【Transformer】自注意力机制Self-Attention | 各种网络归一化Normalization
1. Transformer 由来 & 特点
1.1 从NLP领域内诞生
"Transformer"是一种深度学习模型,首次在"Attention is All You Need"这篇论文中被提出,已经成为自然语言处理(NLP)领域的重要基石。这是因为Transformer模型有几个显著的优点:
-
自注意力机制(Self-Attention):这是Transformer最核心的概念,也是其最大的特点。通过自注意力机制,模型可以关注输入序列中的所有位置,并为每个位置分配不同的注意力权重。这使得模型能够更好地处理长距离的依赖关系,也就是说,对于句子中距离较远的单词,模型也能有效地捕获其关系。
-
并行计算:在之前的很多模型中,如RNN(循环神经网络),处理序列数据需要按照时间步顺序进行,这在处理长序列时会非常慢。而Transformer模型可以同时处理所有的输入,这使得它在大规模数据训练中有显著的效率提升。
-
可扩展性:Transformer模型可以轻松地通过增加层数、隐藏层单元数等来增加模型大小,使其能够处理更复杂的任务。
正因为这些优点,Transformer模型在很多NLP任务上都有出色的表现,包括机器翻译、文本摘要、情感分析等等。后续发展出的BERT、GPT等模型,都是基于Transformer的架构,进一步推动了AI领域的进步。
1.2 计算机视觉 + Transformer
尽管Transformer最初是为处理自然语言处理(NLP)任务设计的,但近年来,它也被广泛应用于计算机视觉(CV)领域,包括图像分类、对象检测、图像分割等任务。
Transformer在视觉领域的应用主要体现在以下两个方面:
-
图像中的长程依赖:与NLP问题类似,图像中的像素也存在长程依赖性。例如,一幅图像中的某个部分可能会对图像的其他部分产生影响。Transformer的自注意力机制可以捕捉到这些依赖关系。
-
端到端的全局优化:传统的卷积神经网络(CNN)通常会使用局部的卷积操作来提取图像特征,这些操作不容易捕获全局的图像信息。而Transformer的自注意力机制可以直接处理全局的信息,能实现端到端的全局优化。
其中,一个代表性的视觉Transformer模型是ViT(Vision Transformer)。ViT模型将图像切割为一系列小的patch,然后将这些patch视为序列输入,使用Transformer对其进行编码。这样就可以将全局的图像上下文信息整合到每一个patch的表示中,有助于提升视觉任务的性能。
至今为止,包括ViT在内的一些视觉Transformer模型已经在多个重要的计算机视觉任务中取得了最先进的结果,显示出Transformer架构的巨大潜力和广泛应用性。
必须读:ViT中的Self-Attention
1.3 自注意力机制 Self-Attention
自注意力机制(Self-Attention Mechanism),也被称为自我注意力机制或者只是注意力机制,是Transformer模型的核心部分。自注意力机制的基本思想是在处理序列数据时,不只是关注当前的输入,而是关注整个序列,并且为序列中的每一个元素赋予不同的重要性或权重。
