C语言自动抓取淘宝商品详情网页数据,实现轻松高效爬虫
你是否曾经遇到过需要大量获取网页上的数据,但手动复制粘贴又太过费时费力?那么这篇文章就是为你而写。今天我们将会详细讨论如何使用C语言实现自动抓取网页上的数据。本文将会从以下8个方面进行逐步分析讨论。
1. HTTP协议的基本原理
在开始之前,我们需要了解HTTP协议的基本原理。HTTP是一种客户端和服务器端之间传输数据的协议,它使用TCP/IP协议作为传输层。当客户端需要访问某个服务器时,它会向服务器发送一个HTTP请求。服务器在接收到请求后,会返回一个HTTP响应。HTTP请求和响应都是由一个头部和一个可选的消息体组成。
2.使用C语言发送HTTP请求
在C语言中,我们可以使用libcurl库来发送HTTP请求。libcurl提供了一系列函数来处理网络请求,并且支持各种常见的网络协议,包括HTTP、FTP、SMTP等等。下面是一个简单的例子:
#include <stdio.h>#include <curl/curl.h>int main(void){ CURL *curl; CURLcode res; curl = curl_easy_init(); if(curl){ curl_easy_setopt(curl, CURLOPT_URL,";); res = curl_easy_perform(curl); if(res != CURLE_OK) fprintf(stderr,"curl_easy_perform() failed:%s\n", curl_easy_strerror(res)); curl_easy_cleanup(curl); } return 0;}
这个例子中,我们使用了curl_easy_init函数来初始化一个curl对象。然后,我们使用curl_easy_setopt函数来设置请求的URL。最后,我们使用curl_easy_perform函数来执行请求,并将返回结果存储在res变量中。
3.使用正则表达式解析HTML
当我们从网页上获取到数据后,我们需要对其进行解析。HTML是一种标记语言,因此我们可以使用正则表达式来进行解析。下面是一个简单的例子:
#include <stdio.h>#include <regex.h>int main(void){ regex_t regex; int reti; char msgbuf[100]; const char *pattern ="<title>(.*)</title>"; char *data ="<html><head><title>Example</title></head><body><p>Hello World!</p></body></html>"; reti = regcomp(®ex, pattern, REG_EXTENDED); if (reti){ fprintf(stderr,"Could not compile regex\n"); return 1; } reti = regexec(®ex, data,0, NULL,0); if (!reti){ puts("Match"); regmatch_t matches[2]; reti = regexec(®ex, data,2, matches,0); if (!reti){ printf("Match:%.*s\n",(int)(matches[1].rm_eo - matches[1].rm_so),&data[matches[1].rm_so]); } } else if (reti == REG_NOMATCH){ puts("No match"); } else { regerror(reti,®ex, msgbuf, sizeof(msgbuf)); fprintf(stderr,"Regex match failed:%s\n", msgbuf); return 1; } regfree(®ex); return 0;}
这个例子中,我们使用了正则表达式来匹配网页中的标题。首先,我们使用regcomp函数来编译正则表达式。然后,我们使用regexec函数来执行匹配操作,并将结果存储在matches数组中。
4.使用XPath解析HTML
除了正则表达式外,我们还可以使用XPath来解析HTML。XPath是一种用于在XML文档中进行导航的语言,它也可以用于HTML文档的解析。下面是一个简单的例子:
#include <stdio.h>#include <libxml/xpath.h>#include <libxml/HTMLparser.h>int main(void){ char *data ="<html><head><title>Example</title></head><body><p>Hello World!</p></body></html>"; htmlDocPtr doc = htmlReadMemory(data, strlen(data), NULL, NULL, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR); if (doc == NULL){ fprintf(stderr,"Failed to parse document\n"); return 1; } xmlXPathContextPtr context = xmlXPathNewContext(doc); if (context == NULL){ fprintf(stderr,"Failed to create XPath context\n"); xmlFreeDoc(doc); return 1; } xmlXPathObjectPtr result = xmlXPathEvalExpression((const xmlChar*)"//title/text()", context); if (result == NULL){ fprintf(stderr,"Failed to evaluate XPath expression\n"); xmlXPathFreeContext(context); xmlFreeDoc(doc); return 1; } if (xmlXPathNodeSetIsEmpty(result->nodesetval)){ fprintf(stderr,"No match found\n"); xmlXPathFreeObject(result); xmlXPathFreeContext(context); xmlFreeDoc(doc); return 1; } printf("Match:%s\n", result->nodesetval->nodeTab[0]->content); xmlXPathFreeObject(result); xmlXPathFreeContext(context); xmlFreeDoc(doc); return 0;}
