C++初阶之一篇文章教会你list(模拟实现)

list(模拟实现)
- list模拟实现
- list_node节点结构定义
- std::__reverse_iterator逆向迭代器实现
- list迭代器 __list_iterator定义
- list类成员定义
- list成员函数定义
- 1.begin()、end()、rbegin()和rend()
- 2.empty_init()
- 3.构造函数定义
- 4.swap
- 5.析构函数定义
- 6.clear()
- 7.push_back
- 8.push_front
- 9.insert
- 10.erase
- 11.pop_back()和pop_front()
- 12.empty()、size()、front()和back()
- 13.resize
- 14.赋值运算符重载
- list模拟实现全部代码
- list 和 vector的区别
- 结语
list模拟实现
成员类型表

这个表中列出了C++标准库中list容器的一些成员类型定义。这些类型定义是为了使list能够与C++标准库的其他组件协同工作,并提供一些通用的标准接口。每个成员类型的用处:
value_type: 这个成员类型代表list容器中存储的数据类型,即模板参数T的类型。
allocator_type: 这个成员类型代表分配器的类型,用于为容器的内存分配和管理。默认情况下,使用allocator<value_type>作为分配器。
reference: 这个成员类型表示对元素的引用类型。对于默认分配器,它是value_type&,即对元素的引用。
const_reference: 这个成员类型表示对常量元素的引用类型。对于默认分配器,它是const value_type&,即对常量元素的引用。
pointer: 这个成员类型表示指向元素的指针类型。对于默认分配器,它是value_type*,即指向元素的指针。
const_pointer: 这个成员类型表示指向常量元素的指针类型。对于默认分配器,它是const value_type*,即指向常量元素的指针。
iterator: 这个成员类型是一个双向迭代器类型,可以用于遍历容器的元素。它可以隐式转换为const_iterator,允许在遍历时修改元素。
const_iterator: 这个成员类型也是一个双向迭代器类型,用于遍历常量容器的元素,不允许修改元素。
reverse_iterator: 这个成员类型是iterator的逆向迭代器,可以从容器尾部向头部遍历。
const_reverse_iterator: 这个成员类型是const_iterator的逆向迭代器,用于从常量容器的尾部向头部遍历。
difference_type: 这个成员类型表示两个迭代器之间的距离,通常使用的是ptrdiff_t,与指针的差值类型相同。
size_type: 这个成员类型表示非负整数的类型,通常使用的是size_t,用于表示容器的大小。
这些成员类型的定义使得list容器能够与其他C++标准库的组件以及用户自定义的代码进行交互,从而实现更加通用和灵活的功能。
list_node节点结构定义
定义链表的节点结构 list_node,用于存储链表中的每个元素。让我们逐一解释每个部分的含义。
template<class T>
struct list_node
{T _data; // 存储节点的数据list_node<T>* _next; // 指向下一个节点的指针list_node<T>* _prev; // 指向前一个节点的指针// 构造函数list_node(const T& x = T()):_data(x) // 使用参数 x 初始化 _data, _next(nullptr) // 初始化 _next 为 nullptr, _prev(nullptr) // 初始化 _prev 为 nullptr{}
};
T _data;:存储节点中的数据,类型为模板参数 T,可以是任意数据类型。
list_node<T>* _next;:指向下一个节点的指针,用于构建链表结构。初始时设为 nullptr,表示当前节点没有后继节点。
list_node<T>* _prev;:指向前一个节点的指针,同样用于构建链表结构。初始时设为 nullptr,表示当前节点没有前驱节点。
构造函数 list_node(const T& x = T()):构造函数可以接收一个参数 x,用于初始化节点的数据。如果没有传入参数,默认构造一个空节点。
通过这个节点结构,你可以创建一个双向链表list,将不同类型的数据存储在节点中,并连接节点以构建链表的结构。这个节点结构为链表的实现提供了基础。
std::__reverse_iterator逆向迭代器实现
#pragma oncenamespace xzq
{// 复用,迭代器适配器template<class Iterator, class Ref, class Ptr>struct __reverse_iterator{Iterator _cur;typedef __reverse_iterator<Iterator, Ref, Ptr> RIterator;__reverse_iterator(Iterator it):_cur(it){}RIterator operator++(){--_cur;return *this;}RIterator operator--(){++_cur;return *this;}Ref operator*(){auto tmp = _cur;--tmp;return *tmp;}Ptr operator->(){return &(operator*());}bool operator!=(const RIterator& it){return _cur != it._cur;}};
}
说明:
__reverse_iterator类模板定义了一个逆向迭代器,它有三个模板参数:Iterator(迭代器的类型)、Ref(引用类型)和Ptr(指针类型)。
_cur是一个私有成员变量,保存当前迭代器的位置。
构造函数接受一个正向迭代器作为参数,并将其存储在_cur成员变量中。
operator++()重载了递增操作符,让迭代器向前移动一个位置。
operator--()重载了递减操作符,让迭代器向后移动一个位置。
operator*()重载了解引用操作符,返回逆向迭代器指向的元素的引用。
operator->()重载了成员访问操作符,返回逆向迭代器指向的元素的指针。
operator!=()重载了不等于操作符,用于判断两个逆向迭代器是否不相等。
这个逆向迭代器可以用于支持从容器的尾部向头部的方向进行迭代。在 C++ 标准库中,std::reverse_iterator 用于实现类似的功能。
这个代码实现了一个迭代器适配器。迭代器适配器是一种在现有迭代器基础上提供不同功能的封装器,使得原本的迭代器能够适应新的使用场景。
__reverse_iterator 就是一个逆向迭代器适配器。它封装了一个正向迭代器,但通过重载操作符等方式,使其可以从容器的尾部向头部进行迭代。这样的适配器能够让原本的正向迭代器在逆向遍历时更加方便。在下面的list模拟实现中的反向迭代器函数需要用到,当然它也可以适用于其他容器的模拟实现,因场景而定,并不是所有容器都可以适用。
list迭代器 __list_iterator定义
迭代器 __list_iterator,用于遍历链表中的节点。让我们逐一解释每个部分的含义。
template<class T, class Ref, class Ptr>
struct __list_iterator
{typedef list_node<T> Node; // 定义一个类型别名 Node,用于表示 list 节点的类型typedef __list_iterator<T, Ref, Ptr> iterator; // 定义一个类型别名 iterator,用于表示 list 迭代器的类型typedef bidirectional_iterator_tag iterator_category; // 定义迭代器的分类,这里是双向迭代器typedef T value_type; // 定义元素的类型,即模板参数 Ttypedef Ptr pointer; // 定义指向元素的指针类型,用于迭代器typedef Ref reference; // 定义对元素的引用类型,用于迭代器typedef ptrdiff_t difference_type; // 定义表示迭代器之间距离的类型Node* _node; // 指向链表中的节点__list_iterator(Node* node):_node(node) // 初始化迭代器,指向给定的节点{}bool operator!=(const iterator& it) const{return _node != it._node; // 比较两个迭代器是否不相等}bool operator==(const iterator& it) const{return _node == it._node; // 比较两个迭代器是否相等}Ref operator*(){return _node->_data; // 返回当前节点的数据}Ptr operator->(){ return &(operator*()); // 返回当前节点数据的地址}// ++ititerator& operator++(){_node = _node->_next; // 迭代器自增,指向下一个节点return *this;}// it++iterator operator++(int){iterator tmp(*this); // 创建一个临时迭代器保存当前迭代器_node = _node->_next; // 迭代器自增,指向下一个节点return tmp; // 返回保存的临时迭代器}// --ititerator& operator--(){_node = _node->_prev; // 迭代器自减,指向前一个节点return *this;}// it--iterator operator--(int){iterator tmp(*this); // 创建一个临时迭代器保存当前迭代器_node = _node->_prev; // 迭代器自减,指向前一个节点return tmp; // 返回保存的临时迭代器}
};
这个迭代器结构为链表提供了遍历节点的能力。它可以用于循环遍历链表的每个元素,提供了类似于指针的行为,使得遍历链表变得更加方便。
这里提一下迭代器类型的分类:
C++ 标准库中的迭代器分为五种主要类型,每种类型提供了不同的功能和支持的操作。这些类型分别是:
输入迭代器(Input Iterator):只允许从容器中读取元素,但不能修改容器内的元素。只支持逐个移动、解引用、比较以及比较是否相等等操作。输入迭代器通常用于算法中,如 std::find()。
输出迭代器(Output Iterator):只允许向容器写入元素,但不能读取容器内的元素。支持逐个移动和逐个写入元素等操作。
