ES索引重建reindex详解
目录
一、使用场景
二、reindex介绍
三、使用手册
1、覆盖更新
2、创建丢失的文档并更新旧版本的文档
3、仅创建丢失的文档
4、冲突处理
5、source中添加查询条件
6、source中包含多个源索引
7、限制处理的记录数
8、从远程ES集群中重建索引
9、提取随机子集
10、修改字段名称
11、reindex超时情况
四、性能优化
1、提升批量写入大小值
2、提高scroll的并行度
3、ES副本数设置为0
4、增加refresh间隔
5、异步刷新translog
五、查看&取消任务
1、获取reindex任务列表
2、根据任务id查看任务
3、取消任务
一、使用场景
- 分片数变更:当你的数据量过大,而你的索引最初创建的分片数量不足,导致数据入库较慢的情况,此时需要扩大分片的数量,此时可以尝试使用Reindex。
- mapping字段变更:当数据的mapping需要修改,但是大量的数据已经导入到索引中了,重新导入数据到新的索引太耗时;但是在ES中,一个字段的mapping在定义并且导入数据之后是不能再修改的,所以这种情况下也可以考虑尝试使用Reindex。
- 分词规则修改,比如使用了新的分词器或者对分词器自定义词库进行了扩展,而之前保存的数据都是按照旧的分词规则保存的,这时候必须进行索引重建。
二、reindex介绍
官方reindex说明地址
reindex 为 ES 5.X 版本之后提供的数据迁移功能,不需要额外安装,支持同集群索引迁移和跨集群索引迁移。
使用 reindex,要注意两点:
- 要求源端索引的元字段 _source 是打开的,默认就是打开的。
- reindex 过程并不会自动将源端索引的设置拷贝到目标索引,所以需要事先在目标集群(源集群和目标集群可以是同一个集群)中按照源端索引的表结构建立好目标索引。
reindex 适用于迁移数量量和索引数都较小的场景,迁移速度较慢,可在集群性能允许的情况下,通过调大 size 参数值来提升迁移速度,默认 size 大小为 1000。
基础使用命令:
POST _reindex
{"source": {"index": "old_index"},"dest": {"index": "new_index"}
}三、使用手册
1、覆盖更新
说明:"version_type": "internal",internal表示内部的,省略version_type或version_type设置为 internal 将导致 Elasticsearch 盲目地将文档转储到目标中,覆盖任何具有相同类型和 ID 的文件。
这也是最常见的重建方式。
POST _reindex
{"source": {"index": "twitter"},"dest": {"index": "new_twitter","version_type": "internal"}
}2、创建丢失的文档并更新旧版本的文档
说明:"version_type": "external",external表示外部的,将 version_type 设置为 external 将导致 Elasticsearch 保留源中的版本,创建任何丢失的文档,并更新目标索引中版本比源索引中版本旧的任何文档。
id不存在的文档会直接更新;id存在的文档会先判断版本号,只会更新版本号旧的文档。
POST _reindex
{"source": {"index": "twitter"},"dest": {"index": "new_twitter","version_type": "external"}
}3、仅创建丢失的文档
要创建的 op_type 设置将导致 _reindex 仅在目标索引中创建丢失的文档,所有存在的文档都会引起版本冲突。
只要两个索引中存在id相同的记录,就会引起版本冲突。
POST _reindex
{"source": {"index": "twitter"},"dest": {"index": "new_twitter","op_type": "create"}
}4、冲突处理
默认情况下,版本冲突会中止 _reindex 进程。 “冲突”请求正文参数可用于指示 _reindex 继续处理有关版本冲突的下一个文档。 需要注意的是,其他错误类型的处理不受“冲突”参数的影响。
当"conflicts": "proceed"在请求正文中设置时,_reindex 进程将继续处理版本冲突并返回遇到的版本冲突计数。
POST _reindex
{"conflicts": "proceed","source": {"index": "twitter"},"dest": {"index": "new_twitter","op_type": "create"}
}5、source中添加查询条件
POST _reindex
{"source": {"index": "twitter","query": {"term": {"user": "kimchy"}}},"dest": {"index": "new_twitter"}
}6、source中包含多个源索引
源中的索引可以是一个列表,允许您在一个请求中从多个源中复制。 这将从 twitter 和 blog 索引中复制文档:
