Kubernetes 调度约束(亲和性、污点、容忍)
目录
一、Pod启动典型创建过程
二、调度流程
三、指定调度节点
1.使用nodeName字段指定调度节点
2.使用nodeSelector指定调度节点
2.1给对应的node节点添加标签
2.2修改为nodeSelector调度方式
3.通过亲和性来指定调度节点
3.1节点亲和性
3.2Pod亲和性与反亲和性
3.2.1使用Pod亲和性调度
3.2.2使用Pod反亲和性调度
4.使用污点(Taint) 和 容忍(Tolerations)指定调度节点
4.1污点(Taint)
4.2容忍(Tolerations)
四、cordon 和 drain
五、Pod详解
1.Pod启动阶段(相位 phase)
2. Pod常见状态
3. 如何删除 Unknown 状态的 Pod ?
4. 故障排除步骤
一、Pod启动典型创建过程
Kubernetes 是通过 List-Watch 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。
用户是通过 kubectl 根据配置文件,向 APIServer 发送命令,在 Node 节点上面建立 Pod 和 Container。
APIServer 经过 API 调用,权限控制,调用资源和存储资源的过程,实际上还没有真正开始部署应用。这里 需要 Controller Manager、Scheduler 和 kubelet 的协助才能完成整个部署过程。
在 Kubernetes 中,所有部署的信息都会写到 etcd 中保存。实际上 etcd 在存储部署信息的时候,会发送 Create 事件给 APIServer,而 APIServer 会通过监听(Watch)etcd 发过来的事件。其他组件也会监听(Watch)APIServer 发出来的事件。

Pod 是 Kubernetes 的基础单元,Pod 启动典型创建过程如下:
- 这里有三个 List-Watch,分别是 Controller Manager(运行在 Master),Scheduler(运行在 Master),kubelet(运行在 Node)。 他们在进程已启动就会监听(Watch)APIServer 发出来的事件。
- 用户通过 kubectl 或其他 API 客户端提交请求给 APIServer 来建立一个 Pod 对象副本。
- APIServer 尝试着将 Pod 对象的相关元信息存入 etcd 中,待写入操作执行完成,APIServer 即会返回确认信息至客户端。
- 当 etcd 接受创建 Pod 信息以后,会发送一个 Create 事件给 APIServer。
- 由于 Controller Manager 一直在监听(Watch,通过https的6443端口)APIServer 中的事件。此时 APIServer 接受到了 Create 事件,又会发送给 Controller Manager。
- Controller Manager 在接到 Create 事件以后,调用其中的 Replication Controller 来保证 Node 上面需要创建的副本数量。一旦副本数量少于 RC 中定义的数量,RC 会自动创建副本。总之它是保证副本数量的 Controller(PS:扩容缩容的担当)。
- 在 Controller Manager 创建 Pod 副本以后,APIServer 会在 etcd 中记录这个 Pod 的详细信息。例如 Pod 的副本数,Container 的内容是什么。
- 同样的 etcd 会将创建 Pod 的信息通过事件发送给 APIServer。
- 由于 Scheduler 在监听(Watch)APIServer,并且它在系统中起到了“承上启下”的作用,“承上”是指它负责接收创建的 Pod 事件,为其安排 Node;“启下”是指安置工作完成后,Node 上的 kubelet 进程会接管后继工作,负责 Pod 生命周期中的“下半生”。 换句话说,Scheduler 的作用是将待调度的 Pod 按照调度算法和策略绑定到集群中 Node 上。
- Scheduler 调度完毕以后会更新 Pod 的信息,此时的信息更加丰富了。除了知道 Pod 的副本数量,副本内容。还知道部署到哪个 Node 上面了。并将上面的 Pod 信息更新至 API Server,由 APIServer 更新至 etcd 中,保存起来。
- etcd 将更新成功的事件发送给 APIServer,APIServer 也开始反映此 Pod 对象的调度结果。
- kubelet 是在 Node 上面运行的进程,它也通过 List-Watch 的方式监听(Watch,通过https的6443端口)APIServer 发送的 Pod 更新的事件。kubelet 会尝试在当前节点上调用 Docker 启动容器,并将 Pod 以及容器的结果状态回送至 APIServer。
- APIServer 将 Pod 状态信息存入 etcd 中。在 etcd 确认写入操作成功完成后,APIServer将确认信息发送至相关的 kubelet,事件将通过它被接受。
#注意:在创建 Pod 的工作就已经完成了后,为什么 kubelet 还要一直监听呢?原因很简单,假设这个时候 kubectl 发命令,要扩充 Pod 副本数量,那么上面的流程又会触发一遍,kubelet 会根据最新的 Pod 的部署情况调整 Node 的资源。又或者 Pod 副本数量没有发生变化,但是其中的镜像文件升级了,kubelet 也会自动获取最新的镜像文件并且加载。
二、调度流程
Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上。其主要考虑的问题如下:
- 公平:如何保证每个节点都能被分配资源
- 资源高效利用:集群所有资源最大化被使用
- 效率:调度的性能要好,能够尽快地对大批量的 pod 完成调度工作
- 灵活:允许用户根据自己的需求控制调度的逻辑
Sheduler 是作为单独的程序运行的,启动之后会一直监听 APIServer,获取 spec.nodeName 为空的 pod,对每个 pod 都会创建一个 binding,表明该 pod 应该放到哪个节点上。
调度分为几个部分:首先是过滤掉不满足条件的节点,这个过程称为预算策略(predicate);然后对通过的节点按照优先级排序,这个是优选策略(priorities);最后从中选择优先级最高的节点。如果中间任何一步骤有错误,就直接返回错误。
Predicate 有一系列的常见的算法可以使用:
- PodFitsResources:节点上剩余的资源是否大于 pod 请求的资源。
- PodFitsHost:如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配。
- PodFitsHostPorts:节点上已经使用的 port 是否和 pod 申请的 port 冲突。
- PodSelectorMatches:过滤掉和 pod 指定的 label 不匹配的节点。
- NoDiskConflict:已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非它们都是只读。
如果在 predicate 过程中没有合适的节点,pod 会一直在 pending 状态,不断重试调度,直到有节点满足条件。 经过这个步骤,如果有多个节点满足条件,就继续 priorities 过程:按照优先级大小对节点排序。
优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。有一系列的常见的优先级选项包括:
- LeastRequestedPriority:通过计算CPU和Memory的使用率来决定权重,使用率越低权重越高。也就是说,这个优先级指标倾向于资源使用比例更低的节点。
- BalancedResourceAllocation:节点上 CPU 和 Memory 使用率越接近,权重越高。这个一般和上面的一起使用,不单独使用。比如 node01 的 CPU 和 Memory 使用率 20:60,node02 的 CPU 和 Memory 使用率 50:50,虽然 node01 的总使用率比 node02 低,但 node02 的 CPU 和 Memory 使用率更接近,从而调度时会优选 node02。
- ImageLocalityPriority:倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高。
通过算法对所有的优先级项目和权重进行计算,得出最终的结果。
三、指定调度节点
1.使用nodeName字段指定调度节点
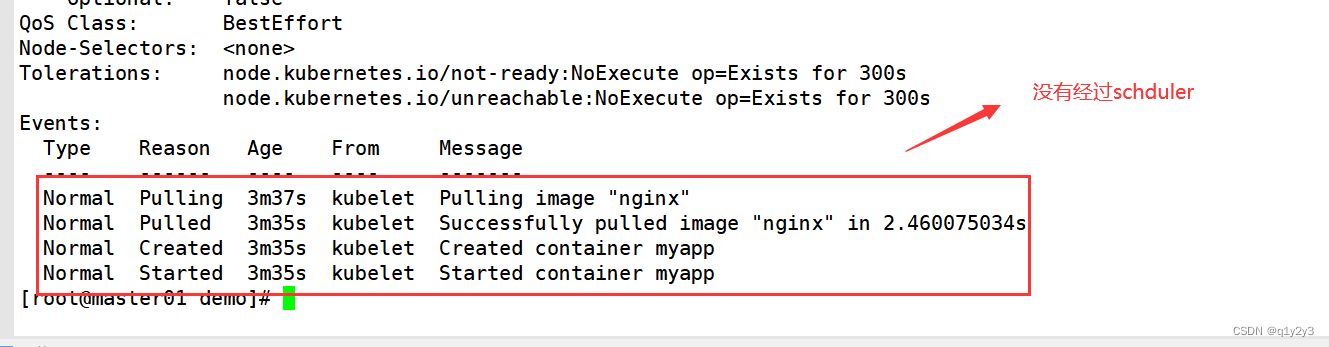
nodeName 将 Pod 直接调度到指定的 Node 节点上,会跳过 Scheduler 的调度策略,该匹配规则是强制匹配
apiVersion: apps/v1
kind: Deployment #创建deployment控制器
metadata:name: myapp #deployment控制器名称:myapp
spec: #定义模板文件replicas: 3 #副本集为3个selector: #标签选择器matchLabels: #匹配的标签为 app: myapp1app: myapp1template: #定义pod模板metadata:labels: #pod的标签app: myapp1spec: nodeName: node01 #pod创建后所在的node节点名称containers: #定义pod中的容器- name: myapp #pod容器中的名称image: nginx #容器使用的镜像ports: - containerPort: 80kubectl apply -f demo1.yamlkubectl get pods --show-labels -owide
#查看详细事件(发现未经过 scheduler 调度分配)
kubectl describe pod myapp-6bc58d7775-6wlpp

