生成式人工智能模型:提升营销分析用户体验
使用生成式人工智能来改善分析体验,使业务用户能够询问有关我们数据平台中可用数据的任何信息。
在本文中,我们将解释如何使用新的生成式人工智能模型 ( LLM ) 来改善业务用户在我们的分析平台上的体验。假设我们为零售销售经理提供 Web 应用程序或移动应用程序,他们可以使用自然语言实时分析销售和库存行为。
这些应用程序通常具有一系列限制,主要显示通用类型的分析,用户可以根据某些过滤器对其进行过滤或分段,并提供诸如以下的信息:
- 销售行为
- 通过...渠道贩卖
- 缺货
- 股票行为
所有这些数据,无论粒度大小,都可以回答某人之前确定的问题。问题在于,并非所有用户都有相同的问题,有时定制水平太高,以至于解决方案变成了一条大鲸鱼。大多数时候,信息是可用的,但没有时间将其包含在 Web 应用程序中。
过去几年,市场上出现了一些低代码解决方案,试图加快应用程序的开发速度,以尽可能快地响应此类用户的需求。所有这些平台都需要一些技术知识。LLM 模型使我们能够以自然语言与用户进行交互,并将他们的问题转化为代码并调用我们平台中的 API,从而能够以敏捷的方式向他们提供有价值的信息。
生成式人工智能营销平台用例
为了增强我们的销售平台,我们可以包括两个用例:
1. 迭代业务分析问题
允许业务用户通过以下功能询问有关我们数据平台中的数据的迭代问题:
- 能够用自然语言提问,可以是交互式的,但也必须允许用户保存他的个性化问题。
- 答案将基于更新的数据。
2. 讲故事
当您向业务用户提供有关销售共享的数据时,一个基本部分是讲故事。这可以增强理解并将数据转化为有价值的信息。如果我们能够让用户能够以自然语言获得这种解释,而不是用户必须解释指标,那就太好了。
实例:设计聊天营销
概述
这是一个实现起来非常简单的想法,并且为用户带来了很多商业价值,我们将训练我们的 LLM 模型,使其能够提出问题,以了解哪个数据服务提供信息。为此,我们的架构必须满足三个要求:
所有数据均通过API公开。
所有数据实体均已定义并记录。
我们有一个标准化的 API 层。
下图显示了该高级解决方案的架构:
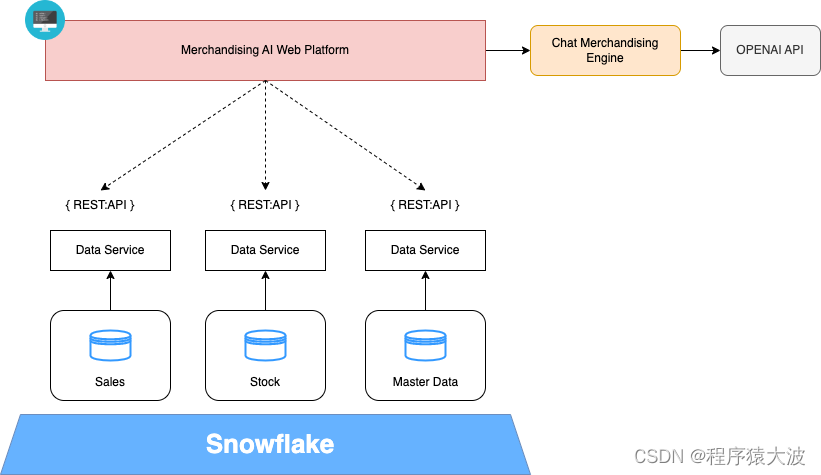
- Merchandising AI Web Platform:基于Vue的网络渠道,通过用户使用聊天推销。
- 数据服务:它提供API Rest来消费数据平台中可用的业务数据实体。
- Chat Merchandising Engine:Python后端服务,执行前端和LLM服务之间的集成;在本例中,我们使用 Open AI API。
- 开放人工智能:它提供了一个 Rest API 来访问生成式人工智能模型。
- 业务数据域和数据存储库:新一代数据仓库,例如 Snowflake,以业务实体可用的数据域为模型。
在此 PoC 中,我们使用了 OpenAI 服务,但您可以使用任何其他 SaaS 或部署您的 LLM;另一个重要的一点是,在这个用例中,我们不会向 OpenAI 服务发送任何业务数据 ,因为 LLM 模型所做的只是将用户以自然语言发出的请求转换为对我们数据服务的请求。
营销人工智能网络平台
通过 LLM 和生成式UI,前端获得了新的相关性、用户与其交互的方式以及前端如何响应交互;现在我们有一个新的参与者,即生成人工智能,它需要与前端交互来管理用户请求。
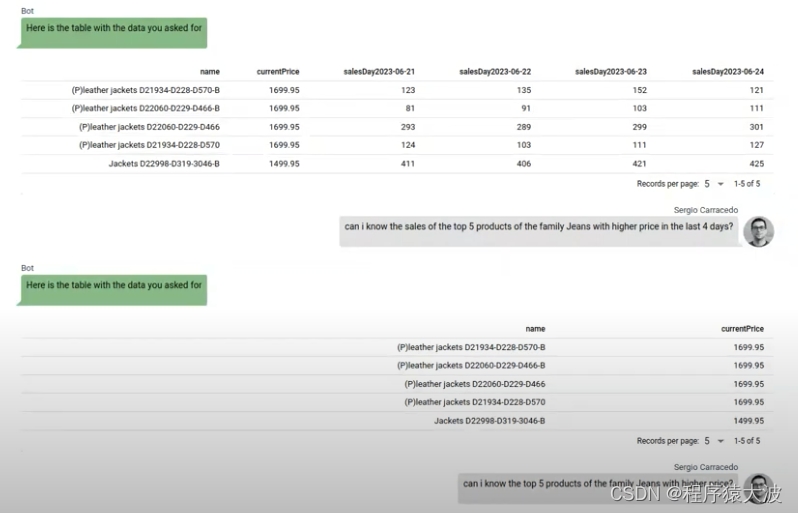
前端需要为用户消息提供上下文,并能够以用户想要的方式显示响应。在此 PoC 中,我们将从模型中得到不同类型的响应:
要在表中显示的数据数组:
要在图表中显示的数据数组:
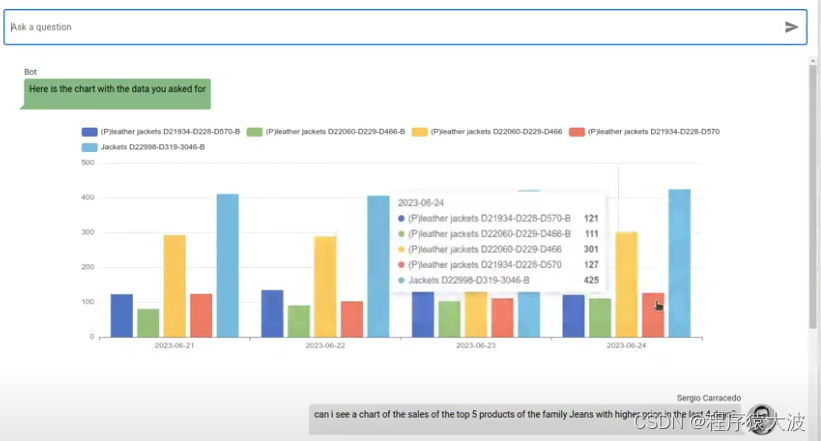
前端需要知道模型或用户希望在响应中看到的内容如何按要求行事;例如,如果用户请求一个图表,前端需要渲染一个图表;如果它要求一个表格,前端应该渲染一个表格,如果它刚刚经过测试,则显示文本(即使存在错误,我们也应该以不同的方式显示它)。
我们输入聊天商品引擎响应(在后端和前端):
