Kafka API与SpringBoot调用
文章目录
- 首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。
- 1、使用Kafka原生API
- 1.1、创建spring工程
- 1.2、创建发布者
- 1.3、对生产者的优化
- 1.4、批量发送消息
- 1.5、创建消费者组
- 1.6 消费者同步手动提交
- 1.7、消费者异步手动提交
- 1.8、消费者同异步手动提交
- 2、SpringBoot Kafka
- 2.1、定义发布者
- 1、修改配置文件
- 2、定义发布者处理器
- 2.2、定义消费者
- 1、修改配置文件
- 2、定义消费者
首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。

1、使用Kafka原生API
1.1、创建spring工程
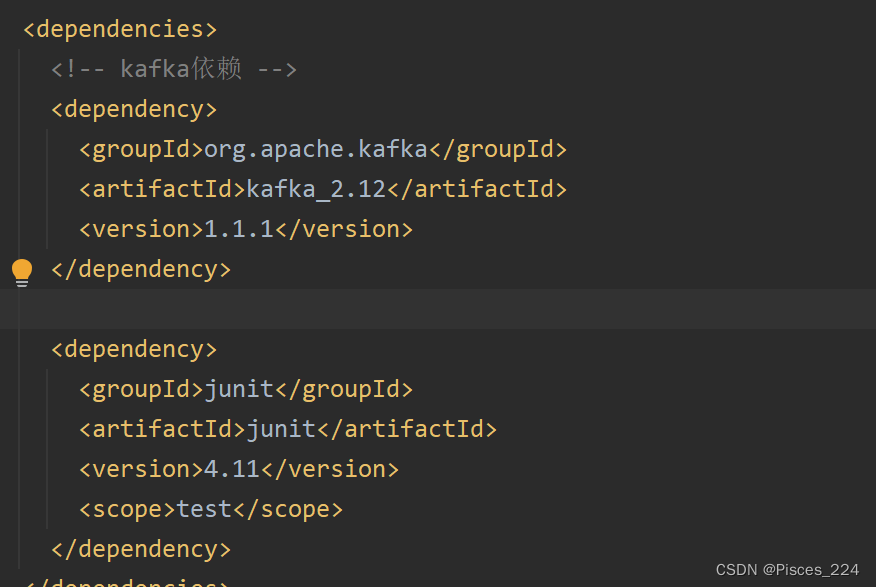
导入依赖:
1.2、创建发布者
先创建一个发布者类OneProsucer:
(注意需要配置一下ip主机名映射:添加映射)
public class OneProducer {// 第一个泛型:当前生产者所生产消息的key// 第二个泛型:当前生产者所生产的消息本身private KafkaProducer<Integer, String> producer;public OneProducer() {Properties properties = new Properties();// 指定kafka集群properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");// 指定key与value的序列化器properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");this.producer = new KafkaProducer<Integer, String>(properties);}public void sendMsg() {// 创建消息记录(包含主题、消息本身) (String topic, V value)// ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "tianjin");// 创建消息记录(包含主题、key、消息本身) (String topic, K key, V value)// ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 1, "tianjin");// 创建消息记录(包含主题、partition、key、消息本身) (String topic, Integer partition, K key, V value)ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 1, "tianjin");producer.send(record);}
}
注意代码中的字符串kafka都是有对应的常量的,这里便于理解用原生字符串来来写。
一般情况下,我们可能无法记住这些参数名。为此,Kafka的ProducerConfig类提供了一系列的参数常量。例如:
bootstrap.servers 可替换为 ProducerConfig.BOOTSTRAP_SERVERS_CONFIG
key.serializer 可替换为 ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG
value.serializer 可替换为 ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG
api生产的消息与命令行消息的区别:
参考:Kafka生产者
再创建一个测试类:
public class OneProducerTest {public static void main(String[] args) throws IOException {OneProducer producer = new OneProducer();producer.sendMsg();System.in.read();}
}
xshell启动主题为cities的一个消费者:
bin/kafka-console-consumer.sh --bootstrap-server 192.168.255.212:9092 --topic cities --from-beginning
启动生产者测试类生产消息:

查看linux端消费者,可以看到消息:

3台主机消费者都可以收到。
1.3、对生产者的优化
对于上一小节,有两个不舒服的点:
- 生产者端启动后控制台没有任何输出,只能通过看消费端消息才确认发送接收成功;
- 生产消息,指定分区的测试
这里可以使用回调方式,发送成功后,触发回调方法,生产端返回提示。
创建发布者类(修改senMsg方法):
public class TwoProducer {// 第一个泛型:当前生产者所生产消息的key// 第二个泛型:当前生产者所生产的消息本身private KafkaProducer<Integer, String> producer;public TwoProducer() {Properties properties = new Properties();// 指定kafka集群properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");// 指定key与value的序列化器properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");this.producer = new KafkaProducer<Integer, String>(properties);}public void sendMsg() {// 创建消息记录(包含主题、消息本身) (String topic, V value)// ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "tianjin");// 创建消息记录(包含主题、key、消息本身) (String topic, K key, V value)// ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 1, "tianjin");// 创建消息记录(包含主题、partition、key、消息本身) (String topic, Integer partition, K key, V value)ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", 2, 1, "tianjin");producer.send(record, (metadata, ex) -> {System.out.println("topic = " + metadata.topic());System.out.println("partition = " + metadata.partition());System.out.println("offset = " + metadata.offset());});}
}
创建测试类:
public class TwoProducerTest {public static void main(String[] args) throws IOException {TwoProducer producer = new TwoProducer();producer.sendMsg();System.in.read();}
}
启动运行:
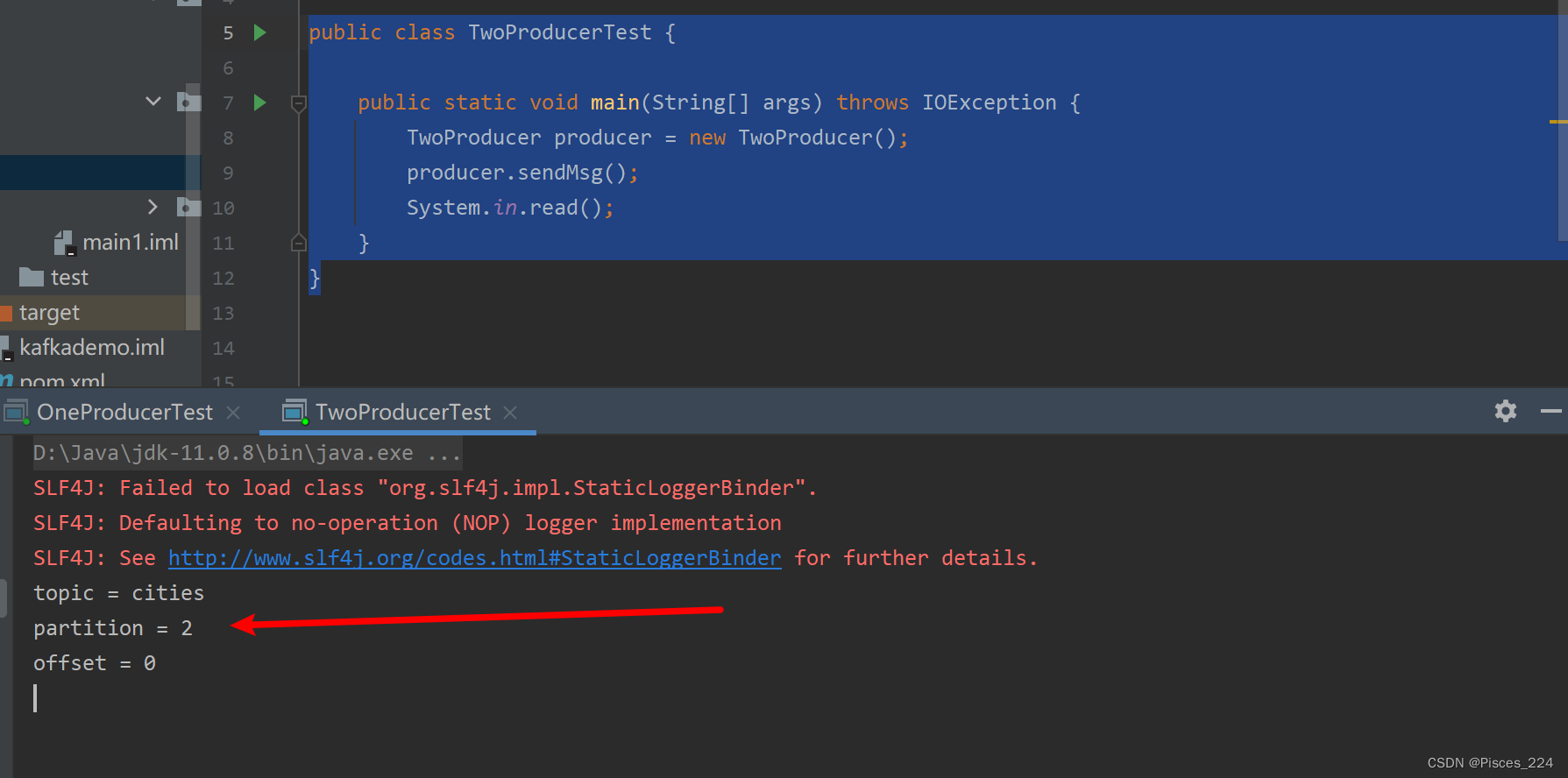
消费端:

