【Kubernetes】Kubernetes的调度
K8S调度
- 一、Kubernetes 调度
- 1. Pod 调度介绍
- 2. Pod 启动创建过程
- 3. Kubernetes 的调度过程
- 3.1 调度需要考虑的问题
- 3.2 具体调度过程
- 二、影响kubernetes调度的因素
- 1. nodeName
- 2. nodeSelector
- 3. 亲和性
- 3.1 三种亲和性的区别
- 3.2 键值运算关系
- 3.3 节点亲和性
- 3.4 Pod 亲和性
- 3.5 Pod 反亲和性
- 4. 污点和容忍
- 4.1 污点(Taint)
- 4.2 容忍(Tolerations)
- 5. cordon 和 drain
- 6. Pod启动阶段(相位 phase)
- 7. phase 的可能状态有
- 8. 如何删除 Unknown 状态的 Pod ?
- 9. 故障排除步骤
- 总结
- 1. K8S 如何实现每个组件的协作
- 2. scheduler 的调度算法
- 3. Pod 调度到指定的 node 节点
- 4. 标签的管理操作
- 5. 亲和性
- 6. 亲和性的策略
- 7. 污点和容忍
- 8. 不可调度方式
- 9. Pod 的启动过程
- 10. Pod 生命周期的 5 种状态
- 11. K8S 中的排障手段
一、Kubernetes 调度
1. Pod 调度介绍
Kubernetes 是通过 List-Watch 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。
用户是通过 kubectl 根据配置文件,向 APIServer 发送命令,在 Node 节点上面建立 Pod 和 Container。
APIServer 经过 API 调用,权限控制,调用资源和存储资源的过程,实际上还没有真正开始部署应用。这里 需要 Controller Manager、Scheduler 和 kubelet 的协助才能完成整个部署过程。
在 Kubernetes 中,所有部署的信息都会写到 etcd 中保存。实际上 etcd 在存储部署信息的时候,会发送 Create 事件给 APIServer,而 APIServer 会通过监听(Watch)etcd 发过来的事件。其他组件也会监听(Watch)APIServer 发出来的事件。
调度框架:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/scheduling-framework/
调度策略:https://kubernetes.io/zh-cn/docs/reference/scheduling/policies/
2. Pod 启动创建过程
Pod 是 Kubernetes 的基础单元,Pod 启动典型创建过程如下:
-
(1)这里有三个 List-Watch,分别是 Controller Manager(运行在 Master),Scheduler(运行在 Master),kubelet(运行在 Node)。 他们在进程已启动就会监听(Watch)APIServer 发出来的事件。
-
(2)用户通过 kubectl 或其他 API 客户端提交请求给 APIServer 来建立一个 Pod 对象副本。
-
(3)APIServer 尝试着将 Pod 对象的相关元信息存入 etcd 中,待写入操作执行完成,APIServer 即会返回确认信息至客户端。
-
(4)当 etcd 接受创建 Pod 信息以后,会发送一个 Create 事件给 APIServer。
-
(5)由于 Controller Manager 一直在监听(Watch,通过https的6443端口)APIServer 中的事件。此时 APIServer 接受到了 Create 事件,又会发送给 Controller Manager。
-
(6)Controller Manager 在接到 Create 事件以后,调用其中的 Replication Controller 来保证 Node 上面需要创建的副本数量。一旦副本数量少于 RC 中定义的数量,RC 会自动创建副本。总之它是保证副本数量的 Controller(PS:扩容缩容的担当)。
-
(7)在 Controller Manager 创建 Pod 副本以后,APIServer 会在 etcd 中记录这个 Pod 的详细信息。例如 Pod 的副本数,Container 的内容是什么。
-
(8)同样的 etcd 会将创建 Pod 的信息通过事件发送给 APIServer。
-
(9)由于 Scheduler 在监听(Watch)APIServer,并且它在系统中起到了“承上启下”的作用,“承上”是指它负责接收创建的 Pod 事件,为其安排 Node;“启下”是指安置工作完成后,Node 上的 kubelet 进程会接管后继工作,负责 Pod 生命周期中的“下半生”。 换句话说,Scheduler 的作用是将待调度的 Pod 按照调度算法和策略绑定到集群中 Node 上。
-
(10)Scheduler 调度完毕以后会更新 Pod 的信息,此时的信息更加丰富了。除了知道 Pod 的副本数量,副本内容。还知道部署到哪个 Node 上面了。并将上面的 Pod 信息更新至 API Server,由 APIServer 更新至 etcd 中,保存起来。
-
(11)etcd 将更新成功的事件发送给 APIServer,APIServer 也开始反映此 Pod 对象的调度结果。
-
(12)kubelet 是在 Node 上面运行的进程,它也通过 List-Watch 的方式监听(Watch,通过https的6443端口)APIServer 发送的 Pod 更新的事件。kubelet 会尝试在当前节点上调用 Docker 启动容器,并将 Pod 以及容器的结果状态回送至 APIServer。
-
(13)APIServer 将 Pod 状态信息存入 etcd 中。在 etcd 确认写入操作成功完成后,APIServer将确认信息发送至相关的 kubelet,事件将通过它被接受。