2.使用nodeSelector指定调度节点
通过 kubernetes 的 label-selector 机制选择节点,由调度器调度策略匹配 label,然后调度 Pod 到目标节点,该匹配规则属于强制约束
2.1给对应的node节点添加标签
kubectl label nodes node01 app=akubectl label nodes node02 app=b#查看标签
kubectl get nodes --show-labels注:
#修改一个 label 的值,需要加上 --overwrite 参数
kubectl label nodes node02 app=a --overwrite#删除一个 label,只需在命令行最后指定 label 的 key 名并与一个减号相连即可:
kubectl label nodes node02 app-
或
kubectl label nodes node02 app=b-#指定标签查询 node 节点
kubectl get node -l app=a
2.2修改为nodeSelector调度方式
vim myapp1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp1
spec:replicas: 3selector:matchLabels:run: myapp1template:metadata:labels:run: myapp1spec:nodeSelector:app: acontainers:- name: myapp1image: nginx:1.14ports:- containerPort: 80kubectl apply -f myapp1.yaml
kubectl get pods -owide
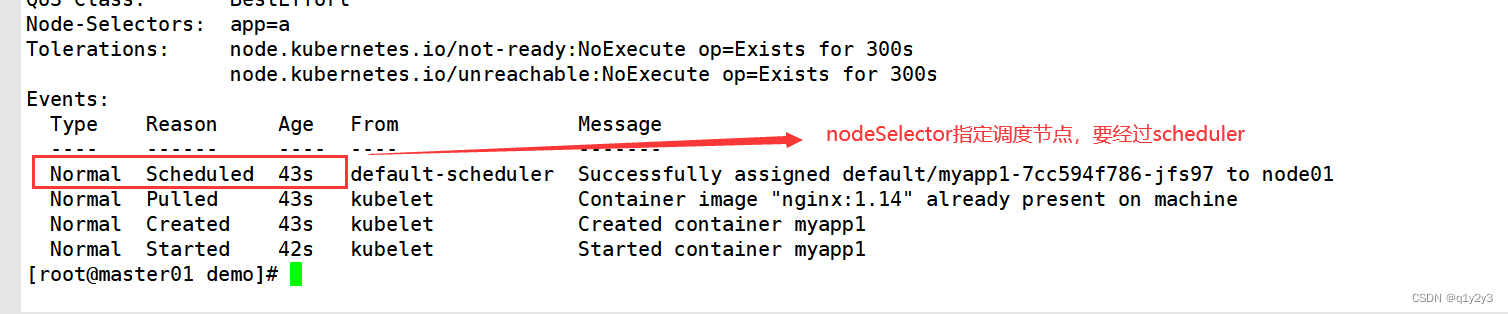
#查看详细事件(通过事件可以发现要先经过 scheduler 调度分配)
kubectl describe pod myapp1-7cc594f786-jfs97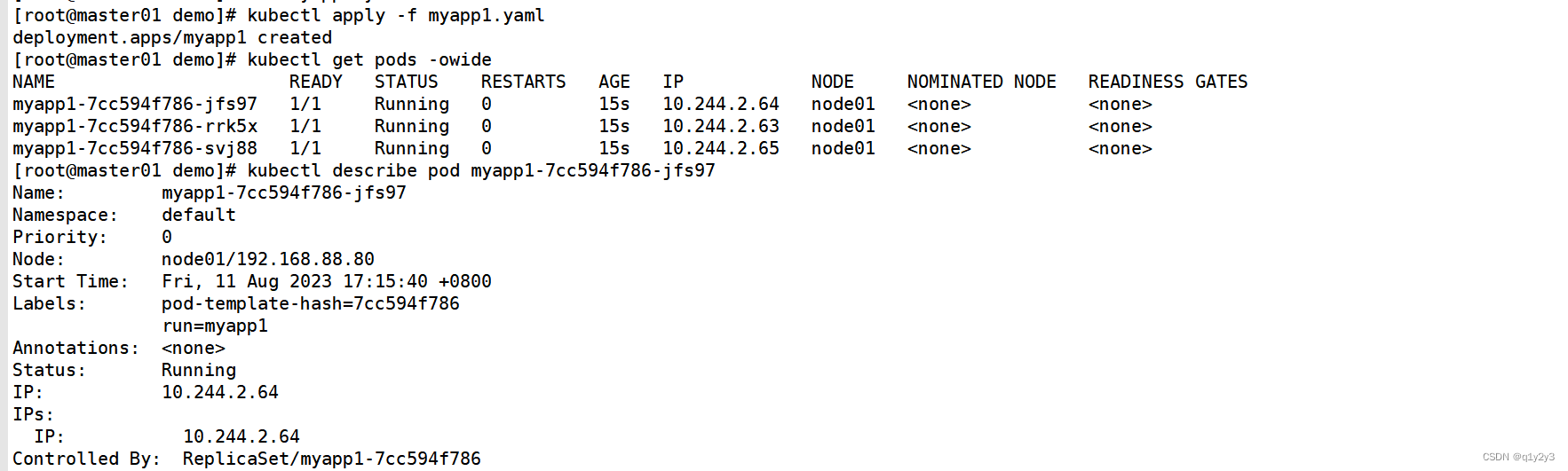
3.通过亲和性来指定调度节点
将 Pod 指派给节点 | Kubernetes
3.1节点亲和性
pod.spec.nodeAffinity
- preferredDuringSchedulingIgnoredDuringExecution:软策略
- requiredDuringSchedulingIgnoredDuringExecution:硬策略
注:
- 硬策略就是Pod必须要去指定条件的node节点,不去不行
- 软策略表示Pod最优先去指定node节点,如果没有符合条件的node节点,也可以选择其它node节点
键值运算关系
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
nodeAffinity硬策略和软策略示例
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution: #先满足硬策略,排除有kubernetes.io/hostname=node02标签的节点nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: NotInvalues:- node02preferredDuringSchedulingIgnoredDuringExecution: #再满足软策略,优先选择有app=a标签的节点- weight: 1 #如果有多个软策略,权重越大,优先级越大preference:matchExpressions:- key: appoperator: Invalues:- a只有硬策略的情况下,如果硬策略不满足条件,Pod 状态一直会处于 Pending 状态。
如果把硬策略和软策略合在一起使用,则要先满足硬策略之后才会满足软策略
3.2Pod亲和性与反亲和性
pod.spec.affinity.podAffinity/podAntiAffinity
- preferredDuringSchedulingIgnoredDuringExecution:软策略
- requiredDuringSchedulingIgnoredDuringExecution:硬策略
| 调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 |
| nodeAffinity | 主机 | In, NotIn, Exists,DoesNotExist, Gt, Lt | 否 | 指定主机 |
| podAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | Pod与指定Pod同一拓扑域 |
| podAntiAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | Pod与指定Pod不在同一拓扑域 |
3.2.1使用Pod亲和性调度
apiVersion: v1
kind: Pod
metadata:name: myapplabels: #定义该Pod的标签app: myapp
spec:containers:- name: myapp01image: nginxaffinity:podAffinity: #定义pod亲和性requiredDuringSchedulingIgnoredDuringExecution: #pod亲和性的硬策略- labelSelector: #定义硬策略标签选择器的信息matchExpressions: #定义标签选择器选择的信息- key: app #定义键名operator: In #定义键值之间的运算关系values: #定义键值- myapptopologyKey: run #定义节点标签的键,判断是否在同一拓扑域中topologykey: run表示如果node节点都包含有标签为run=键值,
当node节点的键值相同时,则表示node节点在同一拓扑域中;
当run键的值不相同时,则表示node节点不在同一拓扑域中。注:
- 仅当节点上至少包含一个已运行且 app=myapp 的标签 的 Pod 处于拓扑域 a 时,才可以将该 Pod 调度到拓扑域 a 上的节点。 (更确切的说,新建pod分配node节点,会选择有标签为app=myapp的pod运行的node节点或该node节点所处拓扑域上其它node节点。)
- topologyKey 是节点标签的键。如果两个节点使用此键标记并且具有相同的标签值,则调度器会将这两个节点视为处于同一拓扑域中。 调度器试图在每个拓扑域中放置数量均衡的 Pod。
