MySQL DQL 数据查询
文章目录
- 1.SELECT 语句
- 2.SELECT 子句
- 3.FROM 子句
- 4.WHERE 子句
- 5.GROUP BY 子句
- 6.HAVING 子句
- 7.ORDER BY 子句
- 8.LIMIT 子句
- 9.DISTINCT 子句
- 10.JOIN 子句
- 11.UNION 子句
- 12.查看数据表记录数
- 13.检查查询语句的执行效率
- 14.查看 SQL 执行时的警告
- 参考文献
1.SELECT 语句
MySQL 的 SELECT 语句用于从数据库表中检索数据。功能强大,语句结构复杂多样。不过基本的语句格式像下面这个样子。
SELECT [列名称] FROM [表名称] where [条件]
一个完整的 SELECT 语句包含一些可选的子句。SELECT 语句定义如下:
<SELECT clause>
[FROM clause]
[WHERE clause]
[GROUP BY clause]
[HAVING clause]
[ORDER BY clause]
[LIMIT clause]
- SELECT 子句是必选的,其它子句是可选的。
一个 SELECT 可以在不引用任何表的情况下进行计算,也就是没有其他任何字句,只有 SELECT 子句。
SELECT 1 + 1 AS sum;
+-----+
| sum |
+-----+
| 2 |
+-----+
- 一个 SELECT 语句中,子句的顺序是固定的。如 GROUP BY 子句不会位于 WHERE 子句前面。
- SELECT 语句不同子句的执行顺序:
开始 > FROM子句 > WHERE子句 > GROUP BY子句 > HAVING子句 > SELECT子句 > ORDER BY子句 > LIMIT子句 > 最终结果
每个子句执行后都会产生一个中间数据结果,即所谓的临时视图,供接下来的子句使用,如果不存在某个子句则跳过。
需要注意的是,不同的数据库管理系统可能会有一些差异,但一般情况下,上述顺序适用于大多数SQL查询。
MySQL 和标准 SQL 执行顺序基本是一样的。
2.SELECT 子句
SELECT 子句用于指定要选择的列或使用表达式生成新的值。
对于所选数据,还可以添加一些修饰,比如使用 DISTINCT 关键字用于去重。
一个完整的 SELECT 子句组成如下。
SELECT[ALL | DISTINCT | DISTINCTROW ][HIGH_PRIORITY][STRAIGHT_JOIN][SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT][SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]select_expr [, select_expr] ...[into_option]into_option: {INTO OUTFILE 'file_name'[CHARACTER SET charset_name]export_options| INTO DUMPFILE 'file_name'| INTO var_name [, var_name] ...
}
其中 select_expr 是必选的,表示要查询的列、表达式或使用 * 表示所有列。
SELECT * FROM t1 INNER JOIN t2 ...
可以对列使用函数进行运算,并使用 AS 关键字对结果列命名(AS 是可选的,可以省略)。
SELECT AVG(score) AS avg_score, t1.* FROM t1 ...# 或
SELECT AVG(score) avg_score, t1.* FROM t1 ...
3.FROM 子句
FROM 子句指示要从中检索行的表。如果为多个表命名,则执行连接。对于指定的每个表,您可以选择指定一个别名。
FROM table_references [PARTITION partition_list]
SELECT 支持显式分区选择,使用 PARTITION 子句,在 table_references 表的名称后面跟着一个分区或子分区列表(或两者都有)在这种情况下,只从列出的分区中选择行,而忽略表的任何其他分区。关于分区可参考 Chapter 24 Partitioning。
4.WHERE 子句
如果给定 WHERE 子句,则指示行必须满足的一个或多个条件才能被选中。where_condition 是一个表达式,对于要选择的每一行,其计算结果为 true 才会被选择。如果没有 WHERE 子句,将选择所有行。
[WHERE where_condition]
下面的运算符可在 WHERE 子句的条件表达式中使用。
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| != 或 <> | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN AND | 在某个范围内 |
| LIKE | 搜索某种模式 |
| AND | 多个条件与 |
| OR | 多个条件或 |
(1)WHERE IN 的用法
IN 在 WHERE 子句中的用法主要有两种:
- IN 后面是子查询产生的记录集,注意,子查询结果数据列只能有一列且无需给子查询的结果集添加别名。
SELECT * FROM tbl_name1 WHERE col_name1 IN (SELECT col_name2 FROM tbl_name2);
- IN 后面是数据集合。
SELECT * FROM tbl_name WHERE col_name IN ('foo', 'bar', 'baz', 'qux');
注意:如果数据类型是字符串,一定要将字符串用单引号引起来。
5.GROUP BY 子句
GROUP BY 子句中的数据列应该是 SELECT 指定的数据列中的所有列,除非这列是用于聚合函数,如 SUM()、AVG()、COUNT()等。
