PyTorch 微调终极指南:第 1 部分 — 预训练模型及其配置

一、说明
如今,在训练深度学习模型时,通过在自己的数据上微调预训练模型来迁移学习已成为首选方法。通过微调这些模型,我们可以利用他们的专业知识并使其适应我们的特定任务,从而节省宝贵的时间和计算资源。本文分为四个部分,侧重于微调模型的不同方面。
第一部分概述
- 简介 — 模型及其配置
- 加载预训练模型
- 修改模型头
- 设置学习率、优化器和权重衰减
- 选择损失函数
- 冻结全部或部分网络
- 定义模型浮点精度
- 训练和验证模式
- 单显卡和多显卡
- 结论
二、介绍
定义模型包括一系列重要决策,包括选择合适的架构、自定义模型头、配置损失函数和学习率、设置所需的浮点精度以及确定要冻结或微调的层等等。在本文中,我们将详细探讨这些方面,提供有价值的见解来帮助您有效地定义和微调模型。
2.1 加载预训练模型

DensNet 架构示例
在加载预先训练的模型之前,清楚地了解您的特定问题并相应地选择合适的架构至关重要。虽然此任务可能看起来具有挑战性,但重要的是不要随机选择模型体系结构。考虑您的业务要求,并选择符合这些需求的合适架构。
例如,如果您要对分类进行微调,并且低延迟是优先事项,那么像MobileNet这样的架构将是一个不错的选择。通过做出明智的架构决策,您可以优化微调实验以获得更好的结果。
请注意 — 您可以从多个来源加载预先训练的模型以进行微调。在本文中,我指的是timm(Pytorch图像模型)和Torchvision模型
下面是一个从火炬视觉加载预先训练的resnet50模型的示例:
# From torchvision.models
from torchvision import models
model = models.resnet50(pretrained=False)从 timm 加载(Pytorch 图像模型):
import timm# from timm
pretrained_model_name = "resnet50"
model = timm.create_model(pretrained_model_name, pretrained=False)需要注意的是,无论预训练模型的来源如何,所需的关键修改都是调整模型的全连接 FC 层(或者可以是线性/分类器/头部)。此外,对于您的目标任务,您可以合并额外的线性图层。我们将在下一节中进一步探讨这一点。
2.2 修改模型头
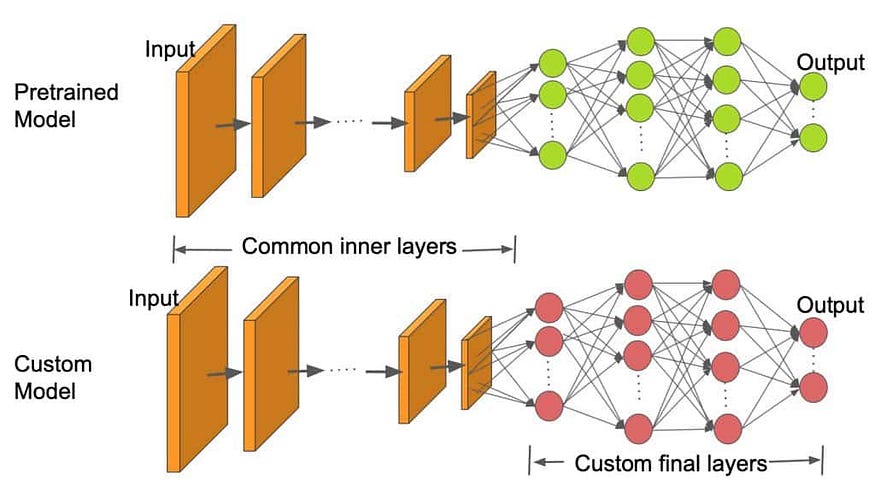
对适用于目标任务的预训练模型的视觉描述,具有除头部修改之外的其他层。来源: OpenCV
修改模型的头部对于使其与您的特定目标任务保持一致至关重要。预训练模型在大型数据集(如ImageNet)上进行图像分类,或在文本数据(如BooksCorpus和Wikipedia)上进行文本生成。通过修改模型的头部,预先训练的模型可以适应新任务并利用它所学到的有价值的特征,从而提高其在新任务中的性能。
例如,您可以修改分类任务的 RestNet 头:
import torch.nn as nn
import timmnum_classes = 4 # Replace num_classes with the number of classes in your data# Load pre-trained model from timm
model = timm.create_model('resnet50', pretrained=True)# Modify the model head for fine-tuning
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, num_classes)或者,您可以修改分类任务的 RestNet 头,同时添加额外的线性层以增强模型的预测能力(ps — 这只是一个说明性示例):
import torch.nn as nn
import timmnum_classes = 4 # Replace num_classes with the number of classes in your data# Load pre-trained model from timm
model = timm.create_model('resnet50', pretrained=True)# Modify the model head for fine-tuning
num_features = model.fc.in_features# Additional linear layer and dropout layer
