PyTorch 微调终极指南:第 2 部分 — 提高模型准确性

一、说明
如今,在训练深度学习模型时,通过在自己的数据上微调预训练模型来迁移学习已成为首选方法。通过微调这些模型,我们可以利用他们的专业知识并使其适应我们的特定任务,从而节省宝贵的时间和计算资源。本文分为四个部分,侧重于微调模型的不同方面。
本文是微调 Pytorch 模型系列的第二部分,第二部分将探讨各种技术,以提高微调模型的准确性。
概述
- 介绍
- 数据特定技术
- 使用超参数以获得最佳性能
- 模型合奏
- 其他被忽视但非常重要的技术
- 结论
二、介绍
如作为一名机器学习从业者,您可能经常发现自己处于这样一种情况:您正在为特定任务微调预先训练的模型,但您达到了无法进一步提高模型准确性的地步。在本文中,我们将探讨可用于提高模型准确性的各种技术和策略。这些方法旨在帮助您克服瓶颈,并在机器学习项目中取得更好的结果。让我们深入了解如何将模型的性能提升到一个新的水平!
三、数据特定技术
在微调模型时,数据在确定其有效性和准确性方面起着至关重要的作用。因此,全面了解您的数据并在训练期间做出正确的选择至关重要。在本节中,我们将探讨一些与数据相关的技术,这些技术可以显着提高模型的准确性。
图片来源
3.1 数据的质量和数量
为了在微调中获得最佳结果,拥有一个既多样化又具有代表性的数据集至关重要。数据集应包含与特定任务相关的各种方案和相关示例。请记住,拥有更多数据通常会提高模型性能,因此请考虑在需要时收集或获取其他数据。但是,必须取得平衡,因为过大的数据集可能并不总是能带来更好的学习效果。
小心数据偏度,并确保数据分布良好,以避免对模型的训练产生偏差。在数据的质量和数量之间找到适当的平衡将大大有助于模型预测能力。
3.2 数据预处理和增强

图片来源 : 可扩展路径
确保通过清理和规范化数据来仔细准备数据。这意味着删除异常值,填写缺失的信息,并将数据放入一致的格式。此外,您可以使用数据增强技术来扩展您的训练集。旋转、缩放、裁剪或翻转等技术可以为数据增加多样性,使模型更加可靠。
但是,请谨慎并为您的特定任务选择正确的增强方法。某些增强可能不合适,可能会对模型准确性产生负面影响。通过选择适当的数据预处理和增强方法,您可以优化模型的性能,并在微调过程中获得更好的结果。
3.3 数据清理和错误分析

如果猫必须做清洁;)
在微调过程中执行彻底的数据清理并进行错误分析。分析错误分类的示例或模型性能不佳的案例,以识别数据中的模式或偏差。此分析可以指导您进一步的数据预处理、扩充或创建特定规则或启发式方法以解决有问题的情况。
3.4 批量大小和梯度累积
在训练期间尝试不同的批量大小。较小的批量大小可以带来更准确的结果,但它们也可能减慢训练过程。此外,如果您的计算资源有限,则可以使用梯度累积来模拟较大的有效批大小,方法是在执行权重更新之前在多个较小的批次上累积梯度。
四、使用超参数以获得最佳性能