- 如果 app 对应的值不一样就是不同的拓扑域。比如 Pod1 在 app=a 的 Node 上,Pod2 在 app=b 的 Node 上,Pod3 在 app=a 的 Node 上,则 Pod2 和 Pod1、Pod3 不在同一个拓扑域,而Pod1 和 Pod3在同一个拓扑域。
3.2.2使用Pod反亲和性调度
apiVersion: v1
kind: Pod
metadata:name: myapplabels:app: myapp
spec:containers:- name: myappimage: nginxaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- atopologyKey: run如果节点处于 Pod 所在的同一拓扑域且具有键“app”和值“a”的标签, 则该 pod 不能将其调度到该节点上。
(如果 topologyKey 为 run,则意味着当节点和具有键 “app”和值“a”的 Pod 处于相同的拓扑域,Pod 不能被调度到该节点上。)4.使用污点(Taint) 和 容忍(Tolerations)指定调度节点
4.1污点(Taint)
节点亲和性,是Pod的一种属性(偏好或硬性要求),它使Pod被吸引到一类特定的节点。Taint 则相反,它使节点能够排斥一类特定的 Pod。
Taint 和 Toleration 相互配合,可以用来避免 Pod 被分配到不合适的节点上。每个节点上都可以应用一个或多个 taint ,这表示对于那些不能容忍这些 taint 的 Pod,是不会被该节点接受的。如果将 toleration 应用于 Pod 上,则表示这些 Pod 可以(但不一定)被调度到具有匹配 taint 的节点上。
使用 kubectl taint 命令可以给某个 Node 节点设置污点,Node 被设置上污点之后就和 Pod 之间存在了一种相斥的关系,可以让 Node 拒绝 Pod 的调度执行,甚至将 Node 已经存在的 Pod 驱逐出去。污点的组成格式如下:
key=value:effect每个污点有一个 key 和 value 作为污点的标签,其中 value 可以为空,effect 描述污点的作用。当前 taint effect 支持如下三个选项:
●NoSchedule:表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上
●PreferNoSchedule:表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上
●NoExecute:表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上,同时会将 Node 上已经存在的 Pod 驱逐出去#设置污点
kubectl taint node node01 key1=value1:NoSchedule#节点说明中,查找 Taints 字段
kubectl describe node node01 #去除污点
kubectl taint node node01 key1:NoSchedule-4.2容忍(Tolerations)
设置了污点的 Node 将根据 taint 的 effect:NoSchedule、PreferNoSchedule、NoExecute 和 Pod 之间产生互斥的关系,Pod 将在一定程度上不会被调度到 Node 上。但我们可以在 Pod 上设置容忍(Tolerations),意思是设置了容忍的 Pod 将可以容忍污点的存在,可以被调度到存在污点的 Node 上。
apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1tolerations:- key: "check" #定义污点键名operator: "Equal" value: "mycheck" #定义污点键值effect: "NoExecute" #定义污点的作用tolerationSeconds: 3600#其中的 key、vaule、effect 都要与 Node 上设置的 taint 保持一致
#operator 的值为 Exists 将会忽略 value 值,即存在即可
#tolerationSeconds 用于描述当 Pod 需要被驱逐时可以在 Node 上继续保留运行的时间
注意事项:
(1)当不指定 key 值时,表示容忍所有的污点 keytolerations:- operator: "Exists"(2)当不指定 effect 值时,表示容忍所有的污点作用tolerations:- key: "key"operator: "Exists"(3)有多个 Master 存在时,防止资源浪费,可以如下设置
kubectl taint node Master-Name node-role.kubernetes.io/master=:PreferNoSchedule//如果某个 Node 更新升级系统组件,为了防止业务长时间中断,可以先在该 Node 设置 NoExecute 污点,把该 Node 上的 Pod 都驱逐出去
kubectl taint node node01 check=mycheck:NoExecute//此时如果别的 Node 资源不够用,可临时给 Master 设置 PreferNoSchedule 污点,让 Pod 可在 Master 上临时创建
kubectl taint node master node-role.kubernetes.io/master=:PreferNoSchedule//待所有 Node 的更新操作都完成后,再去除污点
kubectl taint node node01 check=mycheck:NoExecute-四、cordon 和 drain
对节点执行维护操作:
kubectl get nodes//将 Node 标记为不可调度的状态,这样就不会让新创建的 Pod 在此 Node 上运行
kubectl cordon <NODE_NAME> #该node将会变为SchedulingDisabled状态//kubectl drain 可以让 Node 节点开始释放所有 pod,并且不接收新的 pod 进程。drain 本意排水,意思是将出问题的 Node 下的 Pod 转移到其它 Node 下运行
kubectl drain <NODE_NAME> --ignore-daemonsets --delete-emptydir-data --force--ignore-daemonsets:无视 DaemonSet 管理下的 Pod。