export interface TextChatResponse {type: 'text'text: string
}export interface TableDataChatResponse {type: 'table-data'data: TableData
}export interface ChartChatResponse {type: 'chart'options: EChartOptions
}export interface ErrorChatResponse {type: 'error'error: string
}export type ChatResponse = TextChatResponse | TableDataChatResponse | ErrorChatResponse | ChartChatResponse这就是我们决定显示哪个组件的方式。
<div class="chat-messages"><template v-for="(message, index) in messages" :key="index"> <q-chat-messagev-if="message.type === 'text'":avatar="message.avatar":name="message.name":sent="message.sent":text="message.text"/> <div class="chart" v-if="message.type === 'chart'"><v-chart :option="message.options" autoresize class="chart"/></div><div class="table-wrapper" v-if="message.type === 'table-data'"><q-table :columns="getTableCols(message.data)" :rows="message.data" dense></q-table></div></template>
</div>通过这种方法,前端可以以结构化的方式接收消息,并知道如何显示数据:作为文本、作为表格、作为图表或任何你能想到的东西,并且对于后端也非常有用,因为它可以获取侧通道的数据。
对于图表,您可以在 JS 对象中配置与图表相关的所有内容(对于任何类型的图表),因此在 PoC 的下一次迭代中,您可以向模型询问该对象,它可以告诉我们如何渲染图表,甚至是更适合数据的图表类型等。
聊天营销引擎
我们在引擎中的逻辑非常简单:它的职责只是充当前端、开放人工智能服务和我们的数据服务之间的网关。这是必要的,因为开放人工智能模型没有在我们的服务环境中进行训练。我们的引擎负责提供该上下文。如果模型经过训练,我们在该引擎中包含的小逻辑将位于前端服务层。
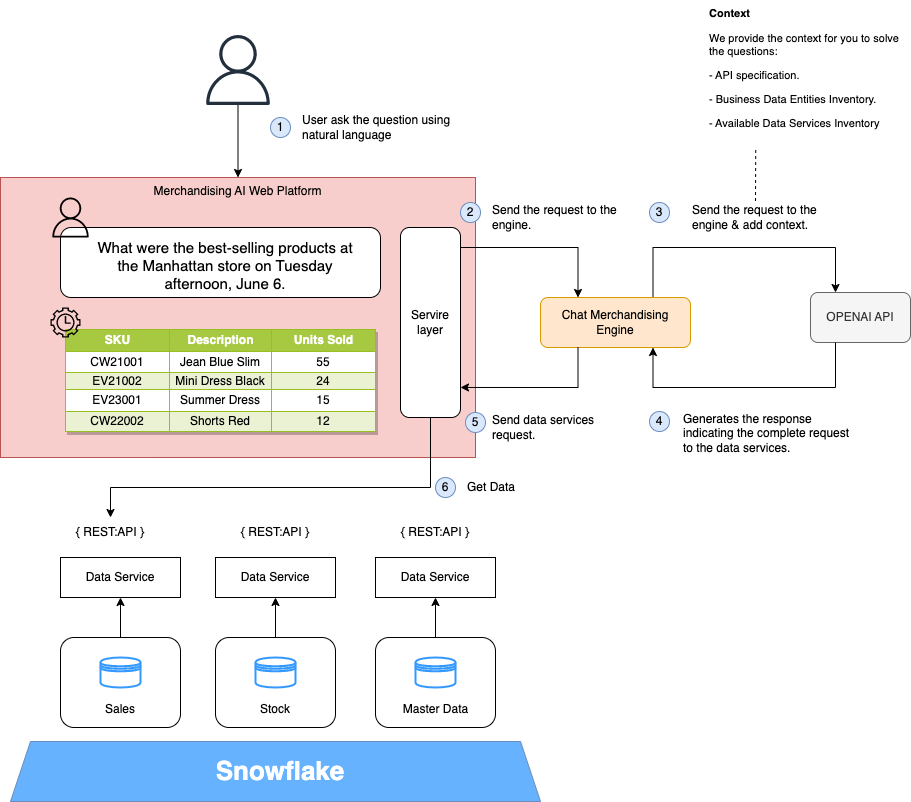
我们使用 Python 实现了这项服务,因为Open AI提供了一个库来促进与其 API 的集成。我们正在使用聊天完成 API(型号 gpt-3.5-turbo),但我们可以使用新功能函数调用(型号 gpt-3.5-turbo-0613)。
# Initial context
messages=[{"role": "system", "content": API_description_context},{"role": "system", "content": load_openapi_specification_from_yaml_to_string()},{"role": "system", "content": entities},]# Add User Query to messages array
messages.append({"role": "user", "content": user_input})# Call Open AI API
