django使用多个数据库实现
一、说明:
在开发 Django 项目的时候,很多时候都是使用一个数据库,即 settings 中只有 default 数据库,但是有一些项目确实也需要使用多个数据库,这样的项目,在数据库配置和使用的时候,就比较麻烦一点。
二、Django使用多个数据库中settings中的DATABASES的设置
2.1 默认只是用一个数据库时 DATABASES 的设置(以 SQLite 为例)
DATABASES = {'default': {'ENGINE': 'django.db.backends.sqlite3', 'NAME': 'db.sqlite3',}
}
2.2 Django 数据库支持的 ENGINE 类型
-
'django.db.backends.postgresql''django.db.backends.mysql''django.db.backends.sqlite3''django.db.backends.oracle'
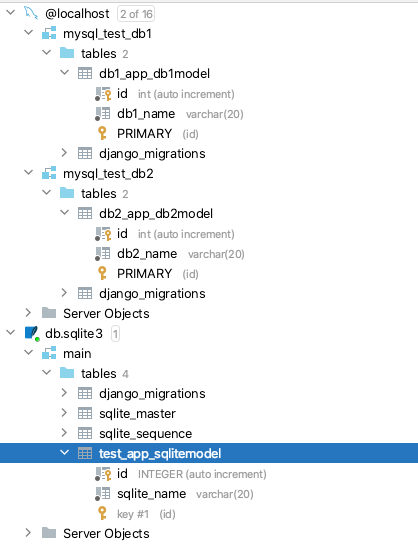
2.3 设置了多个数据库后 settings 中的 DATABASES 的设置
![]()
DATABASES = {'default': {'ENGINE': 'django.db.backends.sqlite3','NAME': 'db.sqlite3',},'db1': {'ENGINE': 'django.db.backends.mysql','NAME': 'mysql_test_db1','USER': 'root','PASSWORD': 'Se7eN521','HOST': '127.0.0.1','PORT': '3306'},'db2': {'ENGINE': 'django.db.backends.mysql','NAME': 'mysql_test_db2','USER': 'root','PASSWORD': 'Se7eN521','HOST': '127.0.0.1','PORT': '3306'}
}
![]()
三、实现思路
- 多个应用对应多个数据库和一个应用对应多个数据库
- 情况一:项目有多个 应用app 且需要使用到多个数据库
- 情况二:项目只有一个应用app, 且但需要使用到多个数据库,
- 这两种情况的实现思路其实都是一样的,都是为每个数据库创建一个应用,即这个应用只对接一个数据库,如果这个应用不需要写任何业务逻辑的代码,也需要创建一个空的应用,主要是用来做数据库迁移的
- 核心思想就是:一个model类对应一个数据库,通过数据库路由和model定义时指定的all_label来实现。
四、案例实现
第一步:创建需要的 应用app,并且在 INSTALLED_APPS 中引用
其中db1_app这个应用主要是用来对接数据库db1的
其中db2_app这个应用主要是用来对接数据库db2的
其中test_app这个应用主要用来实现业务逻辑的

