用神经网络玩转数据聚类:自编码器的原理与实践
目录
- 引言
- 一、什么是自编码器
- 二、自编码器的应用场景
- 三、自编码器的优缺点
- 四、如何实现基于自编码器的聚类算法
- 五、总结
引言
随着数据量的爆炸性增长,如何有效地处理和分析数据成为了一个重要的问题。数据聚类是一种常用的数据分析方法,它可以将数据集划分为若干个相似的子集,称为聚类。聚类算法的目标是使同一聚类内的数据点尽可能相似,不同聚类间的数据点尽可能不同。聚类算法可以用于数据挖掘、图像分割、社交网络分析、推荐系统等领域。
然而,传统的聚类算法通常需要人为地指定聚类数目、距离度量、初始聚类中心等参数,而且对高维、非线性、复杂的数据表现不佳。为了解决这些问题,一种基于自编码器的聚类算法被提出。自编码器是一种神经网络模型,它可以学习输入数据的低维表示,也称为隐层特征或编码。自编码器由两部分组成:编码器和解码器。编码器将输入数据映射到隐层特征,解码器将隐层特征重构为输入数据,使其尽可能接近原始数据。
基于自编码器的聚类算法的思想是利用自编码器学习到的隐层特征作为数据点的新表示,然后在这个新表示空间上进行聚类。这样可以实现数据降维、去噪、非线性变换等功能,从而提高聚类效果和质量。
本文将介绍自编码器的原理、特点、应用场景和相关资源,并使用matlab来实现一个简单的基于自编码器的聚类算法,并对鸢尾花数据集进行了实验。本文旨在帮助读者理解和掌握自编码器的基本概念和用法。
一、什么是自编码器
自编码器是一种无监督学习模型,它可以学习输入数据 x 的低维表示 f(x),也称为隐层特征或编码。自编码器由两部分组成:编码器和解码器。编码器将输入数据 x 映射到隐层特征 f(x),解码器将隐层特征 f(x) 重构为输入数据 r,使其尽可能接近原始数据 x。
自编码器的核心公式是:

其中,x是输入数据,f是编码器函数,g是解码器函数,r是重构数据。自编码器的目标是使r尽可能接近x,同时让f(x)具有一些有用的属性。
自编码器可以用于聚类分析,即将数据集划分为若干个相似的子集,称为聚类。聚类算法的目标是使同一聚类内的数据点尽可能相似,不同聚类间的数据点尽可能不同。基于自编码器的聚类算法的思想是利用自编码器学习到的隐层特征作为数据点的新表示,然后在这个新表示空间上进行聚类。
二、自编码器的应用场景
自编码器的应用场景有很多,例如:
- 数据降维:自编码器可以将高维的数据压缩到低维的潜在空间,从而实现数据的可视化、存储、分析等。
- 数据去噪:自编码器可以对输入数据添加一些噪声,然后训练自己去除噪声,从而提高数据的质量和鲁棒性。
- 数据生成:自编码器可以从潜在空间中采样一些随机向量,然后通过解码器生成新的数据,从而实现数据的增强、填充、创造等。
三、自编码器的优缺点
基于自编码器的聚类算法的优点是:
- 它可以自动地学习数据的低维表示,而不需要人为地指定特征提取或降维方法。
- 它可以同时考虑数据的重构质量和聚类质量,而不需要分别进行自编码器训练和聚类分析。
- 它可以适应不同类型和结构的数据,而不需要假设数据服从某种特定的分布或模型。
基于自编码器的聚类算法的缺点是:
- 它需要调整多个参数,比如隐层特征维度、正则化参数、损失函数等,这些参数可能会影响算法的性能和稳定性。
- 它需要进行迭代优化,比如使用梯度下降法或期望最大化(EM)算法等,这些优化方法可能会陷入局部最优或者收敛缓慢。
- 它需要预先指定聚类数目,这个数目可能不容易确定或者与真实情况不一致。
四、如何实现基于自编码器的聚类算法
下面我们使用matlab来实现一个简单的基于自编码器的聚类算法,步骤如下:
1)导入数据集
我们使用matlab自带的鸢尾花数据集(iris),它包含了150个样本,每个样本有4个特征和1个类别标签。我们只使用特征作为输入数据,不使用类别标签。
2)构建自编码器
我们使用matlab的深度学习工具箱(Deep Learning Toolbox)提供的函数来构建一个简单的全连接自编码器。我们设置隐层特征维度为2,激活函数为sigmoid,损失函数为均方误差(MSE),优化算法为随机梯度下降(SGD)。
3)训练自编码器
我们使用matlab的训练函数来训练自编码器,设置迭代次数为100,批量大小为10,学习率为0.01。
4)提取隐层特征
我们使用matlab的预测函数来计算输入数据在自编码器的隐层特征。
5)进行聚类
我们使用matlab的统计与机器学习工具箱(Statistics and Machine Learning Toolbox)提供的函数来进行k-means聚类。我们设置聚类数目为3,距离度量为欧氏距离(Euclidean distance),初始聚类中心为随机选择。
6)可视化结果
我们使用matlab的绘图函数来可视化输入数据和隐层特征在二维平面上的分布,并用不同颜色表示不同聚类。
以下是matlab代码及注释:
% 导入数据集
load fisheriris % 加载鸢尾花数据集
X = meas; % 获取输入数据
% 构建自编码器
hiddenSize = 2; % 设置隐层特征维度
autoenc = feedforwardnet(hiddenSize); % 创建一个全连接网络