response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=messages,temperature=0
)# Get messagesgenerated_texts = [choice.message["content"].strip() for choice in response["choices"]]我们用自然语言描述组成了上下文,其中包括一些示例、API 规范和 API 的定义。
Merchandasing Data Service is an information query API, based on OPEN API 3,
this is an example of URL http://{business_domain}.retail.co/data/api/v1/{{entity}}.Following parameters are included in the API: "fields" to specify the attributes of the entity that we want to get;
"filter" to specify the conditions that must satisfy the search;For example to answer the question of retrieving the products that are not equal to the JEANS family a value
would be products that are not equal to the JEANS family a value would be filter=familyName%%20ne%%20JEANS我们解析响应并使用正则表达式获取生成的 URL,尽管我们可以选择使用一些特殊引号的另一种策略。
def find_urls(model_message_response):# Patrón para encontrar URLsurl_pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')urls = re.findall(url_pattern, model_message_response)return urls我们还要求模型在 URL 中添加一个片段(例如 #chart),以便我们了解用户期望在前端看到什么
该解决方案比在用户输入中搜索字符串要好得多,因为用户可以在不使用图表词(即模型)的情况下请求图表,该模型“理解”谁决定使用图表表示的问题。
最后,我们将此答案发送回前端,因为对数据服务的调用是从前端本身进行的,这允许我们使用用户自己的 JWT 令牌来使用数据服务。
结论
在过去的几年里,许多组织和团队致力于拥有敏捷的架构、良好的数据治理和 API 策略,使他们能够以敏捷的方式适应变化。生成式人工智能模型可以提供巨大的商业价值,并且只需很少的努力就可以开始提供价值。
我们在几个小时内开发了这个 PoC,您可以在视频中看到,使用 Vue3、Quasar Ui 作为基本组件和表格,并使用 Echarts 来渲染图表和 Open AI。毫无疑问,算法是新趋势,也将是数据驱动战略的关键;从标准化和敏捷架构开始的组织在这一挑战中处于领先地位。
相关文章:
生成式人工智能模型:提升营销分析用户体验
使用生成式人工智能来改善分析体验,使业务用户能够询问有关我们数据平台中可用数据的任何信息。 在本文中,我们将解释如何使用新的生成式人工智能模型 ( LLM ) 来改善业务用户在我们的分析平台上的体验。假设我们为零售销售经理提供 Web 应用程序或移动应…...
【并发编程】无锁环形队列Disruptor并发框架使用
Disruptor 是苹国外厂本易公司LMAX开发的一个高件能列,研发的初夷是解决内存队列的延识问顾在性能测试中发现竟然与10操作处于同样的数量级),基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCn演讲后,获得了业界关注…...