POST _reindex
{"source": {"index": ["twitter", "blog"]},"dest": {"index": "all_together"}
}也支持*号来匹配多个索引。POST _reindex
{"source": {"index": "twitter*"},"dest": {"index": "all_together"}
}7、限制处理的记录数
通过设置size大小来限制处理文档的数量。
POST _reindex
{"size": 10000,"source": {"index": "twitter","sort": { "date": "desc" }},"dest": {"index": "new_twitter"}
}8、从远程ES集群中重建索引
注意:要保证源索引与目的索引的表结构信息一致,否则可能导致源索引与目的索引字段类型等信息不一致
例如:1、查询出源索引的表结构信息,并根据此表结构提前在目的集群中创建出目的索引2、若源索引有对应的索引模版,可提前将该索引模版在目的集群中创建出
在目的 es 集群中配置上源 es 集群的白名单信息
vim elasticsearch.yml
# 在目的集群的elasticsearch.yml文件中增加源es集群的白名单配置
reindex.remote.whitelist: “otherhost:9200”POST _reindex?wait_for_completion=false
{"source": {"remote": {"host": "http://otherhost:9200","username": "user","password": "password"},"size":5000"index": "source"},"dest": {"index": "dest"}
}9、提取随机子集
说明:从源索引中随机取10条数据到新索引中。
POST _reindex
{"size": 10,"source": {"index": "twitter","query": {"function_score" : {"query" : { "match_all": {} },"random_score" : {}}},"sort": "_score" },"dest": {"index": "random_twitter"}
}10、修改字段名称
原索引
POST test/_doc/1?refresh
{"text": "words words","flag": "foo"
}重建索引,将原索引中的flag字段重命名为tag字段。POST _reindex
{"source": {"index": "test"},"dest": {"index": "test2"},"script": {"source": "ctx._source.tag = ctx._source.remove(\"flag\")"}
}结果:
GET test2/_doc/1
{"found": true,"_id": "1","_index": "test2","_type": "_doc","_version": 1,"_seq_no": 44,"_primary_term": 1,"_source": {"text": "words words","tag": "foo"}
}11、reindex超时情况
es中的请求超时时间默认是1分钟,当重建索引的数据量太大时,经常会出现超时。这种情况可以增大超时时间,也可以添加wait_for_completion=false参数将请求转为异步任务。
POST _reindex?wait_for_completion=false
{"source": {"index": "twitter"},"dest": {"index": "new_twitter"}
}四、性能优化
常规的如果我们只是进行少量的数据迁移利用普通的reindex就可以很好的达到要求,但是当我们发现我们需要迁移的数据量过大时,我们会发现reindex的速度会变得很慢。数据量几十个G的场景下,elasticsearch reindex速度太慢,从旧索引导数据到新索引,当前最佳方案是什么?
原因分析:
reindex的核心做跨索引、跨集群的数据迁移。
慢的原因及优化思路无非包括:
- 批量大小值可能太小。需要结合堆内存、线程池调整大小;
- reindex的底层是scroll实现,借助scroll并行优化方式,提升效率;
- 跨索引、跨集群的核心是写入数据,考虑写入优化角度提升效率。
可行方案:
- 提升批量写入的大小值size
- 通过设置sliced提高写入的并行度
- 提升写入速度,ES副本数设置为0、增加refresh间隔、index.translog.durability设置为async
1、提升批量写入大小值
默认情况下 _reindex 使用 1000 的滚动批次。可以使用源元素source中的 size 字段更改批次大小:
POST _reindex
{"source": {"index": "source","size": 5000},"dest": {"index": "dest"}