前向迭代器(Forward Iterator):类似于输入迭代器,但支持多次解引用。前向迭代器可以用于一些需要多次迭代的操作,如遍历一个单链表。
双向迭代器(Bidirectional Iterator):在前向迭代器的基础上,增加了向前遍历的能力。除了支持输入迭代器的操作外,还支持向前移动和逐个向前移动元素等操作。
随机访问迭代器(Random Access Iterator):是最强大的迭代器类型。除了支持前向迭代器和双向迭代器的所有操作外,还支持类似指针的算术操作,如加法、减法,以及随机访问容器中的元素。随机访问迭代器通常用于数组等支持随机访问的数据结构中。
在上面的代码中,typedef bidirectional_iterator_tag iterator_category; 表示这个迭代器是双向迭代器类型,因此它应该支持前向和双向迭代器的所有操作,包括移动、解引用、比较等。这是为了确保这个迭代器在遍历 list 类的容器元素时能够正常工作。
list类成员定义
下面的代码是C++ 中双向链表模板类 list 的类定义部分。这个类定义了一些公共的成员类型和私有成员变量来支持链表的操作。让我们逐一解释每个部分的含义。
template<class T>
class list
{typedef list_node<T> Node;
public:// 定义迭代器类型typedef __list_iterator<T, T&, T*> iterator;typedef __list_iterator<T, const T&, const T*> const_iterator;typedef __reverse_iterator<iterator, T&, T*> reverse_iterator;typedef __reverse_iterator<const_iterator, const T&, const T*> const_reverse_iterator;private:Node* _head;
};
typedef list_node<T> Node;:定义一个别名 Node,代表链表节点类型 list_node<T>。
typedef __list_iterator<T, T&, T*> iterator;:定义了链表的正向迭代器类型 iterator,它使用 __list_iterator 结构模板,并指定了相应的参数类型。
typedef __list_iterator<T, const T&, const T*> const_iterator;:定义了链表的常量正向迭代器类型 const_iterator,用于在不修改链表元素的情况下遍历链表。
typedef __reverse_iterator<iterator, T&, T*> reverse_iterator;:定义了链表的反向迭代器类型 reverse_iterator,这个迭代器从链表末尾向链表开头遍历。
typedef __reverse_iterator<const_iterator, const T&, const T*> const_reverse_iterator;:定义了链表的常量反向迭代器类型 const_reverse_iterator。
Node* _head;:链表的私有成员变量,指向链表的头节点。
这个部分的代码定义了 list 类的公共成员类型和私有成员变量,为实现链表的操作和管理提供了基础。
list成员函数定义
1.begin()、end()、rbegin()和rend()
const_iterator begin() const{return const_iterator(_head->_next);}const_iterator end() const{return const_iterator(_head);}iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}reverse_iterator rbegin(){return reverse_iterator(end());}reverse_iterator rend(){return reverse_iterator(begin());}
这部分代码是关于 list 类的迭代器成员函数的定义。它们用于返回不同类型的迭代器,使得用户可以遍历 list 容器的元素。
const_iterator begin() const: 这是一个常量成员函数,返回一个常量迭代器,它指向容器中的第一个元素(节点)。由于是常量迭代器,所以不允许通过它修改容器内的元素。
const_iterator end() const: 这也是一个常量成员函数,返回一个常量迭代器,它指向容器末尾的“尾后”位置,即不存在的元素位置。常量迭代器不能用于修改元素。
iterator begin(): 这是一个非常量成员函数,返回一个非常量迭代器,它指向容器中的第一个元素(节点)。允许通过这个迭代器修改容器内的元素。
iterator end(): 这也是一个非常量成员函数,返回一个非常量迭代器,它指向容器末尾的“尾后”位置,即不存在的元素位置。非常量迭代器可以用于修改元素。
reverse_iterator rbegin(): 这是一个返回反向迭代器的函数,它将 end() 的迭代器作为参数传递给 reverse_iterator 构造函数,从而返回一个指向容器末尾的反向迭代器。
reverse_iterator rend(): 这是一个返回反向迭代器的函数,它将 begin() 的迭代器作为参数传递给 reverse_iterator 构造函数,从而返回一个指向容器开始的反向迭代器。
这些函数的目的是为了方便用户在不同情况下遍历容器元素,包括正向遍历和反向遍历,以及使用常量或非常量迭代器。通过这些迭代器,用户可以在 list 容器中轻松访问和操作元素。
2.empty_init()
void empty_init()
{_head = new Node; // 创建一个新的节点作为链表头部_head->_next = _head; // 将头部节点的下一个指针指向自身,表示链表为空_head->_prev = _head; // 将头部节点的前一个指针也指向自身,表示链表为空
}
这是 list 类中的一个私有成员函数 empty_init(),它用于初始化一个空的链表。
该函数的目的是在创建一个新的空链表时,为头部节点 _head 初始化正确的指针,使得链表为空。链表的头部节点 _head 用来标识链表的起始位置和结束位置。
在这个函数中,首先通过 new 运算符创建一个新的节点作为链表的头部。然后,将头部节点的 _next 指针和 _prev 指针都指向自身,表示链表为空。这种情况下,链表的头部节点既是首节点也是尾节点,形成一个环状的链表结构。
在 list 类的构造函数中,通过调用 empty_init() 来创建一个空链表。这在后续的操作中为链表的插入、删除等操作提供了正确的基础。
3.构造函数定义
template <class InputIterator>
list(InputIterator first, InputIterator last)
{empty_init(); // 初始化一个空链表while (first != last){push_back(*first); // 将当前迭代器指向的元素添加到链表尾部++first; // 移动迭代器到下一个元素}
}
list 类的构造函数模板,它接受一个范围内的元素,并将这些元素添加到链表中。
这个构造函数使用了一个模板参数 InputIterator,它表示输入迭代器的类型。这样,构造函数可以接受不同类型的迭代器,例如普通指针、list 的迭代器等。
在构造函数中,首先调用 empty_init() 函数来初始化一个空链表,确保链表头部的 _head 节点正确初始化。
然后,使用一个循环遍历输入迭代器范围内的元素。在每次循环中,通过 push_back() 函数将当前迭代器指向的元素添加到链表的尾部。之后,将迭代器向前移动一个位置,以便处理下一个元素。
list()
{empty_init(); // 初始化一个空链表
}
这是 list 类的无参构造函数,它用于创建一个空的链表。
这个构造函数不接受任何参数,它只是在对象创建时将 _head 节点初始化为一个空链表。调用 empty_init() 函数会创建一个只包含 _head 节点的链表,该节点的 _next 和 _prev 都指向自身,表示链表为空。
list(const list<T>& lt)
{empty_init(); // 初始化一个空链表list<T> tmp(lt.begin(), lt.end()); // 使用迭代器从 lt 创建一个临时链表swap(tmp); // 交换临时链表和当前链表,完成拷贝操作
}
这是 list 类的拷贝构造函数,它用于创建一个新链表,该链表与另一个已存在的链表 lt 相同
在这个构造函数中,首先通过调用 empty_init() 函数初始化了一个空链表,然后创建了一个临时链表 tmp,这个临时链表的元素和链表 lt 中的元素相同,通过迭代器从 lt 范围内创建。接着,通过调用 swap() 函数将当前链表与临时链表 tmp 交换,从而实现了链表的拷贝。
这种方式能够实现拷贝构造的效果,因为在 swap() 函数中,临时链表 tmp 的资源会交给当前链表,而临时链表 tmp 会被销毁,从而实现了链表内容的拷贝。
4.swap
void swap(list<T>& x)
{std::swap(_head, x._head); // 交换两个链表的头结点指针
}
这是 list 类的成员函数 swap,它用于交换两个链表的内容。
在这个函数中,通过调用标准库函数 std::swap,将当前链表的头结点指针 _head 与另一个链表 x 的头结点指针 _head 进行交换。这个操作会导致两个链表的内容被互相交换,但是实际上并没有复制链表中的元素,只是交换了链表的结构。
这种交换操作通常在需要交换两个对象的内容时使用,它可以在不复制数据的情况下实现两个对象之间的内容互换,从而提高了效率。
需要注意的是,这个函数只是交换了链表的头结点指针,而链表中的元素顺序没有改变。
5.析构函数定义
~list()
{clear(); // 清空链表中的所有元素delete _head; // 删除头结点_head = nullptr; // 将头结点指针置为空指针
}
这是 list 类的析构函数,用于销毁链表对象。
在这个析构函数中,首先调用了成员函数 clear() 来清空链表中的所有元素,确保在删除链表之前释放所有资源。然后,使用 delete 关键字释放头结点的内存。最后,将头结点指针 _head 置为空指针,以避免出现野指针。
这样,在链表对象被销毁时,它所占用的内存将会被正确地释放,从而防止内存泄漏。
6.clear()
void clear()
{iterator it = begin(); // 获取链表的起始迭代器while (it != end()) // 遍历链表{it = erase(it); // 使用 erase() 函数删除当前元素,并将迭代器指向下一个元素}
}