【C语言】初阶指针详解
大家好,我是苏貝,本篇博客带大家了解C语言中令人头疼的指针,如果大家觉得我写的不错的话,可以给我一个赞👍吗,感谢❤️ 使用的是VS2019编译器,默认为32位平台 文章目录 ①指针是什么②指针定义与…...
ElasticSearch:项目实战(1)
es环境搭建参考:ElasticSearch:环境搭建步骤_Success___的博客-CSDN博客 需求: 用户输入关键可搜索文章列表 关键词高亮显示 文章列表展示与home展示一样,当用户点击某一篇文章,可查看文章详情 思路: …...

React 实现文件分片上传和下载
React 实现文件分片上传和下载 在开发中,文件的上传和下载是常见的需求。然而,当面对大型文件时,直接的上传和下载方式可能会遇到一些问题,比如网络传输不稳定、文件过大导致传输时间过长等等。为了解决这些问题,我们…...

2023.8.13
atcoder_abc\AtCoder Beginner Contest 310\E_NAND_repeatedly //题意:给定一个n长度的01串,计算f(l,r)(l<r,l在1~n,r在1~n)的和,f的计算(ai,a(i1))运算,有0就为1,11为0 //若f(l,r)1,则f(l,r-1)为0或sr为0,即只取决于上一位的情况和当前位ÿ…...

kvm not all arguments converted during string
kylin virt-manager 远程镜像制作问题记录(not all arguments ) 项目场景: 服务器端安装的OS版本:Kylin-Server-10-SP1-Release-Build20-20210518-arm64-2021-05-18 客户端安装的OS版本:Kylin-Server-10-SP1-Release-Build20-20210518-x86_…...

