黑马B站八股文学习笔记
视频地址:https://www.yuque.com/linxun-bpyj0/linxun/vy91es9lyg7kbfnr
大纲

基础篇
基础篇要点:算法、数据结构、基础设计模式
1. 二分查找
要求
- 能够用自己语言描述二分查找算法
- 能够手写二分查找代码
- 能够解答一些变化后的考法
算法描述
- 前提:有已排序数组 A(假设已经做好)
- 定义左边界 L、右边界 R,确定搜索范围,循环执行二分查找(3、4两步)
- 获取中间索引 M = Floor((L+R) /2)
- 中间索引的值 A[M] 与待搜索的值 T 进行比较
① A[M] == T 表示找到,返回中间索引
② A[M] > T,中间值右侧的其它元素都大于 T,无需比较,中间索引左边去找,M - 1 设置为右边界,重新查找
③ A[M] < T,中间值左侧的其它元素都小于 T,无需比较,中间索引右边去找, M + 1 设置为左边界,重新查找 - 当 L > R 时,表示没有找到,应结束循环
更形象的描述请参考:binary_search.html
算法实现
public static int binarySearch(int[] a, int t) {int l = 0, r = a.length - 1, m;while (l <= r) {m = (l + r) / 2;if (a[m] == t) {return m;} else if (a[m] > t) {r = m - 1;} else {l = m + 1;}}return -1;
}
测试代码
public static void main(String[] args) {int[] array = {1, 5, 8, 11, 19, 22, 31, 35, 40, 45, 48, 49, 50};int target = 47;int idx = binarySearch(array, target);System.out.println(idx);
}
解决整数溢出问题
当 l 和 r 都较大时,l + r 有可能超过整数范围,造成运算错误,解决方法有两种:
int m = l + (r - l) / 2;
还有一种是:
int m = (l + r) >>> 1;
其它考法
- 有一个有序表为 1,5,8,11,19,22,31,35,40,45,48,49,50 当二分查找值为 48 的结点时,查找成功需要比较的次数
- 使用二分法在序列 1,4,6,7,15,33,39,50,64,78,75,81,89,96 中查找元素 81 时,需要经过( )次比较
- 在拥有128个元素的数组中二分查找一个数,需要比较的次数最多不超过多少次
对于前两个题目,记得一个简要判断口诀:奇数二分取中间,偶数二分取中间靠左。对于后一道题目,需要知道公式:
其中 n 为查找次数,N 为元素个数
2. 冒泡排序
要求
- 能够用自己语言描述冒泡排序算法
- 能够手写冒泡排序代码
- 了解一些冒泡排序的优化手段
算法描述
- 依次比较数组中相邻两个元素大小,若 a[j] > a[j+1],则交换两个元素,两两都比较一遍称为一轮冒泡,结果是让最大的元素排至最后
- 重复以上步骤,直到整个数组有序
更形象的描述请参考:bubble_sort.html
算法实现
public static void bubble(int[] a) {for (int j = 0; j < a.length - 1; j++) {// 一轮冒泡boolean swapped = false; // 是否发生了交换for (int i = 0; i < a.length - 1 - j; i++) {System.out.println("比较次数" + i);if (a[i] > a[i + 1]) {Utils.swap(a, i, i + 1);swapped = true;}}System.out.println("第" + j + "轮冒泡"+ Arrays.toString(a));if (!swapped) {break;}}
}
- 优化点1:每经过一轮冒泡,内层循环就可以减少一次
- 优化点2:如果某一轮冒泡没有发生交换,则表示所有数据有序,可以结束外层循环
进一步优化
public static void bubble_v2(int[] a) {int n = a.length - 1;while (true) {int last = 0; // 表示最后一次交换索引位置for (int i = 0; i < n; i++) {System.out.println("比较次数" + i);if (a[i] > a[i + 1]) {Utils.swap(a, i, i + 1);last = i;}}n = last;System.out.println("第轮冒泡"+ Arrays.toString(a));if (n == 0) {break;}}
}
- 每轮冒泡时,最后一次交换索引可以作为下一轮冒泡的比较次数,如果这个值为零,表示整个数组有序,直接退出外层循环即可
3. 选择排序
要求
- 能够用自己语言描述选择排序算法
- 能够比较选择排序与冒泡排序
- 理解非稳定排序与稳定排序
算法描述
- 将数组分为两个子集,排序的和未排序的,每一轮从未排序的子集中选出最小的元素,放入排序子集
- 重复以上步骤,直到整个数组有序
更形象的描述请参考:selection_sort.html
算法实现
public static void selection(int[] a) {for (int i = 0; i < a.length - 1; i++) {// i 代表每轮选择最小元素要交换到的目标索引int s = i; // 代表最小元素的索引for (int j = s + 1; j < a.length; j++) {if (a[s] > a[j]) { // j 元素比 s 元素还要小, 更新 ss = j;}}if (s != i) {swap(a, s, i);}System.out.println(Arrays.toString(a));}
}
- 优化点:为减少交换次数,每一轮可以先找最小的索引,在每轮最后再交换元素
与冒泡排序比较
- 二者平均时间复杂度都是
- 选择排序一般要快于冒泡,因为其交换次数少
- 但如果集合有序度高,冒泡优于选择
- 冒泡属于稳定排序算法,而选择属于不稳定排序
-
- 稳定排序指,按对象中不同字段进行多次排序,不会打乱同值元素的顺序
- 不稳定排序则反之
稳定排序与不稳定排序
System.out.println("=================不稳定================");
Card[] cards = getStaticCards();
System.out.println(Arrays.toString(cards));
selection(cards, Comparator.comparingInt((Card a) -> a.sharpOrder).reversed());
System.out.println(Arrays.toString(cards));
selection(cards, Comparator.comparingInt((Card a) -> a.numberOrder).reversed());
System.out.println(Arrays.toString(cards));System.out.println("=================稳定=================");
cards = getStaticCards();
System.out.println(Arrays.toString(cards));
bubble(cards, Comparator.comparingInt((Card a) -> a.sharpOrder).reversed());
System.out.println(Arrays.toString(cards));
bubble(cards, Comparator.comparingInt((Card a) -> a.numberOrder).reversed());
System.out.println(Arrays.toString(cards));
都是先按照花色排序(♠♥♣♦),再按照数字排序(AKQJ…)
- 不稳定排序算法按数字排序时,会打乱原本同值的花色顺序
[[♠7], [♠2], [♠4], [♠5], [♥2], [♥5]]
[[♠7], [♠5], [♥5], [♠4], [♥2], [♠2]]
原来 ♠2 在前 ♥2 在后,按数字再排后,他俩的位置变了
- 稳定排序算法按数字排序时,会保留原本同值的花色顺序,如下所示 ♠2 与 ♥2 的相对位置不变
[[♠7], [♠2], [♠4], [♠5], [♥2], [♥5]]
[[♠7], [♠5], [♥5], [♠4], [♠2], [♥2]]
4. 插入排序
要求
- 能够用自己语言描述插入排序算法
- 能够比较插入排序与选择排序
算法描述
- 将数组分为两个区域,排序区域和未排序区域,每一轮从未排序区域中取出第一个元素,插入到排序区域(需保证顺序)
- 重复以上步骤,直到整个数组有序
更形象的描述请参考:insertion_sort.html
算法实现
// 修改了代码与希尔排序一致
public static void insert(int[] a) {// i 代表待插入元素的索引for (int i = 1; i < a.length; i++) {int t = a[i]; // 代表待插入的元素值int j = i;System.out.println(j);while (j >= 1) {if (t < a[j - 1]) { // j-1 是上一个元素索引,如果 > t,后移a[j] = a[j - 1];j--;} else { // 如果 j-1 已经 <= t, 则 j 就是插入位置break;}}a[j] = t;System.out.println(Arrays.toString(a) + " " + j);}
}
与选择排序比较
- 二者平均时间复杂度都是
- 大部分情况下,插入都略优于选择
- 有序集合插入的时间复杂度为
- 插入属于稳定排序算法,而选择属于不稳定排序
提示
插入排序通常被同学们所轻视,其实它的地位非常重要。小数据量排序,都会优先选择插入排序
5. 希尔排序
要求
- 能够用自己语言描述希尔排序算法
算法描述
- 首先选取一个间隙序列,如 (n/2,n/4 … 1),n 为数组长度
- 每一轮将间隙相等的元素视为一组,对组内元素进行插入排序,目的有二
① 少量元素插入排序速度很快
② 让组内值较大的元素更快地移动到后方 - 当间隙逐渐减少,直至为 1 时,即可完成排序
更形象的描述请参考:shell_sort.html
算法实现
private static void shell(int[] a) {int n = a.length;for (int gap = n / 2; gap > 0; gap /= 2) {// i 代表待插入元素的索引for (int i = gap; i < n; i++) {int t = a[i]; // 代表待插入的元素值int j = i;while (j >= gap) {// 每次与上一个间隙为 gap 的元素进行插入排序if (t < a[j - gap]) { // j-gap 是上一个元素索引,如果 > t,后移a[j] = a[j - gap];j -= gap;} else { // 如果 j-1 已经 <= t, 则 j 就是插入位置break;}}a[j] = t;System.out.println(Arrays.toString(a) + " gap:" + gap);}}
}
参考资料
- https://en.wikipedia.org/wiki/Shellsort
6. 快速排序
要求
- 能够用自己语言描述快速排序算法
- 掌握手写单边循环、双边循环代码之一
- 能够说明快排特点
- 了解洛穆托与霍尔两种分区方案的性能比较
算法描述
- 每一轮排序选择一个基准点(pivot)进行分区
-
- 让小于基准点的元素的进入一个分区,大于基准点的元素的进入另一个分区
- 当分区完成时,基准点元素的位置就是其最终位置
- 在子分区内重复以上过程,直至子分区元素个数少于等于 1,这体现的是分而治之的思想 (divide-and-conquer)
- 从以上描述可以看出,一个关键在于分区算法,常见的有洛穆托分区方案、双边循环分区方案、霍尔分区方案
更形象的描述请参考:quick_sort.html
单边循环快排(lomuto 洛穆托分区方案)
- 选择最右元素作为基准点元素
- j 指针负责找到比基准点小的元素,一旦找到则与 i 进行交换
- i 指针维护小于基准点元素的边界,也是每次交换的目标索引
- 最后基准点与 i 交换,i 即为分区位置
public static void quick(int[] a, int l, int h) {if (l >= h) {return;}int p = partition(a, l, h); // p 索引值quick(a, l, p - 1); // 左边分区的范围确定quick(a, p + 1, h); // 左边分区的范围确定
}private static int partition(int[] a, int l, int h) {int pv = a[h]; // 基准点元素int i = l;for (int j = l; j < h; j++) {if (a[j] < pv) {if (i != j) {swap(a, i, j);}i++;}}if (i != h) {swap(a, h, i);}System.out.println(Arrays.toString(a) + " i=" + i);// 返回值代表了基准点元素所在的正确索引,用它确定下一轮分区的边界return i;
}
双边循环快排(不完全等价于 hoare 霍尔分区方案)
- 选择最左元素作为基准点元素
- j 指针负责从右向左找比基准点小的元素,i 指针负责从左向右找比基准点大的元素,一旦找到二者交换,直至 i,j 相交
- 最后基准点与 i(此时 i 与 j 相等)交换,i 即为分区位置
要点
- 基准点在左边,并且要先 j 后 i
- while( i < j && a[j] > pv ) j–
- while ( i < j && a[i] <= pv ) i++
private static void quick(int[] a, int l, int h) {if (l >= h) {return;}int p = partition(a, l, h);quick(a, l, p - 1);quick(a, p + 1, h);
}private static int partition(int[] a, int l, int h) {int pv = a[l];int i = l;int j = h;while (i < j) {// j 从右找小的while (i < j && a[j] > pv) {j--;}// i 从左找大的while (i < j && a[i] <= pv) {i++;}swap(a, i, j);}swap(a, l, j);System.out.println(Arrays.toString(a) + " j=" + j);return j;
}
快排特点
- 平均时间复杂度是
,最坏时间复杂度
- 数据量较大时,优势非常明显
- 属于不稳定排序
洛穆托分区方案 vs 霍尔分区方案
- 霍尔的移动次数平均来讲比洛穆托少3倍
- https://qastack.cn/cs/11458/quicksort-partitioning-hoare-vs-lomuto
补充代码说明
- day01.sort.QuickSort3 演示了空穴法改进的双边快排,比较次数更少
- day01.sort.QuickSortHoare 演示了霍尔分区的实现
- day01.sort.LomutoVsHoare 对四种分区实现的移动次数比较
7. ArrayList
要求
- 掌握 ArrayList 扩容规则
扩容规则
- ArrayList() 会使用长度为零的数组
- ArrayList(int initialCapacity) 会使用指定容量的数组
- public ArrayList(Collection<? extends E> c) 会使用 c 的大小作为数组容量
- add(Object o) 首次扩容为 10,再次扩容为上次容量的 1.5 倍
- addAll(Collection c) 没有元素时,扩容为 Math.max(10, 实际元素个数),有元素时为 Math.max(原容量 1.5 倍, 实际元素个数)
其中第 4 点必须知道,其它几点视个人情况而定
提示
- 测试代码见
day01.list.TestArrayList,这里不再列出 - 要注意的是,示例中用反射方式来更直观地反映 ArrayList 的扩容特征,但从 JDK 9 由于模块化的影响,对反射做了较多限制,需要在运行测试代码时添加 VM 参数
--add-opens java.base/java.util=ALL-UNNAMED方能运行通过,后面的例子都有相同问题
代码说明
- day01.list.TestArrayList#arrayListGrowRule 演示了 add(Object) 方法的扩容规则,输入参数 n 代表打印多少次扩容后的数组长度
8. Iterator
要求
- 掌握什么是 Fail-Fast、什么是 Fail-Safe
Fail-Fast 与 Fail-Safe
- ArrayList 是 fail-fast 的典型代表,遍历的同时不能修改,尽快失败
- CopyOnWriteArrayList 是 fail-safe 的典型代表,遍历的同时可以修改,原理是读写分离
提示
- 测试代码见
day01.list.FailFastVsFailSafe,这里不再列出
9. LinkedList
要求
- 能够说清楚 LinkedList 对比 ArrayList 的区别,并重视纠正部分错误的认知
LinkedList
- 基于双向链表,无需连续内存
- 随机访问慢(要沿着链表遍历)
- 头尾插入删除性能高
- 占用内存多
ArrayList
- 基于数组,需要连续内存
- 随机访问快(指根据下标访问)
- 尾部插入、删除性能可以,其它部分插入、删除都会移动数据,因此性能会低
- 可以利用 cpu 缓存,局部性原理
代码说明
- day01.list.ArrayListVsLinkedList#randomAccess 对比随机访问性能
- day01.list.ArrayListVsLinkedList#addMiddle 对比向中间插入性能
- day01.list.ArrayListVsLinkedList#addFirst 对比头部插入性能
- day01.list.ArrayListVsLinkedList#addLast 对比尾部插入性能
- day01.list.ArrayListVsLinkedList#linkedListSize 打印一个 LinkedList 占用内存
- day01.list.ArrayListVsLinkedList#arrayListSize 打印一个 ArrayList 占用内存
10. HashMap
要求
- 掌握 HashMap 的基本数据结构
- 掌握树化
- 理解索引计算方法、二次 hash 的意义、容量对索引计算的影响
- 掌握 put 流程、扩容、扩容因子
- 理解并发使用 HashMap 可能导致的问题
- 理解 key 的设计
1)基本数据结构
- 1.7 数组 + 链表
- 1.8 数组 + (链表 | 红黑树)
更形象的演示,见资料中的 hash-demo.jar,运行需要 jdk14 以上环境,进入 jar 包目录,执行下面命令
java -jar --add-exports java.base/jdk.internal.misc=ALL-UNNAMED hash-demo.jar
2)树化与退化
树化意义
- 红黑树用来避免 DoS 攻击,防止链表超长时性能下降,树化应当是偶然情况,是保底策略
- hash 表的查找,更新的时间复杂度是
,而红黑树的查找,更新的时间复杂度是
,TreeNode 占用空间也比普通 Node 的大,如非必要,尽量还是使用链表
- hash 值如果足够随机,则在 hash 表内按泊松分布,在负载因子 0.75 的情况下,长度超过 8 的链表出现概率是 0.00000006,树化阈值选择 8 就是为了让树化几率足够小
树化规则
- 当链表长度超过树化阈值 8 时,先尝试扩容来减少链表长度,如果数组容量已经 >=64,才会进行树化
退化规则
- 情况1:在扩容时如果拆分树时,树元素个数 <= 6 则会退化链表
- 情况2:remove 树节点时,若 root、root.left、root.right、root.left.left 有一个为 null ,也会退化为链表
3)索引计算
索引计算方法
- 首先,计算对象的 hashCode()
- 再进行调用 HashMap 的 hash() 方法进行二次哈希
-
- 二次 hash() 是为了综合高位数据,让哈希分布更为均匀
- 最后 & (capacity – 1) 得到索引
数组容量为何是 2 的 n 次幂
- 计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
- 扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
注意
- 二次 hash 是为了配合 容量是 2 的 n 次幂 这一设计前提,如果 hash 表的容量不是 2 的 n 次幂,则不必二次 hash
- 容量是 2 的 n 次幂 这一设计计算索引效率更好,但 hash 的分散性就不好,需要二次 hash 来作为补偿,没有采用这一设计的典型例子是 Hashtable
4)put 与扩容
put 流程
- HashMap 是懒惰创建数组的,首次使用才创建数组
- 计算索引(桶下标)
- 如果桶下标还没人占用,创建 Node 占位返回
- 如果桶下标已经有人占用
-
- 已经是 TreeNode 走红黑树的添加或更新逻辑
- 是普通 Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑
- 返回前检查容量是否超过阈值,一旦超过进行扩容
1.7 与 1.8 的区别
- 链表插入节点时,1.7 是头插法,1.8 是尾插法
- 1.7 是大于等于阈值且没有空位时才扩容,而 1.8 是大于阈值就扩容
- 1.8 在扩容计算 Node 索引时,会优化
扩容(加载)因子为何默认是 0.75f
- 在空间占用与查询时间之间取得较好的权衡
- 大于这个值,空间节省了,但链表就会比较长影响性能
- 小于这个值,冲突减少了,但扩容就会更频繁,空间占用也更多
5)并发问题
扩容死链(1.7 会存在)
1.7 源码如下:
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}
}
- e 和 next 都是局部变量,用来指向当前节点和下一个节点
- 线程1(绿色)的临时变量 e 和 next 刚引用了这俩节点,还未来得及移动节点,发生了线程切换,由线程2(蓝色)完成扩容和迁移