autoenc.inputs{1}.processFcns = {}; % 取消输入预处理
autoenc.outputs{2}.processFcns = {}; % 取消输出后处理
autoenc.layers{1}.transferFcn = 'logsig'; % 设置激活函数为sigmoid
autoenc.trainFcn = 'trainscg'; % 设置优化算法为SGD
autoenc.performFcn = 'mse'; % 设置损失函数为MSE
% 训练自编码器
maxEpochs = 100; % 设置迭代次数
miniBatchSize = 10; % 设置批量大小
options = trainingOptions('sgdm', ... % 设置训练选项'MaxEpochs',maxEpochs, ...'MiniBatchSize',miniBatchSize, ...'Plots','training-progress', ...'Verbose',false);
autoenc = train(autoenc,X,options); % 训练自编码器
% 提取隐层特征
features = predict(autoenc,X); % 计算隐层特征
% 进行聚类
k = 3; % 设置聚类数目
[idx,C] = kmeans(features,k); % 进行k-means聚类
% 可视化结果
subplot(1,2,1) % 创建一个1行2列的子图,选择第1个
gscatter(X(:,1),X(:,2),idx) % 绘制输入数据的第1和第2个特征,用不同颜色表示不同聚类
title('Input Data') % 设置标题
xlabel('Sepal Length') % 设置x轴标签
ylabel('Sepal Width') % 设置y轴标签
subplot(1,2,2) % 选择第2个子图
gscatter(features(:,1),features(:,2),idx) % 绘制隐层特征的第1和第2个维度,用不同颜色表示不同聚类
title('Hidden Features') % 设置标题
xlabel('Feature 1') % 设置x轴标签
ylabel('Feature 2') % 设置y轴标签
五、总结
本文介绍了如何使用matlab来实现一个简单的基于自编码器的聚类算法,并对鸢尾花数据集进行了实验。本文还介绍了自编码器的原理、特点、应用场景和相关资源。本文旨在帮助读者理解和掌握自编码器的基本概念和用法。
基于自编码器的聚类算法是一种结合了自编码器和聚类算法的方法,它可以利用自编码器学习到的隐层特征作为数据点的新表示,然后在这个新表示空间上进行聚类。这样可以实现数据降维、去噪、非线性变换等功能,从而提高聚类效果和质量。基于自编码器的聚类算法有着广泛的应用前景,但也存在一些挑战和局限性,需要进一步的研究和改进。希望对来访读者有所帮助~
相关文章:
用神经网络玩转数据聚类:自编码器的原理与实践
目录 引言一、什么是自编码器二、自编码器的应用场景三、自编码器的优缺点四、如何实现基于自编码器的聚类算法五、总结 引言 随着数据量的爆炸性增长,如何有效地处理和分析数据成为了一个重要的问题。数据聚类是一种常用的数据分析方法,它可以将数据集…...