}2、提高scroll的并行度
Reindex 支持 Sliced Scroll 来并行化重新索引过程。 这种并行化可以提高效率并提供一种将请求分解为更小的部分的便捷方式。
每个Scroll请求,可以分成多个Slice请求,可以理解为切片,各Slice独立并行,利用Scroll重建或者遍历要快很多倍。
slicing的设定分为两种方式:手动设置分片、自动设置分片。
自动设置分片如下:
POST _reindex?slices=5&refresh
{"source": {"index": "twitter"},"dest": {"index": "new_twitter"}
}slices大小设置注意事项:
1)slices大小的设置可以手动指定,或者设置slices设置为auto,auto的含义是:针对单索引,slices大小=分片数;针对多索引,slices=分片的最小值。
2)当slices的数量等于索引中的分片数量时,查询性能最高效。slices大小大于分片数,非但不会提升效率,反而会增加开销。
3)如果这个slices数字很大(例如500),建议选择一个较低的数字,因为过大的slices 会影响性能。
3、ES副本数设置为0
如果要进行大量批量导入,请考虑通过设置index.number_of_replicas来禁用副本:0。
主要原因在于:
- 复制文档时,将整个文档发送到副本节点,并逐字重复索引过程。 这意味着每个副本都将执行分析,索引和潜在合并过程。
- 相反,如果您使用零副本进行索引,然后在提取完成时启用副本,则恢复过程本质上是逐字节的网络传输。 这比复制索引过程更有效。
PUT /my_logs/_settings
{"number_of_replicas": 1
}4、增加refresh间隔
如果你的搜索结果不需要接近实时的准确性,考虑先不要急于索引刷新refresh。可以将每个索引的refresh_interval到30s。
如果正在进行大量数据导入,可以通过在导入期间将此值设置为-1来禁用刷新。完成后不要忘记重新启用它!
设置方法:
PUT /my_logs/_settings
{ "refresh_interval": -1 }5、异步刷新translog
translog默认的持久化策略为:request。这个非常影响 ES 写入速度。但是这样写操作比较可靠。如果系统可以接受一定概率的数据丢失(例如:数据写入主分片成功,尚未复制到副分片时,主机断电。由于数据既没有刷到Lucene,translog也没有刷盘,恢复时translog中没有这个数据,数据丢失),则调整translog持久化策略。
在每一个索引,删除,更新或批量请求之后是否进行fsync和commit操作。此设置接受以下参数:
- request:(默认)在每次请求后fsync并commit。如果发生硬件故障,所有已确认的写入将已经提交到磁盘。
- async:每隔sync_interval段时间进行fsync并commit。如果发生故障,则自上次自动提交以来所有已确认的写入将被丢弃。
PUT /my_logs/_settings
{ "index.translog.durability": "async" }五、查看&取消任务
1、获取reindex任务列表
GET _tasks?actions=*reindex*&detailed
2、根据任务id查看任务
GET /_tasks/W29Va7J_Tj--sUYS6fSWlg:280879028其中task.status.total表示源数据总行数,task.status.created表示已同步的行数
3、取消任务
POST _tasks/W29Va7J_Tj--sUYS6fSWlg:280879028/_cancel
相关文章:
ES索引重建reindex详解
目录 一、使用场景 二、reindex介绍 三、使用手册 1、覆盖更新 2、创建丢失的文档并更新旧版本的文档 3、仅创建丢失的文档 4、冲突处理 5、source中添加查询条件 6、source中包含多个源索引 7、限制处理的记录数 8、从远程ES集群中重建索引 9、提取随机子集 10、…...
前沿分享-中距离射频取电
目前来看,微能源有四种技术路线,一是环境光采集、温差转换采集、无线射频采集和振动能量采集。 无线射频微能源是在通信设备通信过程中自然产生的,可以通过射频能量芯片实现无线射频取电,能瞬间大功率储电和安全驱动负载。 通过射…...
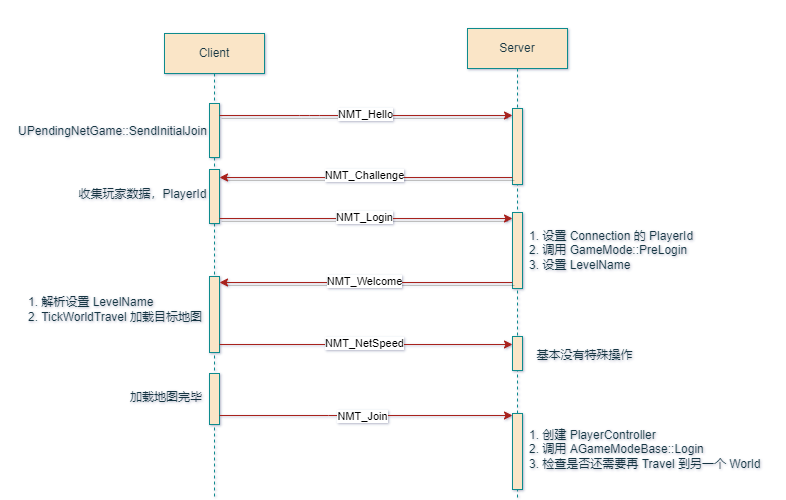
UnrealEngine - 网络同步之连接篇
1 连接过程 - 握手 传统的 C/S 架构下,Client 和 Server 通常会建立一条抽象的 Connection,用来进行两端的通信。 UE 的官方文档中提供了 Client 连接到 Server 的示例 ,简单来说分为如下几步: 打包构建好 Client 和 Server 进程…...
【JDBC系列】- 扩展提升学习
扩展提升学习 😄生命不息,写作不止 🔥 继续踏上学习之路,学之分享笔记 👊 总有一天我也能像各位大佬一样 🏆 博客首页 怒放吧德德 To记录领地 🌝分享学习心得,欢迎指正࿰…...