自注意力机制的运作流程如下:
-
首先,每个输入元素都有三个向量表示:Query(查询),Key(键),Value(值)。这些向量是输入元素经过不同的线性转换(也就是乘以权重矩阵)得到的。
-
然后,通过计算Query和所有Key的点积,得到每个元素的得分。这个得分反映了当前元素与其他元素的关联程度。更高的得分意味着这两个元素更相关。
-
接着,将这些得分经过softmax函数转换为概率值,这样所有的得分加起来就为1了。这个概率值就是注意力权重,反映了模型对每个元素的关注程度。
-
最后,用这些注意力权重去加权求和所有的Value,得到最终的输出。
这样,每个输出都包含了整个序列的信息,而且这个信息的整合是根据每个元素与当前元素的相关性进行的。这使得模型能够捕捉到长距离的依赖关系,并且可以并行处理整个序列,大大提高了效率。这就是自注意力机制的魅力所在,也是Transformer模型能够在很多任务上取得优秀表现的原因。
2. 台大李宏毅:自注意力机制 Self-Attention
这一part是看视频做的笔记,视频可以在B站上找到~
- 可扩展性强:轻松增加Self-Attention的层数!!
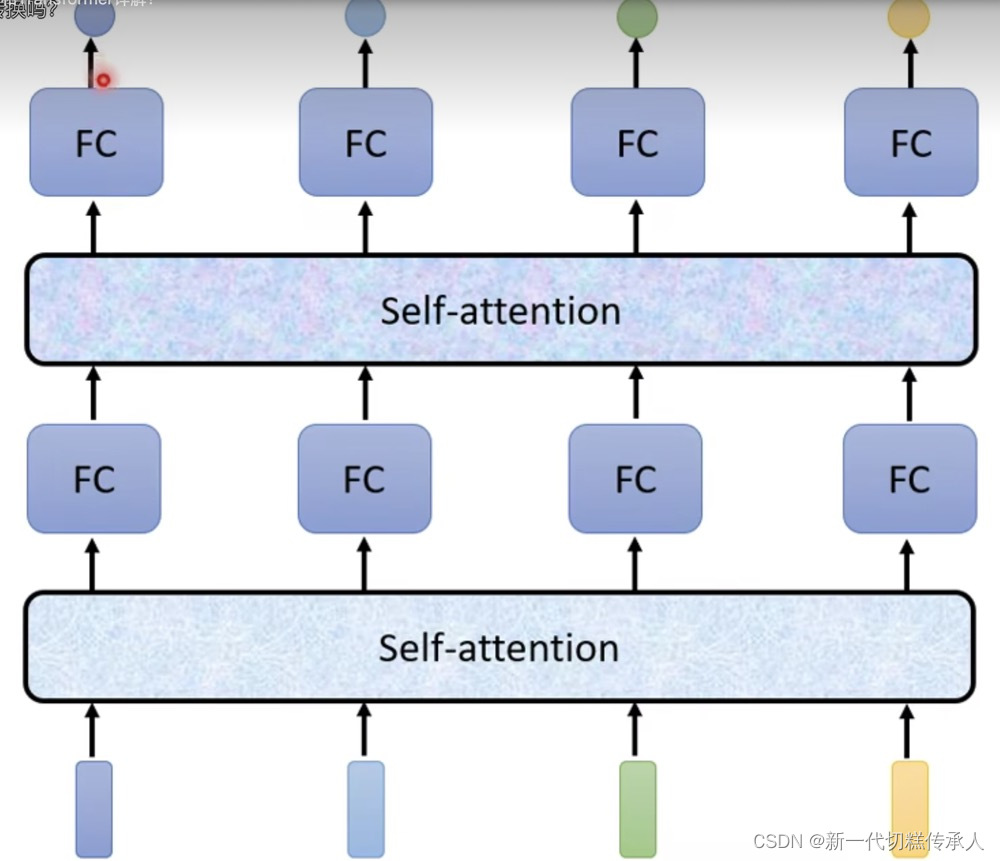
Seq2Seq模型:
- 自注意力机制核心:vector --> vector 考虑了整个input sequence才产生了每一个output!!!
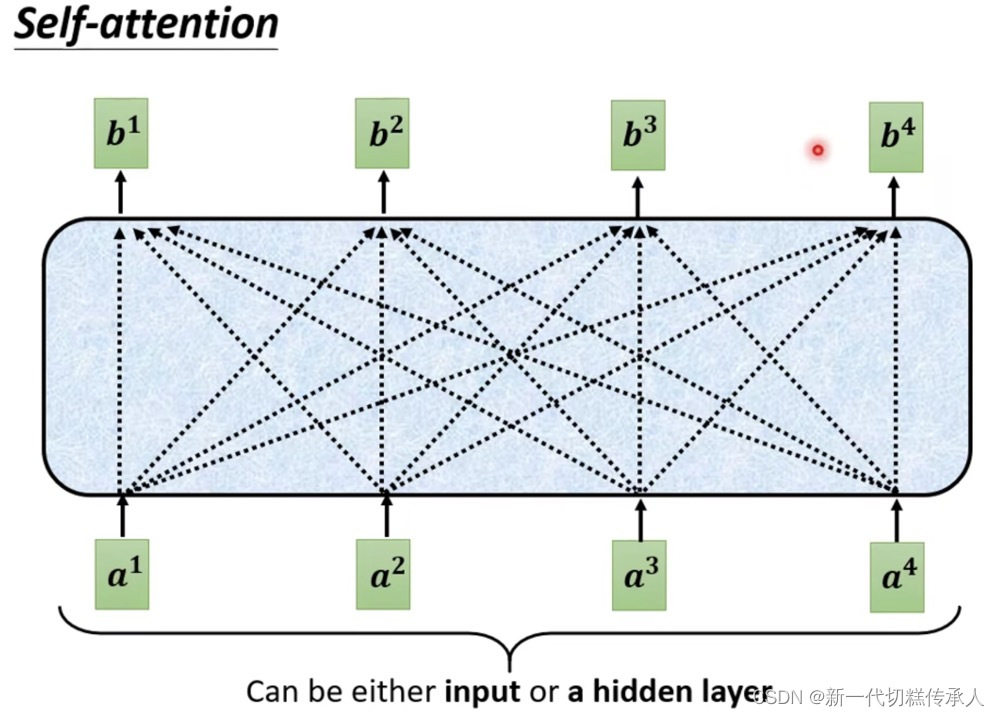
- 上图中,如何产生每一个output vector?
学习链接:20’25’'起看
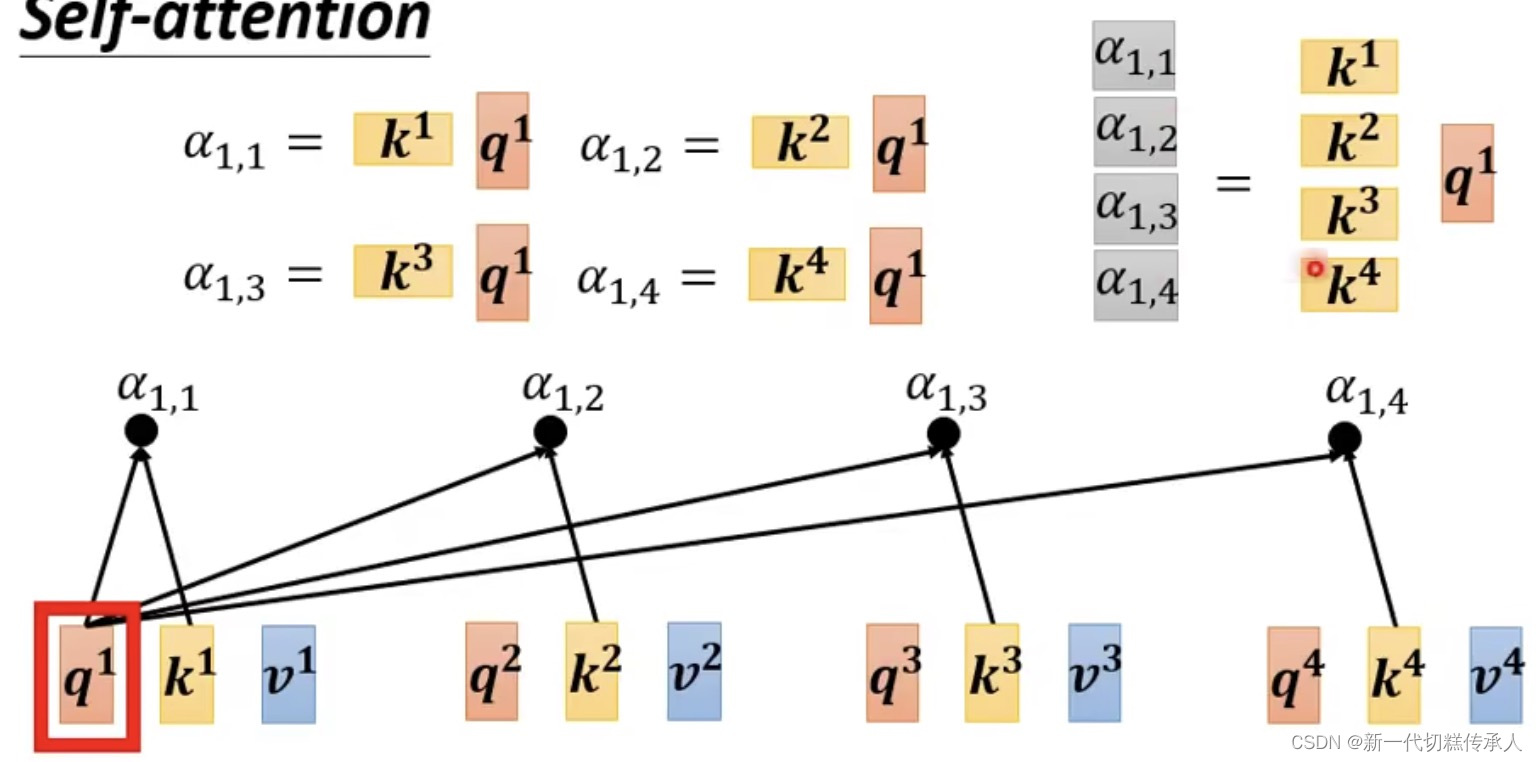
Step 1: Find the relevant vectors in a sequence!
找到其它vectors中,哪些vector是对判断a1的label是重要的!
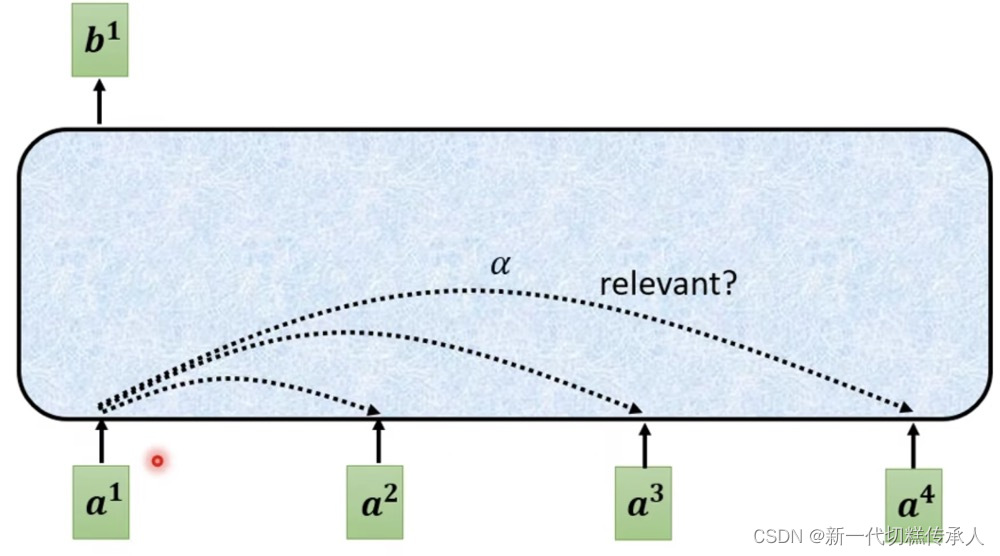
a1和a4有多相关?相关度α计算:使用「计算attention的module」!
下面是 两种常见的【相关度α计算module】
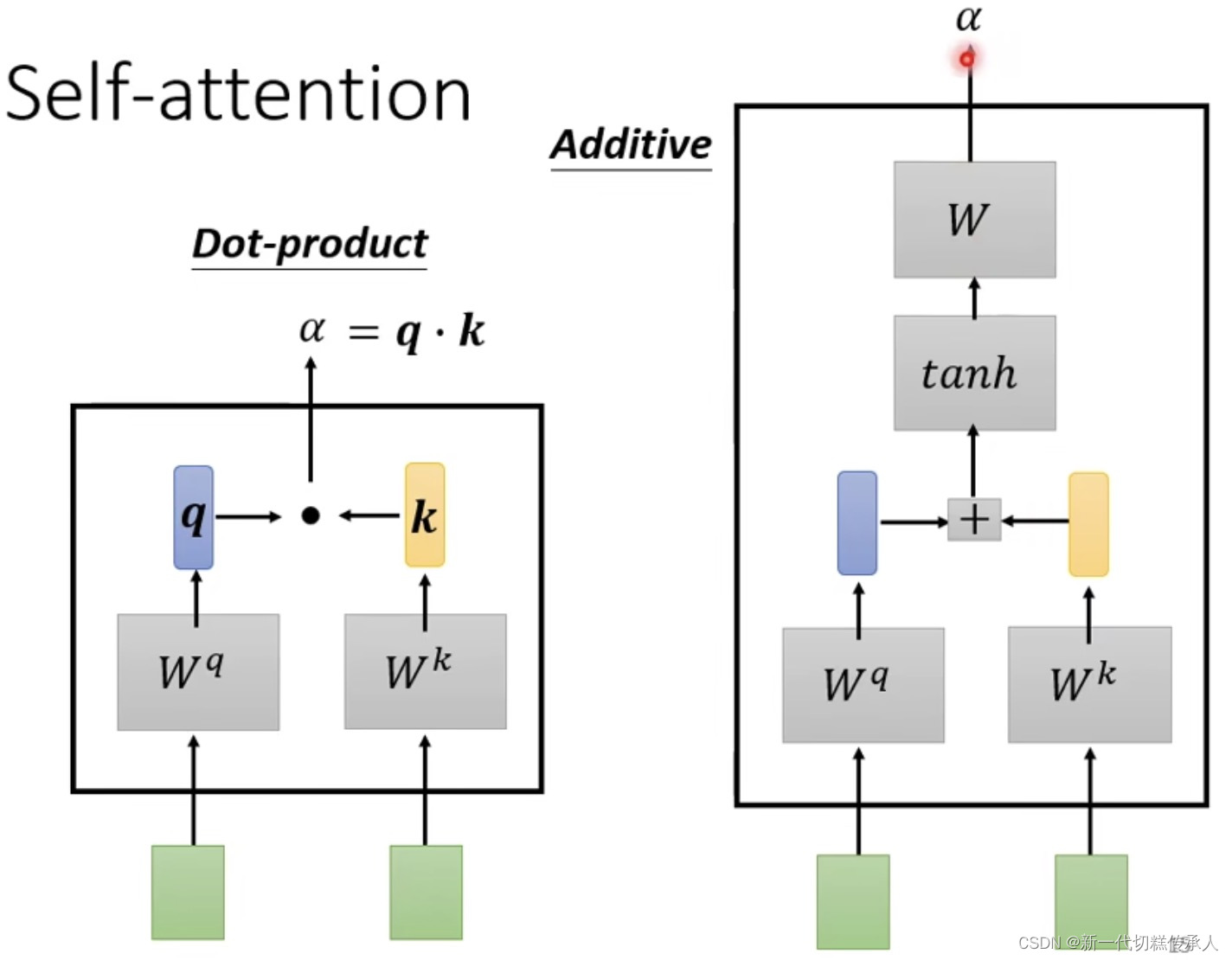
其中,Dot-product (点积)是最常用的,用在了 Transformer 里。
然后使用计算 Dot-product 来计算 attention score(即:关联性)。
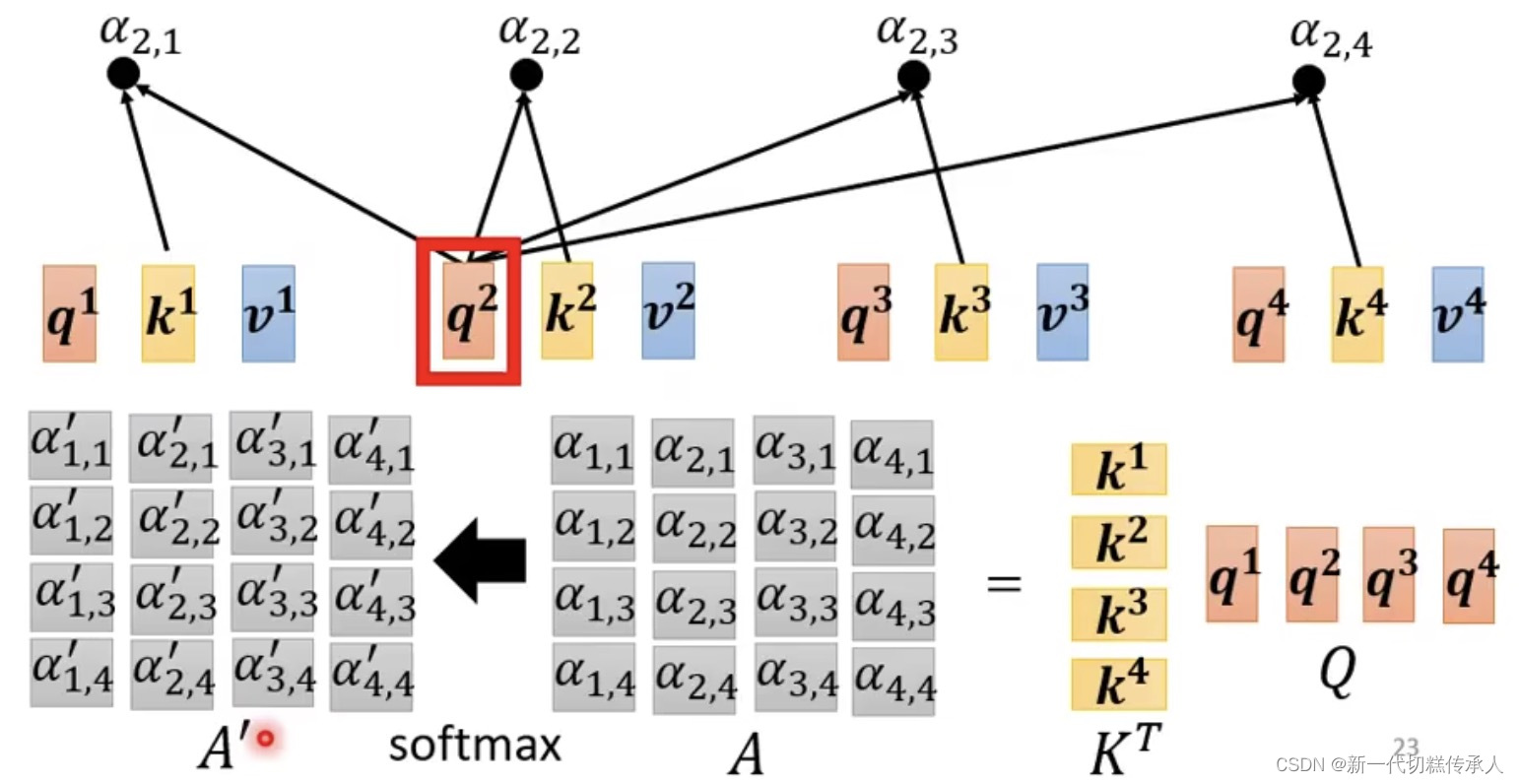
下图中经过Dot-product得到的 α1,1 α1,2 … α1,4 就是 α1和α2,α3,α4的关联性!!!
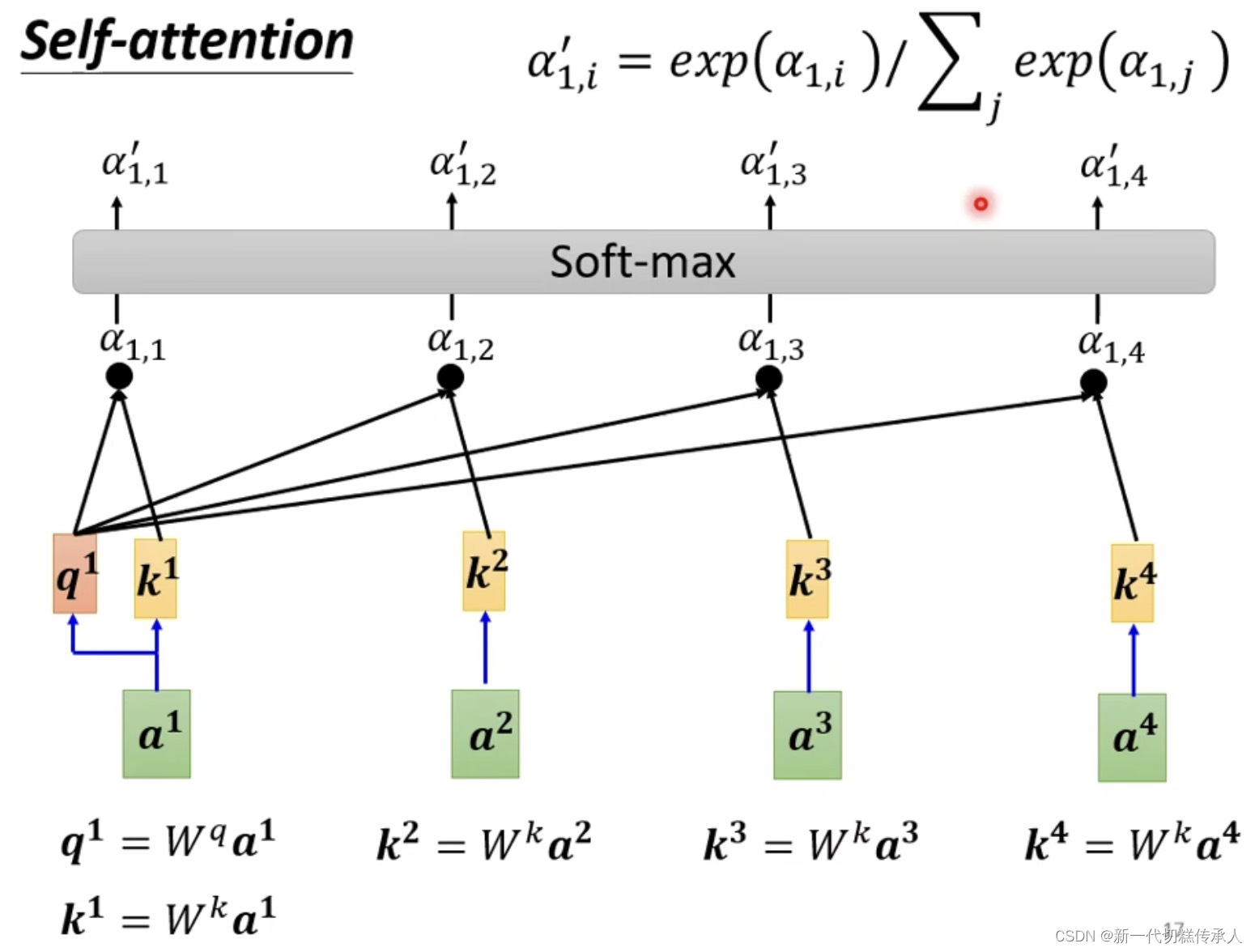
soft-max的作用是:生成「注意力权重」
将这些得分经过softmax函数转换为概率值,这样所有的得分加起来就为1了。这个概率值就是注意力权重,反映了模型对每个元素的关注程度。
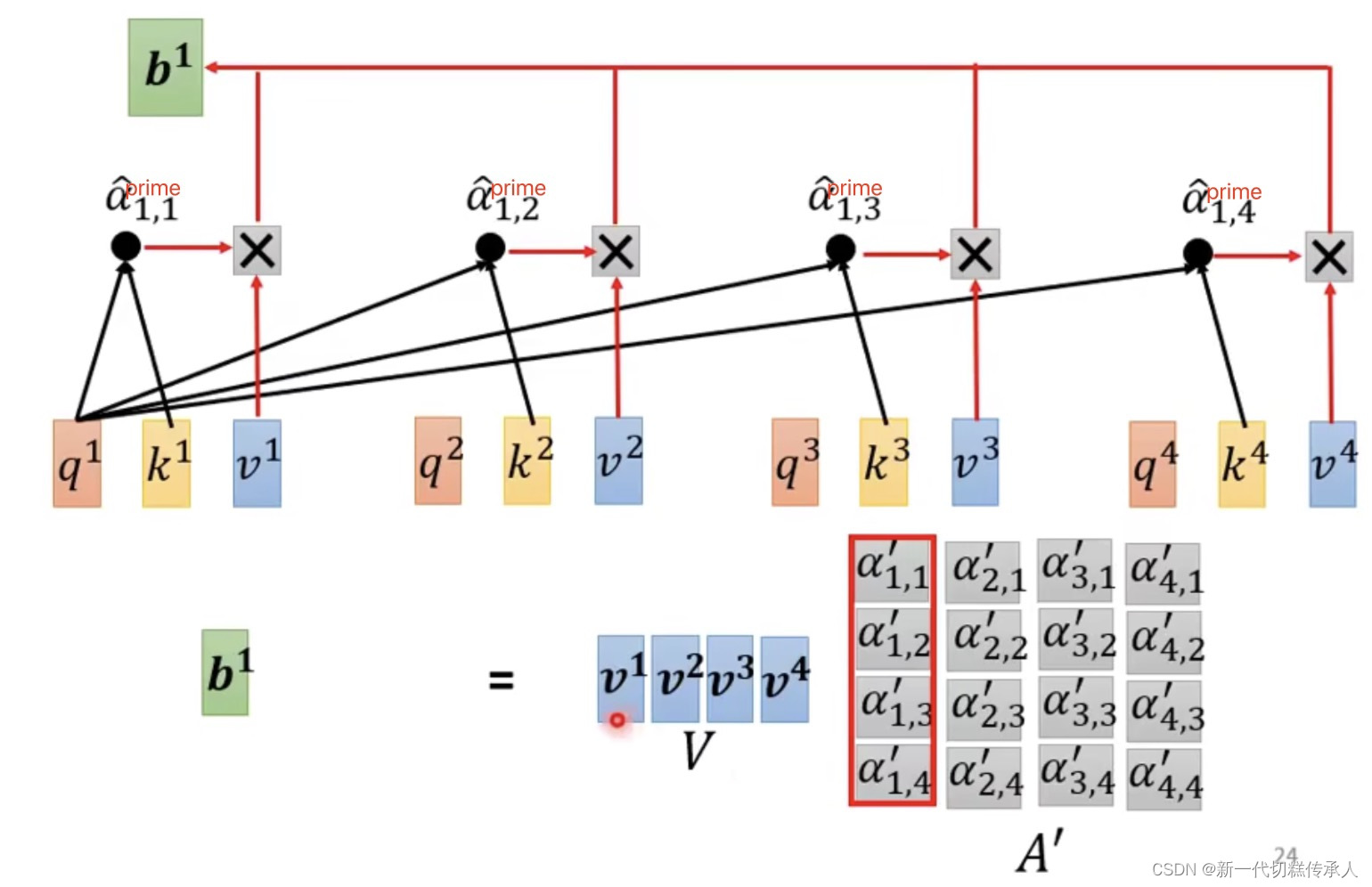
Step 2: Extract information based on attention scores!