这是 list 类的 clear() 成员函数,用于清空链表中的所有元素。
在这个函数中,首先获取链表的起始迭代器 begin(),然后通过一个循环遍历链表中的所有元素。在循环内部,调用了 erase() 函数来删除当前迭代器指向的元素,并将迭代器更新为指向被删除元素的下一个元素。这样可以确保链表中的所有元素都被逐个删除。
需要注意的是,erase() 函数在删除元素后会返回指向下一个元素的迭代器,因此在每次循环迭代时更新迭代器是必要的,以便继续正确地遍历链表。
总之,这个 clear() 函数用于释放链表中的所有元素,并确保链表变为空链表。
7.push_back
void push_back(const T& x)
{Node* tail = _head->_prev; // 获取当前链表的末尾节点Node* newnode = new Node(x); // 创建一个新节点,保存新元素 xtail->_next = newnode; // 更新末尾节点的下一个指针,指向新节点newnode->_prev = tail; // 新节点的前一个指针指向原末尾节点newnode->_next = _head; // 新节点的下一个指针指向头节点_head->_prev = newnode; // 头节点的前一个指针指向新节点,完成插入操作
}
这是 list 类的 push_back() 成员函数,用于在链表的末尾添加一个新元素。
在这个函数中,首先获取当前链表的末尾节点(尾节点的 _prev 指向链表的最后一个元素),然后创建一个新的节点 newnode,并将新元素 x 存储在新节点中。接着,更新末尾节点的 _next 指针,使其指向新节点,然后更新新节点的 _prev 指针,使其指向原末尾节点。同时,将新节点的 _next 指针指向头节点,完成循环链表的连接。最后,更新头节点的 _prev 指针,使其指向新节点,确保链表的连接是完整的。
需要注意的是,这个函数在链表末尾添加了一个新元素,不影响其他元素的相对位置。
8.push_front
void push_front(const T& x)
{insert(begin(), x); // 调用 insert 函数,在头部插入新元素 x
}
这个函数简单地调用了 insert 函数,将新元素 x 插入到链表的头部。
9.insert
iterator insert(iterator pos, const T& x)
{Node* cur = pos._node; // 获取当前位置的节点Node* prev = cur->_prev; // 获取当前位置节点的前一个节点Node* newnode = new Node(x); // 创建一个新节点,保存新元素 xprev->_next = newnode; // 更新前一个节点的下一个指针,指向新节点newnode->_prev = prev; // 新节点的前一个指针指向前一个节点newnode->_next = cur; // 新节点的下一个指针指向当前位置节点cur->_prev = newnode; // 当前位置节点的前一个指针指向新节点,完成插入操作return iterator(newnode); // 返回指向新节点的迭代器
}
在 insert 函数中,首先获取当前位置节点 pos 和其前一个节点 prev,然后创建一个新节点 newnode 并将新元素 x 存储在新节点中。接着,更新前一个节点的 _next 指针,使其指向新节点,然后更新新节点的 _prev 指针,使其指向前一个节点。同时,将新节点的 _next 指针指向当前位置节点 cur,完成插入操作。最后,更新当前位置节点的 _prev 指针,使其指向新节点,确保链表的连接是完整的。最后,函数返回一个指向新节点的迭代器,表示插入操作完成后的位置。
10.erase
iterator erase(iterator pos)
{assert(pos != end()); // 断言:确保 pos 不等于链表的结束迭代器Node* cur = pos._node; // 获取当前位置的节点Node* prev = cur->_prev; // 获取当前位置节点的前一个节点Node* next = cur->_next; // 获取当前位置节点的后一个节点prev->_next = next; // 更新前一个节点的下一个指针,指向后一个节点next->_prev = prev; // 更新后一个节点的前一个指针,指向前一个节点delete cur; // 删除当前位置的节点return iterator(next); // 返回指向后一个节点的迭代器,表示删除操作完成后的位置
}
这部分代码实现了从链表中删除指定位置元素的功能。
在 erase 函数中,首先使用断言来确保删除位置 pos 不是链表的结束迭代器。然后,获取当前位置节点 pos、其前一个节点 prev 和后一个节点 next。接着,更新前一个节点的 _next 指针,使其指向后一个节点,同时更新后一个节点的 _prev 指针,使其指向前一个节点。这样,当前位置节点就从链表中断开了。最后,释放当前位置节点的内存空间,并返回一个指向后一个节点的迭代器,表示删除操作完成后的位置。
11.pop_back()和pop_front()
void pop_back()
{erase(--end()); // 通过 erase 函数删除链表末尾的元素
}
pop_back 函数通过将链表的结束迭代器向前移动一个位置,然后调用 erase 函数来删除该位置的元素,实现了从链表末尾删除一个元素的操作。
void pop_front()
{erase(begin()); // 通过 erase 函数删除链表头部的元素
}
pop_front 函数直接调用 erase 函数,删除链表头部的元素,实现了从链表头部删除一个元素的操作。
这两个函数分别对应于从链表的末尾和头部删除元素的操作,通过调用 erase 函数来完成删除操作,从而保持了链表的连接性。
12.empty()、size()、front()和back()
bool list<T>::empty() const
{return begin() == end(); // 判断 begin() 是否等于 end() 来确定是否为空
}typename list<T>::size_t list<T>::size() const
{size_t count = 0;for (const_iterator it = begin(); it != end(); ++it){++count;}return count; // 遍历链表来计算元素个数
}typename list<T>::reference list<T>::front()
{assert(!empty()); // 如果链表为空,则抛出断言return *begin(); // 返回链表的第一个元素
}typename list<T>::const_reference list<T>::front() const
{assert(!empty()); // 如果链表为空,则抛出断言return *begin(); // 返回链表的第一个元素
}typename list<T>::reference list<T>::back()
{assert(!empty()); // 如果链表为空,则抛出断言return *(--end()); // 返回链表的最后一个元素
}typename list<T>::const_reference list<T>::back() const
{assert(!empty()); // 如果链表为空,则抛出断言return *(--end()); // 返回链表的最后一个元素
}
上述代码实现了 empty() 函数用于判断链表是否为空,size() 函数用于获取链表元素个数,front() 函数用于获取链表第一个元素,以及 back() 函数用于获取链表最后一个元素。注意函数中的断言用于确保在链表为空时不执行非法操作。
13.resize
template<class T>
void list<T>::resize(size_t n, const T& val)
{if (n < size()) {iterator it = begin();std::advance(it, n); // 定位到新的尾部位置while (it != end()) {it = erase(it); // 从尾部截断,删除多余的元素}}else if (n > size()) {insert(end(), n - size(), val); // 插入足够数量的默认值元素}
}
如果 n 小于当前链表的大小size(),意味着你想要缩小链表的大小。在这种情况下,函数会迭代遍历链表,从尾部开始删除多余的元素,直到链表的大小等于 n。
首先,函数会使用 begin() 获取链表的起始迭代器,然后使用 std::advance 函数将迭代器向前移动 n 个位置,使其指向新的尾部位置。
接下来,函数使用 erase 函数将从新尾部位置到链表末尾的所有元素删除,从而使链表的大小减小到 n。
如果 n 大于当前链表的大小,表示你想要增大链表的大小。在这种情况下,函数会插入足够数量的值为 val 的元素到链表的末尾,直到链表的大小等于 n。
函数会使用 insert 函数在链表的末尾插入 n - size() 个值为 val 的元素,从而使链表的大小增大到 n。
14.赋值运算符重载
list<T>& operator=(list<T> lt)
{swap(lt); // 交换当前对象和传入对象的内容return *this; // 返回当前对象的引用
}
这是一个赋值运算符重载函数,它采用了拷贝并交换(Copy and Swap)的技巧来实现赋值操作。
这是一个成员函数,用于将一个 list<T> 类型的对象赋值给当前的对象。
参数 lt 是通过值传递的,所以会调用 list<T> 的拷贝构造函数创建一个临时副本。
然后,通过 swap(lt) 调用 swap 函数来交换当前对象和临时副本的内容。在交换后,临时副本的数据会被赋值给当前对象,而临时副本会被销毁。由于交换是高效的操作,可以避免大量的数据复制。
最后,函数返回当前对象的引用,以支持连续赋值操作。
这种方式不仅避免了手动管理内存的麻烦,还确保了异常安全,因为临时副本在函数结束时会被正确销毁。
list模拟实现全部代码
#pragma once#include <assert.h>
#include <iostream>namespace xzq
