取爬取所有页面 数据清洗 经过学习基础,我们学以致用一下子,爬取小说,注意这个小说本身是免费的哦,以后再进阶。 本次…...

git: ‘lfs‘ is not a git command. see ‘git --help‘
在克隆hugging face里面的项目文件的时候,需要用到git lfs,本文介绍安装git lfs方法 在Ubuntu下 curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash sudo apt-get install git-lfs在Windows下 到这个链…...

python案例
这猜单词游戏。具体步骤如下: 导入random模块,用于随机选择单词。 设置初始生命次数为3。 创建一个单词列表words,其中包含了一些单词。 使用random.choices()函数从单词列表中随机选择一个单词作为秘密单词secret_word。 创建一个clue列表&a…...
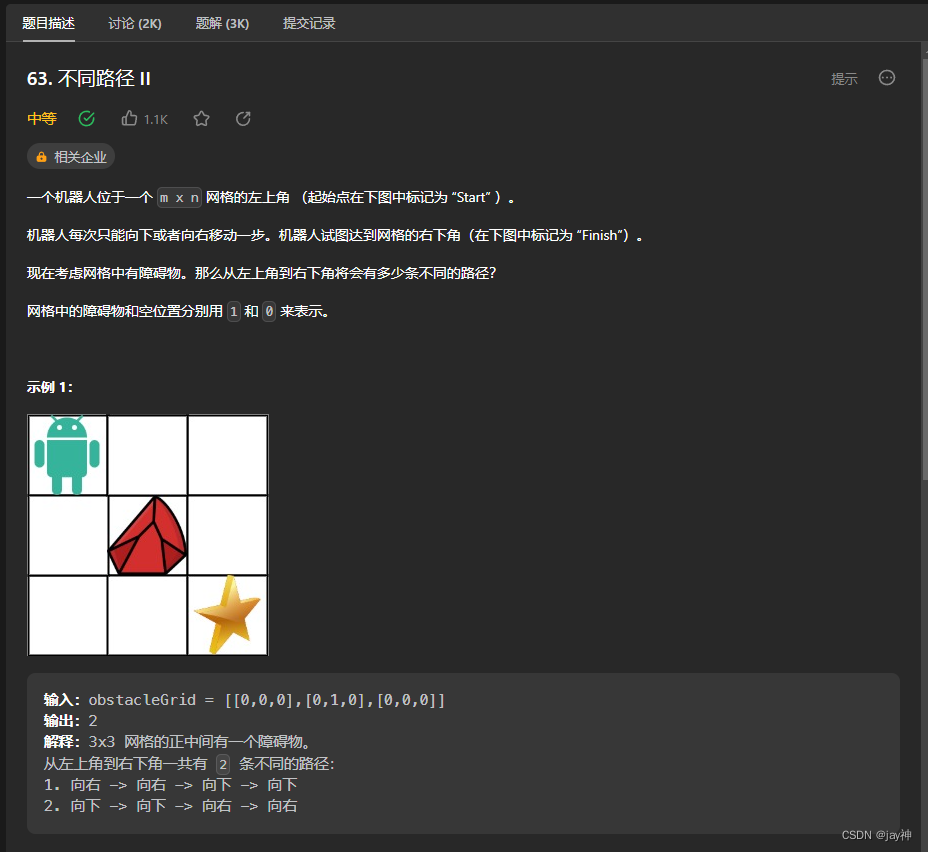
leetcode 63. 不同路径 II
2023.8.9 这题是不同路径I的升级版,在路径上增加了障碍物,有障碍物的地方无法通过。 我的思路依然还是使用动态规划,dp[i][j]的含义依然是到(i,j)这个位置的路径个数。只需要在dp数组中将有障碍物的地方赋为…...

