Streamlit项目: 轻松搭建部署个人博客网站
文章目录
- 1 前言
- 1.1 探索 Streamlit:轻松创建交互式应用
- 1.2 最全 Streamlit 教程专栏
- 2 我的个人博客网站已上线!
- 2.1 一个集成了智能中医舌诊-中e诊专栏的博客网站
- 2.2 前期准备
- 2.3 使用 Streamlit Cloud 运行
- 3 知识点讲解
- 3.1 实现多页面:两种方案
- 3.2 代码讲解
- 3.3 实现步骤
- 3.4 完整代码
- 4 结语

1 前言
大家好,欢迎来到我的博客!在这篇文章中,我将为大家详细介绍如何使用 Streamlit 这一强大的工具来搭建个人博客网站。如果你对数据可视化、交互式应用和博客撰写有兴趣,那么这篇文章一定会给你带来很大的帮助。
1.1 探索 Streamlit:轻松创建交互式应用
首先,让我们来认识一下 Streamlit。Streamlit 是一个用于数据科学家和开发者的开源 Python 库,它能够让你以简单的方式构建交互式和高度定制化的数据应用程序。无需繁琐的前端开发,你只需要使用 Python 编写代码,就能够快速创建具有交互性的数据可视化应用。Streamlit 提供了丰富的组件和布局选项,使你能够轻松地将数据展示出来,与用户进行互动,以及分享你的成果。
1.2 最全 Streamlit 教程专栏
在我的专栏:最全 Streamlit 教程 中,我已经分享了一系列关于 Streamlit 的教程,带你从零开始掌握这个工具。如果你还没有了解过 Streamlit,我建议你先阅读以下几篇文章,以便更好地理解本文中将要讲解的内容:
Streamlit 讲解专栏(一):安装以及初步应用
Streamlit 讲解专栏(二):搭建第一个应用
Streamlit 讲解专栏(三):两种方案构建多页面
Streamlit 讲解专栏(五):探索强大而灵活的 st.write() 函数
Streamlit 讲解专栏(六):展示文本魔力
Streamlit 讲解专栏(八):图像、音频与视频魔法
2 我的个人博客网站已上线!
我的个人博客网站已经成功上线啦!你可以通过以下链接访问我的博客网站:网站链接
2.1 一个集成了智能中医舌诊-中e诊专栏的博客网站
这个博客网站是一个汇集了我在 智能中医舌诊-中e诊 专栏中所有文章的地方。你可以在这里轻松浏览、阅读每一篇专栏文章,并且查看每篇文章中的图片和内容。这个网站的搭建是基于 Streamlit 技术完成的,这使得我能够以简单的方式构建了这个交互式的博客网站,无需过多的前端开发。

2.2 前期准备
这里需要将你的博文导出,贴心的CSDN为我们提供了导出功能!
在博客编辑页面点击导出→点击导出为MarkDown文件
ps:这也可以作为你博客备份的方法


