【变形金刚03】使用 Pytorch 开始构建transformer

一、说明
在本教程中,我们将使用 PyTorch 从头开始构建一个基本的转换器模型。Vaswani等人在论文“注意力是你所需要的一切”中引入的Transformer模型是一种深度学习架构,专为序列到序列任务而设计,例如机器翻译和文本摘要。它基于自我注意机制,已成为许多最先进的自然语言处理模型的基础,如GPT和BERT。
二、准备活动
若要生成转换器模型,我们将按照以下步骤操作:
- 导入必要的库和模块
- 定义基本构建块:多头注意力、位置前馈网络、位置编码
- 构建编码器和解码器层
- 组合编码器和解码器层以创建完整的转换器模型
- 准备示例数据
- 训练模型
让我们从导入必要的库和模块开始。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copy现在,我们将定义转换器模型的基本构建基块。
三、多头注意力
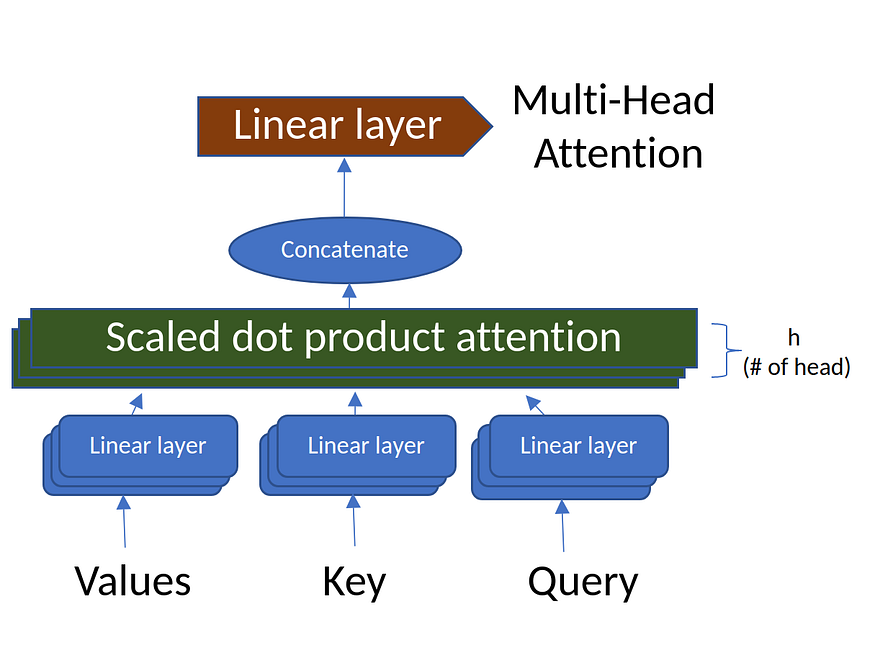
图2.多头注意力(来源:作者创建的图像)
多头注意力机制计算序列中每对位置之间的注意力。它由多个“注意头”组成,用于捕获输入序列的不同方面。
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super(MultiHeadAttention, self).__init__()assert d_model % num_heads == 0, "d_model must be divisible by num_heads"self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_headsself.W_q = nn.Linear(d_model, d_model)self.W_k = nn.Linear(d_model, d_model)self.W_v = nn.Linear(d_model, d_model)self.W_o = nn.Linear(d_model, d_model)def scaled_dot_product_attention(self, Q, K, V, mask=None):attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)if mask is not None:attn_scores = attn_scores.masked_fill(mask == 0, -1e9)attn_probs = torch.softmax(attn_scores, dim=-1)output = torch.matmul(attn_probs, V)return outputdef split_heads(self, x):batch_size, seq_length, d_model = x.size()return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)def combine_heads(self, x):batch_size, _, seq_length, d_k = x.size()return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)def forward(self, Q, K, V, mask=None):Q = self.split_heads(self.W_q(Q))K = self.split_heads(self.W_k(K))V = self.split_heads(self.W_v(V))attn_output = self.scaled_dot_product_attention(Q, K, V, mask)output = self.W_o(self.combine_heads(attn_output))return outputMultiHeadAttention 代码使用输入参数和线性变换层初始化模块。它计算注意力分数,将输入张量重塑为多个头部,并将所有头部的注意力输出组合在一起。前向方法计算多头自我注意,允许模型专注于输入序列的某些不同方面。
四、位置前馈网络
class PositionWiseFeedForward(nn.Module):def __init__(self, d_model, d_ff):super(PositionWiseFeedForward, self).__init__()self.fc1 = nn.Linear(d_model, d_ff)self.fc2 = nn.Linear(d_ff, d_model)self.relu = nn.ReLU()def forward(self, x):return self.fc2(self.relu(self.fc1(x)))PositionWiseFeedForward 类扩展了 PyTorch 的 nn。模块并实现按位置的前馈网络。该类使用两个线性转换层和一个 ReLU 激活函数进行初始化。forward 方法按顺序应用这些转换和激活函数来计算输出。此过程使模型能够在进行预测时考虑输入元素的位置。
五、位置编码
位置编码用于注入输入序列中每个令牌的位置信息。它使用不同频率的正弦和余弦函数来生成位置编码。
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_seq_length):super(PositionalEncoding, self).__init__()pe = torch.zeros(max_seq_length, d_model)position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe.unsqueeze(0))def forward(self, x):return x + self.pe[:, :x.size(1)]PositionalEncoding 类使用 d_model 和 max_seq_length 输入参数进行初始化,从而创建一个张量来存储位置编码值。该类根据比例因子div_term分别计算偶数和奇数指数的正弦和余弦值。前向方法通过将存储的位置编码值添加到输入张量中来计算位置编码,从而使模型能够捕获输入序列的位置信息。
现在,我们将构建编码器层和解码器层。
六、编码器层