第二步:创建 应用app 和 数据库之间的映射关系
在settings.py 文件夹中设置 DATABASE_APPS_MAPPING 的字典,里面主要是配置 应用app 和数据库的对应关系
DATABASE_APPS_MAPPING = {"db1_app": "db1", # db1_app 对应 db1 数据库"db2_app": "db2" # db2_app 对应 db2 数据库
}
第三步:创建数据库路由
在项目的主文件夹即 settings.py 的同目录下创建一个 database_router.py 文件,该文件的作用就是给不同应用app 配置不同的数据库。
# _*_ coding:utf-8 _*_
# @Time : 2023/4/20 5:37 下午from django.conf import settingsDATABASE_MAPPING = settings.DATABASE_APPS_MAPPING
print('DATABASE_MAPPING = {}'.format(DATABASE_MAPPING))class DatabaseAppsRouter(object):# 设置 应用app 读取时数据库的设置def db_for_read(self, model, **hints)if model._meta.app_label in DATABASE_MAPPING:return DATABASE_MAPPING[model._meta.app_label]return Nonedef db_for_write(self, model, **hints):if model._meta.app_label in DATABASE_MAPPING:return DATABASE_MAPPING[model._meta.app_label]return Nonedef allow_relation(self, obj1, obj2, **hints):db_obj1 = DATABASE_MAPPING.get(obj1._meta.app_label)db_obj2 = DATABASE_MAPPING.get(obj2._meta.app_label)if db_obj1 and db_obj2:if db_obj1 == db_obj2:return Trueelse:return Falsereturn Nonedef allow_migrate(self, db, app_label, model_name=None, **hints):"""Make sure that apps only appear in the related database.根据app_label的值只在相应的数据库中创建一个表,如果删除该def或不指定过滤条件,则一个Model会在每个数据库里都创建一个表。"""if db in DATABASE_MAPPING.values():return DATABASE_MAPPING.get(app_label) == dbelif app_label in DATABASE_MAPPING:return Falsereturn None
第四步:在setting.py中配置 DATABASE_ROUTERS 指定自由路由文件:
#test_django为项目名,database_router为路由文件名,DatabaseAppsRouter为路由中创建的类名 DATABASE_ROUTERS = ['django_db_demo.database_router.DatabaseAppsRouter']
第五步:创建model类
说明:model 可以根据需要卸载任何一个应用app的model.py文件中,也可以分散写在多个应用的model.py中,这个根据自己的需要即可,但是如何推荐一定要在model类的Meta中指定app_label。不然会全部将表创建到default数据库中
from django.db import modelsclass SqliteModel(models.Model):"""帐号和用户关联"""sqlite_name = models.CharField(max_length=20)class Meta:# 当前这个 SqliteModel 定义的数据库的表将会创建在test_app 对应的default 数据库中app_label = "test_app" # 当有多个数据库链接的时候,要通过app_label 来区分这个model对应那个数据库class Db1Model(models.Model):"""帐号和用户关联"""db1_name = models.CharField(max_length=20)class Meta:# 当前这个Db1Model 定义的数据库的表将会创建在 db1_app 对应的 db1 数据库中app_label = "db1_app" # 当有多个数据库链接的时候,要通过app_label 来区分这个model对应那个数据库class Db2Model(models.Model):"""帐号和用户关联"""db2_name = models.CharField(max_length=20)class Meta:# 当前这个Db2Model 定义的数据库的表将会创建在 db2_app 对应的 db1 数据库中app_label = "db2_app" # 当有多个数据库链接的时候,要通过app_label 来区分这个model对应那个数据库
第六步:数据迁移
python3 manage.py makemigrations python3 manage.py migrate --database=default # 当有多个数据库,需要迁移多次 python3 manage.py migrate --database=db1 python3 manage.py migrate --database=db2
第七步:查看迁移:
model对应的表,分别迁移到不同的数据库成功,剩下的增删改查的就正常引入model对象即可,这样就实现了,不同的model对象,对应不用数据库的表。
第五步:总结
- 创建多个数据库连接设置
- 创建多个数据与应用app的映射关系
- 创建数据库路由
- 创建model类的时候置指明app_label,即这个model是属于那个app,从而觉得迁移到那个数据库
相关文章:
django使用多个数据库实现
一、说明: 在开发 Django 项目的时候,很多时候都是使用一个数据库,即 settings 中只有 default 数据库,但是有一些项目确实也需要使用多个数据库,这样的项目,在数据库配置和使用的时候,就比较麻…...

Linux常见面试题,应对面试分享
操作系统基础 1.cpu占⽤率太⾼了怎么办? 排查思路是什么,怎么定位这个问题,处理流程 其他程序: 1.通过top命令按照CPU使⽤率排序找出占⽤资源最⾼的进程 2.lsof查看这个进程在使⽤什么⽂件或者有哪些线程 3.询问开发或者⽼⼤,是什么业务在使⽤这个进程…...
mysql索引的数据结构(Innodb)
首选要注意,这里的数据结构是存储在硬盘上的数据结构,不是内存中的数据结构,要重点考虑io次数. 一.不适合的数据结构: 1.Hash:不适合进行范围查询和模糊匹配查询.(有些数据库索引会使用Hash,但是只能精准匹配) 2.红黑树:可以范围查询和模糊匹配,但是和硬盘io次数比较多. 二…...