{template<class T>struct list_node{T _data;list_node<T>* _next;list_node<T>* _prev;list_node(const T& x = T()):_data(x), _next(nullptr), _prev(nullptr){}};template<class T, class Ref, class Ptr>struct __list_iterator{typedef list_node<T> Node;typedef __list_iterator<T, Ref, Ptr> iterator;typedef bidirectional_iterator_tag iterator_category;typedef T value_type;typedef Ptr pointer;typedef Ref reference;typedef ptrdiff_t difference_type;Node* _node;__list_iterator(Node* node):_node(node){}bool operator!=(const iterator& it) const{return _node != it._node;}bool operator==(const iterator& it) const{return _node == it._node;}Ref operator*(){return _node->_data;}Ptr operator->(){ return &(operator*());}// ++ititerator& operator++(){_node = _node->_next;return *this;}// it++iterator operator++(int){iterator tmp(*this);_node = _node->_next;return tmp;}// --ititerator& operator--(){_node = _node->_prev;return *this;}// it--iterator operator--(int){iterator tmp(*this);_node = _node->_prev;return tmp;}};template<class T>class list{typedef list_node<T> Node;public:typedef __list_iterator<T, T&, T*> iterator;typedef __list_iterator<T, const T&, const T*> const_iterator;typedef __reverse_iterator<iterator, T&, T*> reverse_iterator;typedef __reverse_iterator<const_iterator, const T&, const T*> const_reverse_iterator;const_iterator begin() const{return const_iterator(_head->_next);}const_iterator end() const{return const_iterator(_head);}iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}reverse_iterator rbegin(){return reverse_iterator(end());}reverse_iterator rend(){return reverse_iterator(begin());}void empty_init(){_head = new Node;_head->_next = _head;_head->_prev = _head;}template <class InputIterator> list(InputIterator first, InputIterator last){empty_init();while (first != last){push_back(*first);++first;}}list(){empty_init();}void swap(list<T>& x){std::swap(_head, x._head);}list(const list<T>& lt){empty_init();list<T> tmp(lt.begin(), lt.end());swap(tmp);}list<T>& operator=(list<T> lt){swap(lt);return *this;}~list(){clear();delete _head;_head = nullptr;}void clear(){iterator it = begin();while (it != end()){it = erase(it);}}void push_back(const T& x){Node* tail = _head->_prev;Node* newnode = new Node(x);tail->_next = newnode;newnode->_prev = tail;newnode->_next = _head;_head->_prev = newnode;//insert(end(), x);}void push_front(const T& x){insert(begin(), x);}iterator insert(iterator pos, const T& x){Node* cur = pos._node;Node* prev = cur->_prev;Node* newnode = new Node(x);prev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}void pop_back(){erase(--end());}void pop_front(){erase(begin());}iterator erase(iterator pos){assert(pos != end());Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;prev->_next = next;next->_prev = prev;delete cur;return iterator(next);}bool list<T>::empty() const{return begin() == end(); // 判断 begin() 是否等于 end() 来确定是否为空}typename list<T>::size_t list<T>::size() const{size_t count = 0;for (const_iterator it = begin(); it != end(); ++it){++count;}return count; // 遍历链表来计算元素个数}typename list<T>::reference list<T>::front(){assert(!empty()); // 如果链表为空,则抛出断言return *begin(); // 返回链表的第一个元素}typename list<T>::const_reference list<T>::front() const{assert(!empty()); // 如果链表为空,则抛出断言return *begin(); // 返回链表的第一个元素}typename list<T>::reference list<T>::back(){assert(!empty()); // 如果链表为空,则抛出断言return *(--end()); // 返回链表的最后一个元素}typename list<T>::const_reference list<T>::back() const{assert(!empty()); // 如果链表为空,则抛出断言return *(--end()); // 返回链表的最后一个元素}void resize(size_t n, const T& val = T()){if (n < size()) {iterator it = begin();std::advance(it, n);while (it != end()) {it = erase(it); // 从尾部截断,删除多余的元素}}else if (n > size()) {insert(end(), n - size(), val); // 插入足够数量的默认值元素}}private:Node* _head;};
}
list 和 vector的区别
通过模拟实现 list 和 vector,你可以更好地理解它们之间的区别和特点。这两者是 C++ 标准库中的序列式容器,但它们在内部实现和使用场景上有很大的区别。
底层实现:
list通常是一个双向链表,每个节点都包含了数据和指向前一个和后一个节点的指针。这使得在任何位置进行插入和删除操作都是高效的,但随机访问和内存占用可能相对较差。
vector是一个动态数组,元素在内存中是连续存储的。这使得随机访问非常高效,但插入和删除操作可能需要移动大量的元素,效率较低。
插入和删除操作:
在
list中,插入和删除操作是高效的,无论是在容器的任何位置还是在开头和结尾。这使得list在需要频繁插入和删除操作时非常适用。
在vector中,插入和删除操作可能需要移动元素,特别是在容器的中间或开头。因此,当涉及大量插入和删除操作时,vector可能不如list效率高。
随机访问:
list不支持随机访问,即不能通过索引直接访问元素,必须通过迭代器逐个遍历。
vector支持随机访问,可以通过索引快速访问元素,具有良好的随机访问性能。
内存占用:
由于
list使用链表存储元素,每个节点都需要额外的指针来指向前后节点,可能会导致更多的内存占用。
vector在内存中是连续存储的,通常占用的内存较少。
迭代器失效:
在
list中,插入和删除操作不会导致迭代器失效,因为节点之间的关系不会改变。
在vector中,插入和删除操作可能导致内存重新分配,从而使原来的迭代器失效。
综上所述,如果你需要频繁进行插入和删除操作,而对于随机访问性能没有特别高的要求,那么使用 list 是一个不错的选择。而如果你更注重随机访问性能,可以选择使用 vector。当然,在实际开发中,还需要根据具体情况权衡使用哪种容器。
结语
有兴趣的小伙伴可以关注作者,如果觉得内容不错,请给个一键三连吧,蟹蟹你哟!!!
制作不易,如有不正之处敬请指出
感谢大家的来访,UU们的观看是我坚持下去的动力
在时间的催化剂下,让我们彼此都成为更优秀的人吧!!!
(创作128天纪念日,暂时还没有想好怎么分享,下次再写喽)
相关文章:
C++初阶之一篇文章教会你list(模拟实现)
list(模拟实现) list模拟实现list_node节点结构定义std::__reverse_iterator逆向迭代器实现list迭代器 __list_iterator定义list类成员定义list成员函数定义1.begin()、end()、rbegin()和rend()2.empty_init()3.构造函数定义4.swap5.析构函数定义6.clear…...
设备工单管理系统如何实现工单流程自动化?
设备工单管理系统属于工单系统的一种,基于其丰富的功能,它可以同时处理不同的多组流程,旨在有效处理发起人提交的事情,指派相应人员完成服务请求和记录全流程。该系统主要面向后勤管理、设备维护、物业管理、酒店民宿等服务行业设…...