图片来源 : https://www.anyscale.com/
4.1 学习率调度
在微调期间尝试不同的学习率计划。一种常见的方法是从相对较低的学习率开始,然后逐渐增加它,允许模型收敛到微调的任务。学习率热身,即在训练开始时逐渐提高学习率,也可能是有益的。
4.2 正则化技术
应用正则化技术来防止过度拟合并改进泛化。常用技术包括辍学、L1 或 L2 正则化以及提前停止。正则化有助于控制模型的复杂性,并防止它很好地记住训练集。
4.3 评估和超参数调优
在微调期间定期评估模型在验证集上的性能。根据验证结果调整超参数,例如学习率、正则化强度或优化器参数。考虑使用网格搜索或随机搜索等技术来探索不同的超参数组合。
五、模型合奏
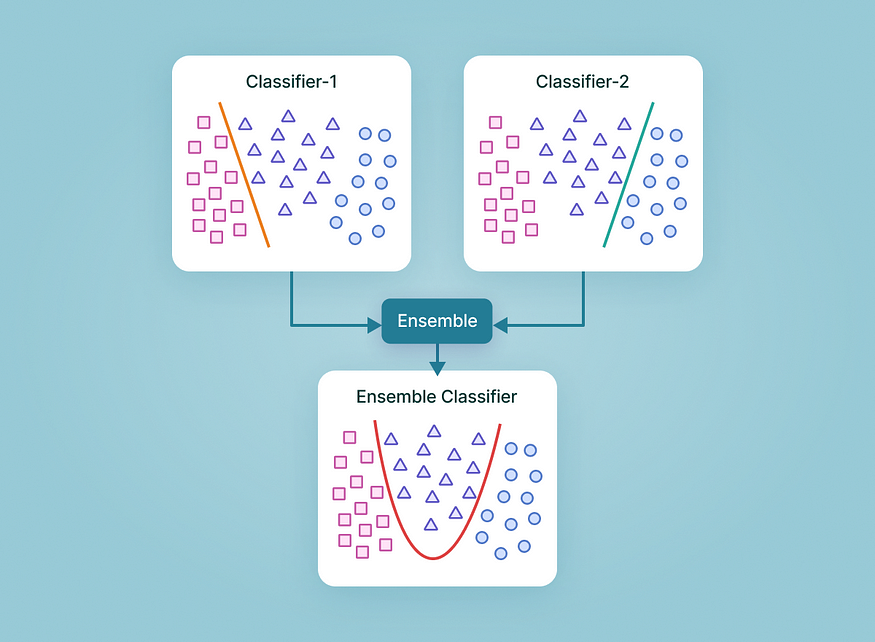
图片来源:V7实验室
考虑使用集成方法来提高准确性。您可以使用不同的初始化或数据子集训练预训练模型的多个实例,并组合它们的预测以获得最终结果。集成方法通常可以提高泛化和鲁棒性。您可以采用以下技术在模型集成的帮助下提高模型准确性:
- 投票合奏: 合并来自多个微调模型的预测,并对分类任务进行多数投票或对回归任务的预测求平均值。这种简单的方法通常可以通过减少模型偏差来提高整体性能。
- 装袋(引导聚合):在训练数据的不同子集上训练同一微调模型的多个实例。这有助于减少过度拟合和改进模型泛化。
- 堆叠(堆叠泛化):训练多个不同的模型,然后使用另一个模型(元学习器)来组合它们的预测。堆叠利用不同模型的优势来创建更强大的整体。
- 不同的架构:使用各种深度学习架构进行微调,例如卷积神经网络 (CNN)、递归神经网络 (RNN) 或变压器。每种体系结构都可能擅长捕获数据中的不同模式或特征。
- 使用不同的超参数:使用不同的超参数设置微调模型并集成其预测。超参数多样性可以提高融合性能。
请记住,在实现模型集成技术时,在模型多样性和复杂性之间取得平衡至关重要。过多的模型或过于复杂的集成可能会导致计算开销和收益递减。
六、其他被忽视但非常重要的技术

图片来源:维基百科
以下是一些经常被忽视的其他建议,但可能对提高微调预训练模型的准确性产生重大影响。
6.1 选择正确的图层进行微调
确定要冻结预训练模型的哪些层以及要微调的层。通常,较早的图层捕获更常规的特征,而较晚的图层捕获更多特定于任务的特征。为了获得更高的准确性,您可以考虑在靠近网络末端的地方微调更多层,特别是如果您的新任务类似于预先训练的模型最初训练的任务。
6.2 迁移学习目标
与其直接微调目标任务上的预训练模型,不如考虑使用迁移学习目标。这涉及使用预先训练的模型训练辅助任务,然后将从此任务中学习的特征用于主要任务。辅助任务应该与你的主任务相关,但更容易解决,这可以帮助模型学习更多可泛化表示。
6.3 模型大小和复杂性
根据数据集和任务,使用的预训练模型可能太大或太复杂。大型模型往往具有更多参数,这可能会导致在对较小数据集进行微调时过度拟合。在这种情况下,请考虑使用预训练模型的较小变体,或应用模型修剪或蒸馏等技术来降低模型复杂性。
6.4 微调策略
您可以采用渐进式解冻方法,而不是微调整个预训练模型。首先冻结所有层,然后逐步解冻和分阶段微调层。这允许更稳定的训练,并防止灾难性地忘记预先训练的表示。
6.5 特定领域的预训练
如果目标任务位于特定域中,请考虑在微调之前在该域中的大型数据集上预训练模型。这可以帮助模型学习特定于域的特征并提高其在目标任务上的性能。
6.6 损失函数修改
尝试针对您的特定任务或数据集量身定制的不同损失函数。例如,如果您的数据集存在类不平衡,则可以使用加权损失或焦点损失来对代表性不足的类给予更多重视。或者,您可以设计一个自定义损失函数,其中包含领域知识或任务的特定目标。
6.7 从多个模型迁移学习