【MySQL】Java实现JDBC编程
文章目录 1. JDBC2. 添加驱动包3. 编程3.1 创建数据源3.2 与数据库建立连接3.3 构造SQL语句3.4 执行SQL语句3.5 释放资源,关闭连接 1. JDBC 数据库编程必须掌握至少一门编程语言,一种数据库,会导入数据库驱动包。 操作和连接不同数据库都需要…...
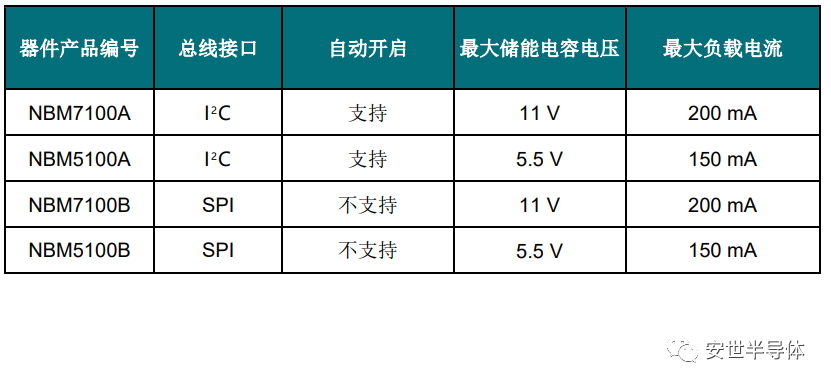
纽扣电池寿命和功率增强器
近日,基础半导体器件领域的高产能生产专家Nexperia(安世半导体)宣布推出NBM7100和NBM5100。这两款IC采用了具有突破意义的创新技术,是专为延长不可充电的典型纽扣锂电池寿命而设计的新型电池寿命增强器,相比于同类解决…...
bilibili倍数脚本,油猴脚本
一. 内容简介 bilibili倍数脚本,油猴脚本 二. 软件环境 2.1 Tampermonkey 三.主要流程 3.1 创建javascript脚本 点击添加新脚本 就是在 (function() {use strict;// 在这编写自己的脚本 })();倍数脚本,含解析 // UserScript // name bi…...
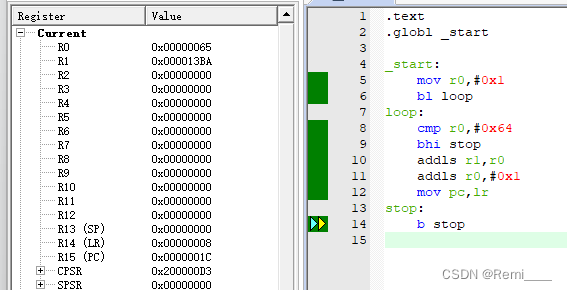
8.14 作业
1. .text .globl _start_start:mov r0,#0x9mov r1,#0xfbl loop loop:cmp r0,r1beq stopsubhi r0,r1subls r1,r0mov pc,lr stop:b stop 2.实现1-100的和 .text .globl _start_start:mov r0,#0x1bl loop loop:cmp r0,#0x64bhi stopaddls r1,r0addls r0,#0x1mov pc,lr stop:b sto…...

Debian安装和使用Elasticsearch 8.9
命令行通过 .deb 包安装 Elasticsearch 创建一个新用户 adduser elastic --> rust # 添加sudo权限 # https://phoenixnap.com/kb/how-to-create-sudo-user-on-ubuntu usermod -aG sudo elastic groups elastic下载Elasticsearch v8.9.0 Debian 包 https://www.elastic.co/…...