将你的博客都导出后,整理到一个文件夹中,前期准备结束!
2.3 使用 Streamlit Cloud 运行
我将这个博客网站部署在了 Streamlit Cloud 上,这是 Streamlit 官方提供的一项服务。通过 Streamlit Cloud,我能够将我的应用程序直接部署到云端,并与大家分享。如果你想了解更多关于如何使用 Streamlit Cloud 运行和部署应用的知识,我会在 最全 Streamlit 教程 专栏中进行详细讲解,敬请期待!
我非常期待大家能够访问我的个人博客网站,体验其中的交互性和丰富多样的内容。如果你对 Streamlit、数据可视化和交互式应用感兴趣,那么这个博客网站一定会为你带来很多收获。
3 知识点讲解
3.1 实现多页面:两种方案
在我的个人博客网站中,我采用了两种不同的方法来实现多页面功能,让读者能够更加方便地浏览和阅读不同的博文。下面,我将为大家简要介绍这两种方案,如果你想深入了解每个方案的实现细节,可以前往我的文章:Streamlit 讲解专栏(三):两种方案构建多页面。
第一种方案:使用 Session State 实现多页面交互
在这种方案中,我使用了 Streamlit 的 Session State 功能,通过共享状态来实现多页面的交互。每个页面都对应一个不同的状态,使得我能够根据用户的选择和操作在不同页面之间进行切换,并保持页面状态的一致性。这种方法适用于相对简单的多页面应用,而且在不需要额外的 URL 路由设置的情况下,实现起来相对较为简单。
第二种方案:Streamlit 内置多页面
另一种方法是使用 Streamlit 内置的多页面功能。Streamlit 最新的版本已经支持创建多个页面,并通过不同的按钮或链接进行导航。我通过为每个页面编写不同的函数,然后在用户点击不同的链接时调用相应的函数,来实现了多页面的切换。这种方法对于较复杂的多页面应用来说非常实用,它可以让你更灵活地组织你的应用结构,并提供更多的自定义选项。
如果你对这两种方案感兴趣,我强烈建议你阅读我的文章:Streamlit 讲解专栏(三):两种方案构建多页面,其中我详细介绍了每种方案的实现步骤和注意事项。无论你是初学者还是有一定经验的开发者,这篇文章都将为你带来有益的指导和启发。
3.2 代码讲解
下面是我们使用 Streamlit 搭建个人博客网站的代码实现。首先,让我们看一下代码的整体结构:
# 导入所需的库
import streamlit as st
import os
import re
import requests
from PIL import Image
from io import BytesIO# 获取当前路径
current_path = os.getcwd()# ...(略去了其他导入和定义函数的部分)# 主应用程序
def main():# 在侧边栏添加标题st.sidebar.title("博文选择")# 设置博文文件夹路径(相对于当前路径)markdown_folder = current_path + '/blog/' # 修改为你的文件夹路径markdown_files = [file for file in os.listdir(markdown_folder) if file.endswith('.md')]# 创建博文选择的下拉列表selected_file = st.sidebar.selectbox("选择要阅读的博文", markdown_files)# 构建博文的完整文件路径file_path = os.path.join(markdown_folder, selected_file)# 调用创建博文页面函数blog_page(file_path)if __name__ == "__main__":main()接下来,让我们逐个分块详细讲解代码中涉及的 Streamlit 知识点。
导入所需的库
首先,我们导入了我们将在代码中使用的库,包括 Streamlit、os、re、requests、PIL(用于处理图像)、BytesIO(用于处理字节流)。
获取当前路径
我们使用 os.getcwd() 函数获取当前工作路径,这将帮助我们确定博客文件夹的路径。
读取 Markdown 文件内容
这一部分代码定义了一个函数 read_markdown_file(file_path),用于读取 Markdown 文件的内容。我们使用 with open() 来打开文件,读取内容并返回。
将 Markdown 内容按图片链接分割
这一部分代码定义了一个函数 split_markdown_by_images(markdown_content),用于将 Markdown 内容按图片链接分割为多个部分。我们使用正则表达式和字符串操作来实现分割。
创建博文页面
这一部分代码定义了一个函数 blog_page(file_path),用于创建单篇博文的页面。首先,我们使用 st.title() 设置页面标题。然后,我们获取文件名并使用 st.write() 插入博文标题。
接着,我们调用之前定义的函数来读取并显示 Markdown 内容。通过判断行中是否包含图片链接,我们将内容分割成多个部分。如果是图片链接,我们使用 requests 库获取图片并使用 st.image() 将图片显示在页面上;否则,我们使用 st.markdown() 将文字内容以 Markdown 格式显示。
主应用程序
在主应用程序中,我们首先在侧边栏添加一个标题。然后,我们设置博文文件夹路径,并列出文件夹中的所有 Markdown 文件。使用 st.sidebar.selectbox(),我们创建了一个下拉列表,允许用户选择要阅读的博文。