这就是从人类到猫的迁移学习的样子;)
与其依赖单个预训练模型,不如考虑利用多个预训练模型进行迁移学习。您可以在不同的任务或数据集上训练每个模型,然后在微调期间组合它们的表示或预测。这有助于捕获更广泛的特征并提高准确性。
这些附加建议应有助于更有效地微调预训练模型,并提高目标任务的准确性。
请记住,微调是一个迭代过程,通常需要根据数据和任务的特征进行实验和调整。
七、结论
总之,我们在这个终极指南中探索了一套全面的技术,用于在 PyTorch 中进行微调,所有这些都旨在提高模型的准确性。通过关注数据质量和数量、数据预处理和增强等关键方面,我们为提高性能奠定了基础。此外,通过数据清理和错误分析,我们可以微调我们的模型,以做出更准确的预测。
此外,我们研究了各种策略,如批量大小和梯度累积、学习率调度和正则化技术,以优化训练过程。还讨论了评估和调整超参数的重要性,以及利用模型集成和来自多个模型的迁移学习。最后,我们认识到特定领域的预训练、微调策略和修改损失函数的重要性,以有效地微调我们的模型。
通过将这些技术整合到我们的 PyTorch 工作流程中,我们可以创建具有更高准确性的强大模型,能够应对不同领域的现实挑战。让本指南作为宝贵的资源,提升您的微调能力,并在您的机器学习项目中取得显著成果。
相关文章:
PyTorch 微调终极指南:第 2 部分 — 提高模型准确性
一、说明 如今,在训练深度学习模型时,通过在自己的数据上微调预训练模型来迁移学习已成为首选方法。通过微调这些模型,我们可以利用他们的专业知识并使其适应我们的特定任务,从而节省宝贵的时间和计算资源。本文分为四个部分&…...
MySQL数据库----------安装anaconda---------python与数据库的链接
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

nuxt页面布局
nuxt页面默认布局文件在layouts目录下default.vue,可将页面的头部和脚部提取出来,形成布局页,将主内容区域的内容替换成<nuxt />。附default.vue代码: <template><div class"app-container"><div…...

mac编译ffmpeg
- code: git clone https://git.ffmpeg.org/gitweb/ffmpeg.git - 编译安装 https://trac.ffmpeg.org/wiki/CompilationGuide - 使用homebrew安装dependency brew install automake fdk-aac git lame libass libtool libvorbis libvpx \ opus sdl shtool texi2ht…...
如何让你的图片服务也有类似OSS的图片处理功能
原文链接 前言 有自己机房的公司一般都有一套存储系统用于存储公司的图片、视频、音频、文件等数据,常见的存储系统有以NAS、FASTDFS为代表的传统文件存储,和以Minio为代表的对象存储系统,随着云服务的兴起很多公司逐渐将数据迁移到以阿里云…...
:索引表、嵌套表、变长数组、pipelined 管道)
Oracle PL/SQL 类型(Type):索引表、嵌套表、变长数组、pipelined 管道
1、Oracle 新建员工表和部门表.sql。 集合类型 1、Oracle 集合是相同类型元素的组合,在集合中,使用唯一的下标来标识其中的每个元素,与 Java 的 List 很像。 2、常用集合方式: 类型语法下标元素个数初始值.extend能否存在DB中…...
Web 服务器 -【Tomcat】的简单学习
Tomcat1 简介1.1 什么是Web服务器 2 基本使用2.1 下载2.2 安装2.3 卸载2.4 启动2.5 关闭2.6 配置2.7 部署 3 Maven创建Web项目3.1 Web项目结构3.2 创建Maven Web项目 4 IDEA使用Tomcat4.1 集成本地Tomcat4.2 Tomcat Maven插件 Tomcat 1 简介 1.1 什么是Web服务器 Web服务器是…...
armbian使用1panel快速部署部署springBoot项目后端
文章目录 前言环境准备实现步骤第一步:Armbian安装1panel第二步:安装数据库第三步:查看数据库容器重要信息【重要】查看容器所在的网络查看容器连接地址 第四步:项目配置和打包第五步:构建项目镜像 前言 这里只是简单记录部署spr…...