三 、CTR预估数据准备
三 CTR预估数据准备 3.1 分析并预处理raw_sample数据集 # 从HDFS中加载样本数据信息 df spark.read.csv("hdfs://localhost:9000/datasets/raw_sample.csv", headerTrue) df.show() # 展示数据,默认前20条 df.printSchema()显示结果: ------------…...
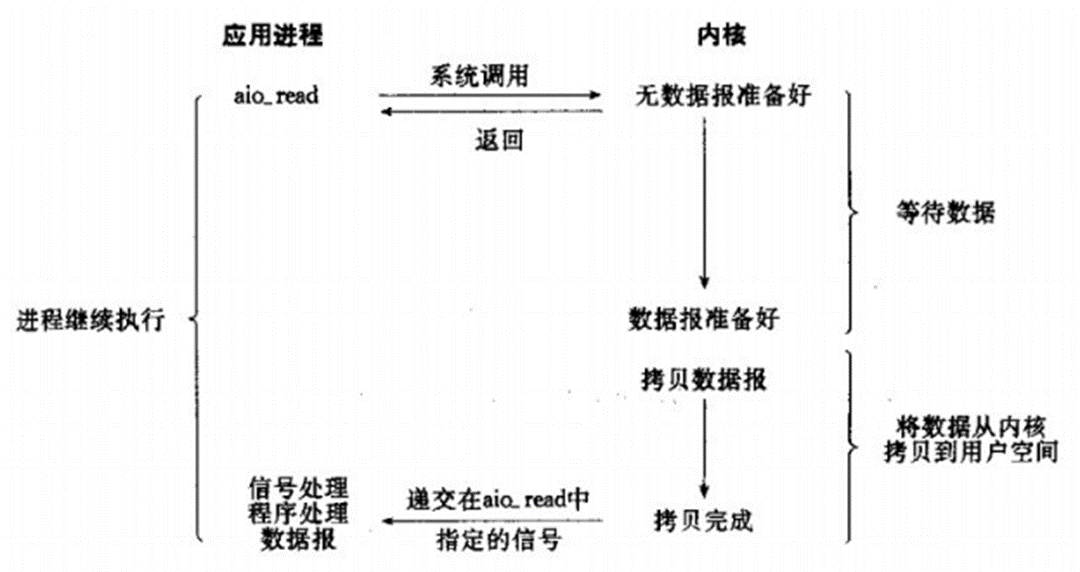
netty学习分享 二
操作系统IO模型与实现原理 阻塞IO 模型 应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。如果数据没有准备好,一直等待….数据准备好了,从内核拷贝到用户空间,IO函数返回成功指示。 当调用recv()函数时,系…...

聊聊web服务器NGINX
文章目录 聊聊web服务器NGINXNGINX的起源NGINX早期阶段首次发布快速扩展模块化架构逐步增加功能商业收购 NGINX能做什么NGINX的优势NGINX为何能兴起 聊聊web服务器NGINX NGINX的起源 NGINX是一个 HTTP 和反向代理服务器,一个邮件代理服务器,以及一个通…...