- 线程2 扩容完成,由于头插法,链表顺序颠倒。但线程1 的临时变量 e 和 next 还引用了这俩节点,还要再来一遍迁移
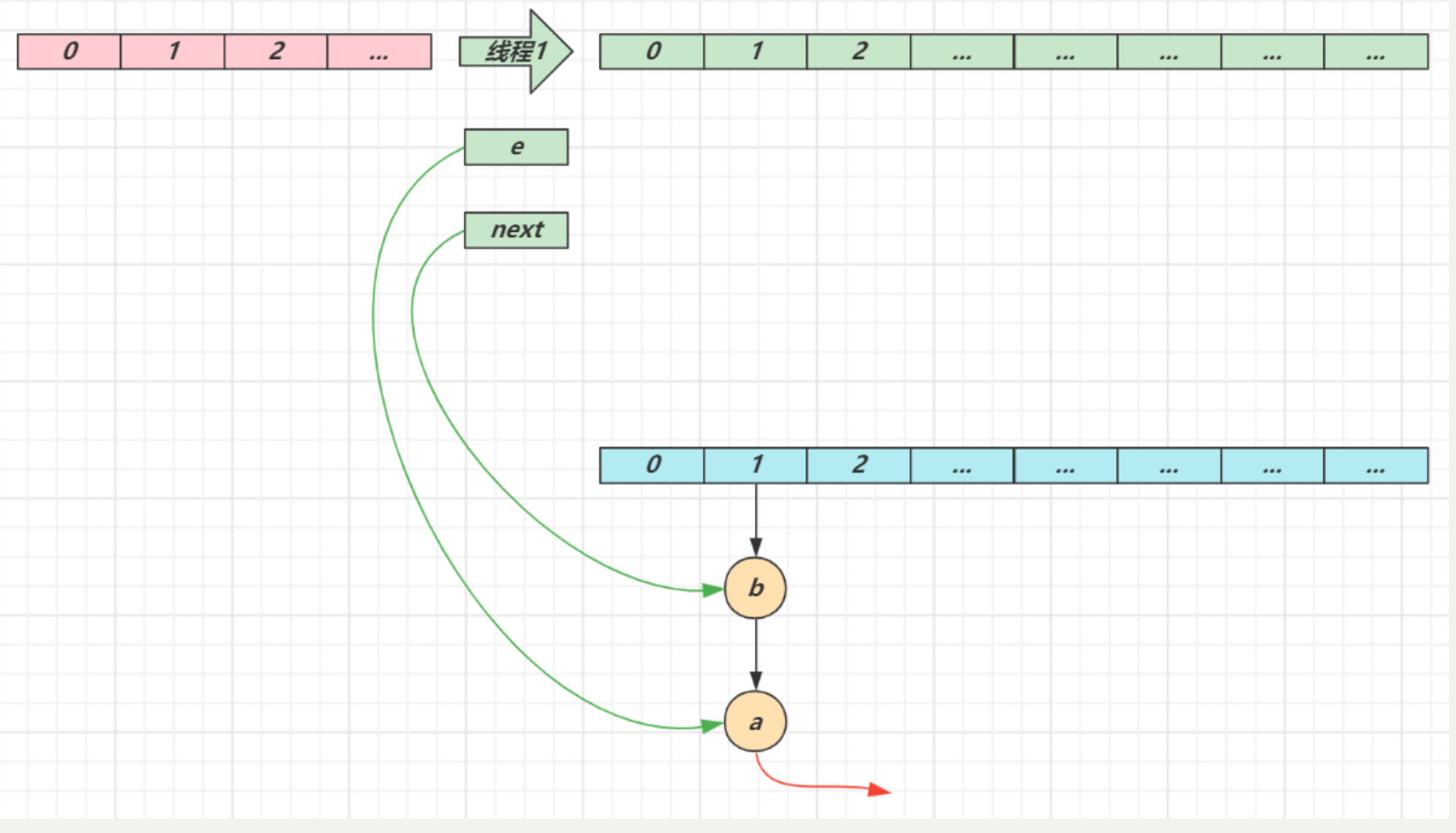
- 第一次循环
-
- 循环接着线程切换前运行,注意此时 e 指向的是节点 a,next 指向的是节点 b
- e 头插 a 节点,注意图中画了两份 a 节点,但事实上只有一个(为了不让箭头特别乱画了两份)
- 当循环结束是 e 会指向 next 也就是 b 节点

- 第二次循环
-
- next 指向了节点 a
- e 头插节点 b
- 当循环结束时,e 指向 next 也就是节点 a
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A3enIgab-1691920287269)()]
- 第三次循环
-
- next 指向了 null
- e 头插节点 a,a 的 next 指向了 b(之前 a.next 一直是 null),b 的 next 指向 a,死链已成
- 当循环结束时,e 指向 next 也就是 null,因此第四次循环时会正常退出