model.fc = nn.Sequential(nn.Linear(num_features, 256), # Additional linear layer with 256 output featuresnn.ReLU(inplace=True), # Activation function (you can choose other activation functions too)nn.Dropout(0.5), # Dropout layer with 50% probabilitynn.Linear(256, num_classes) # Final prediction fc layer
)或者你可以修改 RestNet 头的回归任务:
model = timm.create_model('resnet50', pretrained=True)# Modify the model head for regression
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 1) # Regression task has a single output需要注意的一件事 — 模型并不总是有一个我们修改输出特征(例如,num_classes)的 FC(全连接)层。模型的架构可能会有所不同,我们需要修改的层的名称和位置可能会有所不同。
在许多预训练模型中,特别是在卷积神经网络 (CNN) 架构中,模型末尾通常有一个线性层或 FC 层来执行最终分类。但是,这不是一个严格的规则,某些模型可能具有不同的结构。
要识别需要修改的图层,您可以执行以下操作,例如:
import torch
import timm# Load pre-trained model from timm
model = timm.create_model('resnet50', pretrained=True)
print(model)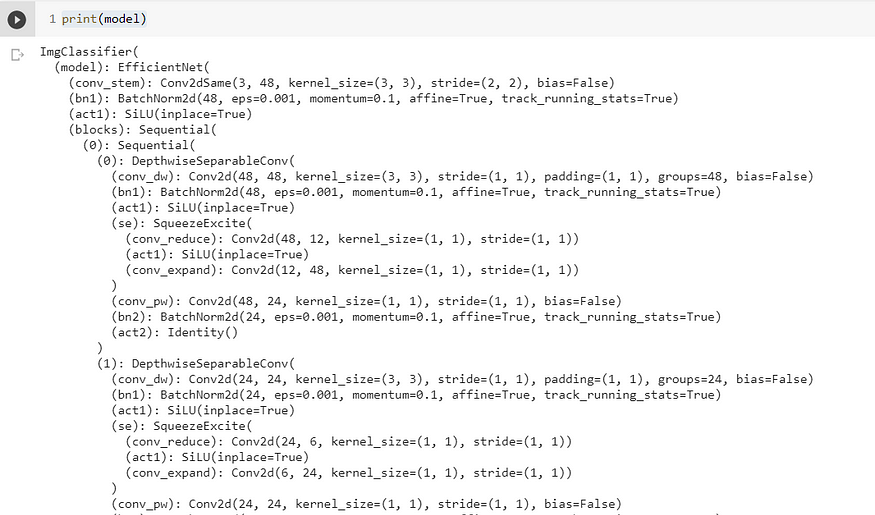
打印的模型架构显示需要修改的特定最后一层的标识。来源: kakaocdn.net
通过打印模型,您可以查看其体系结构并确定要修改的相应层。查找用作最终分类图层的线性或 FC 图层,并将其替换为与类数或任务要求匹配的新图层。
三、设置优化器、学习率、权重衰减和动量
Setting Optimizer, Learning Rate, Weight Decay, and Momentum
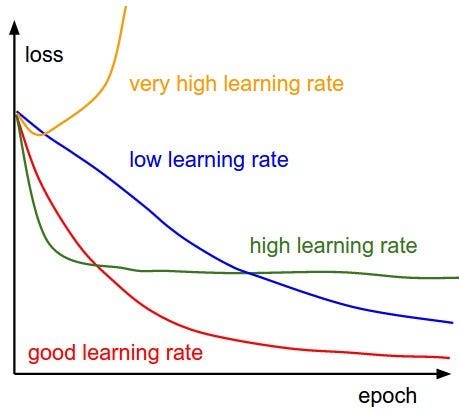
Image source
在微调中,学习率、损失函数和优化器是相互关联的组件,它们共同影响模型适应新任务的能力,同时利用从预训练中获得的知识。精心选择的学习率可确保以合理的速度有效收敛模型,精心选择的损失函数将训练过程中的损失最小化与目标任务对齐,适当的优化器可以有效地优化模型的参数。
微调需要对这些组件进行仔细的实验和迭代调整,以在微调模型中取得适当的平衡并达到所需的性能水平。
3.1 优化器
为了更详细地了解如何选择正确的优化器进行微调,我建议参考博客 https://towardsdatascience.com/7-tips-to-choose-the-best-optimizer-47bb9c1219e
优化器根据反向传播期间计算的梯度确定用于更新模型参数的算法。不同的优化器(如 SGD、Adam 或 RMSprop)具有不同的参数更新规则和收敛属性。优化器的选择会显著影响模型训练和微调模型的最终性能。选择最合适的优化器需要考虑任务的性质、数据集的大小和可用的计算资源等因素。
3.2 学习率、动量和权重衰减
在定义优化器时,我们还必须设置学习率(LR),这是一个超参数,用于确定优化期间每次迭代的步长。它控制在反向传播期间响应计算的梯度而更新的模型参数的量。选择合适的学习率至关重要,因为设置得太高可能会导致优化过程振荡或发散或超过最佳解,而设置得太低可能会导致收敛缓慢或陷入局部最小值。
除了学习率之外,在定义优化器时还需要考虑其他关键的超参数,例如权重衰减和动量(特定于 SGD)。让我们快速浏览一下这两个超参数:
- 权重衰减,也称为 L2 正则化,是一种用于防止过度拟合并鼓励模型学习更简单、更可泛化表示的技术。
- 动量用于随机梯度下降(SGD),以加速收敛并逃脱局部最小值。
import torch.optim as optim# Define your optimizer with weight decay
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.001)# Define your optimizer with weight decay
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=0.0001)四、选择损失函数
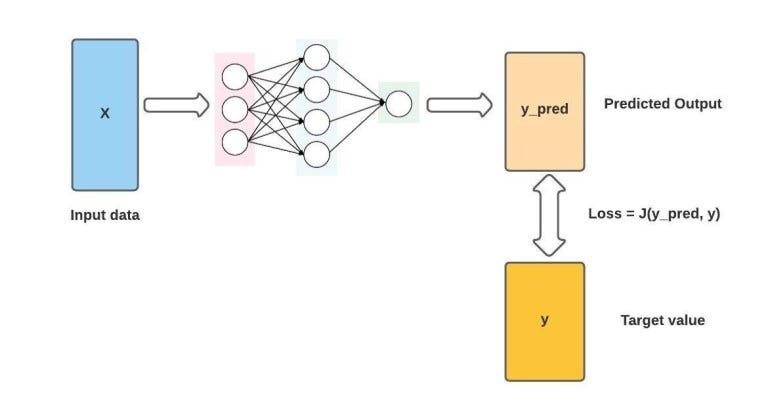
图片来源 : naptune.ai