--delete-emptydir-data:如果有 mount local volume 的 pod,会强制杀掉该 pod。
--force:强制释放不是控制器管理的 Pod。注:执行 drain 命令,会自动做了两件事情:
(1)设定此 node 为不可调度状态(cordon)
(2)evict(驱逐)了 Pod//kubectl uncordon 将 Node 标记为可调度的状态
kubectl uncordon <NODE_NAME>
五、Pod详解
1.Pod启动阶段(相位 phase)
Pod 创建完之后,一直到持久运行起来,中间有很多步骤,也就有很多出错的可能,因此会有很多不同的状态。
一般来说,pod 这个过程包含以下几个步骤:
- 调度到某台 node 上。kubernetes 根据一定的优先级算法选择一台 node 节点将其作为 Pod 运行的 node
- 拉取镜像
- 挂载存储配置等
- 容器运行起来。如果有健康检查,会根据检查的结果来设置其状态。
2. Pod常见状态
- Pending:表示APIServer创建了Pod资源对象并已经存入了etcd中,但是它并未被调度完成(比如还没有调度到某台node上),或者仍然处于从仓库下载镜像的过程中。
- Running:Pod已经被调度到某节点之上,并且Pod中所有容器都已经被kubelet创建。至少有一个容器正在运行,或者正处于启动或者重启状态(也就是说Running状态下的Pod不一定能被正常访问)。
- Succeeded:有些pod不是长久运行的,比如job、cronjob,一段时间后Pod中的所有容器都被成功终止,并且不会再重启。需要反馈任务执行的结果。
- Failed:Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止,比如 command 写的有问题。
- Unknown:表示无法读取 Pod 状态,通常是 kube-controller-manager 无法与 Pod 通信。Pod 所在的 Node 出了问题或失联,从而导致 Pod 的状态为 Unknow
3. 如何删除 Unknown 状态的 Pod ?
- 从集群中删除有问题的 Node。使用公有云时,kube-controller-manager 会在 VM 删除后自动删除对应的 Node。 而在物理机部署的集群中,需要管理员手动删除 Node(kubectl delete node <node_name>)。
- 被动等待 Node 恢复正常,Kubelet 会重新跟 kube-apiserver 通信确认这些 Pod 的期待状态,进而再决定删除或者继续运行这些 Pod。
- 主动删除 Pod,通过执行 kubectl delete pod <pod_name> --grace-period=0 --force 强制删除 Pod。但是这里需要注意的是,除非明确知道 Pod 的确处于停止状态(比如 Node 所在 VM 或物理机已经关机),否则不建议使用该方法。特别是 StatefulSet 管理的 Pod,强制删除容易导致脑裂或者数据丢失等问题。
4. 故障排除步骤
//查看Pod事件
kubectl describe TYPE NAME_PREFIX //查看Pod日志(Failed状态下)
kubectl logs <POD_NAME> [-c Container_NAME]//进入Pod(状态为running,但是服务没有提供)
kubectl exec –it <POD_NAME> bash//查看集群信息
kubectl get nodes//发现集群状态正常
kubectl cluster-info//查看kubelet日志发现
journalctl -xefu kubelet相关文章:
Kubernetes 调度约束(亲和性、污点、容忍)
目录 一、Pod启动典型创建过程 二、调度流程 三、指定调度节点 1.使用nodeName字段指定调度节点 2.使用nodeSelector指定调度节点 2.1给对应的node节点添加标签 2.2修改为nodeSelector调度方式 3.通过亲和性来指定调度节点 3.1节点亲和性 3.2Pod亲和性与反亲和性 3.2…...
按轨迹运行
文章目录 import math import timeimport numpy as np import matplotlib.pyplot as pltdef plot_arrow(x, y, yaw, length=5, width=1):dx = length * math.cos(yaw)dy = length * math.sin(yaw)plt.arrow(x, y, dx, dy, head_length=width, head_width=width)plt.plot([x, x …...
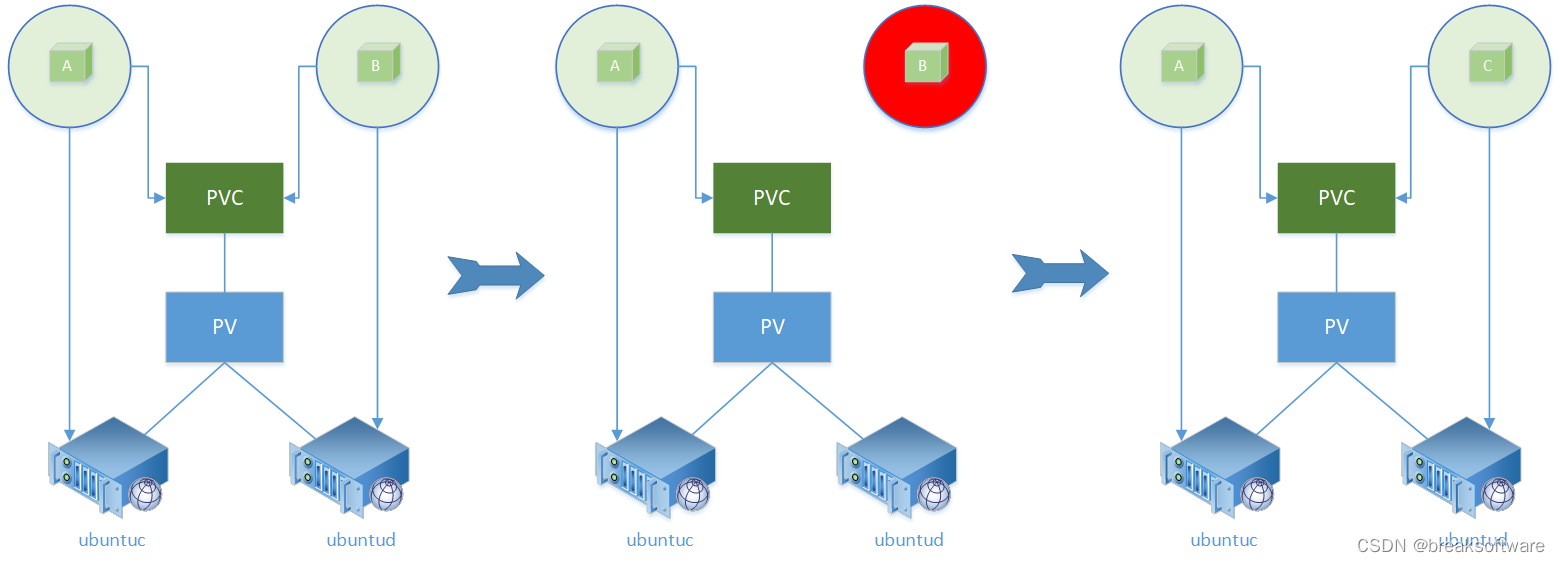
研发工程师玩转Kubernetes——通过PV的节点亲和性影响Pod部署
在《研发工程师玩转Kubernetes——PVC通过storageClassName进行延迟绑定》一文中,我们利用Node亲和性,让Pod部署在节点ubuntud上。因为Pod使用的PVC可以部署在节点ubuntuc或者ubuntud上,而系统为了让Pod可以部署成功,则让PVC与Pod…...
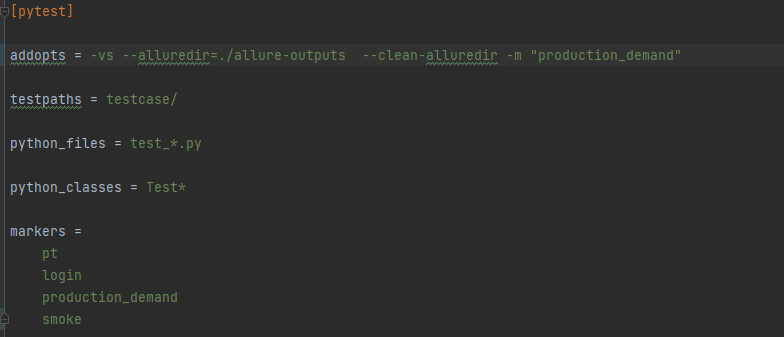
Pytest三种运行方式
Pytest 运行方式共有三种: 1、主函数模式 运行所有 pytest.main() 指定模块 pytest.main([-vs],,./testcase/test_day1.py) 只运行testcase 下的test_day1.py 文件 指定目录 pytest.main([-vs]),./testcase) 只运行testcase 目录下的文件 通过nodeid指定用例…...
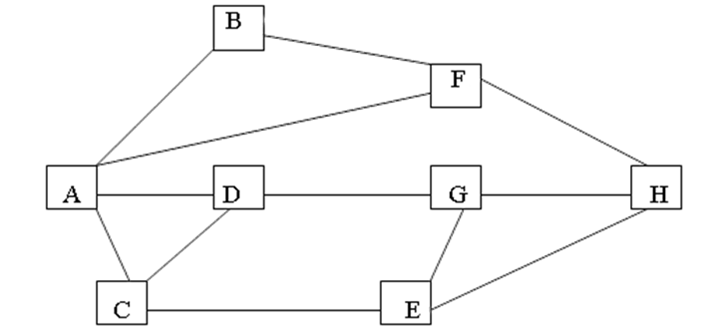
城市最短路
题目描述 下图表示的是从城市A到城市H的交通图。从图中可以看出,从城市A到城市H要经过若干个城市。现要找出一条经过城市最少的一条路线。 输入输出格式 输入格式: 无 输出格式: 倒序输出经过城市最少的一条路线 输入输出样例 输入样例…...
phpspreadsheet excel导入导出
单个sheet页Excel2003版最大行数是65536行。Excel2007开始的版本最大行数是1048576行。Excel2003的最大列数是256列,2007以上版本是16384列。 xlswriter xlswriter - PHP 高性能 Excel 扩展,功能类似phpspreadsheet。它能够处理非常大的文件࿰…...