图3.变压器网络的编码器部分(来源:图片来自原文)
编码器层由多头注意力层、位置前馈层和两个层归一化层组成。
class EncoderLayer(nn.Module):def __init__(self, d_model, num_heads, d_ff, dropout):super(EncoderLayer, self).__init__()self.self_attn = MultiHeadAttention(d_model, num_heads)self.feed_forward = PositionWiseFeedForward(d_model, d_ff)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask):attn_output = self.self_attn(x, x, x, mask)x = self.norm1(x + self.dropout(attn_output))ff_output = self.feed_forward(x)x = self.norm2(x + self.dropout(ff_output))return x类使用输入参数和组件进行初始化,包括一个多头注意模块、一个 PositionWiseFeedForward 模块、两个层规范化模块和一个 dropout 层。前向方法通过应用自注意、将注意力输出添加到输入张量并规范化结果来计算编码器层输出。然后,它计算按位置的前馈输出,将其与归一化的自我注意输出相结合,并在返回处理后的张量之前对最终结果进行归一化。
七、解码器层
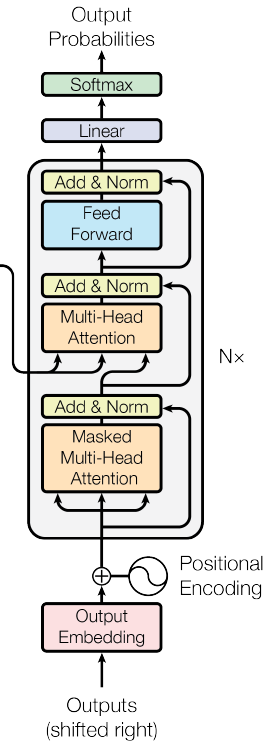
图4.变压器网络的解码器部分(Souce:图片来自原始论文)
解码器层由两个多头注意力层、一个位置前馈层和三个层归一化层组成。
class DecoderLayer(nn.Module):def __init__(self, d_model, num_heads, d_ff, dropout):super(DecoderLayer, self).__init__()self.self_attn = MultiHeadAttention(d_model, num_heads)self.cross_attn = MultiHeadAttention(d_model, num_heads)self.feed_forward = PositionWiseFeedForward(d_model, d_ff)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_output, src_mask, tgt_mask):attn_output = self.self_attn(x, x, x, tgt_mask)x = self.norm1(x + self.dropout(attn_output))attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)x = self.norm2(x + self.dropout(attn_output))ff_output = self.feed_forward(x)x = self.norm3(x + self.dropout(ff_output))return x解码器层使用输入参数和组件进行初始化,例如用于屏蔽自我注意和交叉注意力的多头注意模块、PositionWiseFeedForward 模块、三层归一化模块和辍学层。