最后,我们构建了博文的完整文件路径,并调用之前定义的函数 blog_page() 来创建博文页面。
3.3 实现步骤
步骤一:安装 Streamlit
在开始之前,确保你已经安装了 Streamlit。如果没有安装,可以在命令行中输入以下命令:
pip install streamlit步骤二:准备 Markdown 文章
首先,你需要准备好你的 Markdown 文章,这些文章将会成为你博客网站的内容。你可以将这些 Markdown 文章放在一个文件夹中,例如 “blog” 文件夹。
步骤三:编写 Streamlit 应用
现在,让我们一步步编写 Streamlit 应用,创建一个个人博客网站。
首先,导入所需的库:
import streamlit as st
import os
import re
import requests
from PIL import Image
from io import BytesIO接下来,获取当前路径:
current_path = os.getcwd()定义一个函数来读取 Markdown 文件内容:
def read_markdown_file(file_path):with open(file_path, 'r', encoding='utf-8') as file:content = file.read()return content实现一个函数,将 Markdown 内容按图片链接分割:
def split_markdown_by_images(markdown_content):parts = []current_part = ""lines = markdown_content.splitlines()for line in lines:if re.match(r'\!\[.*\]\(http[s]?://.*\)', line):if current_part:parts.append(current_part)parts.append(line)current_part = ""else:current_part += line + "\n"if current_part:parts.append(current_part)return parts创建博文页面的函数:
def blog_page(file_path):st.title("蓝色是天的中医舌诊博客网站")# 获取博文标题markdown_title = os.path.splitext(os.path.basename(file_path))[0]st.write(f"## {markdown_title}") # 插入博文标题# 读取并显示Markdown内容markdown_content = read_markdown_file(file_path)# 将Markdown内容按图片链接分割content_parts = split_markdown_by_images(markdown_content)for part in content_parts:if re.match(r'\!\[.*\]\(http[s]?://.*\)', part):image_url = re.search(r'\((http[s]?://.*)\)', part).group(1)response = requests.get(image_url)response = response.contentbytes_io_obj = BytesIO()bytes_io_obj.write(response)img = Image.open(bytes_io_obj)st.image(img, use_column_width=True)else:st.markdown(part)最后,创建主应用程序:
def main():st.sidebar.title("博文选择")markdown_folder = current_path + '/blog/' # 修改为你的文件夹路径markdown_files = [file for file in os.listdir(markdown_folder) if file.endswith('.md')]selected_file = st.sidebar.selectbox("选择要阅读的博文", markdown_files)file_path = os.path.join(markdown_folder, selected_file)blog_page(file_path)if __name__ == "__main__":main()步骤四:运行 Streamlit 应用
在终端中运行以下命令来启动你的 Streamlit 应用:
streamlit run your_app_name.py
替换 “your_app_name.py” 为你保存代码的文件名。这将启动一个本地服务器,并在浏览器中显示你的个人博客网站。
步骤五:发布网站
你可以使用 Streamlit Cloud 将你的博客网站发布到互联网上。Streamlit Cloud 是一个允许你分享和发布 Streamlit 应用的平台。具体的发布步骤,你可以在我的专栏文章中找到更多信息。
这就是使用 Streamlit 搭建个人博客网站的完整流程。通过这个简单的应用,你可以将你的 Markdown 博文与图像展示在一个美观的交互式界面中,让读者更加愉快地阅读你的内容。不仅如此,Streamlit 还提供了更多的定制选项,你可以进一步改进你的博客网站。
