pycorrector一键式文本纠错工具,整合了BERT、MacBERT、ELECTRA、ERNIE等多种模型,让您立即享受纠错的便利和效果
pycorrector:一键式文本纠错工具,整合了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer、T5等多种模型,让您立即享受纠错的便利和效果

pycorrector: 中文文本纠错工具。支持中文音似、形似、语法错误纠正,python3开发。实现了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer等多种模型的文本纠错,并在SigHAN数据集评估各模型的效果。
1.中文文本纠错任务,常见错误类型:
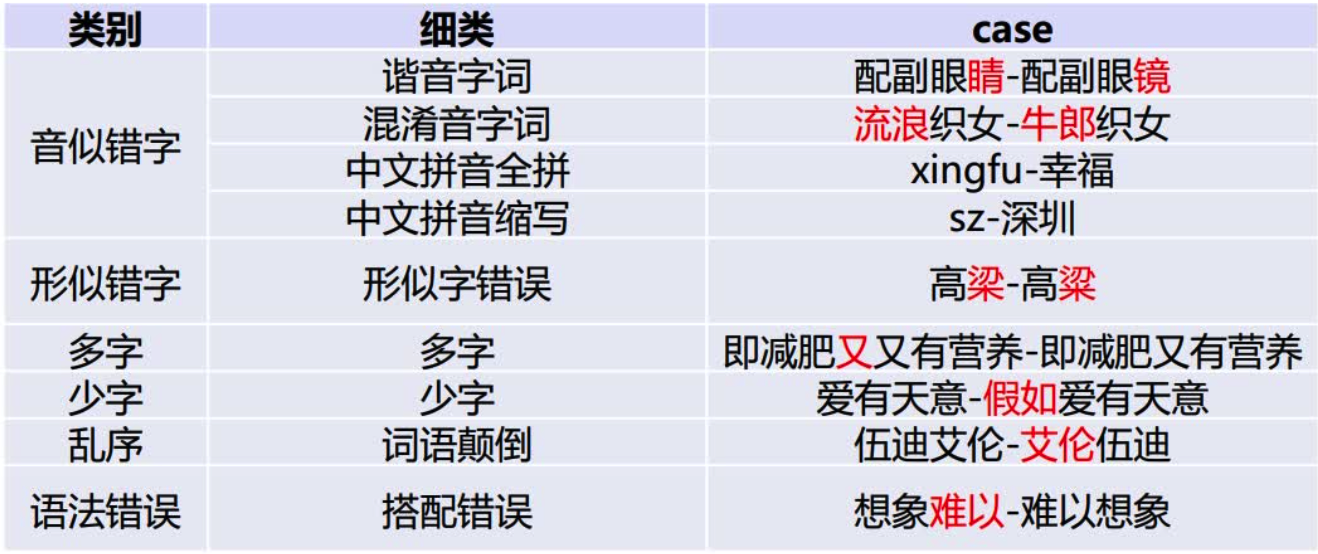
当然,针对不同业务场景,这些问题并不一定全部存在,比如拼音输入法、语音识别校对关注音似错误;五笔输入法、OCR校对关注形似错误,
搜索引擎query纠错关注所有错误类型。
本项目重点解决其中的"音似、形字、语法、专名错误"等类型。
2.解决方案
2.1 规则的解决思路
依据语言模型检测错别字位置,通过拼音音似特征、笔画五笔编辑距离特征及语言模型困惑度特征纠正错别字。
- 中文纠错分为两步走,第一步是错误检测,第二步是错误纠正;
- 错误检测部分先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误, 整合这两种粒度的疑似错误结果,形成疑似错误位置候选集;
- 错误纠正部分,是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
2.2 深度模型的解决思路
- 端到端的深度模型可以避免人工提取特征,减少人工工作量,RNN序列模型对文本任务拟合能力强,RNN Attn在英文文本纠错比赛中取得第一名成绩,证明应用效果不错;
- CRF会计算全局最优输出节点的条件概率,对句子中特定错误类型的检测,会根据整句话判定该错误,阿里参赛2016中文语法纠错任务并取得第一名,证明应用效果不错;
- Seq2Seq模型是使用Encoder-Decoder结构解决序列转换问题,目前在序列转换任务中(如机器翻译、对话生成、文本摘要、图像描述)使用最广泛、效果最好的模型之一;
- BERT/ELECTRA/ERNIE/MacBERT等预训练模型强大的语言表征能力,对NLP届带来翻天覆地的改变,海量的训练数据拟合的语言模型效果无与伦比,基于其MASK掩码的特征,可以简单改造预训练模型用于纠错,加上fine-tune,效果轻松达到最优。
PS:
- 作者纠错分享
- 网友源码解读
2.2 模型推荐
-
Kenlm模型:本项目基于Kenlm统计语言模型工具训练了中文NGram语言模型,结合规则方法、混淆集可以纠正中文拼写错误,方法速度快,扩展性强,效果一般
-
MacBERT模型【推荐】:本项目基于PyTorch实现了用于中文文本纠错的MacBERT4CSC模型,模型加入了错误检测和纠正网络,适配中文拼写纠错任务,效果好
-
Seq2Seq模型:本项目基于PyTorch实现了用于中文文本纠错的Seq2Seq模型、ConvSeq2Seq模型,其中ConvSeq2Seq在NLPCC-2018的中文语法纠错比赛中,使用单模型并取得第三名,可以并行训练,模型收敛快,效果一般
-
T5模型:本项目基于PyTorch实现了用于中文文本纠错的T5模型,使用Langboat/mengzi-t5-base的预训练模型fine-tune中文纠错数据集,模型改造的潜力较大,效果好
-
BERT模型:本项目基于PyTorch实现了基于原生BERT的fill-mask能力进行纠正错字的方法,效果差
-
ELECTRA模型:本项目基于PyTorch实现了基于原生ELECTRA的fill-mask能力进行纠正错字的方法,效果差
-
ERNIE_CSC模型:本项目基于PaddlePaddle实现了用于中文文本纠错的ERNIE_CSC模型,模型在ERNIE-1.0上fine-tune,模型结构适配了中文拼写纠错任务,效果好
-
DeepContext模型:本项目基于PyTorch实现了用于文本纠错的DeepContext模型,该模型结构参考Stanford University的NLC模型,2014英文纠错比赛得第一名,效果一般
-
Transformer模型:本项目基于PyTorch的fairseq库调研了Transformer模型用于中文文本纠错,效果一般
-
思考
- 规则的方法,在词粒度的错误召回还不错,但错误纠正的准确率还有待提高,更多优质的纠错集及纠错词库会有提升,我更希望算法模型上有更大的突破。
- 现在的文本错误不再局限于字词粒度上的拼写错误,需要提高中文语法错误检测(CGED, Chinese Grammar Error Diagnosis)及纠正能力,列在TODO中,后续调研。