ubuntu20.04.6anzhuang mtt s80
需要打开主板的Resize BAR和Above 4G功能,否则GPU显存不能被正确识别; 2. 在某些不支持PCIe Gen5的主板上,需要把PCIe速率由auto设置为PCIe Gen4速率; sudo apt install lightdm unity-greetersheding lightdm : lightdm sudo apt install /…...

【LeetCode-中等】剑指 Offer 36. 二叉搜索树与双向链表
题目链接 剑指 Offer 36. 二叉搜索树与双向链表 标签 后序遍历、二叉搜索树 步骤 二叉搜索树中的任一节点的直接前驱为其左子树的最右侧节点,直接后继为其右子树的最左侧节点。因此,可以通过这个关系来操作原来的二叉树。为了不影响深度较大的节点的…...
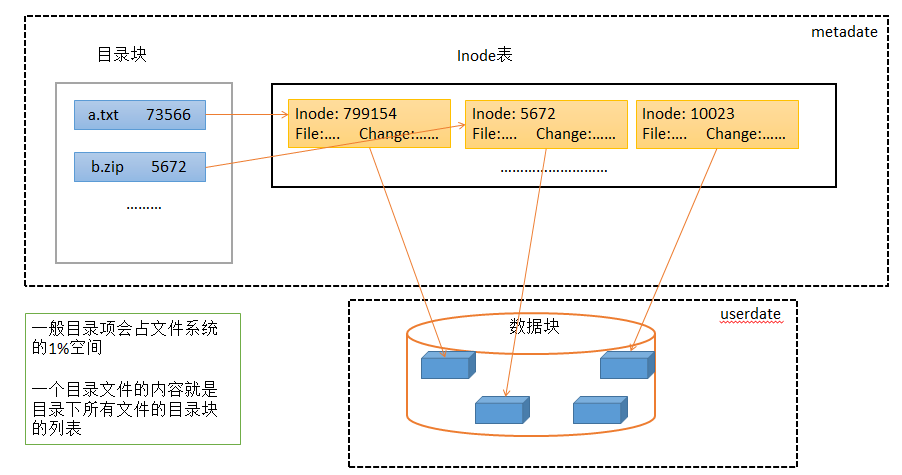
Linux —— 文件系统
目录 一,背景 二,文件系统 一,磁盘简介 磁盘分为SSD、机械磁盘;机械磁盘,即磁盘高速转动,磁头移动到读写扇区所在磁道,让磁头在目标扇区上划过,即可完成对扇区的读写操作ÿ…...

