Python-组合数据类型
今天要介绍的是Python的组合数据类型
整理不易,希望得到大家的支持,欢迎各位读者评论点赞收藏
感谢!
目录
- 知识点
- 知识导图
- 1、组合数据类型的基本概念
- 1.1 组合数据类型
- 1.2 集合类型概述
- 1.3 序列类型概述
- 1.4 映射类型概述
- 2、列表类型
- 2.1 列表的定义
- 2.2 列表的索引
- 2.3 列表的切片
- 3、列表类型的操作
- 3.1 列表的操作函数
- 3.2 列表的操作方法
- 4、字典类型
- 4.1 字典的定义
- 4.2 字典的索引
- 5、字典类型的操作
- 5.1 字典的操作函数
- 5.2 字典的操作方法
- 6、实例解析:文本词频统计
- 小结
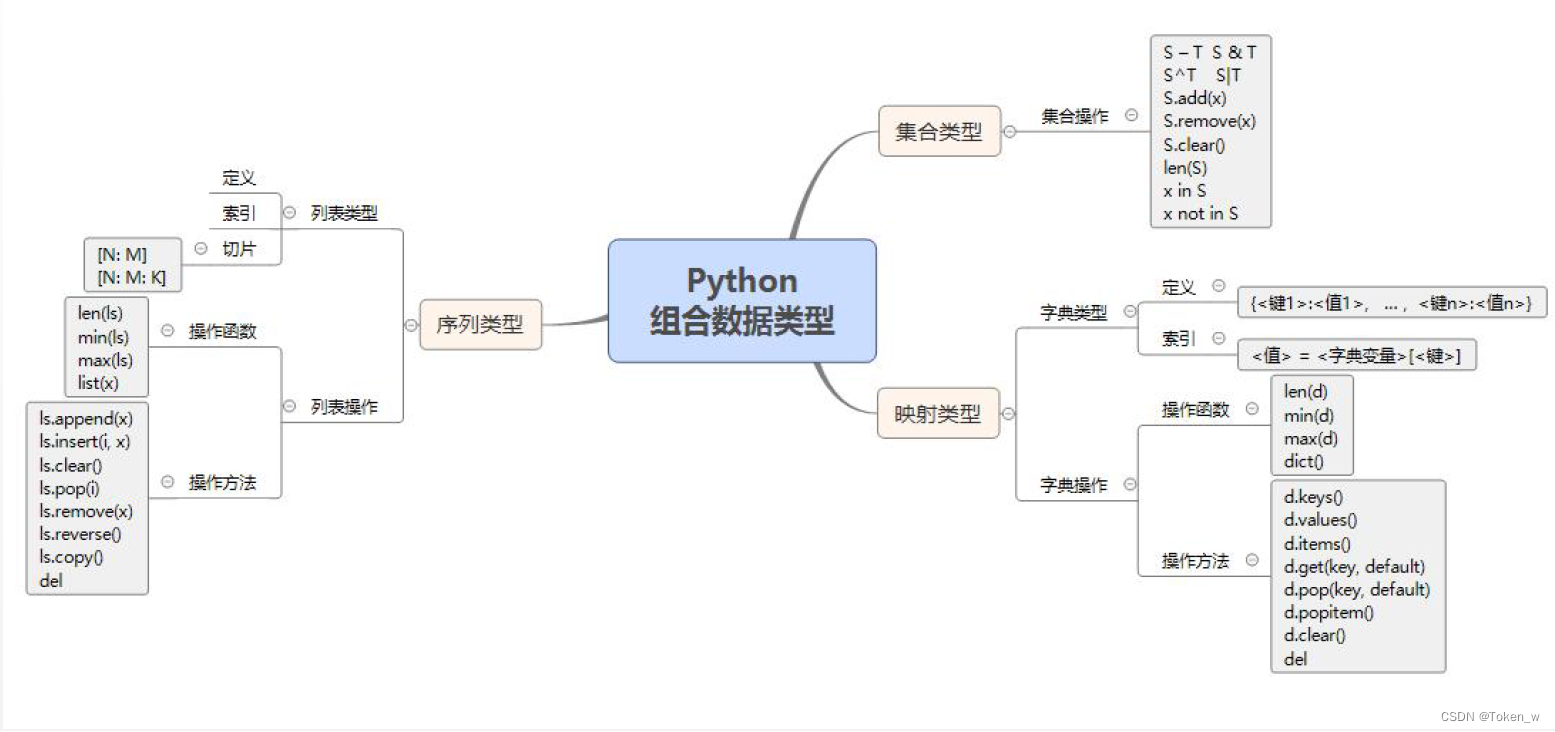
知识点
- 组合数据类型的基本概念
- 列表类型:定义、索引、切片
- 列表类型的操作:列表的操作函数、列表的操作方法
- 字典类型:定义、索引
- 字典类型的操作:字典的操作函数、字典的操作方法
知识导图
1、组合数据类型的基本概念
1.1 组合数据类型
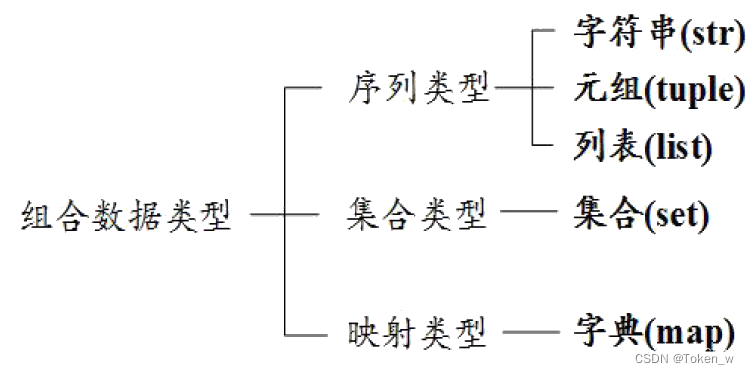
- Python语言中最常用的组合数据类型有3大类,分别是集合类型、序列类型和映射类型。
- 集合类型是一个具体的数据类型名称,而序列类型和映射类型是一类数据类型的总称。
- 集合类型是一个元素集合,元素之间无序,相同元素在集合中唯一存在。
- 序列类型是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排他。序列类型的典型代表是字符串类型和列表类型。
- 映射类型是“键-值”数据项的组合,每个元素是一个键值对,表示为(key, value)。映射类型的典型代表是字典类型。
1.2 集合类型概述
- Python语言中的集合类型与数学中的集合概念一致,即包含0个或多个数据项的无序组合。
- 集合是无序组合,用大括号({})表示,它没有索引和位置的概念,集合中元素可以动态增加或删除。
- 集合中元素不可重复,元素类型只能是固定数据类型,例如:整数、浮点数、字符串、元组等,列表、字典和集合类型本身都是可变数据类型,不能作为集合的元素出现。
S = {1010, "1010", 78.9}
print(type(S))
# <class 'set'>
print(len(S))
# 3
print(S)
# {78.9, 1010, '1010'}
- 需要注意,由于集合元素是无序的,集合的打印效果与定义顺序可以不一致。由于集合元素独一无二,使用集合类型能够过滤掉重复元素。
T = {1010, "1010", 12.3, 1010, 1010}
print(T)
# {1010, '1010', 12.3}
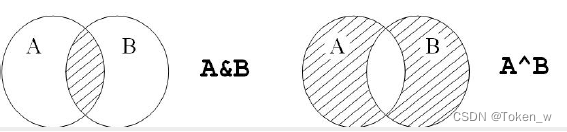
- 集合类型有4个操作符,交集(&)、并集(|)、差集(-)、补集(^),操作逻辑与数学定义相同。
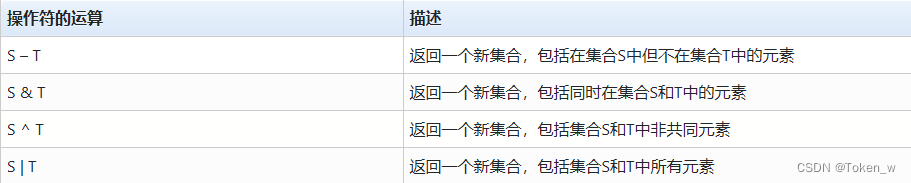