但是,如果 SELECT 指定的数据列,没有用于聚合函数也不在 GROUP BY 子句中,按理说会报错,但是 MySQL 会选择第一条显示在结果集中。
# 选择发起加好友请求次数超过10次的QQ(uin),被加方(to_uin)只会显示第一个
SELECT uin, to_uin, count(*) AS cnt from inner_raw_add_friend_20170514 GROUP BY uin HAVING cnt>10;
6.HAVING 子句
HAVING 和 WHERE 子句一样,用于指定选择条件。
但 HAVING 和 WHERE 子句的用法上却有明显的区别。
- 作用的对象不同。WHERE 子句作用于表和视图,HAVING 子句作用于组。
# 选取 QQ 3585076592 和 3585075773 在 20170514 当天发出加好友请求次数且满足次数>10
SELECT uin,count(*) AS cnt FROM inner_raw_add_friend_20170514 where uin=3585076592 or uin=3585075773 GROUP BY uin HAVING cnt>10;
- 作用的阶段不同。
WHERE 在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算),而 HAVING 在分组和聚集之后选取分组。因此,WHERE 子句不能包含聚集函数,因为试图用聚集函数判断哪些行输入给聚集运算是没有意义的。 相反,HAVING 子句一般包含聚集函数。当然,也可以使用 HAVING 对结果集进行筛选,但不建议这样做,同样的条件可以更有效地用于 WHERE 阶段。
# 查询指定 QQ 加好友请求信息(where作用于输入阶段的数据集)
SELECT * FROM inner_raw_add_friend_20170514 WHERE uin=3585078528;# 作用等同于 WHERE, 但 HAVING 作用于结果阶段的结果集
SELECT * FROM inner_raw_add_friend_20170514 HAVING uin=3585078528;
7.ORDER BY 子句
ORDER BY 子句用于根据指定的列对结果集进行排序。
[ORDER BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]]
ORDER BY 语句默认按照升序 ASC(ascend)对记录进行排序。如果希望按照降序排序,可以使用 DESC(descend)关键字,随机使用随机数函数RAND()。
在指定待排序的列时,不建议使用列位置(从1开始),因为该语法已从SQL标准中删除。
比如以 QQ 号码降序排序。
SELECT * FROM inner_raw_add_friend_20170514 ORDER BY uin DESC;
8.LIMIT 子句
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
LIMIT 接受一个或两个数值参数。参数必须是一个整数常量。如果给定两个参数,有两种用法。
offset,row_count
# 或
row_count OFFSET offset
offset 为返回记录行的开始偏移量,从 0 开始,row_count 为返回记录行的最大数目。
只给一个参数,表示返回记录行的 Top 最大行数,起始偏移量默认为 0。
返回从起始偏移量开始,返回剩余所有的记录,可以使用一些值很大的第二个参数。如检索所有从第 96 行到最后一行。
SELECT * FROM tbl LIMIT 95,18446744073709551615;
注意,MySQL目前不支持使用 -1 表示返回从偏移量开始剩余的所有记录,即下面的写法是错误的:
SELECT * FROM tbl LIMIT 95,-1
9.DISTINCT 子句
DISTINCT 关键字用于查询结果中去除重复的行,只返回唯一的行。
(1)利用 DISTINCT 结合 COUNT() 函数可以统计不重复记录的数量。
# 选择每一个 QQ 发起加好友请求涉及到的不同的 QQ 数
SELECT uin, count(distinct to_uin) c FROM add_friend GROUP BY uin;
(2)DISTINCT 用于选择不同的记录,且只能放在所选列的开头,作用于紧随其后的所有列。
# 查询 uin 和 to_uin 不重复的加好友请求
SELECT DISTINCT uin, to_uin FROM add_friend;# 示例数据表
uin to_uin
10000 123456
10000 121212
10001 121212
10001 131313# 结果集
uin to_uin
10000 123456
10000 121212
10001 121212
10001 131313
如果想使 DISTINCT 的功能作用于第二列的 to_uin,使用 DISTINCT 是无望了,因为 MySQL 语法尚不支持,可以使用 GROUP BY 取而代之。
SELECT uin, to_uin FROM add_friend WHERE GROUP BY to_uin;# 结果集
uin to_uin
10000 123456
10000 121212
10001 131313
这个奇怪的技巧只能存在于 MySQL 中,因为标准的 SQL 语法规定非聚合函数中的列一定要存在于 GROUP BY 子句中。MySQL 规定,当非聚合函数中的列不存在于 GROUP BY 子句中,则选择每个分组的第一行。
(3)COUNT DISTINCT 统计符合条件的记录数量。
如果像对符合条件的记录进行 COUNT DISTINCT,那么如何添加条件呢?