根据attention score’ (注意力权重),去抽取重要的information!
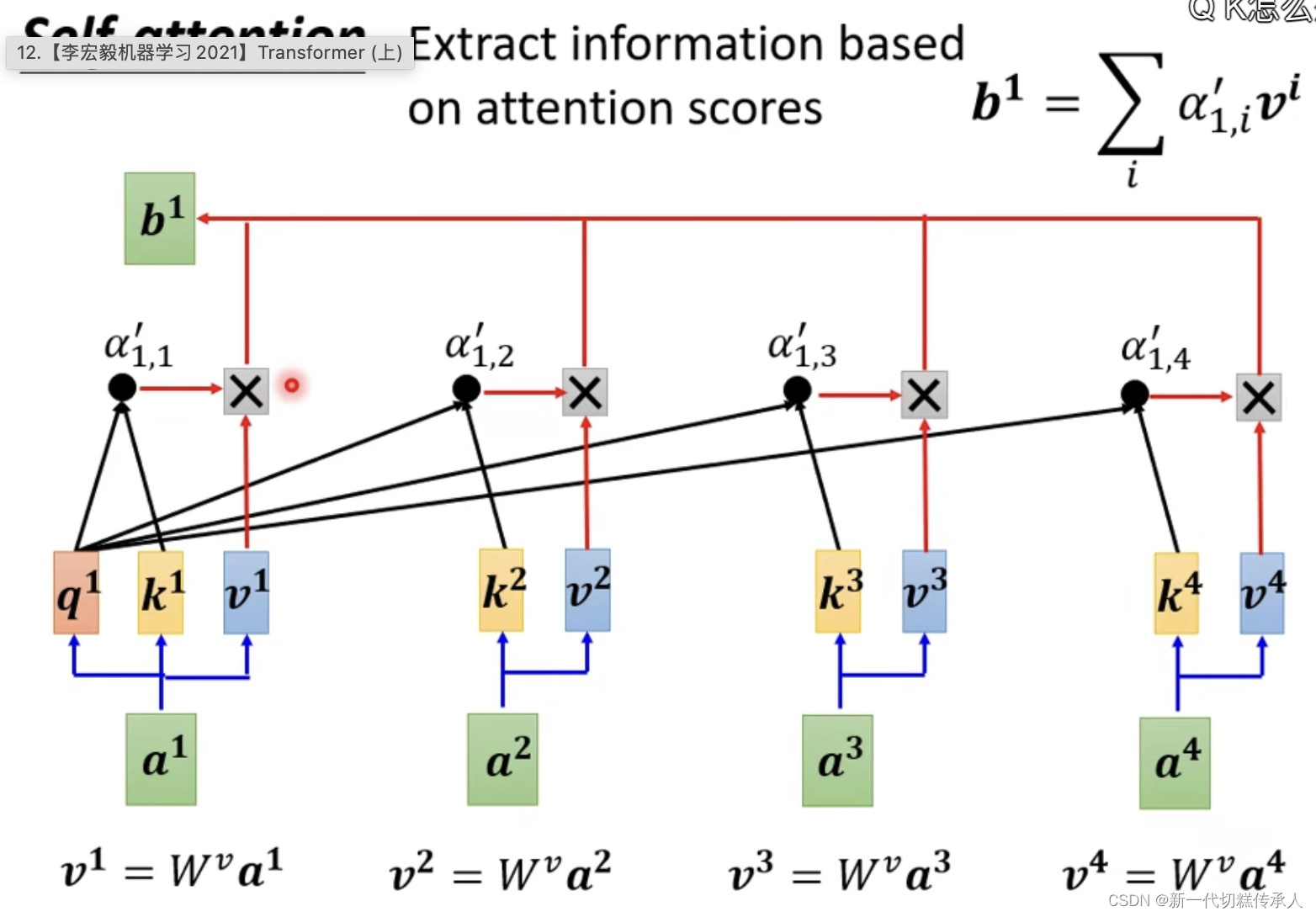
并行计算的思想在这也有体现!上图仅展示计算b1的过程,但b1、b2、b3、b4 实际上是平行被计算的,他们是并行的(从矩阵操作的角度看)!在大规模数据中效率也很高!
下面这些图是从矩阵计算的角度来看attention的执行过程~——
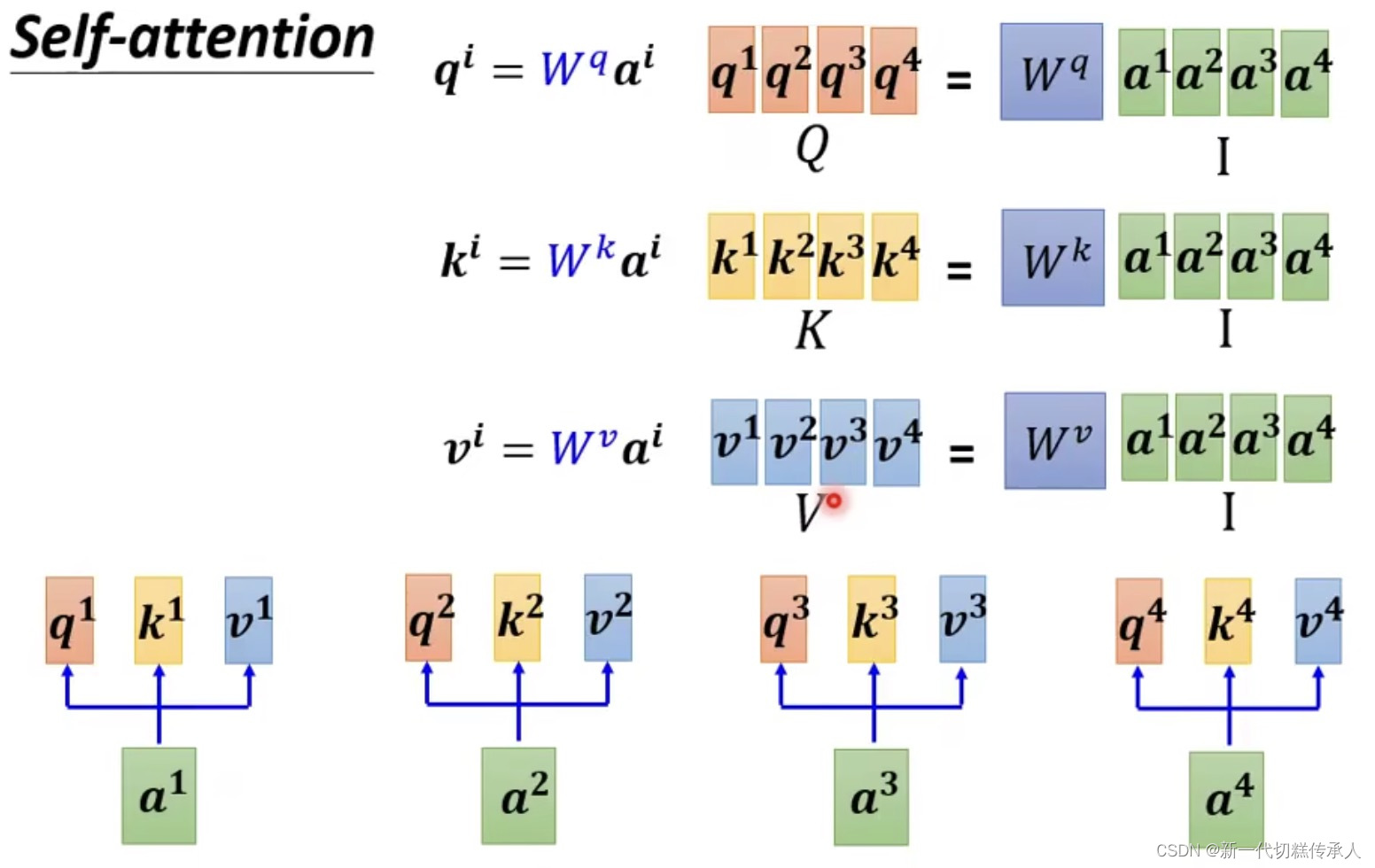
总而言之,言而总之,self-attention技术可以归结为 一整串的矩阵乘法: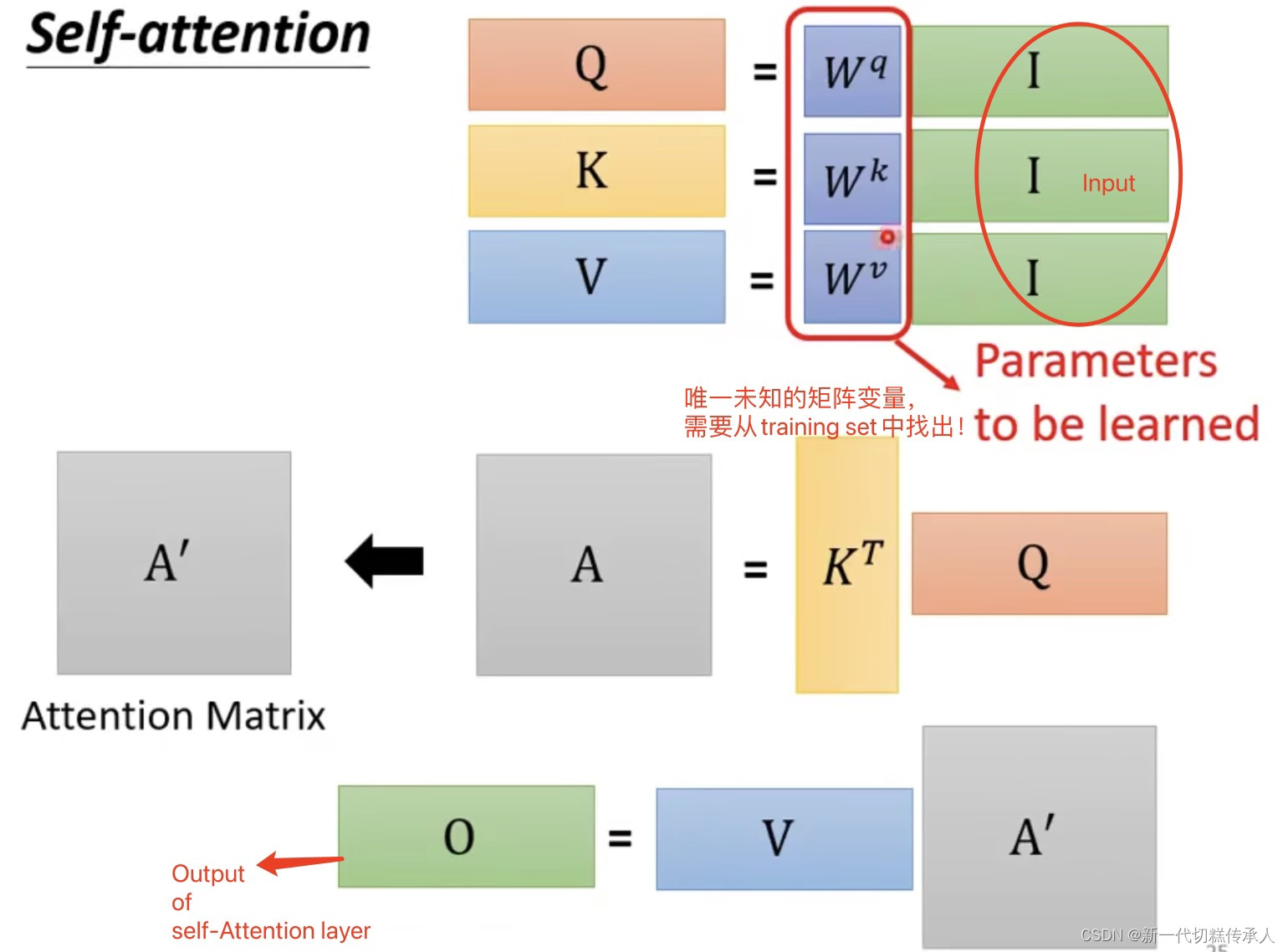
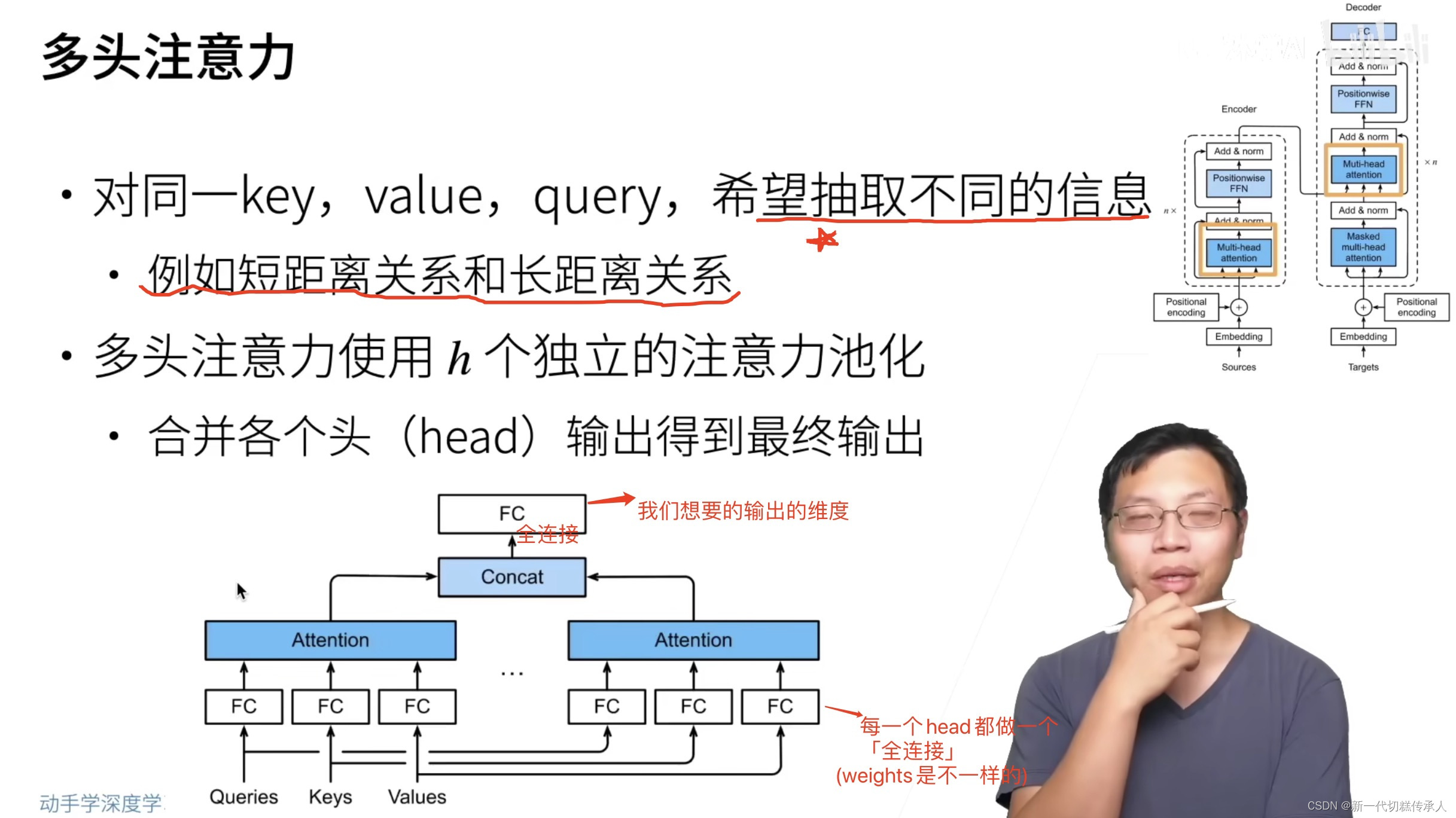
Multi-Head Attention
指的是多组q,k,v分别做self-attention,在同一个网络里。
特点:
- 目的:多头注意力的设计允许模型同时在不同的表示子空间(representation subspaces)上学习和获取信息。每个头可以关注输入的不同部分。
- 定义:在传统的注意力机制中,我们有一个查询(Q), 键(K)和值(V)。对于多头注意力,我们不仅有一套Q、K和V,而是有多套(每个“头”一套)。这意味着模型可以在多个子空间上并行地学习不同的注意力权重。
- 操作:
对于每一个头,我们首先通过权重矩阵来线性变换输入的Q、K和V。
使用变换后的Q、K和V计算注意力权重并得到输出。
各个头的输出会被拼接起来,并通过另一个线性变换得到最终的多头自注意力输出。 - 参数共享:每个头都有自己的权重矩阵,但在整个模型的训练过程中,这些权重都是被学习的。这意味着每个头可以学到不同的注意力策略。
- 优点:通过使用多头,模型可以捕捉到更丰富的信息和更复杂的模式。例如,一个头可能会专注于句子的语法结构,而另一个头可能会专注于句子的语义内容。
- 实际应用:在NLP任务中,如机器翻译、文本分类等,使用多头自注意力机制的Transformer模型已经成为了一种标准做法。此外,这种结构也已被用于其他领域,如计算机视觉,因为它提供了强大的表征学习能力。(在实际实现中,需要注意如何正确地进行权重共享、如何组合多头输出以及如何调整头的数量来达到最佳的效果。)
Positional Encoding 「位置」
一句话概括,Positional Encoding就是句子中词语相对位置的编码,让Transformer保留词语的位置信息。
似乎在NLP用的多。看:【AI理论学习】对Transformer中Positional Encoding的理解
Self-Attention 在 CV领域的使用(原始idea):
一张5x10 pixels的图可以看作是一个vector set。因为RGB的三channels图像那就是5x10x3的tensor,其中的每一个pixel就是一个三维的vector。
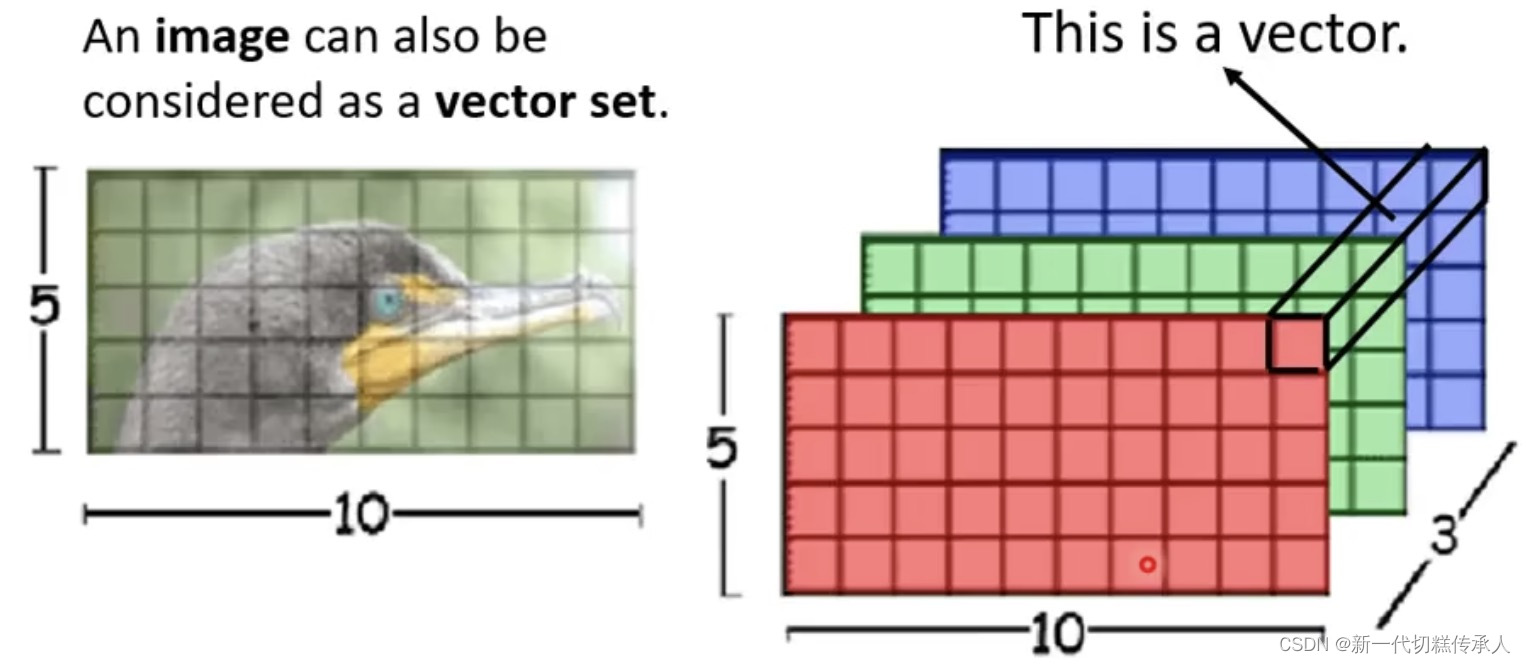
应用了 Self-Attention 的CV models:DETR,self-attention GAN