Linux系统调试课:Linux Kernel Printk
🚀返回专栏总目录 文章目录 0、printk 说明1、printk 日志等级设置2、屏蔽等级日志控制机制3、printk打印常用方式4、printk打印格式0、printk 说明 在开发Linux device Driver或者跟踪调试内核行为的时候经常要通过Log API来trace整个过程,Kernel API printk()是整个Kern…...
不同版本Idea部署Maven和Tomcat教学
目录 一、2019版Idea 1.1. Maven配置 1.2. Tomcat配置 二、2023版Idea 2.1 Maven配置 2.2. Tomcat配置 一、2019版Idea 1.1. Maven配置 在这篇 http://t.csdn.cn/oetKq 我已经详细讲述了Maven的下载安装及配置,本篇就直接开始实操 : 1. 首先进入设置搜索Mave…...

Vue 3.0中的Treeshaking?
1.treeshaking是什么? Tree shaking 是一种通过清除多余代码方式来优化项目打包体积的技术,专业术语叫 Dead code elimination 简单来讲,就是在保持代码运行结果不变的前提下,去除无用的代码 如果把代码打包比作制作蛋糕&#…...
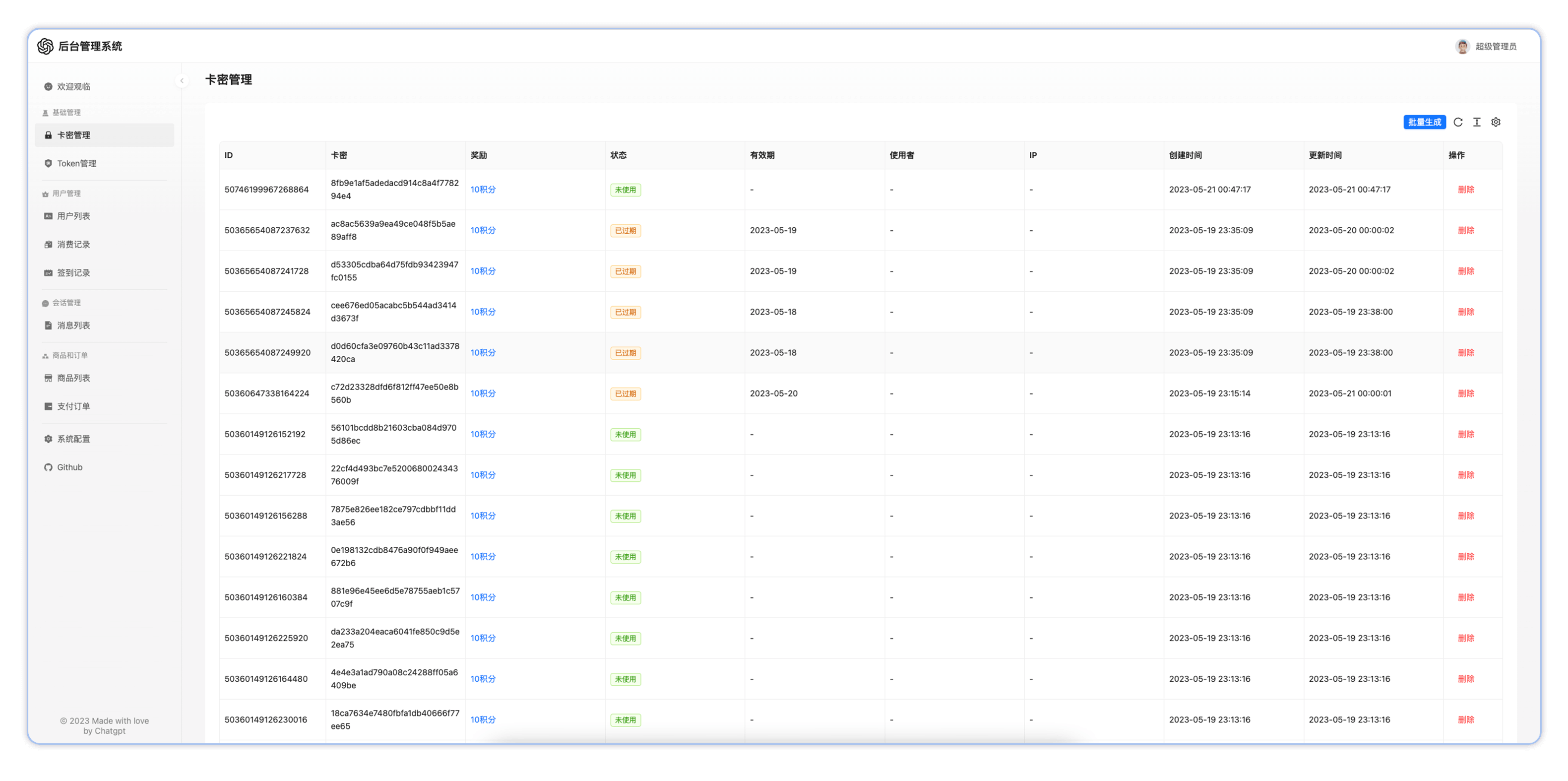
开源可商业运营的ChatGpt网页源码v1.2.2
🤖 主要功能 后台管理系统,可对用户,Token,商品,卡密等进行管理 精心设计的 UI,响应式设计 极快的首屏加载速度(~100kb) 支持Midjourney绘画和DALLE模型绘画,GPT4等应用 海量的内置 prompt 列表,来自中文和英文 一键导…...