我希望这篇文章对于想要使用 Streamlit 构建个人博客网站的你们有所帮助。欢迎探索 Streamlit 的更多功能,创造出令人赞叹的交互式数据应用!
3.4 完整代码
import streamlit as st
import os
import re
import requests
from PIL import Image
from io import BytesIO# 获取当前路径
current_path = os.getcwd()# 读取Markdown文件内容
def read_markdown_file(file_path):with open(file_path, 'r', encoding='utf-8') as file:content = file.read()return content# 将Markdown内容按图片链接分割
def split_markdown_by_images(markdown_content):parts = []current_part = ""lines = markdown_content.splitlines()for line in lines:if re.match(r'\!\[.*\]\(http[s]?://.*\)', line):if current_part:parts.append(current_part)parts.append(line)current_part = ""else:current_part += line + "\n"if current_part:parts.append(current_part)return parts# 创建博文页面
def blog_page(file_path):# 设置页面标题st.title("蓝色是天的中医舌诊博客网站")# 获取博文标题markdown_title = os.path.splitext(os.path.basename(file_path))[0]st.write(f"## {markdown_title}") # 插入博文标题# 读取并显示Markdown内容markdown_content = read_markdown_file(file_path)# 将Markdown内容按图片链接分割content_parts = split_markdown_by_images(markdown_content)for part in content_parts:if re.match(r'\!\[.*\]\(http[s]?://.*\)', part):image_url = re.search(r'\((http[s]?://.*)\)', part).group(1)response = requests.get(image_url)response = response.contentbytes_io_obj = BytesIO()bytes_io_obj.write(response)img = Image.open(bytes_io_obj)st.image(img, use_column_width=True)else:st.markdown(part)# 主应用程序
def main():# 在侧边栏添加标题st.sidebar.title("博文选择")# 设置博文文件夹路径(相对于当前路径)markdown_folder = current_path + '/blog/' # 修改为你的文件夹路径markdown_files = [file for file in os.listdir(markdown_folder) if file.endswith('.md')]# 创建博文选择的下拉列表selected_file = st.sidebar.selectbox("选择要阅读的博文", markdown_files)# 构建博文的完整文件路径file_path = os.path.join(markdown_folder, selected_file)# 调用创建博文页面函数blog_page(file_path)if __name__ == "__main__":main()4 结语
通过本文,我们学习了如何使用 Streamlit 这一强大的工具来搭建个人博客网站,将 Markdown 内容和图像展示在一个交互式界面中。无需繁琐的前端开发,我们可以专注于用 Python 编写代码,创造出优雅而功能丰富的博客平台。
Streamlit 提供了简单易用的界面元素,使我们能够迅速构建出交互式的数据应用,从而与读者分享我们的知识和见解。在搭建个人博客网站的过程中,我们探索了如何读取 Markdown 文件内容、处理图片链接、创建多页面交互等知识点。同时,我们还了解了如何通过 Streamlit Cloud 将我们的网站发布到互联网上,与更多的读者分享我们的内容。
随着技术的不断发展,我们能够以更加创新和便捷的方式与读者进行互动。使用 Streamlit,我们不仅能够搭建个人博客,还可以创造出各种交互式数据应用,将复杂的数据和见解以直观的方式展示给大众。
在这个信息时代,拥有一个个性化的博客网站,是分享知识、交流经验的绝佳途径。我鼓励大家尝试使用 Streamlit,将你的想法和见解呈现给世界,创造出一个充满创意和交互性的学习平台。
希望本文能够帮助你入门 Streamlit,探索搭建个人博客网站的乐趣。无论你是数据科学家、开发者还是博主,Streamlit 都能够助你创造出令人惊叹的交互式应用。让我们一起在技术的海洋中留下自己的足迹,创造出更多精彩的故事!

