三 、CTR预估数据准备
三 CTR预估数据准备
3.1 分析并预处理raw_sample数据集
# 从HDFS中加载样本数据信息
df = spark.read.csv("hdfs://localhost:9000/datasets/raw_sample.csv", header=True)
df.show() # 展示数据,默认前20条
df.printSchema()
显示结果:
+------+----------+----------+-----------+------+---+
| user|time_stamp|adgroup_id| pid|nonclk|clk|
+------+----------+----------+-----------+------+---+
|581738|1494137644| 1|430548_1007| 1| 0|
|449818|1494638778| 3|430548_1007| 1| 0|
|914836|1494650879| 4|430548_1007| 1| 0|
|914836|1494651029| 5|430548_1007| 1| 0|
|399907|1494302958| 8|430548_1007| 1| 0|
|628137|1494524935| 9|430548_1007| 1| 0|
|298139|1494462593| 9|430539_1007| 1| 0|
|775475|1494561036| 9|430548_1007| 1| 0|
|555266|1494307136| 11|430539_1007| 1| 0|
|117840|1494036743| 11|430548_1007| 1| 0|
|739815|1494115387| 11|430539_1007| 1| 0|
|623911|1494625301| 11|430548_1007| 1| 0|
|623911|1494451608| 11|430548_1007| 1| 0|
|421590|1494034144| 11|430548_1007| 1| 0|
|976358|1494156949| 13|430548_1007| 1| 0|
|286630|1494218579| 13|430539_1007| 1| 0|
|286630|1494289247| 13|430539_1007| 1| 0|
|771431|1494153867| 13|430548_1007| 1| 0|
|707120|1494220810| 13|430548_1007| 1| 0|
|530454|1494293746| 13|430548_1007| 1| 0|
+------+----------+----------+-----------+------+---+
only showing top 20 rowsroot|-- user: string (nullable = true)|-- time_stamp: string (nullable = true)|-- adgroup_id: string (nullable = true)|-- pid: string (nullable = true)|-- nonclk: string (nullable = true)|-- clk: string (nullable = true)
- 分析数据集字段的类型和格式
- 查看是否有空值
- 查看每列数据的类型
- 查看每列数据的类别情况
print("样本数据集总条目数:", df.count())
# 约2600w
print("用户user总数:", df.groupBy("user").count().count())
# 约 114w,略多余日志数据中用户数
print("广告id adgroup_id总数:", df.groupBy("adgroup_id").count().count())
# 约85w
print("广告展示位pid情况:", df.groupBy("pid").count().collect())
# 只有两种广告展示位,占比约为六比四
print("广告点击数据情况clk:", df.groupBy("clk").count().collect())
# 点和不点比率约: 1:20
显示结果:
样本数据集总条目数: 26557961
用户user总数: 1141729
广告id adgroup_id总数: 846811
广告展示位pid情况: [Row(pid='430548_1007', count=16472898), Row(pid='430539_1007', count=10085063)]
广告点击数据情况clk: [Row(clk='0', count=25191905), Row(clk='1', count=1366056)]
- 使用dataframe.withColumn更改df列数据结构;使用dataframe.withColumnRenamed更改列名称
# 更改表结构,转换为对应的数据类型
from pyspark.sql.types import StructType, StructField, IntegerType, FloatType, LongType, StringType# 打印df结构信息
df.printSchema()
# 更改df表结构:更改列类型和列名称
raw_sample_df = df.\withColumn("user", df.user.cast(IntegerType())).withColumnRenamed("user", "userId").\withColumn("time_stamp", df.time_stamp.cast(LongType())).withColumnRenamed("time_stamp", "timestamp").\withColumn("adgroup_id", df.adgroup_id.cast(IntegerType())).withColumnRenamed("adgroup_id", "adgroupId").\withColumn("pid", df.pid.cast(StringType())).\withColumn("nonclk", df.nonclk.cast(IntegerType())).\withColumn("clk", df.clk.cast(IntegerType()))
raw_sample_df.printSchema()
raw_sample_df.show()
显示结果:
root|-- user: string (nullable = true)|-- time_stamp: string (nullable = true)|-- adgroup_id: string (nullable = true)|-- pid: string (nullable = true)|-- nonclk: string (nullable = true)|-- clk: string (nullable = true)root|-- userId: integer (nullable = true)|-- timestamp: long (nullable = true)|-- adgroupId: integer (nullable = true)|-- pid: string (nullable = true)|-- nonclk: integer (nullable = true)|-- clk: integer (nullable = true)+------+----------+---------+-----------+------+---+
|userId| timestamp|adgroupId| pid|nonclk|clk|
+------+----------+---------+-----------+------+---+
|581738|1494137644| 1|430548_1007| 1| 0|
|449818|1494638778| 3|430548_1007| 1| 0|
|914836|1494650879| 4|430548_1007| 1| 0|
|914836|1494651029| 5|430548_1007| 1| 0|
|399907|1494302958| 8|430548_1007| 1| 0|
|628137|1494524935| 9|430548_1007| 1| 0|
|298139|1494462593| 9|430539_1007| 1| 0|
|775475|1494561036| 9|430548_1007| 1| 0|
|555266|1494307136| 11|430539_1007| 1| 0|
|117840|1494036743| 11|430548_1007| 1| 0|
|739815|1494115387| 11|430539_1007| 1| 0|
|623911|1494625301| 11|430548_1007| 1| 0|
|623911|1494451608| 11|430548_1007| 1| 0|
|421590|1494034144| 11|430548_1007| 1| 0|
|976358|1494156949| 13|430548_1007| 1| 0|
|286630|1494218579| 13|430539_1007| 1| 0|
|286630|1494289247| 13|430539_1007| 1| 0|
|771431|1494153867| 13|430548_1007| 1| 0|
|707120|1494220810| 13|430548_1007| 1| 0|
|530454|1494293746| 13|430548_1007| 1| 0|
+------+----------+---------+-----------+------+---+
only showing top 20 rows
-
特征选取(Feature Selection)
-
特征选择就是选择那些靠谱的Feature,去掉冗余的Feature,对于搜索广告,Query关键词和广告的匹配程度很重要;但对于展示广告,广告本身的历史表现,往往是最重要的Feature。
根据经验,该数据集中,只有广告展示位pid对比较重要,且数据不同数据之间的占比约为6:4,因此pid可以作为一个关键特征
nonclk和clk在这里是作为目标值,不做为特征
-
-
热独编码 OneHotEncode
-
热独编码是一种经典编码,是使用N位状态寄存器(如0和1)来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
假设有三组特征,分别表示年龄,城市,设备;
[“男”, “女”][0,1]
[“北京”, “上海”, “广州”][0,1,2]
[“苹果”, “小米”, “华为”, “微软”][0,1,2,3]
传统变化: 对每一组特征,使用枚举类型,从0开始;
["男“,”上海“,”小米“]=[ 0,1,1]
["女“,”北京“,”苹果“] =[1,0,0]
传统变化后的数据不是连续的,而是随机分配的,不容易应用在分类器中
而经过热独编码,数据会变成稀疏的,方便分类器处理:
["男“,”上海“,”小米“]=[ 1,0,0,1,0,0,1,0,0]
["女“,”北京“,”苹果“] =[0,1,1,0,0,1,0,0,0]
这样做保留了特征的多样性,但是也要注意如果数据过于稀疏(样本较少、维度过高),其效果反而会变差
-
-
Spark中使用热独编码
-
注意:热编码只能对字符串类型的列数据进行处理
StringIndexer:对指定字符串列数据进行特征处理,如将性别数据“男”、“女”转化为0和1
OneHotEncoder:对特征列数据,进行热编码,通常需结合StringIndexer一起使用
Pipeline:让数据按顺序依次被处理,将前一次的处理结果作为下一次的输入
-
-
特征处理
'''特征处理'''
'''
pid 资源位。该特征属于分类特征,只有两类取值,因此考虑进行热编码处理即可,分为是否在资源位1、是否在资源位2 两个特征
'''
from pyspark.ml.feature import OneHotEncoder
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline# StringIndexer对指定字符串列进行特征处理
stringindexer = StringIndexer(inputCol='pid', outputCol='pid_feature')# 对处理出来的特征处理列进行,热独编码
encoder = OneHotEncoder(dropLast=False, inputCol='pid_feature', outputCol='pid_value')
# 利用管道对每一个数据进行热独编码处理
pipeline = Pipeline(stages=[stringindexer, encoder])
pipeline_model = pipeline.fit(raw_sample_df)
new_df = pipeline_model.transform(raw_sample_df)
new_df.show()
显示结果:
+------+----------+---------+-----------+------+---+-----------+-------------+
|userId| timestamp|adgroupId| pid|nonclk|clk|pid_feature| pid_value|
+------+----------+---------+-----------+------+---+-----------+-------------+