这个例子中,我们使用了libxml2库来解析HTML。首先,我们使用htmlReadMemory函数将HTML文档读入内存,并解析成一个DOM树。然后,我们使用xmlXPathNewContext函数创建一个XPath上下文。接着,我们使用xmlXPathEvalExpression函数来执行XPath表达式,并将结果存储在result对象中。
5.使用JSON解析数据
当我们从网页上获取到数据时,它有可能是JSON格式的。JSON是一种轻量级的数据交换格式,易于阅读和编写。我们可以使用cJSON库来解析JSON数据。下面是一个简单的例子:
#include <stdio.h>#include <stdlib.h>#include <string.h>#include "cJSON.h"int main(void){ char *data ="{\"name\":\"John Smith\",\"age\":30,\"hobbies\":[\"reading\",\"swimming\"]}"; cJSON *root = cJSON_Parse(data); if (root == NULL){ fprintf(stderr,"Failed to parse JSON data\n"); return 1; } cJSON *name = cJSON_GetObjectItem(root,"name"); if (name == NULL){ fprintf(stderr,"Failed to get name\n"); cJSON_Delete(root); return 1; } printf("Name:%s\n", name->valuestring); cJSON *age = cJSON_GetObjectItem(root,"age"); if (age == NULL){ fprintf(stderr,"Failed to get age\n"); cJSON_Delete(root); return 1; } printf("Age:%d\n", age->valueint); cJSON *hobbies = cJSON_GetObjectItem(root,"hobbies"); if (hobbies == NULL){ fprintf(stderr,"Failed to get hobbies\n"); cJSON_Delete(root); return 1; } int i; for (i=0; i < cJSON_GetArraySize(hobbies);i++){ cJSON *hobby = cJSON_GetArrayItem(hobbies,i); printf("Hobby %d:%s\n", i +1, hobby->valuestring); } cJSON_Delete(root); return 0;}
这个例子中,我们使用了cJSON库来解析JSON数据。首先,我们使用cJSON_Parse函数将JSON数据解析成一个cJSON对象。然后,我们使用cJSON_GetObjectItem函数来获取对象中的属性。最后,我们使用cJSON_GetArrayItem函数来获取数组中的元素。6.使用数据库存储数据
当我们从网页上获取到数据时,我们可以将其存储到数据库中。在C语言中,我们可以使用SQLite库来操作数据库。下面是一个简单的例子:
#include <stdio.h>#include <sqlite3.h>static int callback(void *NotUsed, int argc, char **argv, char **azColName){ int i; for (i=0; i < argc;i++){ printf("%s=%s\n", azColName[i], argv[i]? argv[i]:"NULL"); } printf("\n"); return 0;}int main(void){ sqlite3 *db; char *zErrMsg =0; int rc; rc = sqlite3_open("test.db",&db); if (rc){ fprintf(stderr,"Can't open database:%s\n", sqlite3_errmsg(db)); sqlite3_close(db); return 1; } const char *sql ="CREATE TABLE IF NOT EXISTS users (" "id INTEGER PRIMARY KEY," "name TEXT NOT NULL," "age INTEGER NOT NULL)"; rc = sqlite3_exec(db, sql, NULL,0,&zErrMsg); if (rc != SQLITE_OK){ fprintf(stderr,"SQL error:%s\n", zErrMsg); sqlite3_free(zErrMsg); sqlite3_close(db); return 1; } sql ="INSERT INTO users (name, age) VALUES ('John Smith', 30)"; rc = sqlite3_exec(db, sql, NULL,0,&zErrMsg); if (rc != SQLITE_OK){ fprintf(stderr,"SQL error:%s\n", zErrMsg); sqlite3_free(zErrMsg); sqlite3_close(db); return 1; } sql ="SELECT * FROM users"; rc = sqlite3_exec(db, sql, callback,0,&zErrMsg); if (rc != SQLITE_OK){ fprintf(stderr,"SQL error:%s\n", zErrMsg); sqlite3_free(zErrMsg); sqlite3_close(db); return 1; } sqlite3_close(db); return 0;}