参见 MySQL distinct count if conditions unique,可以使用下面的方法。
COUNT(DISTINCT CASE WHERE 条件 THEN 字段 END)
参见 mysql count if distinct,也可以使用下面这种方法。
COUNT(DISTINCT col_name1, IF(col_name2=1, true, null))
10.JOIN 子句
MySQL 支持 SELECT 语句以及多表 DELETE 和 UPDATE 语句中使用 JOIN。
MySQL 支持三种 JOIN。
- 内连接 INNER JOIN,INNER 可省略。
内连接返回两个表中满足连接条件的记录。
SELECT columns
FROM table1
INNER JOIN table2 ON table1.column = table2.column;
- 左连接 LEFT JOIN。
左连接返回左表中所有记录,以及与右表中满足连接条件的记录。如果右表中没有匹配的记录,对应位置将显示 NULL。
SELECT columns
FROM table1
LEFT JOIN table2 ON table1.column = table2.column;
- 右连接 RIGHT JOIN。
右连接与左连接类似,但是返回右表中所有记录,以及与左表中满足连接条件的记录。如果左表中没有匹配的记录,对应位置将显示 NULL。
SELECT columns
FROM table1
RIGHT JOIN table2 ON table1.column = table2.column;
关于 JOIN 一些问题需要注意一下。
- 多表查询与 INNER JOIN 的区别。
实际测试一下可以看出区别,以 a 和 b 表为例。
SELECT * FROM a;
+------+------+
| id | col |
+------+------+
| 1 | 11 |
| 2 | 12 |
+------+------+SELECT * FROM b;
+------+------+
| id | col |
+------+------+
| 2 | 22 |
| 3 | 23 |
+------+------+SELECT * FROM a,b;
+------+------+------+------+
| id | col | id | col |
+------+------+------+------+
| 1 | 11 | 2 | 22 |
| 2 | 12 | 2 | 22 |
| 1 | 11 | 3 | 23 |
| 2 | 12 | 3 | 23 |
+------+------+------+------+SELECT* FROM a JOIN b ON a.id=b.id;
+------+------+------+------+
| id | col | id | col |
+------+------+------+------+
| 2 | 12 | 2 | 22 |
+------+------+------+------+
从结果可以看出,SELECT FROM 两个表的结果是两张表记录的笛卡尔乘积,INNER JOIN 则只连接含有相同字段的记录。
如果多表查询时,指定与 ON 相同的条件,则查询结果一致,二者没有任何区别。
SELECT * FROM a,b WHERE a.id=b.id;
+------+------+------+------+
| id | col | id | col |
+------+------+------+------+
| 2 | 12 | 2 | 22 |
+------+------+------+------+
在性能上,使用 EXPLAIN SQL 查看查询情况,二者也是一样的。也就说多表查询与 INNER JOIN 并无区别,只是写法上不同而已。
(2)关于 CROSS JOIN。
实际上,在 MySQL 中(仅限于 MySQL) CROSS JOIN 与 INNER JOIN 的表现是一样的,在不指定 ON 条件得到的结果都是笛卡尔积,反之取得两个表各自匹配的结果。
(3)关于 OUTER JOIN。
外连接就是求两个集合的并集。从笛卡尔积的角度讲就是从笛卡尔积中挑出ON子句条件成立的记录,然后加上左表中剩余的记录,最后加上右表中剩余的记录。
MySQ L不支持 OUTER JOIN,但是我们可以对左连接和右连接的结果做 UNION 操作来实现。
11.UNION 子句
UNION 的作用是将两次或多次查询结果纵向合并起来。
query_expression_body UNION [ALL | DISTINCT] query_block[UNION [ALL | DISTINCT] query_expression_body][...]
下面是一个示例。
mysql> SELECT 1, 2;
+---+---+
| 1 | 2 |
+---+---+
| 1 | 2 |
+---+---+
mysql> SELECT 'a', 'b';
+---+---+
| a | b |
+---+---+
| a | b |
+---+---+
mysql> SELECT 1, 2 UNION SELECT 'a', 'b';
+---+---+
| 1 | 2 |
+---+---+
| 1 | 2 |
| a | b |
+---+---+
使用 UNION 需要注意以下几点。
(1)UNION 的使用条件
UNION 只能作用于结果集,不能直接作用于原表。结果集的列数相同就可以,即使字段类型不相同也可以使用。值得注意的是 UNION 后字段的名称以第一条 SQL 为准。
(2)UNION 与 UNION ALL 的区别
UNION 用于合并两个或多个 SELECT 语句的结果集,并消去合并后的重复行。UNION ALL 则保留重复行。