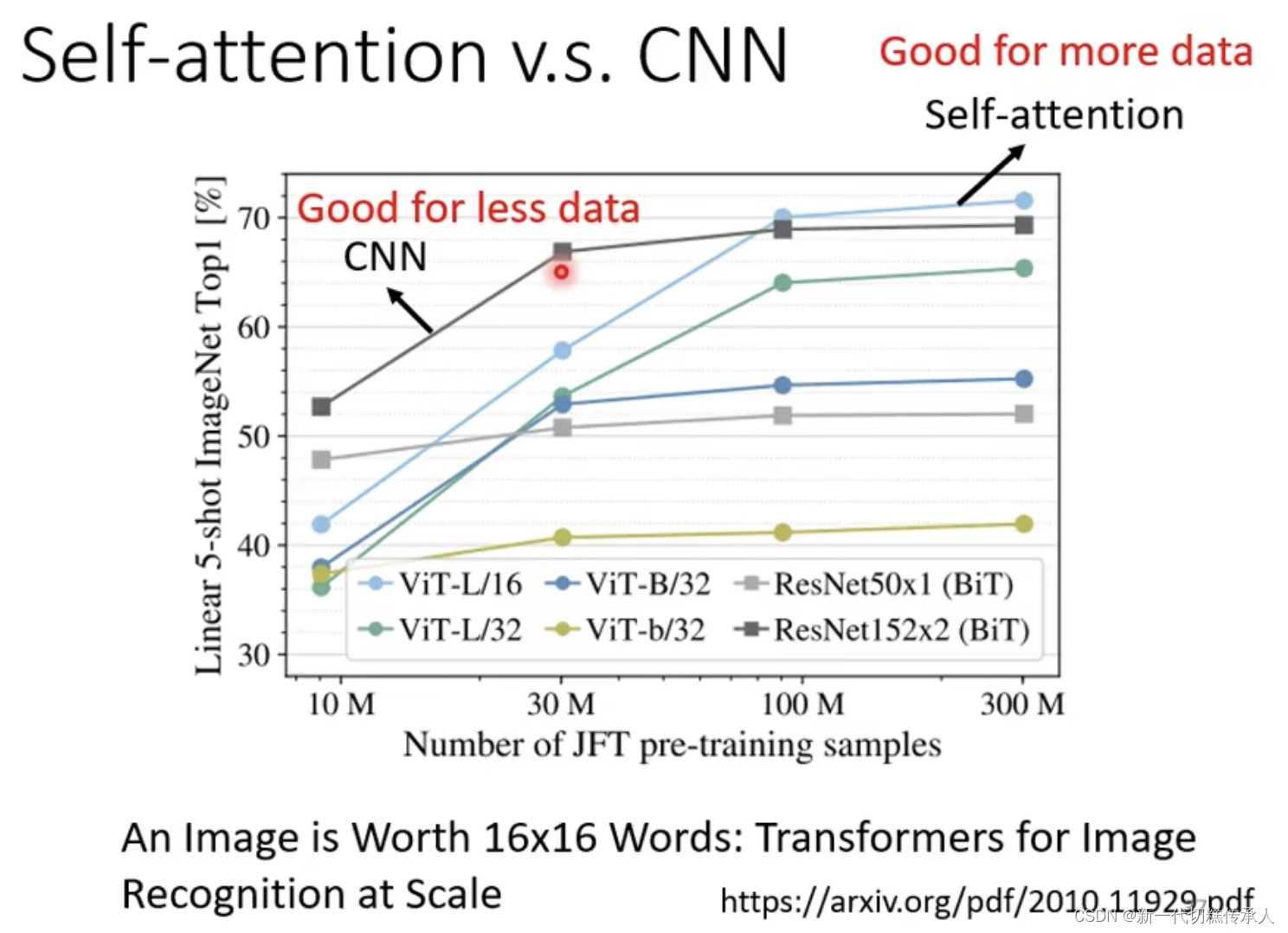
CNN其实就是self-Attention的一个特例。 但,数据量少的时候CNN更好用(此时self-attention因弹性大所以容易过拟合),而数据量多的时候self-attention能取得更好的结果! 参见下图。
此外,Self-Attention取代了RNN!因为干的事情是差不多的,但RNN需要大量的memory,而self-attention能做到“天涯若比邻”!!(如下图所示)
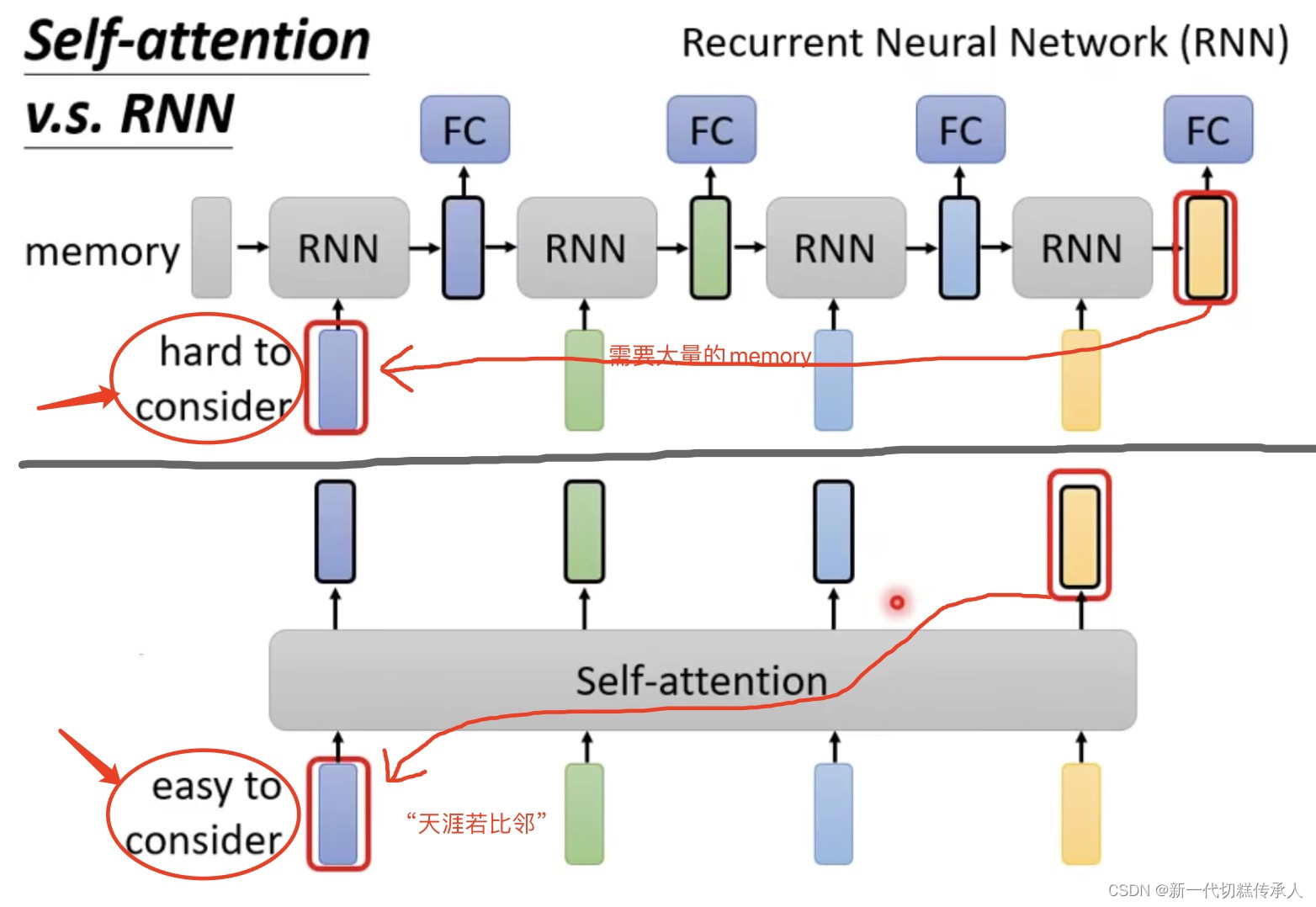
而且,RNN在计算时不是parallel的!它需要从左到右一个一个往下继续计算(看上图可知)。而self-Attention是parallel计算的,可以平行处理所有的输出,效率非常高!工业界已逐渐把RNN架构的产物逐渐改成self-Attention架构了。
3. 台大李宏毅:Transformer
3.1 概述 | Encoder | Decoder
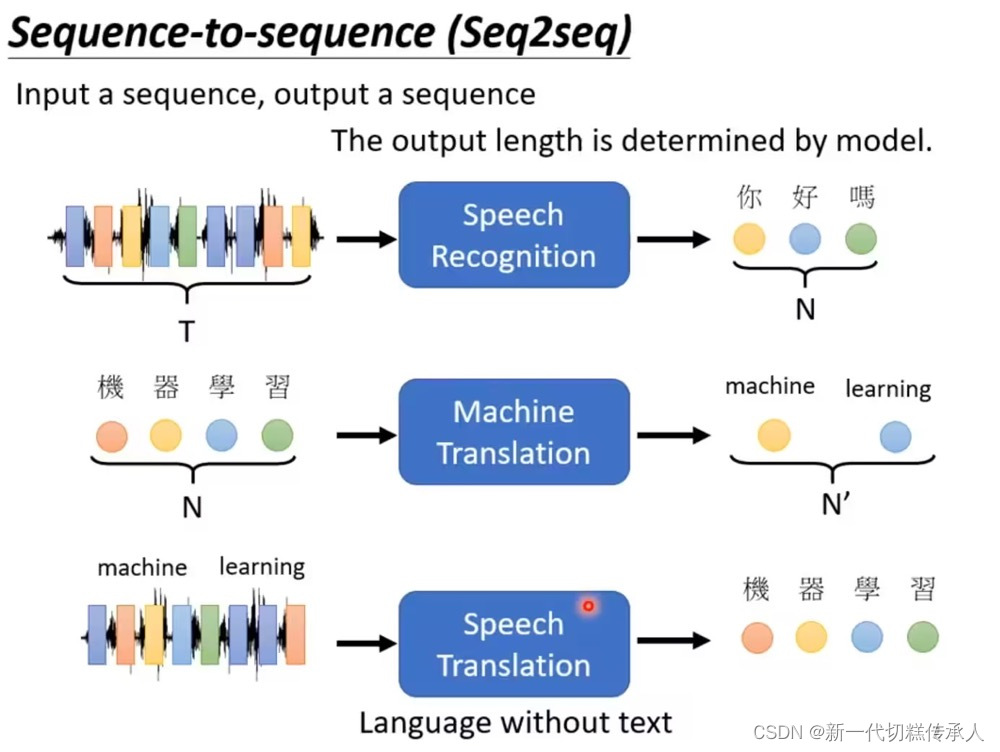
Transformer是一个sequence-to-sequence (Seq2seq) model。也就是input和output都是sequence。而output的sequence,可以是定长的,也可以是和input一样长的,也可能是我们不知道有多长的需要机器自己判别的。
例如:语音辨识,声音讯号–>文本,这个场景下的output就是机器自己决定的。机器翻译同理。
文本 & 声音讯号互转 案例:中文文字---->台语/闽南语 点击精准空降
「硬train一发」指不知道输出是多长的,干脆直接把数据丢进去让seq2seq模型自己来决定输出啥。
Seq2seq模型中,Encoder读入数据,处理后丢给Decoder,由Decoder来决定要输出多少东西。
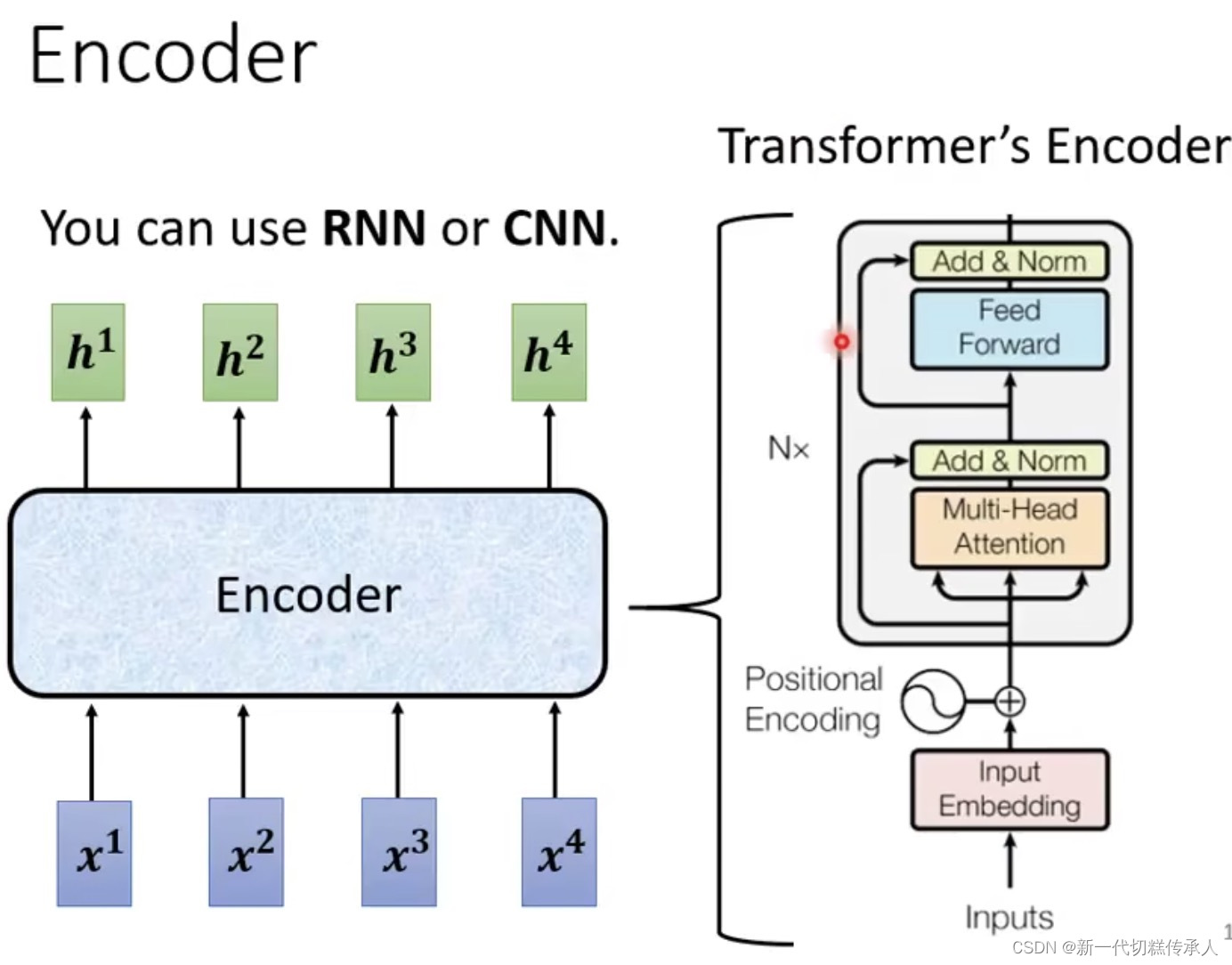
1. Encoder
Input一排向量,output一个同样长度的向量。
每个Encoder里面可能有好几个blocks,每个block里面可能有好几个layers在干各种事情!
2. Decoder
以语音辨识为例,即声音讯号转文字。
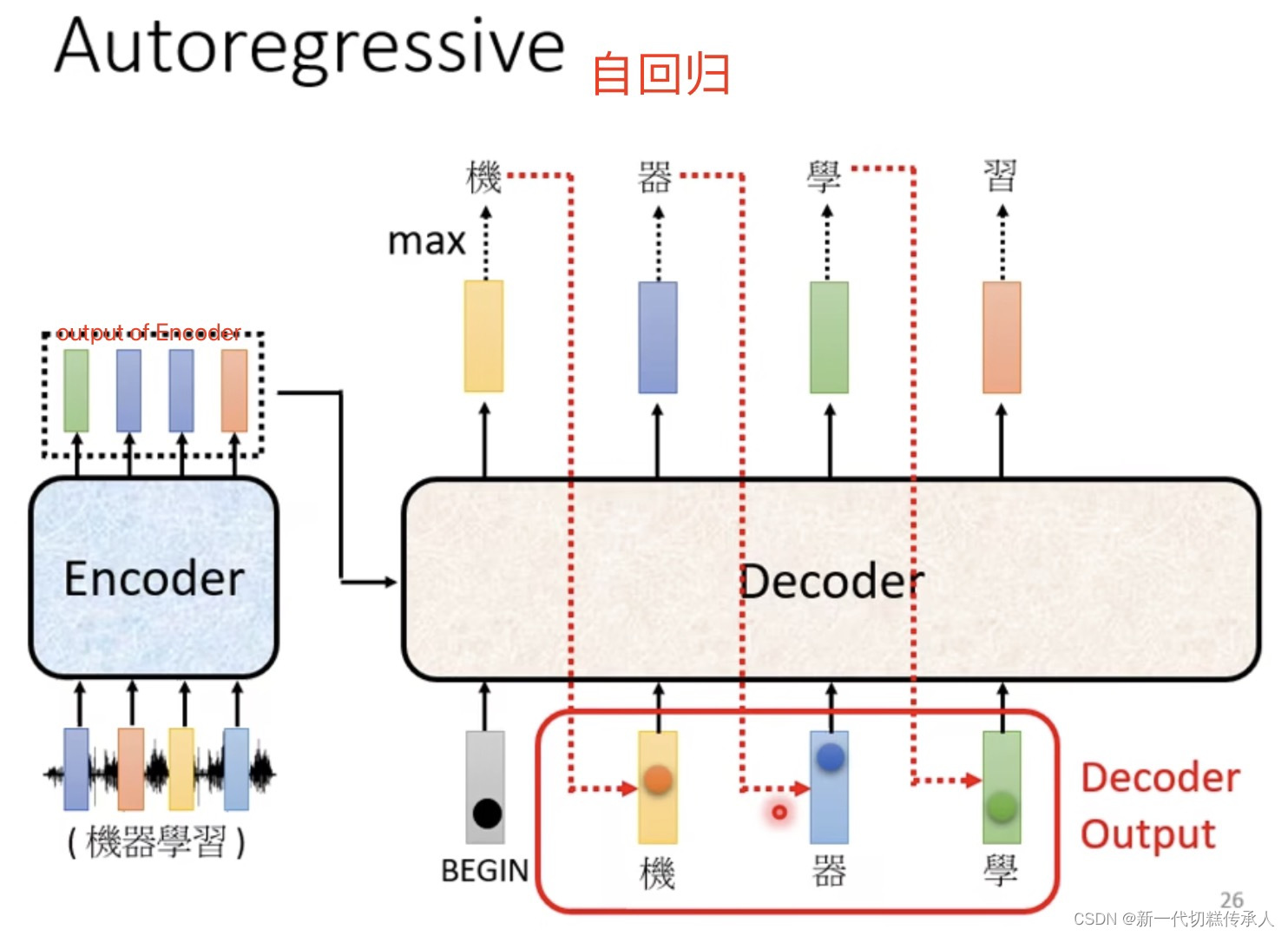
Decoder必须自己决定输出的sequence的长度。
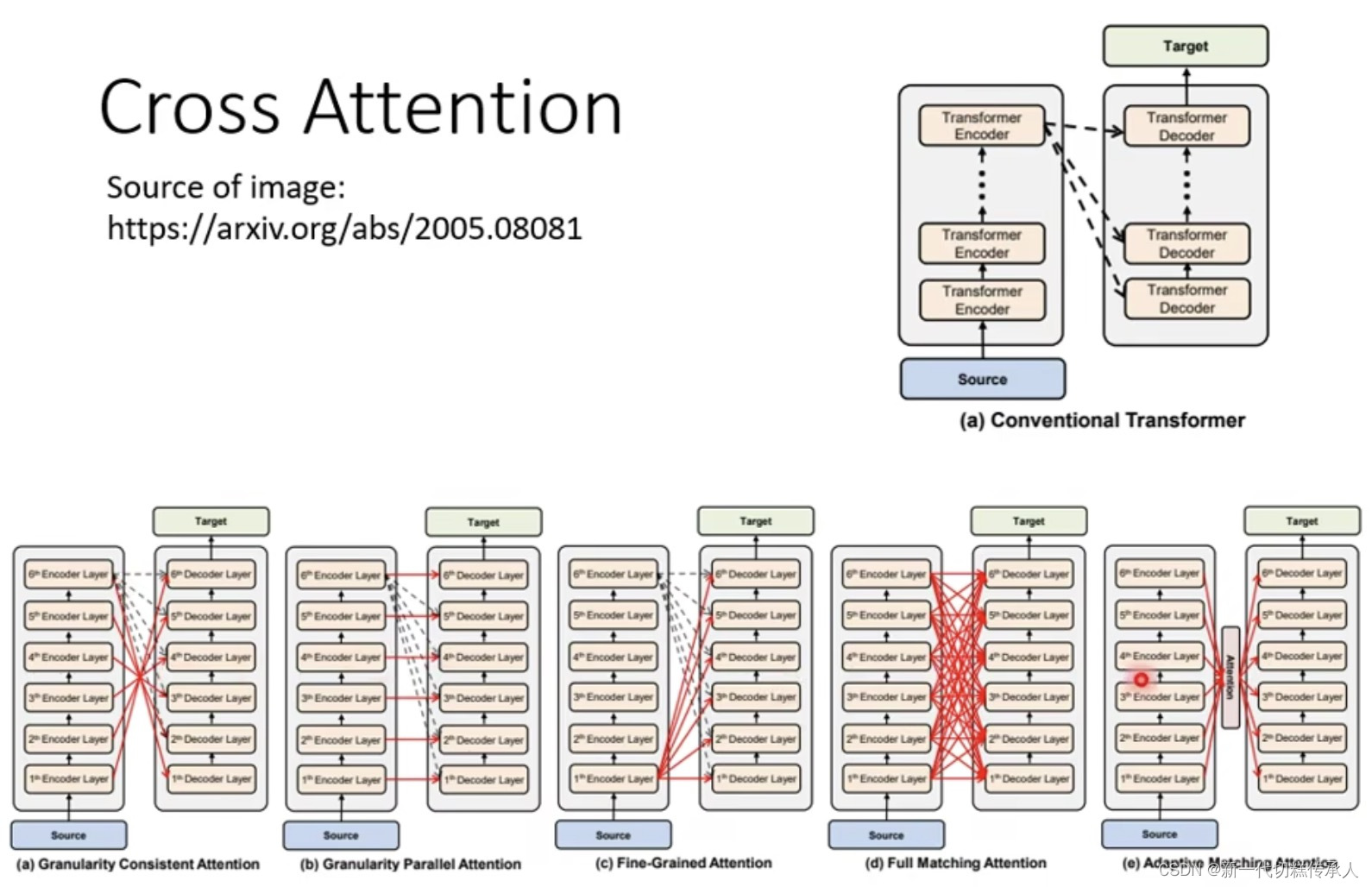
3. Encoder 和 Decoder 之间如何传递数据
各式各样的传递方式。。。
4. 李沐《动手学》:注意力机制 & Transformer框架 & 归一化 Normalization