再次生产消息,偏移量变为1:
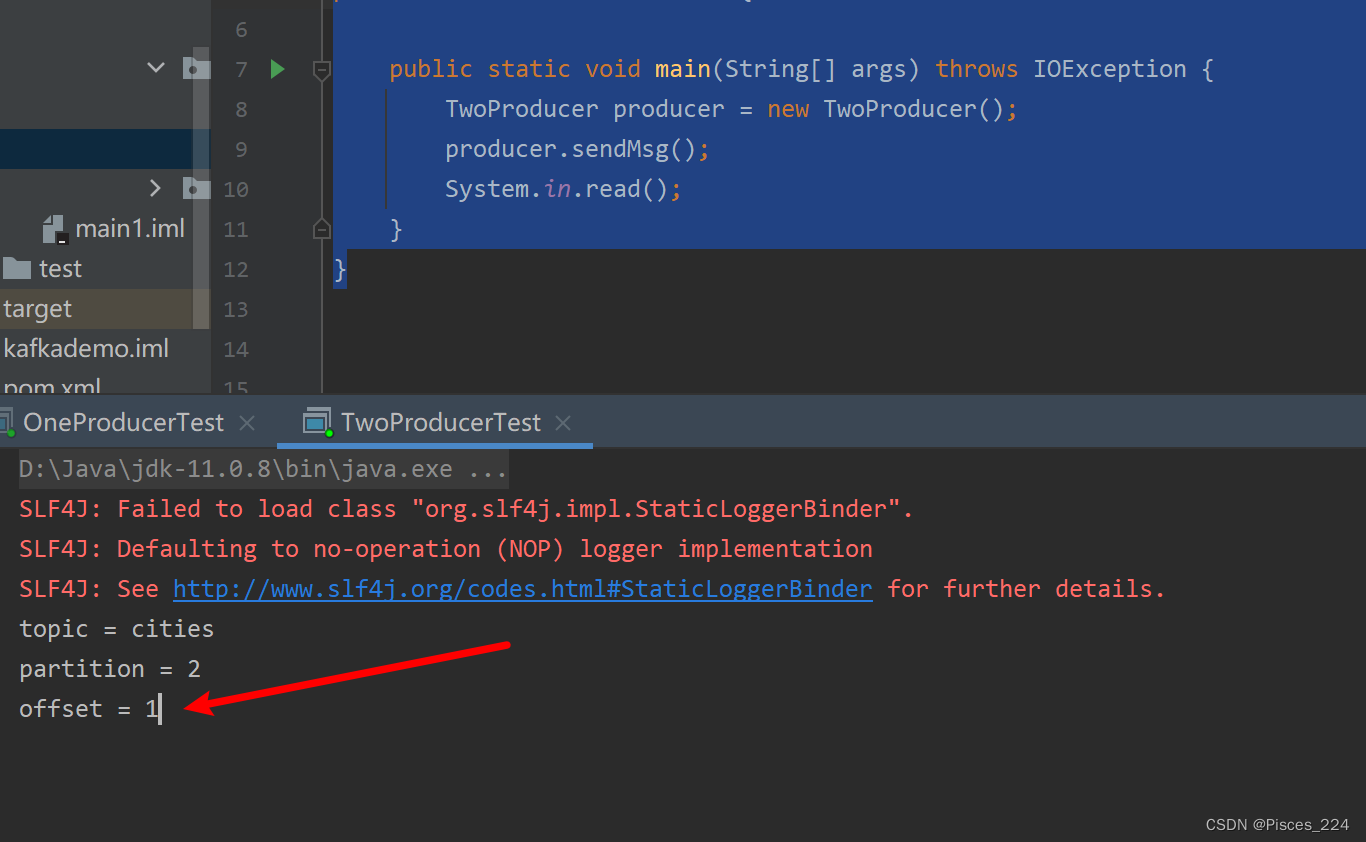
但是到目前为止,生产者一次只能发送一条消息,接下来看生产者批量发送消息。
1.4、批量发送消息
创建发布者类:
public class SomeProducerBatch {// 第一个泛型:当前生产者所生产消息的key// 第二个泛型:当前生产者所生产的消息本身private KafkaProducer<Integer, String> producer;public SomeProducerBatch() {Properties properties = new Properties();// 指定kafka集群properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");// 指定key与value的序列化器properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 指定生产者每10条向broker发送一次properties.put("batch.size", 10);// 指定生产者每50ms向broker发送一次properties.put("linger.ms", 50);this.producer = new KafkaProducer<Integer, String>(properties);}public void sendMsg() {for(int i=0; i<50; i++) {ProducerRecord<Integer, String> record = new ProducerRecord<>("cities", "city-" + i);int k = i;producer.send(record, (metadata, ex) -> {System.out.println("i = " + k);System.out.println("topic = " + metadata.topic());System.out.println("partition = " + metadata.partition());System.out.println("offset = " + metadata.offset());});}}
}
注意:
- batch.size
- lingger.ms
如果50ms没产生50条,时间到了也发消息。
创建一个测试类:
public class ProducerBatchTest {public static void main(String[] args) throws IOException {SomeProducerBatch producer = new SomeProducerBatch();producer.sendMsg();System.in.read();}
}
本身send方法执行了50次,但是并不是每一次都发送,仅仅是生产了50条消息;发送是按照上面的设置每10条向broker发送一次或者每50ms发送一次。
(分区是轮询的):
i = 0
topic = cities
partition = 0
offset = 2
i = 3
topic = cities
partition = 0
offset = 3
i = 1
topic = cities
partition = 2
offset = 2
i = 4
topic = cities
partition = 2
offset = 3
i = 6
topic = cities
partition = 0
offset = 4
i = 9
topic = cities
partition = 0
offset = 5
i = 7
topic = cities
partition = 2
offset = 4
i = 10
topic = cities
partition = 2
offset = 5
i = 12
topic = cities
partition = 0
offset = 6
i = 15
topic = cities
partition = 0
offset = 7
i = 13
topic = cities
partition = 2
offset = 6
i = 16
topic = cities
partition = 2
offset = 7
i = 18
topic = cities
partition = 0
offset = 8
i = 21
topic = cities
partition = 0
offset = 9
i = 24
topic = cities
partition = 0
offset = 10
i = 27
topic = cities
partition = 0
offset = 11
i = 19
topic = cities
partition = 2
offset = 8
i = 22
topic = cities
partition = 2
offset = 9
i = 30
topic = cities
partition = 0
offset = 12
i = 33
topic = cities
partition = 0
offset = 13
i = 36
topic = cities
partition = 0
offset = 14
i = 39
topic = cities
partition = 0
offset = 15
i = 42
topic = cities
partition = 0
offset = 16
i = 45
topic = cities
partition = 0
offset = 17
i = 25
topic = cities
partition = 2
offset = 10
i = 28
topic = cities
partition = 2
offset = 11
i = 31
topic = cities
partition = 2
offset = 12
i = 34
topic = cities
partition = 2
offset = 13
i = 37
topic = cities
partition = 2
offset = 14
i = 40
topic = cities
partition = 2
offset = 15
i = 43
topic = cities
partition = 2
offset = 16
i = 46
topic = cities
partition = 2
offset = 17
i = 48
topic = cities
partition = 0
offset = 18
i = 49
topic = cities
partition = 2
offset = 18
i = 2
topic = cities
partition = 1
offset = 0
i = 5
topic = cities
partition = 1
offset = 1
i = 8
topic = cities
partition = 1
offset = 2
i = 11
topic = cities
partition = 1
offset = 3
i = 14
topic = cities
partition = 1
offset = 4
i = 17
topic = cities
partition = 1
offset = 5
i = 20
topic = cities
partition = 1
offset = 6
i = 23
topic = cities
partition = 1
offset = 7
i = 26
topic = cities
partition = 1
offset = 8
i = 29
topic = cities
partition = 1
offset = 9
i = 32
topic = cities
partition = 1
offset = 10
i = 35
topic = cities
partition = 1
offset = 11
i = 38
topic = cities
partition = 1
offset = 12
i = 41
topic = cities
partition = 1
offset = 13
i = 44
topic = cities
partition = 1
offset = 14
i = 47
topic = cities
partition = 1
offset = 15
linux端:
city-1
city-4
city-7
city-10
city-0
city-3
city-6
city-9
city-13
city-16
city-19
city-22
city-25
city-28
city-31
city-34
city-37
city-40
city-12
city-15
city-18
city-21
city-24
city-27
city-30
city-33
city-36
city-39
city-42
city-45
city-43
city-46
city-49
city-48