这个例子中,我们使用了SQLite库来操作数据库。首先,我们使用sqlite3_open函数打开一个数据库连接。然后,我们使用sqlite3_exec函数执行SQL语句。最后,我们使用回调函数来处理查询结果。
7.使用多线程提高效率
当我们需要从多个网页上获取数据时,我们可以使用多线程来提高效率。在C语言中,我们可以使用pthread库来创建和管理线程。下面是一个简单的例子:
#include <stdio.h>#include <pthread.h>void *thread_func(void *arg){ int i; for (i=0; i < 10;i++){ printf("Thread %d:%d\n",*((int*)arg),i); } return NULL;}int main(void){ pthread_t threads[4]; int thread_args[4]; int i; for (i=0; i <4;i++){ thread_args[i]= i +1; pthread_create(&threads[i], NULL, thread_func,&thread_args[i]); } for (i=0; i <4;i++){ pthread_join(threads[i], NULL); } return 0;}
这个例子中,我们使用了pthread库来创建和管理线程。首先,我们使用pthread_create函数创建一个新的线程,并将thread_args数组中的元素传递给线程函数。然后,我们使用pthread_join函数等待线程结束。
8.使用定时器实现定时抓取
当我们需要定时抓取网页上的数据时,我们可以使用定时器来实现。在C语言中,我们可以使用timer_create函数来创建一个定时器。下面是一个简单的例子:
#include <stdio.h>#include <signal.h>#include <time.h>void handler(int sig){ printf("Timer expired\n");}int main(void){ struct sigevent sev; timer_t timerid; struct itimerspec its; sev.sigev_notify = SIGEV_SIGNAL; sev.sigev_signo = SIGUSR1; sev.sigev_value.sival_ptr =&timerid; timer_create(CLOCK_REALTIME,&sev,&timerid); signal(SIGUSR1, handler); _sec =5; _nsec =0; _sec =5; _nsec =0; timer_settime(timerid,0,&its, NULL); while (1){f56ac3d0fc4809ae1c100a6b745ccf4b// do something } return 0;}
9.举例说明:通过C语言进行封装接口获取淘宝商品详情返回值说明
9.1公共参数
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中,演示demo地址) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 (复制Taobaoapi2014获取API SDK文件) |
9.2 请求示例(C语言)
#include<stdio.h>
#include <stdlib.h>
#include<string.h>
#include<curl/curl.h>int main(){CURL *curl; CURLcode res; struct curl_slist *headers=NULL; char url[] = "https://api.xxxxx.cn/taobao/item_get/?key=<您自己的apiKey>&secret=<您自己的apiSecret>&num_iid=商品ID&is_promotion=1";curl_global_init(CURL_GLOBAL_ALL); curl = curl_easy_init(); if(curl) {curl_easy_setopt(curl, CURLOPT_URL,url);headers = curl_slist_append(headers, "Content-Type: application/json"); curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers); res = curl_easy_perform(curl);if(res != CURLE_OK){printf("curl_easy_perform(): %s\n",curl_easy_strerror(res)); }curl_easy_cleanup(curl); }curl_global_cleanup();return 0;
}通过上面的代码,我们可以得到一个简单版的爬虫程序,它可以从目标网站上抓取内涵段子,并提取出来打印输出。
注意事项及高级技巧
在使用PHP编写爬虫程序时,需要注意以下事项:
遵循目标网站的robots.txt协议,不要滥用爬虫而导致网站崩溃;
使用cURL等工具时,需要设置User-Agent、Referer等头部信息,模拟浏览器行为;
对获取的HTML数据进行适当的编码处理,防止乱码问题;
避免频繁访问目标网站,操作过于频繁可能会被网站封禁IP地址;
如需获取验证码等需要人工干预的内容,需要使用图像识别技术等高级技巧。
通过以上这些注意事项和高级技巧,我们可以更好地应对不同的爬虫需求,实现更加高效、稳定的数据采集。
相关文章:

C语言自动抓取淘宝商品详情网页数据,实现轻松高效爬虫
你是否曾经遇到过需要大量获取网页上的数据,但手动复制粘贴又太过费时费力?那么这篇文章就是为你而写。今天我们将会详细讨论如何使用C语言实现自动抓取网页上的数据。本文将会从以下8个方面进行逐步分析讨论。 1. HTTP协议的基本原理 在开始之前&…...
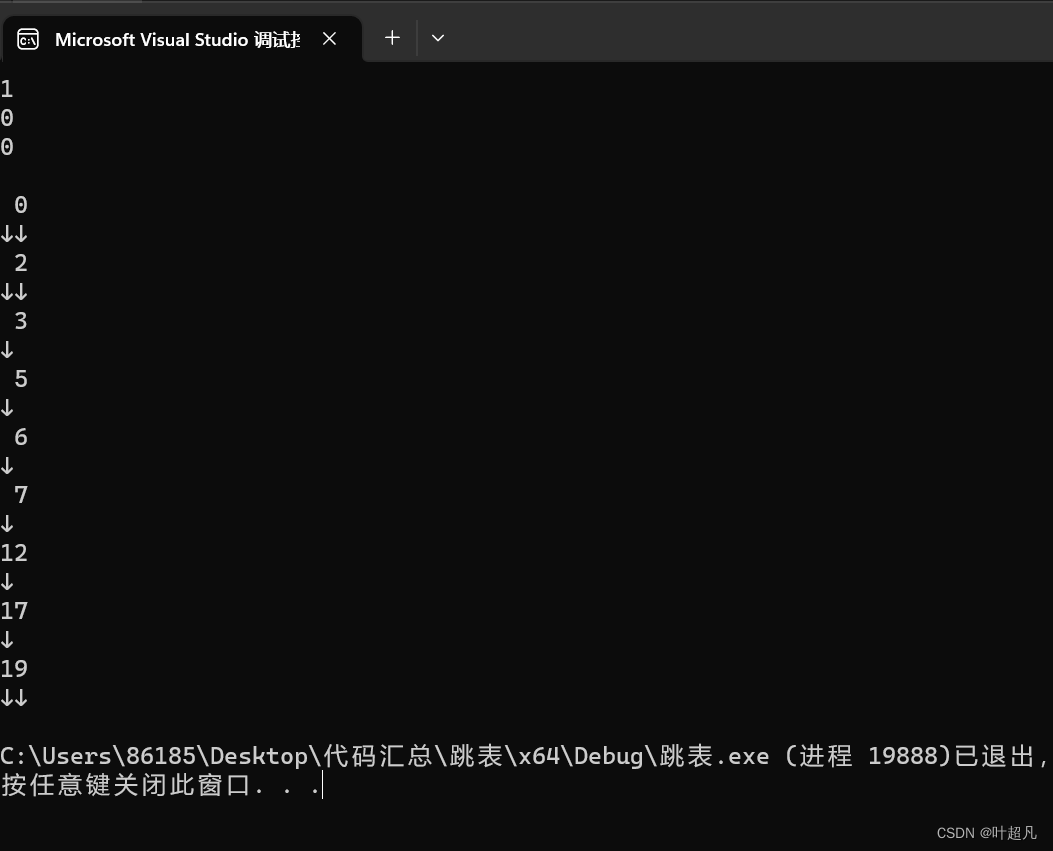
数据结构---跳表
目录标题 为什么会有跳表跳表的原理跳表的模拟实现准备工作find函数insert函数erase函数 测试效率比较 为什么会有跳表 在前面的学习过程中我们学习过链表这个容器,这个容器在头部和尾部插入数据的时间复杂度为O(1),但是该容器存在一个缺陷就是不管数据…...