#注意:在创建 Pod 的工作就已经完成了后,为什么 kubelet 还要一直监听呢?原因很简单,假设这个时候 kubectl 发命令,要扩充 Pod 副本数量,那么上面的流程又会触发一遍,kubelet 会根据最新的 Pod 的部署情况调整 Node 的资源。又或者 Pod 副本数量没有发生变化,但是其中的镜像文件升级了,kubelet 也会自动获取最新的镜像文件并且加载。
3. Kubernetes 的调度过程
3.1 调度需要考虑的问题
Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上。其主要考虑的问题如下:
- 公平:如何保证每个节点都能被分配资源;
- 资源高效利用:集群所有资源最大化被使用;
- 效率:调度的性能要好,能够尽快地对大批量的 pod 完成调度工作;
- 灵活:允许用户根据自己的需求控制调度的逻辑。
Sheduler 是作为单独的程序运行的,启动之后会一直监听 APIServer,获取 spec.nodeName 为空的 pod,对每个 pod 都会创建一个 binding,表明该 pod 应该放到哪个节点上。
3.2 具体调度过程
- 首先是过滤掉不满足条件的节点,这个过程称为预算策略(predicate);
- 然后对通过的节点按照优先级排序,这个是优选策略(priorities);
- 最后从中选择优先级最高的节点。如果中间任何一步骤有错误,就直接返回错误。
- 如果在 predicate 过程中没有合适的节点,pod 会一直在 pending 状态,不断重试调度,直到有节点满足条件。 经过这个步骤,如果有多个节点满足条件,就继续 priorities 过程:按照优先级大小对节点排序。
- 通过算法对所有的优先级项目和权重进行计算,得出最终的结果。
Predicate 常见的算法
| 算法 | 含义 |
|---|---|
| PodFitsResources | 节点上剩余的资源是否大于 pod 请求的资源。 |
| PodFitsHost | 如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配。 |
| PodFitsHostPorts | 节点上已经使用的 port 是否和 pod 申请的 port 冲突。 |
| PodSelectorMatches | 过滤掉和 pod 指定的 label 不匹配的节点。 |
| NoDiskConflict | 已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非它们都是只读。 |
优先级
优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。有一系列的常见的优先级选项包括:
| 选项 | 含义 |
|---|---|
| LeastRequestedPriority | 通过计算CPU和Memory的使用率来决定权重,使用率越低权重越高。也就是说,这个优先级指标倾向于资源使用比例更低的节点。 |
| BalancedResourceAllocation | 节点上 CPU 和 Memory 使用率越接近,权重越高。这个一般和LeastRequestedPriority一起使用,不单独使用。 比如 node01 的 CPU 和 Memory 使用率 20:60,node02 的 CPU 和 Memory 使用率 50:50,虽然 node01 的总使用率比 node02 低,但 node02 的 CPU 和 Memory 使用率更接近,从而调度时会优选 node02。 |
| ImageLocalityPriority | 倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高。 |
二、影响kubernetes调度的因素
1. nodeName
指定调度节点:pod.spec.nodeName 将 Pod 直接调度到指定的 Node 节点上,会跳过 Scheduler 的调度策略,该匹配规则是强制匹配。
vim myapp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp
spec:replicas: 3selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:nodeName: node01containers:- name: myappimage: nginxports:- containerPort: 80

kubectl apply -f demo1.yamlkubectl get pods -o wide#查看详细事件(发现未经过 scheduler 调度分配)
kubectl describe pod myapp-6bc58d7775-6wlpp

2. nodeSelector
pod.spec.nodeSelector:通过 kubernetes 的 label-selector 机制选择节点,由调度器调度策略匹配 label,然后调度 Pod 到目标节点,该匹配规则属于强制约束。
#获取标签帮助
kubectl label --help
Usage:kubectl label [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N
[--resource-version=version] [options]#需要获取 node 上的 NAME 名称
kubectl get node
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 54m v1.20.15
node01 Ready <none> 51m v1.20.15
node02 Ready <none> 51m v1.20.15

#给对应的 node 设置标签分别为 class=a 和 class=b
kubectl label nodes node01 class=a
kubectl label nodes node02 class=b#查看标签
kubectl get nodes --show-labels

#修改成 nodeSelector 调度方式
vim myapp1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp1
spec:replicas: 3selector:matchLabels:app: myapp1template:metadata:labels:app: myapp1spec:nodeSelector:class: acontainers:- name: myapp1image: nginxports:- containerPort: 80

kubectl apply -f myapp1.yaml kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp1-6f999d795-9vc8w 0/1 ContainerCreating 0 13s <none> node01 <none> <none>
myapp1-6f999d795-gpfsh 0/1 ContainerCreating 0 13s <none> node01 <none> <none>
myapp1-6f999d795-nhlg7 0/1 ContainerCreating 0 13s <none> node01 <none>#查看详细事件(通过事件可以发现要先经过 scheduler 调度分配)
kubectl describe pod myapp1-6f999d795-9vc8w
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Scheduled 41s default-scheduler Successfully assigned default/myapp1-6f999d795-9vc8w to node01Normal Pulling 40s kubelet Pulling image "nginx"Normal Pulled 9s kubelet Successfully pulled image "nginx" in 30.729226268sNormal Created 9s kubelet Created container myapp1Normal Started 9s kubelet Started container myapp1

#修改一个 label 的值,需要加上 --overwrite 参数
kubectl label nodes node02 class=a --overwrite#删除一个 label,只需在命令行最后指定 label 的 key 名并与一个减号相连即可:
kubectl label nodes node02 class-#指定标签查询 node 节点
kubectl get node -l class=a