city-2
city-5
city-8
city-11
city-14
city-17
city-20
city-23
city-26
city-29
city-32
city-35
city-38
city-41
city-44
city-47
1.5、创建消费者组
消费者类:
public class SomeConsumer extends ShutdownableThread {private KafkaConsumer<Integer, String> consumer;public SomeConsumer() {// 两个参数:// 1)指定当前消费者名称// 2)指定消费过程是否会被中断super("KafkaConsumerTest", false);Properties properties = new Properties();String brokers = "kafka01:9092,kafka02:9092,kafka03:9092";// 指定kafka集群properties.put("bootstrap.servers", brokers);// 指定消费者组IDproperties.put("group.id", "cityGroup1");// 开启自动提交,默认为trueproperties.put("enable.auto.commit", "true");// 指定自动提交的超时时限,默认5sproperties.put("auto.commit.interval.ms", "1000");// 指定消费者被broker认定为挂掉的时限。若broker在此时间内未收到当前消费者发送的心跳,则broker// 认为消费者已经挂掉。默认为10sproperties.put("session.timeout.ms", "30000");// 指定两次心跳的时间间隔,默认为3s,一般不要超过session.timeout.ms的 1/3properties.put("heartbeat.interval.ms", "10000");// 当kafka中没有指定offset初值时,或指定的offset不存在时,从这里读取offset的值。其取值的意义为:// earliest:指定offset为第一条offset// latest: 指定offset为最后一条offsetproperties.put("auto.offset.reset", "earliest");// 指定key与value的反序列化器properties.put("key.deserializer","org.apache.kafka.common.serialization.IntegerDeserializer");properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");this.consumer = new KafkaConsumer<Integer, String>(properties);}@Overridepublic void doWork() {// 订阅消费主题consumer.subscribe(Collections.singletonList("cities"));// 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。// 0,表示没有消息什么也不返回// >0,表示当时间到后仍没有消息,则返回空ConsumerRecords<Integer, String> records = consumer.poll(1000);for(ConsumerRecord record : records) {System.out.println("topic = " + record.topic());System.out.println("partition = " + record.partition());System.out.println("key = " + record.key());System.out.println("value = " + record.value());}}
}
测试类:
public class ConsumerTest {public static void main(String[] args) {SomeConsumer consumer = new SomeConsumer();consumer.start();}
}
启动运行,查看消费者控制台:
topic = cities
partition = 0
key = 1
value = tianjin
topic = cities
partition = 0
key = 1
value = tianjin
topic = cities
partition = 0
key = null
value = city-0
topic = cities
partition = 0
key = null
value = city-3
topic = cities
partition = 0
key = null
value = city-6
topic = cities
partition = 0
...
1.6 消费者同步手动提交
(1) 自动提交的问题
前面的消费者都是以自动提交 offset 的方式对 broker 中的消息进行消费的,但自动提交
可能会出现消息重复消费的情况。所以在生产环境下,很多时候需要对 offset 进行手动提交,
以解决重复消费的问题。
(2) 手动提交分类
手动提交又可以划分为同步提交、异步提交,同异步联合提交。这些提交方式仅仅是
doWork()方法不相同,其构造器是相同的。所以下面首先在前面消费者类的基础上进行构造
器的修改,然后再分别实现三种不同的提交方式。
创建创建消费者类 SyncManualConsumer:
-
A、原理
同步提交方式是,消费者向 broker 提交 offset 后等待 broker 成功响应。若没有收到响
应,则会重新提交,直到获取到响应。而在这个等待过程中,消费者是阻塞的。其严重影响
了消费者的吞吐量。 -
B、 修改构造器
直接复制前面的 SomeConsumer,在其基础上进行修改。
public class SyncManualConsumer extends ShutdownableThread {private KafkaConsumer<Integer, String> consumer;public SyncManualConsumer() {// 两个参数:// 1)指定当前消费者名称// 2)指定消费过程是否会被中断super("KafkaConsumerTest", false);Properties properties = new Properties();String brokers = "kafkaOS1:9092,kafkaOS2:9092,kafkaOS3:9092";// 指定kafka集群properties.put("bootstrap.servers", brokers);// 指定消费者组IDproperties.put("group.id", "cityGroup1");// 开启手动提交properties.put("enable.auto.commit", "false");// 指定自动提交的超时时限,默认5s// properties.put("auto.commit.interval.ms", "1000");// 指定一次提交10个offsetproperties.put("max.poll.records", 10);// 指定消费者被broker认定为挂掉的时限。若broker在此时间内未收到当前消费者发送的心跳,则broker// 认为消费者已经挂掉。默认为10sproperties.put("session.timeout.ms", "30000");// 指定两次心跳的时间间隔,默认为3s,一般不要超过session.timeout.ms的 1/3properties.put("heartbeat.interval.ms", "10000");// 当kafka中没有指定offset初值时,或指定的offset不存在时,从这里读取offset的值。其取值的意义为:// earliest:指定offset为第一条offset// latest: 指定offset为最后一条offsetproperties.put("auto.offset.reset", "earliest");// 指定key与value的反序列化器properties.put("key.deserializer","org.apache.kafka.common.serialization.IntegerDeserializer");properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");this.consumer = new KafkaConsumer<Integer, String>(properties);}@Overridepublic void doWork() {// 订阅消费主题consumer.subscribe(Collections.singletonList("cities"));// 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。// 0,表示没有消息什么也不返回// >0,表示当时间到后仍没有消息,则返回空ConsumerRecords<Integer, String> records = consumer.poll(1000);for(ConsumerRecord record : records) {System.out.println("topic = " + record.topic());System.out.println("partition = " + record.partition());System.out.println("key = " + record.key());System.out.println("value = " + record.value());// 手动同步提交consumer.commitSync();}}