S = {1010, "1010", 78.9}
T = {1010, "1010", 12.3, 1010, 1010}
print(S - T)
# {78.9}
print(T – S)
# {12.3}
print(S & T)
# {1010, '1010'}
print(T & S)
# {1010, '1010'}
print(S ^ T)
# {78.9, 12.3}
print(T ^ S)
# {78.9, 12.3}
print(S | T)
# {78.9, 1010, 12.3, '1010'}
print(T | S)
# {1010, 12.3, 78.9, '1010'}
- 集合类型有一些常用的操作函数或方法
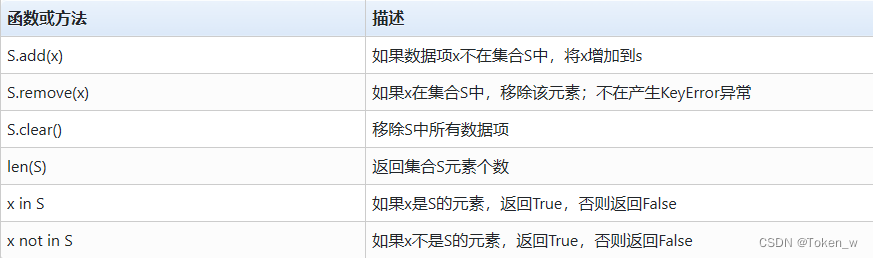
- 集合类型主要用于元素去重,适合于任何组合数据类型。
S = set('知之为知之不知为不知')
print(S)
# {'不', '为', '之', '知'}
for i in S:print(i, end="")
# 不为之知
1.3 序列类型概述
- 序列类型是一维元素向量,元素之间存在先后关系,通过序号访问。
- 由于元素之间存在顺序关系,所以序列中可以存在相同数值但位置不同的元素。Python语言中有很多数据类型都是序列类型,其中比较重要的是:字符串类型和列表类型,此外还包括元组类型。
- 字符串类型可以看成是单一字符的有序组合,属于序列类型。列表则是一个可以使用多种类型元素的序列类型。序列类型使用相同的索引体系,即正向递增序号和反向递减序号。

