PyTorch翻译官网教程-NLP FROM SCRATCH: GENERATING NAMES WITH A CHARACTER-LEVEL RNN
官网链接
NLP From Scratch: Generating Names with a Character-Level RNN — PyTorch Tutorials 2.0.1+cu117 documentation
使用字符级RNN生成名字
这是我们关于“NLP From Scratch”的三篇教程中的第二篇。在第一个教程中</intermediate/char_rnn_classification_tutorial> 我们使用RNN将名字按其原始语言进行分类。这一次,我们将通过语言中生成名字。
> python sample.py Russian RUS
Rovakov
Uantov
Shavakov> python sample.py German GER
Gerren
Ereng
Rosher> python sample.py Spanish SPA
Salla
Parer
Allan> python sample.py Chinese CHI
Chan
Hang
Iun我们仍然手工制作一个带有几个线性层的小型RNN模型。最大的区别在于,我们不是在读取一个名字的所有字母后预测一个类别,而是输入一个类别并每次输出一个字母。经常预测字符以形成语言(这也可以用单词或其他高阶结构来完成)通常被称为“语言模型”。
推荐阅读:
我假设你至少安装了PyTorch,了解Python,并且理解张量:
- PyTorch 安装说明
- Deep Learning with PyTorch: A 60 Minute Blitz 来开始使用PyTorch
- Learning PyTorch with Examples pytorch使用概述
- PyTorch for Former Torch Users 如果您是前Lua Torch用户
了解rnn及其工作原理也很有用:
- The Unreasonable Effectiveness of Recurrent Neural Networks 展示了一些现实生活中的例子
- Understanding LSTM Networks 是专门关于LSTM的,但也有关于RNN的信息
我还推荐上一篇教程, NLP From Scratch: Classifying Names with a Character-Level RNN
准备数据
从这里(here)下载数据并将其解压缩到当前目录。
有关此过程的更多细节,请参阅最后一篇教程。简而言之,有一堆纯文本文件data/names/[Language].txt 每行有一个名称。我们将每行分割成一个数组,将Unicode转换为ASCII,最后得到一个字典{language: [names ...]}.
from io import open
import glob
import os
import unicodedata
import stringall_letters = string.ascii_letters + " .,;'-"
n_letters = len(all_letters) + 1 # Plus EOS markerdef findFiles(path): return glob.glob(path)# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn'and c in all_letters)# Read a file and split into lines
def readLines(filename):with open(filename, encoding='utf-8') as some_file:return [unicodeToAscii(line.strip()) for line in some_file]# Build the category_lines dictionary, a list of lines per category
category_lines = {}
all_categories = []
for filename in findFiles('data/names/*.txt'):category = os.path.splitext(os.path.basename(filename))[0]all_categories.append(category)lines = readLines(filename)category_lines[category] = linesn_categories = len(all_categories)if n_categories == 0:raise RuntimeError('Data not found. Make sure that you downloaded data ''from https://download.pytorch.org/tutorial/data.zip and extract it to ''the current directory.')print('# categories:', n_categories, all_categories)
print(unicodeToAscii("O'Néàl"))输出
# categories: 18 ['Arabic', 'Chinese', 'Czech', 'Dutch', 'English', 'French', 'German', 'Greek', 'Irish', 'Italian', 'Japanese', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Scottish', 'Spanish', 'Vietnamese']
O'Neal创建网络
这个网络扩展了上一篇教程的RNN(the last tutorial’s RNN),为类别张量增加了一个额外的参数,它与其他参数连接在一起。category张量是一个独热向量就像输入的字母一样。
我们将把输出解释为下一个字母出现的概率。采样时,最可能的输出字母被用作下一个输入字母。
我添加了第二个线性层o2o(在将hidden和output结合起来之后),让其更有影响力。还有一个dropout层,它以给定的概率(这里是0.1)随机地将部分输入归零,通常用于模糊输入以防止过拟合。在这里,我们在网络的末尾使用它来有意地增加一些混乱和增加采样的多样性。
import torch