数据错乱(1.7,1.8 都会存在)
- 代码参考
day01.map.HashMapMissData,具体调试步骤参考视频
补充代码说明
- day01.map.HashMapDistribution 演示 map 中链表长度符合泊松分布
- day01.map.DistributionAffectedByCapacity 演示容量及 hashCode 取值对分布的影响
-
- day01.map.DistributionAffectedByCapacity#hashtableGrowRule 演示了 Hashtable 的扩容规律
- day01.sort.Utils#randomArray 如果 hashCode 足够随机,容量是否是 2 的 n 次幂影响不大
- day01.sort.Utils#lowSameArray 如果 hashCode 低位一样的多,容量是 2 的 n 次幂会导致分布不均匀
- day01.sort.Utils#evenArray 如果 hashCode 偶数的多,容量是 2 的 n 次幂会导致分布不均匀
- 由此得出对于容量是 2 的 n 次幂的设计来讲,二次 hash 非常重要
- day01.map.HashMapVsHashtable 演示了对于同样数量的单词字符串放入 HashMap 和 Hashtable 分布上的区别
6)key 的设计
key 的设计要求
- HashMap 的 key 可以为 null,但 Map 的其他实现则不然
- 作为 key 的对象,必须实现 hashCode 和 equals,并且 key 的内容不能修改(不可变)
- key 的 hashCode 应该有良好的散列性
如果 key 可变,例如修改了 age 会导致再次查询时查询不到
public class HashMapMutableKey {public static void main(String[] args) {HashMap<Student, Object> map = new HashMap<>();Student stu = new Student("张三", 18);map.put(stu, new Object());System.out.println(map.get(stu));stu.age = 19;System.out.println(map.get(stu));}static class Student {String name;int age;public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}}
}
String 对象的 hashCode() 设计
- 目标是达到较为均匀的散列效果,每个字符串的 hashCode 足够独特
- 字符串中的每个字符都可以表现为一个数字,称为
,其中 i 的范围是 0 ~ n - 1
- 散列公式为:
- 31 代入公式有较好的散列特性,并且 31 * h 可以被优化为
-
- 即 $32 ∗h -h $
- 即
- 即
11. 单例模式
要求
- 掌握五种单例模式的实现方式
- 理解为何 DCL 实现时要使用 volatile 修饰静态变量
- 了解 jdk 中用到单例的场景
饿汉式
public class Singleton1 implements Serializable {private Singleton1() {if (INSTANCE != null) {throw new RuntimeException("单例对象不能重复创建");}System.out.println("private Singleton1()");}private static final Singleton1 INSTANCE = new Singleton1();public static Singleton1 getInstance() {return INSTANCE;}public static void otherMethod() {System.out.println("otherMethod()");}public Object readResolve() {return INSTANCE;}
}
- 构造方法抛出异常是防止反射破坏单例
readResolve()是防止反序列化破坏单例
枚举饿汉式
public enum Singleton2 {INSTANCE;private Singleton2() {System.out.println("private Singleton2()");}@Overridepublic String toString() {return getClass().getName() + "@" + Integer.toHexString(hashCode());}public static Singleton2 getInstance() {return INSTANCE;}public static void otherMethod() {System.out.println("otherMethod()");}
}
- 枚举饿汉式能天然防止反射、反序列化破坏单例
懒汉式
public class Singleton3 implements Serializable {private Singleton3() {System.out.println("private Singleton3()");}private static Singleton3 INSTANCE = null;// Singleton3.classpublic static synchronized Singleton3 getInstance() {if (INSTANCE == null) {INSTANCE = new Singleton3();}return INSTANCE;}public static void otherMethod() {System.out.println("otherMethod()");}}
- 其实只有首次创建单例对象时才需要同步,但该代码实际上每次调用都会同步
- 因此有了下面的双检锁改进
双检锁懒汉式
public class Singleton4 implements Serializable {private Singleton4() {System.out.println("private Singleton4()");}private static volatile Singleton4 INSTANCE = null; // 可见性,有序性public static Singleton4 getInstance() {if (INSTANCE == null) {synchronized (Singleton4.class) {if (INSTANCE == null) {INSTANCE = new Singleton4();}}}return INSTANCE;}public static void otherMethod() {System.out.println("otherMethod()");}
}
为何必须加 volatile:
INSTANCE = new Singleton4()不是原子的,分成 3 步:创建对象、调用构造、给静态变量赋值,其中后两步可能被指令重排序优化,变成先赋值、再调用构造- 如果线程1 先执行了赋值,线程2 执行到第一个
INSTANCE == null时发现 INSTANCE 已经不为 null,此时就会返回一个未完全构造的对象
内部类懒汉式
public class Singleton5 implements Serializable {private Singleton5() {System.out.println("private Singleton5()");}private static class Holder {static Singleton5 INSTANCE = new Singleton5();}public static Singleton5 getInstance() {return Holder.INSTANCE;}public static void otherMethod() {System.out.println("otherMethod()");}