驱动阿托斯DLHZO-T伺服比例阀放大器定制
DLHZO-T型伺服比例换向阀,直动式,带LVDT位置传感器和阀芯零遮盖,可应用于各种位置闭环控制实现最佳的性能。 比例阀和模块式数字放大器配合使用。 LVDT传感器和阀套结构可确保非常高的调节精度和响应灵敏度。 失电保护位可实现在电源中断的…...
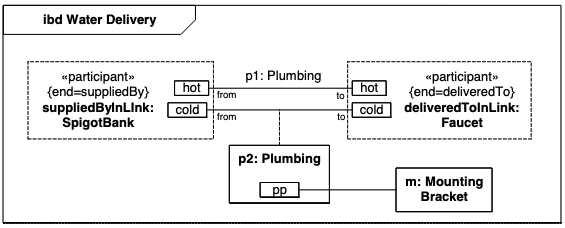
SysML V1.2 Blocks
本人看的实在是太枯燥了,很多都是机翻过了一遍 后面复习的时候,我再用chatgpt润色一下 一、综述 块是系统描述的模块化单元。每个块定义了一组特征来描述系统或其他感兴趣的元素。这些可能包括结构和行为特征,例如属性和操作,以…...

反编译微信小程序,可导出uniapp或taro项目
微信小程序反编译(全网通用) 微信小程序反编译 反编译主要分为四个阶段 操作流程 1. node.js安装 2. node安装模块 3. 开始反编译 4. 导入到微信开发者工具既可运行 微信小程序反编译 当碰到不会写的小程序功能时,正好看到隔壁小程序有类似…...
鉴源实验室丨汽车网络安全攻击实例解析(二)
作者 | 田铮 上海控安可信软件创新研究院项目经理 来源 | 鉴源实验室 社群 | 添加微信号“TICPShanghai”加入“上海控安51fusa安全社区” 引言:汽车信息安全事件频发使得汽车行业安全态势愈发紧张。这些汽车网络安全攻击事件,轻则给企业产品发布及产品…...
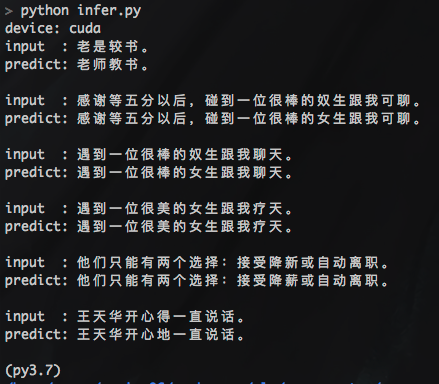
pycorrector一键式文本纠错工具,整合了BERT、MacBERT、ELECTRA、ERNIE等多种模型,让您立即享受纠错的便利和效果
pycorrector:一键式文本纠错工具,整合了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer、T5等多种模型,让您立即享受纠错的便利和效果 pycorrector: 中文文本纠错工具。支持中文音似、形似、语法错误纠正,pytho…...

Linux 日志管理
Linux 日志管理 一.Linux 下的日志服务简介 1.1 CentOS5 之前的版本 centos5 之前的版本使用系统和内核日志分离的格式记录日志 syslogd:该服务专门用于记录系统日志(system application logs) klogd: 该服务专门用于记录内核日志(linux kernel logs) centos5 之前事件的记录格…...

统计学补充概念04-最大似然估计
概念 最大似然估计(Maximum Likelihood Estimation,简称MLE)是一种统计方法,用于估计模型的参数,使得给定观测数据的似然函数达到最大。在最大似然估计中,我们寻找能够最大化观测数据的可能性(…...
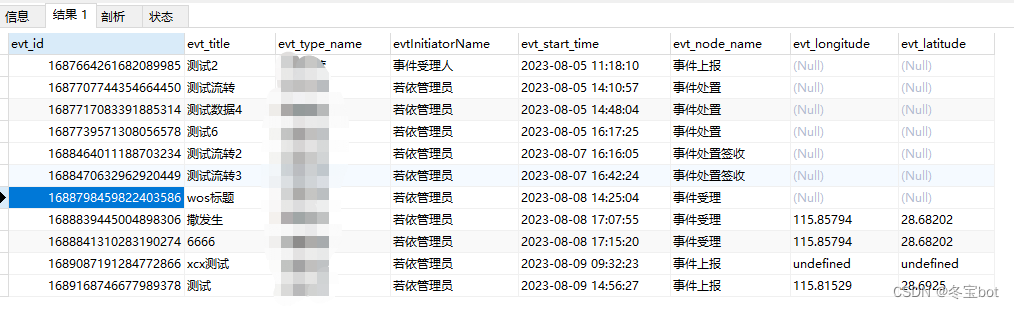
mysql一些统计实用函数
文章目录 一对多,多的一端只查询最新数据YEAR 年份函数MONTH 月份函数QUARTER 季度函数往前递推十年往后递推十年查询去年12月份统计身份证户籍所在地人数 一对多,多的一端只查询最新数据 ROW_NUMBER() over(PARTITION BY evt_id ORDER BY evt_node_rec…...

IC设计仿真云架构
对于IC仿真来说,最重要的是要安全、可维护、高性能的的HPC环境环境。 那么云上如何搭建起一套完整的IC仿真云环境呢? 这种架构应该长什么样子? 桌面虚拟化基础架构 将所有桌面虚拟机在数据中心进行托管并统一管理;同时用户能够…...