3. 亲和性
官网:https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/
节点亲和 和 pod亲和 如果同时存在且发生冲突,会报错!
亲和性调度是指通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活。
亲和性(Affinity)主要分为三类:
- 节点亲和性(nodeAfinity): 以node为目标,解决pod可以调度到哪些node的问题。
- pod亲和性(podAffinity):以pod为目标,解决pod可以和哪些已经存在pod部署到同一个拓扑域中的问题。
- pod反亲和性(podAntiAfinity): 以pod为目标,解决pod不能和哪些已存在的pod部署在统一个拓扑域中的问题。
#节点亲和性
pod.spec.nodeAffinity
● preferredDuringSchedulingIgnoredDuringExecution:软策略
● requiredDuringSchedulingIgnoredDuringExecution:硬策略#Pod 亲和性
pod.spec.affinity.podAffinity/podAntiAffinity
● preferredDuringSchedulingIgnoredDuringExecution:软策略
● requiredDuringSchedulingIgnoredDuringExecution:硬策略
3.1 三种亲和性的区别
| 调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 |
|---|---|---|---|---|
| nodeAffinity | 主机 | In,NotIn,Exisits,DoesNotExist,Gt,Lt | 否 | 指定主机 |
| podAffinity | Pod | In,NotIn,Exisits,DoesNotExist | 是 | Pod与指定Pod同一拓扑域 |
| podAntiAffinity | Pod | In,NotIn,Exisits,DoesNotExist | 是 | Pod与指定Pod不在同一拓扑域 |
3.2 键值运算关系
In #label 的值在某个列表中
NotIn #label 的值不在某个列表中
Gt #label 的值大于某个值
Lt #label 的值小于某个值
Exists #某个 label 存在
DoesNotExist #某个 label 不存在
3.3 节点亲和性
kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
master01 Ready control-plane,master 110m v1.20.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=
node01 Ready <none> 107m v1.20.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=linux
node02 Ready <none> 107m v1.20.15 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node02,kubernetes.io/os=linux

硬策略
#requiredDuringSchedulingIgnoredDuringExecution:硬策略
mkdir /opt/affinity
cd /opt/affinityvim pod1.yaml
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: nginxaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostname #指定node的标签operator: NotIn #设置Pod安装到kubernetes.io/hostname的标签值不在values列表中的node上values:- node02

kubectl apply -f pod1.yamlkubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 13s 10.244.1.30 node01 <none> <none>kubectl delete pod --all && kubectl apply -f pod1.yaml && kubectl get pods -o wide#如果硬策略不满足条件,Pod 状态一直会处于 Pending 状态。

软策略
#preferredDuringSchedulingIgnoredDuringExecution:软策略
vim pod2.yaml
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: nginxaffinity:nodeAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 1 #如果有多个软策略选项的话,权重越大,优先级越高preference:matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- node02kubectl apply -f pod2.yamlkubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 5s 10.244.2.35 node02 <none> <none>

#把values:的值改成node01,则会优先在node01上创建Pod
kubectl delete pod --all
kubectl apply -f pod2.yaml
kubectl get pods -o wide

硬策略和软策略结合使用
#如果把硬策略和软策略合在一起使用,则要先满足硬策略之后才会满足软策略
kubectl label nodes node01 class=a
kubectl label nodes node02 class=b
kubectl get nodes --show-labels

vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: nginxaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution: #先满足硬策略,排除有kubernetes.io/hostname=node02标签的节点nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: NotInvalues:- node02preferredDuringSchedulingIgnoredDuringExecution: #再满足软策略,优先选择有class=a标签的节点- weight: 1preference:matchExpressions:- key: classoperator: Invalues:- akubectl apply -f pod3.yaml
kubectl get pods -o wide

3.4 Pod 亲和性
#创建标签
kubectl label nodes node01 class=a
kubectl label nodes node02 class=a#创建一个标签为 app=myapp01 的 Pod
vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1kubectl apply -f pod3.yamlkubectl get pods --show-labels -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
myapp01 1/1 Running 0 37s 10.244.2.3 node01 <none> <none> app=myapp01

#使用 Pod 亲和性调度,创建多个 Pod 资源
vim pod4.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp02labels:app: myapp02
spec:containers:- name: myapp02image: nginxaffinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- myapp01topologyKey: class#仅当节点和至少一个已运行且有键为“app”且值为“myapp01”的标签 的 Pod 处于同一拓扑域时,才可以将该 Pod 调度到节点上。 (更确切的说,如果节点 N 具有带有键 class 和某个值 V 的标签,则 Pod 有资格在节点 N 上运行,以便集群中至少有一个具有键 class 和值为 V 的节点正在运行具有键“app”和值 “myapp01”的标签的 pod。)
#topologyKey 是节点标签的键。如果两个节点使用此键标记并且具有相同的标签值,则调度器会将这两个节点视为处于同一拓扑域中。 调度器试图在每个拓扑域中放置数量均衡的 Pod。
#如果 class 对应的值不一样就是不同的拓扑域。比如 Pod1 在 class=a 的 Node 上,Pod2 在 class=b 的 Node 上,Pod3 在 class=a 的 Node 上,则 Pod2 和 Pod1、Pod3 不在同一个拓扑域,而Pod1 和 Pod3在同一个拓扑域。kubectl apply -f pod4.yamlkubectl get pods --show-labels -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
myapp01 1/1 Running 0 4m22s 10.244.1.15 node01 <none> <none> app=myapp01
myapp02 1/1 Running 0 39s 10.244.2.4 node02 <none> <none> app=myapp02