JVM 基础
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 JVM 类加载机制 JVM 类加载机制分为五个部分:加载,验证,准备,解析,初始化&am…...

智谷星图赵俊:让人才和区块链产业“双向奔赴”丨对话MVP
区块链产业需要什么样的人才?赵俊很有发言权。 赵俊是北京智谷星图科技有限公司的技术总监,也是FISCO BCOS官方认证讲师。他2017年接触区块链,随后选择人才培育领域深耕。“为区块链行业引进更多人才这件事很有价值,跟我的职业理…...
C# Equals()方法报错:NullReferenceException was unhandled
下面是一个C# Equals()方法的例子,执行时报错了 static void Main(string[] args) {string name "sandeep";string myName null;Console.WriteLine(" operator result is {0}", name myName);Console.WriteLine("Equals method result…...
Linux下C语言调用libcurl库获取天气预报信息
一、概述 当前文章介绍如何在Linux(Ubuntu)下使用C语言调用libcurl库获取天气预报的方法。通过HTTP GET请求访问百度天气API,并解析返回的JSON数据,可以获取指定城市未来7天的天气预报信息。 二、设计思路 【1】使用libcurl库进…...

“深入解析JVM:Java虚拟机原理和内部结构“
标题:深入解析JVM:Java虚拟机原理和内部结构 摘要:本文将深入解析JVM(Java虚拟机)的原理和内部结构。我们将从JVM的基础概念开始,逐步介绍其组成部分,包括类加载器、运行时数据区、字节码解释器…...
 返回的list不能add,remove)
Arrays.asList() 返回的list不能add,remove
一.Arrays.asList() 返回的list不能add,remove Arrays.asList()返回的是List,而且是一个定长的List,所以不能转换为ArrayList,只能转换为AbstractList 原因在于asList()方法返回的是某个数组的列表形式,返回的列表只是数组的另一个视图,而数组本身并没…...
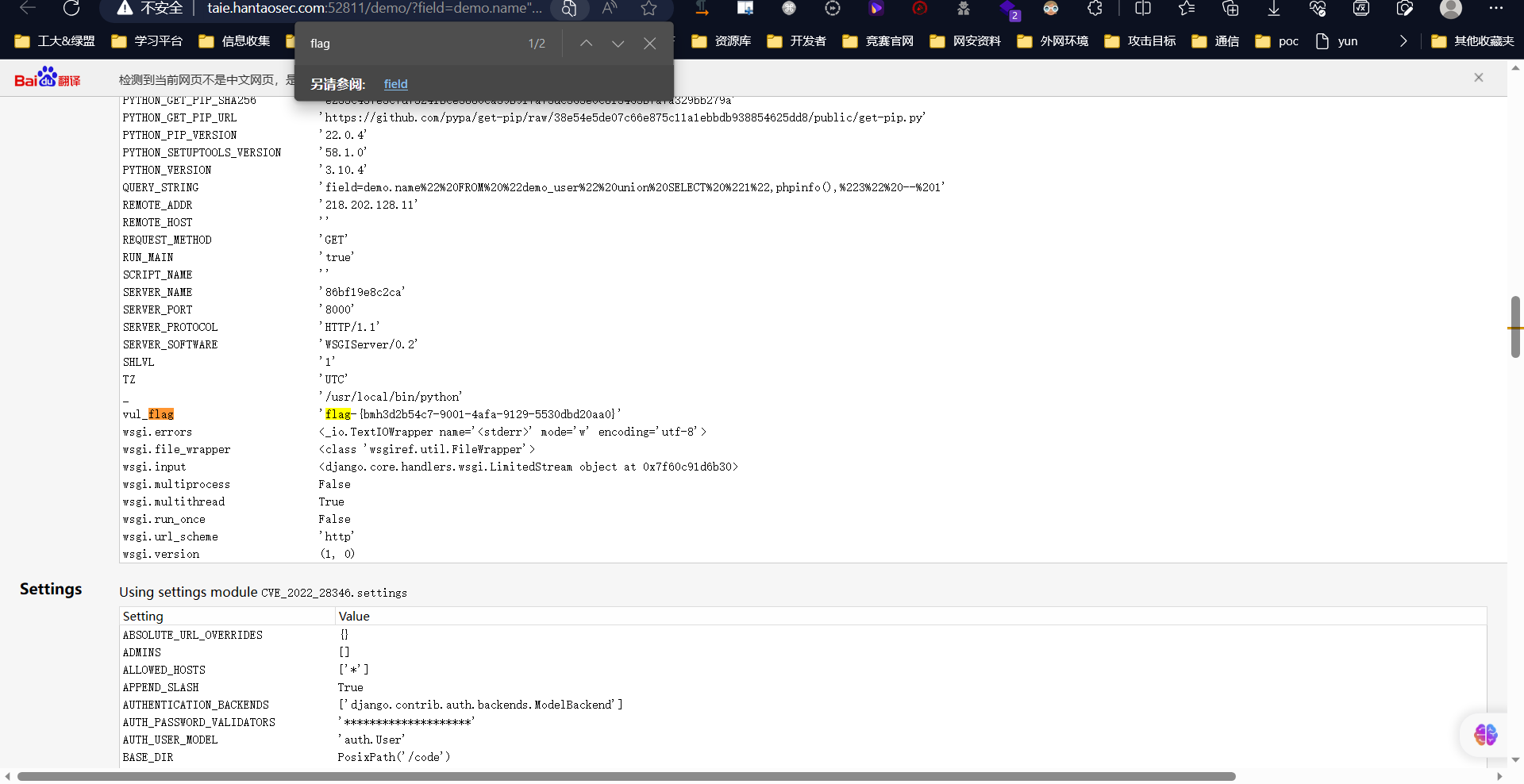
命令执行漏洞
1、命令执行漏洞 1.1、简介 Django是用Python开发的一个免费开源的Web结构,几乎包括了Web使用方方面面,能够用于快速建立高性能、文雅的网站,Diango提供了许多网站后台开发常常用到的模块,使开发者可以专注于业务部分。 1.2、漏…...