import torch.nn as nnclass RNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(RNN, self).__init__()self.hidden_size = hidden_sizeself.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)self.o2o = nn.Linear(hidden_size + output_size, output_size)self.dropout = nn.Dropout(0.1)self.softmax = nn.LogSoftmax(dim=1)def forward(self, category, input, hidden):input_combined = torch.cat((category, input, hidden), 1)hidden = self.i2h(input_combined)output = self.i2o(input_combined)output_combined = torch.cat((hidden, output), 1)output = self.o2o(output_combined)output = self.dropout(output)output = self.softmax(output)return output, hiddendef initHidden(self):return torch.zeros(1, self.hidden_size)
训练
训练准备
首先,辅助函数获得(类别,行)的随机对:
import random# Random item from a list
def randomChoice(l):return l[random.randint(0, len(l) - 1)]# Get a random category and random line from that category
def randomTrainingPair():category = randomChoice(all_categories)line = randomChoice(category_lines[category])return category, line对于每个时间步(即对于训练词中的每个字母),网络的输入将是(category, current letter, hidden state),输出将是(next letter, next hidden state)。对于每个训练集,我们需要类别,一组输入字母,和一组输出/目标字母。
由于我们预测每个时间步当前字母的下一个字母,因此字母对是一行中连续字母的组-例如,"ABCD<EOS>" 我们将创建(“A”,“B”),(“B”,“C”),(“C”,“D”),(“D”,“EOS”)。
category张量是一个独热张量,大小为<1 x n_categories>. 当训练时,我们在每个时间步向网络提供它,这是一个设计选择,它可以作为初始隐藏状态的一部分或其他策略。
# One-hot vector for category
def categoryTensor(category):li = all_categories.index(category)tensor = torch.zeros(1, n_categories)tensor[0][li] = 1return tensor# One-hot matrix of first to last letters (not including EOS) for input
def inputTensor(line):tensor = torch.zeros(len(line), 1, n_letters)for li in range(len(line)):letter = line[li]tensor[li][0][all_letters.find(letter)] = 1return tensor# ``LongTensor`` of second letter to end (EOS) for target
def targetTensor(line):letter_indexes = [all_letters.find(line[li]) for li in range(1, len(line))]letter_indexes.append(n_letters - 1) # EOSreturn torch.LongTensor(letter_indexes)为了在训练过程中方便起见,我们将创建一个randomTrainingExample函数来获取一个随机的(category, line)对。并将它们转换为所需的(category, input, target)张量。
# Make category, input, and target tensors from a random category, line pair
def randomTrainingExample():category, line = randomTrainingPair()category_tensor = categoryTensor(category)input_line_tensor = inputTensor(line)target_line_tensor = targetTensor(line)return category_tensor, input_line_tensor, target_line_tensor训练网络
与只使用最后一个输出的分类相反,我们在每一步都进行预测,因此我们在每一步都计算损失。
自动梯度的魔力让你可以简单地将每一步的损失加起来,并在最后进行反向调用。
criterion = nn.NLLLoss()learning_rate = 0.0005def train(category_tensor, input_line_tensor, target_line_tensor):target_line_tensor.unsqueeze_(-1)hidden = rnn.initHidden()rnn.zero_grad()loss = torch.Tensor([0]) # you can also just simply use ``loss = 0``for i in range(input_line_tensor.size(0)):output, hidden = rnn(category_tensor, input_line_tensor[i], hidden)l = criterion(output, target_line_tensor[i])loss += lloss.backward()for p in rnn.parameters():p.data.add_(p.grad.data, alpha=-learning_rate)return output, loss.item() / input_line_tensor.size(0)为了跟踪训练需要多长时间,我添加了一个timeSince(timestamp)函数,它返回一个人类可读的字符串:
import time
import mathdef timeSince(since):now = time.time()s = now - sincem = math.floor(s / 60)s -= m * 60return '%dm %ds' % (m, s)训练和往常一样——调用train多次并等待几分钟,在每个print_every示例中打印当前时间和损失,并在all_losses中保存每个plot_every示例的平均损失,以便稍后绘制。