相关文章:
Streamlit项目: 轻松搭建部署个人博客网站
文章目录 1 前言1.1 探索 Streamlit:轻松创建交互式应用1.2 最全 Streamlit 教程专栏 2 我的个人博客网站已上线!2.1 一个集成了智能中医舌诊-中e诊专栏的博客网站2.2 前期准备2.3 使用 Streamlit Cloud 运行 3 知识点讲解3.1 实现多页面:两种…...

手把手教你如何实现内网搭建电影网站并进行公网访问(保姆级教学)
手把手教你如何实现内网搭建电影网站并进行公网访问 文章目录 手把手教你如何实现内网搭建电影网站并进行公网访问前言1. 把软件分别安装到本地电脑上1.1 打开PHPStudy软件,安装一系列电影网站所需的支持软件1.2 设置MacCNS10的运行环境1.3 进入电影网页的安装程序1…...

Redis_事务操作
13. redis事务操作 13.1事务简介 原子性(Atomicity) 一致性(Consistency) 隔离性(isolation) 持久性(durabiliby) ACID 13.2 Redis事务 提供了multi、exec命令来完成 第一步,客户端使用multi命令显式地开启事务第二步,客户端把事务中要执行的指令发…...

python质检工具(pylint)安装使用总结
1、Pylint Pylint工具主要类似java中的checkStyle和findbugs,是检查代码样式和逻辑规范的工具。 1.1、Pylint安装流程: 打开PyCharm软件,打开如图1.1所示Terminal终端窗口,先查看python版本和pip版本,pip是19.0.3,python是2.7 图1.1 运行pip install pylint安装pylin…...

“深入探究JVM:解密Java虚拟机的工作原理“
标题:深入探究JVM:解密Java虚拟机的工作原理 摘要:本文将深入探究Java虚拟机(JVM)的工作原理,包括JVM的组成部分、类加载过程、内存管理、垃圾回收机制以及即时编译器等。通过了解JVM的工作原理࿰…...