c语言每日一练(5)
前言:每日一练系列,每一期都包含5道选择题,2道编程题,博主会尽可能详细地进行讲解,令初学者也能听的清晰。每日一练系列会持续更新,暑假时三天之内必有一更,到了开学之后,将看学业情…...
pycharm配置conda虚拟环境
📕作者简介:热编程的贝贝,致力于C/C、Java、Python等多编程语言,热爱跑步健身,喜爱音乐的一位博主。 📗本文收录于贝贝的日常汇报系列,大家有兴趣的可以看一看 📘相关专栏深度学习、…...
ubuntu 如何命令行打开系统设置(Wifi,网络,应用程序...)
关于GNOME GNOME 是一个自由、开放源代码的桌面环境,它运行在 Linux 和其他类 UNIX 操作系统上。它是 GNU 项目的一部分,旨在为 Linux 操作系统提供一个现代化、易于使用的用户界面。 GNOME 桌面环境包括许多应用程序,例如文件管理器、文本编…...

MySQL DQL 数据查询
文章目录 1.SELECT 语句2.SELECT 子句3.FROM 子句4.WHERE 子句5.GROUP BY 子句6.HAVING 子句7.ORDER BY 子句8.LIMIT 子句9.DISTINCT 子句10.JOIN 子句11.UNION 子句12.查看数据表记录数13.检查查询语句的执行效率14.查看 SQL 执行时的警告参考文献 1.SELECT 语句 MySQL 的 SE…...
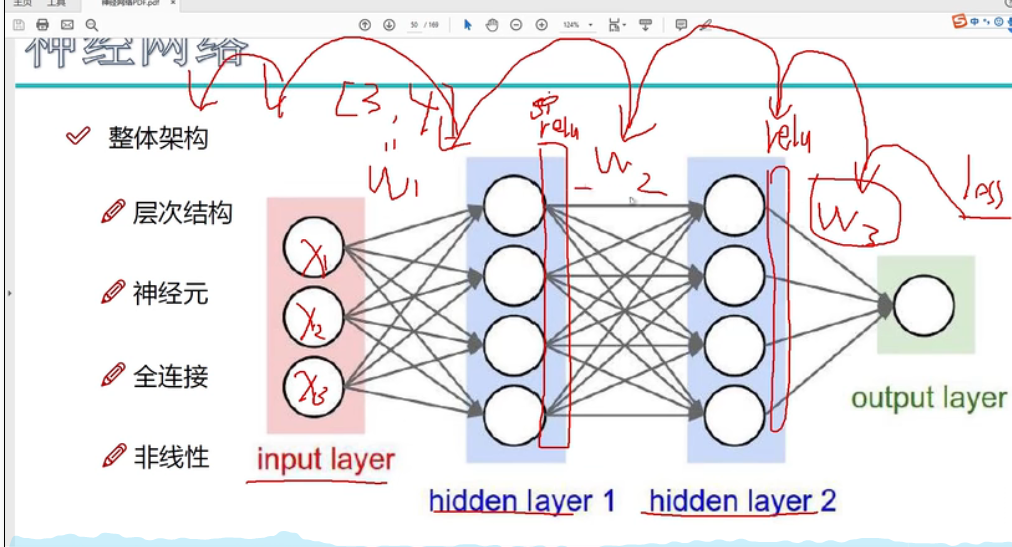
深度学习基础知识笔记
深度学习要解决的问题 1 深度学习要解决的问题2 应用领域3 计算机视觉任务4 视觉任务中遇到的问题5 得分函数6 损失函数7 前向传播整体流程8 返向传播计算方法1 梯度下降 9 神经网络整体架构11 神经元个数对结果的影响12 正则化和激活函数1 正则化2 激活函数 13 神经网络过拟合…...

怎么系统的学习机器学习、深度学习?当然是看书了
目录 前言 内容简介 学完本书,你将能够 作者简介 本书目录 京东自购链接 前言 近年来,机器学习方法凭借其理解海量数据和自主决策的能力,已在医疗保健、 机器人、生物学、物理学、大众消费和互联网服务等行业得到了广泛的应用。自从Ale…...