日常BUG ——乱码
😜作 者:是江迪呀✒️本文关键词:日常BUG、BUG、问题分析☀️每日 一言 :存在错误说明你在进步! 一、问题描述 A系统使用Feign调用B系统时,传递的String字符串,到了B系统中变为了乱…...
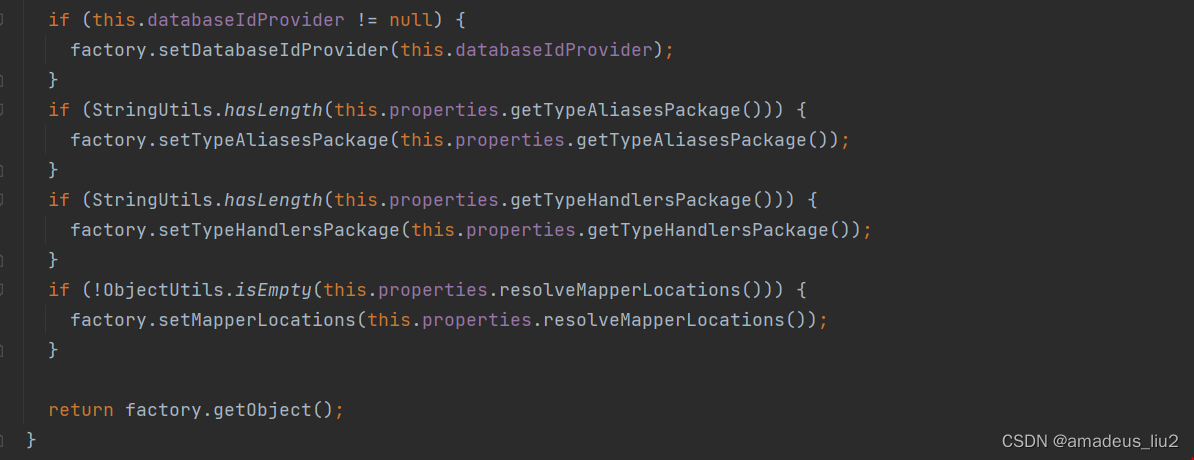
SpringBoot复习:(44)MyBatisAutoConfiguration
可以看到MyBatisAutoConfiguration引入了MyBatisProperties这个属性: MyBatisAutoConfiguration中配置了一个SqlSessionFactoryBean,代码如下: 可以配置mybatis-config.xml,需要配置文件里指定: mybatis.config-locationclasspath:/mybat…...

SpringBoot校验,DTO文件中常用的注解应用案例.
在观看本篇文章之前,可以先参考我之前写的一篇文章 “ Spring5,Service层对DTO文件进行数据格式校验. ” ,这篇文章是介绍在 Service层 对DTO文件的校验。 以下方的 CompanyDTO 文件为例,讲解不同的注解使用场景,以及…...

Qt 窗口随鼠标移动效果
实现在窗口任意位置按下鼠标左键都可以移动窗口的效果,完整代码如下: mainwindow.h: #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QMouseEvent>QT_BEGIN_NAMESPACE namespace Ui { class MainW…...