同济子豪兄模板 半天搞定图像分类
同济子豪兄模板 半天搞定图像分类 ‘’import cv2 import numpy as np import time from tqdm import tqdm 视频逐帧处理代码模板 不需修改任何代码,只需定义process_frame函数即可 def generate_video(input_path‘videos/robot.mp4’): filehead input_path.…...
接口自动化测试,Fiddler使用抓包辅助实战,一篇彻底打通...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、快捷设置&…...
概念解析 | 隐式神经表示:揭开神经网络黑盒的奥秘
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:隐式神经表示(Implicit Neural Representations) 隐式神经表示:揭开神经网络黑盒的奥秘 近年来,神经网络在各种任务上取得了惊人的进步,但其内部表示方式依然难以解读,被称为“…...

深入浅出PHP封装根据商品ID获取淘宝商品详情数据方法
要通过淘宝的API获取商品详情,您可以使用淘宝开放平台提供的接口来实现。以下是一种使用PHP编程语言实现的示例,展示如何通过淘宝开放平台API获取商品详情: 首先,确保您已注册成为淘宝开放平台的开发者,并创建一个应用…...

自动切换HTTP爬虫ip助力Python数据采集
在Python数据采集中,如果你需要爬取一些网站的数据,并且需要切换IP地址来避免被封或限制,我们可以考虑以下几种方式来实现自动切换HTTP爬虫IP。 1. 使用代理服务器 使用代理服务器是常见的IP切换技术之一。你可以购买或使用免费的代理服务器…...
20230811导出Redmi Note12Pro 5G手机的录音机APP的录音
20230811导出Redmi Note12Pro 5G手机的录音机APP的录音 2023/8/11 10:54 redmi note12 pro 录音文件 位置 貌似必须导出录音,录音的源文件不知道存储到哪里了! 参考资料: https://jingyan.baidu.com/article/b87fe19e9aa79b1319356842.html 红…...
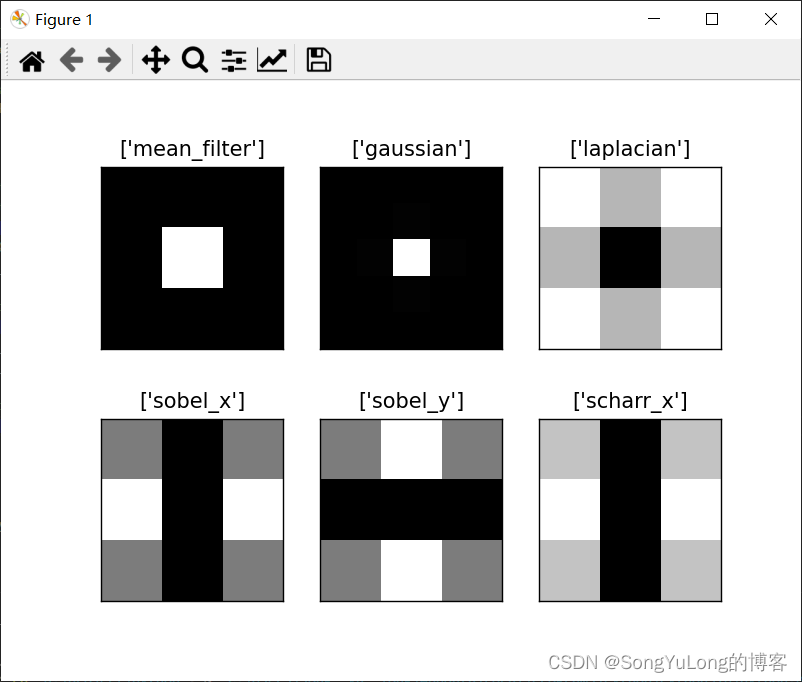
Python-OpenCV中的图像处理-傅里叶变换
Python-OpenCV中的图像处理-傅里叶变换 傅里叶变换Numpy中的傅里叶变换Numpy中的傅里叶逆变换OpenCV中的傅里叶变换OpenCV中的傅里叶逆变换 DFT的性能优化不同滤波算子傅里叶变换对比 傅里叶变换 傅里叶变换经常被用来分析不同滤波器的频率特性。我们可以使用 2D 离散傅里叶变…...