转发方法通过执行以下步骤来计算解码器层输出:
- 计算掩蔽的自我注意输出并将其添加到输入张量中,然后进行 dropout 和层归一化。
- 计算解码器和编码器输出之间的交叉注意力输出,并将其添加到规范化的掩码自注意力输出中,然后进行 dropout 和层规范化。
- 计算按位置的前馈输出,并将其与归一化交叉注意力输出相结合,然后是压差和层归一化。
- 返回已处理的张量。
这些操作使解码器能够根据输入和编码器输出生成目标序列。
现在,让我们组合编码器和解码器层来创建完整的转换器模型。
八、变压器型号
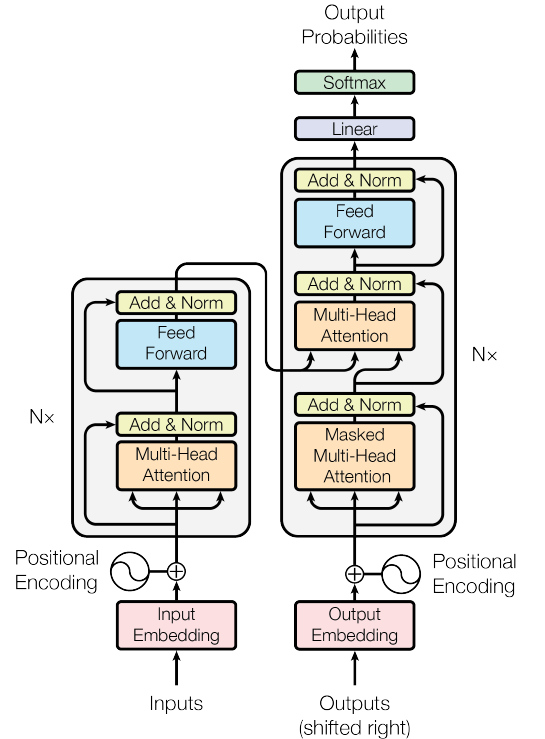
图5.The Transformer Network(来源:图片来源于原文)
将它们全部合并在一起:
class Transformer(nn.Module):def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):super(Transformer, self).__init__()self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)self.positional_encoding = PositionalEncoding(d_model, max_seq_length)self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])self.fc = nn.Linear(d_model, tgt_vocab_size)self.dropout = nn.Dropout(dropout)def generate_mask(self, src, tgt):src_mask = (src != 0).unsqueeze(1).unsqueeze(2)tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)seq_length = tgt.size(1)nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()tgt_mask = tgt_mask & nopeak_maskreturn src_mask, tgt_maskdef forward(self, src, tgt):src_mask, tgt_mask = self.generate_mask(src, tgt)src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))enc_output = src_embeddedfor enc_layer in self.encoder_layers:enc_output = enc_layer(enc_output, src_mask)dec_output = tgt_embeddedfor dec_layer in self.decoder_layers:dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)output = self.fc(dec_output)return output类组合了以前定义的模块以创建完整的转换器模型。在初始化期间,Transformer 模块设置输入参数并初始化各种组件,包括源序列和目标序列的嵌入层、位置编码模块、用于创建堆叠层的编码器层和解码器层模块、用于投影解码器输出的线性层以及 dropout 层。