3.5 Pod 反亲和性
vim pod5.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp10labels:app: myapp10
spec:containers:- name: myapp10image: nginxaffinity:podAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 100podAffinityTerm:labelSelector:matchExpressions:- key: appoperator: Invalues:- myapp01topologyKey: kubernetes.io/hostname#如果节点处于 Pod 所在的同一拓扑域且具有键“app”和值“myapp01”的标签, 则该 pod 不应将其调度到该节点上。 (如果 topologyKey 为 kubernetes.io/hostname,则意味着当节点和具有键 “app”和值“myapp01”的 Pod 处于相同的拓扑域,Pod 不能被调度到该节点上。)

kubectl apply -f pod5.yamlkubectl get pods --show-labels -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
myapp01 1/1 Running 0 8m12s 10.244.1.15 node01 <none> <none> app=myapp01
myapp02 1/1 Running 0 4m29s 10.244.2.4 node02 <none> <none> app=myapp02
myapp10 1/1 Running 0 22s 10.244.2.5 node02 <none> <none> app=myapp10

vim pod6.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp20labels:app: myapp20
spec:containers:- name: myapp20image: nginxaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- myapp01topologyKey: class#由于指定 Pod 所在的 node01 节点上具有带有键 class 和标签值 a 的标签,node02 也有这个kgc=a的标签,所以 node01 和 node02 是在一个拓扑域中,反亲和要求新 Pod 与指定 Pod 不在同一拓扑域,所以新 Pod 没有可用的 node 节点,即为 Pending 状态。

kubectl get pod --show-labels -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
myapp01 1/1 Running 0 43s 10.244.1.68 node01 <none> <none> app=myapp01
myapp20 0/1 Pending 0 4s <none> <none> <none> <none> app=myapp03kubectl label nodes node02 class=b --overwritekubectl get pod --show-labels -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
myapp01 1/1 Running 0 7m40s 10.244.1.68 node01 <none> <none> app=myapp01
myapp21 1/1 Running 0 7m1s 10.244.2.65 node02 <none> <none> app=myapp03

4. 污点和容忍
4.1 污点(Taint)
节点亲和性,是Pod的一种属性(偏好或硬性要求),它使Pod被吸引到一类特定的节点。Taint 则相反,它使节点能够排斥一类特定的 Pod。
Taint 和 Toleration 相互配合,可以用来避免 Pod 被分配到不合适的节点上。每个节点上都可以应用一个或多个 taint ,这表示对于那些不能容忍这些 taint 的 Pod,是不会被该节点接受的。如果将 toleration 应用于 Pod 上,则表示这些 Pod 可以(但不一定)被调度到具有匹配 taint 的节点上。
使用 kubectl taint 命令可以给某个 Node 节点设置污点,Node 被设置上污点之后就和 Pod 之间存在了一种相斥的关系,可以让 Node 拒绝 Pod 的调度执行,甚至将 Node 已经存在的 Pod 驱逐出去。
#污点的格式
key=value:effect#每个污点有一个 key 和 value 作为污点的标签,其中 value 可以为空,effect 描述污点的作用。
当前 taint effect 支持如下三个选项:
| 选项 | 含义 |
|---|---|
| NoSchedule | 表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上。 |
| PreferNoSchedule | 表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上。 |
| NoExecute | 表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上,同时会将 Node 上已经存在的 Pod 驱逐出去。 |
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 7m54s v1.20.15
node01 Ready <none> 2m58s v1.20.15
node02 Ready <none> 2m57s v1.20.15#master 就是因为有 NoSchedule 污点,k8s 才不会将 Pod 调度到 master 节点上
kubectl describe node master
......
Taints: node-role.kubernetes.io/master:NoSchedule

#设置污点
kubectl taint node node01 key1=value1:NoSchedule#节点说明中,查找 Taints 字段
kubectl describe node node01 | grep Taints #去除污点
kubectl taint node node01 key1:NoSchedule-

kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-5fb876b6f7-6dxmn 1/1 Running 0 97s 10.244.2.4 node02 <none> <none>
myapp-5fb876b6f7-9jgb2 1/1 Running 0 97s 10.244.2.2 node02 <none> <none>
myapp-5fb876b6f7-l9fzc 1/1 Running 0 97s 10.244.2.3 node02 <none> <none>kubectl taint node node02 check=mycheck:NoExecute#查看 Pod 状态,会发现 node02 上的 Pod 已经被全部驱逐(注:如果是 Deployment 或者 StatefulSet 资源类型,为了维持副本数量则会在别的 Node 上再创建新的 Pod)
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-5fb876b6f7-pf9dd 0/1 Pending 0 0s <none> node02 <none> <none>

4.2 容忍(Tolerations)
设置了污点的 Node 将根据 taint 的 effect:NoSchedule、PreferNoSchedule、NoExecute 和 Pod 之间产生互斥的关系,Pod 将在一定程度上不会被调度到 Node 上。但我们可以在 Pod 上设置容忍(Tolerations),意思是设置了容忍的 Pod 将可以容忍污点的存在,可以被调度到存在污点的 Node 上。
kubectl taint node node01 check=mycheck:NoExecutevim pod3.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: nginxkubectl apply -f pod3.yaml

#在两个 Node 上都设置了污点后,此时 Pod 将无法创建成功
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp01 0/1 Pending 0 17s <none> <none> <none> <none>vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: nginxtolerations:- key: "check"operator: "Equal"value: "mycheck"effect: "NoExecute"tolerationSeconds: 3600#其中的 key、vaule、effect 都要与 Node 上设置的 taint 保持一致
#operator 的值为 Exists 将会忽略 value 值,即存在即可
#tolerationSeconds 用于描述当 Pod 需要被驱逐时可以在 Node 上继续保留运行的时间

kubectl apply -f pod3.yaml#在设置了容忍之后,Pod 创建成功
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp01 1/1 Running 0 10m 10.244.1.5 node01 <none> <none>