8.10 用redis实现缓存功能和Spring Cache
什么是缓存? 缓存(Cache), 就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码。 通过Redis来缓存数据,减少数据库查询操作; 逻辑 每个分类的菜品保存一份缓存数据 数据库菜品数据有变更时清理缓存数据 如何将商品数据缓存起…...
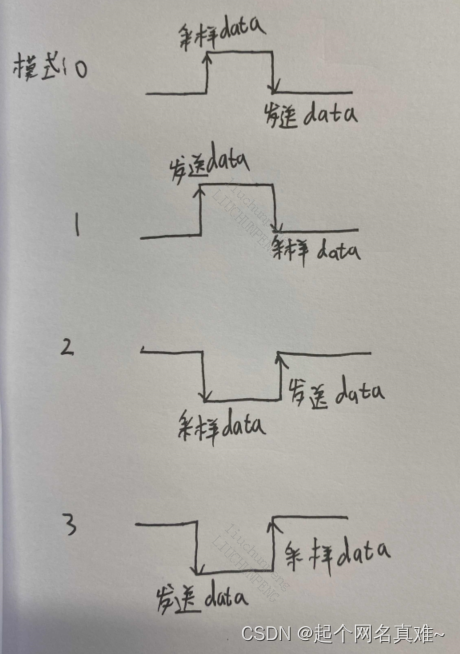
SPI协议个人记录
SPI协议 SPI(Serial Peripheral Interface)是一种同步串行接口技术,由Motorola公司推出。SPI总线系统是一种同步串行外设接口,允许MCU与各种外围设备以串行方式进行通信和数据交换。外围设备包括FLASHRAM、A/D转换器、网络控制器…...

【深度学习 video detect】Towards High Performance Video Object Detection for Mobiles
文章目录 摘要IntroductionRevisiting Video Object Detection BaselinePractice for Mobiles Model Architecture for MobilesLight Flow 摘要 尽管在桌面GPU上取得了视频目标检测的最近成功,但其架构对于移动设备来说仍然过于沉重。目前尚不清楚在非常有限的计算…...

时序预测 | MATLAB实现EEMD-LSTM、LSTM集合经验模态分解结合长短期记忆神经网络时间序列预测对比
时序预测 | MATLAB实现EEMD-LSTM、LSTM集合经验模态分解结合长短期记忆神经网络时间序列预测对比 目录 时序预测 | MATLAB实现EEMD-LSTM、LSTM集合经验模态分解结合长短期记忆神经网络时间序列预测对比效果一览基本介绍模型搭建程序设计参考资料 效果一览 基本介绍 时序预测 | …...
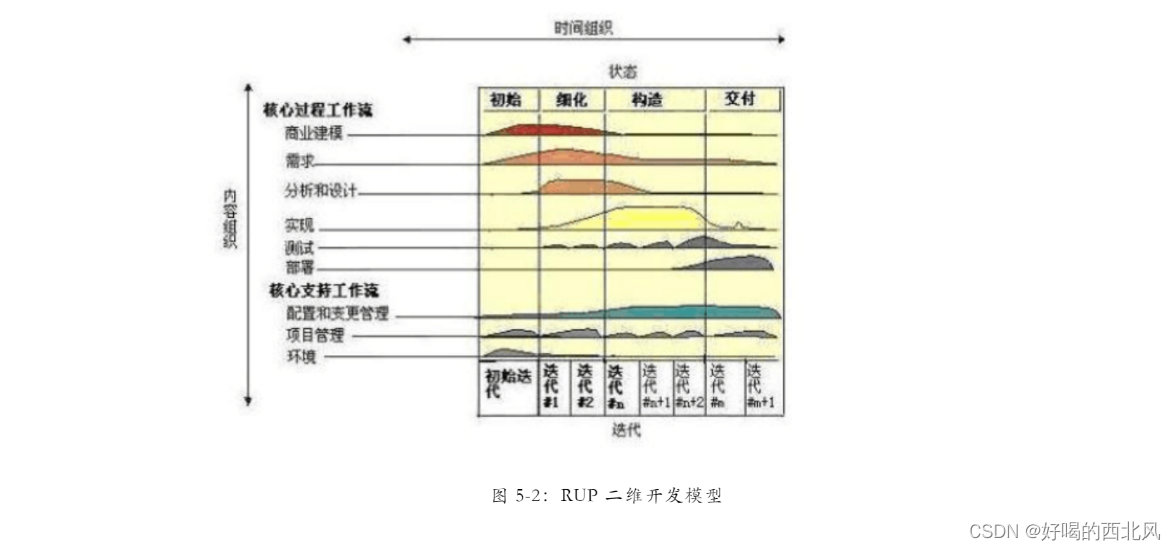
【软件工程】面向对象方法-RUP
RUP(Rational Unified Process,统一软件开发过程)。 RUP特点 以用况驱动的,以体系结构为中心的,迭代增量式开发 用况驱动 用况是能够向用户提供有价值结果的系统中的一种功能用况获取的是功能需求 在系统的生存周期中…...