自动驾驶传感器选型
360的场景,避免有盲区,长距离 Lidar(激光雷达) 典型特点一圈一圈的,轮廓和很高的位置精度 禾赛的机械雷达 速腾的固态雷达 固态雷达是车规级的,车规级的意思是可以装到量产车上 Radar(毫米…...
)
4.利用matlab符号矩阵的四则运算(matlab程序)
1.简述 符号对象的建立 sym函数 sym函数用于建立单个符号对象,其常用调用格式为: 符号对象名sym(A) 1 将由A来建立符号对象,其中,A可以是一个数值常量、数值矩阵或数值表达式(不加单引号),此时符号对象为一个符号常量;…...
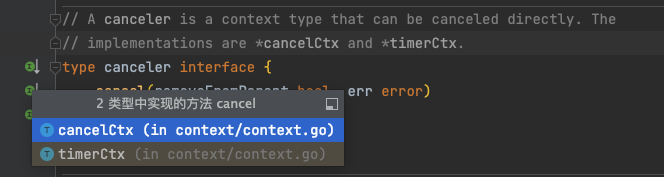
Go context.WithCancel()的使用
WithCancel可以将一个Context包装为cancelCtx,并提供一个取消函数,调用这个取消函数,可以Cancel对应的Context Go语言context包-cancelCtx 疑问 context.WithCancel()取消机制的理解 父母5s钟后出门,倒计时,父母在时要学习,父母一走就可以玩 …...