}
创建测试类:
public class SyncManualTest {public static void main(String[] args) {SyncManualConsumer consumer = new SyncManualConsumer();consumer.start();}
}
1.7、消费者异步手动提交
(1) 原理
手动同步提交方式需要等待 broker 的成功响应,效率太低,影响消费者的吞吐量。异步提交方式是,消费者向 broker 提交 offset 后不用等待成功响应,所以其增加了消费者的吞吐量。
(2) 创建消费者类 AsyncManualConsumer
复制前面的 SyncManualConsumer 类,在其基础上进行修改。
public class AsynManualConsumer extends ShutdownableThread {private KafkaConsumer<Integer, String> consumer;public AsynManualConsumer() {...}@Overridepublic void doWork() {// 订阅消费主题consumer.subscribe(Collections.singletonList("cities"));// 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。// 0,表示没有消息什么也不返回// >0,表示当时间到后仍没有消息,则返回空ConsumerRecords<Integer, String> records = consumer.poll(1000);for(ConsumerRecord record : records) {System.out.println("topic = " + record.topic());System.out.println("partition = " + record.partition());System.out.println("key = " + record.key());System.out.println("value = " + record.value());// 手动异步提交// consumer.commitAsync();consumer.commitAsync((offsets, ex) -> {if(ex != null) {System.out.print("提交失败,offsets = " + offsets);System.out.println(", exception = " + ex);}});}}
}
启动类:
public class AsyncManualTest {public static void main(String[] args) {AsynManualConsumer consumer = new AsynManualConsumer();consumer.start();}
}
1.8、消费者同异步手动提交
(1) 原理
同异步提交,即同步提交与异步提交组合使用。一般情况下,若偶尔出现提交失败,其
也不会影响消费者的消费。因为后续提交最终会将这次提交失败的 offset 给提交了。
但异步提交会产生重复消费,为了防止重复消费,可以将同步提交与异常提交联合使用。
(2) 创建消费者类 SyncAsyncManualConsumer
复制前面的 AsyncManualConsumer 类,在其基础上进行修改。
@Overridepublic void doWork() {// 订阅消费主题consumer.subscribe(Collections.singletonList("cities"));// 从broker摘取消费。参数表示,若buffer中没有消费,消费者等待消费的时间。// 0,表示没有消息什么也不返回// >0,表示当时间到后仍没有消息,则返回空ConsumerRecords<Integer, String> records = consumer.poll(1000);for(ConsumerRecord record : records) {System.out.println("topic = " + record.topic());System.out.println("partition = " + record.partition());System.out.println("key = " + record.key());System.out.println("value = " + record.value());consumer.commitAsync((offsets, ex) -> {if(ex != null) {System.out.print("提交失败,offsets = " + offsets);System.out.println(", exception = " + ex);// 同步提交consumer.commitSync();}});}}
2、SpringBoot Kafka
新建一个简单案例,将发布者和订阅者定义到一个工程中。
创建一个SpringBoot工程,pom.xml添加如下依赖:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
</dependencies>
2.1、定义发布者
Spring 是通过 KafkaTemplate 来完成对 Kafka 的操作的。
1、修改配置文件
# 自定义属性
kafka:topic: cities# 配置Kafka
spring:kafka:bootstrap-servers: kafkaOS1:9092,kafkaOS2:9092,kafkaOS3:9092# producer: # 配置生产者# key-serializer: org.apache.kafka.common.serialization.StringSerializer# value-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer: # 配置消费者group-id: group0 # 消费者组# key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
2、定义发布者处理器
@RestController
public class SomeProducer {@Autowiredprivate KafkaTemplate<String, String> template;// 从配置文件读取自定义属性@Value("${kafka.topic}")private String topic;// 由于是提交数据,所以使用Post方式@PostMapping("/msg/send")public String sendMsg(@RequestParam("message") String message) {template.send(topic, message);return "send success";}
}
2.2、定义消费者
Spring 是通过监听方式实现消费者的。
1、修改配置文件
如上一小节,在配置文件中添加消费者配置内容。注意,Spring 中要求必须为消费者指定组。
2、定义消费者
Spring Kafka 是通过 KafkaListener 监听方式来完成消息订阅与接收的。当监听到有指定
主题的消息时,就会触发@KafkaListener 注解所标注的方法的执行
@Component
public class SomeConsumer {@KafkaListener(topics = "${kafka.topic}")public void onMsg(String message) {System.out.println("Kafka消费者接受到消息 " + message);}}
run运行,postman访问接口输入消息:
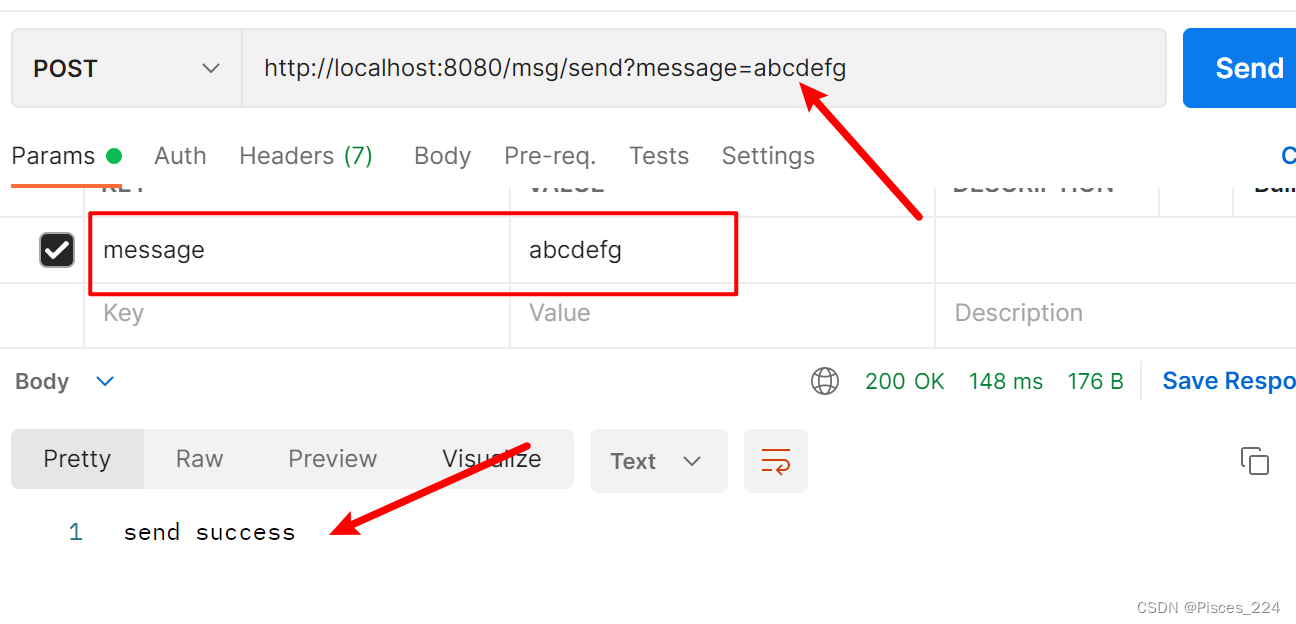
消费者收到消息:

因为SpringBoot自动配置的原理,Kafka自动配置里:
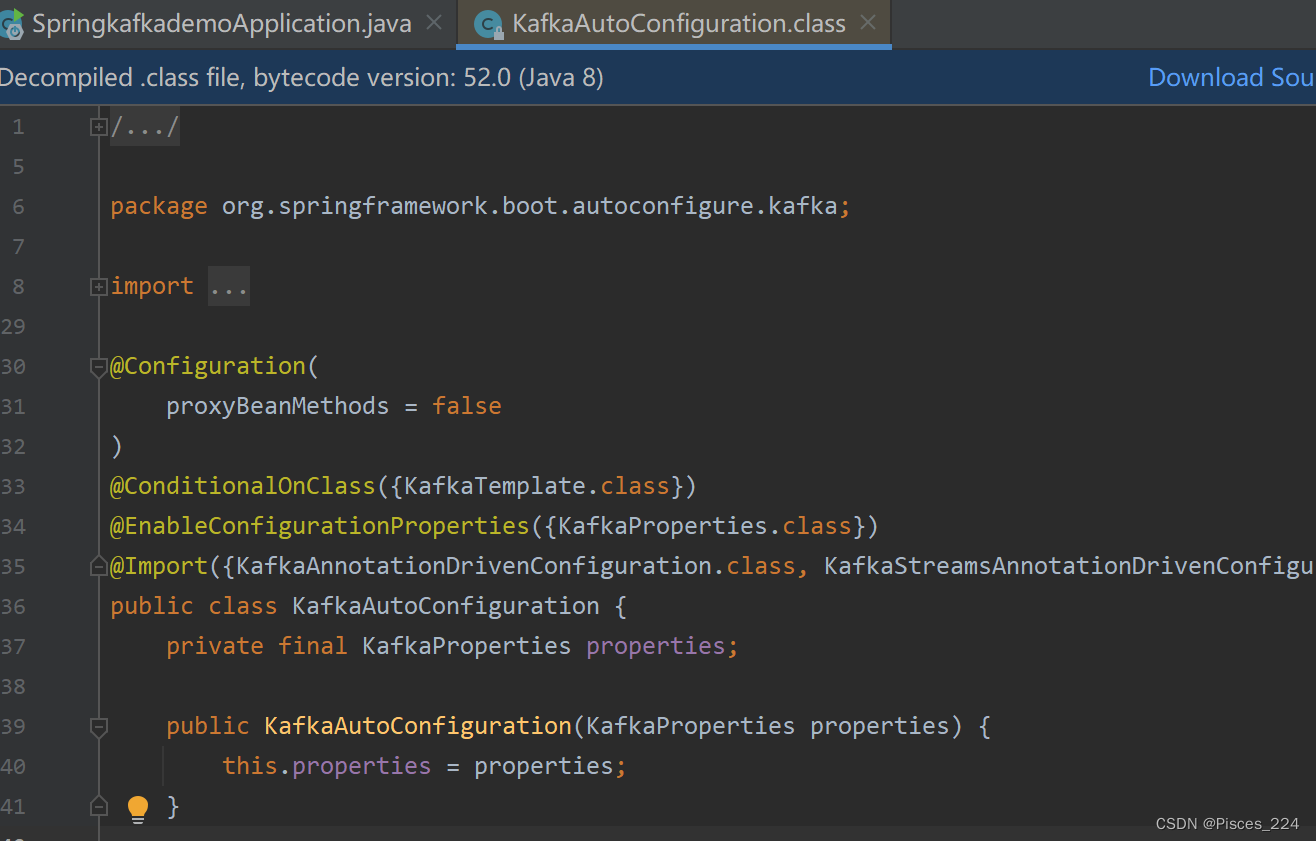
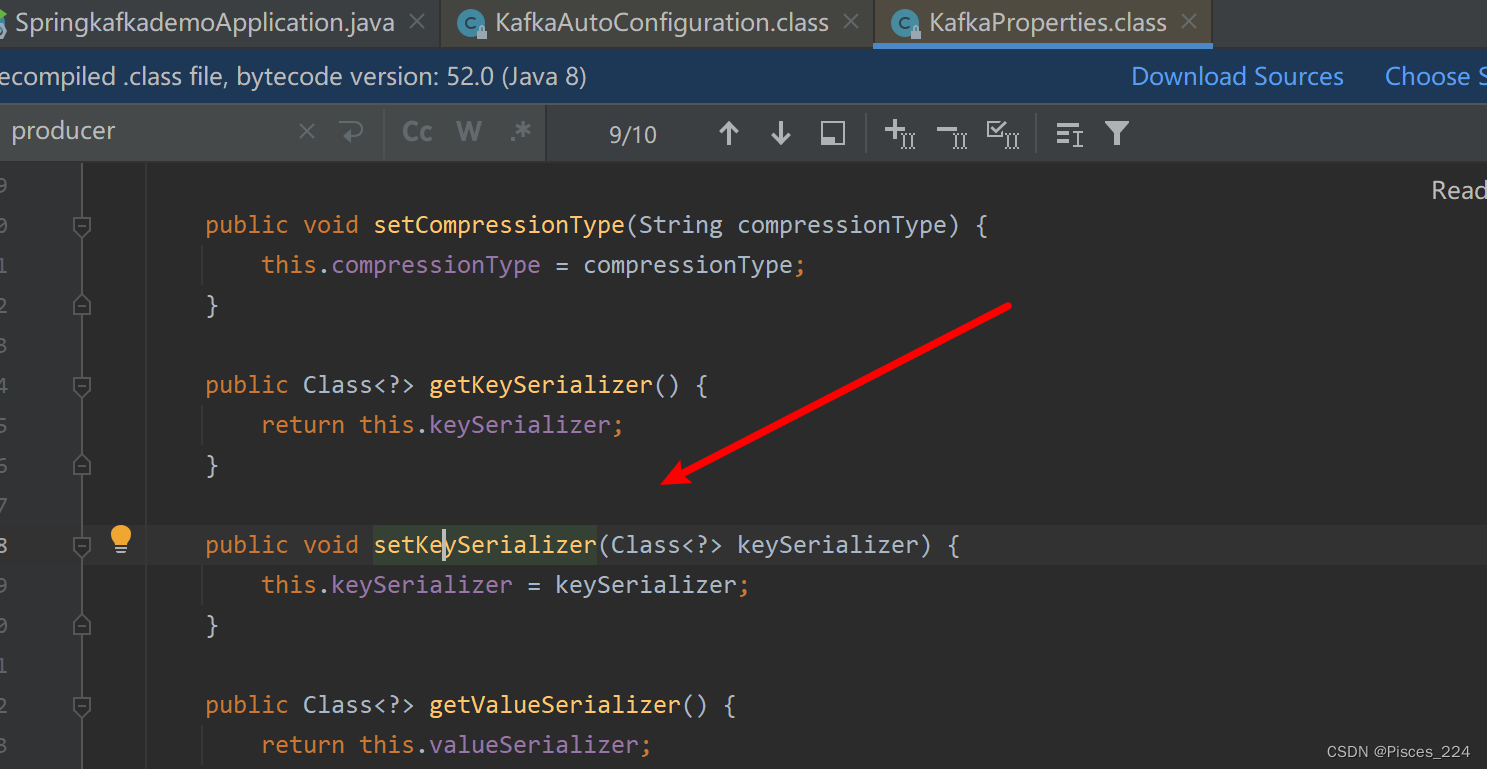
默认就有了序列化,所以配置文件可以不用配置生产者的序列化。
相关文章:
Kafka API与SpringBoot调用
文章目录 首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。 1、使用Kafka原生API1.1、创建spring工程1.2、创建发布者1.3、对生产者的优化1.4、批量发送消息1.5、创建消费者组1.6 消费者同步手动提交1.7、消费者异步手动提交1.8、消费者同异步手动…...