要为您的目标任务探索和选择合适的损失函数,我建议参考有关损失函数的官方 PyTorch 文档。
损失函数测量模型的预测输出与实际正确答案之间的差异或差距。它为我们提供了一种了解模型在任务上的表现的方法。在微调预训练模型时,选择适合我们正在处理的特定任务的损失函数非常重要。例如,对于分类任务,通常使用交叉熵损失,而均方误差更适合回归问题。选择正确的损失函数可确保模型专注于在训练期间优化所需目标。
import torch.nn as nn# Define the loss function - For classification problem
loss_function = nn.CrossEntropyLoss()# Define the loss function - For regression problem
loss_function = nn.MSELoss() # Mean Squared Error loss还要注意的是,在选择和处理损失函数方面,还可以应用一些额外的考虑因素和技术。这方面的一些例子是:
- 自定义损失函数 — 您可能需要修改或自定义损失函数以满足特定要求。一个例子是对重要的单个类别的错误分类进行 10 倍的惩罚。下面是一个示例代码,演示了自定义损失的实现,为您提供了如何完成它的想法:
import torch
import torch.nn.functional as Fclass CustomLoss(torch.nn.Module):def __init__(self, class_weights):super(CustomLoss, self).__init__()self.class_weights = class_weightsdef forward(self, inputs, targets):ce_loss = F.cross_entropy(inputs, targets, reduction='none')weights = torch.ones_like(targets).float()for class_idx, weight in enumerate(self.class_weights):weights[targets == class_idx] = weightweighted_loss = ce_loss * weightsreturn torch.mean(weighted_loss)# Assuming you have a model and training data
model = YourModel()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Assuming 5 classes so class_weights = [1.0, 1.0, 1.0, 1.0, 10.0]
criterion = CustomLoss(class_weights=[1.0, 1.0, 1.0, 1.0, 10.0]) # Inside the training loop
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()- 基于指标的损失 — 在某些情况下,可能会根据损失本身以外的指标来评估模型的性能。在这种情况下,您可以设计或调整损失函数以直接针对这些指标进行优化。
- 正则化 — 正则化方法(例如 L1 或 L2 正则化)可以在微调期间合并到损失函数中,以防止过度拟合并改善模型泛化。正则化术语可以帮助控制模型的复杂性,并降低过分强调数据中特定模式或特征的风险。L2 正则化可以通过在优化器中设置值来应用,而 L1 正则化需要的方法略有不同。
weight_decay
L2 正则化实现:
# Define a loss function
criterion = nn.CrossEntropyLoss()# L2 regularization
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.01)L1 正则化实现:
# Define a loss function
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# Inside the training loop
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)# L1 regularization
regularization_loss = 0.0
for param in model.parameters():regularization_loss += torch.norm(param, 1)
loss += 0.01 * regularization_loss#Adjust regularization strength as needed还有一件事 😁