generate_mask 方法为源序列和目标序列创建二进制掩码,以忽略填充标记并防止解码器处理将来的令牌。前向方法通过以下步骤计算转换器模型的输出:
- 使用 generate_mask 方法生成源掩码和目标掩码。
- 计算源和目标嵌入,并应用位置编码和丢弃。
- 通过编码器层处理源序列,更新enc_output张量。
- 通过解码器层处理目标序列,使用enc_output和掩码,并更新dec_output张量。
- 将线性投影层应用于解码器输出,获取输出对数。
这些步骤使转换器模型能够处理输入序列,并根据其组件的组合功能生成输出序列。
九、准备样本数据
在此示例中,我们将创建一个用于演示目的的玩具数据集。实际上,您将使用更大的数据集,预处理文本,并为源语言和目标语言创建词汇映射。
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)十、训练模型
现在,我们将使用示例数据训练模型。在实践中,您将使用更大的数据集并将其拆分为训练集和验证集。
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)transformer.train()for epoch in range(100):optimizer.zero_grad()output = transformer(src_data, tgt_data[:, :-1])loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))loss.backward()optimizer.step()print(f"Epoch: {epoch+1}, Loss: {loss.item()}")我们可以使用这种方式在 Pytorch 中从头开始构建一个简单的转换器。所有大型语言模型都使用这些转换器编码器或解码器块进行训练。因此,了解启动这一切的网络非常重要。希望本文能帮助所有希望深入了解LLM的人。
相关文章:
【变形金刚03】使用 Pytorch 开始构建transformer
一、说明 在本教程中,我们将使用 PyTorch 从头开始构建一个基本的转换器模型。Vaswani等人在论文“注意力是你所需要的一切”中引入的Transformer模型是一种深度学习架构,专为序列到序列任务而设计,例如机器翻译和文本摘要。它基于自我注意机…...
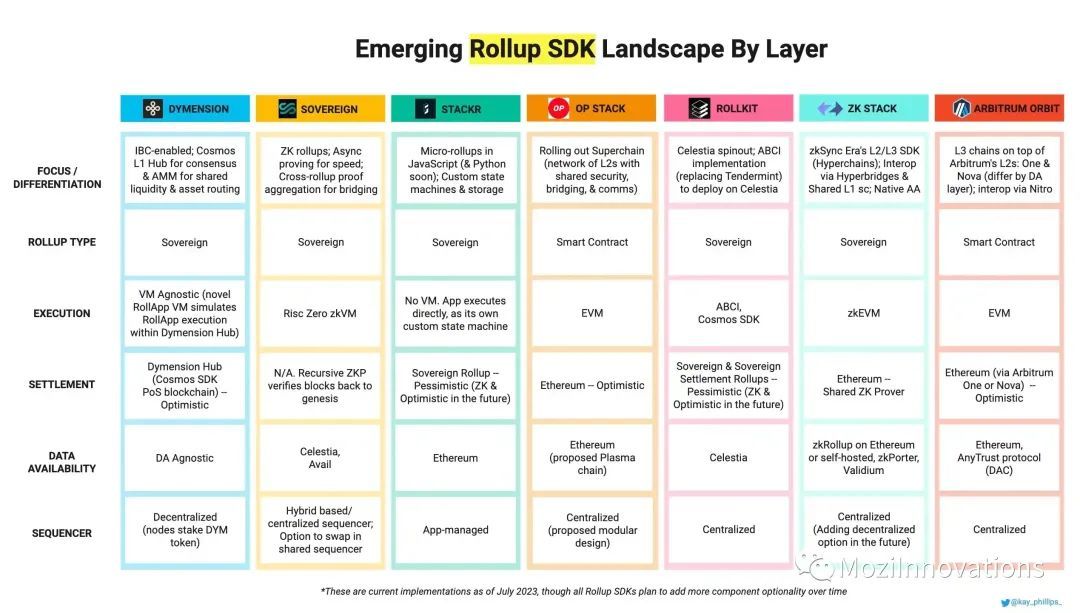
「Web3大厂」价值70亿美元的核心竞争力
经过近 5 年的研发和酝酿,Linea 团队在 7 月的巴黎 ETHCC 大会期间宣布了主网 Alpha 的上线,引起了社区的广泛关注。截止 8 月 4 日,据 Dune 数据信息显示,其主网在一周内就涌入了 100 多个生态项目,跨入了超 2 万枚 E…...