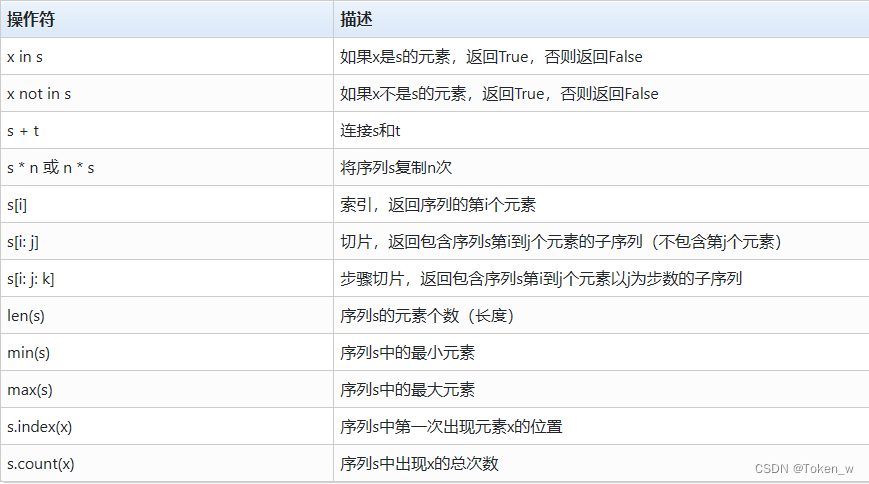
- 序列类型有一些通用的操作符和函数
1.4 映射类型概述
-
映射类型是“键-值”数据项的组合,每个元素是一个键值对,即元素是(key, value),元素之间是无序的。键值对是一种二元关系,源于属性和值的映射关系
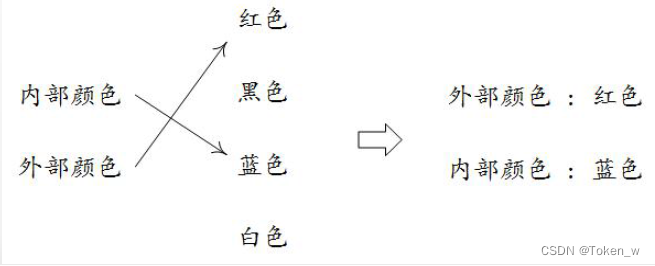
-
映射类型是序列类型的一种扩展。在序列类型中,采用从0开始的正向递增序号进行具体元素值的索引。而映射类型则由用户来定义序号,即键,用其去索引具体的值。
-
键(key)表示一个属性,也可以理解为一个类别或项目,值(value)是属性的内容,键值对刻画了一个属性和它的值。键值对将映射关系结构化,用于存储和表达。
2、列表类型
2.1 列表的定义
- 列表是包含0个或多个元组组成的有序序列,属于序列类型。列表可以元素进行增加、删除、替换、查找等操作。列表没有长度限制,元素类型可以不同,不需要预定义长度。
- 列表类型用中括号([])表示,也可以通过list(x)函数将集合或字符串类型转换成列表类型。
ls = [1010, "1010", [1010, "1010"], 1010]
print(ls)
# [1010, '1010', [1010, '1010'], 1010]
print(list('列表可以由字符串生成'))
# ['列', '表', '可', '以', '由', '字', '符', '串', '生', '成']
print(list())
# []
- 列表属于序列类型,所以列表类型支持序列类型对应的操作
2.2 列表的索引
- 索引是列表的基本操作,用于获得列表的一个元素。使用中括号作为索引操作符。
ls = [1010, "1010", [1010, "1010"], 1010]
print(ls[3])
# 1010
print(ls[-2])
# [1010, '1010']
print(ls[5])
'''
Traceback (most recent call last):File "<pyshell#35>", line 1, in <module>ls[5]
IndexError: list index out of range'''
- 可以使用遍历循环对列表类型的元素进行遍历操作,基本使用方式如下:
for <循环变量> in <列表变量>:<语句块>
ls = [1010, "1010", [1010, "1010"], 1010]
for i in ls:print(i*2)
'''
2020
10101010
[1010, '1010', 1010, '1010']
2020'''
2.3 列表的切片
- 切片是列表的基本操作,用于获得列表的一个片段,即获得一个或多个元素。切片后的结果也是列表类型。切片有两种使用方式:
<列表或列表变量>[N: M]或<列表或列表变量>[N: M: K]
- 切片获取列表类型从N到M(不包含M)的元素组成新的列表。当K存在时,切片获取列表类型从N到M(不包含M)以K为步长所对应元素组成的列表。
ls = [1010, "1010", [1010, "1010"], 1010]
print(ls[1:4])
# ['1010', [1010, '1010'], 1010]
print(ls[-1:-3])
# []
print(ls[-3:-1])
# ['1010', [1010, '1010']]
print(ls[0:4:2])
# [1010, [1010, '1010']]
3、列表类型的操作
3.1 列表的操作函数
- 列表类型继承序列类型特点,有一些通用的操作函数
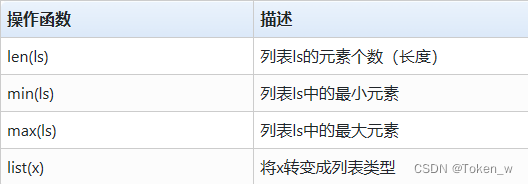
ls = [1010, "1010", [1010, "1010"], 1010]
print(len(ls))
# 4
lt =["Python", ["1010", 1010, [
1010, "
Python"]]]
print(len(lt))
# 2
- min(ls)和max(ls)分别返回一个列表的最小或最大元素,使用这两个函数的前提是列表中各元素类型可以进行比较。
ls = [1010, 10.10, 0x1010]
print(min(ls))
# 10.1
lt = ["1010", "10.10", "Python"]
print(max(lt))
# 'Python'
ls = ls + lt
print(ls)
# [1010, 10.1, 4112, '1010', '10.10', 'Python']
print(min(ls))
'''
Traceback (most recent call last):File "<pyshell#15>", line 1, in <module>min(ls)
TypeError: '<' not supported between instances of 'str' and 'float''''
- list(x)将变量x转变成列表类型,其中x可以是字符串类型,也可以是字典类型。
print(list("Python"))
# ['P', 'y', 't', 'h', 'o', 'n']
print(list({"小明", "小红", "小白", "小新"}))
# ['小红', '小明', '小新', '小白']
print(list({"201801":"小明", "201802":"小红", "201803":"小白"}))
# ['201801', '201802', '201803']
3.2 列表的操作方法
- 列表类型存在一些操作方法,使用语法形式是:
<列表变量>.<方法名称>(<方法参数>)
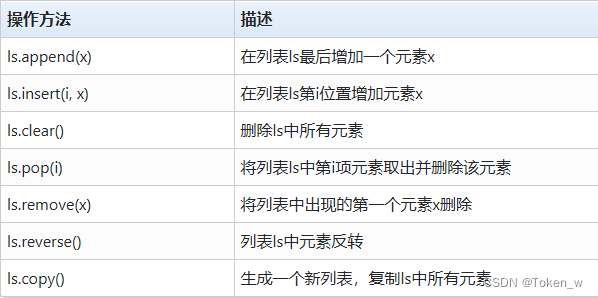
- ls.append(x)在列表ls最后增加一个元素x。
lt = ["1010", "10.10", "Python"]
lt.append(1010)
print(lt)
# ['1010', '10.10', 'Python', 1010]
lt.append([1010, 0x1010])
print(lt)
# ['1010', '10.10', 'Python', 1010, [1010, 4112]]
- ls.append(x)仅用于在列表中增加一个元素,如果希望增加多个元素,可以使用加号,将两个列表合并。