(3)关于 UNION 的排序
有两张表,内容如下:
# table1
uin nickname
10001 monkey
10002 monkey king# table2
uin nickname
20000 cat
20001 dog
对两个结果集按照 uin 进行降序排序后再联合。
(SELECT * FROM table1 ORDER BY uin DESC) UNION (SELECT * FROM table2 ORDER BY uin DESC);uin nickname
10001 monkey
10002 monkey king
20000 cat
20001 dog
可以发现,内层排序没有发生作用,那现在试试在外层排序。
SELECT * FROM table1 UNION SELECT * FROM table2 ORDER BY uin DESC;uin nickname
20001 dog
20000 cat
10002 monkey king
10001 monkey
可见外层排序发生了作用。那是不是内层排序就没有用了呢,其实换个角度想想内层先排序,如果外层又排序,明显内层排序显得多余,所以 MySQL 优化了 SQL 语句,不让内层排序起作用。要想内层排序起作用,必须要使内层排序的结果能影响最终的结果,如加上 LIMIT。
(SELECT * FROM table1 ORDER BY uin DESC LIMIT 2) UNION (SELECT * FROM table2 ORDER BY uin DESC LIMIT 2);uin nickname
10002 monkey king
10001 monkey
20001 dog
20000 cat
此外,UNION 与 JOIN 在使用时,有一个本质区别我们必须知道。
UNION 只能作用于 SELECT 结果集,不能直接作用于数据表,而 JOIN 则恰恰相反,只作用于数据表,不能直接作用于 SELECT 结果集(可以将 SELECT 结果集指定别名作为派生表)。
12.查看数据表记录数
查看数据表行数有多种方法。
- 使用 COUNT(*)
SELECT COUNT(*) FROM tbl_name;
对于 MyISAM 数据表很快,建议使用,因为 MyISAM 数据表事先将行数缓存起来,可直接获取。InnoDB 数据表不建议使用,当数据表行数过大时,因需要扫描全表,查询较慢。
- 查看 information_schema.tables 视图
SELECT table_rows FROM information_schema.tables WHERE TABLE_SCHEMA = 'DatabaseName' and table_name='TableName';
information_schema 是 MySQL 中的一个系统数据库,它包含了关于数据库、表、列等元数据信息。可以通过查询 information_schema.tables 视图获取指定数据表的记录数。
- 使用 SHOW TABLE STATUS 命令
SHOW TABLE STATUS LIKE 'table_name';
需要注意的是,SHOW TABLE STATUS 命令返回的行数是一个近似值,并不是实时的准确值。这是因为 MySQL 在某些情况下会对行数进行估算,而不是实时计算。如果需要准确的行数,建议使用 COUNT(*) 函数或查询 information_schema.tables 视图。
13.检查查询语句的执行效率
EXPLAIN 是一个用于查询优化的工具,它可以提供有关 SELECT 查询的执行计划的详细信息。通过使用 EXPLAIN 命令,可以了解 MySQL 是如何执行查询的,包括使用的索引、连接类型、扫描的行数等。
{EXPLAIN | DESCRIBE | DESC} select_statement;
EXPLAIN 命令的输出结果包含以下列:
id:查询的标识符,用于标识查询中的每个步骤。
select_type:查询的类型,如 SIMPLE(简单查询)、PRIMARY(主查询)、SUBQUERY(子查询)等。
table:查询涉及的表。
partitions:查询涉及的分区。
type:访问表的方式,如 ALL(全表扫描)、INDEX(使用索引扫描)、RANGE(范围扫描)等。
possible_keys:可能使用的索引。
key:实际使用的索引。
key_len:使用的索引的长度。
ref:与索引比较的列或常量。
rows:扫描的行数。
filtered:过滤的行百分比。
Extra:额外的信息,如使用了临时表、使用了文件排序等。
14.查看 SQL 执行时的警告
SHOW WARNINGS 是一个用于查看最近一次执行的语句产生的警告信息的命令。在 MySQL 中,警告(Warning)是一种表示潜在问题或异常情况的消息,它不会导致语句的执行失败,但可能会影响到查询结果或性能。
SHOW WARNINGS;
SHOW WARNINGS 命令的输出结果包含以下列:
Level:警告的级别,如 Warning、Note 等。
Code:警告的代码。
Message:警告的具体消息。
通过查看警告信息,可以了解到语句执行过程中可能存在的问题或异常情况,如截断数据、丢失数据等。根据警告信息,可以进行相应的调整和处理,以确保查询的正确性和性能。
参考文献
MySQL 8.0 Reference Manual :: 13.2.13 SELECT Statement
MySQL 8.0 Reference Manual :: 13.2.18 UNION Clause
MySQL 8.0 Reference Manual :: 13.2.13.2 JOIN Clause
MySQL 8.0 Reference Manual :: 13.8.2 EXPLAIN Statement
8.8.1 Optimizing Queries with EXPLAIN
相关文章:

MySQL DQL 数据查询
文章目录 1.SELECT 语句2.SELECT 子句3.FROM 子句4.WHERE 子句5.GROUP BY 子句6.HAVING 子句7.ORDER BY 子句8.LIMIT 子句9.DISTINCT 子句10.JOIN 子句11.UNION 子句12.查看数据表记录数13.检查查询语句的执行效率14.查看 SQL 执行时的警告参考文献 1.SELECT 语句 MySQL 的 SE…...
深度学习基础知识笔记
深度学习要解决的问题 1 深度学习要解决的问题2 应用领域3 计算机视觉任务4 视觉任务中遇到的问题5 得分函数6 损失函数7 前向传播整体流程8 返向传播计算方法1 梯度下降 9 神经网络整体架构11 神经元个数对结果的影响12 正则化和激活函数1 正则化2 激活函数 13 神经网络过拟合…...

怎么系统的学习机器学习、深度学习?当然是看书了
目录 前言 内容简介 学完本书,你将能够 作者简介 本书目录 京东自购链接 前言 近年来,机器学习方法凭借其理解海量数据和自主决策的能力,已在医疗保健、 机器人、生物学、物理学、大众消费和互联网服务等行业得到了广泛的应用。自从Ale…...

无涯教程-Perl - binmode函数
描述 此函数设置在区分两者的操作系统上以二进制形式读取和写入FILEHANDLE的格式。非二进制文件的CR LF序列在输入时转换为LF,在LF时在输出时转换为CR LF。这对于使用两个字符分隔文本文件中的行的操作系统(MS-DOS)至关重要,但对使用单个字符的操作系统(Unix,Mac OS,QNX)没有影…...