Golang 的面向对象
文章目录 duck typingnil不一定是空接口组合代替继承接口转换回具体的类型使用switch匹配接口的原始类型 duck typing golang中实现某个接口不需要像其它语言使用 implemet 去继承实现,而是只要你的结构体包含接口所需的方法即可 package mainimport "fmt&qu…...
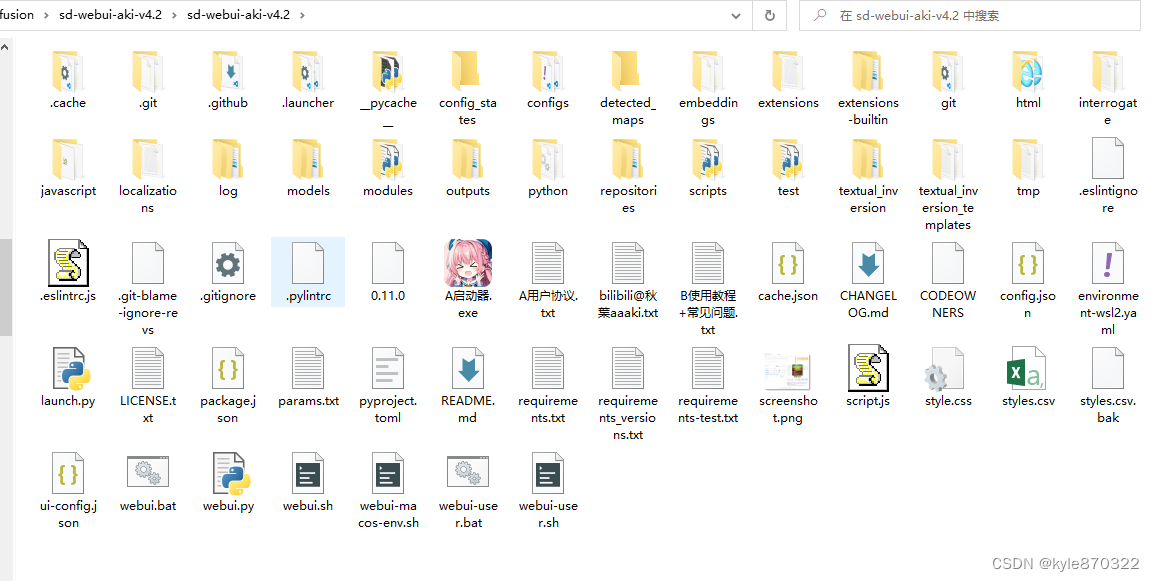
STABLE DIFFUSION模型及插件的存放路径
记录下学习SD的一些心得,使用的是秋叶大佬的集成webui,下载了之后点击启动器即可开启,文件夹中的内容如下 主模型存放在models文件下的stable-diffusion文件夹内,一些扩展类的插件是存放在extensions文件夹下...
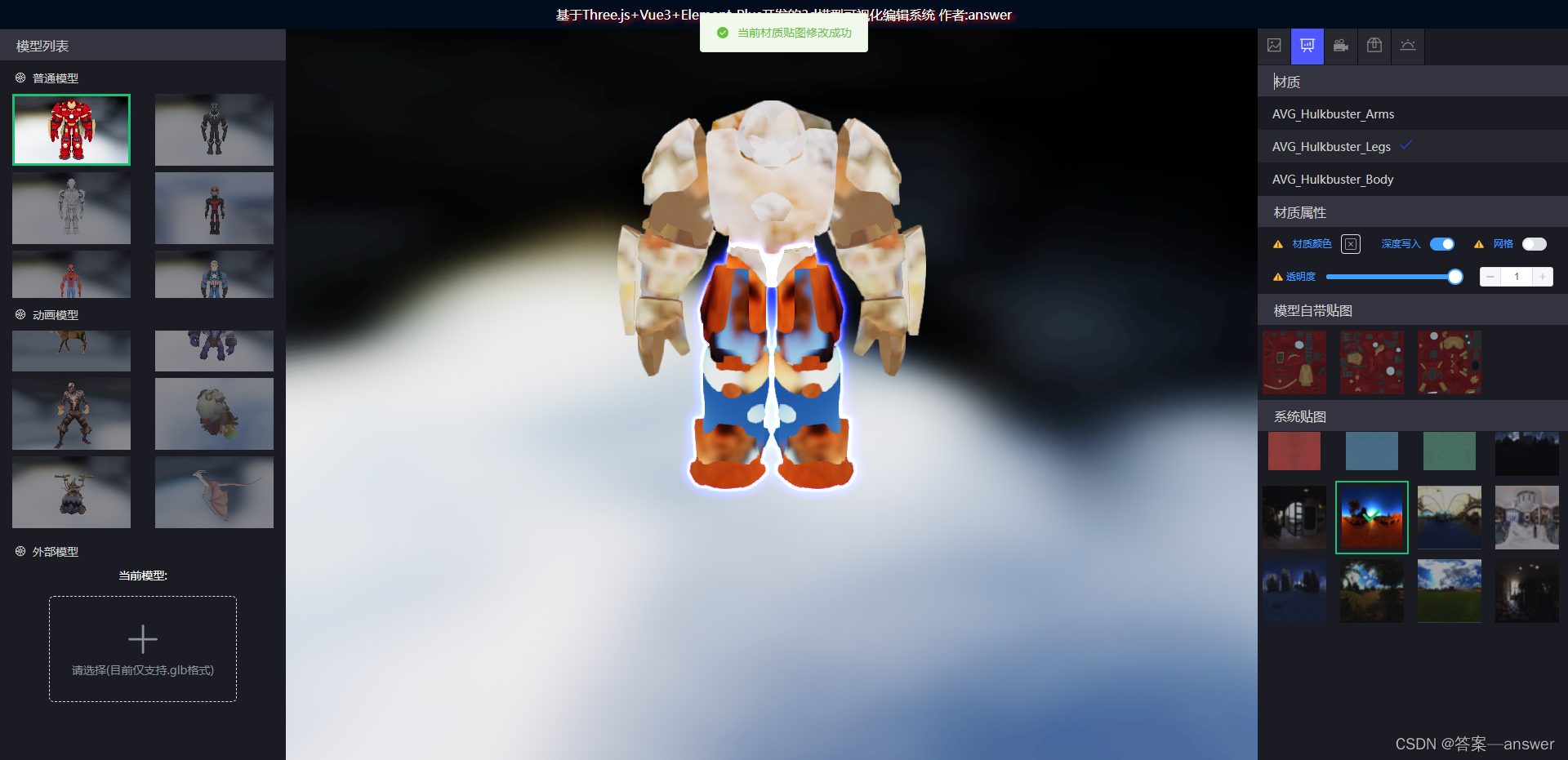
Three.js 设置模型材质纹理贴图和修改材质颜色,材质透明度,材质网格
相关API的使用: 1 traverse (模型循环遍历方法) 2. THREE.TextureLoader(用于加载和处理图片纹理) 3. THREE.MeshLambertMaterial(用于创建材质) 4. getObjectByProperty(通过材…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

孤舟笔记 互联网常用框架篇三 Dubbo是如何动态感知服务下线的?注册中心和服务端双保险
文章目录先说结论机制一:注册中心通知机制二:心跳检测机制三:连接事件感知机制四:定时拉取四种机制的协作回答技巧与点评加分回答面试官点评个人网站微服务环境下,服务实例随时可能上下线——重启、扩容、宕机……调用…...