无涯教程-Perl - binmode函数
描述 此函数设置在区分两者的操作系统上以二进制形式读取和写入FILEHANDLE的格式。非二进制文件的CR LF序列在输入时转换为LF,在LF时在输出时转换为CR LF。这对于使用两个字符分隔文本文件中的行的操作系统(MS-DOS)至关重要,但对使用单个字符的操作系统(Unix,Mac OS,QNX)没有影…...

Spring Boot Maven package时显式的跳过test内容
在pom.xml的编译插件部分显式的增加一段内容: <plugin> <!-- maven打包时,显式的跳过test部分 --><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>3.…...

排序算法————基数排序(RadixSort)
基数排序的概念: 什么是基数排序???基数排序是一种和快排、归并、希尔等等不一样的排序...它不需要比较和移动就可以完成整型的排序。它是时间复杂度是O(K*N),空间复杂度是O(KM&…...

leetcode做题笔记75颜色分类
给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sort 函数的情况下解决…...

聊一下互联网开源变现
(点击即可收听) 互联网开源变现其实是指通过开源软件或者开放源代码的方式,实现收益或盈利。这种方式越来越被广泛应用于互联网行业 在互联网开源变现的模式中,最常见的方式是通过捐款、广告、付费支持或者授权等方式获利。 例如,有些开源软件…...

PHP日期差计算器,计算两个时间相差 年/月/日
1. 计算两个日期相隔多少年,多少月,多少天示例:laravel框架实现 /*** 天数计算* return \Illuminate\Http\JsonResponse*/public function loveDateCal(){$start_date $this->request(start_date);$end_date $this->request(end_date…...
20230812在WIN10下使用python3将SRT格式的字幕转换为SSA格式
20230812在WIN10下使用python3将SRT格式的字幕转换为SSA格式 2023/8/12 20:58 本文的SSA格式以【Batch Subtitles Converter(批量字幕转换) v1.23】的格式为准! 1、 缘起:网上找到的各种各样的字幕转换软件/小工具都不是让自己完全满意! 【都…...
matlab使用教程(13)—稀疏矩阵创建和使用
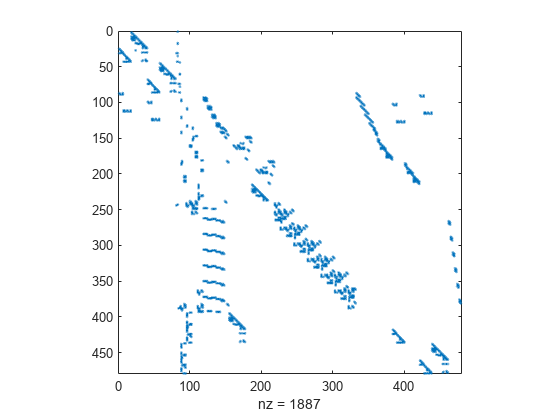
使用稀疏矩阵存储包含众多零值元素的数据,可以节省大量内存并加快该数据的处理速度。sparse 是一种属性,可以将该属性分配给由 double 或 logical 元素组成的任何二维 MATLAB 矩阵。通过 sparse 属性,MATLAB 可以: • 仅存储矩…...

UI美工设计的主要职责(合集)
UI美工设计的主要职责1 职责: 1、执行公司的规章制度及专业管理办法; 2、 负责重点项目的原型设计和产品流程设计、视觉设计,优化网站和移动端的设计流程和规范,制定产品 UI/UE规范及文档编写; 3、负责使用PS、AI、illustrator、MarkMan、…...
【前端二次开发框架关于关闭eslint】
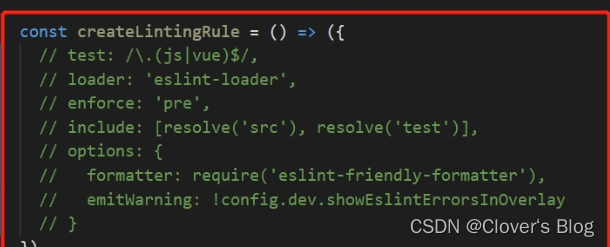
前端二次开发框架关于关闭eslint 方法一方法二方法三方法四:以下是若想要关闭项目中的部分代码时: 方法一 在vue.config.js里面进行配置: module.exports {lintOnSave:false,//是否开启eslint保存检测 ,它的有效值为 true || false || err…...