|581738|1494137644| 1|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|449818|1494638778| 3|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|914836|1494650879| 4|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|914836|1494651029| 5|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|399907|1494302958| 8|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|628137|1494524935| 9|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|298139|1494462593| 9|430539_1007| 1| 0| 1.0|(2,[1],[1.0])|
|775475|1494561036| 9|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|555266|1494307136| 11|430539_1007| 1| 0| 1.0|(2,[1],[1.0])|
|117840|1494036743| 11|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|739815|1494115387| 11|430539_1007| 1| 0| 1.0|(2,[1],[1.0])|
|623911|1494625301| 11|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|623911|1494451608| 11|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|421590|1494034144| 11|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|976358|1494156949| 13|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|286630|1494218579| 13|430539_1007| 1| 0| 1.0|(2,[1],[1.0])|
|286630|1494289247| 13|430539_1007| 1| 0| 1.0|(2,[1],[1.0])|
|771431|1494153867| 13|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|707120|1494220810| 13|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|530454|1494293746| 13|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
+------+----------+---------+-----------+------+---+-----------+-------------+
only showing top 20 rows- 返回字段pid_value是一个稀疏向量类型数据 pyspark.ml.linalg.SparseVector
from pyspark.ml.linalg import SparseVector
# 参数:维度、索引列表、值列表
print(SparseVector(4, [1, 3], [3.0, 4.0]))
print(SparseVector(4, [1, 3], [3.0, 4.0]).toArray())
print("*********")
print(new_df.select("pid_value").first())
print(new_df.select("pid_value").first().pid_value.toArray())
显示结果:
(4,[1,3],[3.0,4.0])
[0. 3. 0. 4.]
*********
Row(pid_value=SparseVector(2, {0: 1.0}))
[1. 0.]- 查看最大时间
new_df.sort("timestamp", ascending=False).show()
+------+----------+---------+-----------+------+---+-----------+-------------+
|userId| timestamp|adgroupId| pid|nonclk|clk|pid_feature| pid_value|
+------+----------+---------+-----------+------+---+-----------+-------------+
|177002|1494691186| 593001|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|243671|1494691186| 600195|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|488527|1494691184| 494312|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|488527|1494691184| 431082|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
| 17054|1494691184| 742741|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
| 17054|1494691184| 756665|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|488527|1494691184| 687854|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|839493|1494691183| 561681|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|704223|1494691183| 624504|430539_1007| 1| 0| 1.0|(2,[1],[1.0])|
|839493|1494691183| 582235|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|704223|1494691183| 675674|430539_1007| 1| 0| 1.0|(2,[1],[1.0])|