3.Demo演示
Official Demo: https://www.mulanai.com/product/corrector/
HuggingFace Demo: https://huggingface.co/spaces/shibing624/pycorrector
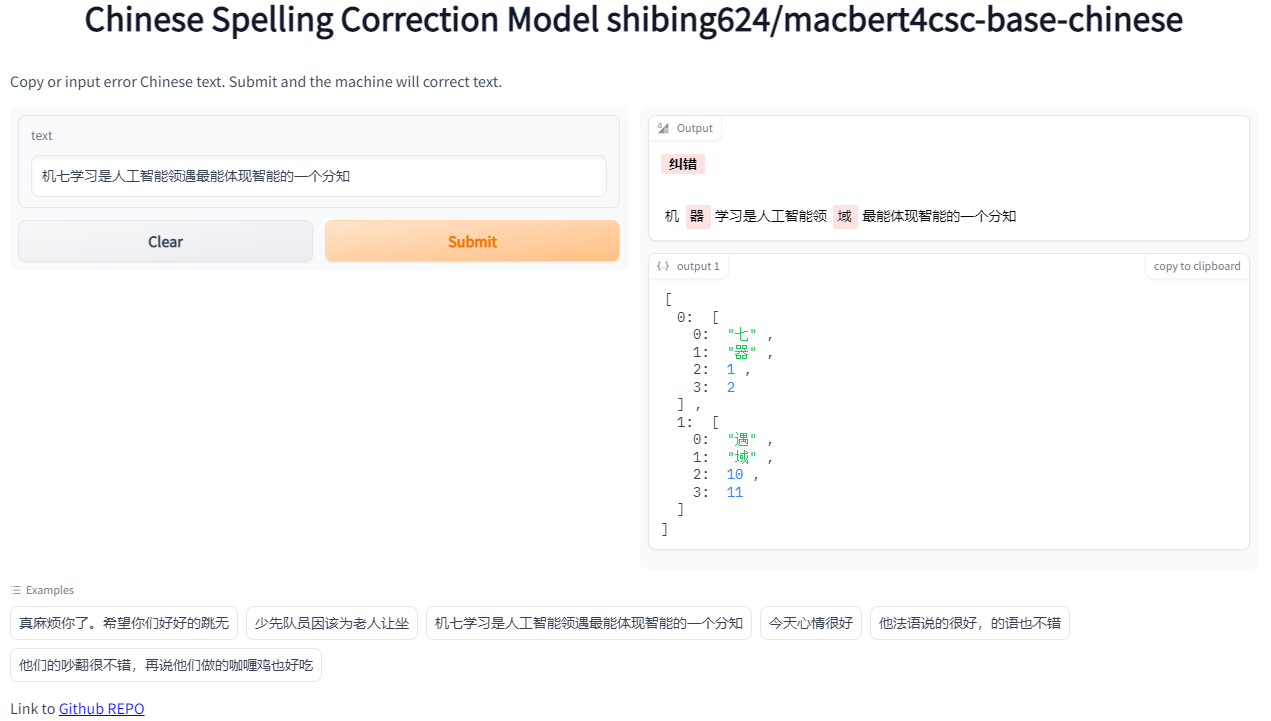
run example: examples/gradio_demo.py to see the demo:
python examples/gradio_demo.py
4.模型评估(sighan15评估集)
提供评估脚本examples/evaluate_models.py:
- 使用sighan15评估集:SIGHAN2015的测试集pycorrector/data/cn/sighan_2015/test.tsv
,已经转为简体中文。 - 评估标准:纠错准召率,采用严格句子粒度(Sentence Level)计算方式,把模型纠正之后的与正确句子完成相同的视为正确,否则为错。
- 评估结果
评估数据集:SIGHAN2015测试集
GPU:Tesla V100,显存 32 GB
| Model Name | Model Hub Link | Backbone | GPU | Precision | Recall | F1 | QPS |
|---|---|---|---|---|---|---|---|
| Rule | - | kenlm | CPU | 0.6860 | 0.1529 | 0.2500 | 9 |
| BERT-CSC | - | bert-base-chinese | GPU | 0.8029 | 0.4052 | 0.5386 | 2 |
| BART-CSC | shibing624/bart4csc-base-chinese | fnlp/bart-base-chinese | GPU | 0.6984 | 0.6354 | 0.6654 | 58 |
| T5-CSC | - | byt5-small | GPU | 0.5220 | 0.3941 | 0.4491 | 111 |
| Mengzi-T5-CSC | shibing624/mengzi-t5-base-chinese-correction | mengzi-t5-base | GPU | 0.8321 | 0.6390 | 0.7229 | 214 |
| ConvSeq2Seq-CSC | - | ConvSeq2Seq | GPU | 0.2415 | 0.1436 | 0.1801 | 6 |
| ChatGLM-6B-CSC | shibing624/chatglm-6b-csc-zh-lora | ChatGLM | GPU | 0.5263 | 0.4052 | 0.4579 | 4 |
| MacBERT-CSC | shibing624/macbert4csc-base-chinese | hfl/chinese-macbert-base | GPU | 0.8254 | 0.7311 | 0.7754 | 224 |
- 结论
- 中文拼写纠错模型效果最好的是MacBert-CSC,模型名称是shibing624/macbert4csc-base-chinese,huggingface model:shibing624/macbert4csc-base-chinese
- 中文语法纠错模型效果最好的是BART-CSC,模型名称是shibing624/bart4csc-base-chinese,huggingface model:shibing624/bart4csc-base-chinese
- 最具潜力的模型是Mengzi-T5-CSC,模型名称是shibing624/mengzi-t5-base-chinese-correction,huggingface model:shibing624/mengzi-t5-base-chinese-correction,未改变模型结构,仅fine-tune中文纠错数据集,已经在
SIGHAN 2015取得接近SOTA的效果 - 基于ChatGLM-6B的纠错微调模型效果也不错,模型名称是shibing624/chatglm-6b-csc-zh-lora,huggingface model:shibing624/chatglm-6b-csc-zh-lora,大模型不仅能改错还能润色句子,但是模型太大,推理速度慢
5.使用指南
pip install -U pycorrector
or
pip install -r requirements.txtgit clone https://github.com/shibing624/pycorrector.git
cd pycorrector
pip install --no-deps .