STM32 F103C8T6学习笔记6:IIC通信__驱动MPU6050 6轴运动处理组件—一阶互补滤波
今日主要学习一款倾角传感器——MPU6050,往后对单片机原理基础讲的会比较少,更倾向于简单粗暴地贴代码,因为经过前些日子对MSP432的学习,对原理方面也有些熟络了,除了在新接触它时会对其引脚、时钟、总线等进行仔细一些的研究之外…...

Ubantu安装Docker(完整详细)
先在官网上查看对应的版本:官网 然后根据官方文档一步一步跟着操作即可 必要准备 要成功安装Docker Desktop,必须: 满足系统要求 拥有64位版本的Ubuntu Jammy Jellyfish 22.04(LTS)或Ubuntu Impish Indri 21.10。 Docker Deskto…...

【从零开始学习JAVA | 第四十一篇】深入JAVA锁机制
目录 前言: 引入: 锁机制: CAS算法: 乐观锁与悲观锁: 总结: 前言: 在多线程编程中,线程之间的协作和资源共享是一个重要的话题。当多个线程同时操作共享数…...
Playable 动画系统
Playable 基本用法 Playable意思是可播放的,可运行的。Playable整体是树形结构,PlayableGraph相当于一个容器,所有元素都被包含在里面,图中的每个节点都是Playable,叶子节点的Playable包裹原始数据,相当于输…...