其它注意事项
#1.当不指定 key 值时,表示容忍所有的污点 keytolerations:- operator: "Exists"#2.当不指定 effect 值时,表示容忍所有的污点作用tolerations:- key: "key"operator: "Exists"#3.有多个 Master 存在时,防止资源浪费,可以如下设置
kubectl taint node Master-Name node-role.kubernetes.io/master=:PreferNoSchedule#如果某个 Node 更新升级系统组件,为了防止业务长时间中断,可以先在该 Node 设置 NoExecute 污点,把该 Node 上的 Pod 都驱逐出去
kubectl taint node node01 check=mycheck:NoExecute#此时如果别的 Node 资源不够用,可临时给 Master 设置 PreferNoSchedule 污点,让 Pod 可在 Master 上临时创建
kubectl taint node master node-role.kubernetes.io/master=:PreferNoSchedule#待所有 Node 的更新操作都完成后,再去除污点
kubectl taint node node01 check=mycheck:NoExecute-
5. cordon 和 drain
##对节点执行维护操作:
kubectl get nodes
将 Node 标记为不可调度的状态,这样就不会让新创建的 Pod 在此 Node 上运行。
#命令格式
kubectl cordon <NODE_NAME> #该node将会变为SchedulingDisabled状态
kubectl drain 可以让 Node 节点开始释放所有 pod,并且不接收新的 pod 进程。drain 本意排水,意思是将出问题的 Node 下的 Pod 转移到其它 Node 下运行。
#命令格式
kubectl drain <NODE_NAME> --ignore-daemonsets --delete-emptydir-data --force--------------------------------------------------------------------------------
--ignore-daemonsets:无视 DaemonSet 管理下的 Pod。
--delete-emptydir-data:如果有 mount local volume 的 pod,会强制杀掉该 pod。
--force:强制释放不是控制器管理的 Pod。
注:执行 drain 命令,会自动做了两件事情:
- 设定此 node 为不可调度状态(cordon)
- evict(驱逐)了 Pod
#kubectl uncordon 将 Node 标记为可调度的状态
kubectl uncordon <NODE_NAME>
6. Pod启动阶段(相位 phase)
Pod 创建完之后,一直到持久运行起来,中间有很多步骤,也就有很多出错的可能,因此会有很多不同的状态。
一般来说,pod 这个过程包含以下几个步骤:
- 调度到某台 node 上。kubernetes 根据一定的优先级算法选择一台 node 节点将其作为 Pod 运行的 node;
- 拉取镜像;
- 挂载存储配置等;
- 容器运行起来。如果有健康检查,会根据检查的结果来设置其状态。
7. phase 的可能状态有
- Pending:表示APIServer创建了Pod资源对象并已经存入了etcd中,但是它并未被调度完成(比如还没有调度到某台node上),或者仍然处于从仓库下载镜像的过程中。
- Running:Pod已经被调度到某节点之上,并且Pod中所有容器都已经被kubelet创建。至少有一个容器正在运行,或者正处于启动或者重启状态(也就是说Running状态下的Pod不一定能被正常访问)。
- Succeeded:有些pod不是长久运行的,比如job、cronjob,一段时间后Pod中的所有容器都被成功终止,并且不会再重启。需要反馈任务执行的结果。
- Failed:Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止,比如 command 写的有问题。
- Unknown:表示无法读取 Pod 状态,通常是 kube-controller-manager 无法与 Pod 通信。Pod 所在的 Node 出了问题或失联,从而导致 Pod 的状态为 Unknow。
8. 如何删除 Unknown 状态的 Pod ?
- 从集群中删除有问题的 Node。使用公有云时,kube-controller-manager 会在 VM 删除后自动删除对应的 Node。 而在物理机部署的集群中,需要管理员手动删除 Node(
kubectl delete node <node_name>)。 - 被动等待 Node 恢复正常,Kubelet 会重新跟 kube-apiserver 通信确认这些 Pod 的期待状态,进而再决定删除或者继续运行这些 Pod。
- 主动删除 Pod,通过执行
kubectl delete pod <pod_name> --grace-period=0 --force强制删除 Pod。但是这里需要注意的是,除非明确知道 Pod 的确处于停止状态(比如 Node 所在 VM 或物理机已经关机),否则不建议使用该方法。特别是 StatefulSet 管理的 Pod,强制删除容易导致脑裂或者数据丢失等问题。
9. 故障排除步骤
#查看Pod事件
kubectl describe TYPE NAME_PREFIX #查看Pod日志(Failed状态下)
kubectl logs <POD_NAME> [-c Container_NAME]#进入Pod(状态为running,但是服务没有提供)
kubectl exec –it <POD_NAME> bashkubectl debug -it <POD_NAME> --image=busybox:1.28 --target=${container_name} #在为 Pod 里的具体某个容器添加一个临时容器(镜像为 busybox),并进行 debug。#查看集群信息
kubectl get nodes#发现集群状态正常
kubectl cluster-info#查看kubelet日志发现
journalctl -xefu kubelet
总结
1. K8S 如何实现每个组件的协作