通过以上两种方法的任何一种完成安装都可以。如果不想安装依赖包,直接使用docker拉取安装好的部署环境即可。
-
安装依赖
-
docker使用
docker run -it -v ~/.pycorrector:/root/.pycorrector shibing624/pycorrector:0.0.2
后续调用python使用即可,该镜像已经安装好kenlm、pycorrector等包,具体参见Dockerfile。
使用示例:

- kenlm安装
pip install kenlm
安装kenlm-wiki
- 其他库包安装
pip install -r requirements.txt
6.应用场景
6.1 文本纠错
example: examples/base_demo.py
import pycorrectorcorrected_sent, detail = pycorrector.correct('少先队员因该为老人让坐')
print(corrected_sent, detail)
output:
少先队员应该为老人让座 [('因该', '应该', 4, 6), ('坐', '座', 10, 11)]
规则方法默认会从路径
~/.pycorrector/datasets/zh_giga.no_cna_cmn.prune01244.klm加载kenlm语言模型文件,如果检测没有该文件,
则程序会自动联网下载。当然也可以手动下载模型文件(2.8G)并放置于该位置。
6.2 错误检测
example: examples/detect_demo.py
import pycorrectoridx_errors = pycorrector.detect('少先队员因该为老人让坐')
print(idx_errors)
output:
[['因该', 4, 6, 'word'], ['坐', 10, 11, 'char']]
返回类型是
list,[error_word, begin_pos, end_pos, error_type],pos索引位置以0开始。
6.3成语、专名纠错
example: examples/proper_correct_demo.py
import syssys.path.append("..")
from pycorrector.proper_corrector import ProperCorrectorm = ProperCorrector()
x = ['报应接中迩来','今天在拼哆哆上买了点苹果',
]for i in x:print(i, ' -> ', m.proper_correct(i))
output:
报应接中迩来 -> ('报应接踵而来', [('接中迩来', '接踵而来', 2, 6)])
今天在拼哆哆上买了点苹果 -> ('今天在拼多多上买了点苹果', [('拼哆哆', '拼多多', 3, 6)])
6.4 自定义混淆集
通过加载自定义混淆集,支持用户纠正已知的错误,包括两方面功能:1)【提升准确率】误杀加白;2)【提升召回率】补充召回。
example: examples/use_custom_confusion.py
import pycorrectorerror_sentences = ['买iphonex,要多少钱','共同实际控制人萧华、霍荣铨、张旗康',
]
for line in error_sentences:print(pycorrector.correct(line))print('*' * 42)
pycorrector.set_custom_confusion_path_or_dict('./my_custom_confusion.txt')
for line in error_sentences:print(pycorrector.correct(line))
output:
('买iphonex,要多少钱', []) # "iphonex"漏召,应该是"iphoneX"
('共同实际控制人萧华、霍荣铨、张启康', [['张旗康', '张启康', 14, 17]]) # "张启康"误杀,应该不用纠
*****************************************************
('买iphonex,要多少钱', [['iphonex', 'iphoneX', 1, 8]])
('共同实际控制人萧华、霍荣铨、张旗康', [])
其中
./my_custom_confusion.txt的内容格式如下,以空格间隔:
iPhone差 iPhoneX
张旗康 张旗康
混淆集功能在
correct方法中生效;
set_custom_confusion_dict方法的path参数为用户自定义混淆集文件路径(str)或混淆集字典(dict)。
6.5 自定义语言模型
默认提供下载并使用的kenlm语言模型zh_giga.no_cna_cmn.prune01244.klm文件是2.8G,内存小的电脑使用pycorrector程序可能会吃力些。
支持用户加载自己训练的kenlm语言模型,或使用2014版人民日报数据训练的模型,模型小(140M),准确率稍低,模型下载地址:people2014corpus_chars.klm(密码o5e9)。
example:examples/load_custom_language_model.py
from pycorrector import Corrector
import ospwd_path = os.path.abspath(os.path.dirname(__file__))
lm_path = os.path.join(pwd_path, './people2014corpus_chars.klm')
model = Corrector(language_model_path=lm_path)corrected_sent, detail = model.correct('少先队员因该为老人让坐')
print(corrected_sent, detail)
output:
少先队员应该为老人让座 [('因该', '应该', 4, 6), ('坐', '座', 10, 11)]
6.6 英文拼写纠错
支持英文单词级别的拼写错误纠正。
example:examples/en_correct_demo.py
import pycorrectorsent = "what happending? how to speling it, can you gorrect it?"
corrected_text, details = pycorrector.en_correct(sent)
print(sent, '=>', corrected_text)
print(details)
output:
what happending? how to speling it, can you gorrect it?
=> what happening? how to spelling it, can you correct it?
[('happending', 'happening', 5, 15), ('speling', 'spelling', 24, 31), ('gorrect', 'correct', 44, 51)]
6.7 中文简繁互换
支持中文繁体到简体的转换,和简体到繁体的转换。
example:examples/traditional_simplified_chinese_demo.py
import pycorrectortraditional_sentence = '憂郁的臺灣烏龜'
simplified_sentence = pycorrector.traditional2simplified(traditional_sentence)
print(traditional_sentence, '=>', simplified_sentence)simplified_sentence = '忧郁的台湾乌龟'
traditional_sentence = pycorrector.simplified2traditional(simplified_sentence)
print(simplified_sentence, '=>', traditional_sentence)
output:
憂郁的臺灣烏龜 => 忧郁的台湾乌龟
忧郁的台湾乌龟 => 憂郁的臺灣烏龜
6.8 命令行模式
支持批量文本纠错
python -m pycorrector -h
usage: __main__.py [-h] -o OUTPUT [-n] [-d] input@description:positional arguments:input the input file path, file encode need utf-8.optional arguments:-h, --help show this help message and exit-o OUTPUT, --output OUTPUTthe output file path.-n, --no_char disable char detect mode.-d, --detail print detail info
case:
python -m pycorrector input.txt -o out.txt -n -d
输入文件:
input.txt;输出文件:out.txt;关闭字粒度纠错;打印详细纠错信息;纠错结果以\t间隔
本项目的初衷之一是比对、共享各种文本纠错方法,抛砖引玉的作用,如果对大家在文本纠错任务上有一点小小的启发就是我莫大的荣幸了。
主要使用了多种深度模型应用于文本纠错任务,分别是前面模型小节介绍的macbert、seq2seq、
bert、electra、transformer
、ernie-csc、T5,各模型方法内置于pycorrector文件夹下,有README.md详细指导,各模型可独立运行,相互之间无依赖。
- 安装依赖
pip install -r requirements-dev.txt
8. 模型推荐
各模型均可独立的预处理数据、训练、预测。
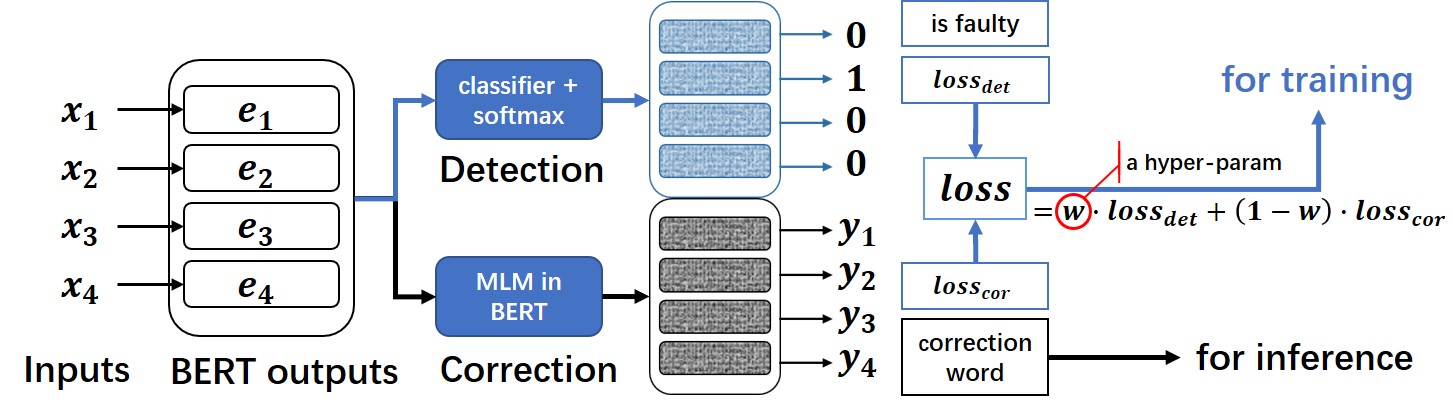
8.1 MacBert4csc模型[推荐]
基于MacBERT改变网络结构的中文拼写纠错模型,模型已经开源在HuggingFace Models:https://huggingface.co/shibing624/macbert4csc-base-chinese
模型网络结构:
- 本项目是 MacBERT 改变网络结构的中文文本纠错模型,可支持 BERT 类模型为 backbone。
- 在原生 BERT 模型上进行了魔改,追加了一个全连接层作为错误检测即 detection ,
MacBERT4CSC 训练时用 detection 层和 correction 层的 loss 加权得到最终的 loss。预测时用 BERT MLM 的 correction 权重即可。
详细教程参考pycorrector/macbert/README.md
example:examples/macbert_demo.py
- 8.1.1 使用pycorrector调用纠错:
import syssys.path.append("..")