lt = ["1010", "10.10", "Python"]
ls = [1010, [1010, 0x1010]]
ls += lt
print(lt)
['1010', '10.10', 'Python', 1010, [1010, 4112]]
- ls.insert(i, x)在列表ls中序号i位置上增加元素x,序号i之后的元素序号依次增加。
lt = ["1010", "10.10", "Python"]
lt.insert(1, 1010)
print(lt)
# ['1010', 1010, '10.10', 'Python']
- ls.clear()将列表ls的所有元素删除,清空列表。
lt = ["1010", "10.10", "Python"]
lt.clear()
print(lt)
# []
- ls.pop(i)将返回列表ls中第i位元素,并将该元素从列表中删除。
lt = ["1010", "10.10", "Python"]
print(lt.pop(1))
# 10.10
print(lt)
# ["1010", "Python"]
- ls.remove(x)将删除列表ls中第一个出现的x元素。
lt = ["1010", "10.10", "Python"]
lt.remove("10.10")
print(lt)
# ["1010", "Python"]
- 除了上述方法,还可以使用Python保留字del对列表元素或片段进行删除,使用方法如下:
del <列表变量>[<索引序号>] 或del <列表变量>[<索引起始>: <索引结束>]
lt = ["1010", "10.10", "Python"]
del lt[1]
print(lt)
# ["1010", "Python"]
lt = ["1010", "10.10", "Python"]
del lt[1:]
print(lt)
# ["1010"]
- ls.reverse()将列表ls中元素进行逆序反转。
lt = ["1010", "10.10", "Python"]
print(lt.reverse())
# ['Python', '10.10', '1010']
- ls.copy() 复制ls中所有元素生成一个新列表。
lt = ["1010", "10.10", "Python"]
ls = lt.copy()
lt.clear() # 清空lt
print(ls)
# ["1010", "10.10", "Python"]
- 由上例看出,一个列表lt使用.copy()方法复制后赋值给变量ls,将lt元素清空不影响新生成的变量ls。
- 需要注意,对于基本的数据类型,如整数或字符串,可以通过等号实现元素赋值。但对于列表类型,使用等号无法实现真正的赋值。其中,ls = lt语句并不是拷贝lt中元素给变量ls,而是新关联了一个引用,即ls和lt所指向的是同一套内容。
lt = ["1010", "10.10", "Python"]
ls = lt # 仅使用等号
lt.clear()
print(ls)
# []
- 使用索引配合等号(=)可以对列表元素进行修改。
lt = ["1010", "10.10", "Python"]
lt[1] = 1010
print(lt)
# ["1010", 1010, "Python"]
- 列表是一个十分灵活的数据结构,它具有处理任意长度、混合类型的能力,并提供了丰富的基础操作符和方法。当程序需要使用组合数据类型管理批量数据时,请尽量使用列表类型。
4、字典类型
4.1 字典的定义
- “键值对”是组织数据的一种重要方式,广泛应用在Web系统中。键值对的基本思想是将“值”信息关联一个“键”信息,进而通过键信息查找对应值信息,这个过程叫映射。Python语言中通过字典类型实现映射。
- Python语言中的字典使用大括号{}建立,每个元素是一个键值对,使用方式如下:
{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
- 其中,键和值通过冒号连接,不同键值对通过逗号隔开。字典类型也具有和集合类似的性质,即键值对之间没有顺序且不能重复。
- 变量d可以看作是“学号”与“姓名”的映射关系。需要注意,字典各个元素并没有顺序之分。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(d)
# {'201801': '小明', '201802': '小红', '201803': '小白'}
4.2 字典的索引
- 列表类型采用元素顺序的位置进行索引。由于字典元素“键值对”中键是值的索引,因此,可以直接利用键值对关系索引元素。
- 字典中键值对的索引模式如下,采用中括号格式:
<值> = <字典变量>[<键>]
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(d["201802"])
# 小红
- 利用索引和赋值(=)配合,可以对字典中每个元素进行修改。
d["201802"] = '新小红'
print(d)
# {'201801': '小明', '201803': '小白', '201802': '新小红'}
- 使用大括号可以创建字典。通过索引和赋值配合,可以向字典中增加元素。
t = {}
t["201804"] = "小新"
print(d)
# {'201804': '小新'}
- 字典是存储可变数量键值对的数据结构,键和值可以是任意数据类型,通过键索引值,并可以通过键修改值。
5、字典类型的操作
5.1 字典的操作函数
- 字典类型有一些通用的操作函数
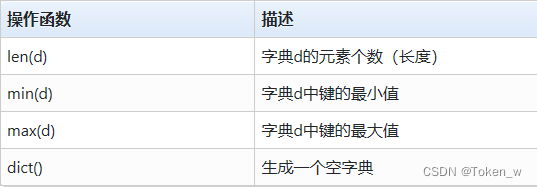
- len(d)给出字典d的元素个数,也称为长度。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(len(d))
# 3
- min(d)和max(d)分别返回字典d中最小或最大索引值。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(min(d))
# '201801'
print(max(d))
# '201803'
- dict()函数用于生成一个空字典,作用和{}一致。
d = dict()
print(d)
# {}
5.2 字典的操作方法
- 字典类型存在一些操作方法,使用语法形式是:
<字典变量>.<方法名称>(<方法参数>)