智慧校园的权限管控,如何按角色精准设置操作范围?
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

倾斜光栅的参数优化及公差分析
摘要 对于背光系统、光内连器和近眼显示器等许多应用来说,将光高效地耦合到引导结构中是一个重要的问题。对于这种应用,倾斜光栅以能够高效地耦合单色光而闻名。在本例中,提出了利用严格傅里叶模态方法(FMM,也称为RCWA…...
)
别再傻傻全量引入antd了!React项目用craco+less-loader搞定按需加载与主题定制(附最新版本避坑指南)
2023终极方案:用cracoless-loader实现antd按需加载与主题定制 在React生态中,antd作为企业级UI库的标杆,其丰富的组件和设计语言深受开发者喜爱。但随着项目规模扩大,全量引入antd带来的性能问题逐渐显现——一个中型项目仅antd样…...

Maple Mono终极指南:如何快速打造你的完美编程字体体验
Maple Mono终极指南:如何快速打造你的完美编程字体体验 【免费下载链接】maple-font Maple Mono: Open source monospace font with round corner, ligatures and Nerd-Font icons for IDE and terminal, fine-grained customization options. 带连字和控制台图标的…...

别再手动记代码了!用这个开源VBA工具箱,把Excel变成你的私人代码库
解放双手:用开源VBA工具箱打造你的Excel智能代码库 每次打开Excel准备写VBA时,你是否也经历过这样的场景?明明上周才用过的循环语句,今天却要重新翻文档;好不容易找到的数据库连接代码,却因为版本不同需要…...

Windows事件日志分析新思路:不用记Event ID,用PowerShell和Log Parser自动化生成安全周报
Windows安全日志自动化分析:告别手工整理,用PowerShell打造智能周报系统 每次月底赶安全报告时,IT管理员最头疼的莫过于要反复筛选事件日志、统计各类安全事件的发生次数。传统方法需要记住大量Event ID,手动导出数据再整理成表格…...

Ubuntu 20.04 装 ROS Noetic,我为什么建议你跳过 rosdep 这一步?
Ubuntu 20.04 安装 ROS Noetic:为什么你可以安全跳过 rosdep 初始化? 在机器人操作系统(ROS)的安装文档中,rosdep init 和 rosdep update 这两个步骤总是被列为必选项。但作为一个在三个不同国家的机器人实验室工作过的…...

单智能体 vs 多智能体:架构选型指南,90% 的效率提升不等于 17 倍的错误放大!
本文深入探讨了单智能体和多智能体架构的优劣,指出正确的架构选择应基于任务结构而非技术野心。单智能体适合紧密耦合工作,而多智能体在可并行化任务中效率高,但错误放大风险大。行业领导者 Anthropic、OpenAI 等建议从单智能体开始ÿ…...

2026年4月21日60秒读懂世界:阅读与手机时间、汽车价格战、脑机接口临床提速,今天最值得关注的6个信号
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

Phi-3.5-mini-instruct部署教程:vLLM服务容器化+Prometheus指标暴露配置
Phi-3.5-mini-instruct部署教程:vLLM服务容器化Prometheus指标暴露配置 1. 模型简介 Phi-3.5-mini-instruct 是一个轻量级的开放模型,属于Phi-3模型家族。它基于高质量的数据集构建,特别关注推理密集型任务。该模型支持128K令牌的上下文长度…...