来源 : tenor.com
五、 冻结全部或部分网络

图片来源 : www.therescuevets.com
当我们提到冻结时,这意味着在微调过程中固定特定层或整个网络的权重。Netwrok 冻结允许我们保留预训练模型捕获的知识,同时只更新某些层以适应目标任务。因此,这非常重要,如果您正在微调预先训练的模型,则不应忽略这一点。
在微调之前,决定是应该冻结预训练模型的所有层(全网络)还是部分层,归结为你特定的目标任务。
例如,如果预训练模型已在类似于目标任务的大规模数据集上进行了训练,则冻结整个网络可以帮助保留学习的表示,防止它们被覆盖。在这种情况下,只有模型的头部被修改和从头开始训练。
另一方面,当预训练模型的较低层捕获可能与新任务相关的一般特征时,仅冻结网络的一部分可能很有用。通过冻结这些较低层,我们可以利用预先训练的模型的知识,同时更新较高层以专注于特定于任务的功能。此方法在目标数据集较小或与训练预训练模型的数据集明显不同的情况下特别有用。
要在 PyTorch 中实现冻结,您可以访问模型中的各个层或模块,并将其属性设置为 。这样可以防止在向后传递期间计算梯度和更新权重。requires_gradFalse
下面是一个示例代码,演示了冻结整个网络的实现:
# Freeze all the layers of the pre-trained model
for param in model.parameters():param.requires_grad = False# Modify the model's head for a new task
num_classes = 10
model.fc = nn.Linear(model.fc.in_features, num_classes)仅冻结网络中的卷积层:
# Freeze only the convolutional layers of the pre-trained model
for param in model.parameters():if isinstance(param, nn.Conv2d):param.requires_grad = False# Modify the model's head for a new task
num_classes = 10
model.fc = nn.Linear(model.fc.in_features, num_classes)仅冻结网络中的特定层:
# Freeze specific layers (e.g.,the first two convolutional layers) of the pre-trained model
for name, param in model.named_parameters():if 'conv1' in name or 'layer1' in name:param.requires_grad = False# Modify the model's head for a new task
num_classes = 10
model.fc = nn.Linear(model.fc.in_features, num_classes)请务必注意,考虑到任务和数据集的特定要求,应深思熟虑地进行冻结图层。这是利用预先训练的知识与允许模型有效适应新任务之间的微妙平衡。
六、定义模型浮点精度
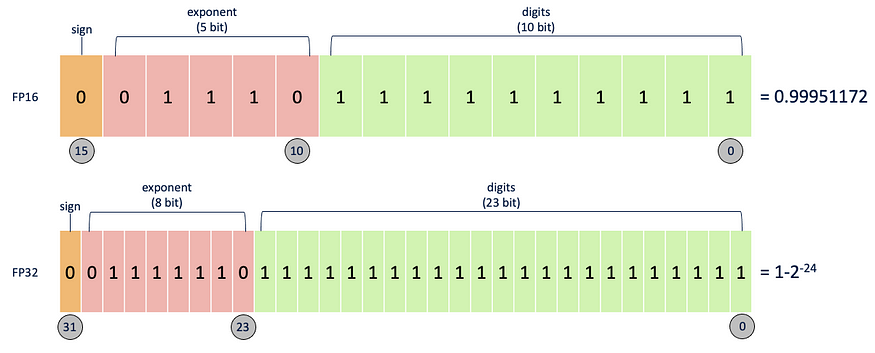
了解混合精度训练 乔纳森·戴维斯
快速汇总定义模型浮点精度是指深度学习模型中用于表示数值的数据类型。在 PyTroch 中,32 位(float32 或 FP32)和 16 位(float16 或 FP16 或半精度)是两种常用的浮点精度。
- float32 — 此精度提供宽动态范围和高数值精度,允许精确计算,但消耗更多内存。FP32 使用 32 位来表示一个数字。
- float16 — 这种较低的精度可以减少模型的内存占用和计算要求,从而可能提高效率和速度。但是,这可能会导致数值精度损失,并可能影响模型的准确性或收敛性。FP16 使用 16 位来表示一个数字。
FP16 和 FP32 被称为单精度,正如我们在上面的指针中看到的那样,两者都有自己的优点和缺点。为了利用两者的优势,我们有混合精度,它在训练管道中结合了 FP16 和 FP32 浮点精度。混合精度可提高计算效率、减少内存占用、加速训练并增加模型容量。
要更详细地了解混合精度训练,我建议参考文章“了解混合精度训练”
下面是如何使用自动混合精度 (AMP) 库在 PyTorch 训练管道中实现混合精度训练的示例:
import torch
from torch import nn, optim
from torch.cuda.amp import autocast, GradScaler# Define your model and optimizer
model = YourModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)# Define loss function
criterion = nn.CrossEntropyLoss()# Define scaler for automatic scaling of gradients
scaler = GradScaler()# Define your training loop
for epoch in range(num_epochs):for batch_idx, (data, targets) in enumerate(train_loader):data, targets = data.to(device), targets.to(device)# Zero the gradientsoptimizer.zero_grad()# Enable autocasting for mixed precisionwith autocast():# Forward passoutputs = model(data)loss = criterion(outputs, targets)# Perform backward pass and gradient scalingscaler.scale(loss).backward()# Update model parametersscaler.step(optimizer)scaler.update()# Print training progressif batch_idx % log_interval == 0:print(f"Epoch {epoch+1}/{num_epochs} | Batch {batch_idx}/{len(train_loader)} | Loss: {loss.item():.4f}")在上面的示例中,对象用于执行渐变缩放。以下是所用方法的细分:GradScaler()
scaler.scale(loss):此方法按缩放器确定的适当因子缩放损失值。它返回将用于向后传递的缩放损失。scaler.step(optimizer):此方法使用向后传递期间计算的梯度更新优化器的参数。它像往常一样执行优化器步骤,但考虑了缩放器执行的梯度缩放。scaler.update():此方法调整缩放器在下一次迭代中使用的比例因子。它通过根据梯度大小动态调整刻度来帮助防止下溢或溢出问题。它被称为 .scaler.step(optimizer)
使用和相关方法的目的是减轻使用低精度 (FP16) 计算时可能出现的潜在数值不稳定问题。通过适当地缩放损失和梯度,缩放器可确保优化器的更新保持在稳定的范围内。GradScaler()
这种使用 PyTorch 的 AMP 库实现混合精度训练的做法允许有效利用 FP16 计算,以提高训练速度并减少内存使用,同时保持使用 FP32 进行准确权重更新所需的精度。
虽然混合精度训练可以带来一些好处,但在某些情况下,它可能不适合或可能损害训练过程。
使用混合精度训练的潜在危害包括:
- 由于 FP16 导致的数值精度损失和这种精度损失可能会导致模型精度降低,尤其是在需要高精度的任务中。当涉及到数值精度关键型任务时,混合精度可能不适用。
- 由于训练期间的数值不稳定,下溢和溢出的脆弱性增加,这可能会影响模型的收敛性和性能。
- 由于混合精度而增加复杂性,这需要额外的考虑因素,例如管理精度转换、缩放梯度以及处理与精度不匹配相关的可能问题。
- 如果您的模型遇到严重的梯度爆炸或消失问题,则在混合精度训练中切换到低精度计算 (FP16) 可能会使这些问题恶化。 在这种情况下,在考虑混合精度训练之前,解决潜在的不稳定问题至关重要。
七、训练和验证模式