controller-manager、scheduler、kubelet 通过 List-Watch 机制监听 apiserver 发出的事件,apiserver 通过 List-Watch 机制监听 etcd 发出的事件
2. scheduler 的调度算法
预选策略/预算策略:通过调度算法过滤掉不满足条件的Node节点,如果没有满足条件的Node节点,Pod会处于Pending状态,直到有符合条件的Node节点出现
PodFitsResources、PodFitsHost、PodFitsHostPorts、PodSelectorMatches、NoDiskConflict优选策略:根据优先级选项为满足预选策略条件的Node节点进行优先级权重排序,最终选择优先级最高的Node节点来调度Pod
LeastRequestedPriority、BalancedResourceAllocation、ImageLocalityPriority
3. Pod 调度到指定的 node 节点
1)使用 nodeName 字段指定 Node 节点名称
2)使用 node Selector 指定 Node 节点的标签
3)使用 节点/Pod 亲和性
4)使用 污点+容忍
4. 标签的管理操作
kubectl label <资源类型> <资源名称> 标签key=标签value #添加标签
kubectl label <资源类型> <资源名称> 标签key=标签value --overwrite #将标签进行重写
kubectl label <资源类型> <资源名称> 标签key- #删除标签kubectl get <资源类型> <资源名称> --show-labels #查看标签
kubectl label <资源类型> -l 标签key[] #过滤标签
5. 亲和性
节点亲和性(nodeAffinity):匹配指定的Node节点标签,将要部署的Pod调度到满足条件的Node节点上Pod亲和性(podAffinity):匹配指定的Pod标签,将要部署的Pod调度到与指定Pod所在的Node节点处于 同一个拓扑域 的Node节点上Pod反亲和性(podAntiAffinity):匹配指定的Pod标签,将要部署的Pod调度到与指定Pod所在的Node节点处于 不同的拓扑域 的Node节点上#如何判断是否处于同一个拓扑域
看拓扑域key(topologKey),如果有其他Node节点拥有与指定Pod所在的Node节点相同的 拓扑域key的标签key和value,那么它们就在同一个拓扑域。
6. 亲和性的策略
硬策略(required....):要强制性的满足指定条件,如果没有满足条件的Node节点,Pod会处于Pending状态,直到有符合条件的Node节点出现软策略(preferred....):非强制性的,会优先选择满足条件的Node节点调度,即使没有满足条件的Node节点,Pod依然会完成调度
7. 污点和容忍
#污点 taint
kubectl taint node <node名称> key=value:effectNoSchedule(一定不会被调度) PreferNoSchedule(尽量不被调度) NoExecute(不会被调度,并驱逐节点上的Pod)kubectl taint node <node名称> key[=value:effect]-kubectl describe nodes <node名称> | grep Taints#容忍 tolerations
spec:tolerations:- key: 污点键名operator: Equal|Existsvalue: 污点键值effect: NoSchedule|PreferNoSchedule|NoExecute
8. 不可调度方式
#不可调度
kubectl cordon <node名称>kubectl uncordon <node名称>#不可调度 + 驱逐
kubectl drain <node名称> --ignore-daemonsets --delete-emptydir-data --force
9. Pod 的启动过程
1)通过 scheduler 根据调度算法选择一条在最合适的 Node 节点运行 Pod
2)拉取镜像
3)挂载 存储卷 等
4)创建并运行容器
5)根据容器的探针探测结果设置 Pod 状态
10. Pod 生命周期的 5 种状态
pending pod已经创建,但处于包括pod还未完成调度到node节点的过程或者处于镜像拉取过程中、存储卷挂载失败等情况
running pod中至少有一个容器正在运行
succeeded pod中的所有容器都已经成功退出,且不再重启(Complated)
failed pod中的所有容器都已终止,且至少有一个容器异常退出(Error)
unkunown Master 节点的 controller-manager 无法获取pod的状态,通常是因为 Maste r节点与pod所在的 Node 节点通信失联#Pod遵循预定义的生命周期,起始于Pending阶段,如果至少其中有一个主要容器正常启动,
#则进入Running阶段,之后取决于Pod中是否有容器以失败状态结束而进入Succeeded或者Failed阶段。
11. K8S 中的排障手段
kubectl get pods #查看Pod运行状态
kubectl desrcibe <资源类型|pods> <资源名称> #查看资源的详细信息和事件
kubectl logs <pod名称> [-c <容器名>] [-p] #查看容器的进程日志
kubectl exec -it <pod名称> [-c <容器名>] sh|bash #进入Pod容器,查看容器内部相关状态信息
kubectl debug -it <pod名称> --image=<临时容器的镜像名> --target=<目标容器> #在Pod中创建临时容器进入目标容器进行调试在Pod容器的宿主机使用nsenter转换网络等命名空间,直接在宿主机进入目标容器的命名空间进行调试。kubectl get nodes #查看Node节点的运行状态
kubectl get cs #查看Master组件的状态
kubectl cluster-info #查看集群信息journalctl -u kubelet -f #跟踪查看Kubelet进程日志
相关文章:
【Kubernetes】Kubernetes的调度
K8S调度 一、Kubernetes 调度1. Pod 调度介绍2. Pod 启动创建过程3. Kubernetes 的调度过程3.1 调度需要考虑的问题3.2 具体调度过程 二、影响kubernetes调度的因素1. nodeName2. nodeSelector3. 亲和性3.1 三种亲和性的区别3.2 键值运算关系3.3 节点亲和性3.4 Pod 亲和性3.5 P…...