Hive 中 sort by 和 order by 的区别
文章目录 数据量大小区别作用范围 在 Hive 中, SORT BY 和 ORDER BY 都用于对查询结果进行排序,但它们在实现方式和适用场景上有一些区别。 数据量大小区别 SORT BY: SORT BY 用于在 Hive 中对查询结果进行排序,它的主要特点是在…...

网络资源利用最大化:爬虫带宽优化解决方案
大家好,作为一名专业的爬虫程序员,我们都知道在爬取大量数据的过程中,网络带宽是一个十分宝贵的资源。如果我们不合理地利用网络带宽,可能会导致爬虫任务的效率低下或者不稳定。今天,我将和大家分享一些优化爬虫带宽利…...

STDF - 基于 Svelte 和 Tailwind CSS 打造的移动 web UI 组件库,Svelte 生态里不可多得的优秀项目
Svelte 是一个新兴的前端框架,组件库不多,今天介绍一款 Svelte 移动端的组件库。 关于 STDF STDF 是一个移动端的 UI 组件库,主要用来开发移动端 web 应用。和我之前介绍的很多 Vue 组件库不一样,STDF 是基于近来新晋 js 框架 S…...
C语言一些有趣的冷门知识
文章目录 概要1.访问数组元素的方法运行结果 2.中括号的特殊用法运行结果 3.大括号的特殊用法运行结果 4.sizeof的用法运行结果 5.渐进运算符运行结果 小结 概要 本文章只是介绍一些有趣的C语言知识,纯属娱乐。这里所有的演示代码我是使用的编译器是Visual Studio …...

Oracle数据库审计
1.什么是审计 审计是用来监控和记录用户的数据库操作的 2.审计级别 语句审计权限审计对象审计 3.查看审计功能是否开启: show parameter audit;相关参数: audit_file_destOS中审计信息存放位置audit_sys_operations默认值为FALSE,即不审…...