Spring Boot Maven package时显式的跳过test内容
在pom.xml的编译插件部分显式的增加一段内容: <plugin> <!-- maven打包时,显式的跳过test部分 --><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>3.…...

排序算法————基数排序(RadixSort)
基数排序的概念: 什么是基数排序???基数排序是一种和快排、归并、希尔等等不一样的排序...它不需要比较和移动就可以完成整型的排序。它是时间复杂度是O(K*N),空间复杂度是O(KM&…...

leetcode做题笔记75颜色分类
给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sort 函数的情况下解决…...

聊一下互联网开源变现
(点击即可收听) 互联网开源变现其实是指通过开源软件或者开放源代码的方式,实现收益或盈利。这种方式越来越被广泛应用于互联网行业 在互联网开源变现的模式中,最常见的方式是通过捐款、广告、付费支持或者授权等方式获利。 例如,有些开源软件…...

PHP日期差计算器,计算两个时间相差 年/月/日
1. 计算两个日期相隔多少年,多少月,多少天示例:laravel框架实现 /*** 天数计算* return \Illuminate\Http\JsonResponse*/public function loveDateCal(){$start_date $this->request(start_date);$end_date $this->request(end_date…...
20230812在WIN10下使用python3将SRT格式的字幕转换为SSA格式
20230812在WIN10下使用python3将SRT格式的字幕转换为SSA格式 2023/8/12 20:58 本文的SSA格式以【Batch Subtitles Converter(批量字幕转换) v1.23】的格式为准! 1、 缘起:网上找到的各种各样的字幕转换软件/小工具都不是让自己完全满意! 【都…...
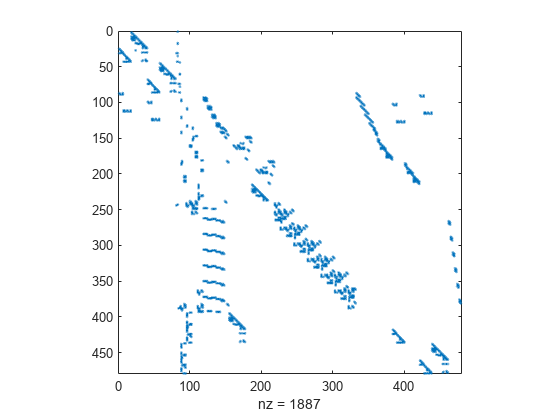
matlab使用教程(13)—稀疏矩阵创建和使用
使用稀疏矩阵存储包含众多零值元素的数据,可以节省大量内存并加快该数据的处理速度。sparse 是一种属性,可以将该属性分配给由 double 或 logical 元素组成的任何二维 MATLAB 矩阵。通过 sparse 属性,MATLAB 可以: • 仅存储矩…...