- d.keys()返回字典中的所有键信息,返回结果是Python的一种内部数据类型dict_keys,专用于表示字典的键。如果希望更好的使用返回结果,可以将其转换为列表类型。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.keys())
# dict_keys(['201801', '201802', '201803'])
print(type(d.keys()))
# <class 'dict_keys'>
print(list(d.keys()))
# ['201801', '201802', '201803']
- d.values()返回字典中的所有值信息,返回结果是Python的一种内部数据类型dict_values。如果希望更好的使用返回结果,可以将其转换为列表类型。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.values())
# dict_values(['小明', '小红', '小白'])
print(type(d.values()))
# <class 'dict_values'>
print(list(d.values()))
# ['小明', '小红', '小白']
- d.items()返回字典中的所有键值对信息,返回结果是Python的一种内部数据类型dict_items。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.items())
# dict_items([('201801', '小明'), ('201802', '小红'),('201803', '小白')])
print(type(d.items()))
# <class 'dict_items'>
print(list(d.items()))
# [('201801', '小明'), ('201802', '小红'), ('201803', '小白')]
- d.get(key, default)根据键信息查找并返回值信息,如果key存在则返回相应值,否则返回默认值,第二个元素default可以省略,如果省略则默认值为空。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.get('201802'))
'小红'
print(d.get('201804'))
print(d.get('201804', '不存在'))
'不存在'
- d.pop(key, default)根据键信息查找并取出值信息,如果key存在则返回相应值,否则返回默认值,第二个元素default可以省略,如果省略则默认值为空。相比d.get()方法,d.pop()在取出相应值后,将从字典中删除对应的键值对。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.pop('201802'))
# '小红'
print(d)
# {'201801': '小明', '201803': '小白'}
print(d.pop('201804', '不存在'))
# '不存在'
- d.popitem()随机从字典中取出一个键值对,以元组(key,value)形式返回。取出后从字典中删除这个键值对。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.popitem())
# ('201803', '小白')
print(d)
# {'201801': '小明', '201802': '小红'}
- d.clear()删除字典中所有键值对。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
d.clear()
print(d)
# {}
- 此外,如果希望删除字典中某一个元素, 可以使用Python保留字del。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
del d["201801"]
print(d)
# {'201802': '小红', '201803': '小白'}
- 字典类型也支持保留字in,用来判断一个键是否在字典中。如果在则返回True,否则返回False。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print("201801" in d)
# True
print("201804" in d)
# False
- 与其他组合类型一样,字典可以遍历循环对其元素进行遍历,基本语法结构如下:
for <变量名> in <字典名><语句块>
- for循环返回的变量名是字典的索引值。如果需要获得键对应的值,可以在语句块中通过get()方法获得。
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
for k in d:print("字典的键和值分别是:{}和{}".format(k, d.get(k)))
'''
字典的键和值分别是:201801和小明
字典的键和值分别是:201802和小红
字典的键和值分别是:201803和小白'''
6、实例解析:文本词频统计
-
在很多情况下,会遇到这样的问题:对于一篇给定文章,希望统计其中多次出现的词语,进而概要分析文章的内容。这个问题的解决可用于对网络信息进行自动检索和归档。
-
在信息爆炸时代,这种归档或分类十分有必要。这就是“词频统计”问题。
统计《哈姆雷特》英文词频 -
第一步:分解并提取英文文章的单词
通过txt.lower()函数将字母变成小写,排除原文大小写差异对词频统计的干扰。为统一分隔方式,可以将各种特殊字符和标点符号使用txt.replace()方法替换成空格,再提取单词。 -
第二步:对每个单词进行计数
if word in counts:
else:counts[word] = 1
或者,这个处理逻辑可以更简洁的表示为如下代码:
counts[word] = counts.get(word,0) + 1
- 第三步:对单词的统计值从高到低进行排序
由于字典类型没有顺序,需要将其转换为有顺序的列表类型,再使用sort()方法和lambda函数配合实现根据单词次数对元素进行排序。
items = list(counts.items())#将字典转换为记录列表
items.sort(key=lambda x:x[1], reverse=True) #以第2列排序
# CalHamlet.py
def getText():txt = open("hamlet.txt", "r").read()txt = txt.lower()for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':txt = txt.replace(ch, " ") #将文本中特殊字符替换为空格return txt
hamletTxt = getText()
words = hamletTxt.split()
counts = {}
for word in words:counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):word, count = items[i]print ("{0:<10}{1:>5}".format(word, count))>>>
the 1138
and 965
to 754
of 669
you 550
a 542
i 542
my 514
hamlet 462
in 436
小结
主要针对初学程序设计的读者,具体讲解了程序设计语言的基本概念,理解程序开发的IPO编写方法,配置Python开发环境的具体步骤,以及Python语言和Python程序特点等内容,进一步给出了5个简单Python实例代码,帮助读者测试Python开发环境,对该语言有一个直观认识。
Python大戏即将上演,一起来追剧吧。
相关文章:
Python-组合数据类型
今天要介绍的是Python的组合数据类型 整理不易,希望得到大家的支持,欢迎各位读者评论点赞收藏 感谢! 目录 知识点知识导图1、组合数据类型的基本概念1.1 组合数据类型1.2 集合类型概述1.3 序列类型概述1.4 映射类型概述 2、列表类型2.1 列表的…...