|628998|1494691180| 618965|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|674444|1494691179| 427579|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|627200|1494691179| 782038|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|627200|1494691179| 420769|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|674444|1494691179| 588664|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|738335|1494691179| 451004|430539_1007| 1| 0| 1.0|(2,[1],[1.0])|
|627200|1494691179| 817569|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|322244|1494691179| 820018|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
|322244|1494691179| 735220|430548_1007| 1| 0| 0.0|(2,[0],[1.0])|
+------+----------+---------+-----------+------+---+-----------+-------------+
only showing top 20 rows
# 本样本数据集共计8天数据
# 前七天为训练数据、最后一天为测试数据from datetime import datetime
datetime.fromtimestamp(1494691186)
print("该时间之前的数据为训练样本,该时间以后的数据为测试样本:", datetime.fromtimestamp(1494691186-24*60*60))
显示结果:
该时间之前的数据为训练样本,该时间以后的数据为测试样本: 2017-05-12 23:59:46- 训练样本
# 训练样本:
train_sample = raw_sample_df.filter(raw_sample_df.timestamp<=(1494691186-24*60*60))
print("训练样本个数:")
print(train_sample.count())
# 测试样本
test_sample = raw_sample_df.filter(raw_sample_df.timestamp>(1494691186-24*60*60))
print("测试样本个数:")
print(test_sample.count())# 注意:还需要加入广告基本特征和用户基本特征才能做程一份完整的样本数据集
显示结果:
训练样本个数:
23249291
测试样本个数:
33086703.2 分析并预处理ad_feature数据集
# 从HDFS中加载广告基本信息数据,返回spark dafaframe对象
df = spark.read.csv("hdfs://localhost:9000/datasets/ad_feature.csv", header=True)
df.show() # 展示数据,默认前20条
显示结果:
+----------+-------+-----------+--------+------+-----+
|adgroup_id|cate_id|campaign_id|customer| brand|price|
+----------+-------+-----------+--------+------+-----+
| 63133| 6406| 83237| 1| 95471|170.0|
| 313401| 6406| 83237| 1| 87331|199.0|
| 248909| 392| 83237| 1| 32233| 38.0|
| 208458| 392| 83237| 1|174374|139.0|
| 110847| 7211| 135256| 2|145952|32.99|
| 607788| 6261| 387991| 6|207800|199.0|
| 375706| 4520| 387991| 6| NULL| 99.0|
| 11115| 7213| 139747| 9|186847| 33.0|
| 24484| 7207| 139744| 9|186847| 19.0|
| 28589| 5953| 395195| 13| NULL|428.0|
| 23236| 5953| 395195| 13| NULL|368.0|
| 300556| 5953| 395195| 13| NULL|639.0|
| 92560| 5953| 395195| 13| NULL|368.0|
| 590965| 4284| 28145| 14|454237|249.0|
| 529913| 4284| 70206| 14| NULL|249.0|
| 546930| 4284| 28145| 14| NULL|249.0|
| 639794| 6261| 70206| 14| 37004| 89.9|
| 335413| 4284| 28145| 14| NULL|249.0|
| 794890| 4284| 70206| 14|454237|249.0|
| 684020| 6261| 70206| 14| 37004| 99.0|
+----------+-------+-----------+--------+------+-----+
only showing top 20 rows
# 注意:由于本数据集中存在NULL字样的数据,无法直接设置schema,只能先将NULL类型的数据处理掉,然后进行类型转换from pyspark.sql.types import StructType, StructField, IntegerType, FloatType# 替换掉NULL字符串,替换掉
df = df.replace("NULL", "-1")# 打印df结构信息
df.printSchema()
# 更改df表结构:更改列类型和列名称
ad_feature_df = df.\withColumn("adgroup_id", df.adgroup_id.cast(IntegerType())).withColumnRenamed("adgroup_id", "adgroupId").\withColumn("cate_id", df.cate_id.cast(IntegerType())).withColumnRenamed("cate_id", "cateId").\withColumn("campaign_id", df.campaign_id.cast(IntegerType())).withColumnRenamed("campaign_id", "campaignId").\withColumn("customer", df.customer.cast(IntegerType())).withColumnRenamed("customer", "customerId").\withColumn("brand", df.brand.cast(IntegerType())).withColumnRenamed("brand", "brandId").\withColumn("price", df.price.cast(FloatType()))