from pycorrector.macbert.macbert_corrector import MacBertCorrectorif __name__ == '__main__':error_sentences = ['真麻烦你了。希望你们好好的跳无','少先队员因该为老人让坐','机七学习是人工智能领遇最能体现智能的一个分知','一只小鱼船浮在平净的河面上','我的家乡是有明的渔米之乡',]m = MacBertCorrector("shibing624/macbert4csc-base-chinese")for line in error_sentences:correct_sent, err = m.macbert_correct(line)print("query:{} => {}, err:{}".format(line, correct_sent, err))
output:
query:真麻烦你了。希望你们好好的跳无 => 真麻烦你了。希望你们好好的跳舞, err:[('无', '舞', 14, 15)]
query:少先队员因该为老人让坐 => 少先队员应该为老人让坐, err:[('因', '应', 4, 5)]
query:机七学习是人工智能领遇最能体现智能的一个分知 => 机器学习是人工智能领域最能体现智能的一个分知, err:[('七', '器', 1, 2), ('遇', '域', 10, 11)]
query:一只小鱼船浮在平净的河面上 => 一只小鱼船浮在平净的河面上, err:[]
query:我的家乡是有明的渔米之乡 => 我的家乡是有名的渔米之乡, err:[('明', '名', 6, 7)]
- 8.1.2 使用原生transformers库调用纠错:
import operator
import torch
from transformers import BertTokenizerFast, BertForMaskedLM
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")tokenizer = BertTokenizerFast.from_pretrained("shibing624/macbert4csc-base-chinese")
model = BertForMaskedLM.from_pretrained("shibing624/macbert4csc-base-chinese")
model.to(device)texts = ["今天新情很好", "你找到你最喜欢的工作,我也很高心。"]text_tokens = tokenizer(texts, padding=True, return_tensors='pt').to(device)
with torch.no_grad():outputs = model(**text_tokens)def get_errors(corrected_text, origin_text):sub_details = []for i, ori_char in enumerate(origin_text):if ori_char in [' ', '“', '”', '‘', '’', '\n', '…', '—', '擤']:# add unk wordcorrected_text = corrected_text[:i] + ori_char + corrected_text[i:]continueif i >= len(corrected_text):breakif ori_char != corrected_text[i]:if ori_char.lower() == corrected_text[i]:# pass english upper charcorrected_text = corrected_text[:i] + ori_char + corrected_text[i + 1:]continuesub_details.append((ori_char, corrected_text[i], i, i + 1))sub_details = sorted(sub_details, key=operator.itemgetter(2))return corrected_text, sub_detailsresult = []
for ids, (i, text) in zip(outputs.logits, enumerate(texts)):_text = tokenizer.decode((torch.argmax(ids, dim=-1) * text_tokens.attention_mask[i]),skip_special_tokens=True).replace(' ', '')corrected_text, details = get_errors(_text, text)print(text, ' => ', corrected_text, details)result.append((corrected_text, details))
print(result)
output:
今天新情很好 => 今天心情很好 [('新', '心', 2, 3)]
你找到你最喜欢的工作,我也很高心。 => 你找到你最喜欢的工作,我也很高兴。 [('心', '兴', 15, 16)]
模型文件:
macbert4csc-base-chinese├── config.json├── added_tokens.json├── pytorch_model.bin├── special_tokens_map.json├── tokenizer_config.json└── vocab.txt
8.2 ErnieCSC模型
基于ERNIE的中文拼写纠错模型,模型已经开源在PaddleNLP的
模型库中https://bj.bcebos.com/paddlenlp/taskflow/text_correction/csc-ernie-1.0/csc-ernie-1.0.pdparams。
模型网络结构:
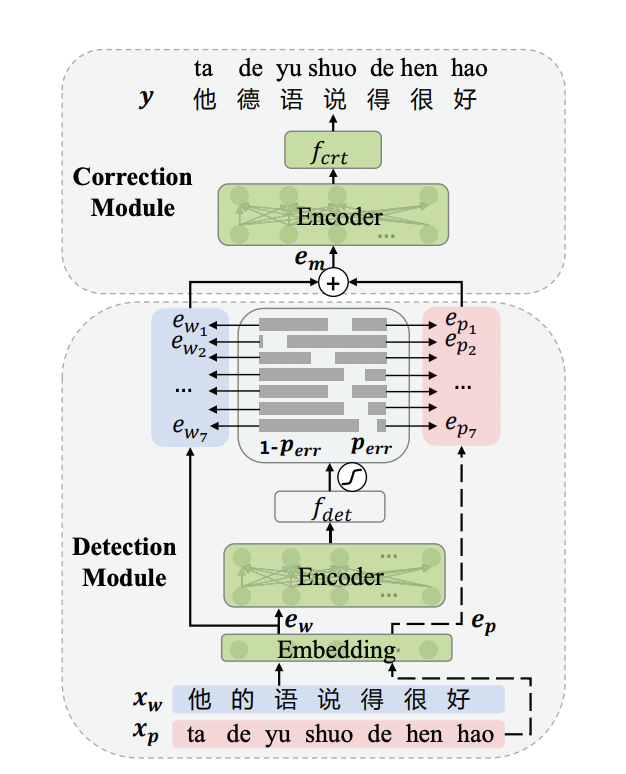
详细教程参考pycorrector/ernie_csc/README.md
example:examples/ernie_csc_demo.py
- 使用pycorrector调用纠错:
from pycorrector.ernie_csc.ernie_csc_corrector import ErnieCSCCorrectorif __name__ == '__main__':error_sentences = ['真麻烦你了。希望你们好好的跳无','少先队员因该为老人让坐','机七学习是人工智能领遇最能体现智能的一个分知','一只小鱼船浮在平净的河面上','我的家乡是有明的渔米之乡',]corrector = ErnieCSCCorrector("csc-ernie-1.0")for line in error_sentences:result = corrector.ernie_csc_correct(line)[0]print("query:{} => {}, err:{}".format(line, result['target'], result['errors']))
output:
query:真麻烦你了。希望你们好好的跳无 => 真麻烦你了。希望你们好好的跳舞, err:[{'position': 14, 'correction': {'无': '舞'}}]
query:少先队员因该为老人让坐 => 少先队员应该为老人让座, err:[{'position': 4, 'correction': {'因': '应'}}, {'position': 10, 'correction': {'坐': '座'}}]