阻塞和非阻塞,同步和异步
文章目录 典型的一次IO的两个阶段IO多路复用是同步还是异步? 典型的一次IO的两个阶段 数据就绪和数据读写 同步:需要应用程序自己操作 IO多路复用是同步还是异步? epoll也是同步的 具体数据读取还是通过应用程序自己完成的 只有使用了特…...
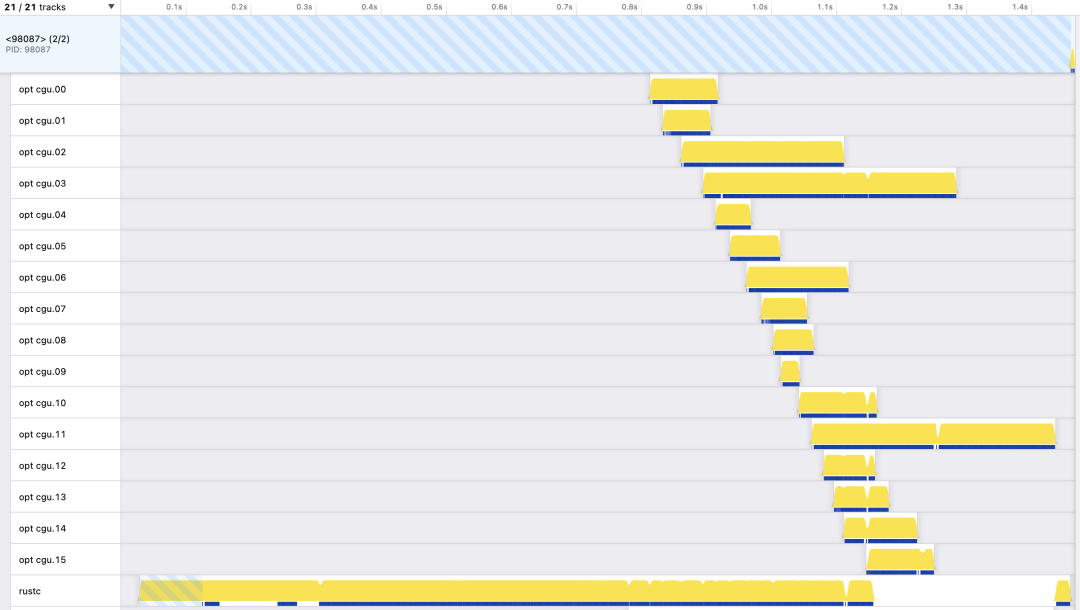
提速Rust编译器!
Nethercote是一位研究Rust编译器的软件工程师。最近,他正在探索如何提升Rust编译器的性能,在他的博客文章中介绍了Rust编译器是如何将代码分割成代码生成单元(CGU)的以及rustc的性能加速。 他解释了不同数量和大小的CGU之间的权衡…...
QT创建项目
可选择CMake或qmake...