用于训练与验证(推理)模式的图像参考。图片来源 : teledyneimaging.com
微调模型时,在加载预训练模型后,它最初默认处于训练模式。但是,我们可以在推理或验证期间将模型切换到验证模式。这些模式更改会相应地改变模型的行为。
7.1 训练模式
当模型处于训练模式时,它会启用训练过程中所需的特定操作,例如计算梯度、更新参数和应用正则化技术(如 dropout)。在此模式下,模型的行为就像是在训练数据集上进行训练一样,并准备好从数据中学习。
model.train() # sets model in training mode7.2 验证模式
当模型处于评估模式时,它会禁用某些仅在训练期间需要的操作,例如计算梯度、dropout 和更新参数。此模式通常在验证或测试期间使用,当您想要评估模型对未见过的数据的性能时。
model.val() # sets model in validation mode在微调期间将模型设置为正确的模式非常重要,因为将模型设置为正确的模式可确保每个阶段(训练或评估)的行为一致和正确的操作。这样可以获得准确的结果、高效的资源使用,并防止过度拟合或规范化不一致等问题。
7.3 单显卡和多显卡

具有多个 GPU 的计算机。图片来源:普吉特系统
GPU 对于深度学习和微调任务至关重要,因为它们擅长执行高度并行的计算,从而显着加快训练过程。在可以访问多个 GPU 的情况下,您可以利用它们的集体力量来进一步加速训练。下面是如何利用多个 GPU 的示例(如果有):
# Define your model
model = MyModel()
model = model.to(device) # Move the model to the desired device (CPU or GPU)# Check if multiple GPUs are available
if torch.cuda.device_count() > 1:print("Using", torch.cuda.device_count(), "GPUs for training.")model = nn.DataParallel(model) # Wrap the model with DataParallel# Define your loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)此代码段首先使用 检查是否有多个 GPU 可用。如果有多个 GPU,则模型将包装为 ,允许它利用所有可用的 GPU 进行训练。每个 GPU 同时处理一部分数据,从而缩短训练时间。如果仅存在单个 GPU,则代码将在该 GPU 上运行,而不使用 .torch.cuda.device_count()nn.DataParallelnn.DataParallel
八、结论
在 PyTorch 微调终极指南的第一部分中,我们探讨了微调预训练模型以适应我们的特定任务所涉及的基本步骤。通过利用迁移学习,我们可以节省大量时间和计算资源,同时取得令人印象深刻的结果。在本文中,我们学习了如何加载预先训练的模型,调整其头部架构以匹配目标任务,以及自定义超参数(如学习率、优化器和权重衰减)以优化微调过程。此外,我们还研究了选择合适的损失函数以及冻结网络特定部分以实现更可控的微调的好处。
此外,我们还讨论了定义模型浮点精度的重要性,以及在微调期间在训练和验证模式之间切换的重要性。此外,我们还探讨了如何充分利用单 GPU 和多 GPU 设置来加速训练并提高性能。
在本系列的第 2 部分中,我们将深入研究高级技术,以提高微调模型的准确性和泛化能力。我们将探索数据增强、学习率时间表、梯度裁剪和集成等方法,以进一步提高模型在多样化和具有挑战性的数据集上的性能。
Ultimate Guide to Fine-Tuning in PyTorch : Part 1 — Pre-trained Model and Its Configuration | by Ruman Khan | Jul, 2023 | Medium
相关文章:
PyTorch 微调终极指南:第 1 部分 — 预训练模型及其配置
一、说明 如今,在训练深度学习模型时,通过在自己的数据上微调预训练模型来迁移学习已成为首选方法。通过微调这些模型,我们可以利用他们的专业知识并使其适应我们的特定任务,从而节省宝贵的时间和计算资源。本文分为四个部分&…...
GO学习之 微框架(Gin)
GO系列 1、GO学习之Hello World 2、GO学习之入门语法 3、GO学习之切片操作 4、GO学习之 Map 操作 5、GO学习之 结构体 操作 6、GO学习之 通道(Channel) 7、GO学习之 多线程(goroutine) 8、GO学习之 函数(Function) 9、GO学习之 接口(Interface) 10、GO学习之 网络通信(Net/Htt…...
C语言 字符指针
1、介绍 概念: 字符指针,就是字符类型的指针,同整型指针,指针指向的元素表示整型一样,字符指针指向的元素表示的是字符。 假设: char ch a;char * pc &ch; pc 就是字符指针变量,字符指…...