JavaScript构造函数和类的区别
原文 构造函数 没有显式的创建对象创建对象时使用new操作符。所有属性和方法赋值给this对象。没有return语句按照惯例,构造函数的方法名首字母应该使用大写字母,用于区分普通函数,其实构造函数也是函数,其主要功能是用来创建对象…...
Spring与Spring Bean
Spring 原理 它是一个全面的、企业应用开发一站式的解决方案,贯穿表现层、业务层、持久层。但是 Spring 仍然可 以和其他的框架无缝整合。 Spring 特点 轻量级 控制反转 面向切面 容器 框架集合 Spring 核心组件 Spring 总共有十几个组件核心容器(Spring core) S…...
并发相关面试题
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 如何理解volatile关键字 在并发领域中,存在三大特性:原子性、有序性、可见性。volatile关键字用来修饰对象的属性…...
Hadoop+Python+Django+Mysql热门旅游景点数据分析系统的设计与实现(包含设计报告)
系统阐述的是使用热门旅游景点数据分析系统的设计与实现,对于Python、B/S结构、MySql进行了较为深入的学习与应用。主要针对系统的设计,描述,实现和分析与测试方面来表明开发的过程。开发中使用了 django框架和MySql数据库技术搭建系统的整体…...

php中nts和ts
PHP语言解析器:官方提供了2种类型的版本,线程安全(TS)版和非线程安全(NTS)版 TS: TS(Thread-Safety)即线程安全,多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时进行数据加锁保护,其他线程不能同时进行访…...
设计模式之责任链模式【Java实现】
责任链(Chain of Resposibility) 模式 概念 责任链(chain of Resposibility) 模式:为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者 通过前一对象记住其下一个对象的引用而连成一条…...