学习链接🔗:https://zh.d2l.ai/chapter_attention-mechanisms/index.html
https://space.bilibili.com/1567748478/channel/seriesdetail?sid=358497
4.1 多头注意力 Multi-Head Attention
看图上的笔记!!!!!!!!!!
4.2 层归一化 Layer Normalization
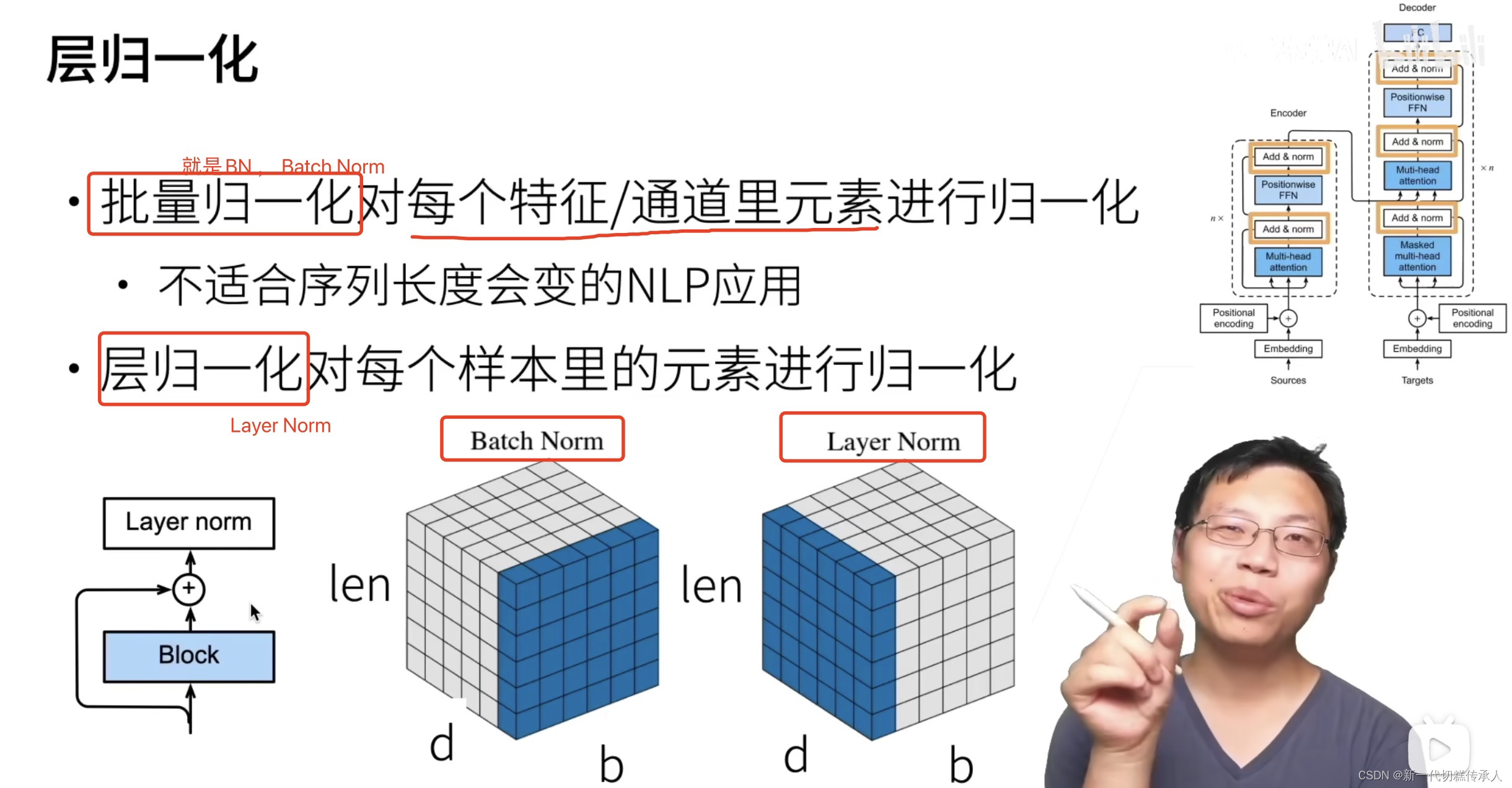
LN适用于 输入输出序列长度会变的data,所以NLP领域基本都用LN。
而BN常用于CV领域。
4.3 批量归一化 Batch Normalization (2015)
假设总共有30个样本,每5个样本构成一个batch来进行训练!
参考学习链接:(1)5分钟速食 https://www.bilibili.com/video/BV12d4y1f74C/?spm_id_from=333.337.search-card.all.click&vd_source=6b4de80fe82d569d8c1324a8320a624f
(2)台大 李宏毅 讲BN:https://www.bilibili.com/video/BV1bx411V798/?spm_id_from=333.337.search-card.all.click&vd_source=6b4de80fe82d569d8c1324a8320a624f # 真的很会讲 每次听都豁然开朗
BN可以保证网络中间的层,每一层的输入的分布都是类似的。
以下笔记来自 台大李宏毅老师 讲BN的视频:
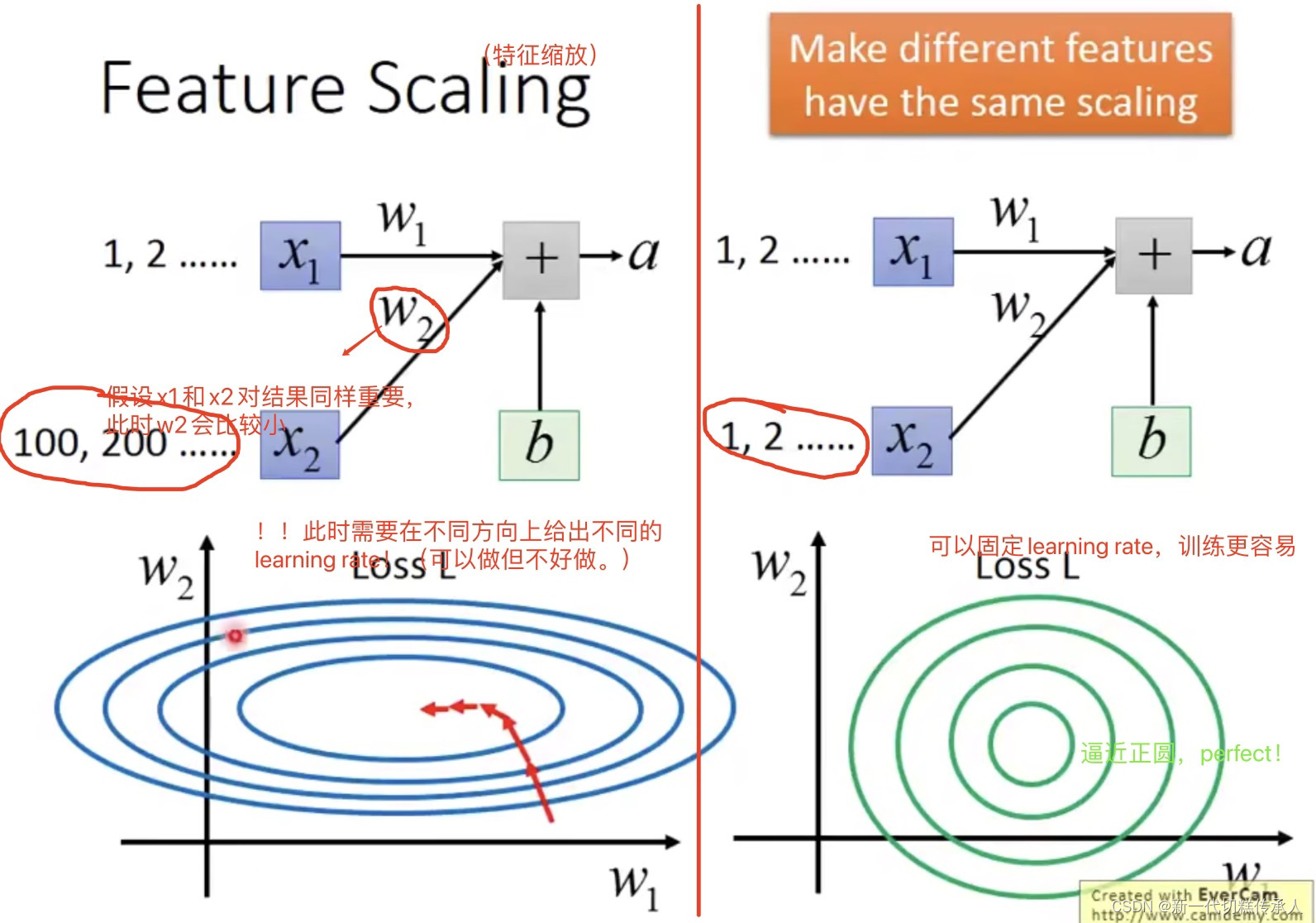
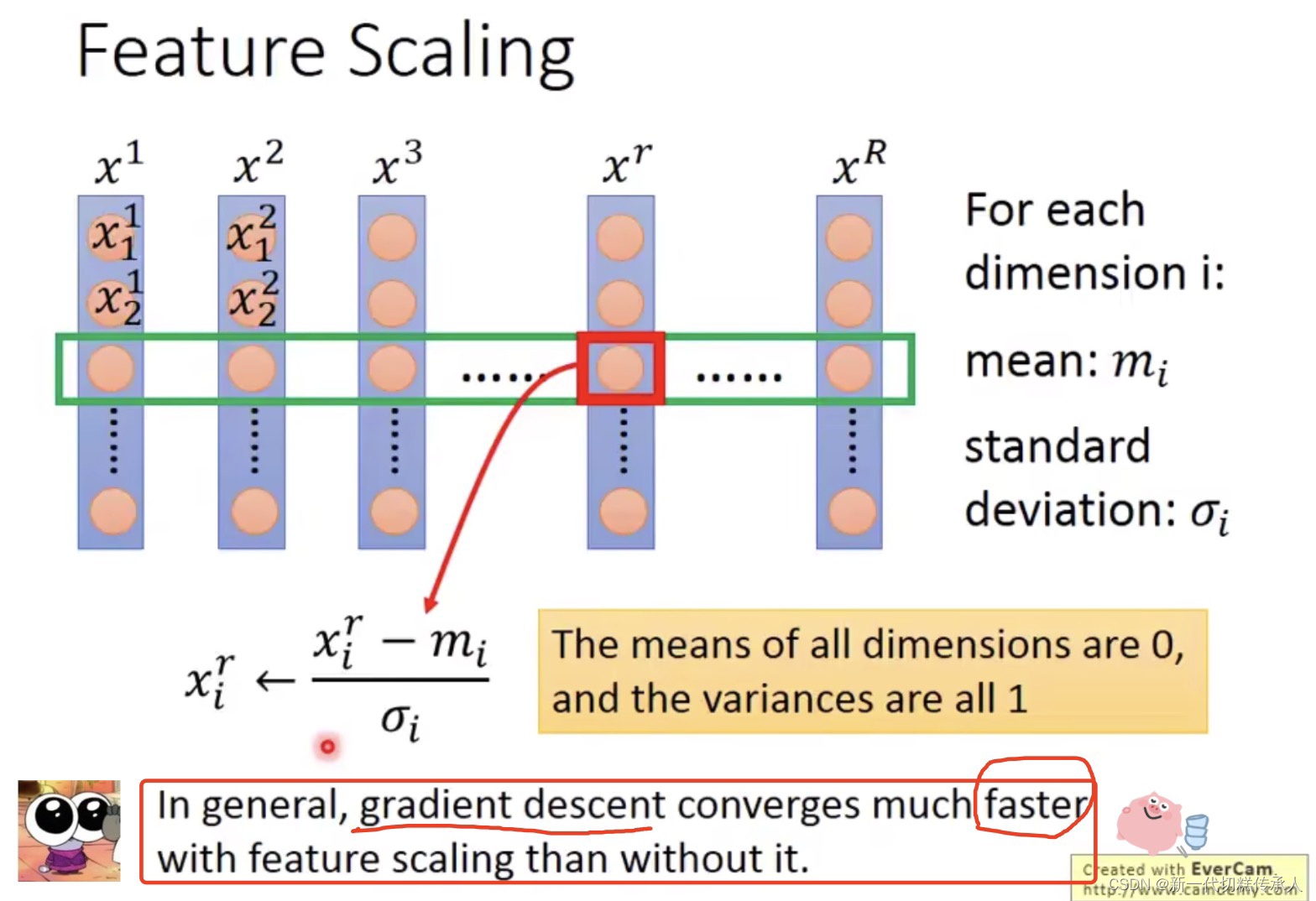
但是在网络中的hidden layers,都吃上一层输出的结果作为input,而这些数据是否也需要 Feature Scaling???
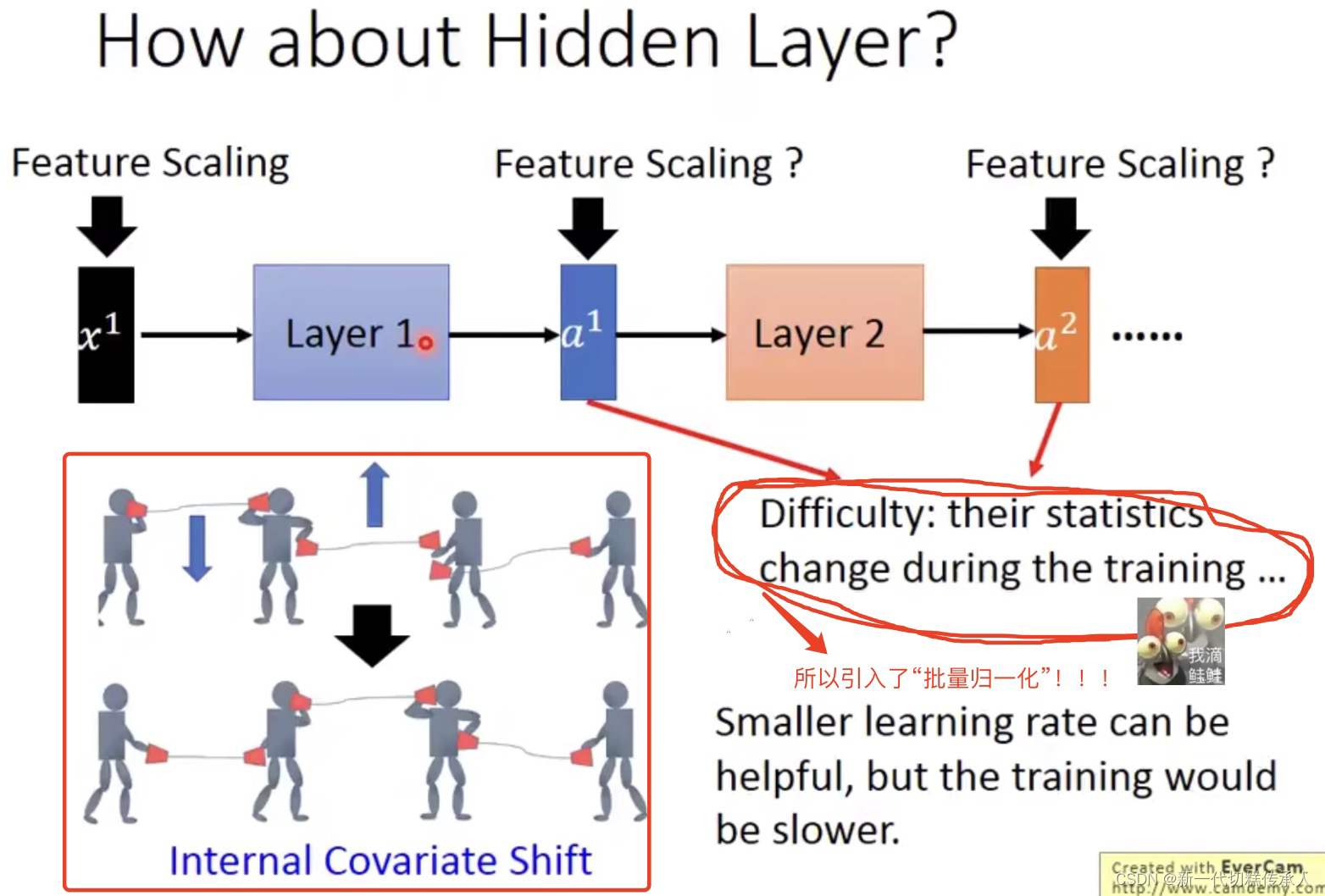
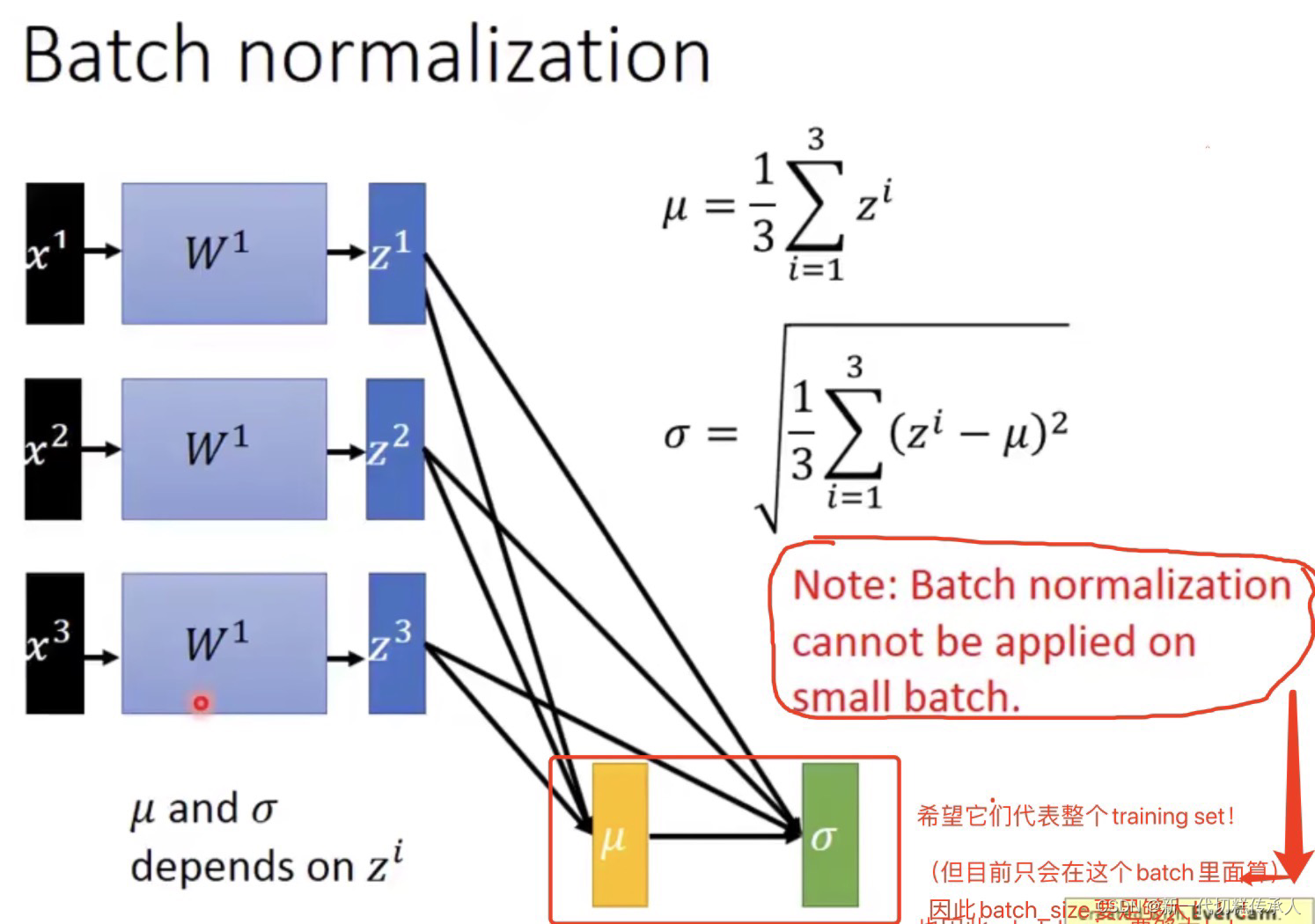
由上图可知:BN不可以在太小的batch上面被很好地应用,因为太小的batch计算得到的两个统计参数并不能很好地代表整个training set。因此,batch_size要足够大!!!
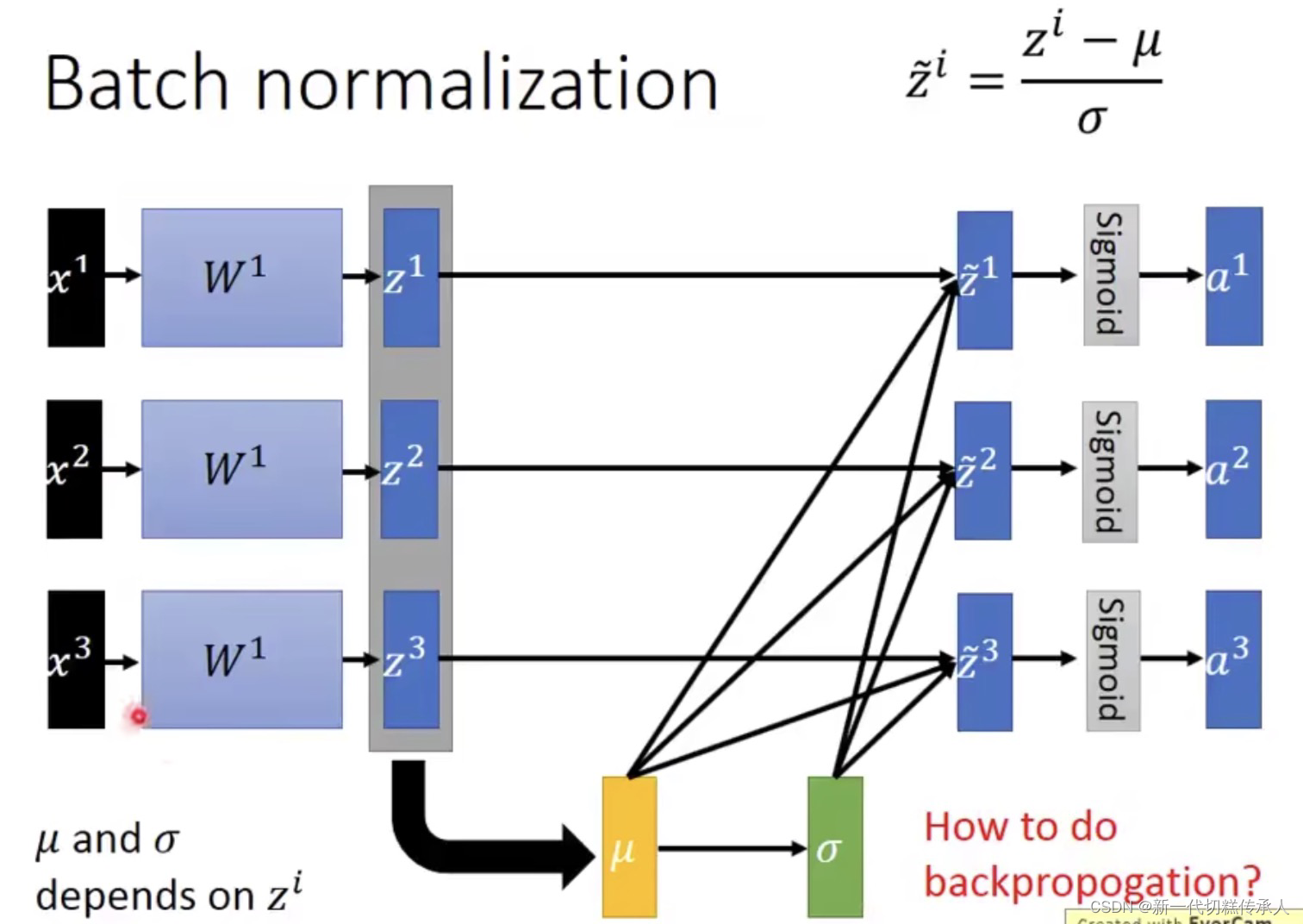
在 Testing stage / Inference时,如何使用 Batch Norm???
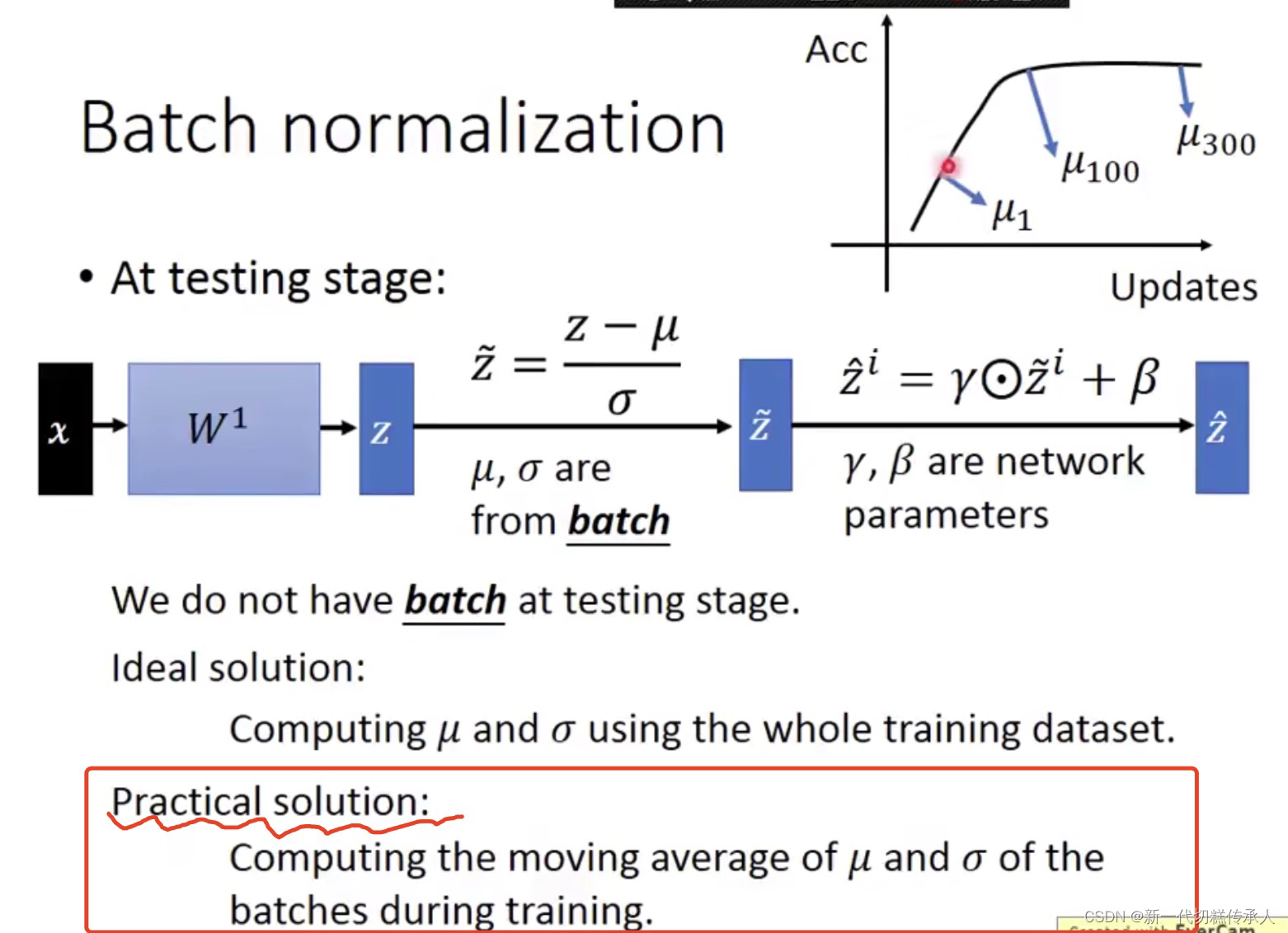
BN可以提速,但一般不改变模型的精度。
4.4 四种常见的「网络归一化」