大数据Flink(五十九):Flink on Yarn的三种部署方式介绍以及注意
文章目录 Flink on Yarn的三种部署方式介绍以及注意 一、Pre-Job 模式部署作业...
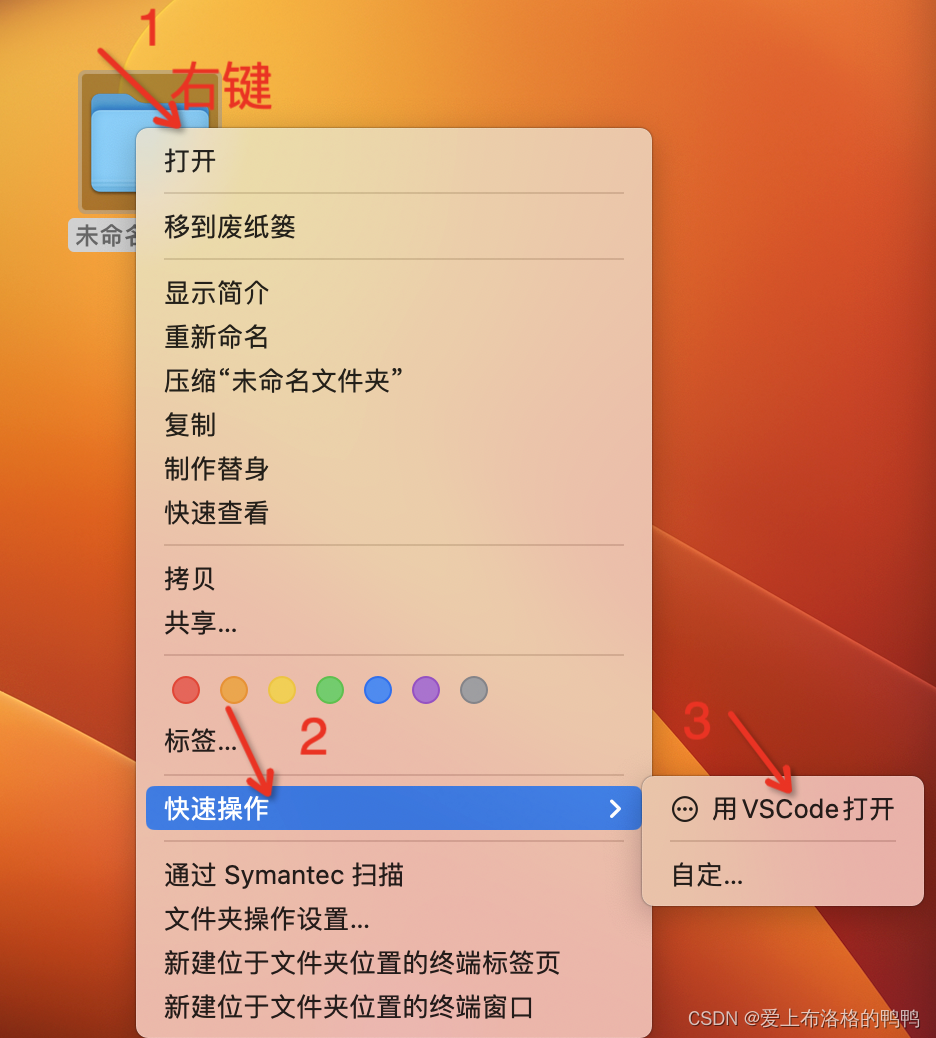
mac-右键-用VSCode打开
1.点击访达,搜索自动操作 2.选择快速操作 3.执行shell脚本 替换代码如下: for f in "$" doopen -a "Visual Studio Code" "$f" donecommand s保存会出现一个弹框,保存为“用VSCode打开” 5.使用...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

【DeepSeek集成测试黄金标准】:20年专家亲授5大避坑指南与自动化落地框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试黄金标准的演进与核心价值 集成测试在大语言模型工程化落地过程中已从“验证功能可用”跃迁为“保障推理一致性、上下文鲁棒性与安全边界的三位一体质量门禁”。DeepSeek系列模型&…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...

实战教程:5步构建基于YOLOv5的FPS游戏智能瞄准系统
实战教程:5步构建基于YOLOv5的FPS游戏智能瞄准系统 【免费下载链接】FPSAutomaticAiming 基于yolov5的FPS游戏AI。 项目地址: https://gitcode.com/gh_mirrors/fp/FPSAutomaticAiming FPSAutomaticAiming是一个基于YOLOv5深度学习算法的FPS游戏自动瞄准系统&…...

ThriftPy性能测试与基准对比:Cython加速效果分析
ThriftPy性能测试与基准对比:Cython加速效果分析 【免费下载链接】thriftpy Thriftpy has been deprecated, please migrate to https://github.com/Thriftpy/thriftpy2 项目地址: https://gitcode.com/gh_mirrors/th/thriftpy ThriftPy是一款高效的Python T…...

PyKafka社区贡献指南:从问题报告到代码提交的完整流程
PyKafka社区贡献指南:从问题报告到代码提交的完整流程 【免费下载链接】pykafka Apache Kafka client for Python; high-level & low-level consumer/producer, with great performance. 项目地址: https://gitcode.com/gh_mirrors/py/pykafka 想要为PyK…...