前端发送请求和后端springboot接受参数
0.xhr、 ajax、axios、promise和async/await 和http基本方法 xhr、 ajax、axios、promise和async/await都是异步编程和网络请求相关的概念和技术! xhr:XMLHttpRequest是浏览器提供的js对象(API),用于请求服务器资源。…...

程序一直在阿里云服务器运行
保持阿里云服务器开机程序保持运行. 1.下载Screen CentOS 系列系统: yum install screen Ubuntu 系列系统: sudo apt-get install screen 2、运行screen,创建一个screen screen -S name:name是标记进程, 给进程备注…...

Linux 文件与目录管理
nvLinux 文件与目录管理 我们知道 Linux 的目录结构为树状结构,最顶级的目录为根目录 /。 其他目录通过挂载可以将它们添加到树中,通过解除挂载可以移除它们。 在开始本教程前我们需要先知道什么是绝对路径与相对路径。 绝对路径: 路径的写…...

【CSS】CSS 布局——弹性盒子
Flexbox 是一种强大的布局系统,旨在更轻松地使用 CSS 创建复杂的布局。 它特别适用于构建响应式设计和在容器内分配空间,即使项目的大小是未知的或动态的。Flexbox 通常用于将元素排列成一行或一列,并提供一组属性来控制 flex 容器内的项目行…...
)
“华为杯”研究生数学建模竞赛2018年-【华为杯】B题:光传送网建模与价值评估(附优秀论文及matlab代码实现)
目录 摘要: 1.问题重述 1.1 问题背景 1.2 问题提出 2.问题假设 3.符号说明...
群晖 nas 自建 ntfy 通知服务(梦寐以求)
目录 一、什么是 ntfy ? 二、在群晖nas上部署ntfy 1. 在Docker中安装ntfy 2. 设置ntfy工作文件夹 3. 启动部署在 docker 中的 ntfy(binwiederhier/ntfy) 三、启动配置好后,如何使用ntfy 1. 添加订阅主题( Subscribe to topic…...
)
Java基础练习九(方法)
求和 设计一个方法,用于计算整数的和 public class Work1101 {public static void main(String[] args) {// 设计一个方法,用于计算整数的和System.out.println(sum(7, 6));}public static int sum(int a, int b) {return a b;} }阶乘 编写一个方法&…...
Python-OpenCV中的图像处理-图像轮廓
Python-OpenCV中的图像处理-图像轮廓 轮廓什么是轮廓查找轮廓绘制轮廓轮廓特征图像的矩轮廓面积轮廓周长(弧长)轮廓近似凸包凸性检测边界矩形直边界矩形旋转边界矩形(最小面积矩形)最小外接圆最小外接三角椭圆拟合直线拟合 轮廓的…...