基于vue3+webpack5+qiankun实现微前端
一 主应用改造(又称基座改造) 1 在主应用中安装qiankun(npm i qiankun -S) 2 在src下新建micro-app.js文件,用于存放所有子应用。 const microApps [// 当匹配到activeRule 的时候,请求获取entry资源,渲染到containe…...

华为OD真题--完美走位--带答案
2023华为OD统一考试(AB卷)题库清单-带答案(持续更新)or2023年华为OD真题机考题库大全-带答案(持续更新) 题目描述 输入一个长度为4的倍数的字符串Q,字符串中仅包含WASD四个字母。 将这个字符串中的连续子串…...
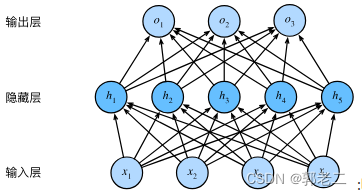
【AI】《动手学-深度学习-PyTorch版》笔记(十四):多层感知机
AI学习目录汇总 1、多层感知机网络结构 1.1 线性模型:softmax回归 在前面介绍过,使用softmax回归来处理分类问题时,每个输出通过都一个仿射函数计算,网络结构如下,输入和输出之间为全链接层: 1.2 多层感知机 多层感知机就是在输入和输出中间再添加一个或多个全链接…...
本地开发 npm 好用的http server、好用的web server、静态服务器
好用的web server总结 有时需要快速启动一个web 服务器(http服务器)来伺服静态网页,安装nginx又太繁琐,那么可以考虑使用npm serve、http-server、webpack-dev-server。 npm serve npm 的serve可以提供给http server功能&#…...
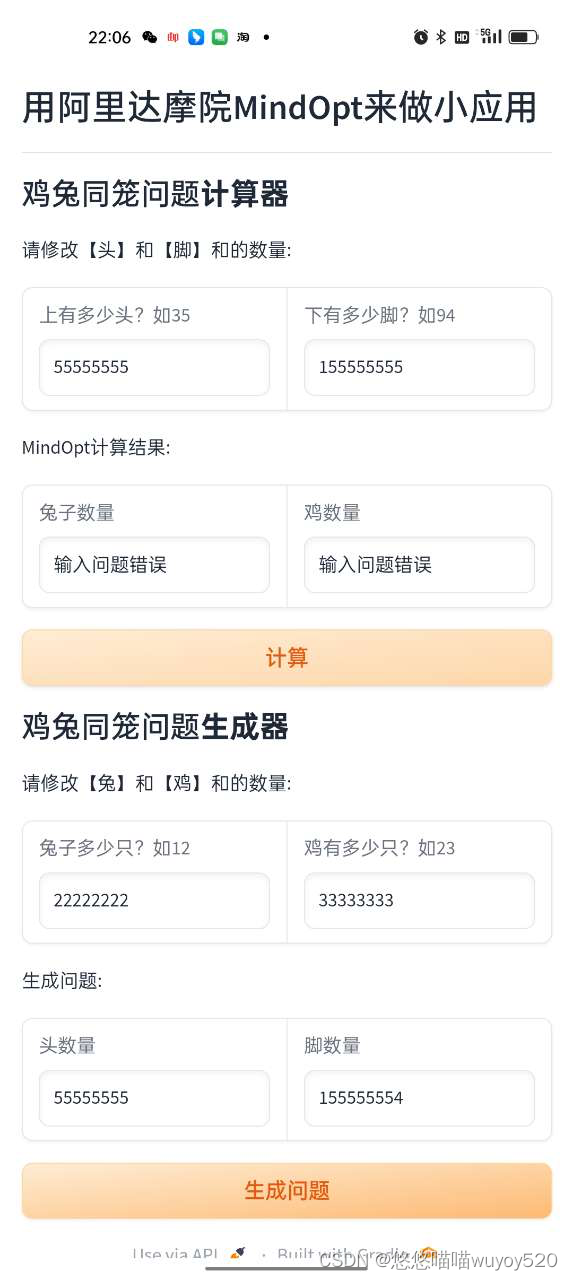
Gradio入门,并搭个鸡兔同笼问题小应用,附源码(MindOpt)
应用链接: https://979427749bc9ceec34.gradio.live 是公开访问链接,3天有效。 在modelscope中的创空间发布长期有效:https://modelscope.cn/studios/wuyoy520v01/MindOpt_Chicken-with-rabbit-cage/summary。 应用图如下,源代码见正文。 知…...