题目:2511.最多可以摧毁的敌人城堡数量
题目来源: leetcode题目,网址:2511. 最多可以摧毁的敌人城堡数目 - 力扣(LeetCode) 解题思路: 顺序遍历数组,记录上一个我军城堡和没有城堡的位置。当碰到空位置时,若上一次更新的…...

22 | 书籍推荐数据分析
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn import neighbors from sklearn.model_selection import train_test_split from sklearn.preprocessing import...

vscode extension 怎么区分dev prod
开发模式注入环境变量 使用vsode 提供的api...

Java学习手册——第一篇Java简介
今后Java学习手册就来给大家梳理JavaSE的基础知识啦, 除了这个专栏我们还有其他专栏:前端、安全、后端等。 希望大家可以在这里一起讨论学习哟~ Java学习手册——第一篇Java简介 1. Java基础知识2. Java能干嘛3. Java基础环境搭建 1. Java基础知识 出生…...
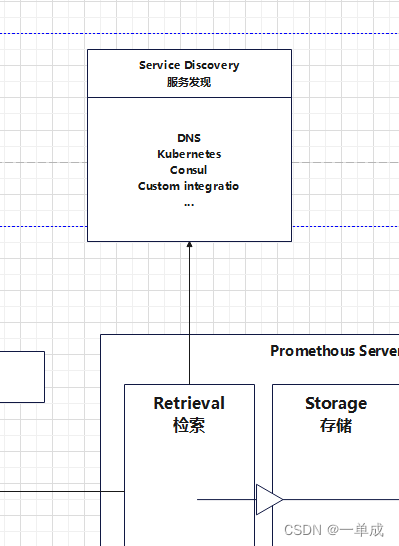
Prometheus流程图(自绘)-核心组件-流程详解
阿丹手绘流程图:图片可能有点小查看的时候放大看看哈! prometheus核心组件 prometheus server Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。Prometheus Server可以通过静态配置管理…...

回归模型常见评估指标mae,mse,rmse
文章目录 MAE(平均绝对误差)计算公式sklearn实现numpy实现mse(均方误差)计算公式sklearn实现numpy实现rmse(均方根误差)计算公式sklearn实现MAE(平均绝对误差) 计算公式 MAE ( y ,...

服务器数据恢复-断电导致ext4文件系统文件丢失的数据恢复案例
服务器数据恢复环境: 一台服务器挂载一台存储设备,存储中划分一个Lun;服务器操作系统是Linux centos,EXT4文件系统。 服务器故障&分析: 意外断电导致服务器操作系统无法启动,系统在修复后可以正常启动&…...

链表(基础详解、实现、OJ笔试题)
文章目录 🧚什么是链表(链表概念及分类)链表分类单链表和双链表的区别 🚴♂️单链表、双向链表的实现单链表的实现双向链表的实现 🍉链表经典OJ笔试题反转单链表移除链表元素合并两个有序链表链表分割链表的中间结点…...
W5100S-EVB-PICO作为TCP Client 进行数据回环测试(五)
前言 上一章我们用W5100S-EVB-PICO开发板通过DNS解析www.baidu.com(百度域名)成功得到其IP地址,那么本章我们将用我们的开发板作为客户端去连接服务器,并做数据回环测试:收到服务器发送的数据,并回传给服务…...
大数据-玩转数据-Redis 安装与使用
一、说明 大多数企业都是基于Linux服务器来部署项目,而且Redis官方也没有提供Windows版本的安装包。因此课程中我们会基于Linux系统来安装Redis. 此处选择的Linux版本为CentOS 7. Redis的官方网站地址:http://download.redis.io/releases 二、下载 m…...

实时指标-1日留存率
2个DWD层 登录→kafka注册→kafka1个DWS 弄2条流,从kafka读取数据将昨日注册数据存到状态中,TTL为2天,存到map状态中,key为注册日期,value为set,存储注册的uid将登录流和注册流进行连接来一条登录数据&…...

【玩转23种Java设计模式】行为型模式篇:责任链模式
软件设计模式(Design pattern),又称设计模式,是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性、程序的重用性。 汇总目录链接&…...

【C#】获取电脑CPU、内存、屏幕、磁盘等信息
通过WMI类来获取电脑各种信息,参考文章:WMI_04_常见的WMI类的属性_wmi scsilogicalunit_fantongl的博客-CSDN博客 自己整理了获取电脑CPU、内存、屏幕、磁盘等信息的代码 #region 系统信息/// <summary>/// 电脑信息/// </summary>public p…...

途乐证券-最准确的KDJ改良指标?
KDJ目标是技术剖析的一种重要目标之一,它是利用随机目标(%R)发展而来的,是一种反映商场超买和超卖状况的买卖目标。KDJ目标由快线(K线)、慢线(D线)和随机值(J线ÿ…...
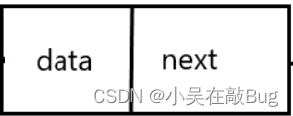
数据结构——线性表
文章目录 线性表的定义和基本操作顺序表线性表的链式表示 线性表的定义和基本操作 线性表是具有相同数据类型的(n≥0)个数据元素的有限序列,其中n为表长,当n0时线性表是一个空表。若用L命名线性表,则其中一般表示为:L(a1,a2,a3, …...
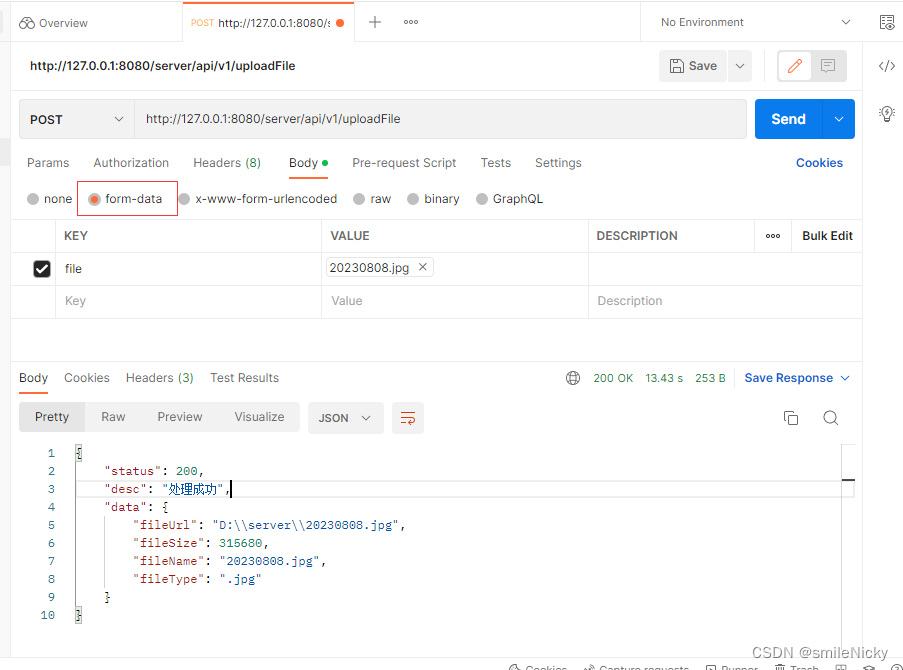
SpringBoot系列之基于Jersey实现文件上传API
前言 JAX-RS:JAX-RS是可以用可以用于实现RESTFul应用程序的JAVA API,给开发者提供了一系列的RESTFul注解Jersey:是基于JAX-RX API的实现框架,用于实现RESTful Web 服务的开源框架。 JAX-RX常用的注解: javax.ws.rs.Pa…...