}
- 避免了双检锁的缺点
JDK 中单例的体现
- Runtime 体现了饿汉式单例
- Console 体现了双检锁懒汉式单例
- Collections 中的 EmptyNavigableSet 内部类懒汉式单例
- ReverseComparator.REVERSE_ORDER 内部类懒汉式单例
- Comparators.NaturalOrderComparator.INSTANCE 枚举饿汉式单例
并发篇
1. 线程状态
要求
- 掌握 Java 线程六种状态
- 掌握 Java 线程状态转换
- 能理解五种状态与六种状态两种说法的区别
六种状态及转换
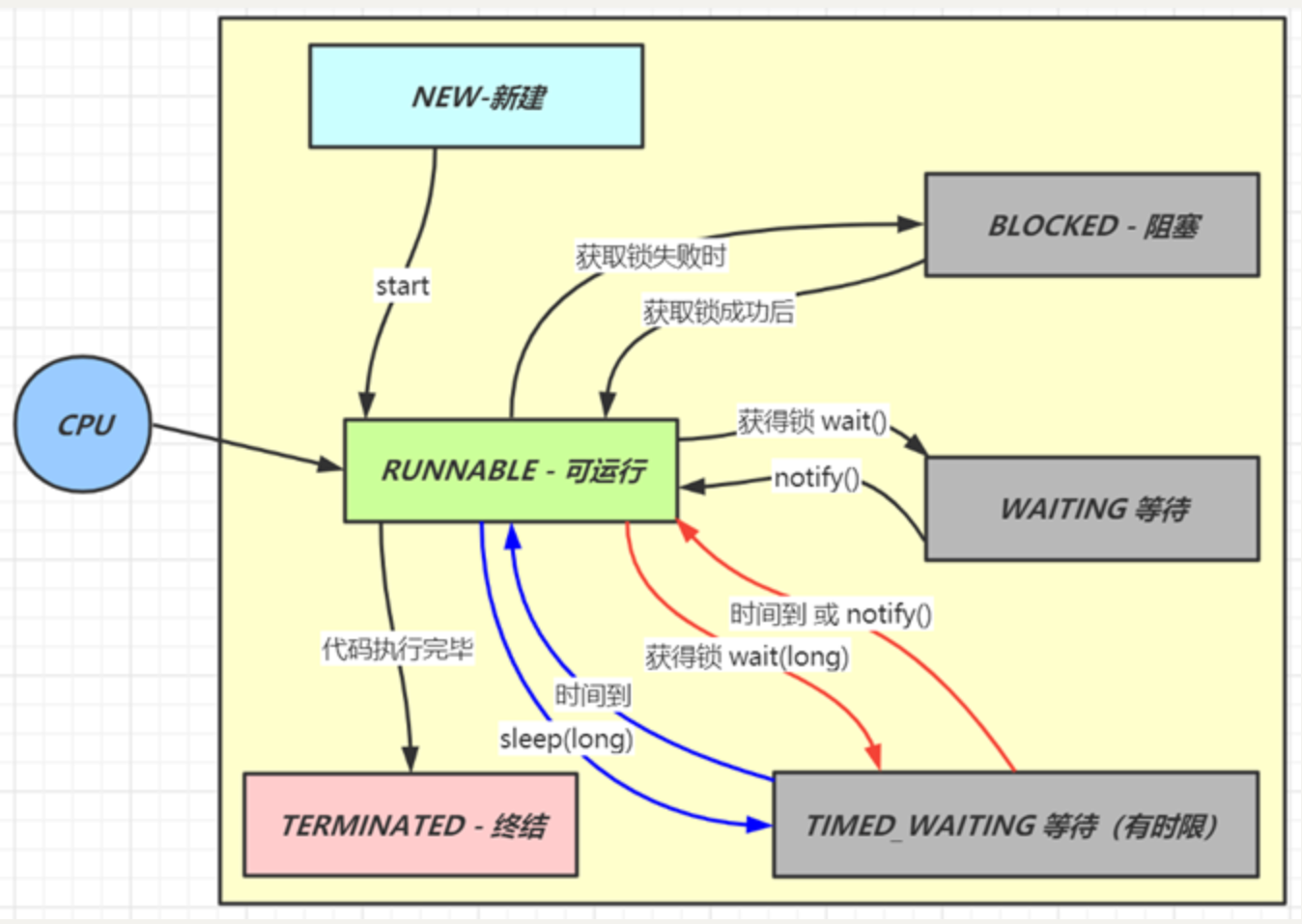
分别是
- 新建
-
- 当一个线程对象被创建,但还未调用 start 方法时处于新建状态
- 此时未与操作系统底层线程关联
- 可运行
-
- 调用了 start 方法,就会由新建进入可运行
- 此时与底层线程关联,由操作系统调度执行
- 终结
-
- 线程内代码已经执行完毕,由可运行进入终结
- 此时会取消与底层线程关联
- 阻塞
-
- 当获取锁失败后,由可运行进入 Monitor 的阻塞队列阻塞,此时不占用 cpu 时间
- 当持锁线程释放锁时,会按照一定规则唤醒阻塞队列中的阻塞线程,唤醒后的线程进入可运行状态
- 等待
-
- 当获取锁成功后,但由于条件不满足,调用了 wait() 方法,此时从可运行状态释放锁进入 Monitor 等待集合等待,同样不占用 cpu 时间
- 当其它持锁线程调用 notify() 或 notifyAll() 方法,会按照一定规则唤醒等待集合中的等待线程,恢复为可运行状态
- 有时限等待
-
- 当获取锁成功后,但由于条件不满足,调用了 wait(long) 方法,此时从可运行状态释放锁进入 Monitor 等待集合进行有时限等待,同样不占用 cpu 时间
- 当其它持锁线程调用 notify() 或 notifyAll() 方法,会按照一定规则唤醒等待集合中的有时限等待线程,恢复为可运行状态,并重新去竞争锁
- 如果等待超时,也会从有时限等待状态恢复为可运行状态,并重新去竞争锁
- 还有一种情况是调用 sleep(long) 方法也会从可运行状态进入有时限等待状态,但与 Monitor 无关,不需要主动唤醒,超时时间到自然恢复为可运行状态
其它情况(只需了解)
- 可以用 interrupt() 方法打断等待、有时限等待的线程,让它们恢复为可运行状态
- park,unpark 等方法也可以让线程等待和唤醒
五种状态
五种状态的说法来自于操作系统层面的划分
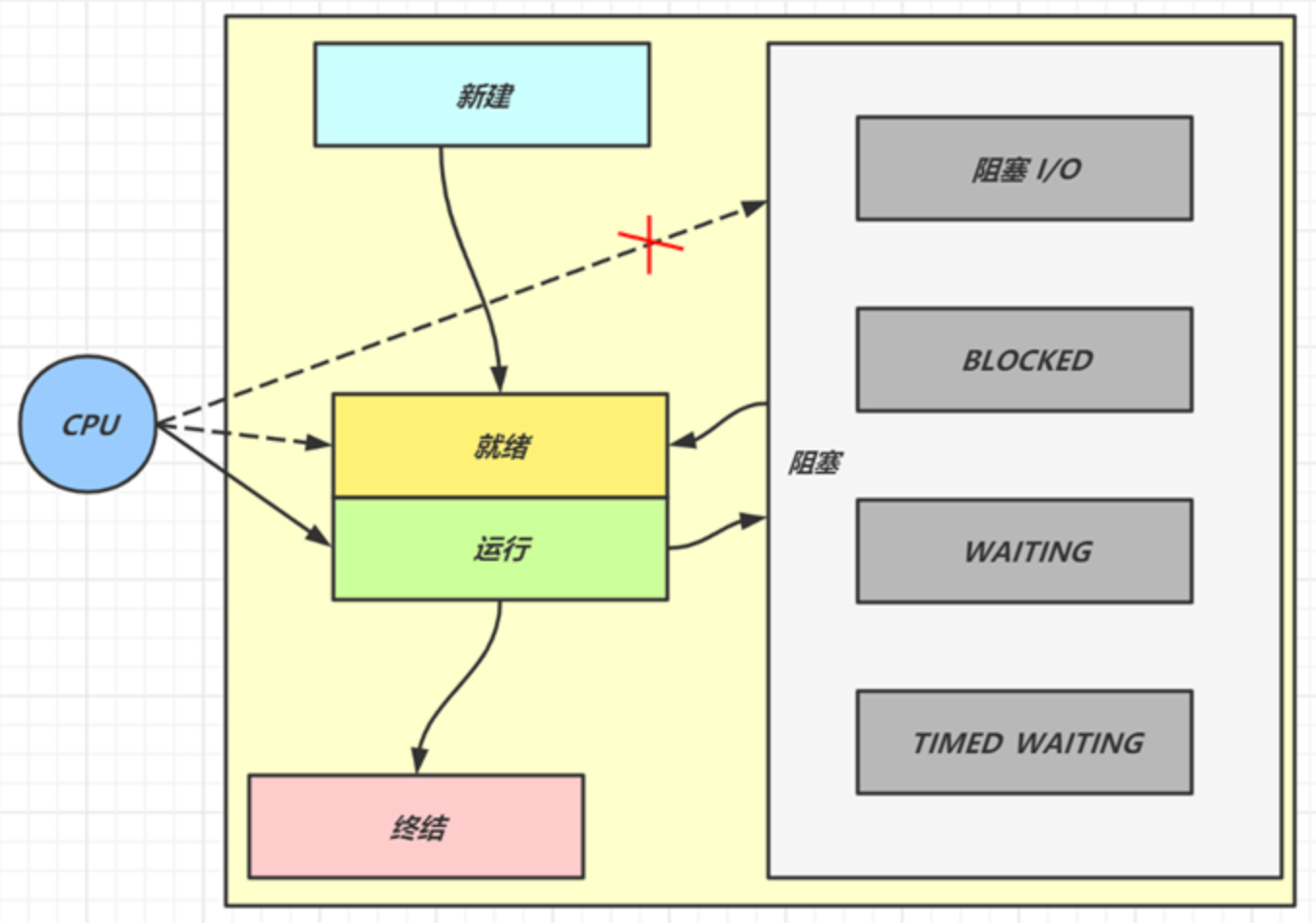
- 运行态:分到 cpu 时间,能真正执行线程内代码的
- 就绪态:有资格分到 cpu 时间,但还未轮到它的
- 阻塞态:没资格分到 cpu 时间的
-
- 涵盖了 java 状态中提到的阻塞、等待、有时限等待
- 多出了阻塞 I/O,指线程在调用阻塞 I/O 时,实际活由 I/O 设备完成,此时线程无事可做,只能干等
- 新建与终结态:与 java 中同名状态类似,不再啰嗦
2. 线程池
要求
- 掌握线程池的 7 大核心参数
七大参数
- corePoolSize 核心线程数目 - 池中会保留的最多线程数
- maximumPoolSize 最大线程数目 - 核心线程+救急线程的最大数目
- keepAliveTime 生存时间 - 救急线程的生存时间,生存时间内没有新任务,此线程资源会释放
- unit 时间单位 - 救急线程的生存时间单位,如秒、毫秒等
- workQueue - 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
- threadFactory 线程工厂 - 可以定制线程对象的创建,例如设置线程名字、是否是守护线程等
- handler 拒绝策略 - 当所有线程都在繁忙,workQueue 也放满时,会触发拒绝策略
-
- 抛异常 java.util.concurrent.ThreadPoolExecutor.AbortPolicy
- 由调用者执行任务 java.util.concurrent.ThreadPoolExecutor.CallerRunsPolicy
- 丢弃任务 java.util.concurrent.ThreadPoolExecutor.DiscardPolicy
- 丢弃最早排队任务 java.util.concurrent.ThreadPoolExecutor.DiscardOldestPolicy
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U9e6Mevj-1691920287271)()]
代码说明
day02.TestThreadPoolExecutor 以较为形象的方式演示了线程池的核心组成
3. wait vs sleep
要求
- 能够说出二者区别
一个共同点,三个不同点
共同点
- wait() ,wait(long) 和 sleep(long) 的效果都是让当前线程暂时放弃 CPU 的使用权,进入阻塞状态
不同点
- 方法归属不同
-
- sleep(long) 是 Thread 的静态方法
- 而 wait(),wait(long) 都是 Object 的成员方法,每个对象都有
- 醒来时机不同
-
- 执行 sleep(long) 和 wait(long) 的线程都会在等待相应毫秒后醒来
- wait(long) 和 wait() 还可以被 notify 唤醒,wait() 如果不唤醒就一直等下去
- 它们都可以被打断唤醒
- 锁特性不同(重点)
-
- wait 方法的调用必须先获取 wait 对象的锁,而 sleep 则无此限制
- wait 方法执行后会释放对象锁,允许其它线程获得该对象锁(我放弃 cpu,但你们还可以用)
- 而 sleep 如果在 synchronized 代码块中执行,并不会释放对象锁(我放弃 cpu,你们也用不了)
4. lock vs synchronized
要求
- 掌握 lock 与 synchronized 的区别
- 理解 ReentrantLock 的公平、非公平锁
- 理解 ReentrantLock 中的条件变量
三个层面
不同点
- 语法层面
-
- synchronized 是关键字,源码在 jvm 中,用 c++ 语言实现
- Lock 是接口,源码由 jdk 提供,用 java 语言实现
- 使用 synchronized 时,退出同步代码块锁会自动释放,而使用 Lock 时,需要手动调用 unlock 方法释放锁
- 功能层面
-
- 二者均属于悲观锁、都具备基本的互斥、同步、锁重入功能
- Lock 提供了许多 synchronized 不具备的功能,例如获取等待状态、公平锁、可打断、可超时、多条件变量
- Lock 有适合不同场景的实现,如 ReentrantLock, ReentrantReadWriteLock
- 性能层面
-
- 在没有竞争时,synchronized 做了很多优化,如偏向锁、轻量级锁,性能不赖
- 在竞争激烈时,Lock 的实现通常会提供更好的性能
公平锁
- 公平锁的公平体现
-
- 已经处在阻塞队列中的线程(不考虑超时)始终都是公平的,先进先出
- 公平锁是指未处于阻塞队列中的线程来争抢锁,如果队列不为空,则老实到队尾等待
- 非公平锁是指未处于阻塞队列中的线程来争抢锁,与队列头唤醒的线程去竞争,谁抢到算谁的
- 公平锁会降低吞吐量,一般不用
条件变量
- ReentrantLock 中的条件变量功能类似于普通 synchronized 的 wait,notify,用在当线程获得锁后,发现条件不满足时,临时等待的链表结构
- 与 synchronized 的等待集合不同之处在于,ReentrantLock 中的条件变量可以有多个,可以实现更精细的等待、唤醒控制
代码说明
- day02.TestReentrantLock 用较为形象的方式演示 ReentrantLock 的内部结构
5. volatile
要求
- 掌握线程安全要考虑的三个问题
- 掌握 volatile 能解决哪些问题