vue3+vue-simple-uploader实现大文件上传
vue-simple-uploader本身是基于vue2实现,如果要使用vue3会报错。如何在vue3中使用,可参考我的另一篇文章:解决vue3中不能使用vue-simple-uploader__Jyann_的博客-CSDN博客 一.实现思路 使用vue-simple-uploader组件的uploader组件,设置自动上传为false,即可开启手动上传。…...
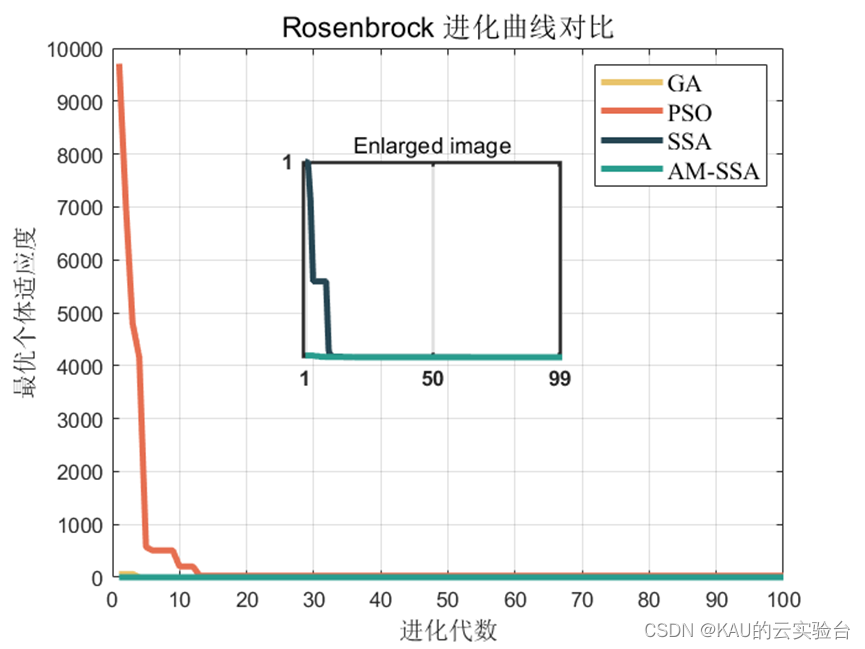
自适应变异麻雀搜索算法及其Matlab实现
麻雀搜索算法( sparrow search algorithm,SSA) 是2020 年新提出的一种元启发式算法[1],它是受麻雀种群的觅食和反捕食行为启发,将搜索群体分为发现者、加入者和侦察者 3 部分,其相互分工寻找最优值,通过 19 个标准测试…...
ETL技术入门之ETLCloud初认识
首先ETL是什么? ETL代表“Extract, Transform, Load”,是一种用于数据集成和转换的过程。它在数据管理和分析中扮演着重要的角色。下面我们将分解每个步骤: Extract(抽取): 这一步骤涉及从多个不同的数据源…...