自然策略优化的解释 Natural Policy Optimization
Natural Policy Optimization(自然策略优化)是一种用于优化策略梯度算法的方法。它是基于概率策略的强化学习算法,旨在通过迭代地更新策略参数来最大化累积回报。 传统的策略梯度算法通常使用梯度上升法来更新策略参数,但这种方法…...

docker基本使用方法
docker使用 1. Docker 介绍 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。Docker 使您能够将应用程序与基础架构分开,从而可以快速交付软件。通过利用 …...
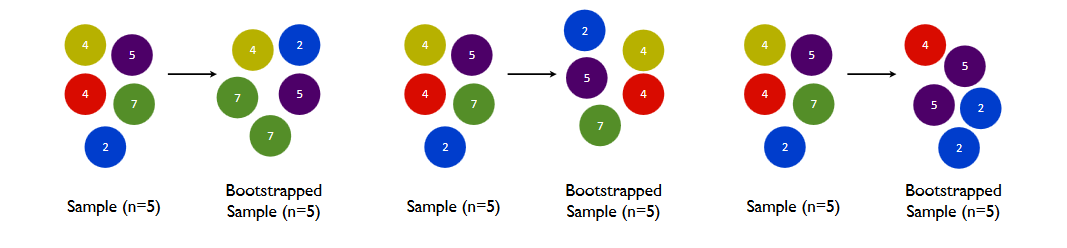
机器学习(十八):Bagging和随机森林
全文共10000余字,预计阅读时间约30~40分钟 | 满满干货(附数据及代码),建议收藏! 本文目标:理解什么是集成学习,明确Bagging算法的过程,熟悉随机森林算法的原理及其在Sklearn中的各参数定义和使用方法 代码…...
使用蓝牙外设却不小心把台式机电脑蓝牙关了
起因 今天犯了一个贼SB的错误,起因是蓝牙键盘突然就不能输入了(虽然是连接状态,但是按什么键都没有反应) 原来我的解决方法就是重启一下电脑,但是那会电脑开了贼多的软件。我就想重启也太麻烦了,既然重启…...