【LangChain】Prompts之示例选择器
LangChain学习文档 【LangChain】向量存储(Vector stores)【LangChain】向量存储之FAISS【LangChain】Prompts之Prompt templates【LangChain】Prompts之自定义提示模板【LangChain】Prompts之示例选择器 概要 如果您有大量示例,您可能需要选择要包含在提示中的哪…...

Neo4j之CREATE基础
在 Neo4j 中,CREATE 语句用于创建节点、关系以及节点属性。 创建节点: CREATE (p:Person {name: John, age: 30});这个查询会创建一个具有 "Person" 标签的节点,节点属性包括 "name" 和 "age"。 创建带有关…...

Kali Hyper-V安装正常启动后 黑屏 只能进命令模式
问题: Hyper-V安装虚拟机Kali系统一切安装正常, 没有出现错误. 安装成功后重启,只能进入命令模式,tt1-tt6,进不去GUI桌面. 尝试: 一代二代虚拟硬盘都试过,同样问题,只能开进后进入命令模式,在命令模式下一切运行正常, 也修复过系统 GNOM等的,不管用. 以下为国外论坛给的建议,尝…...

AI辅助开发术语体系深度剖析
随着生成式AI与软件开发的深度融合,一系列全新的术语和开发范式应运而生。这些概念并非孤立存在,而是相互关联、层层支撑,共同构成了当前AI编程的新骨架。对于有一定基础的开发者而言,系统性掌握这套术语体系,不仅能提…...

AI测试标准更新:2026年新规详解
从“野蛮生长”到“有标可依”的行业转折点进入2026年,人工智能技术已深度融入各行各业,从生成式内容创作到具身智能机器人,AI系统正以前所未有的速度重塑生产和生活。然而,技术狂奔的背后,是日益凸显的风险与挑战&…...

Excalidraw虚拟白板工具:如何用5分钟开启你的手绘图表创作之旅?
Excalidraw虚拟白板工具:如何用5分钟开启你的手绘图表创作之旅? 【免费下载链接】excalidraw Virtual whiteboard for sketching hand-drawn like diagrams 项目地址: https://gitcode.com/GitHub_Trending/ex/excalidraw 你是否厌倦了传统图表工…...

【硬件进阶】DRC零报错却沦为废砖?PCB设计中价值千金的4个“致命雷区”
前言: 从“连线工”蜕变为“硬件专家”,分水岭就在于你是否具备 DFM(可制造性设计) 和 PI/SI(电源/信号完整性) 的全局思维。今天,我们拆解四个极其隐蔽、但一旦踩中就会让你的板子直接报废的 P…...
 —— 从launch到all_gather:环境初始化与数据同步实战)
torch.distributed多卡/多GPU/分布式DPP(一) —— 从launch到all_gather:环境初始化与数据同步实战
1. 分布式训练入门:为什么需要多GPU协作 当你面对一个庞大的图像分类数据集时,单张GPU的训练速度可能让你等到花儿都谢了。这时候分布式训练就像请来了一群帮手,让多张GPU同时干活。想象一下,如果让4个厨师同时切菜,肯…...
- 田忌赛马(Java JS Python C))
(200分)- 田忌赛马(Java JS Python C)
(200分)- 田忌赛马(Java & JS & Python & C)题目描述给定两个只包含数字的数组a,b,调整数组 a 里面的数字的顺序,使得尽可能多的a[i] > b[i]。数组a和b中的数字各不相同。输出所有可以达到最优结果的a数…...

终极指南:使用Jsxer快速解密Adobe JSXBIN文件
终极指南:使用Jsxer快速解密Adobe JSXBIN文件 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer 你是否曾经遇到过以JSXBIN开头的Adobe脚本文件,想要查看或修改其内部逻辑却无从…...

VRCT终极指南:免费解锁VRChat多语言交流的神奇工具
VRCT终极指南:免费解锁VRChat多语言交流的神奇工具 【免费下载链接】VRCT VRCT(VRChat Chatbox Translator & Transcription) 项目地址: https://gitcode.com/gh_mirrors/vr/VRCT 你是否曾在VRChat中因为语言障碍而错失精彩对话?当你听到日语…...

UE4/UE5 Runtime FBX导入:从零到一构建高效动态模型加载方案
1. 为什么需要Runtime FBX导入? 在游戏开发中,动态加载3D模型是个常见需求。想象一下这样的场景:你的游戏允许玩家上传自定义角色模型,或者需要从服务器实时下载建筑模型。如果每次都要重启游戏才能加载新模型,用户体验…...
)
揭秘LLM代码生成落地困局:5类典型业务场景的个性化适配路径(含可复用决策树)
第一章:智能代码生成个性化适配策略 2026奇点智能技术大会(https://ml-summit.org) 智能代码生成已从通用模板输出迈向深度个性化适配阶段。开发者背景、项目约束、团队规范与运行时环境共同构成多维适配边界,单一模型输出无法满足真实工程场景的差异化…...