query:机七学习是人工智能领遇最能体现智能的一个分知 => 机器学习是人工智能领域最能体现智能的一个分知, err:[{'position': 1, 'correction': {'七': '器'}}, {'position': 10, 'correction': {'遇': '域'}}]
query:一只小鱼船浮在平净的河面上 => 一只小鱼船浮在平净的河面上, err:[]
query:我的家乡是有明的渔米之乡 => 我的家乡是有名的渔米之乡, err:[{'position': 6, 'correction': {'明': '名'}}]- 使用PaddleNLP库调用纠错:
可以使用PaddleNLP提供的Taskflow工具来对输入的文本进行一键纠错,具体使用方法如下:
from paddlenlp import Taskflowtext_correction = Taskflow("text_correction")
text_correction('遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。')
text_correction('人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。')output:
[{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。','target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。','errors': [{'position': 3, 'correction': {'竟': '境'}}]}][{'source': '人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。','target': '人生就是如此,经过磨练才能让自己更加茁壮,才能使自己更加乐观。','errors': [{'position': 18, 'correction': {'拙': '茁'}}]}]8.3 Bart模型
from transformers import BertTokenizerFast
from textgen import BartSeq2SeqModeltokenizer = BertTokenizerFast.from_pretrained('shibing624/bart4csc-base-chinese')
model = BartSeq2SeqModel(encoder_type='bart',encoder_decoder_type='bart',encoder_decoder_name='shibing624/bart4csc-base-chinese',tokenizer=tokenizer,args={"max_length": 128, "eval_batch_size": 128})
sentences = ["少先队员因该为老人让坐"]
print(model.predict(sentences))
output:
['少先队员应该为老人让座']
如果需要训练Bart模型,请参考 https://github.com/shibing624/textgen/blob/main/examples/seq2seq/training_bartseq2seq_zh_demo.py
- Release models
基于SIGHAN+Wang271K中文纠错数据集训练的Bart模型,已经release到HuggingFace Models:
- BART模型:模型已经开源在HuggingFace Models:https://huggingface.co/shibing624/bart4csc-base-chinese
#3 8.4 ConvSeq2Seq模型
pycorrector/seq2seq 模型使用示例:
- 训练
data example:
#train.txt:
你说的是对,跟那些失业的人比起来你也算是辛运的。 你说的是对,跟那些失业的人比起来你也算是幸运的。
cd seq2seq
python train.py
convseq2seq训练sighan数据集(2104条样本),200个epoch,单卡P40GPU训练耗时:3分钟。
- 预测
python infer.py
output:
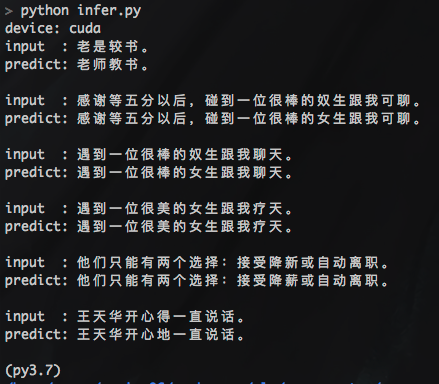
- 如果训练数据太少(不足万条),深度模型拟合不足,会出现预测结果全为
unk的情况,解决方法:增大训练样本集,使用下方提供的纠错熟语料(nlpcc2018+hsk,130万对句子)试试。 - 深度模型训练耗时长,有GPU尽量用GPU,加速训练,节省时间。
- Release models
基于SIGHAN2015数据集训练的convseq2seq模型,已经release到github:
- convseq2seq model url: https://github.com/shibing624/pycorrector/releases/download/0.4.5/convseq2seq_correction.tar.gz
9.数据集
9.1 开源数据集
| 数据集 | 语料 | 下载链接 | 压缩包大小 |
|---|---|---|---|
SIGHAN+Wang271K中文纠错数据集 | SIGHAN+Wang271K(27万条) | 百度网盘(密码01b9) shibing624/CSC | 106M |
原始SIGHAN数据集 | SIGHAN13 14 15 | 官方csc.html | 339K |
原始Wang271K数据集 | Wang271K | Automatic-Corpus-Generation dimmywang提供 | 93M |
人民日报2014版语料 | 人民日报2014版 | 飞书(密码cHcu) | 383M |
NLPCC 2018 GEC官方数据集 | NLPCC2018-GEC | 官方trainingdata | 114M |
NLPCC 2018+HSK熟语料 | nlpcc2018+hsk+CGED | 百度网盘(密码m6fg) 飞书(密码gl9y) | 215M |
NLPCC 2018+HSK原始语料 | HSK+Lang8 | 百度网盘(密码n31j) 飞书(密码Q9LH) | 81M |
中文纠错比赛数据汇总 | Chinese Text Correction(CTC) | 中文纠错汇总数据集(天池) | - |
说明:
- SIGHAN+Wang271K中文纠错数据集(27万条),是通过原始SIGHAN13、14、15年数据集和Wang271K数据集格式转化后得到,json格式,带错误字符位置信息,SIGHAN为test.json,
macbert4csc模型训练可以直接用该数据集复现paper准召结果,详见pycorrector/macbert/README.md。 - NLPCC 2018 GEC官方数据集NLPCC2018-GEC,
训练集trainingdata[解压后114.5MB],该数据格式是原始文本,未做切词处理。 - 汉语水平考试(HSK)和lang8原始平行语料[HSK+Lang8]百度网盘(密码n31j),该数据集已经切词,可用作数据扩增。
- NLPCC 2018 + HSK + CGED16、17、18的数据,经过以字切分,繁体转简体,打乱数据顺序的预处理后,生成用于纠错的熟语料(nlpcc2018+hsk)
,百度网盘(密码:m6fg) [130万对句子,215MB]
SIGHAN+Wang271K中文纠错数据集,数据格式:
[{"id": "B2-4029-3","original_text": "晚间会听到嗓音,白天的时候大家都不会太在意,但是在睡觉的时候这嗓音成为大家的恶梦。","wrong_ids": [5,31],"correct_text": "晚间会听到噪音,白天的时候大家都不会太在意,但是在睡觉的时候这噪音成为大家的恶梦。"}
]
字段解释:
- id:唯一标识符,无意义