原子性
- 起因:多线程下,不同线程的指令发生了交错导致的共享变量的读写混乱
- 解决:用悲观锁或乐观锁解决,volatile 并不能解决原子性
可见性
- 起因:由于编译器优化、或缓存优化、或 CPU 指令重排序优化导致的对共享变量所做的修改另外的线程看不到
- 解决:用 volatile 修饰共享变量,能够防止编译器等优化发生,让一个线程对共享变量的修改对另一个线程可见
有序性
- 起因:由于编译器优化、或缓存优化、或 CPU 指令重排序优化导致指令的实际执行顺序与编写顺序不一致
- 解决:用 volatile 修饰共享变量会在读、写共享变量时加入不同的屏障,阻止其他读写操作越过屏障,从而达到阻止重排序的效果
- 注意:
-
- volatile 变量写加的屏障是阻止上方其它写操作越过屏障排到 volatile 变量写之下
- volatile 变量读加的屏障是阻止下方其它读操作越过屏障排到 volatile 变量读之上
- volatile 读写加入的屏障只能防止同一线程内的指令重排
代码说明
- day02.threadsafe.AddAndSubtract 演示原子性
- day02.threadsafe.ForeverLoop 演示可见性
-
- 注意:本例经实践检验是编译器优化导致的可见性问题
- day02.threadsafe.Reordering 演示有序性
-
- 需要打成 jar 包后测试
- 请同时参考视频讲解
6. 悲观锁 vs 乐观锁
要求
- 掌握悲观锁和乐观锁的区别
对比悲观锁与乐观锁
- 悲观锁的代表是 synchronized 和 Lock 锁
-
- 其核心思想是【线程只有占有了锁,才能去操作共享变量,每次只有一个线程占锁成功,获取锁失败的线程,都得停下来等待】
- 线程从运行到阻塞、再从阻塞到唤醒,涉及线程上下文切换,如果频繁发生,影响性能
- 实际上,线程在获取 synchronized 和 Lock 锁时,如果锁已被占用,都会做几次重试操作,减少阻塞的机会
- 乐观锁的代表是 AtomicInteger,使用 cas 来保证原子性
-
- 其核心思想是【无需加锁,每次只有一个线程能成功修改共享变量,其它失败的线程不需要停止,不断重试直至成功】
- 由于线程一直运行,不需要阻塞,因此不涉及线程上下文切换
- 它需要多核 cpu 支持,且线程数不应超过 cpu 核数
代码说明
- day02.SyncVsCas 演示了分别使用乐观锁和悲观锁解决原子赋值
- 请同时参考视频讲解
7. Hashtable vs ConcurrentHashMap
要求
- 掌握 Hashtable 与 ConcurrentHashMap 的区别
- 掌握 ConcurrentHashMap 在不同版本的实现区别
更形象的演示,见资料中的 hash-demo.jar,运行需要 jdk14 以上环境,进入 jar 包目录,执行下面命令
java -jar --add-exports java.base/jdk.internal.misc=ALL-UNNAMED hash-demo.jar
Hashtable 对比 ConcurrentHashMap
- Hashtable 与 ConcurrentHashMap 都是线程安全的 Map 集合
- Hashtable 并发度低,整个 Hashtable 对应一把锁,同一时刻,只能有一个线程操作它
- ConcurrentHashMap 并发度高,整个 ConcurrentHashMap 对应多把锁,只要线程访问的是不同锁,那么不会冲突
ConcurrentHashMap 1.7
- 数据结构:
Segment(大数组) + HashEntry(小数组) + 链表,每个 Segment 对应一把锁,如果多个线程访问不同的 Segment,则不会冲突 - 并发度:Segment 数组大小即并发度,决定了同一时刻最多能有多少个线程并发访问。Segment 数组不能扩容,意味着并发度在 ConcurrentHashMap 创建时就固定了
- 索引计算
-
- 假设大数组长度是
,key 在大数组内的索引是 key 的二次 hash 值的高 m 位
- 假设小数组长度是
,key 在小数组内的索引是 key 的二次 hash 值的低 n 位
- 假设大数组长度是
- 扩容:每个小数组的扩容相对独立,小数组在超过扩容因子时会触发扩容,每次扩容翻倍
- Segment[0] 原型:首次创建其它小数组时,会以此原型为依据,数组长度,扩容因子都会以原型为准
ConcurrentHashMap 1.8
- 数据结构:
Node 数组 + 链表或红黑树,数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突。首次生成头节点时如果发生竞争,利用 cas 而非 syncronized,进一步提升性能 - 并发度:Node 数组有多大,并发度就有多大,与 1.7 不同,Node 数组可以扩容
- 扩容条件:Node 数组满 3/4 时就会扩容
- 扩容单位:以链表为单位从后向前迁移链表,迁移完成的将旧数组头节点替换为 ForwardingNode
- 扩容时并发 get
-
- 根据是否为 ForwardingNode 来决定是在新数组查找还是在旧数组查找,不会阻塞
- 如果链表长度超过 1,则需要对节点进行复制(创建新节点),怕的是节点迁移后 next 指针改变
- 如果链表最后几个元素扩容后索引不变,则节点无需复制
- 扩容时并发 put
-
- 如果 put 的线程与扩容线程操作的链表是同一个,put 线程会阻塞
- 如果 put 的线程操作的链表还未迁移完成,即头节点不是 ForwardingNode,则可以并发执行
- 如果 put 的线程操作的链表已经迁移完成,即头结点是 ForwardingNode,则可以协助扩容
- 与 1.7 相比是懒惰初始化
- capacity 代表预估的元素个数,capacity / factory 来计算出初始数组大小,需要贴近
- loadFactor 只在计算初始数组大小时被使用,之后扩容固定为 3/4
- 超过树化阈值时的扩容问题,如果容量已经是 64,直接树化,否则在原来容量基础上做 3 轮扩容
8. ThreadLocal
要求
- 掌握 ThreadLocal 的作用与原理
- 掌握 ThreadLocal 的内存释放时机
作用
- ThreadLocal 可以实现【资源对象】的线程隔离,让每个线程各用各的【资源对象】,避免争用引发的线程安全问题
- ThreadLocal 同时实现了线程内的资源共享
原理
每个线程内有一个 ThreadLocalMap 类型的成员变量,用来存储资源对象
- 调用 set 方法,就是以 ThreadLocal 自己作为 key,资源对象作为 value,放入当前线程的 ThreadLocalMap 集合中
- 调用 get 方法,就是以 ThreadLocal 自己作为 key,到当前线程中查找关联的资源值
- 调用 remove 方法,就是以 ThreadLocal 自己作为 key,移除当前线程关联的资源值
ThreadLocalMap 的一些特点
- key 的 hash 值统一分配
- 初始容量 16,扩容因子 2/3,扩容容量翻倍
- key 索引冲突后用开放寻址法解决冲突
弱引用 key
ThreadLocalMap 中的 key 被设计为弱引用,原因如下
- Thread 可能需要长时间运行(如线程池中的线程),如果 key 不再使用,需要在内存不足(GC)时释放其占用的内存
内存释放时机
- 被动 GC 释放 key
-
- 仅是让 key 的内存释放,关联 value 的内存并不会释放
- 懒惰被动释放 value
-
- get key 时,发现是 null key,则释放其 value 内存
- set key 时,会使用启发式扫描,清除临近的 null key 的 value 内存,启发次数与元素个数,是否发现 null key 有关
- 主动 remove 释放 key,value
-
- 会同时释放 key,value 的内存,也会清除临近的 null key 的 value 内存
- 推荐使用它,因为一般使用 ThreadLocal 时都把它作为静态变量(即强引用),因此无法被动依靠 GC 回收
相关文章:

黑马B站八股文学习笔记
视频地址:https://www.yuque.com/linxun-bpyj0/linxun/vy91es9lyg7kbfnr 大纲 基础篇 基础篇要点:算法、数据结构、基础设计模式 1. 二分查找 要求 能够用自己语言描述二分查找算法能够手写二分查找代码能够解答一些变化后的考法 算法描述 前提&a…...

前端常用的上传下载文件的几种方式,直接上传、下载文件,读取.xlsx文件数据,导出.xlsx数据
一、通过调用接口下载文件 const onExport async () > {try {let res await axios.request({method: POST,url: 请求地址,responseType: blob,params: { data: null },headers: { Authorization: Bearer UserModule.token },//看看请求是否需要token});let reader new…...
FPGA应用学习笔记--时钟域的控制 亚稳态的解决
时钟域就是同一个时钟的区域,体现在laways语句边缘触发语句中,设计规模增大就会导致时钟不同步,有时差,就要设计多时钟域。 会经过与门的延时产生的新时钟域,这种其实不推荐使用,但在ascl里面很常见 在处理…...
AirServer是什么软件,手机屏幕投屏电脑神器
什么是 AirServer? AirServer 是适用于 Mac 和 PC 的先进的屏幕镜像接收器。 它允许您接收 AirPlay 和 Google Cast 流,类似于 Apple TV 或 Chromecast 设备。AirServer 可以将一个简单的大屏幕或投影仪变成一个通用的屏幕镜像接收器 ,是一款…...