为什么Tomcat的NIO在读取body时要模拟阻塞?
文章首发地址 Tomcat的NIO完全可以以非阻塞方式处理IO,为什么在读取body部分时要模拟阻塞呢?在Tomcat的NIO读取HTTP请求时,为了保证请求的正确性和可靠性,需要模拟阻塞模式,这是因为servlet规范里定义了ServletInputSt…...

26 | 谷歌应用APP数据分析
基于kaggle公开数据集,对谷歌应用市场的APP情况进行数据探索和分析。 from kaggle: https://www.kaggle.com/lava18/google-play-store-apps 分析思路: 0、数据准备 1、数据概览 2、种类对Rating的影响 3、定价策略 4、因素相关性分析 5、用户评价 6、总结 0、数据准备 (…...

BFS 五香豆腐
题目描述 经过谢老师n次的教导,dfc终于觉悟了——过于腐败是不对的。但是dfc自身却无法改变自己,于是他找到了你,请求你的帮助。 dfc的内心可以看成是5*5个分区组成,每个分区都可以决定的的去向,0表示继续爱好腐败&…...

opencv实战项目 手势识别-手势控制键盘
手势识别是一种人机交互技术,通过识别人的手势动作,从而实现对计算机、智能手机、智能电视等设备的操作和控制。 1. opencv实现手部追踪(定位手部关键点) 2.opencv实战项目 实现手势跟踪并返回位置信息(封装调用&am…...