ad_feature_df.printSchema()
ad_feature_df.show()
显示结果:
root|-- adgroup_id: string (nullable = true)|-- cate_id: string (nullable = true)|-- campaign_id: string (nullable = true)|-- customer: string (nullable = true)|-- brand: string (nullable = true)|-- price: string (nullable = true)root|-- adgroupId: integer (nullable = true)|-- cateId: integer (nullable = true)|-- campaignId: integer (nullable = true)|-- customerId: integer (nullable = true)|-- brandId: integer (nullable = true)|-- price: float (nullable = true)+---------+------+----------+----------+-------+-----+
|adgroupId|cateId|campaignId|customerId|brandId|price|
+---------+------+----------+----------+-------+-----+
| 63133| 6406| 83237| 1| 95471|170.0|
| 313401| 6406| 83237| 1| 87331|199.0|
| 248909| 392| 83237| 1| 32233| 38.0|
| 208458| 392| 83237| 1| 174374|139.0|
| 110847| 7211| 135256| 2| 145952|32.99|
| 607788| 6261| 387991| 6| 207800|199.0|
| 375706| 4520| 387991| 6| -1| 99.0|
| 11115| 7213| 139747| 9| 186847| 33.0|
| 24484| 7207| 139744| 9| 186847| 19.0|
| 28589| 5953| 395195| 13| -1|428.0|
| 23236| 5953| 395195| 13| -1|368.0|
| 300556| 5953| 395195| 13| -1|639.0|
| 92560| 5953| 395195| 13| -1|368.0|
| 590965| 4284| 28145| 14| 454237|249.0|
| 529913| 4284| 70206| 14| -1|249.0|
| 546930| 4284| 28145| 14| -1|249.0|
| 639794| 6261| 70206| 14| 37004| 89.9|
| 335413| 4284| 28145| 14| -1|249.0|
| 794890| 4284| 70206| 14| 454237|249.0|
| 684020| 6261| 70206| 14| 37004| 99.0|
+---------+------+----------+----------+-------+-----+
only showing top 20 rows
- 查看各项数据的特征
print("总广告条数:",df.count()) # 数据条数
_1 = ad_feature_df.groupBy("cateId").count().count()
print("cateId数值个数:", _1)
_2 = ad_feature_df.groupBy("campaignId").count().count()
print("campaignId数值个数:", _2)
_3 = ad_feature_df.groupBy("customerId").count().count()
print("customerId数值个数:", _3)
_4 = ad_feature_df.groupBy("brandId").count().count()
print("brandId数值个数:", _4)
ad_feature_df.sort("price").show()
ad_feature_df.sort("price", ascending=False).show()
print("价格高于1w的条目个数:", ad_feature_df.select("price").filter("price>10000").count())
print("价格低于1的条目个数", ad_feature_df.select("price").filter("price<1").count())
显示结果:
总广告条数: 846811
cateId数值个数: 6769
campaignId数值个数: 423436
customerId数值个数: 255875
brandId数值个数: 99815
+---------+------+----------+----------+-------+-----+
|adgroupId|cateId|campaignId|customerId|brandId|price|
+---------+------+----------+----------+-------+-----+
| 485749| 9970| 352666| 140520| -1| 0.01|
| 88975| 9996| 198424| 182415| -1| 0.01|
| 109704| 10539| 59774| 90351| 202710| 0.01|
| 49911| 7032| 129079| 172334| -1| 0.01|
| 339334| 9994| 310408| 211292| 383023| 0.01|
| 6636| 6703| 392038| 46239| 406713| 0.01|
| 92241| 6130| 72781| 149714| -1| 0.01|
| 20397| 10539| 410958| 65726| 79971| 0.01|
| 345870| 9995| 179595| 191036| 79971| 0.01|
| 77797| 9086| 218276| 31183| -1| 0.01|
| 14435| 1136| 135610| 17788| -1| 0.01|