如何使用 AT+WEBSERVER 指令实现自定义的 Webserver html 网页配网
开启 AT 固件中的 Webserver 指令和 FS 指令支持 乐鑫官网发布的默认通用 AT 固件不支持 webserver 配网功能, 需要用户自己搭建 esp-at 环境,并在 sdkconfig 中开启 webserver AT 指令 和 FS 指令的支持, 如下图所示: 测试 AT 固…...
期权定价模型系列【4】—期权组合的Delta-Gamma-Vega中性
期权组合的Delta-Gamma-Vega中性 期权组合构建时往往会进行delta中性对冲,在进行中性对冲后,期权组合的delta敞口为0,此时期权组合仍然存在gamma与vega敞口。因此研究期权组合的delta-gamma-vega敞口中性是有必要的。 本文旨在对delta-gamma-…...

k8sday02
第四章 实战入门 本章节将介绍如何在kubernetes集群中部署一个nginx服务,并且能够对其进行访问。 Namespace Namespace是kubernetes系统中的一种非常重要资源,它的主要作用是用来实现多套环境的资源隔离或者多租户的资源隔离。 默认情况下&…...
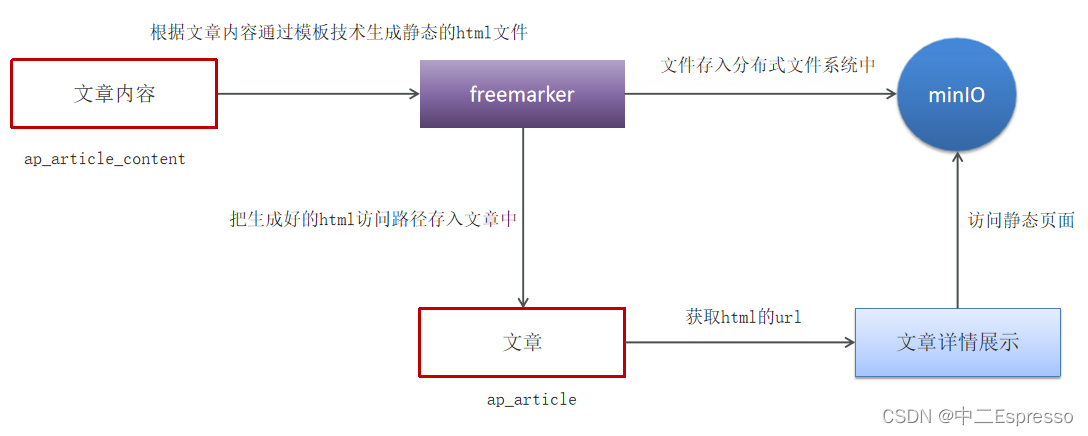
黑马头条项目学习--Day2: app端文章查看,静态化freemarker,分布式文件系统minIO
app端文章 Day02: app端文章查看,静态化freemarker,分布式文件系统minIOa. app端文章列表查询1) 需求分析2) 实现思路 b. app端文章详细1) 需求分析2) Freemarker概述a) 基础语法种类b) 集合指令(List和Map)c) if指令d) 运算符e) 空值处理f) …...
特语云用Linux和MCSM面板搭建 我的世界基岩版插件服 教程
Linux系统 用MCSM和DockerWine 搭建 我的世界 LiteLoaderBDS 服务器 Minecraft Bedrock Edition 也就是我的世界基岩版,这是 Minecraft 的另一个版本。Minecraft 基岩版可以运行在 Win10、Android、iOS、XBox、switch。基岩版不能使用 Java 版的服务器,…...

2023.8
编译 make install 去掉 folly armv8-acrc arrow NEON 相关链接 https://blog.csdn.net/u011889952/article/details/118762819 这里面的方案二,我之前也是用的这个 https://blog.csdn.net/zzhongcy/article/details/105512565 参考的此博客 火焰图 https://b…...
CSV文件编辑器——Modern CSV for mac
Modern CSV for Mac是一款功能强大、操作简单的CSV文件编辑器,适用于Mac用户快速、高效地处理和管理CSV文件。Modern CSV具有直观的用户界面,可以轻松导入、编辑和导出CSV文件。它支持各种功能,包括排序、过滤、查找和替换,使您能…...
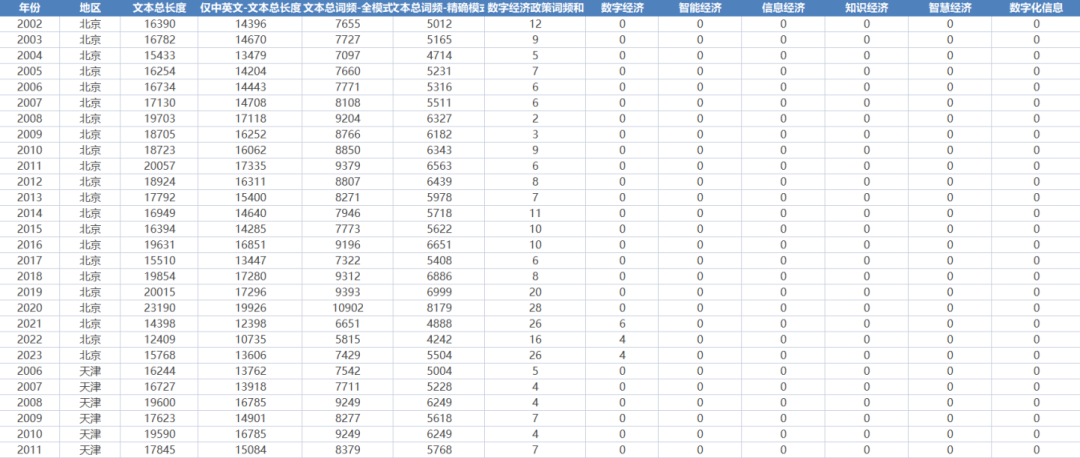
全国各地区数字经济工具变量-文本词频统计(2002-2023年)
数据简介:本数据使用全国各省工作报告,对其中数字经济相关的词汇进行词频统计,从而构建数字经济相关的工具变量。凭借数字经济政策供给与数字经济发展水平的相关系数的显著性作为二者匹配程度的划分依据,一定程度上规避了数字经济…...