4.5 信息传递(编码器 --> 解码器)

相关文章:
【Transformer】自注意力机制Self-Attention | 各种网络归一化Normalization
1. Transformer 由来 & 特点 1.1 从NLP领域内诞生 "Transformer"是一种深度学习模型,首次在"Attention is All You Need"这篇论文中被提出,已经成为自然语言处理(NLP)领域的重要基石。这是因为Transfor…...
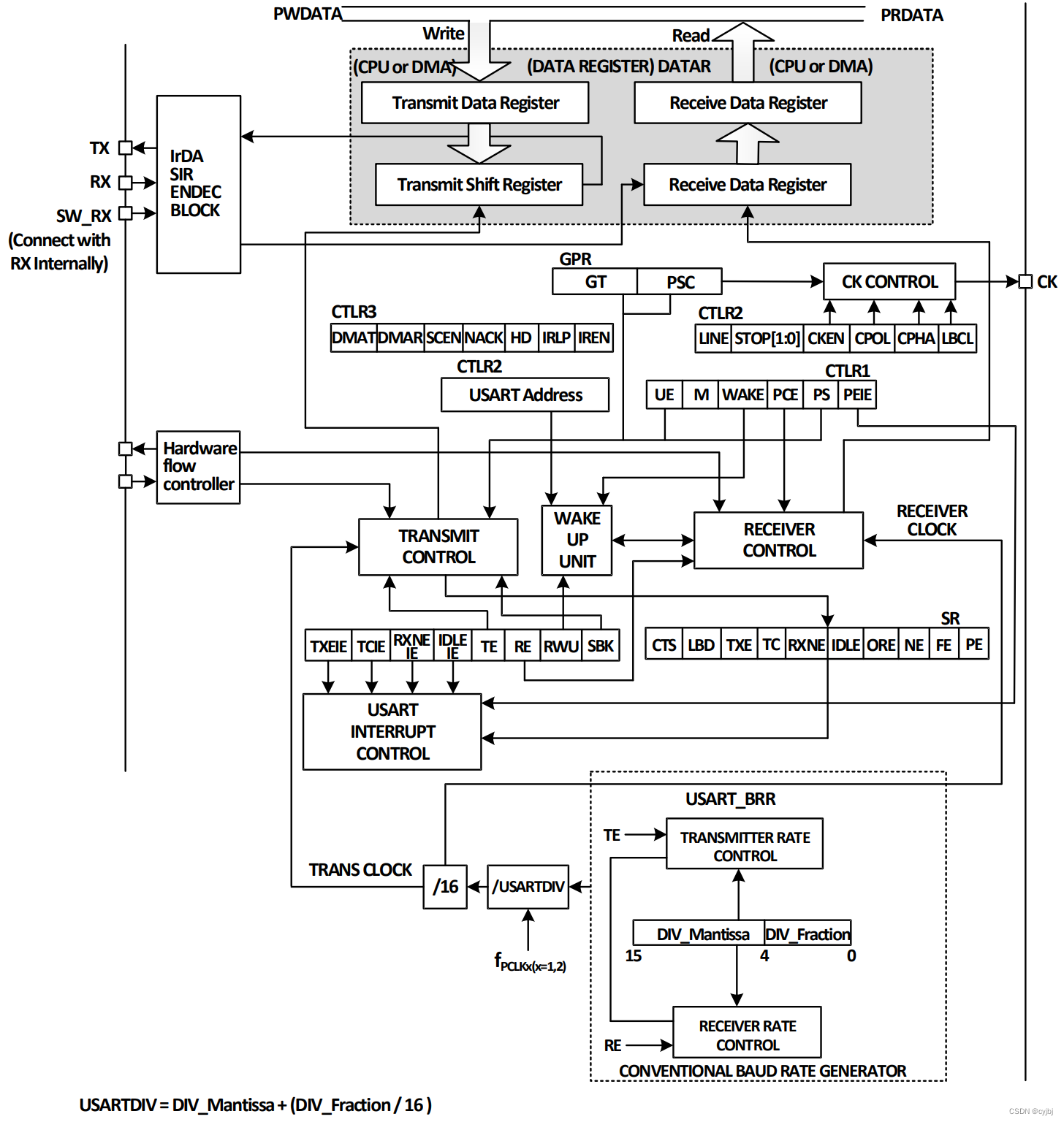
沁恒ch32V208处理器开发(四)串口通信
目录 串口资源资源配置同步模式单线半双工模式中断DMA 串口的初始化串口通信的实现 串口资源 资源配置 CH32V208 系列,是基于 RISC-V 指令架构设计的 32 位 RISC 内核 MCU,根据封装的不同,可用的USART串口资源如下表所示: 且US…...
)
【BASH】回顾与知识点梳理(十八)
【BASH】回顾与知识点梳理 十八 十八. 条件判断式18.1 利用 test 指令的测试功能文件类型判断文件权限侦测两个文件之间的比较两个整数之间的判定判定字符串的数据多重条件判定 18.2 利用判断符号 [ ]18.3 Shell script 的默认参数($0, $1...)shift:造成参数变量号码…...