深入理解Linux内核--虚拟文件
虚拟文件系统(VFS)的作用 虚拟文件系统(Virtual Filesystem)也可以称之为虚拟文件系统转换(Virtual Filesystem Switch,VFS), 是一个内核软件层, 用来处理与Unix标准文件系统相关的所有系统调用。 其健壮性表现在能为各种文件系统提供一个通用的接口。VFS支持的文件…...

记一次 .NET 某外贸ERP 内存暴涨分析
一:背景 1. 讲故事 上周有位朋友找到我,说他的 API 被多次调用后出现了内存暴涨,让我帮忙看下是怎么回事?看样子是有些担心,但也不是特别担心,那既然找到我,就给他分析一下吧。 二࿱…...
关于安卓打包生成aar,jar实现(一)
关于安卓打包生成aar,jar方式 背景 在开发的过程中,主项目引入三方功能的方式有很多,主要是以下几个方面: (1)直接引入源代码module(优点:方便修改源码,易于维护&#…...

QString字符串与16进制QByteArray的转化,QByteArray16进制数字组合拼接,Qt16进制与10进制的转化
文章目录 QString转16进制QByteArry16进制QByteArray转QStringQByteArray16进制数拼接Qt16进制与10进制的转化在串口通信中,常常使用QByetArray储存数据,QByteArray可以看成字节数组,每个索引位置储存一个字节也就是8位的数据,可以储存两位16进制数,可以用uint8取其中的数…...
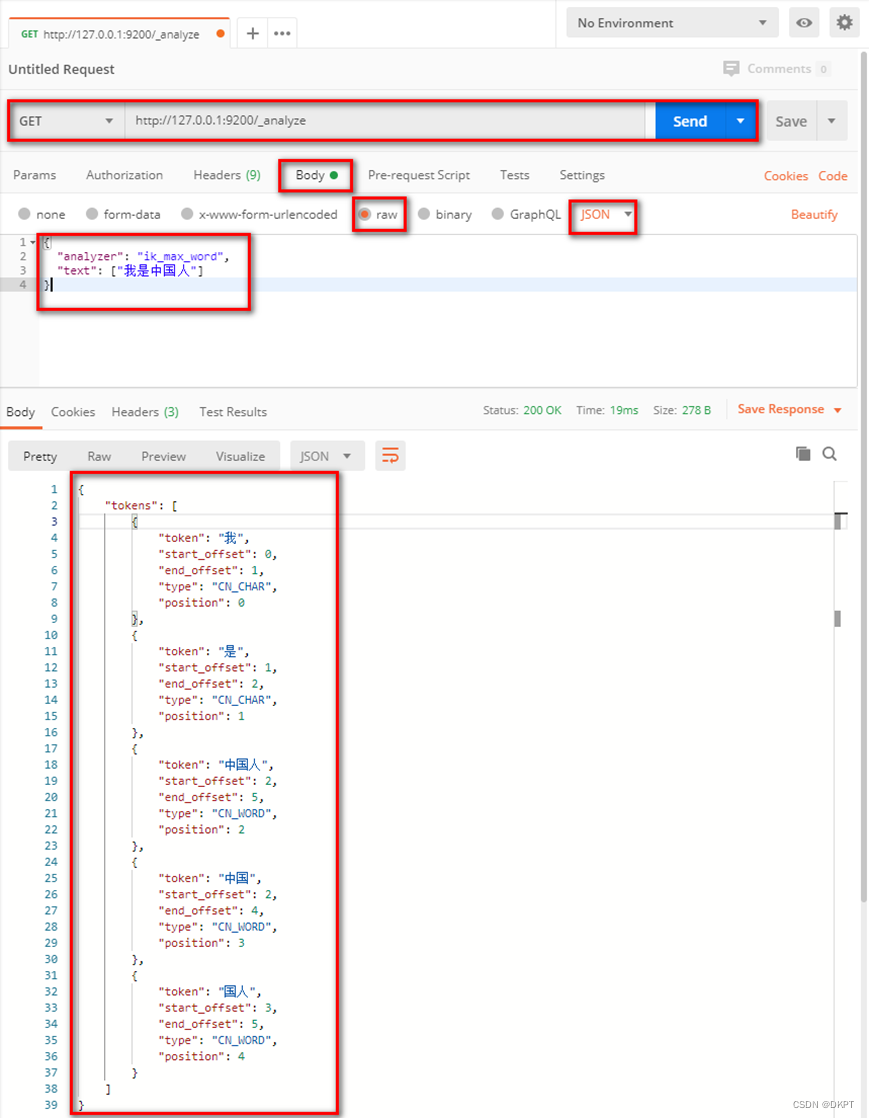
ElasticSearch安装与启动
ElasticSearch安装与启动 【服务端安装】 1.1、下载ES压缩包 目前ElasticSearch最新的版本是7.6.2(截止2020.4.1),我们选择6.8.1版本,建议使用JDK1.8及以上。 ElasticSearch分为Linux和Window版本,基于我们主要学习…...
JavaWeb中Json传参的条件
JavaWeb中我们常用json进行参数传递 对应的注释为RequestBody 但是json传参是有条件的 最主要是你指定的实体类和对应的json参数能否匹配 1.属性和对应的json参数名称对应 2.对应实体类实现了Serializable接口,可以进行序列化和反序列化,这个才是实体类转…...