美国Linux服务器安装Grafana和配置zabbix数据源的教程
美国Linux服务器的Grafana工具是跨平台、开源、时序和可视化面板Dashboard监控平台工具,是在日常管理中帮忙提高效率的实用工具,可以通过将采集的美国Linux服务器系统数据查询后,进行可视化的展示及通知,本文小编就来介绍下美国Li…...

[ROS安装问题] rosdep update 失败报错
【关于ROS安装】 由于日益复杂的国际形势,按照wiki官网的ROS安装流程变得相当困难,这里我推荐使用鱼香ROS大佬写的脚本一键傻瓜式安装: wget http://fishros.com/install -O fishros && . fishros 【关于rosdep失败】 这已经是一…...

Vue2到3 Day5 全套学习内容,众多案例上手(内付源码)
简介: Vue2到3 Day1-3 全套学习内容,众多案例上手(内付源码)_星辰大海1412的博客-CSDN博客本文是一篇入门级的Vue.js介绍文章,旨在帮助读者了解Vue.js框架的基本概念和核心功能。Vue.js是一款流行的JavaScript前端框架…...
STM32 CubeMX (uart_IAP串口)简单示例
STM32 CubeMX STM32 CubeMX (串口IAP) STM32 CubeMXIAP有什么用?整体思路 一、STM32 CubeMX 设置时钟树UART使能UART初始化设置 二、代码部分文件移植
Kafka:安装和配置
producer:发布消息的对象,称为消息产生者 (Kafka topic producer) topic:Kafka将消息分门别类,每一个消息称为一个主题(topic) consumer:订阅消息并处理发布消息的对象…...

786. 第k个数
文章目录 QuestionIdeasCode Question 给定一个长度为 n 的整数数列,以及一个整数 k ,请用快速选择算法求出数列从小到大排序后的第 k 个数。 输入格式 第一行包含两个整数 n 和 k 。 第二行包含 n 个整数(所有整数均在 1∼109 范围内&…...