@Cacheable缓存相关使用总结
本篇文章主要讲解Spring当中Cacheable缓存相关使用 在实际项目开发中,有些数据是变更频率比较低,但是查询频率比较高的,此时为了提升系统性能,可以使用缓存的机制实现,避免每次从数据库获取 第一步:使用E…...

c++ static
static 成员 声明为static的类成员称为类的静态成员,用static修饰的成员变量,称之为静态成员变量;用 static修饰的成员函数,称之为静态成员函数。静态成员变量一定要在类外进行初始化。 看看下面代码体会一下: //其他类 class …...
【数据结构】——栈、队列的相关习题
目录 题型一(栈与队列的基本概念)题型二(栈与队列的综合)题型三(循环队列的判空与判满)题型四(循环链表表示队列)题型五(循环队列的存储)题型六(循…...

C++初阶之一篇文章教会你list(模拟实现)
list(模拟实现) list模拟实现list_node节点结构定义std::__reverse_iterator逆向迭代器实现list迭代器 __list_iterator定义list类成员定义list成员函数定义1.begin()、end()、rbegin()和rend()2.empty_init()3.构造函数定义4.swap5.析构函数定义6.clear…...
设备工单管理系统如何实现工单流程自动化?
设备工单管理系统属于工单系统的一种,基于其丰富的功能,它可以同时处理不同的多组流程,旨在有效处理发起人提交的事情,指派相应人员完成服务请求和记录全流程。该系统主要面向后勤管理、设备维护、物业管理、酒店民宿等服务行业设…...

ubuntu20.04.6anzhuang mtt s80
需要打开主板的Resize BAR和Above 4G功能,否则GPU显存不能被正确识别; 2. 在某些不支持PCIe Gen5的主板上,需要把PCIe速率由auto设置为PCIe Gen4速率; sudo apt install lightdm unity-greetersheding lightdm : lightdm sudo apt install /…...

【LeetCode-中等】剑指 Offer 36. 二叉搜索树与双向链表
题目链接 剑指 Offer 36. 二叉搜索树与双向链表 标签 后序遍历、二叉搜索树 步骤 二叉搜索树中的任一节点的直接前驱为其左子树的最右侧节点,直接后继为其右子树的最左侧节点。因此,可以通过这个关系来操作原来的二叉树。为了不影响深度较大的节点的…...
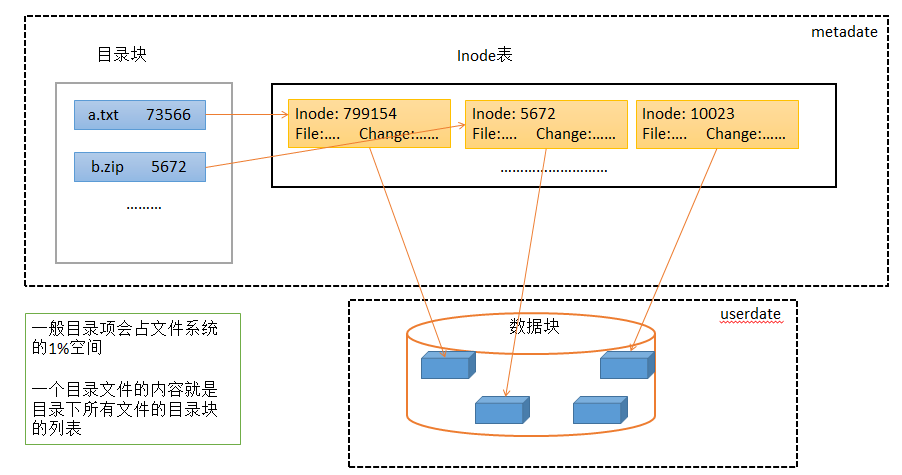
Linux —— 文件系统
目录 一,背景 二,文件系统 一,磁盘简介 磁盘分为SSD、机械磁盘;机械磁盘,即磁盘高速转动,磁头移动到读写扇区所在磁道,让磁头在目标扇区上划过,即可完成对扇区的读写操作ÿ…...