rnn = RNN(n_letters, 128, n_letters)n_iters = 100000
print_every = 5000
plot_every = 500
all_losses = []
total_loss = 0 # Reset every ``plot_every`` ``iters``start = time.time()for iter in range(1, n_iters + 1):output, loss = train(*randomTrainingExample())total_loss += lossif iter % print_every == 0:print('%s (%d %d%%) %.4f' % (timeSince(start), iter, iter / n_iters * 100, loss))if iter % plot_every == 0:all_losses.append(total_loss / plot_every)total_loss = 0输出
0m 37s (5000 5%) 3.1506
1m 15s (10000 10%) 2.5070
1m 55s (15000 15%) 3.3047
2m 33s (20000 20%) 2.4247
3m 12s (25000 25%) 2.6406
3m 50s (30000 30%) 2.0266
4m 29s (35000 35%) 2.6520
5m 6s (40000 40%) 2.4261
5m 45s (45000 45%) 2.2302
6m 24s (50000 50%) 1.6496
7m 2s (55000 55%) 2.7101
7m 41s (60000 60%) 2.5396
8m 19s (65000 65%) 2.5978
8m 57s (70000 70%) 1.6029
9m 35s (75000 75%) 0.9634
10m 13s (80000 80%) 3.0950
10m 52s (85000 85%) 2.0512
11m 30s (90000 90%) 2.5302
12m 8s (95000 95%) 3.2365
12m 47s (100000 100%) 1.7113绘制损失
绘制all_losses的历史损失图显示了网络的学习情况:
import matplotlib.pyplot as pltplt.figure()
plt.plot(all_losses)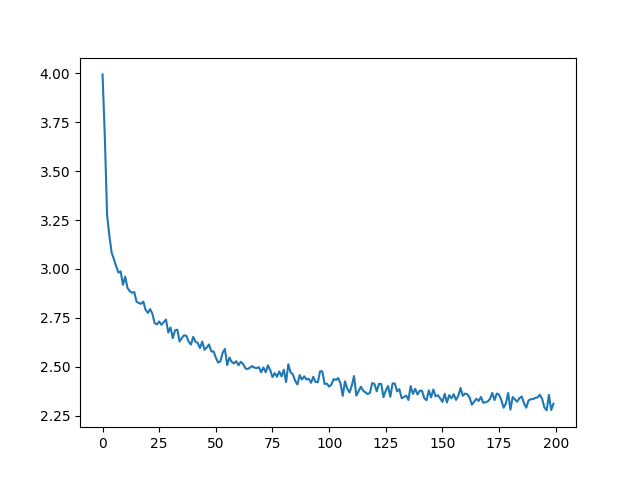
输出
[<matplotlib.lines.Line2D object at 0x7fa0159af880>]网络采样
为了进行示例,我们给网络一个字母并询问下一个字母是什么,将其作为下一个字母输入,并重复直到EOS令牌。
- 为输入类别、起始字母和空隐藏状态创建张量
- 创建一个以字母开头的字符串output_name
- 最大输出长度
-
- 将当前的字母提供给网络
- 从最高输出中获取下一个字母,以及下一个隐藏状态
- 如果字母是EOS,就停在这里
- 如果是普通字母,添加到output_name并继续
- 返回最终名称
与其给它一个起始字母,另一种策略是在训练中包含一个“字符串起始”标记,并让网络选择自己的起始字母。
max_length = 20# Sample from a category and starting letter
def sample(category, start_letter='A'):with torch.no_grad(): # no need to track history in samplingcategory_tensor = categoryTensor(category)input = inputTensor(start_letter)hidden = rnn.initHidden()output_name = start_letterfor i in range(max_length):output, hidden = rnn(category_tensor, input[0], hidden)topv, topi = output.topk(1)topi = topi[0][0]if topi == n_letters - 1:breakelse:letter = all_letters[topi]output_name += letterinput = inputTensor(letter)return output_name# Get multiple samples from one category and multiple starting letters
def samples(category, start_letters='ABC'):for start_letter in start_letters:print(sample(category, start_letter))samples('Russian', 'RUS')samples('German', 'GER')samples('Spanish', 'SPA')samples('Chinese', 'CHI')输出
Rovaki
Uarinovev
Shinan
Gerter
Eeren
Roune
Santera
Paneraz
Allan
Chin
Han
Ion练习
- 尝试使用不同数据集category -> line,例如,
-
- Fictional series -> Character name
- Part of speech -> Word
- Country -> City
- 使用“start of sentence”标记,这样就可以在不选择起始字母的情况下进行抽样
- 拥有一个更大的和/或更好的网络,可以获得更好的结果
-
- 尝试使用 nn.LSTM 和 nn.GRU 网络层
- 将这些RNN组合成一个更高级的网络
相关文章:
PyTorch翻译官网教程-NLP FROM SCRATCH: GENERATING NAMES WITH A CHARACTER-LEVEL RNN
官网链接 NLP From Scratch: Generating Names with a Character-Level RNN — PyTorch Tutorials 2.0.1cu117 documentation 使用字符级RNN生成名字 这是我们关于“NLP From Scratch”的三篇教程中的第二篇。在第一个教程中</intermediate/char_rnn_classification_tutor…...
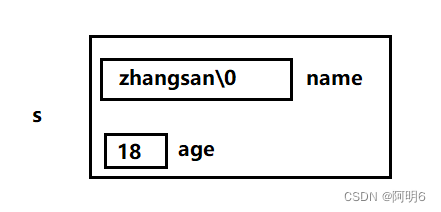
【C语言】结构体详解
现实生活中一个事物,会有许多属性连接起来。而C语言引入一种构造数据类型——结构体 将属于一个事物的多个数据组织起来以体现其内部联系。 一、结构体类型的定义 结构体类型 是一种 构造类型,它是由若干成员组成的,每个成员可以是一个基本…...