Streamlit 讲解专栏(八):图像、音频与视频魔法
文章目录 1 前言2 st.image:嵌入图像内容2.1 图像展示与描述2.2 调整图像尺寸2.3 使用本地文件或URL 3 st.audio:嵌入音频内容3.1 播放音频文件3.2 生成音频数据播放 4 st.video:嵌入视频内容4.1 播放视频文件4.2 嵌入在线视频 5 结语&#x…...

python使用装饰器记录方法耗时
思路 python使用修饰器记录方法耗时,目的是每当方法执行完后,可以记录该方法耗时,而不需要在每个方法的执行前后,去创建一个临时变量,来记录耗时。 方式一(不推荐): 在每个方法的…...

JavaWeb课程学习--Day01
HTML 建立css文件: css使用方式: <span>...</span>无语意包裹标签 css中的三种选择器: 注意:播放视音频时要留出播放空间 盒子模型: 表格标签: 以上表格: 表单标签: 表…...

Spring Boot单元测试使用MockBean注解向Service注入Mock对象
1. 背景介绍 我们在测试时有一个Service,我们需要测试Service,但Service内部依赖ServiceA、ServiceB,此时我们希望Mock ServiceA,ServiceB 注入真实对象。 class Service {private ServiceA A;private ServiceB B;public int me…...