Springboot所有的依赖
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!-- 声明springboot的版本号 -->…...
Flutter BottomSheet 三段式拖拽
BottomSheetBehavior 追踪 BottomSheet系统默认实现效果准备要实现的功能点:定义三段式状态:BottomSheetBehavoir阀值定义1. 未达到滚动阀值,恢复状态2. 达到滚动阀值,更新状态 前面倒是有讲过Android原生的BottomSheetBehavior&a…...
php后端实现调用高德地图进行POI搜索
对于当前位置或者选定省市位置进行查询 接口实现 /*** 查询地址* ApiTitle (查询地址)* ApiSummary (查询地址)* ApiMethod (POST)* ApiRoute (/api/demo/address)* ApiParams (name"dart", type"integer", requiredtrue, description"省…...
uniapp 实现滑动视图切换 顶部滚动导航栏
无论小程序的时候一般有这个功能,在页面处于首页时候,滑动视图,切换视图顶部滚动导航也跟着切换 1.想要实现这个功能就需要实现顶部导航栏,首先实现顶部滚导航栏 点击高亮颜色显示 模板代码 <scroll-view scroll-x"true" class"scroll-content" > …...

ArcGIS API for JavaScript 调用自定义地图模板总结
ArcGIS API for JavaScript 调用自定义地图模板总结 3.9版本4.24版本 3.9版本 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><title>Hello World</title><link rel"stylesheet" href&qu…...

QGraphicsView实现简易地图5『经纬网格』
前文链接:QGraphicsView实现简易地图4『局部加载-地图漫游』 由于GCJ02 Web 墨卡托投影 纬度并不随像素等分,且两极跨度较大,因此本次演示采用的经纬网等分逻辑为等分像素。同等像素跨度之间,两级纬度变化较小,越靠近赤…...
RestTemplate 请求转发异常 ERR_CONTENT_DECODING_FAILED 200 (OK)
#1 问题描述 在基于Spring Boot的项目中实现了请求转发(使用 RestTemplate 的 exchange 方法)的功能,忽然在前端报net::ERR_CONTENT_DECODING_FAILED 200 (OK)的错误,后端及上游系统日志均显示请求已完成。 #2 原因探寻 上述错…...

用python实现一个异或计算器
有这样一条需求:计算某个文件中的数组每一行元素的最后一个参数,异或输出。 因为元素比较多,十几行,通过人工去计算异或值非常困难。 而在线异或的计算器,也需要人为输入这些数值,每次计算一个最终结果需…...
Sketch打不开AI文件?转换方法在这里
1、对比设计软件 Sketch 与 AI 软件功能 Sketch 与 Illustrator 都是行业内优秀的矢量图形设计软件,各有千秋。Sketch 从 2010 年面世,专注 APP 界面设计,深受初学者与专业人士喜爱。Illustrator 拥有更悠久的历史,是处理复杂图标…...

小游戏扫雷实现教学(详解)
目录 【前言】 一、模块化程序设计(多文件编程)介绍 1.概述 2.传统编程的方式 3.模块化程序设计的方法 二、扫雷代码设计思路 三、扫雷代码设计 1.创建菜单函数 2.实现9x9扫雷 3.初始化棋盘 4.打印棋盘 5.随机布置雷的位置 6.排查雷的信息 7.回…...
04 mysql innodb record
前言 最近看到了 何登成 大佬的 "深入MySQL源码 -- Step By Step" 的 pdf 呵呵 似乎是找到了一些 方向 之前对于 mysql 方面的东西, 更多的仅仅是简单的使用[业务中的各种增删改查], 以及一些面试题的背诵 这里会参照 MySQL Internals Manual 来大致的看一下 i…...