leetcode242. 有效的字母异位词
题目:leetcode242. 有效的字母异位词 描述: 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。 示例 1: 输入: s “…...

Unity 编辑器资源导入处理函数 OnPostprocessAudio :深入解析与实用案例
Unity 编辑器资源导入处理函数 OnPostprocessAudio 用法 点击封面跳转下载页面 简介 在Unity中,我们可以使用编辑器资源导入处理函数(OnPostprocessAudio)来自定义处理音频资源的导入过程。这个函数是继承自AssetPostprocessor类的ÿ…...
uniapp开发(由浅到深)
文章目录 1. 项目构建1.1 脚手架构建1.2 HBuilderX创建 uni-app项目步骤: 2 . 包依赖2.1 uView2.2 使用uni原生ui插件2.3 uni-modules2.4 vuex使用 3.跨平台兼容3.1 条件编译 4.API 使用4.1 正逆参数传递 5. 接口封装6. 多端打包3.1 微信小程序3.2 打包App3.2.1 自有…...

QT-基于Buildroot构建系统镜像下实现QT开发
QT-基于Buildroot构建系统镜像下实现QT开发 BuildRootUboot的仓库地址和commit idKernel 的仓库地址和commit id BuildRoot已编译库在Windows上的Create上创建项目编译QT项目 BuildRoot 这部分按照100ask官网的教程走即可: Uboot的仓库地址和commit id https://e.coding.net/…...

优雅地处理RabbitMQ中的消息丢失
目录 一、异常处理 二、消息重试机制 三、错误日志记录 四、死信队列 五、监控与告警 优雅地处理RabbitMQ中的消息丢失对于构建可靠的消息系统至关重要。下面将介绍一些优雅处理消息丢失的方案,包括异常处理、重试机制、错误日志记录、死信队列和监控告警等。…...

Vim入门教程vimtutor1.7总结
vimtutor命令可以打开教程文档 原文特别提示 ⬇⬇⬇ 特别提示:切记您要在使用中学习,而不是在记忆中学习 Vim模式 正常模式(Normal Mode):默认模式,可以使用基础命令进行操作命令模式(Command…...