- original_text: 原始错误文本
- wrong_ids: 错误字的位置,从0开始
- correct_text: 纠正后的文本
9.2 自有数据集
可以使用自己数据集训练纠错模型,把自己数据集标注好,保存为跟训练样本集一样的json格式,然后加载数据训练模型即可。
- 已有大量业务相关错误样本,主要标注错误位置(wrong_ids)和纠错后的句子(correct_text)
- 没有现成的错误样本,可以写脚本生成错误样本(original_text),根据音似、形似等特征把正确句子的指定位置(wrong_ids)字符改为错字,附上
第三方同音字生成脚本同音词替换
10.总结
什么是语言模型?-wiki
语言模型对于纠错步骤至关重要,当前默认使用的是从千兆中文文本训练的中文语言模型zh_giga.no_cna_cmn.prune01244.klm(2.8G),
提供人民日报2014版语料训练得到的轻量版语言模型people2014corpus_chars.klm(密码o5e9)。
大家可以用中文维基(繁体转简体,pycorrector.utils.text_utils下有此功能)等语料数据训练通用的语言模型,或者也可以用专业领域语料训练更专用的语言模型。更适用的语言模型,对于纠错效果会有比较好的提升。
- kenlm语言模型训练工具的使用,请见博客:http://blog.csdn.net/mingzai624/article/details/79560063
- 附上训练语料<人民日报2014版熟语料>,包括: 1)标准人工切词及词性数据people2014.tar.gz, 2)未切词文本数据people2014_words.txt,
3)kenlm训练字粒度语言模型文件及其二进制文件people2014corpus_chars.arps/klm, 4)kenlm词粒度语言模型文件及其二进制文件people2014corpus_words.arps/klm。
- Todo
- 优化形似字字典,提高形似字纠错准确率
- 整理中文纠错训练数据,使用seq2seq做深度中文纠错模型
- 添加中文语法错误检测及纠正能力
- 规则方法添加用户自定义纠错集,并将其纠错优先度调为最高
- seq2seq_attention 添加dropout,减少过拟合
- 在seq2seq模型框架上,新增Pointer-generator network、Beam search、Unknown words replacement、Coverage mechanism等特性
- 更新bert的fine-tuned使用wiki,适配transformers 2.10.0库
- 升级代码,兼容TensorFlow 2.0库
- 升级bert纠错逻辑,提升基于mask的纠错效果
- 新增基于electra模型的纠错逻辑,参数更小,预测更快
- 新增专用于纠错任务深度模型,使用bert/ernie预训练模型,加入文本音似、形似特征。
-
Reference
-
基于文法模型的中文纠错系统
-
Norvig’s spelling corrector
-
Chinese Spelling Error Detection and Correction Based on Language Model, Pronunciation, and Shape[Yu, 2013]
-
Chinese Spelling Checker Based on Statistical Machine Translation[Chiu, 2013]
-
Chinese Word Spelling Correction Based on Rule Induction[yeh, 2014]
-
Neural Language Correction with Character-Based Attention[Ziang Xie, 2016]
-
Chinese Spelling Check System Based on Tri-gram Model[Qiang Huang, 2014]
-
Neural Abstractive Text Summarization with Sequence-to-Sequence Models[Tian Shi, 2018]
-
基于深度学习的中文文本自动校对研究与实现[杨宗霖, 2019]
-
A Sequence to Sequence Learning for Chinese Grammatical Error Correction[Hongkai Ren, 2018]
-
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
-
Revisiting Pre-trained Models for Chinese Natural Language Processing
-
Ruiqing Zhang, Chao Pang et al. “Correcting Chinese Spelling Errors with Phonetic Pre-training”, ACL, 2021
-
DingminWang et al. “A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check”, EMNLP, 2018
参考链接:https://github.com/shibing624/pycorrector
如果github进入不了也可进入 https://download.csdn.net/download/sinat_39620217/88205573 免费下载相关资料
相关文章:
pycorrector一键式文本纠错工具,整合了BERT、MacBERT、ELECTRA、ERNIE等多种模型,让您立即享受纠错的便利和效果
pycorrector:一键式文本纠错工具,整合了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer、T5等多种模型,让您立即享受纠错的便利和效果 pycorrector: 中文文本纠错工具。支持中文音似、形似、语法错误纠正,pytho…...

Linux 日志管理
Linux 日志管理 一.Linux 下的日志服务简介 1.1 CentOS5 之前的版本 centos5 之前的版本使用系统和内核日志分离的格式记录日志 syslogd:该服务专门用于记录系统日志(system application logs) klogd: 该服务专门用于记录内核日志(linux kernel logs) centos5 之前事件的记录格…...

统计学补充概念04-最大似然估计
概念 最大似然估计(Maximum Likelihood Estimation,简称MLE)是一种统计方法,用于估计模型的参数,使得给定观测数据的似然函数达到最大。在最大似然估计中,我们寻找能够最大化观测数据的可能性(…...
mysql一些统计实用函数
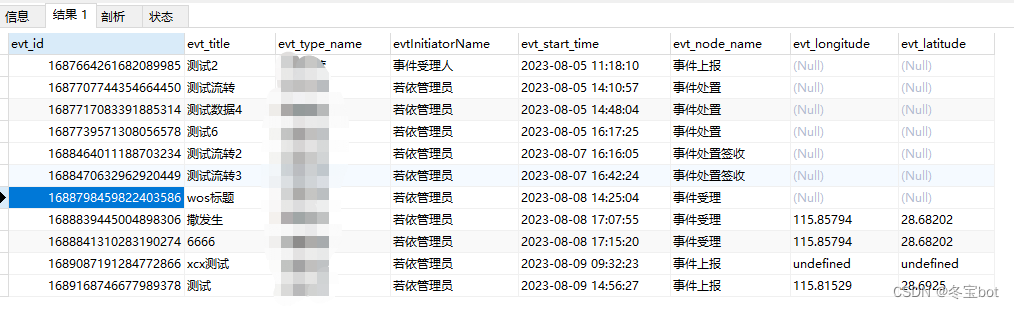
文章目录 一对多,多的一端只查询最新数据YEAR 年份函数MONTH 月份函数QUARTER 季度函数往前递推十年往后递推十年查询去年12月份统计身份证户籍所在地人数 一对多,多的一端只查询最新数据 ROW_NUMBER() over(PARTITION BY evt_id ORDER BY evt_node_rec…...

IC设计仿真云架构
对于IC仿真来说,最重要的是要安全、可维护、高性能的的HPC环境环境。 那么云上如何搭建起一套完整的IC仿真云环境呢? 这种架构应该长什么样子? 桌面虚拟化基础架构 将所有桌面虚拟机在数据中心进行托管并统一管理;同时用户能够…...

日常BUG ——乱码
😜作 者:是江迪呀✒️本文关键词:日常BUG、BUG、问题分析☀️每日 一言 :存在错误说明你在进步! 一、问题描述 A系统使用Feign调用B系统时,传递的String字符串,到了B系统中变为了乱…...