1.作用域
1.1局部作用域 局部作用域分为函数作用域和块作用域。 1.函数作用域: 在函数内部声明的变量只能在函数内部被访问,外部无法直接访问。 总结: (1)函数内部声明的变量,在函数外部无法被访问 (2)函数的参数也是函数内部的局部变量 (3)不同函数…...

黑马B站八股文学习笔记
视频地址:https://www.yuque.com/linxun-bpyj0/linxun/vy91es9lyg7kbfnr 大纲 基础篇 基础篇要点:算法、数据结构、基础设计模式 1. 二分查找 要求 能够用自己语言描述二分查找算法能够手写二分查找代码能够解答一些变化后的考法 算法描述 前提&a…...

前端常用的上传下载文件的几种方式,直接上传、下载文件,读取.xlsx文件数据,导出.xlsx数据
一、通过调用接口下载文件 const onExport async () > {try {let res await axios.request({method: POST,url: 请求地址,responseType: blob,params: { data: null },headers: { Authorization: Bearer UserModule.token },//看看请求是否需要token});let reader new…...
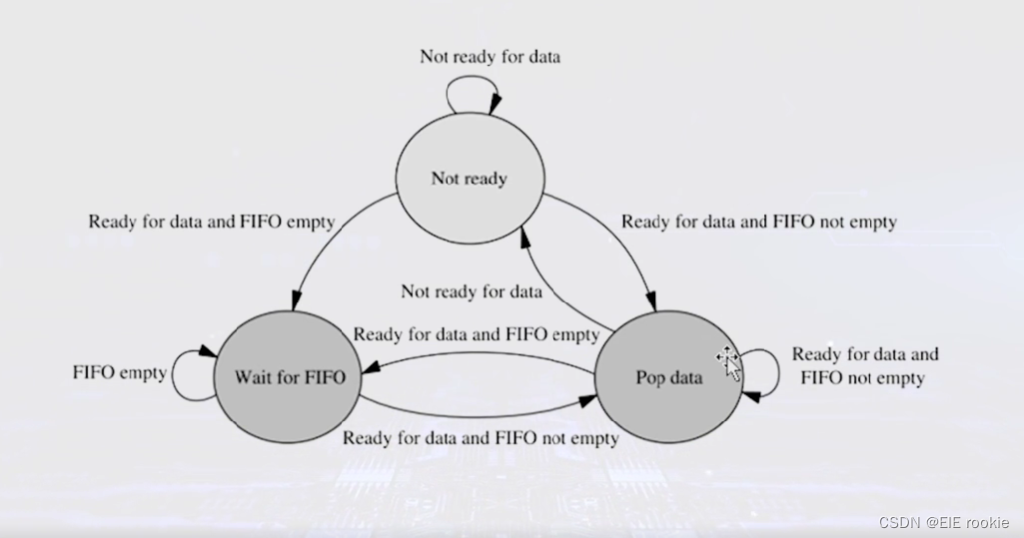
FPGA应用学习笔记--时钟域的控制 亚稳态的解决
时钟域就是同一个时钟的区域,体现在laways语句边缘触发语句中,设计规模增大就会导致时钟不同步,有时差,就要设计多时钟域。 会经过与门的延时产生的新时钟域,这种其实不推荐使用,但在ascl里面很常见 在处理…...
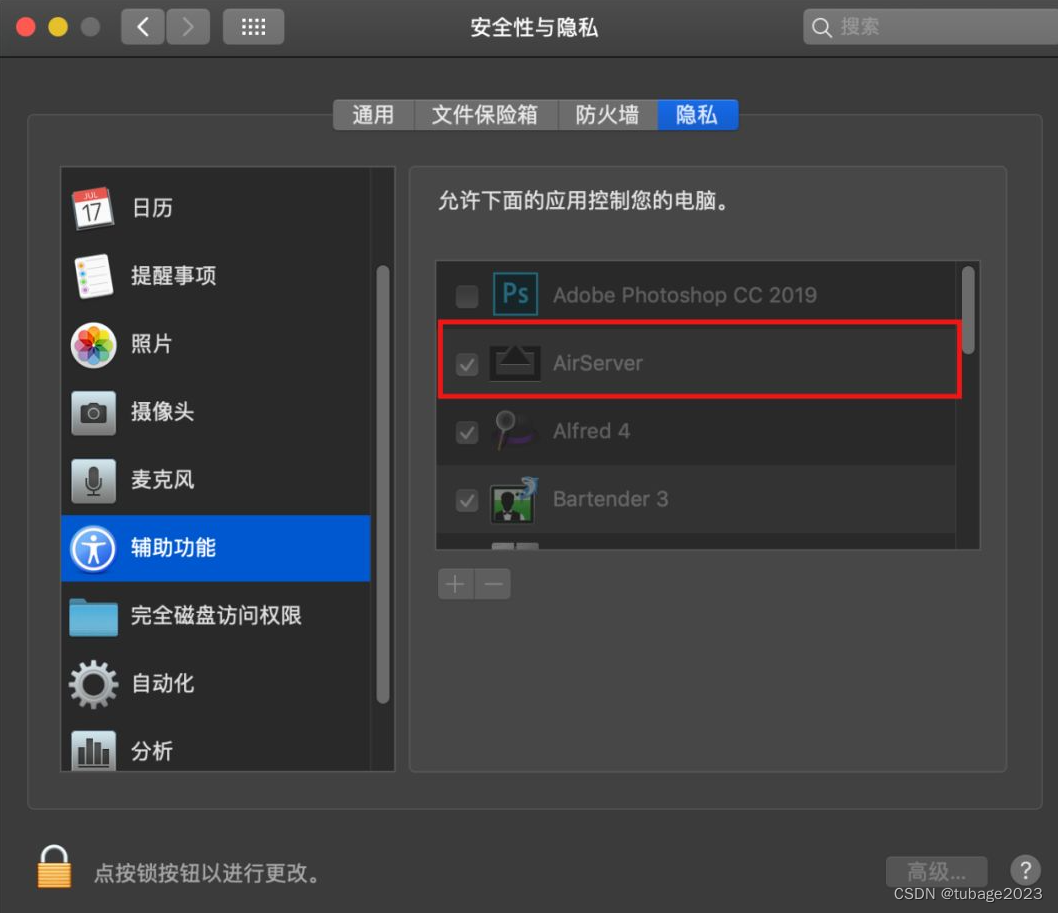
AirServer是什么软件,手机屏幕投屏电脑神器
什么是 AirServer? AirServer 是适用于 Mac 和 PC 的先进的屏幕镜像接收器。 它允许您接收 AirPlay 和 Google Cast 流,类似于 Apple TV 或 Chromecast 设备。AirServer 可以将一个简单的大屏幕或投影仪变成一个通用的屏幕镜像接收器 ,是一款…...