MacOS安装RabbitMQ
官网地址: RabbitMQ: easy to use, flexible messaging and streaming — RabbitMQ 一、brew安装 brew update #更新一下homebrew brew install rabbitmq #安装rabbitMQ 安装结果: > Caveats > rabbitmq Management Plugin enabled by defa…...
关于selenium 元素定位的浅度解析
一、By类单一属性定位 元素名称 描述 Webdriver API id id属性 driver.find_element(By.ID, "id属性值") name name属性 driver.find_element(By.NAME, "name属性值") class_name class属性 driver.find_element(By.CLASS_NAME, "class_na…...

狐猬编程:货运
玩具厂生产了一批玩具需要运往美国销售。该批玩具根据大小,已经将其打包装在不同的包装盒里用以运输。该批玩具包装盒共有六个型号,分别1*1*h、2*2*h、3*3*h、4*4*h、5*5*h、6*6*h的包装盒。由于疫情的影响,运输价格十分昂贵,海运…...
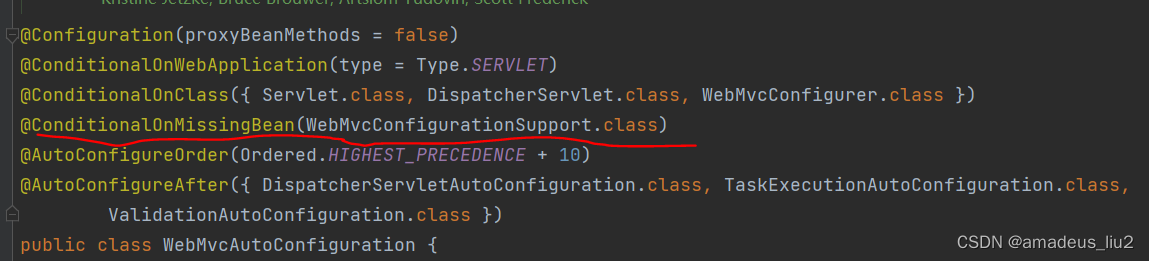
SpringBoot复习:(34)@EnableWebMvc注解为什么让@WebMvcAutoconfiguration失效?
它导入了DelegatingWebMvcConfiguration 它会把容器中的类型为WebMvcConfigurer的bean注入到类型为WebMvcConfigurerComposite的成员变量configurers中。 可以看到它继承了WebMvcConfigurerSupport类 而WebMvcConfigureAutoConfiguration类定义如下 可以看到一个Conditional…...

批量将CSV文件转换为TXT文件
要批量将CSV文件转换为TXT文件,可以按照以下步骤进行操作: 1. 导入所需的Python库:首先,您需要导入csv库来读取CSV文件。 import csv 2. 定义文件路径和输出文件夹: input_folder "your_input_folder_path&q…...

vite跨域配置踩坑,postman链接后端接口正常,但是前端就是不能正常访问
问题一:怎么都链接不了后端地址 根据以下配置,发现怎么都链接不了后端地址,proxy对了呀。 仔细看,才发现host有问题 // 本地运行配置,及反向代理配置server: {host: 0,0,0,0,port: 80,// cors: true, // 默认启用并允…...
模式)
Java设计模式-抽象工厂(Abstract Factory)模式
说明 抽象工厂(Abstract Factory)模式是一种工厂模式。用一个接口类中的不同方法创建不同的产品。 为了便于理解,先打个比方: 将老虎、狮子、猴子比作三个抽象产品的接口类,也就是有3个产品等级。 老虎又分动物园的…...

Hive加密,PostgreSQL解密还原
当前公司数据平台使用的处理架构,由Hive进行大数据处理,然后将应用数据同步到PostgreSQL中做各类外围应用。由于部分数据涉及敏感信息,必须在Hive进行加密,然后在PG使用时再进行单个数据解密,并监控应用的数据调用事情…...

硬件级精细温控:FanControl 风扇控制系统的技术架构与实战应用
硬件级精细温控:FanControl 风扇控制系统的技术架构与实战应用 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tre…...
)
别再只用Tanh了!聊聊ReLU激活函数如何让神经网络‘偷懒’又高效(附稀疏性实验分析)
别再只用Tanh了!聊聊ReLU激活函数如何让神经网络‘偷懒’又高效(附稀疏性实验分析) 激活函数是神经网络中的关键组件,它决定了神经元如何响应输入信号。在深度学习早期,Sigmoid和Tanh函数几乎垄断了所有应用场景。但当…...
)
用STM32F103C8T6做个能遥控能避障的平衡小车,保姆级教程(附代码)
从零打造STM32平衡小车:避障与蓝牙遥控全攻略 第一次看到平衡小车稳稳立在桌面上时,那种成就感至今难忘。作为电子爱好者入门嵌入式开发的经典项目,平衡小车融合了传感器技术、控制算法和硬件设计的精华。本文将带你用STM32F103C8T6这颗性价…...

蓝桥杯备赛指南:从零构建算法知识体系
1. 蓝桥杯竞赛与算法知识体系概述 参加蓝桥杯竞赛就像玩一款策略游戏,你需要先收集基础装备(语法和API),然后学习各种战斗技巧(算法和数据结构),最后才能挑战大Boss(竞赛题目&#…...

终极指南:如何用Bioicons免费矢量图标库快速制作专业科研图表
终极指南:如何用Bioicons免费矢量图标库快速制作专业科研图表 【免费下载链接】bioicons A library of free open source icons for science illustrations in biology and chemistry 项目地址: https://gitcode.com/gh_mirrors/bi/bioicons Bioicons是一个免…...

避坑!这些毕设太好抄了,3000+毕设案例推荐第1078期
781、基于Java的物业报警智慧管理系统的设计与实现(论文+代码+PPT)物业报警智慧管理系统主要功能包括:系统会员、建筑物管理、单元管理、房屋管理、业管理、设备管理、设备维护记录、设备巡检记录、报警管理、报警通知、工单管理、工单日志、…...
)
在Ubuntu 20.04上从零搭建Faster R-CNN PyTorch环境(避坑CUDA 11.1 + PyTorch 1.9)
在Ubuntu 20.04上从零搭建Faster R-CNN PyTorch环境(避坑CUDA 11.1 PyTorch 1.9) 当深度学习遇上目标检测,Faster R-CNN无疑是这个领域的重要里程碑。而PyTorch作为当下最受欢迎的深度学习框架之一,其灵活性和易用性让研究者趋之…...

NerdMiner_v2社区贡献指南:如何参与开源挖矿项目开发
NerdMiner_v2社区贡献指南:如何参与开源挖矿项目开发 【免费下载链接】NerdMiner_v2 Improved version of first ESP32 NerdMiner 项目地址: https://gitcode.com/gh_mirrors/ne/NerdMiner_v2 NerdMiner_v2是一款基于ESP32的开源微型挖矿项目,旨在…...

建站系统是什么?类型、选择标准与常见系统对比
建站系统,顾名思义,是用于创建和管理网站的软件工具或平台。它帮助用户在不编写代码、不深入理解服务器技术的情况下,完成网站的设计、内容发布和功能配置。你可以这样理解:如果说“网站建设”是盖房子,那么“建站系统…...

AssetStudio终极指南:如何免费提取Unity游戏资源
AssetStudio终极指南:如何免费提取Unity游戏资源 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and additional impro…...