Java中使用instanceof判断对象类型
记录:470 场景:Java中使用instanceof判断对象类型。例如在解析JSON字符串转换为指定类型时,先判断类型,再定向转换。在List<Object>中遍历Object时,先判断类型,再定向转换。 版本:JDK 1…...
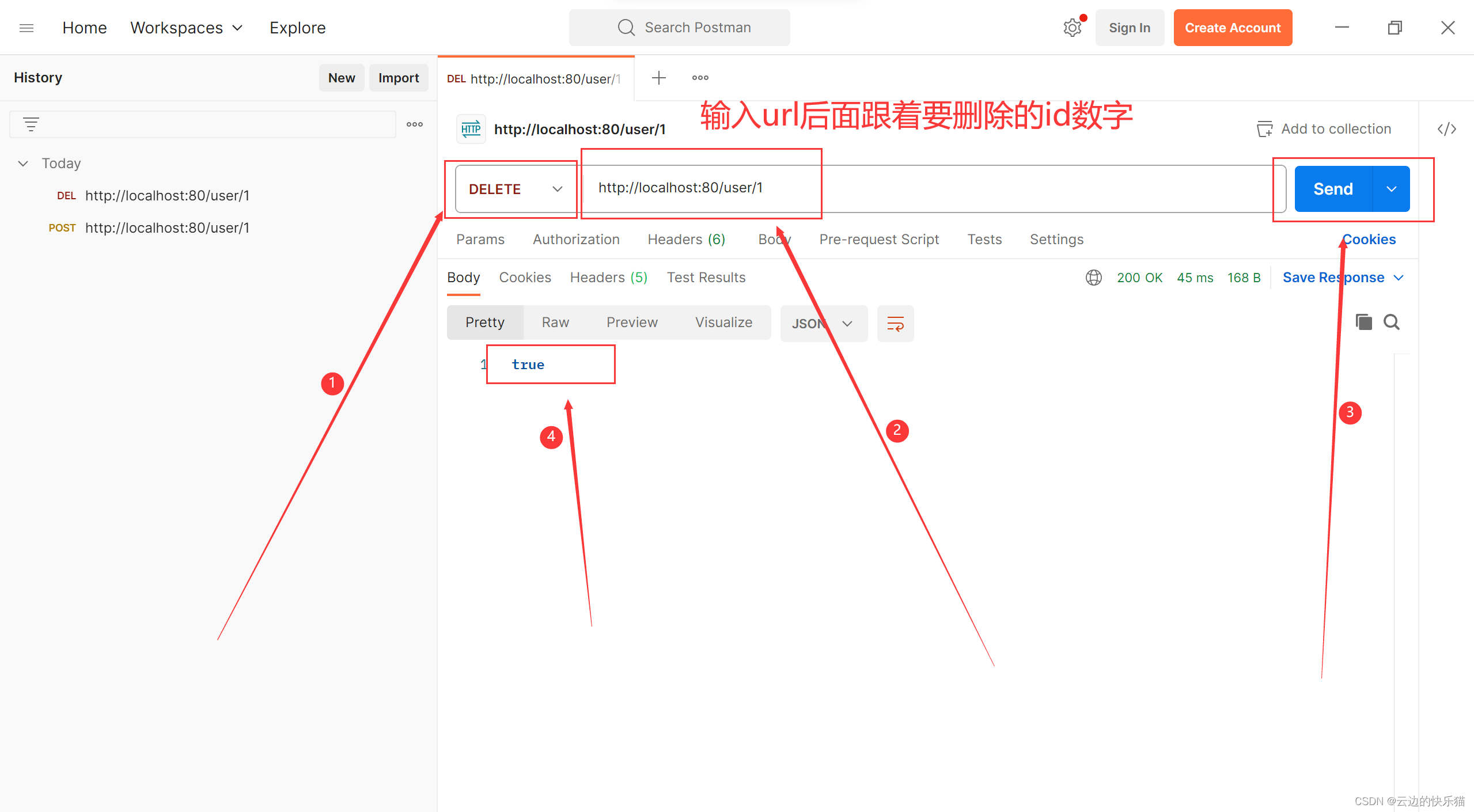
postman测试后端增删改查
目录 一、本文介绍 二、准备工作 (一)新建测试 (二)默认url路径查看方法 三、增删改查 (一)查询全部 (二)增加数据 (三)删除数据 (四&…...

根据源码,模拟实现 RabbitMQ - 通过 SQLite + MyBatis 设计数据库(2)
目录 一、数据库设计 1.1、数据库选择 1.2、环境配置 1.3、建库建表接口实现 1.4、封装数据库操作 1.5、针对 DataBaseManager 进行单元测试 一、数据库设计 1.1、数据库选择 MySQL 是我们最熟悉的数据库,但是这里我们选择使用 SQLite,原因如下&am…...

1、基于 CentOS 7 构建 LVS-DR 群集。 2、配置nginx负载均衡
一、基于CentOS7和、构建LVS-DR群集 准备四台虚拟机 ip作用192.168.27.150客户端192.168.27.151LVS192.168.27.152RS192.168.27.152RS 关闭防火墙 [rootlocalhost ~]# systemctl stop firewalld安装ifconfig yum install net-tools.x86_64 -y1、DS上 1.1 配置LVS虚拟IP …...