Android 12.0 系统systemui状态栏下拉左滑显示通知栏右滑显示控制中心模块的流程分析
1.前言 在android12.0的系统rom定制化开发中,在系统原生systemui进行自定义下拉状态栏布局的定制的时候,需要在systemui下拉状态栏下滑的时候,根据下滑坐标来 判断当前是滑出通知栏还是滑出控制中心模块,所以就需要根据屏幕宽度,来区分x坐标值为多少是左滑出通知栏或者右…...
服务器安装JDK
三种方法 方法一: 方法二: 首先登录到Oracle官网下载JDK JDK上传到服务器中,记住文件上传的位置是在哪里(我放的位置在/www/java),然后看下面指示进行安装 方法三: 首先登录到Oracle官网下载…...

cpu查询
1.mpstat查看系统cpu状况 mpstat 1 1或者mpstat -P ALL查看每个cpu使用状态,(用户态cpu是用来,内核态cpu使用率,等待IO使用率) 2.vmstat 可以查看系统运行任务数(正在cpu运行进程和就绪队列进程࿰…...

【muduo】关于自动增长的缓冲区
目录 为什么需要缓冲区自动增长的缓冲区buffer数据结构buffer类 写详细比较费时间,就简单总结下。 总结自Linux 多线程服务端编程:使用 muduo C 网络库 Muduo网络编程: IO-multiplexnon-blocking 为什么需要缓冲区 Non-blocking IO 的核心…...
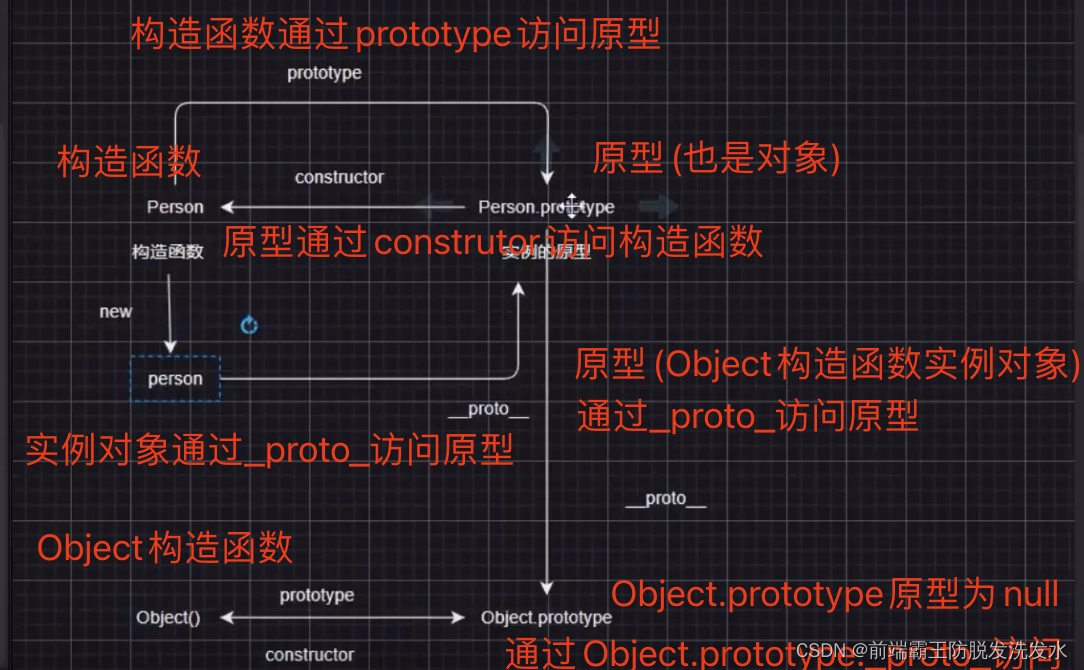
原型和原型链理解
这个图大概能概括原型和原型链的关系 1.对象都是通过 _proto_ 访问原型 2.原型都是通过constructor 访问构造函数 3.原型是构造函数的 prototype 4.原型也是对象实例 也是通过 _proto_ 访问原型(Object.prototype) 5.Object.prototype的原型通过 _proto_ 访问 为null 那么…...

CSS:弹性盒子模型详解(用法 + 例子 + 效果)
目录 弹性盒子模型flex-direction 排列方式 主轴方向换行排序控制子元素缩放比例缩放是如何实现的? 控制子元素的对其方式justify-content 横向 对齐方式align-items 纵向 对齐方式 align-content 多行 对齐方式 弹性盒子模型 flex-direction 排列方式 主轴方向 f…...
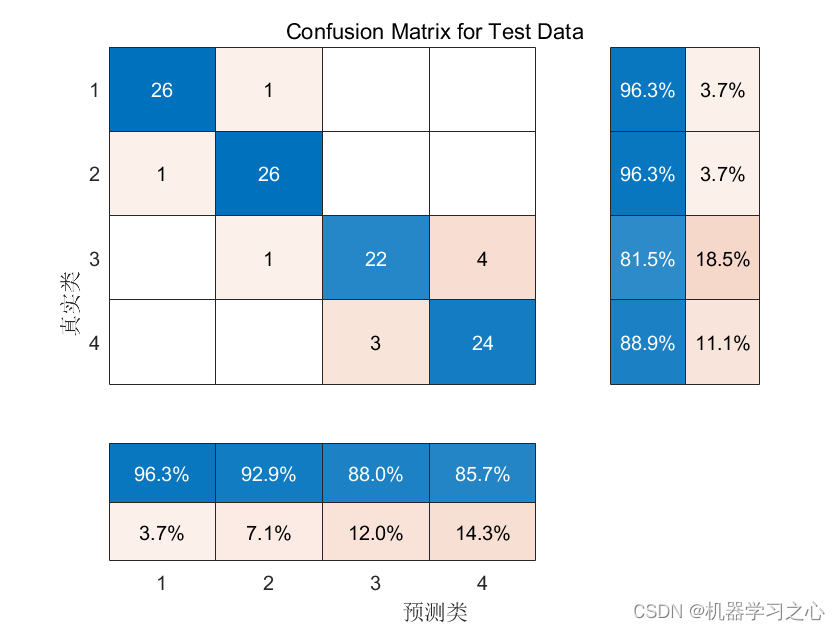
分类预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据分类预测
分类预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据分类预测 目录 分类预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据分类预测效果一览基本介绍研究内容程序设计参考资料 效果一览 基本介绍 Matlab实现基于…...

拜读苏神-1-深度学习+文本情感分类
一、闲聊神经网络与深度学习 参考链接:https://www.kexue.fm/archives/3331 分类模型本质上是在做拟合——模型其实就是一个函数(或者一簇函数),里边有一些待定的参数,根据已有的数据,确定损失函数&#x…...

【uniapp 小程序开发语法篇】资源引入 | 语法介绍 | UTS 语法支持(链接格式)
博主:_LJaXi Or 東方幻想郷 专栏: uni-app | 小程序开发 开发工具:HBuilderX 小程序开发语法篇 引用组件easycom Js文件引入NPM支持 Css文件引入静态资源引入css 引入静态资源如何引入字体图标?css 引入字体图标示例nvue 引入字体…...