uniapp项目如何运行在微信小程序模拟器上
在HbuilderX中的小程序写完后自己一定要保存,否则会出不来效果 那么怎么让uniapp项目运行在微信小程序开发工具中呢 1 在hbuilderx中点击运行到小程序模拟器 2 然后在项目目录中会生成一个文件夹 在微信小程序开发软件中的工具>安全设置>打开端口 或者在微…...
数据挖掘全流程解析
数据挖掘全流程解析 数据指标选择 在这一阶段,使用直方图和柱状图的方式对数据进行分析,观察什么数据属性对于因变量会产生更加明显的结果。 如何绘制直方图和条形统计图 数据清洗 观察数据是否存在数据缺失或者离群点的情况。 数据异常的两种情况…...

详细介绍如何对音乐信息进行检索和音频节拍跟踪
在本文中,我们将了解节拍的概念,以及我们在尝试跟踪节拍时面临的挑战。然后我们将介绍解决问题的方法以及业界最先进的解决方案。 介绍 音乐就在我们身边。每当我们听到任何与我们的心灵和思想相关的音乐时,我们就会迷失其中。我们下意识地随着听到的节拍而敲击。您一定已…...

Java课题笔记~ HTTP协议(请求和响应)
Servlet最主要的作用就是处理客户端请求,并向客户端做出响应。为此,针对Servlet的每次请求,Web服务器在调用service()方法之前,都会创建两个对象 分别是HttpServletRequest和HttpServletResponse。 其中HttpServletRequest用于封…...

在x86下运行的Ubuntu系统上部署QEMU用于模拟RISC-V硬件环境
1.配置工作环境 sudo apt install gcc bison flex libncurses-dev ninja-build \pkg-config build-essential zlib1g-dev pkg-config libglib2.0-dev \binutils-dev libboost-all-dev autoconf libtool libssl-dev \libpixman-1-dev python-capstone virtualenv software-prop…...

网络爬虫选择代理IP的标准
Hey,小伙伴们!作为一家http代理产品供应商,我知道网络爬虫在选择代理IP时可能会遇到些问题,毕竟市面上有很多选择。别担心!今天我要给大家分享一些实用的建议,帮助你们选择适合网络爬虫的代理IP。一起来看看…...

RxJava 复刻简版之三,map 多次中转数据
案例代码:https://gitee.com/bobidali/lite-rx-java/commit/292e9227a5491f7ec6a07f395292ef8e6ff69290 RxJava 的调用第一步是封装了观察者接受了数据的处理,进一步就是使用 map 将数据操作传递给上下游 1、类似Observer.create 创建一个简单的观察者…...
)
06 Word2Vec模型(第一个专门做词向量的模型,CBOW和Skip-gram)
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html 神经网络语言模型(NNL…...
Axure RP9小白安装教程
第一步: 打开:Axure中文学习网 第二步: 鼠标移动软件下载,点击Axure RP 9下载既可 第三步: 注意:Axure RP 9 MAC正式版为苹果版本,Axure RP 9 WIN正式版为Windows版本 中文汉化包ÿ…...

腾讯云CVM服务器2核2g1m带宽支持多少人访问?
腾讯云2核2g1m的服务器支持多少人同时访问?2核2g1m云服务器短板是在1M公网带宽上,腾讯云服务器网以网站应用为例,当大规模用户同时访问网站时,很大概率会卡在公网带宽上,所以压根就谈不上2核2G的CPU内存计算性能是否够…...

8.12学习笔记
在PyTorch中,Dataset和DataLoader是用于处理数据的两个重要类。Dataset类是一个抽象类,用于表示数据集。它的主要作用是将数据加载到内存中,并提供一种统一的方式来访问数据。为了使用Dataset类,你需要继承它并实现两个方法&#…...

计算机体系中的不同的缓存存储层级说明
分级说明 L1缓存的标准延迟是4个周期。这意味着,当CPU请求数据时,L1缓存需要4个时钟周期来将数据传输给CPU。 L2缓存的标准延迟是12个周期。相对于L1缓存,L2缓存的容量更大,但其读取速度更慢,需要更多的时钟周期来传输…...
HCIP 链路聚合技术
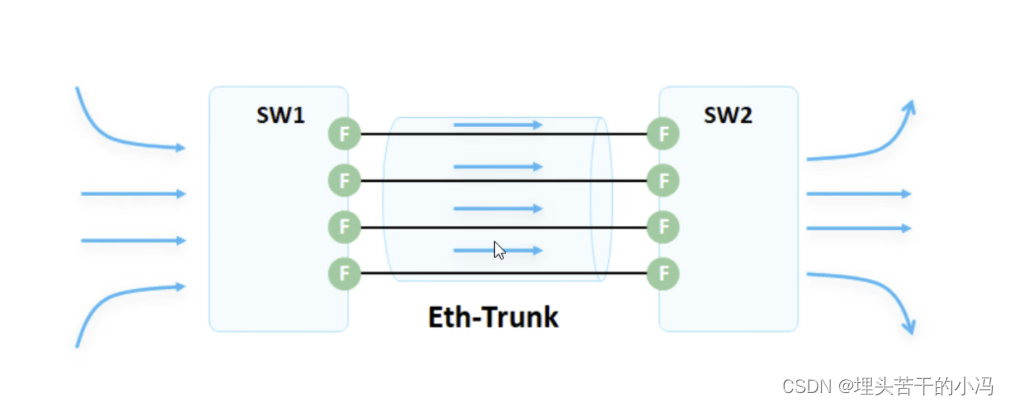
1、链路聚合概述 为了保证网络的稳定性,仅仅是设备进行备份还不够,我们需要针对我们的链路进行备份,同时也增加了链路的利用率,提高带宽。避免一条链路出现故障,导致网络无法正常通信。这就可以使用链路聚合技术。 以…...