包装类+初识泛型
目录 1 .包装类 1.1 基本数据类型对应的包装类 1.2.1装箱 1.2.2拆箱 2.初识泛型 2.1什么是泛型 2.2泛型类 2.3裸类型 2.4泛型的上界 2.5泛型方法 1 .包装类 基本数据类型所对应的类类型 在 Java 中,由于基本类型不是继承自 Object ,为了在泛型…...

如何快速融入Kolors开源社区:完整贡献指南与技术支持体系
如何快速融入Kolors开源社区:完整贡献指南与技术支持体系 【免费下载链接】Kolors Kolors Team 项目地址: https://gitcode.com/gh_mirrors/ko/Kolors Kolors是由快手Kolors团队开发的大规模文本到图像生成模型,基于潜在扩散技术,在数…...

从理论到实践:一维与二维水污染扩散模型的在线模拟与代码实现
1. 水污染扩散模型的基础原理 第一次接触水污染扩散模型时,我也被那些专业术语搞得一头雾水。后来在实际项目中反复应用才发现,理解这些原理其实就像理解咖啡在杯子里扩散一样简单。想象一下,当你把一勺糖倒入咖啡中,糖分是如何逐…...

SpringBoot 多事务并发控制:悲观锁与乐观锁全面详解
前面我们系统学习了 SpringBoot 声明式事务(Transactional)、编程式事务(TransactionTem)plate)、事务传播行为、隔离级别以及事务失效的全套解决方案,核心解决的是「单个业务、单次请求」的事务原子性、一致性问题。但…...

终极Minecraft启动器指南:UltimMC让你的游戏体验更自由
终极Minecraft启动器指南:UltimMC让你的游戏体验更自由 【免费下载链接】Launcher Offline Minecraft launcher. 项目地址: https://gitcode.com/gh_mirrors/lau/Launcher UltimMC是一款功能强大的Minecraft自定义启动器,专为追求自由灵活游戏体验…...

03 原创AI大模型开源:华夏之光永存:华夏本源大模型——合规数据集处理与标准化训练方案
华夏之光永存:华夏本源大模型——合规数据集处理与标准化训练方案 一、本篇核心定位 本篇承接第二篇架构设计,全流程放出合规数据处理模型训练硬核实操内容,所有流程、参数、脚本逻辑均为可直接落地、可复现的开源干货,完全匹配7B…...

【脚本安装】十分钟配置Claude Code:终端里的AI编程搭档
十分钟上手Claude Code:终端里的AI编程搭档从零开始配置属于你自己的AI编程助手,让代码审查、批量修改、技术问答都在命令行里搞定。为什么写这篇 最近折腾了不少AI编程工具,Claude Code给我的体验最接近「搭档」这个词——不是那种被动等指令…...

告别默认路径:Rust环境自定义安装与MinGW配置实战
1. 为什么需要自定义Rust安装路径? 每次重装系统后都要重新配置开发环境,这可能是很多Windows开发者最头疼的事情之一。默认情况下,Rust会把自己的工具链安装在C盘的Users目录下,这不仅占用宝贵的系统盘空间,还会在系统…...

别再手动导数据了!用Kettle从API接口自动同步数据到MySQL的保姆级教程
别再手动导数据了!用Kettle从API接口自动同步数据到MySQL的保姆级教程 每周五下午,销售部门的王经理总会准时出现在IT部门门口,手里拿着一份Excel表格:"小李,这是本周CRM系统的新增客户数据,麻烦导入到…...

手把手教你用ROS camera_calibration完成工业相机内参标定
1. 工业相机标定入门指南 刚接触ROS和工业相机的开发者经常会遇到一个实际问题:为什么拍摄的物体图像会出现变形?比如用Flir相机拍摄的棋盘格线条弯曲,或者测量物体尺寸时总有几个毫米的误差。这些问题往往源于相机镜头本身的畸变和成像系统误…...

CRISPR/Cas9实验避坑大全:那些年我们踩过的sgRNA设计、载体构建和药筛的坑
CRISPR/Cas9实验避坑指南:从sgRNA设计到药筛的实战经验 实验室里的CRISPR/Cas9技术就像一把精准的分子剪刀,但实际操作中却常常遇到各种意料之外的"坑"。记得我第一次尝试构建基因敲除细胞系时,花了三个月时间反复优化sgRNA设计&am…...