如何使用 AT+WEBSERVER 指令实现自定义的 Webserver html 网页配网
开启 AT 固件中的 Webserver 指令和 FS 指令支持 乐鑫官网发布的默认通用 AT 固件不支持 webserver 配网功能, 需要用户自己搭建 esp-at 环境,并在 sdkconfig 中开启 webserver AT 指令 和 FS 指令的支持, 如下图所示: 测试 AT 固…...
期权定价模型系列【4】—期权组合的Delta-Gamma-Vega中性
期权组合的Delta-Gamma-Vega中性 期权组合构建时往往会进行delta中性对冲,在进行中性对冲后,期权组合的delta敞口为0,此时期权组合仍然存在gamma与vega敞口。因此研究期权组合的delta-gamma-vega敞口中性是有必要的。 本文旨在对delta-gamma-…...

k8sday02
第四章 实战入门 本章节将介绍如何在kubernetes集群中部署一个nginx服务,并且能够对其进行访问。 Namespace Namespace是kubernetes系统中的一种非常重要资源,它的主要作用是用来实现多套环境的资源隔离或者多租户的资源隔离。 默认情况下&…...
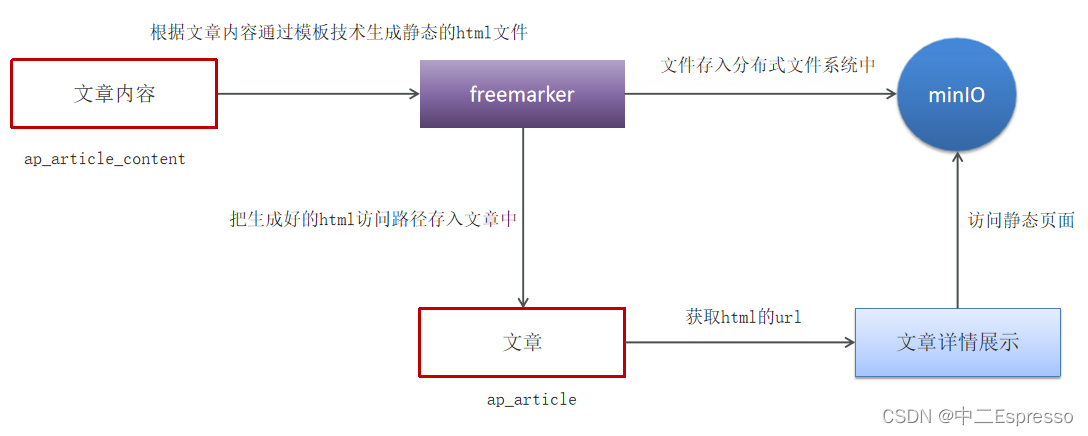
黑马头条项目学习--Day2: app端文章查看,静态化freemarker,分布式文件系统minIO
app端文章 Day02: app端文章查看,静态化freemarker,分布式文件系统minIOa. app端文章列表查询1) 需求分析2) 实现思路 b. app端文章详细1) 需求分析2) Freemarker概述a) 基础语法种类b) 集合指令(List和Map)c) if指令d) 运算符e) 空值处理f) …...
特语云用Linux和MCSM面板搭建 我的世界基岩版插件服 教程
Linux系统 用MCSM和DockerWine 搭建 我的世界 LiteLoaderBDS 服务器 Minecraft Bedrock Edition 也就是我的世界基岩版,这是 Minecraft 的另一个版本。Minecraft 基岩版可以运行在 Win10、Android、iOS、XBox、switch。基岩版不能使用 Java 版的服务器,…...

2023.8
编译 make install 去掉 folly armv8-acrc arrow NEON 相关链接 https://blog.csdn.net/u011889952/article/details/118762819 这里面的方案二,我之前也是用的这个 https://blog.csdn.net/zzhongcy/article/details/105512565 参考的此博客 火焰图 https://b…...
CSV文件编辑器——Modern CSV for mac
Modern CSV for Mac是一款功能强大、操作简单的CSV文件编辑器,适用于Mac用户快速、高效地处理和管理CSV文件。Modern CSV具有直观的用户界面,可以轻松导入、编辑和导出CSV文件。它支持各种功能,包括排序、过滤、查找和替换,使您能…...
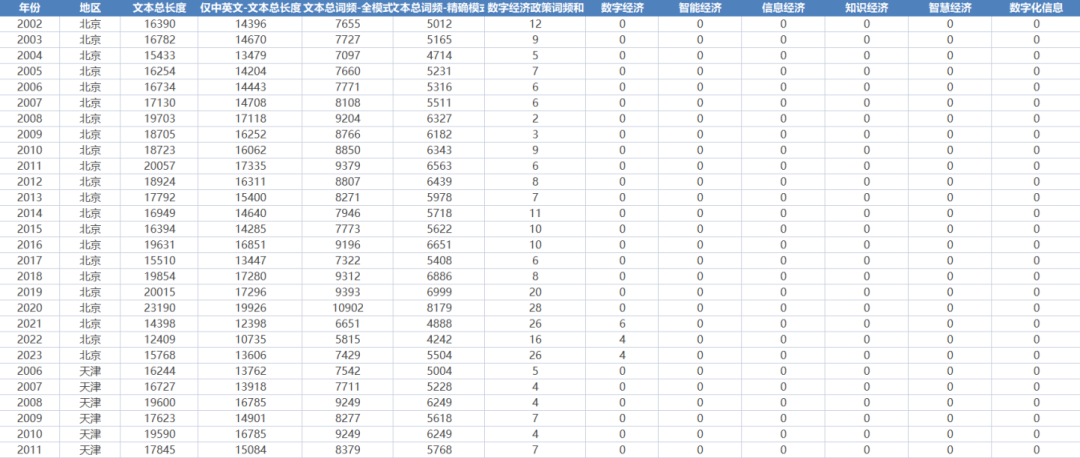
全国各地区数字经济工具变量-文本词频统计(2002-2023年)
数据简介:本数据使用全国各省工作报告,对其中数字经济相关的词汇进行词频统计,从而构建数字经济相关的工具变量。凭借数字经济政策供给与数字经济发展水平的相关系数的显著性作为二者匹配程度的划分依据,一定程度上规避了数字经济…...