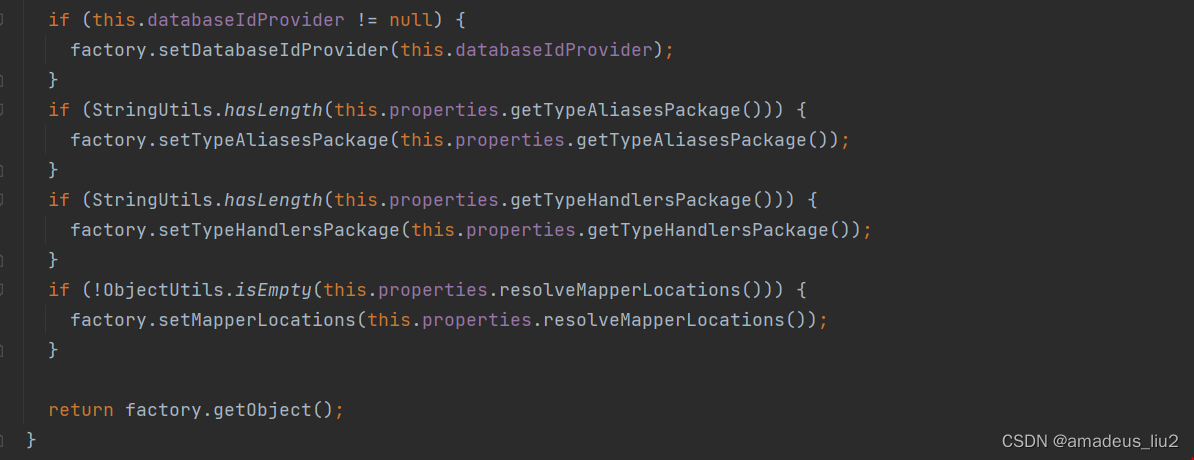
SpringBoot复习:(44)MyBatisAutoConfiguration
可以看到MyBatisAutoConfiguration引入了MyBatisProperties这个属性: MyBatisAutoConfiguration中配置了一个SqlSessionFactoryBean,代码如下: 可以配置mybatis-config.xml,需要配置文件里指定: mybatis.config-locationclasspath:/mybat…...

SpringBoot校验,DTO文件中常用的注解应用案例.
在观看本篇文章之前,可以先参考我之前写的一篇文章 “ Spring5,Service层对DTO文件进行数据格式校验. ” ,这篇文章是介绍在 Service层 对DTO文件的校验。 以下方的 CompanyDTO 文件为例,讲解不同的注解使用场景,以及…...

Qt 窗口随鼠标移动效果
实现在窗口任意位置按下鼠标左键都可以移动窗口的效果,完整代码如下: mainwindow.h: #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QMouseEvent>QT_BEGIN_NAMESPACE namespace Ui { class MainW…...

大数据Flink(五十九):Flink on Yarn的三种部署方式介绍以及注意
文章目录 Flink on Yarn的三种部署方式介绍以及注意 一、Pre-Job 模式部署作业...
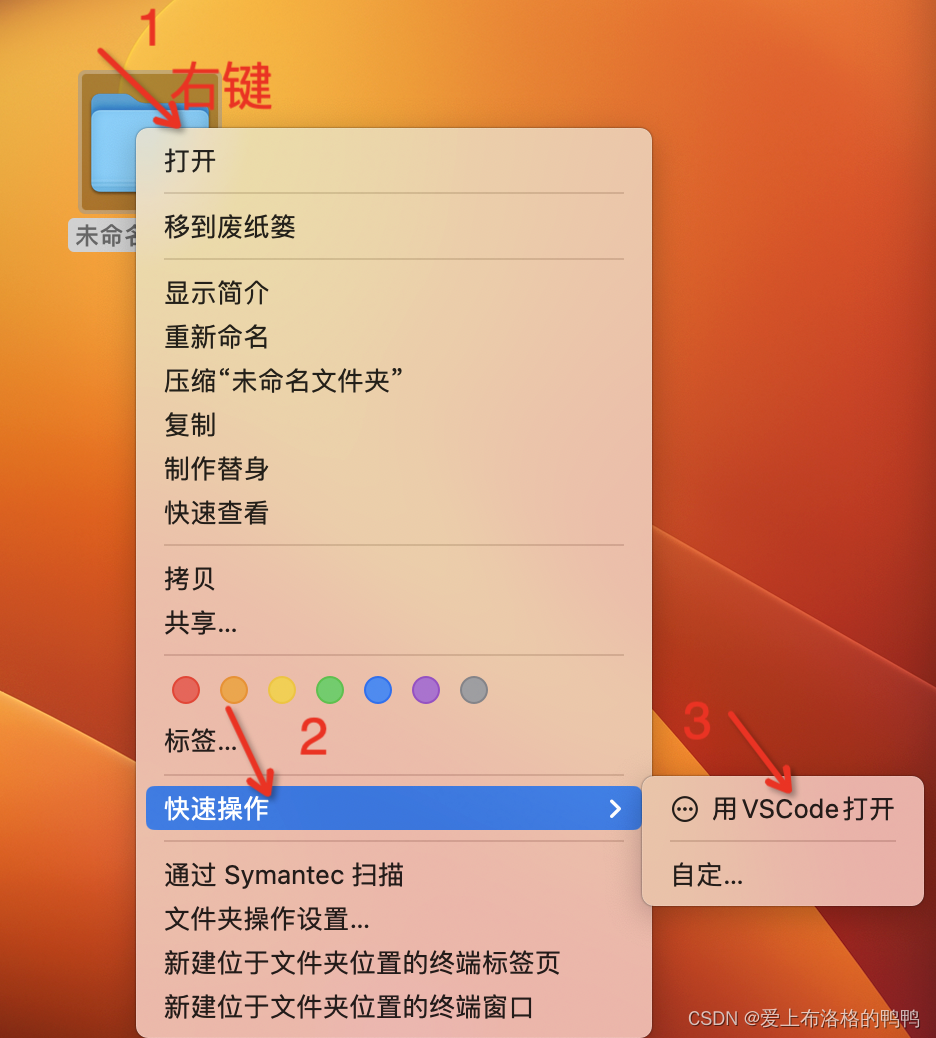
mac-右键-用VSCode打开
1.点击访达,搜索自动操作 2.选择快速操作 3.执行shell脚本 替换代码如下: for f in "$" doopen -a "Visual Studio Code" "$f" donecommand s保存会出现一个弹框,保存为“用VSCode打开” 5.使用...

tkinter+爬虫+pygame实现音乐播放器
文章目录 前文安装模块示意图爬虫完整代码pygametkinter完整代码结尾前文 本文将涉及爬虫(数据的获取),pygame(音乐播放器),tkinter(界面显示),将他们汇聚到一起制造一个音乐播放器,欢迎大家的订阅。 安装模块 pip install requests,parsel,lxpy,pygame 示意图...

css 实现 html 元素内文字水平垂直居中的N种方法
上一篇博文写了div 中元素居中的N种常用方法,那么单个html元素:div(块级元素代表),span(行内元素代表)中的文字如何水平垂直都居中呢?实现方法如下: 本文例子使用的 html…...