用友-NC-Cloud远程代码执行漏洞[2023-HW]
用友-NC-Cloud远程代码执行漏洞[2023-HW] 一、漏洞介绍二、资产搜索三、漏洞复现PoC小龙POC检测脚本: 四、修复建议 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失&#…...
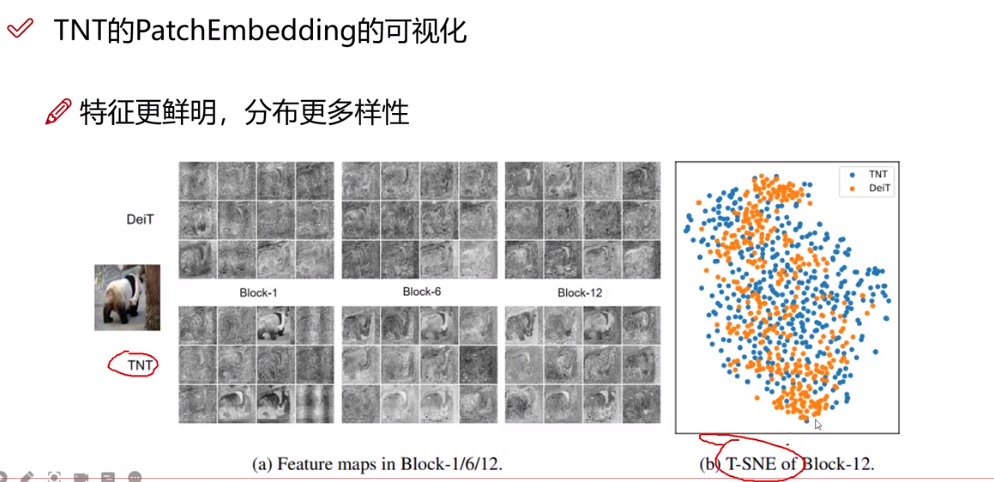
Transformer(二)(VIT,TNT)(基于视觉CV)
目录 1.视觉中的Attention 2.VIT框架(图像分类,不需要decoder) 2.1整体框架 2.2.CNN和Transformer遇到的问题 2.3.1CNN 2.3.2Transformer 2.3.3二者对比 2.4.公式理解 3TNT 参考文献 1.视觉中的Attention 对于人类而言看到一幅图可以立…...

Scratch 详解 之 线性→代数之——求两线段交点坐标
可能有人要问:求交点坐标有什么用呢?而且为啥要用线代来求?直线方程不行吗??? 这个问题,我只能说,直线方程计算的次数过多了,而且动不动就要考虑线的方向,90的…...

Python-组合数据类型
今天要介绍的是Python的组合数据类型 整理不易,希望得到大家的支持,欢迎各位读者评论点赞收藏 感谢! 目录 知识点知识导图1、组合数据类型的基本概念1.1 组合数据类型1.2 集合类型概述1.3 序列类型概述1.4 映射类型概述 2、列表类型2.1 列表的…...

vue3+vue-simple-uploader实现大文件上传
vue-simple-uploader本身是基于vue2实现,如果要使用vue3会报错。如何在vue3中使用,可参考我的另一篇文章:解决vue3中不能使用vue-simple-uploader__Jyann_的博客-CSDN博客 一.实现思路 使用vue-simple-uploader组件的uploader组件,设置自动上传为false,即可开启手动上传。…...

Python 3.12 Key Words - 02 - True、 False、 None
Python 3.12 Key Words - True、 False、 None在 Python 的 35 个硬关键字中,True、False 和 None 属于内置常量。它们不是普通的变量,而是语言本身定义的单例对象,分别代表布尔真、布尔假和“空值”。理解这三个常量是掌握 Python 逻辑判…...

实战构建抖音直播弹幕采集系统:DouyinLiveWebFetcher技术实现方案
实战构建抖音直播弹幕采集系统:DouyinLiveWebFetcher技术实现方案 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2025最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetcher 在社交媒…...

C#与VM二次开发实战:从零构建工业视觉上位机应用
1. 工业视觉上位机开发入门指南 第一次接触工业视觉上位机开发时,我被各种专业术语搞得晕头转向。VM(VisionMaster)作为国内主流的视觉平台,其实用C#进行二次开发并没有想象中那么难。这里分享下我的实战经验,帮助大家…...
)
AI原生研发为何90%团队卡在L2?AISMM成熟度评估实战手册(含自测评分表V2.3)
第一章:AISMM模型详解:AI原生软件研发成熟度评估 2026奇点智能技术大会(https://ml-summit.org) AISMM(AI-native Software Maturity Model)是由ML-Summit联合工业界与学术界共同提出的开源评估框架,专为衡量组织在AI…...

YOLO11和dlib实战:如何用Python在10分钟内搞定一个简易疲劳检测脚本?
YOLO11与dlib极简实战:10分钟搭建Python疲劳检测原型 从理论到实践的快速验证 在计算机视觉领域,快速验证算法可行性是每个开发者都面临的挑战。传统方案往往需要搭建完整的Web系统或移动应用,这对于算法验证而言显得过于沉重。本文将展示如何…...

Sunshine终极故障排除指南:8个常见场景的快速解决方案
Sunshine终极故障排除指南:8个常见场景的快速解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine作为自托管的游戏串流服务器,为用户提供了强…...

避坑指南:用System Generator生成FPGA滤波代码,为什么我劝你谨慎?
警惕图形化工具陷阱:FPGA数字滤波开发的硬核真相 在FPGA开发领域,图形化设计工具如System Generator常被宣传为"快速实现复杂算法"的银弹。许多初入行的工程师会被其直观的拖拽界面和自动代码生成功能所吸引,尤其是在处理数字滤波这…...

用MCNP模拟NaI探测器:从137铯源设置到能谱分析的全流程实战
用MCNP模拟NaI探测器:从137铯源设置到能谱分析的全流程实战 在核技术研究领域,精确模拟探测器响应是实验设计的关键环节。NaI(Tl)闪烁体探测器因其高探测效率和良好的能量分辨率,成为测量伽马射线的首选设备之一。本文将带你完成一个完整的MC…...

G-Helper实战指南:华硕笔记本性能控制与系统优化的开源解决方案
G-Helper实战指南:华硕笔记本性能控制与系统优化的开源解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, …...

把断点从框架泥潭里拽出来, 重新认识 ABAP NetWeaver 7.0 EHP2 里的 SLAD
卡在框架代码里的那个时刻 在很多老的 SAP 项目里, 真正让人头疼的, 不是没有调试器, 而是明明已经进了调试器, 却还是到不了业务代码。一个看起来普通的报错, 背后可能先经过 Web Dynpro 运行时, 再穿过一层又一层框架调用, 还可能裹着 ALV、接口封装、增强点和通用服务类。我…...