Node.js新手在哪儿找小项目练手?
前言 可以参考一下下面的nodejs相关的项目,希望对你的学习有所帮助,废话少说,让我们直接进入正题>> 1、 NodeBB Star: 13.3k 一个基于Node.js的现代化社区论坛软件,具有快速、可扩展、易于使用和灵活的特点。它支持多种数…...

Argo CD 实战:从零构建你的第一个 GitOps 应用
1. 为什么你需要Argo CD? 如果你正在管理Kubernetes应用,肯定遇到过这样的场景:每次代码变更后,都要手动执行kubectl apply来更新集群状态。这种操作不仅容易出错,还很难追踪谁在什么时候改了什么东西。我在实际项目中…...

Linux命令:ping6
ping6 命令 基本介绍 ping6 命令用于测试 IPv6 网络连接是否正常,通过向目标 IPv6 主机发送 ICMPv6(Internet Control Message Protocol version 6)回显请求,并等待目标主机的回显响应。它是 Linux 系统中常用的 IPv6 网络测试工具…...

保姆级教程:用SageMath复现CTF中的AMM算法,手算有限域开方
密码学实战:用SageMath攻克RSA中的AMM算法与有限域开方难题 密码学竞赛中那些看似无解的RSA题目,往往隐藏着令人着迷的数学奥秘。当遇到e与φ(n)不互质的特殊场景时,传统解密方法失效,我们需要搬出数论中的"重型武器"—…...

手把手教你为你的车选数字钥匙方案:ICCE标准 vs CCC标准,哪个更适合国内开发者?
数字钥匙方案深度对比:ICCE与CCC标准在国内开发中的实战选择 站在北京某新能源汽车初创公司的会议室里,技术总监李明正面临一个关键决策——新一代车型的数字钥匙系统究竟该采用国际CCC标准还是国内ICCE标准?玻璃墙外,工程师们激烈…...

终极WebPShop插件安装指南:让Photoshop完美支持WebP格式图片
终极WebPShop插件安装指南:让Photoshop完美支持WebP格式图片 【免费下载链接】WebPShop Photoshop plug-in for opening and saving WebP images 项目地址: https://gitcode.com/gh_mirrors/we/WebPShop 你是否曾经因为Photoshop无法直接处理WebP格式的图片而…...

urllib3 性能优化终极指南:7个提升HTTP请求速度的实用技巧
urllib3 性能优化终极指南:7个提升HTTP请求速度的实用技巧 【免费下载链接】urllib3 urllib3 is a user-friendly HTTP client library for Python 项目地址: https://gitcode.com/gh_mirrors/ur/urllib3 urllib3 是 Python 生态中最受欢迎的 HTTP 客户端库之…...

【AI研究】准确率≠可靠性——普林斯顿团队提出4维度12指标框架,证明Agent能力飙升但可靠性原地踏步
📖 论文速读 | D1 — 2026-03-19 基本信息 论文: Towards a Science of AI Agent Reliability (arXiv 2602.16666) 作者: Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, Arvind Narayanan (普林斯顿大学) 发布: 2026-02-18 仪表…...

Jellyfin元数据终极指南:如何用MetaShark插件打造完美中文媒体库
Jellyfin元数据终极指南:如何用MetaShark插件打造完美中文媒体库 【免费下载链接】jellyfin-plugin-metashark jellyfin电影元数据插件 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-metashark 你是否曾为Jellyfin媒体库中混乱的电影信息而…...

EdgeRemover终极指南:如何彻底卸载Windows中的Microsoft Edge浏览器
EdgeRemover终极指南:如何彻底卸载Windows中的Microsoft Edge浏览器 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemo…...

Ubuntu服务器全盘加密与远程启动自动化解密实践
1. 为什么需要全盘加密与自动解密? 最近帮朋友配置了一台托管在机房的Ubuntu服务器,遇到个头疼的问题:既要保证数据安全,又要能远程重启。传统方案要么加密不彻底,要么每次开机都得手动输密码,对于无人值守…...