Centos7安装Docker
0.安装Docker Docker 分为 CE 和 EE 两大版本。CE 即社区版(免费,支持周期 7 个月),EE 即企业版,强调安全,付费使用,支持周期 24 个月。 Docker CE 分为 stable test 和 nightly 三个更新频道…...
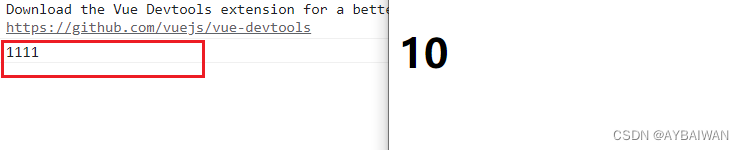
Vue中如何更好地封装组件?
子组件接受父组件传递的事件 1.子组件使用事件名"$emit(父组件中传递的事件名,想给父组件传递的参数(可选))" click"$emit(click)" 2.子组件使用 v-on"$listeners" 父组件: <template><div id"app"><myCo…...
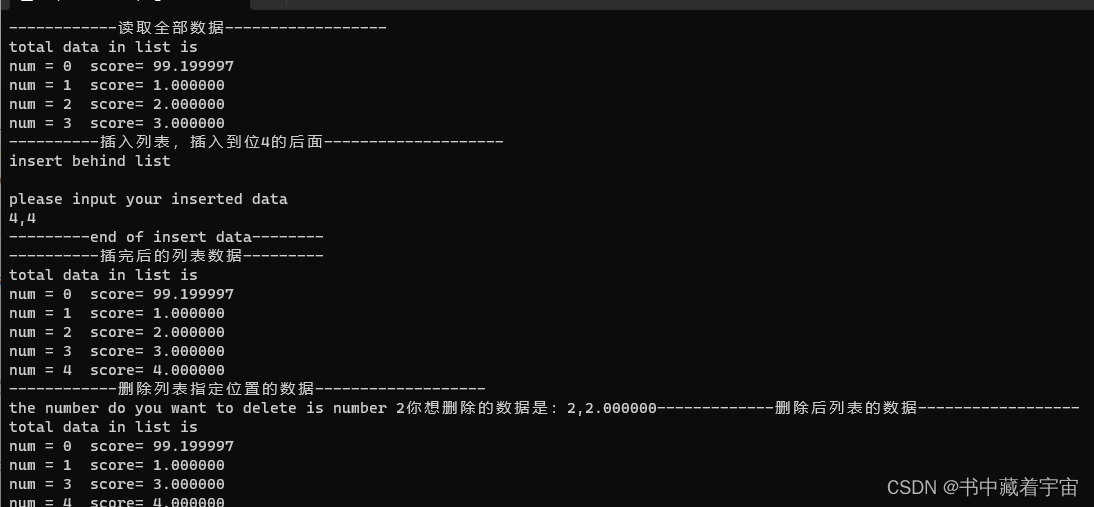
C语言的链表的相关操作
本变博客源于自己想复习一下C语言,所以便自己动手复习了一下链表的相关操作。做个人记录使用。 main.c #include <stdio.h> #include "list.h"int main() {student *a;printf("hello world\n") ;printf("----初始化列表----------\…...

Python3中typing模块
Python类型注解是Python 3.5版本之后引入的新特性,它可以让开发者在函数、变量等声明时为其指定类型。typing模型能够声明类型,防止运行时出现参数和返回值类型不符合的问题。 ### 1. 基本类型注解 def hello(name: str) -> str:return (Hello, na…...

C语言自动抓取淘宝商品详情网页数据,实现轻松高效爬虫
你是否曾经遇到过需要大量获取网页上的数据,但手动复制粘贴又太过费时费力?那么这篇文章就是为你而写。今天我们将会详细讨论如何使用C语言实现自动抓取网页上的数据。本文将会从以下8个方面进行逐步分析讨论。 1. HTTP协议的基本原理 在开始之前&…...
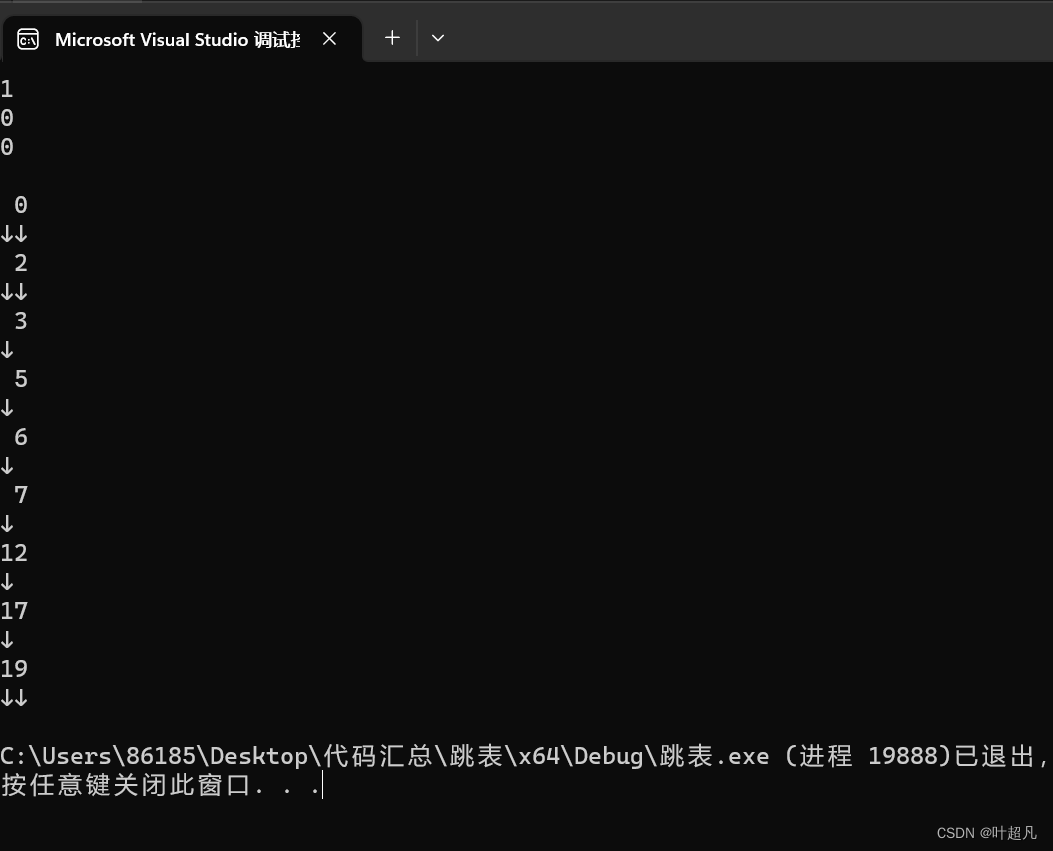
数据结构---跳表
目录标题 为什么会有跳表跳表的原理跳表的模拟实现准备工作find函数insert函数erase函数 测试效率比较 为什么会有跳表 在前面的学习过程中我们学习过链表这个容器,这个容器在头部和尾部插入数据的时间复杂度为O(1),但是该容器存在一个缺陷就是不管数据…...
保姆级避坑指南)
在Ubuntu 20.04上从零搭建宇树Z1机械臂仿真环境(ROS Noetic + Gazebo)保姆级避坑指南
在Ubuntu 20.04上从零搭建宇树Z1机械臂仿真环境(ROS Noetic Gazebo)保姆级避坑指南 宇树Z1作为一款轻量级协作机械臂,其ROS仿真环境的搭建是开发者进行算法验证和功能测试的关键第一步。本文将手把手带你完成从裸机到完整仿真环境的配置过程…...