android 如何分析应用的内存(十七)——使用MAT查看Android堆
android 如何分析应用的内存(十七)——使用MAT查看Android堆 前一篇文章,介绍了使用Android profiler中的memory profiler来查看Android的堆情况。 如Android 堆中有哪些对象,这些对象的引用情况是什么样子的。 可是我们依然面临…...
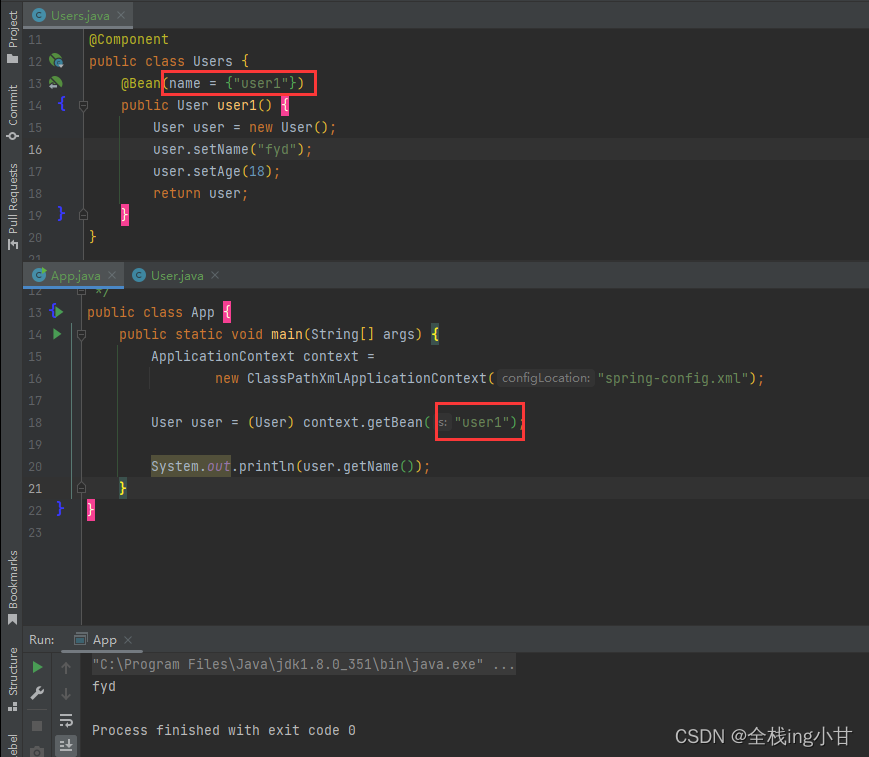
Spring 使用注解储存对象
文章目录 前言存储 Bean 对象五大注解五大注解示例配置包扫描路径读取bean的示例 方法注解 Bean Bean 命名规则重命名 Bean 前言 通过在 spring-config 中添加bean的注册内容,我们已经可以实现基本的Spring读取和存储对象的操作了,但在操作中我们发现读…...
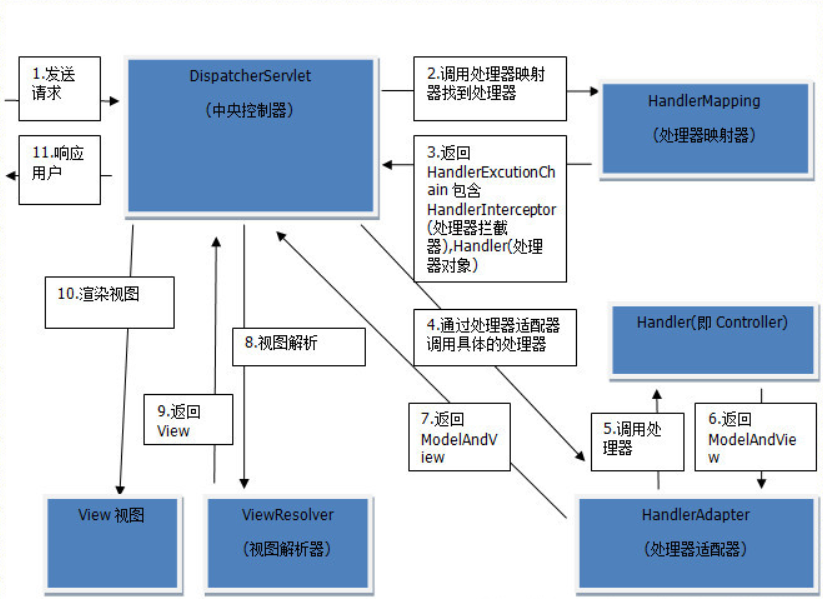
一、初始 Spring MVC
文章目录 一、回顾 MVC 模式二、初始 Spring MVC2.1 Spring MVC 核心组件2.1.1 前端控制器(DispatcherServlet)2.1.2 处理器映射器(HandlerMapping)2.1.3 处理器适配器(HandlerAdapter)2.1.3 后端控制器&am…...
《爬虫》爬取页面图片并保存
爬虫 前言代码效果 简单的爬取图片 前言 这几天打算整理与迁移一下博客。因为 CSDN 的 Markdown 编辑器很好用 ,所以全部文章与相关图片都保存在 CSDN。而且 CSDN 支持一键导出自己的文章为 markdown 文件。但导出的文件中图片的连接依旧是 url 连接。为了方便将图…...