redis核心知识点简略笔记
value数据类型 string 二进制安全 list 有序、可重复 set 无序、不重复 hash field-value的map sorted set 不重复、通过double类型score分数排序 场景 string 计数器缓存分布式锁访问频率控制分布式session hash 购物车等对象属性灵活修改 list 定时排行榜 set 收藏 sorte…...
消息中间件 —— 初识Kafka
文章目录 1、Kafka简介1.1、消息队列1.1.1、为什么要有消息队列?1.1.2、消息队列1.1.3、消息队列的分类1.1.4、p2p 和 发布订阅MQ的比较1.1.5、消息系统的使用场景1.1.6、常见的消息系统 1.2、Kafka简介1.2.1、简介1.2.2、设计目标1.2.3、kafka核心的概念 2、Kafka的…...
Ceph集群安装部署
Ceph集群安装部署 目录 Ceph集群安装部署 1、环境准备 1.1 环境简介1.2 配置hosts解析(所有节点)1.3 配置时间同步2、安装docker(所有节点)3、配置镜像 3.1 下载ceph镜像(所有节点执行)3.2 搭建制作本地仓库(ceph-01节点执行)3.3 配置私有仓库(所有节点执行)3.4 为 Docker 镜像…...

PXC基于docker搭建mysql集群全过程
之前用mysql自带的bin-log复制,总是因为各种冲突,同步就阻塞掉了,一旦阻塞掉了,不主动发现,同步就终止了。还需要想办法手动去处理。所以考虑重新搭建集群。发现PXC方案不错,可以上两台,对服务器…...
项目知识点记录
1.使用druid连接池 使用properties配置文件: driverClassName com.mysql.cj.jdbc.Driver url jdbc:mysql://localhost:3306/book?useSSLtrue&setUnicodetrue&charsetEncodingUTF-8&serverTimezoneGMT%2B8 username root password 123456 #初始化链接数…...

【HDFS】ListenableFuture在HDFS中的应用
本文主要介绍以下内容: ListenableFuture提供的功能和基本使用方法;AsyncLogger、IPCLoggerChannel(它是AsyncLogger的子类)QuorumCall类一、ListenableFuture的基本使用 ListenableFuture 是 Guava 库中提供的一个接口,它扩展了 JDK 中的 Future 接口,并添加了异步任务…...

Databend 开源周报第 105 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 Databend 轻量级…...

ArcGISPro随机森林自动化调参分类预测模型展示
更改ArcGISPro的python环境变量请参考文章 ArcGISPro中如何使用机器学习脚本_Z_W_H_的博客-CSDN博客 脚本文件如下 点击运行 结果展示 负类预测概率 正类预测概率 二值化概率 文件夹(模型验证结果) 数据集数据库 ROC曲线 由于个人数据量太少所以…...