网页爬虫中常用代理IP主要有哪几种?
各位爬虫探索者,你是否有想过在网页爬虫中使用代理IP来规避限制实现数据自由?在这篇文章中,作为一名IP代理产品供应商,我将为你揭示常见的网页爬虫代理IP类型,让你在爬虫的世界中游刃有余! 一、免费公开代理…...
Js小数运算精度缺失的解决方法
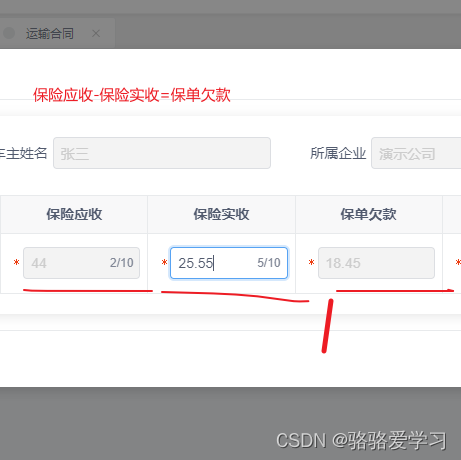
项目场景: 提示:项目需求截图: 问题描述 众所周知Js做运算时0.10.2不等于0.3,目前项目需要计算关于金额的选项,涉及到金额保留后两位。保单欠款是根据用户输入的保单应收和保单欠款自动计算的。 原因分析: 产生浮点数…...

25 | 葡萄酒质量数据分析
基于kaggle提供的公开数据集,对全球葡萄酒分布情况和质量情况进行数据探索和分析 from kaggle: https://www.kaggle.com/zynicide/wine-reviews 分析思路: 0、数据准备 1、葡萄酒的种类 2、葡萄酒质量 3、葡萄酒价格 4、葡萄酒描述词库 5、品鉴师信息 6、总结 0、数据准备 …...

工业相机选型避坑指南:从传感器尺寸到镜头焦距的5个关键参数
工业相机选型避坑指南:从传感器尺寸到镜头焦距的5个关键参数 在工业自动化领域,视觉系统的精度和稳定性往往决定了整个生产线的质量水平。作为系统集成商或自动化工程师,面对市场上琳琅满目的工业相机产品,如何避免"参数陷阱…...

【AGI可信性生死线】:从Gödel不完备到Isabelle/HOL自动化证明,2026奇点大会首次披露6层验证协议栈
第一章:2026奇点智能技术大会:AGI与数学证明 2026奇点智能技术大会(https://ml-summit.org) AGI驱动的自动定理证明新范式 本届大会首次公开展示了基于混合符号-神经架构的AGI定理证明系统FormalMind-7B,该系统在Coq 8.18与Lean 4.8环境中实…...
)
Spring Boot项目调用外部API总报403?排查这5个配置点(含Postman对比测试)
Spring Boot项目调用外部API总报403?排查这5个配置点(含Postman对比测试) 最近在技术社区看到不少开发者反馈同一个问题:用Spring Boot项目调用外部API时频繁遇到403错误,但同样的请求在Postman里却能正常返回数据。这…...

Splashtop XDisplay 实战指南:从零开始将iPad变身高效率触控副屏
1. 为什么你需要把iPad变成副屏? 每次看到同事用双屏办公,效率直接翻倍的样子,是不是特别羡慕?其实你包里那个吃灰的iPad,只需要一根数据线就能变身专业级触控副屏。我用了三年Splashtop XDisplay,从写代码…...

今天不看SITS2026这页PPT,明年招标书里将彻底消失“传统机器人”术语
第一章:SITS2026演讲:AGI与机器人结合 2026奇点智能技术大会(https://ml-summit.org) 核心范式转变 传统机器人系统依赖预编程行为树与模块化感知-决策-执行链路,而SITS2026展示的AGI驱动架构将大语言模型(LLM)与具身…...

ABAP ALV删除行后数据又‘复活’?一个方法搞定check_changed_data
ABAP ALV删除行数据同步异常排查指南:从Del键失效到check_changed_data的深度解析 在SAP系统开发中,可编辑ALV报表的数据同步问题堪称"经典陷阱"。许多开发者都遇到过这样的场景:用户信心满满地按下Del键删除行项目,点击…...

Java的java.util.HexFormat双向支持
Java 16引入的java.util.HexFormat类为开发者提供了高效的十六进制与二进制数据双向转换能力,填补了Java标准库在十六进制处理领域的空白。这个工具类不仅支持基础格式转换,还能处理字节数组、字符序列等复杂场景,其线程安全特性更使其成为网…...

群晖Docker部署Calibre Web踩坑全记录:从权限报错到Kindle推送,一篇讲透所有常见问题
群晖Docker部署Calibre Web全流程避坑指南:从权限配置到Kindle推送实战 每次打开硬盘里堆积如山的电子书却无从下手时,一个得力的书库管理系统就显得尤为重要。作为电子书爱好者的终极解决方案,Calibre Web以其优雅的界面和强大的功能赢得了众…...
的Python Web框架)
FastAPI 是什么: 是一个现代、快速(高性能)的Python Web框架
FastAPI 是什么: 是一个现代、快速(高性能)的Python Web框架 目录 FastAPI 是什么: 是一个现代、快速(高性能)的Python Web框架 核心特点 快速实现示例 1. 安装 2. 完整代码示例(main.py) 3. 运行应用 4. 访问自动生成的交互式文档 简单说明 FastAPI 是一个现代、快速…...

避坑指南:用System Generator生成FPGA滤波代码,为什么我劝你谨慎?
警惕图形化工具陷阱:FPGA数字滤波开发的硬核真相 在FPGA开发领域,图形化设计工具如System Generator常被宣传为"快速实现复杂算法"的银弹。许多初入行的工程师会被其直观的拖拽界面和自动代码生成功能所吸引,尤其是在处理数字滤波这…...