【hello C++】特殊类设计
目录 一、设计一个类,不能被拷贝 二、设计一个类,只能在堆上创建对象 三、设计一个类,只能在栈上创建对象 四、请设计一个类,不能被继承 五、请设计一个类,只能创建一个对象(单例模式) C🌷 一、设计一个类&…...
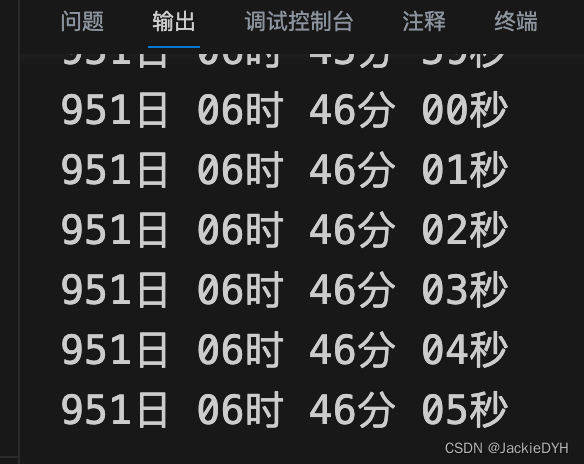
js实现按创建时间戳1609459200000 开始往后开始显示运行时长-demo
运行时长 00日 00时 17分 59秒 代码 function calculateRuntime(timestamp) {const startTime Date.now(); // 获取当前时间戳//const runtimeElement document.getElementById(runtime); // 获取显示运行时长的元素function updateRuntime() {const currentTimestamp Date…...
latex三线表按页面大小填充
latex三线表按页面大小填充 使用Latex表格时会出现下图情况,表格没有填充整个页面,导致不美观。 解决方法: 在\begin{tabular}前加上\resizebox{\linewidth}{!}{ , 在\end{tabular} 后加 ‘}’ 如下:\resizebox{…...
佛祖保佑,永不宕机,永无bug
当我们的程序编译通过,能预防的bug也都预防了,其它的就只能交给天意了。当然请求佛祖的保佑也是必不可少的。 下面是一些常用的保佑图: 佛祖保佑图 ——————————————————————————————————————————…...

redis分布式集群-redis+keepalived+ haproxy
redis分布式集群架构(RedisKeepalivedHaproxy)至少需要3台服务器、6个节点,一台服务器2个节点。 redis分布式集群架构中的每台服务器都使用六个端口来实现多路复用,最终实现主从热备、负载均衡、秒级切换的目标。 redis分布式集…...
快递管理系统springboot 寄件物流仓库java jsp源代码mysql
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 快递管理系统springboot 系统有1权限:管…...
自学黑客/网络安全(学习路线+教程视频+工具包+经验分享)
一、为什么选择网络安全? 这几年随着我国《国家网络空间安全战略》《网络安全法》《网络安全等级保护2.0》等一系列政策/法规/标准的持续落地,网络安全行业地位、薪资随之水涨船高。 未来3-5年,是安全行业的黄金发展期,提前踏入…...
如何进行游戏平台搭建?
游戏平台搭建涉及多个步骤和技术,下面是一个大致的指南: 市场调研和定位:首先,要了解游戏市场和受众的需求,选择适合的游戏类型和定位。 选择平台类型:决定是要搭建网页平台、移动应用平台还是其他类型的…...

安全防御问题
SSL VPN的实现,防火墙需要放行哪些流量? 实现 SSL VPN 时,在防火墙上需要放行以下流量, SSL/TLS 流量:SSL VPN 通过加密通信来确保安全性,因此防火墙需要允许 SSL/TLS 流量通过。一般情况下,SSL…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

抖音批量下载助手:一键构建你的专属视频素材库
抖音批量下载助手:一键构建你的专属视频素材库 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为手动保存抖音视频而烦恼吗?想要批量获取心仪创作者的精彩内容却无从下手&#x…...

如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南
如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南 【免费下载链接】genshin-impact-script 原神脚本,包含自动钓鱼、自动拾取、自动跳过对话等多项实用功能。A Genshin Impact script includes many useful features such as automatic fishing…...

语音AI落地最后一公里卡点,PlayAI质量波动真相:采样率适配缺陷、韵律断层、情感衰减三大隐性陷阱
更多请点击: https://intelliparadigm.com 第一章:PlayAI语音质量评测报告总览 PlayAI语音质量评测体系基于客观指标与主观听感双维度构建,覆盖清晰度、自然度、时延、抗噪性及情感一致性五大核心能力。本报告汇总了在标准测试集(…...

关于我第九次博客作业
(1)Flex布局核心概念一、Flex 是什么Flex 是 CSS3 一维弹性布局,专治元素对齐、自适应、空间分配问题,布局更高效灵活。二、两大核心角色1. 父容器(Flex容器)设置 display: flex 即为弹性父盒子,负责统一规定子元素排列…...