Stephen Wolfram:让 ChatGPT 真正起作用的是什么?
What Really Lets ChatGPT Work? 让 ChatGPT 真正起作用的是什么? Human language—and the processes of thinking involved in generating it—have always seemed to represent a kind of pinnacle of complexity. And indeed it’s seemed somewhat remarkabl…...
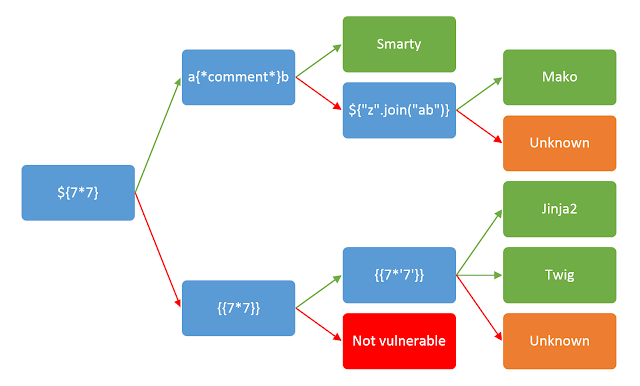
CTF-Flask-Jinja2(持续更新)
放心,我会一直陪着你 一.知识一.在终端的一些指令1.虚拟环境2.docker容器二.SSTI相关知识介绍1.魔术方法2.python如何执行cmd命令3.SSTI常用注入模块(1)文件读取(2)内建函数eval执行命令(3)os模块执行命令(4)importlib类执行命令(5)linecache函数执行命令(6)subproc…...
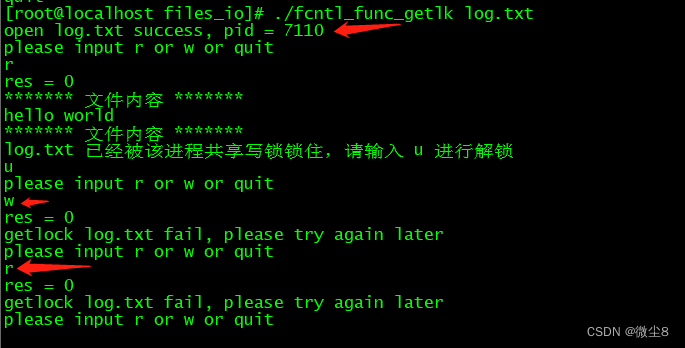
linux文件I/O之 fcntl() 函数用法:设置文件的 flags、设置文件锁(记录锁)
头文件和函数声明 #include <unistd.h> #include <fcntl.h> int fcntl(int fd, int cmd, ... /* arg */ ); 函数功能 获取、设置已打开文件的属性 返回值 成功时返回根据 cmd 传递的命令类型的执行结,失败时返回 -1,并设置 errno 为相…...
)
黑马项目一完结后阶段面试45题 JavaSE基础部分20题(一)
一、Java数据类型 基本数据类型——四类八种 整数型 byte short int long 浮点型 float double 字符型 char 布尔型 boolean 引用数据类型 String字符串 类(对象) 接口类型 数组类型 枚举类型 二、面向对象的三大特性 1.封装 把同一类事物…...
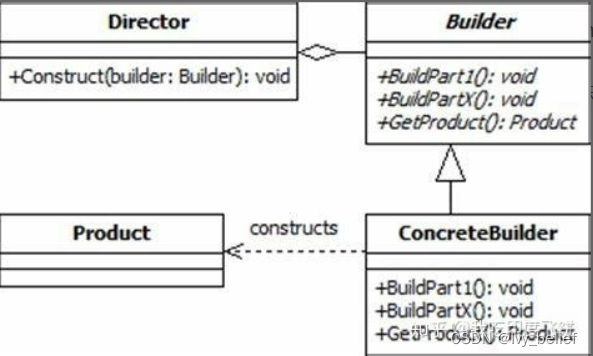
(一)创建型设计模式:3、建造者模式(Builder Pattern)
目录 1、建造者模式含义 2、建造者模式的讲解 3、使用C实现建造者模式的实例 4、建造者模式的优缺点 5、建造者模式VS工厂模式 1、建造者模式含义 The intent of the Builder design pattern is to separate the construction of a complex object from its representatio…...

指针进阶大冒险:解锁C语言中的奇妙世界!
目录 引言 第一阶段:🔍 独特的字符指针 什么是字符指针? 字符指针的用途 演示:使用字符指针拷贝字符串 字符指针与字符串常量 小试牛刀 第二阶段:🎯 玩转指针数组 指针数组是什么? 指针…...
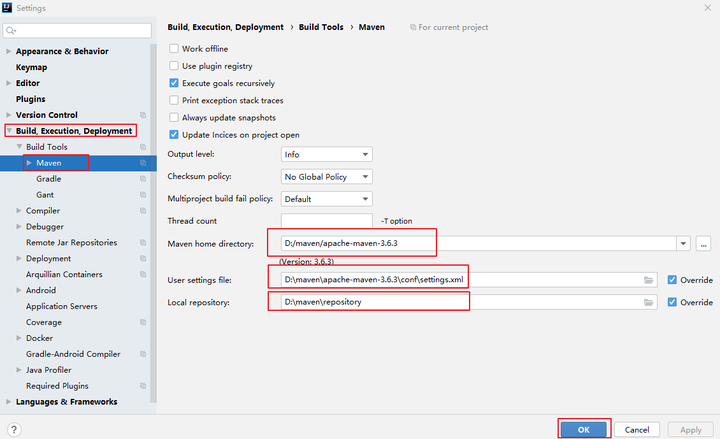
2.0 Maven基础
1. Maven概述 Maven概念 Apache Maven是一个软件项目管理工具,将项目开发和管理过程抽象程一个项目对象模型(POM,Project Object Model)。 Maven作用 项目构建 提供标准的、跨平台的自动化项目构建方式。 依赖管理 方便快捷…...
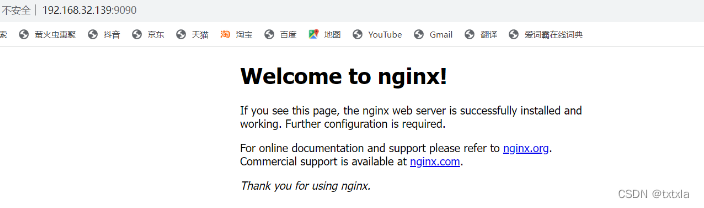
在Linux虚拟机内配置nginx以及docker
目录 1、nginx源码包编译以及安装依赖 1、配置安装所需的编译环境 2、安装函数库(pcre、zlib、openssl) 2、安装nginx 1、获取源码包 2、解压编译 3、启动nginx服务 1、关闭防火墙 2、运行nginx 3、使用本地浏览器进行验证 3、安装docker 1、…...