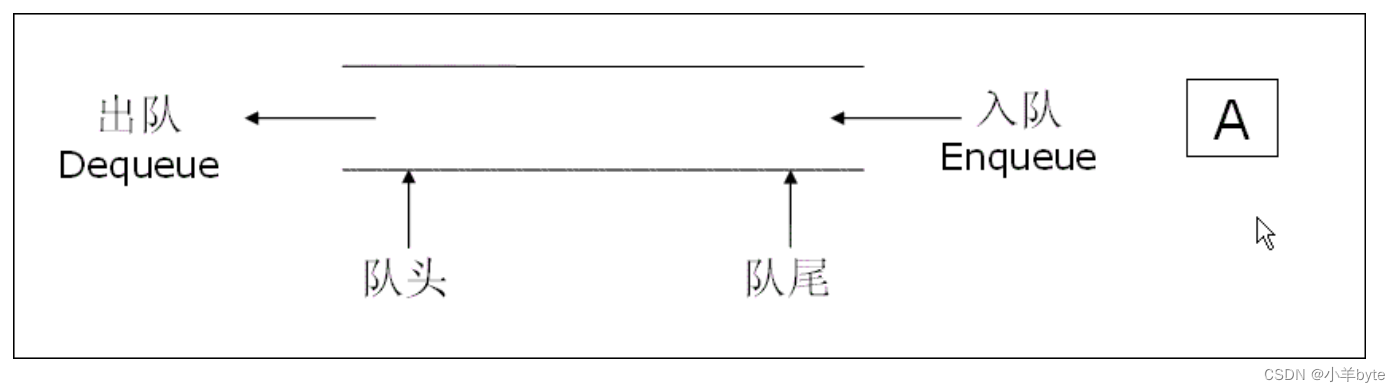
数据结构-队列的实现(C语言版)
前言 队列是一种特殊的线性表,它只允许在一端对数据进行插入操作,在另一端对数据进行删除操作的特殊线性表,队列具有先进先出的(FIFO)的 特性,进行插入操作的一端称为队尾,进行删除操作的一端称…...
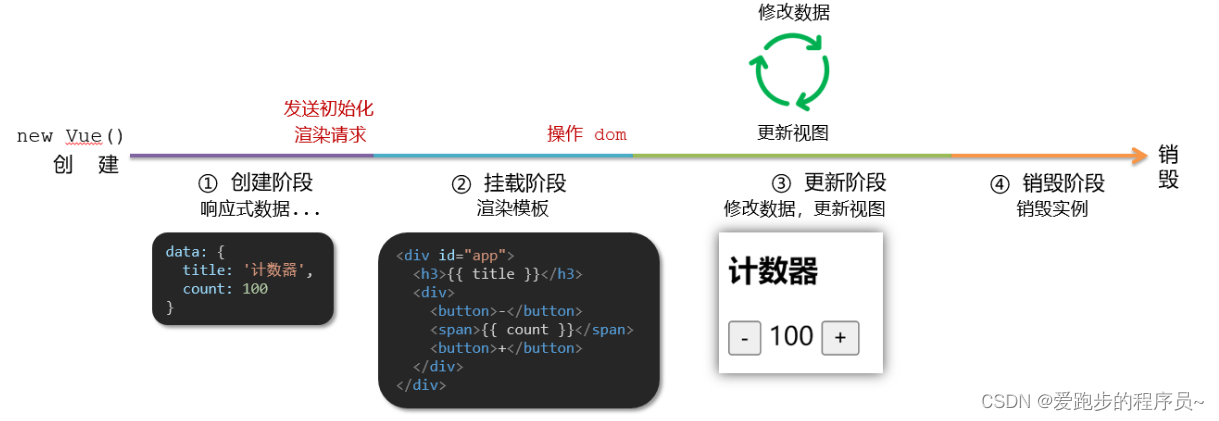
Vue.js 生命周期详解
Vue.js 是一款流行的 JavaScript 框架,它采用了组件化的开发方式,使得前端开发更加简单和高效。在 Vue.js 的开发过程中,了解和理解 Vue 的生命周期非常重要。本文将详细介绍 Vue 生命周期的四个阶段:创建、挂载、更新和销毁。 …...

矩阵定理复习记录
矩阵复习 矩阵导数定理 若A是一个如下矩阵: A [ a 11 a 12 a 21 a 22 ] A \begin{bmatrix}a_{11}&a_{12}\\a_{21}&a_{22}\end{bmatrix} A[a11a21a12a22] y是一个向量矩阵: y ⃗ [ y 1 y 2 ] \vec{y}\begin{bmatrix}y_1\\y_2\e…...
Jenkins+Docker+SpringCloud微服务持续集成项目优化和微服务集群
JenkinsDockerSpringCloud微服务持续集成项目优化和微服务集群 JenkinsDockerSpringCloud部署方案优化JenkinsDockerSpringCloud集群部署流程说明修改所有微服务配置 设计Jenkins集群项目的构建参数编写多选项遍历脚本多项目提交进行代码审查多个项目打包及构建上传镜像把Eurek…...
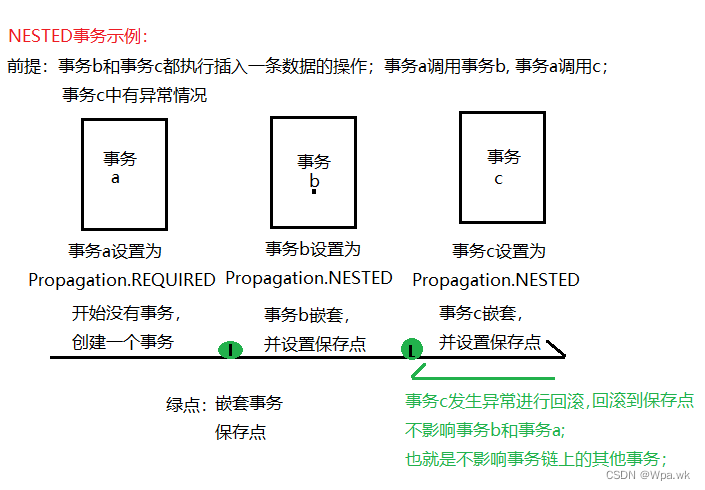
认识 spring 中的事务 与 事务的传播机制
前言 本篇介绍spring中事务的实现方式,如何实现声明式事务,对事物进行参数的设置,了解事务的隔离级别和事务的传播机制;如有错误,请在评论区指正,让我们一起交流,共同进步! 文章目录…...

PHP中的16个危险函数
php中内置了许许多多的函数,在它们的帮助下可以使我们更加快速的进行开发和维护,但是这个函数中依然有许多的函数伴有高风险的,比如说一下的16个函数不到万不得已不尽量不要使用,因为许多“高手”可以通过这些函数抓取你的漏洞。 …...

11、Nvidia显卡驱动、CUDA、cuDNN、Anaconda及Tensorflow Pytorch版本
Nvidia显卡驱动、CUDA、cuDNN、Anaconda及Tensorflow-GPU版本 一、确定版本关系二、安装过程1.安装显卡驱动2、安装CUDA3、安装cudnn4、安装TensorFlow5、安装pytorch 三、卸载 一、确定版本关系 TensorFlow Pytorch推出cuda和cudnn的版本,cuda版本推出驱动可选版本…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...