linux 目录操作命令
目录操作命令 文件列表 ls命令文件列表 ls [选项] [参数]-------------------------------l 详细信息-L 紧接着符号性连接,列出它们指向的文件-a 所有文件,包含隐藏文件(以点号起始的文件)-A 与-a相同,但是不会列出来. 和 ..-c 根据创建时间排…...
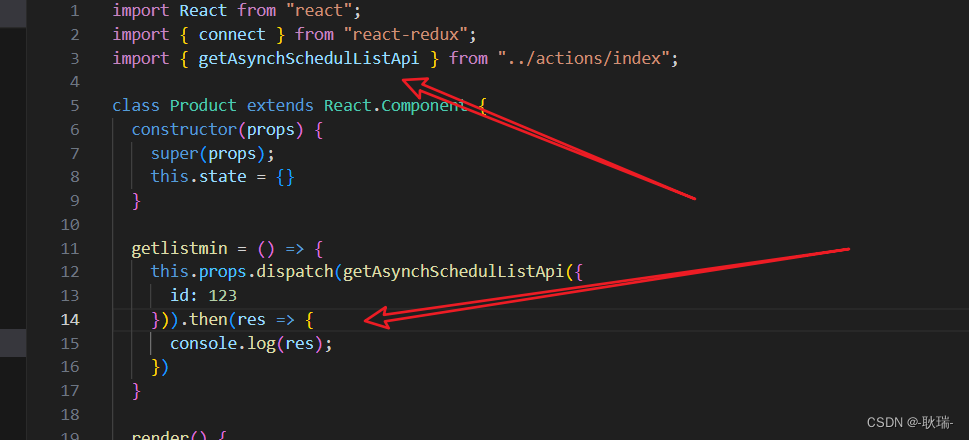
React Dva项目小优化之redux-action
之前 我们讲过 models 接下啦 我们来给大家讲一个新的库 这个库的话 有最好 没有影响也不大 它主要是帮助我们处理 action的 我们直接在 GitHub 官网上搜索 redux-action 我们搜出来 第一个就是 从星数来看 还是非常优秀的 我们拉下来 找到这个Documentation 然后点击进去 进…...
Kotlin反射访问androidx.collection.LruCache类私有变量
Kotlin反射访问androidx.collection.LruCache类私有变量 androidx.collection.LruCache类中定义了一个名为map的LinkedHashMap,map存储了所有LruCache的数据,有时候需要遍历访问该LinkedHashMap,取出里面的值,但是LruCache代码实…...