从《倘若鸟儿回还》看无障碍设计:如何用技术为轮椅用户打造真正的“独立出行”体验
从《倘若鸟儿回还》看无障碍设计:如何用技术为轮椅用户打造真正的“独立出行”体验 艾米的故事让我们看到,残障人士对独立性的渴望往往被善意所掩盖。查尔斯希望成为她"唯一的推椅人",却忽略了轮椅对她而言不是束缚,而是…...

YgoMaster:构建专属游戏王决斗环境的实战手册
YgoMaster:构建专属游戏王决斗环境的实战手册 【免费下载链接】YgoMaster Offline Yu-Gi-Oh! Master Duel 项目地址: https://gitcode.com/gh_mirrors/yg/YgoMaster YgoMaster是一个基于.NET Framework 4.8开发的完整游戏王Master Duel离线对战平台ÿ…...
)
别再只会点灯了!用CubeMX和HAL库玩转GPIO的5个实用小技巧(附代码)
从基础到进阶:CubeMX与HAL库GPIO开发的5个实战技巧 在嵌入式开发中,GPIO操作看似简单,但真正高效地使用它却需要一些技巧。很多开发者停留在最基本的点亮LED阶段,却不知道CubeMX和HAL库提供了更多强大的功能可以提升开发效率和代码…...

跨平台音频下载解决方案:基于Go+Qt5混合架构的技术实现深度解析
跨平台音频下载解决方案:基于GoQt5混合架构的技术实现深度解析 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 在数字内…...

7大录制模式+双音轨独立控制:QuickRecorder让macOS录屏变得如此简单
7大录制模式双音轨独立控制:QuickRecorder让macOS录屏变得如此简单 【免费下载链接】QuickRecorder A lightweight screen recorder based on ScreenCapture Kit for macOS / 基于 ScreenCapture Kit 的轻量化多功能 macOS 录屏工具 项目地址: https://gitcode.co…...

别再傻傻地直接扫了!手把手教你用wafw00f在Windows和Kali上优雅地“试探”网站防火墙
优雅识别Web应用防火墙:wafw00f在Windows与Kali中的实战指南 当安全研究员面对一个陌生网站时,直接发起攻击就像蒙着眼睛走雷区——不仅危险,而且低效。真正的高手总会先做一件事:识别目标网站的防护体系。本文将带你用wafw00f这…...

C++ deprecated 关键字的实战指南:从标记到迁移的最佳实践
1. 理解C deprecated关键字的核心价值 第一次在代码里看到[[deprecated]]标记时,我正接手一个遗留的金融交易系统。那个满是警告的编译输出让我意识到,这个看似简单的属性其实是代码演化的时间胶囊。deprecated不是简单的"不要用"标签…...

第九节Amesim《三位四通换向阀HCD建模实战:从零到一构建精准模型》
1. 三位四通换向阀HCD建模入门指南 第一次接触Amesim的HCD建模时,我也被那些专业术语搞得一头雾水。直到接手一个液压系统项目,需要为某型号滑阀建立精确模型,才真正摸清门道。三位四通换向阀就像液压系统的交通警察,通过阀芯位移…...
技术详解:从理论到工程实践)
弧齿锥齿轮齿面接触分析(TCA)技术详解:从理论到工程实践
158.基于matlab的用于分析弧齿锥齿轮啮合轨迹的输出齿轮啮合轨迹及传递误差程序已调通,可直接运行1. 引言:TCA技术的重要性与挑战 弧齿锥齿轮作为机械传动系统的核心部件,其啮合质量直接影响整个传动装置的可靠性、效率和使用寿命。齿面接触分…...