自然策略优化的解释 Natural Policy Optimization
Natural Policy Optimization(自然策略优化)是一种用于优化策略梯度算法的方法。它是基于概率策略的强化学习算法,旨在通过迭代地更新策略参数来最大化累积回报。 传统的策略梯度算法通常使用梯度上升法来更新策略参数,但这种方法…...

docker基本使用方法
docker使用 1. Docker 介绍 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。Docker 使您能够将应用程序与基础架构分开,从而可以快速交付软件。通过利用 …...

如何用智能工具10分钟搞定黑苹果配置:OpCore-Simplify终极实战指南
如何用智能工具10分钟搞定黑苹果配置:OpCore-Simplify终极实战指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果配置…...

如何快速上手MoeKoeMusic:免费解锁VIP特权的完整音乐播放器指南
如何快速上手MoeKoeMusic:免费解锁VIP特权的完整音乐播放器指南 【免费下载链接】MoeKoeMusic 一款开源简洁高颜值的酷狗第三方客户端 An open-source, concise, and aesthetically pleasing third-party client for KuGou that supports Windows / macOS / Linux /…...

Verdi FSDB转VCD实战:解锁后端功耗分析新姿势
1. 为什么需要FSDB转VCD? 在芯片设计流程中,功耗分析是个绕不开的关键环节。PrimeTime PX(Prime Power)这类工具需要仿真波形作为输入来计算动态功耗。但最近我在项目中遇到个头疼的问题:用最新版Verdi生成的FSDB波形文…...

从GSM到5G NR:手把手教你用ADS2022的【Sources - Modulated】面板搭建通信系统仿真
从GSM到5G NR:用ADS2022构建完整通信系统仿真的实战指南 在无线通信系统设计中,仿真环节往往决定着产品研发的成败。Keysight的ADS2022作为行业标杆工具,其Sources - Modulated面板提供的丰富信号源模型,能够精准模拟从2G到5G的各…...

HEIF Utility:为Windows用户打通苹果照片格式壁垒的3大核心方案
HEIF Utility:为Windows用户打通苹果照片格式壁垒的3大核心方案 【免费下载链接】HEIF-Utility HEIF Utility - View/Convert Apple HEIF images on Windows. 项目地址: https://gitcode.com/gh_mirrors/he/HEIF-Utility 你是否曾经从iPhone传输照片到Window…...

信号处理实战:如何为你的ECG心电信号或音频降噪任务挑选合适的小波函数?
信号处理实战:如何为ECG心电信号或音频降噪挑选合适的小波函数? 第一次处理ECG信号时,我被监护仪输出的波形吓了一跳——那些本该清晰的心跳信号上爬满了高频噪声,就像老式电视机失去信号时的雪花屏。当时导师只说了一句ÿ…...

如何突破Windows窗口限制?WindowResizer终极调整指南
如何突破Windows窗口限制?WindowResizer终极调整指南 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 你是否曾被那些顽固的Windows窗口所困扰?有些应用程序…...

三步解锁QQ音乐加密格式:qmc-decoder让你的音乐收藏真正自由
三步解锁QQ音乐加密格式:qmc-decoder让你的音乐收藏真正自由 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾为QQ音乐下载的歌曲无法在其他播放器播放而…...
)
别再手动测接口了!用JMeter 5.6.3 + CSV文件实现批量登录测试(附实战脚本)
电商登录压力测试实战:用JMeter 5.6.3CSV实现200账号批量验证 在电商系统上线前的关键阶段,登录接口的稳定性直接关系到用户体验和商业转化。传统的手动测试方式不仅效率低下,还难以模拟真实用户并发场景。本文将分享如何通过JMeter 5.6.3的C…...

工业通信协议:Modbus与OPC UA的解析与实现
工业通信协议:Modbus与OPC UA的解析与实现 在现代工业自动化系统中,通信协议是实现设备互联和数据交换的核心技术。Modbus和OPC UA作为两种广泛应用的工业通信协议,分别代表了传统与新兴技术的典型代表。Modbus以其简单、可靠的特点在工业领…...