UI美工设计的主要职责(合集)
UI美工设计的主要职责1 职责: 1、执行公司的规章制度及专业管理办法; 2、 负责重点项目的原型设计和产品流程设计、视觉设计,优化网站和移动端的设计流程和规范,制定产品 UI/UE规范及文档编写; 3、负责使用PS、AI、illustrator、MarkMan、…...
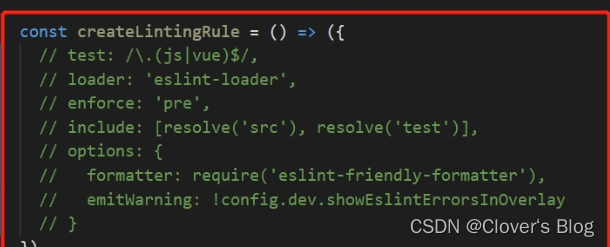
【前端二次开发框架关于关闭eslint】
前端二次开发框架关于关闭eslint 方法一方法二方法三方法四:以下是若想要关闭项目中的部分代码时: 方法一 在vue.config.js里面进行配置: module.exports {lintOnSave:false,//是否开启eslint保存检测 ,它的有效值为 true || false || err…...

Scractch3.0_Arduino_ESP32_学习随记_蓝牙键盘(三)
C02蓝牙键盘 目的器材程序联系我们 目的 通过C02实现蓝牙键盘 器材 硬件: 齐护机器人C02 购买地址 软件: scratch3.0 下载地址:官网下载 程序 在P5口连接按钮模块。 蓝牙键盘组合按键动作的实现。 当对应按键按下时模拟键盘动作,先按下ctrl然后按下对应组合键…...

Spark2.2出现异常:ERROR SparkUI: Failed to bind SparkUI
详细错误信息如下: 复制代码 19/03/19 11:04:18 INFO util.log: Logging initialized 5402ms 19/03/19 11:04:18 INFO server.Server: jetty-9.3.z-SNAPSHOT 19/03/19 11:04:18 INFO server.Server: Started 5604ms 19/03/19 11:04:18 WARN util.Utils: Service ‘S…...

LeetCode 2811. Check if it is Possible to Split Array【脑筋急转弯;前缀和+动态规划或记忆化DFS】中等
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

【学习日记】【FreeRTOS】链表结构体及函数详解
写在前面 本文主要是对于 FreeRTOS 中链表相关内容的详细解释,代码大部分参考了野火FreeRTOS教程配套源码,作了一小部分修改。 一、结构体定义 主要包含三种结构体: 普通节点结构体结尾节点(mini节点)结构体链表结…...
【云原生•监控】基于Prometheus实现自定义指标弹性伸缩(HPA)
【云原生•监控】基于Prometheus实现自定义指标弹性伸缩(HPA) 什么是弹性伸缩 「Autoscaling即弹性伸缩,是Kubernetes中的一种非常核心的功能,它可以根据给定的指标(例如 CPU 或内存)自动缩放Pod副本,从而可以更好地管…...

Windows、 Linux 等操作系统的基本概念及其常见操作
Windows 和 Linux 是两种常见的操作系统,它们在计算机领域中广泛使用。下面我将为您介绍它们的基本概念以及一些常见的操作。 **Windows 操作系统:** 1. **基本概念:** Windows 是由微软公司开发的操作系统系列,旨在为个人计算机…...
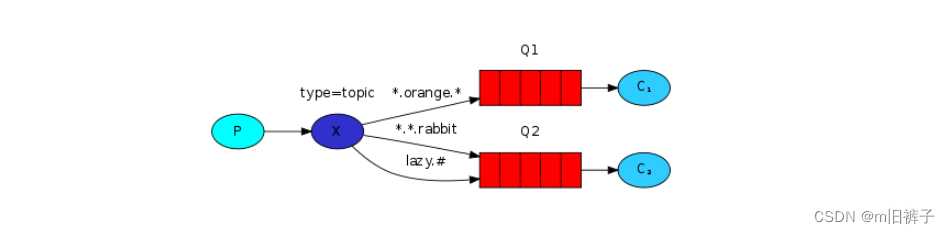
【RabbitMQ】golang客户端教程5——使用topic交换器
topic交换器(主题交换器) 发送到topic交换器的消息不能具有随意的routing_key——它必须是单词列表,以点分隔。这些词可以是任何东西,但通常它们指定与消息相关的某些功能。一些有效的routing_key示例:“stock.usd.ny…...
)
保姆级避坑指南:在Ubuntu 20.04上从源码编译ORB-SLAM3(含Pangolin、OpenCV版本冲突解决)
保姆级避坑指南:在Ubuntu 20.04上从源码编译ORB-SLAM3(含Pangolin、OpenCV版本冲突解决) 视觉SLAM领域的研究者和开发者们,想必对ORB-SLAM3这个开源的视觉惯性SLAM系统都不陌生。作为ORB-SLAM系列的第三代产品,它在精度…...