MacOS安装RabbitMQ
官网地址: RabbitMQ: easy to use, flexible messaging and streaming — RabbitMQ 一、brew安装 brew update #更新一下homebrew brew install rabbitmq #安装rabbitMQ 安装结果: > Caveats > rabbitmq Management Plugin enabled by defa…...

Zotero-OCR插件高级配置与常见问题深度解析
Zotero-OCR插件高级配置与常见问题深度解析 【免费下载链接】zotero-ocr Zotero Plugin for OCR 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-ocr Zotero-OCR作为文献管理工具Zotero的核心OCR扩展插件,为学术研究者和技术用户提供了将扫描PDF转换为…...
:含12个真实Git Diff对比案例与自动化检测脚本)
智能代码生成可读性优化(工业级SOP手册):含12个真实Git Diff对比案例与自动化检测脚本
第一章:智能代码生成代码可读性优化 2026奇点智能技术大会(https://ml-summit.org) 智能代码生成工具(如Copilot、CodeWhisperer、Tabnine)在提升开发效率的同时,常产出语法正确但语义模糊、命名随意、结构扁平的代码,…...
)
保姆级教程:用OpenCV搞定鱼眼双目相机的标定与测距(附完整C++代码)
鱼眼双目视觉实战:从标定到三维测距的全流程解析 鱼眼镜头因其超广视角特性,在机器人导航、VR全景拍摄等领域应用广泛。但大畸变特性也给双目视觉系统带来额外挑战——传统标定方法直接套用往往导致测距误差剧增。本文将用OpenCV的fisheye模块࿰…...

华硕笔记本终极性能优化指南:GHelper完全配置教程
华硕笔记本终极性能优化指南:GHelper完全配置教程 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, …...

LaserGRBL:从零开始掌握激光雕刻的完整免费指南
LaserGRBL:从零开始掌握激光雕刻的完整免费指南 【免费下载链接】LaserGRBL Laser optimized GUI for GRBL 项目地址: https://gitcode.com/gh_mirrors/la/LaserGRBL 想要将创意变为现实?寻找一款简单易用且功能强大的激光雕刻控制软件࿱…...

别再只盯着50050端口了:Cobalt Strike结合frp的多Listener端口转发与负载均衡配置指南
Cobalt Strike高阶架构:基于frp的多端口转发与流量分发实战 引言:为什么需要突破单端口架构? 在安全测试领域,Cobalt Strike(简称CS)作为成熟的C2框架,其基础设施的健壮性直接影响任务成功率。传…...
:栈区与堆区数组代码演示)
C++零基础到工程实战(4.3.2):栈区与堆区数组代码演示
目录 一、本节学习内容概要 二、前言 三、栈区数组代码演示 3.1 栈区数组定义 3.2 值访问与地址访问 3.3 栈区数组大小计算 3.4 栈区数组必须是编译时常量 四、堆区数组代码演示 4.1 基本定义与访问 4.2 值与地址访问 4.3 手动释放 4.4 堆区数组动态大小示例 4.5 …...

FPGA开发效率翻倍!Quartus II 这几个隐藏设置和窗口管理技巧,你知道吗?
FPGA开发效率翻倍!Quartus II 这几个隐藏设置和窗口管理技巧,你知道吗? 作为一名FPGA开发者,你是否经常在Quartus II中感到效率低下?界面混乱、窗口丢失、重复操作消耗大量时间?今天我要分享的这几个隐藏技…...

智能代码生成覆盖率陷阱全解析,资深SRE亲授覆盖率验证三重校验法与CI/CD嵌入指南
第一章:智能代码生成代码覆盖率分析 2026奇点智能技术大会(https://ml-summit.org) 现代智能代码生成系统(如Copilot、CodeWhisperer、Tabnine)在提升开发效率的同时,其输出代码的可测试性与结构完整性正成为质量保障的关键挑战…...
)
【限时解禁】微软VS Code IntelliCode内核逆向文档(含未公开的Symbol Graph Embedding协议v3.2)
第一章:智能代码生成原理与架构解析 2026奇点智能技术大会(https://ml-summit.org) 智能代码生成并非简单地拼接模板或检索已有片段,而是基于大规模代码语料训练的深度语言模型,对编程意图进行语义建模、上下文感知推理与结构化输出控制的系…...