【脚本安装】十分钟配置Claude Code:终端里的AI编程搭档
十分钟上手Claude Code:终端里的AI编程搭档从零开始配置属于你自己的AI编程助手,让代码审查、批量修改、技术问答都在命令行里搞定。为什么写这篇 最近折腾了不少AI编程工具,Claude Code给我的体验最接近「搭档」这个词——不是那种被动等指令…...

mysql升级后日志文件如何处理_mysql日志迁移说明
MySQL升级后日志路径和配置必须显式重设:error log和slow-query-log-file需确保目录存在并授权;log-bin迁移要复制旧文件并避免直接删除;GTID模式下purge需谨慎;废弃参数如log_warnings须替换为log_error_verbosity;升…...

【AI Agent工程实战系列①】Agent系统为什么比你想的难十倍
Demo Agent和生产级Agent:本质区别在哪里 绝大多数Agent教程展示的是这样的系统: 用户输入 → LLM思考 → 选择工具 → 工具执行 → 返回结果这个流程在happy path(正常路径)上工作得很好。教程里的例子永远是: 用户问题清晰、意图明确 工具总是返回正确结果 任务在3-5步…...

软件市场管理中的目标客户选择
软件市场管理中的目标客户选择 在竞争激烈的软件市场中,精准选择目标客户是产品成功的关键。无论是初创企业还是行业巨头,都需要明确哪些用户群体最可能为产品买单,从而优化资源分配,提高市场推广效率。目标客户选择不仅关乎营销…...

Navicat数据库自动备份实战:如何设置夜间定时任务避免业务中断
Navicat数据库自动备份实战:如何设置夜间定时任务避免业务中断 深夜的办公室只剩下服务器指示灯在黑暗中闪烁,数据库管理员小李终于可以松一口气——公司的核心业务数据正在Navicat的自动备份任务中安全流转。对于现代企业而言,数据库就像数字…...

从C1815到2N5401:搞懂NPN/PNP在Arduino和STM32控制电路中的选型与接线
从C1815到2N5401:NPN/PNP在微控制器电路中的实战选型指南 三极管在电子电路中扮演着电流放大和开关控制的角色,但对于许多刚接触硬件开发的工程师来说,NPN和PNP的选择常常令人困惑。记得我第一次用STM32驱动继电器时,就因为选错了…...

解锁学术新境界:书匠策AI——期刊论文创作的智慧灯塔
在学术探索的浩瀚海洋中,每一位研究者都如同勇敢的航海家,怀揣着对知识的渴望,驾驭着思维的航船,不断追寻着真理的彼岸。而在这漫长的旅途中,一篇高质量的期刊论文,无疑是那指引方向的灯塔,照亮…...
)
别再踩坑了!Android 10+ 保存图片到相册的完整流程与权限处理(附完整代码)
Android 10 图片保存实战:避开Scoped Storage的12个深坑 每次看到同事在Android 10设备上调试图片保存功能时抓狂的样子,我都会想起自己曾经踩过的那些坑。从MediaStore的诡异行为到权限申请的玄学问题,这个看似简单的功能背后藏着太多"…...
)
别再只用yum了!CentOS 7下编译安装OpenSSH 8.2p1的完整避坑指南(附zlib/OpenSSL依赖处理)
别再只用yum了!CentOS 7下编译安装OpenSSH 8.2p1的完整避坑指南(附zlib/OpenSSL依赖处理) 在CentOS 7的生产环境中,系统自带的OpenSSH版本往往无法满足最新的安全需求。虽然yum提供了便捷的升级方式,但官方仓库的更新滞…...
 之 Allegro中封装库的精准调用与版本管理)
Cadence Allegro PCB设计88问解析(二十二) 之 Allegro中封装库的精准调用与版本管理
1. 封装库管理的重要性与常见痛点 在PCB设计流程中,封装库就像建筑师的砖瓦库房。我见过太多项目因为封装管理不善导致的问题:某次设计评审后发现30%的封装版本错误,团队不得不通宵返工;还有更惨痛的案例是批量生产时发现QFN封装焊…...