KMS_VL_ALL_AIO:Windows系统与Office套件的一站式智能激活解决方案
KMS_VL_ALL_AIO:Windows系统与Office套件的一站式智能激活解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 在Windows系统管理与软件部署领域,激活问题始终是技术…...

**基于Python的情绪识别实战:从数据预处理到模型部署全流程详解*
基于Python的情绪识别实战:从数据预处理到模型部署全流程详解 在人工智能快速发展的今天,情绪识别(Emotion Recognition) 已成为人机交互、智能客服、心理健康监测等场景的核心技术之一。本文将围绕 Python编程语言,深…...

DS4Windows终极指南:让PS手柄在PC上完美运行的5个秘密技巧
DS4Windows终极指南:让PS手柄在PC上完美运行的5个秘密技巧 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否曾经想过,为什么PS4/PS5手柄在PC上总是"水土…...

【NUMA调度】深入解析NUMA架构下的负载均衡策略与性能调优
1. NUMA架构基础:从对称多处理到非一致性内存访问 第一次接触NUMA架构是在2015年调试一台八路服务器时。当时发现一个奇怪现象:同样的程序在不同CPU核心上运行时,性能差异能达到30%以上。这就是NUMA架构带来的典型特征——非均匀内存访问&…...

Zotero插件市场:一站式插件管理解决方案,让学术研究更高效
Zotero插件市场:一站式插件管理解决方案,让学术研究更高效 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zoter…...

ComfyUI-Manager在MacOS上的完整部署实战手册:从零到专业级管理
ComfyUI-Manager在MacOS上的完整部署实战手册:从零到专业级管理 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...
)
【Docker 27 AI容器调度终极指南】:20年SRE亲授GPU/内存/拓扑感知配置黄金参数(含实测QPS提升3.7倍数据)
第一章:Docker 27 AI容器调度演进与核心变革Docker 27 引入了面向AI工作负载的原生调度增强机制,标志着容器运行时从通用编排向智能感知型调度的关键跃迁。其核心变革在于将传统基于CPU/内存阈值的静态资源分配,升级为融合GPU显存占用率、CUD…...
)
EF Core 10向量扩展生产就绪 checklist(含A/B测试分流、向量维度漂移监控、fallback降级开关)
第一章:EF Core 10向量扩展生产就绪全景概览EF Core 10 向量扩展(Vector Extensions)并非官方内置功能,而是由社区驱动、经微软认可的高性能向量计算增强方案,专为 AI 原生应用与嵌入式相似性搜索场景设计。它深度集成…...
)
告别BurpSuite?手把手教你用Yakit社区版搞定Web渗透测试(附国密证书配置)
从BurpSuite迁移到Yakit:Web渗透测试新范式实战指南 如果你已经习惯了BurpSuite的工作流程,但正在寻找一个更轻量、更符合国内安全需求的替代方案,Yakit社区版可能正是你需要的工具。它不仅继承了BurpSuite的核心功能,还针对中国开…...