高级进阶多线程——多任务处理、线程状态(生命周期)、三种创建多线程的方式
Java多线程 Java中的多线程是一个同时执行多个线程的进程。线程是一个轻量级的子进程,是最小的处理单元。多进程和多线程都用于实现多任务处理。 但是,一般使用多线程而不是多进程,这是因为线程使用共享内存区域。它们不分配单独的内存区域…...

【 K8S 】 Pod 进阶
目录 //资源限制官网示例:重启策略 //健康检查:又称为探针(Probe) //资源限制 当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源。 当为 Pod 中…...

众和转债,宏微转债,阳谷转债上市价格预测
众和转债 基本信息 转债名称:众和转债,评级:AA,发行规模:13.75亿元。 正股名称:新疆众和,今日收盘价:8.14元,转股价格:8.2元。 当前转股价值 转债面值 / 转股…...
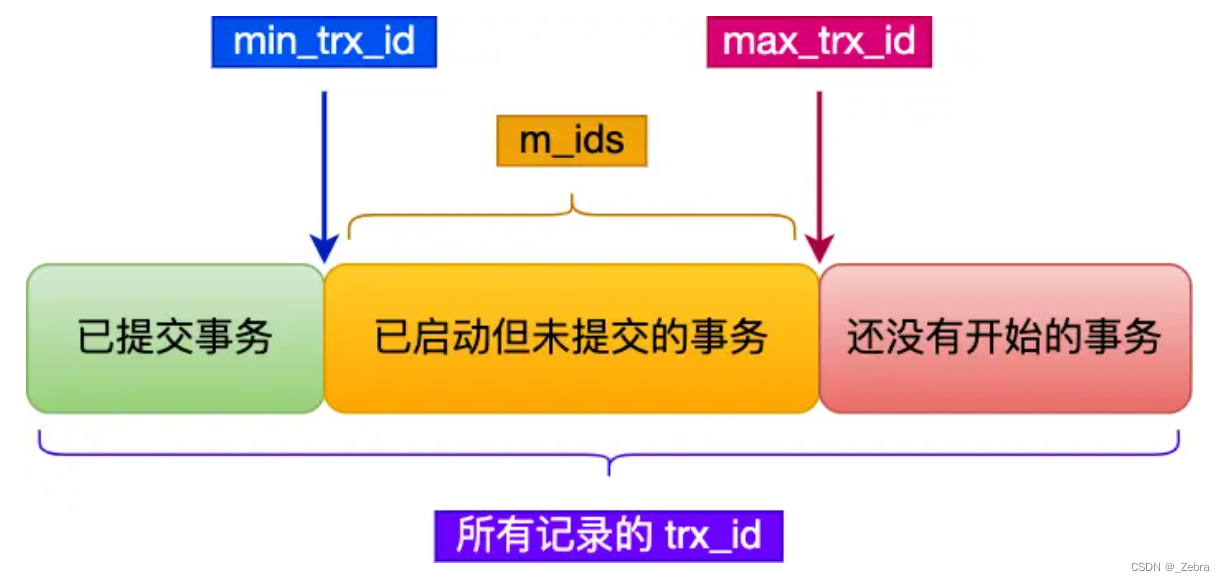
MySQL~事务的四大特性和隔离级别
事务的四大特性 1.原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个…...
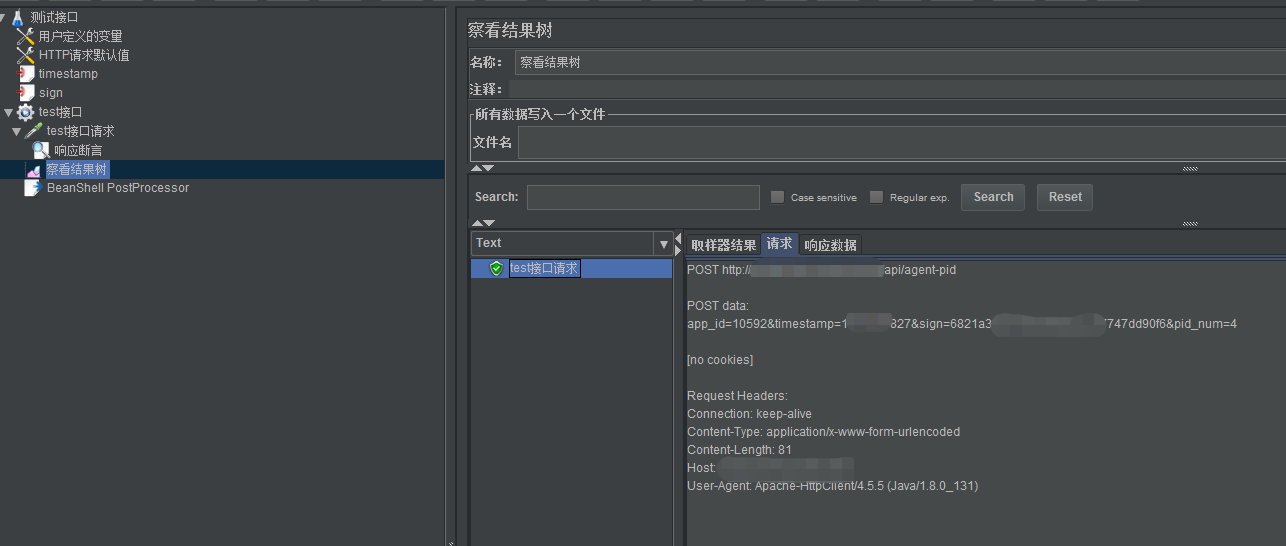
JMeter处理接口签名之BeanShell实现MD5加密
项目A需要给项目B提供一个接口,这个接口加密了,现在需要测试这个接口,需要怎么编写脚本呢?实现接口签名的方式有两种:BeanShell实现MD5加密和函数助手实现MD5加密,之前已经分享过了函数助手实现MD5加密&…...

【Golang】一文学完 Golang 基本语法
Golang 下载 安装包链接:https://share.weiyun.com/InsZoHHu IDE 下载:https://www.jetbrains.com/go/ 第一个 golang 程序 package mainimport "fmt"func main() {fmt.Println("hello golang") }每个可执行代码都必须包含 Pack…...

《Java-SE-第三十五章》之方法引用
前言 在你立足处深挖下去,就会有泉水涌出!别管蒙昧者们叫嚷:“下边永远是地狱!” 博客主页:KC老衲爱尼姑的博客主页 博主的github,平常所写代码皆在于此 共勉:talk is cheap, show me the code 作者是爪哇岛的新手,水平很有限&…...

Effective Java笔记(33)优先考虑类型安全的异构容器
泛型最常用于集合,如 Set<E >和 Map<K ,V>,以及单个元素的容器 ,如 ThreadLocal<T>和 AtomicReference<T> 。 在所有这些用法中,它都充当被参数化了的容器 。 这样就限制每个容器…...

释放AI创作潜能:从大模型训练到高产力应用
文章目录 每日一句正能量前言什么是人工智能生成内容(AIGC)人工智能生成内容(AIGC)能做什么为什么要用人工智能生成内容(AIGC)创作成果用Java实现冒泡排序算法学生信息收集系统学生请假管理系统需求分析教务…...
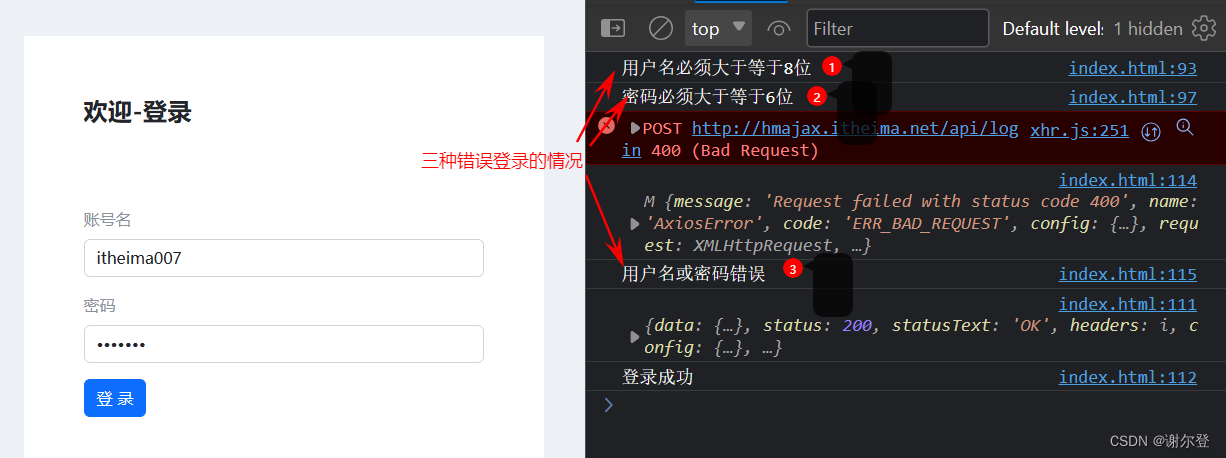
Ajax 笔记(一)—— Ajax 入门
笔记目录 1. Ajax 入门1.1 Ajax 概念1.2 axios 使用1.2.1 URL1.2.2 URL 查询参数1.2.3 小案例-查询地区列表1.2.4 常用请求方法和数据提交1.2.5 错误处理 1.3 HTTP 协议1.3.1 请求报文1.3.2 响应报文 1.4 接口文档1.5 案例1.5.1 用户登录(主要业务)1.5.2…...
Android Studio跳过Haxm打开模拟器
由于公司权限限制无法安装Haxm,这个时候我们可以试试Arm相关的镜像去跳过Haxm运行模拟器。解决方案:安装API27以下的Arm Image. #ifdef __x86_64__if (sarch "arm64" && apiLevel >28) {APANIC("Avds CPU Architecture %s i…...

从一个GPU到多个GPU
在多GPU运行应用程序时,需要正确设计GPU之间的通信,GPU间数据传输的效率取决于GPU是如何连接在一个节点上并跨集群的 在多GPU系统里有两种连接方式 多GPU通过单个节点连接到PCIe总线上 多GPU连接到集群中的网络交换机上 /* * 本示例演示了如何使用 Open…...

小白编写一个Chrome
步骤 1:了解插件的基本结构和功能 首先,向小白解释什么是Chrome插件,它是如何工作的,以及它可以做什么。强调插件可以修改网页内容、添加功能等。 步骤 2:准备工作 安装Chrome浏览器:确保小白的计算机上…...
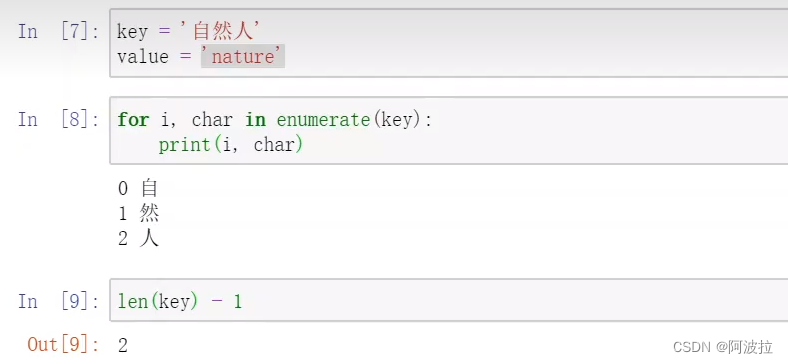
自然语言处理学习笔记(六)————字典树
目录 1.字典树 (1)为什么引入字典树 (2)字典树定义 (3)字典树的节点实现 (4)字典树的增删改查 DFA(确定有穷自动机) (5)优化 1.…...

AGI决策黑箱正在吞噬信任:5个致命可解释性漏洞,今天不修复明天就合规崩盘
第一章:AGI决策黑箱正在吞噬信任:5个致命可解释性漏洞,今天不修复明天就合规崩盘 2026奇点智能技术大会(https://ml-summit.org) 当医疗AI单方面否决肿瘤手术建议、信贷模型在无明确依据下拒绝千万级企业贷款申请、自动驾驶系统突然接管却无…...
)
从SPI Slave到主控:用两块ESP32玩转双向数据透传(附完整工程)
从SPI Slave到主控:用两块ESP32玩转双向数据透传(附完整工程) 在物联网和嵌入式开发领域,设备间的高速数据通信一直是开发者面临的挑战之一。想象一下这样的场景:你需要将一组环境传感器采集的温度、湿度数据实时传输到…...

告别推理卡顿:实测TensorRT INT8量化后,VGG-13推理速度提升7倍的完整配置流程
实战TensorRT INT8量化:VGG-13推理速度提升7倍的完整指南 从理论到实践:INT8量化的技术全景 在深度学习模型部署领域,INT8量化技术正在掀起一场效率革命。当我们把目光投向实际生产环境时,会发现FP32精度的模型虽然能提供优异的准…...

告别蓝绿滤镜:用WaterGAN和Python实战,5分钟搞定水下照片色彩还原
水下照片色彩还原实战:5分钟用WaterGAN让蓝绿世界重焕生机 每次潜水归来,看着相机里那些被蓝绿色调吞噬的照片,总有种说不出的遗憾。珊瑚本该是绚丽的橙红,热带鱼身上的花纹应当鲜艳夺目,但在水下摄影中,这…...

【OCR进阶】从CRNN+CTC到端到端文本识别实战
1. 为什么需要端到端文本识别技术 想象一下你正在开发一个停车场自动收费系统。当车辆驶入时,摄像头拍下车牌照片,传统做法可能需要先定位车牌位置(检测),然后切割每个字符(分割),最…...

《JAVA面经实录》- Web后端面试题
《JAVA面经实录》- Web后端面试题一、《JAVA面经实录》- HTTP面试题1.HTTP协议是什么?HTTP是一个基于TCP/IP通信协议来传递数据,包括html文件、图像、结果等,即是一个客户端和服务器端请求和应答的标准。基本上用到的就是GET和POST࿰…...

docker运行容器
【-it交互式启动容器】docker run -it --gpus all --networkhost --ipchost --rm --name qwen3.5-test \-v /home/vllm-models/Qwen3___5-35B-A3B:/home/vllm-models/Qwen3___5-35B-A3B \-v /etc/localtime:/etc/localtime:ro \-v /etc/timezone:/etc/timezone:ro \--entrypoin…...

如何快速上手Citra模拟器:3步完成3DS游戏体验的终极指南
如何快速上手Citra模拟器:3步完成3DS游戏体验的终极指南 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/GitHub_Trending/ci/citra Citra是一款开源的任天堂3DS模拟器,让你能在PC上畅玩经典的3DS游戏。无论你是想…...

旧本焕新记:华硕A555L低成本改造实战与取舍
1. 老旧笔记本改造的价值评估 拿到这台华硕A555L的第一件事,就是评估它是否值得改造。这台2015年上市的笔记本,配置确实有些年头了:i5-5200U处理器、4GB内存、500GB混合硬盘,再加上入门级的NVIDIA 930M显卡。说实话,现…...

WarcraftHelper:3步解决魔兽争霸3在Win11的兼容性问题
WarcraftHelper:3步解决魔兽争霸3在Win11的兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在Windows 10/11上频…...