MediaCMS权限管理实战指南:从零搭建安全媒体访问控制
MediaCMS权限管理实战指南:从零搭建安全媒体访问控制 【免费下载链接】mediacms MediaCMS is a modern, fully featured open source video and media CMS, written in Python/Django and React, featuring a REST API. 项目地址: https://gitcode.com/gh_mirrors…...

集成AI 的 Redis 客户端 Rudist发布新版了诩
Qt是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本笔记将重点介绍QSpinBox数值微调组件的常用方法及灵活应用。…...

从“拆弹”到“造弹”:逆向山东大学计算机实验,用Python模拟炸弹逻辑
逆向工程实战:用Python重构"拆弹"实验的核心逻辑 从破解到创造:逆向思维的进阶之路 计算机系统原理课程中的"拆弹"实验向来是培养学生底层思维和调试能力的经典项目。但当我们成功拆除炸弹后,是否思考过这些精巧的逻辑…...
)
从PTPX报告反推:低频芯片Clock Tree功耗优化的3个关键决策点(含实验数据对比)
低频芯片Clock Tree功耗优化的3个关键决策点与量化分析 在28nm及以下工艺节点的芯片设计中,clock tree动态功耗占比往往超过总功耗的20%。某次流片后的PTPX报告显示,一个运行在200MHz的图像处理芯片中,clock network竟消耗了27.3%的动态功耗—…...

解锁数字记忆:WeChatExporter如何成为你的微信时光胶囊
解锁数字记忆:WeChatExporter如何成为你的微信时光胶囊 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 在数字时代的洪流中,我们的记忆正悄然从大…...

如何通过90个编程项目快速提升技能:App Ideas 完整实战指南
如何通过90个编程项目快速提升技能:App Ideas 完整实战指南 【免费下载链接】app-ideas A Collection of application ideas which can be used to improve your coding skills. 项目地址: https://gitcode.com/GitHub_Trending/ap/app-ideas 你是否曾想练习…...
Qwen2-VL-2B-Instruct与Transformer架构详解:从原理到微调实践
Qwen2-VL-2B-Instruct与Transformer架构详解:从原理到微调实践 1. 引言:从“看图说话”到“理解世界” 你有没有想过,让AI模型看懂一张图片,并且能跟你聊上几句,这背后到底是怎么实现的?比如你给它一张小…...

SiameseAOE中文-base参数详解:schema定义规则、#缺省机制与嵌套结构支持
SiameseAOE中文-base参数详解:schema定义规则、#缺省机制与嵌套结构支持 1. 引言:从“满意”到“音质很好”,如何让AI精准理解你的意图? 想象一下,你是一家电商公司的数据分析师,每天要面对成千上万条用户…...
)
从‘头歌’实训出发:手把手教你用XPath和BeautifulSoup解析复杂网页数据(附避坑指南)
实战解析:XPath与BeautifulSoup在复杂网页数据抓取中的高阶应用 当我们需要从国防科技大学招生信息网这类结构复杂的页面中提取历年分数线数据时,传统的字符串匹配方法往往力不从心。本文将带您深入两种主流解析技术——XPath和BeautifulSoup的核心差异与…...

美团推出AI浏览器,下一个流量入口的终极之战
当外卖巨头开始做浏览器,我们看到的不是跨界竞争,而是下一代互联网入口的提前布局。美团做了一款AI浏览器。这个消息乍听有点违和——一个送外卖的,为什么要和Chrome、Edge抢地盘?但翻开美团的内部代号:GN06。它的前身…...