数据结构-带头双向循环链表的实现
前言 带头双向循环链表是一种重要的数据结构,它的结构是很完美的,它弥补了单链表的许多不足,让我们一起来了解一下它是如何实现的吧! 1.节点的结构 它的节点中存储着数据和两个指针,一个指针_prev用来记录前一个节点…...
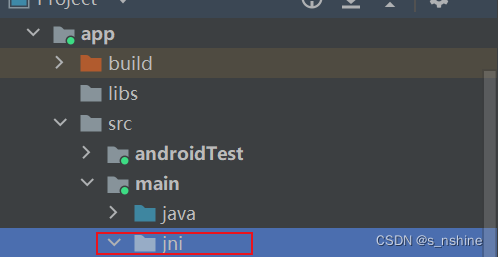
android Ndk Jni动态注册方式以及静态注册
目录 一.静态注册方式 二.动态注册方式 三.源代码 一.静态注册方式 1.项目名\app\src\main下新建一个jni目录 2.在jni目录下,再新建一个Android.mk文件 写入以下配置 LOCAL_PATH := $(call my-dir)//获取当前Android.mk所在目录 inclu...

MySQL中的索引
1.2.MySQL中的索引 InnoDB存储引擎支持以下几种常见的索引:B树索引、全文索引、哈希索引,其中比较关键的是B树索引 1.2.1.B树索引 InnoDB中的索引自然也是按照B树来组织的,前面我们说过B树的叶子节点用来放数据的,但是放什么数…...
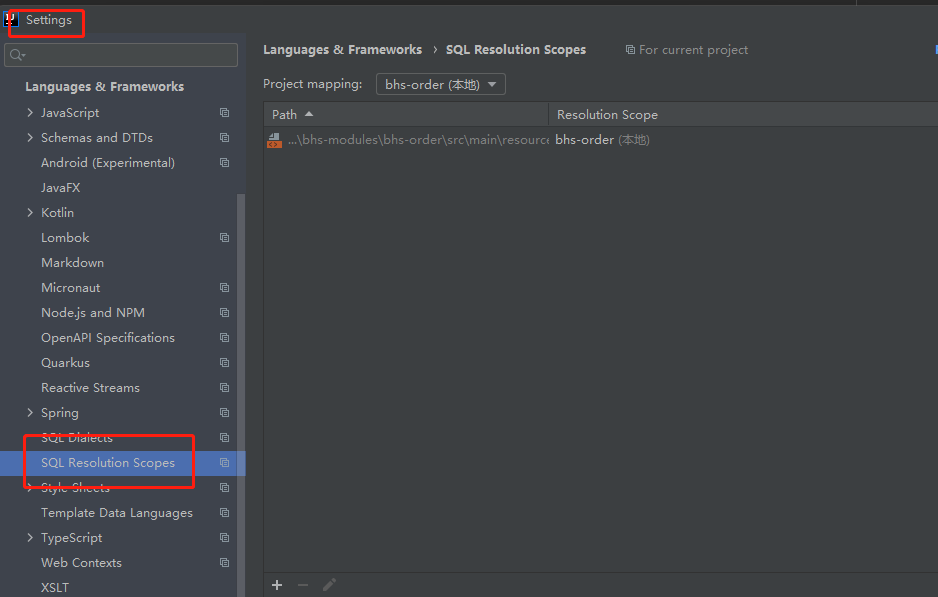
idea中如何处理飘红提示
idea中如何处理飘红提示 在写sql时,总是会提示各种错误 查找资料,大部分都是说关提示,这里把错误提示选择为None即可 关掉以后,也确实不显示任何提示了,但总有一种掩耳盗铃的感觉 这个sms表明明存在,但是还…...