Stable Diffusion教程(9) - AI视频转动漫
配套抖音视频教程:https://v.douyin.com/UfTcrcJ/ 安装mov2mov插件 打开webui点击扩展->从网址安装输入地址,然后点击安装 https://github.com/Scholar01/sd-webui-mov2mov 最后重启webui 下载模型 从国内liblib AI 模型站下载模型 LiblibAI哩…...
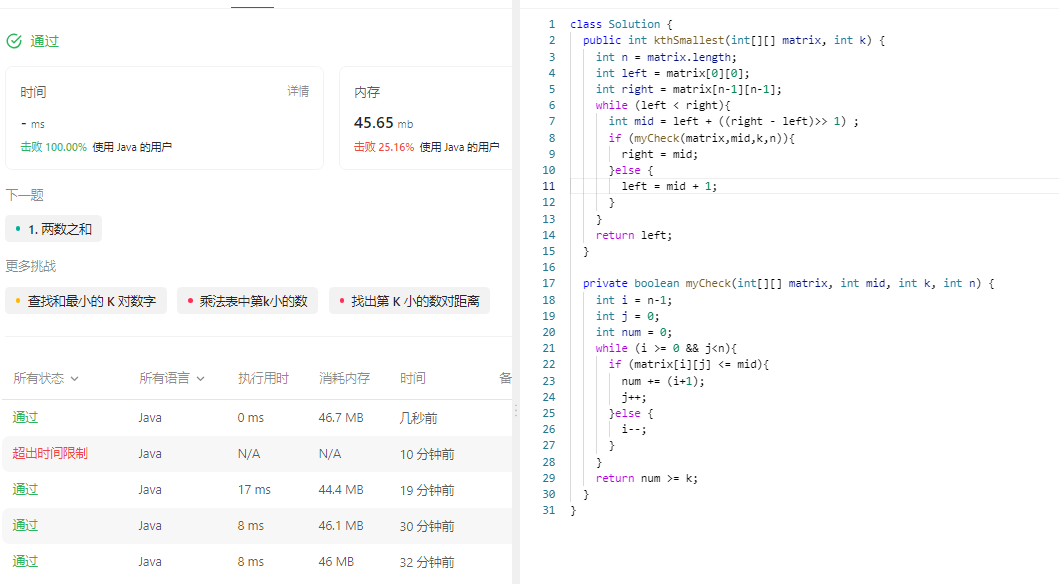
378. 有序矩阵中第 K 小的元素
378. 有序矩阵中第 K 小的元素 原题链接:完成情况:解题思路:参考代码:__378有序矩阵中第K小的元素__直接排序__378有序矩阵中第K小的元素__归并排序__378有序矩阵中第K小的元素__二分查找 原题链接: 378. 有序矩阵中…...
)
商品首页(sass+git本地初始化)
目录 安装sass/sass-loader 首页(vue-setup) 使用git本地提交 同步远程git库 安装sass/sass-loader #安装sass npm i sass -D#安装sass-loader npm i sass-loader10.1.1 -D 首页(vue-setup) <template><view class"u-wrap"><!-- 轮播图 --><…...
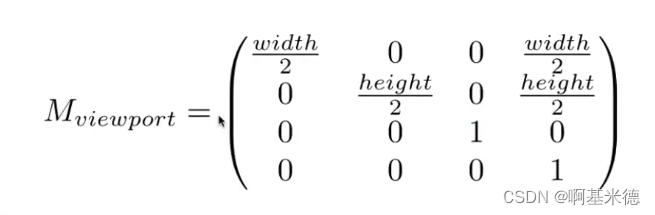
Games101学习笔记 - MVP矩阵
MV矩阵(模型视图变换) 目的,把摄像机通过变换移动的世界坐标远点,并且朝向与Z轴的负方向相同。这个变换就是模型试图变换。 因为移动了相机,如果想保持正确的渲染的话,那么对应的物体需要要和相机保持相对…...
)
实测对比:xenomai 3.1与VxWorks 7在Cortex-A15平台上的实时性能差异(附Jitter数据)
Xenomai 3.1与VxWorks 7实时性能深度评测:Cortex-A15平台实测数据全解析 在工业控制、航空航天、医疗设备等对实时性要求极高的领域,操作系统的响应确定性往往直接决定系统成败。今天我们将基于双核Cortex-A15硬件平台,通过超过7200万次采样数…...

避坑指南:Qt5.14.2在Jetson Nano上交叉编译OpenGL ES2的完整流程与常见错误修复
Jetson Nano上Qt5.14.2交叉编译实战:OpenGL ES2避坑全攻略 在嵌入式开发领域,将Qt应用程序部署到ARM架构设备上一直是个充满挑战的任务。当项目需要图形加速支持时,OpenGL ES模块的引入会让这个过程的复杂度呈指数级上升。Jetson Nano作为一款…...

Matchering 的未来发展:音频AI技术的前景与挑战
Matchering 的未来发展:音频AI技术的前景与挑战 【免费下载链接】matchering 🎚️ Open Source Audio Matching and Mastering 项目地址: https://gitcode.com/gh_mirrors/ma/matchering Matchering 作为一款开源音频匹配与母带处理工具ÿ…...

Alpamayo-R1-10B保姆级教学:WebUI中Trajectory Visualization坐标系解读
Alpamayo-R1-10B保姆级教学:WebUI中Trajectory Visualization坐标系解读 1. 引言:从鸟瞰图到方向盘,看懂自动驾驶的“导航地图” 当你第一次打开Alpamayo-R1-10B的WebUI,点击“开始推理”后,最吸引眼球的可能就是右侧…...

5步搞定Gemma-3-12B-IT:无需代码基础,快速搭建AI对话平台
5步搞定Gemma-3-12B-IT:无需代码基础,快速搭建AI对话平台 1. 为什么选择Gemma-3-12B-IT? Gemma-3-12B-IT是Google最新推出的开源大语言模型,特别适合想要快速搭建AI对话平台的用户。相比前代版本,它在三个方面有明显…...

GLM-4.7-Flash从部署到应用:完整实战案例,助你效率翻倍
GLM-4.7-Flash从部署到应用:完整实战案例,助你效率翻倍 1. 为什么选择GLM-4.7-Flash 在当今AI大模型百花齐放的时代,GLM-4.7-Flash凭借其独特的优势脱颖而出。作为智谱AI推出的最新一代大语言模型,它采用了创新的MoE(…...

DAMOYOLO-S模型效果对比展示:YOLOv8、YOLOv11性能横评
DAMOYOLO-S模型效果对比展示:YOLOv8、YOLOv11性能横评 最近在目标检测圈子里,DAMOYOLO-S这个名字被讨论得挺多的。它作为YOLO家族的一个新成员,主打的就是一个“又快又准”。但光听宣传没用,是骡子是马得拉出来遛遛。正好&#x…...
)
tinyalsa(0)
先给你一个完整配置 采样率(rate) 48000 声道数(channels) 2(左右声道) 采样格式 16bit(2字节) period_size 480 period_count 4一、先从“声音本…...

量化策略回测必备:一份让TA-Lib的MACD/KDJ与国内行情软件对齐的Python代码库
量化策略回测必备:让TA-Lib的MACD/KDJ与国内行情软件精准对齐的Python实战指南 在量化交易领域,指标计算的细微差异可能导致策略信号的天壤之别。许多开发者发现,使用TA-Lib计算的传统技术指标与国内主流行情软件(如通达信、同花顺…...

QT账号注册踩坑实录:密码要求太奇葩?邮箱验证卡住了?一篇帮你全搞定
QT账号注册全流程避坑指南:从密码设置到邮箱验证的实战解析 第一次接触QT开发环境的新手们,往往会在注册环节遇到各种意想不到的障碍。我清楚地记得自己当初注册QT账号时,反复尝试了五次密码才符合要求,邮箱验证邮件等了半小时都…...