终极指南:如何用EverythingToolbar实现Windows文件搜索效率翻倍 [特殊字符]
终极指南:如何用EverythingToolbar实现Windows文件搜索效率翻倍 🚀 【免费下载链接】EverythingToolbar Everything integration for the Windows taskbar. 项目地址: https://gitcode.com/gh_mirrors/eve/EverythingToolbar 你是否厌倦了在Windo…...
)
保姆级教程:用Arduino IDE 1.8.19给ESP32-CAM烧录CameraWebServer(附离线包下载)
ESP32-CAM零基础实战指南:从环境搭建到实时监控一气呵成 当拆开ESP32-CAM包装的瞬间,多数初学者会被这个火柴盒大小的智能摄像头模块震撼——它兼具Wi-Fi连接与图像处理能力,价格却不到百元。但紧接着就会陷入开发环境配置的泥潭:…...

5个专业技巧:掌握Inter字体家族打造完美数字界面体验
5个专业技巧:掌握Inter字体家族打造完美数字界面体验 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体家族是一款专为现代数字屏幕设计的无衬线字体系统,以其卓越的可读性、丰富的Ope…...

医学影像分割新宠UNet 3+:从论文到落地,我是如何用它提升肝脏分割Dice系数的
UNet 3在肝脏CT分割中的实战优化:从数据增强到模型轻量化的完整闭环 当我在三甲医院放射科第一次看到医生手动勾画肝脏肿瘤轮廓时,那个下午改变了我对医学影像分割的认知。主治医师需要花费40分钟在单张CT切片上精确标注病灶区域,而一个典型病…...

容器资源“黑盒”时代终结:Docker 27原生支持27项实时指标导出,立即启用这6个--metrics-xxx参数!
第一章:Docker 27资源监控增强的演进与意义Docker 27 引入了对容器运行时资源监控能力的系统性升级,核心聚焦于更细粒度、更低开销、更高实时性的指标采集与暴露机制。这一演进并非孤立功能叠加,而是围绕 cgroups v2 统一接口深度适配&#x…...

RoboMaster客户端UI绘制避坑指南:从串口协议到服务器调试,手把手教你显示第一条线
RoboMaster客户端UI绘制实战:从协议解析到动态调试的全链路指南 去年备赛期间,我们战队连续三天卡在UI显示问题上——明明协议封装正确,裁判系统指示灯正常,客户端却始终一片空白。直到凌晨三点才发现,原来是服务器端口…...

终极解决方案:在Windows 11上高效实现macOS风格的三指拖拽功能
终极解决方案:在Windows 11上高效实现macOS风格的三指拖拽功能 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/ThreeFinge…...
实战:从监控排错到消息积压处理一条龙)
RabbitMQ管理界面(rabbitmq_management)实战:从监控排错到消息积压处理一条龙
RabbitMQ管理界面深度实战:运维高手的监控排错手册 RabbitMQ的Web管理界面远不止是一个简单的监控工具——对于经验丰富的运维工程师而言,它是诊断消息队列问题的"手术刀"。当深夜收到"消息积压"告警时,如何快速定位是消…...

别再死记硬背!用华为/中兴网管实战拆解SDH复杂环网中的SNCP配置逻辑
华为/中兴SDH网管实战:复杂环网中SNCP配置的逻辑拆解与思维训练 在现网传输工程中,SDH环网拓扑的复杂性往往让工程师陷入配置命令的泥潭。当面对多个相交环、多节点业务调度时,盲目套用模板配置不仅效率低下,更可能在故障发生时导…...

Phi-3-mini-4k-instruct-gguf部署实操:解决vLLM启动失败、模型路径错误、端口被占三大问题
Phi-3-mini-4k-instruct-gguf部署实操:解决vLLM启动失败、模型路径错误、端口被占三大问题 1. 准备工作与环境检查 1.1 硬件与系统要求 在开始部署Phi-3-mini-4k-instruct-gguf模型前,请确保您的系统满足以下最低要求: 操作系统ÿ…...