| 42055| 9994| 43866| 113068| 123242| 0.01|
| 41925| 7032| 85373| 114532| -1| 0.01|
| 67558| 9995| 90141| 83948| -1| 0.01|
| 149570| 7043| 126746| 176076| -1| 0.01|
| 518883| 7185| 403318| 58013| -1| 0.01|
| 2246| 9996| 413653| 60214| 182966| 0.01|
| 290675| 4824| 315371| 240984| -1| 0.01|
| 552638| 10305| 403318| 58013| -1| 0.01|
| 89831| 10539| 90141| 83948| 211816| 0.01|
+---------+------+----------+----------+-------+-----+
only showing top 20 rows+---------+------+----------+----------+-------+-----------+
|adgroupId|cateId|campaignId|customerId|brandId| price|
+---------+------+----------+----------+-------+-----------+
| 658722| 1093| 218101| 207754| -1| 1.0E8|
| 468220| 1093| 270719| 207754| -1| 1.0E8|
| 179746| 1093| 270027| 102509| 405447| 1.0E8|
| 443295| 1093| 44251| 102509| 300681| 1.0E8|
| 31899| 685| 218918| 31239| 278301| 1.0E8|
| 243384| 685| 218918| 31239| 278301| 1.0E8|
| 554311| 1093| 266086| 207754| -1| 1.0E8|
| 513942| 745| 8401| 86243| -1|8.8888888E7|
| 201060| 745| 8401| 86243| -1|5.5555556E7|
| 289563| 685| 37665| 120847| 278301| 1.5E7|
| 35156| 527| 417722| 72273| 278301| 1.0E7|
| 33756| 527| 416333| 70894| -1| 9900000.0|
| 335495| 739| 170121| 148946| 326126| 9600000.0|
| 218306| 206| 162394| 4339| 221720| 8888888.0|
| 213567| 7213| 239302| 205612| 406125| 5888888.0|
| 375920| 527| 217512| 148946| 326126| 4760000.0|
| 262215| 527| 132721| 11947| 417898| 3980000.0|
| 154623| 739| 170121| 148946| 326126| 3900000.0|
| 152414| 739| 170121| 148946| 326126| 3900000.0|
| 448651| 527| 422260| 41289| 209959| 3800000.0|
+---------+------+----------+----------+-------+-----------+
only showing top 20 rows价格高于1w的条目个数: 6527
价格低于1的条目个数 5762-
特征选择
- cateId:脱敏过的商品类目ID;
- campaignId:脱敏过的广告计划ID;
- customerId:脱敏过的广告主ID;
- brandId:脱敏过的品牌ID;
以上四个特征均属于分类特征,但由于分类值个数均过于庞大,如果去做热独编码处理,会导致数据过于稀疏 且当前我们缺少对这些特征更加具体的信息,(如商品类目具体信息、品牌具体信息等),从而无法对这些特征的数据做聚类、降维处理 因此这里不选取它们作为特征
而只选取price作为特征数据,因为价格本身是一个统计类型连续数值型数据,且能很好的体现广告的价值属性特征,通常也不需要做其他处理(离散化、归一化、标准化等),所以这里直接将当做特征数据来使用
3.3 分析并预处理user_profile数据集
# 从HDFS加载用户基本信息数据
df = spark.read.csv("hdfs://localhost:8020/csv/user_profile.csv", header=True)
# 发现pvalue_level和new_user_class_level存在空值:(注意此处的null表示空值,而如果是NULL,则往往表示是一个字符串)
# 因此直接利用schema就可以加载进该数据,无需替换null值
df.show()
显示结果:
+------+---------+------------+-----------------+---------+------------+--------------+----------+---------------------+
|userid|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level |
+------+---------+------------+-----------------+---------+------------+--------------+----------+---------------------+
| 234| 0| 5| 2| 5| null| 3| 0| 3|
| 523| 5| 2| 2| 2| 1| 3| 1| 2|
| 612| 0| 8| 1| 2| 2| 3| 0| null|
| 1670| 0| 4| 2| 4| null| 1| 0| null|
| 2545| 0| 10| 1| 4| null| 3| 0| null|
| 3644| 49| 6| 2| 6| 2| 3| 0| 2|
| 5777| 44| 5| 2| 5| 2| 3| 0| 2|
| 6211| 0| 9| 1| 3| null| 3| 0| 2|
| 6355| 2| 1| 2| 1| 1| 3| 0| 4|
| 6823| 43| 5| 2| 5| 2| 3| 0| 1|
| 6972| 5| 2| 2| 2| 2| 3| 1| 2|
| 9293| 0| 5| 2| 5| null| 3| 0| 4|
| 9510| 55| 8| 1| 2| 2| 2| 0| 2|
| 10122| 33| 4| 2| 4| 2| 3| 0| 2|
| 10549| 0| 4| 2| 4| 2| 3| 0| null|
| 10812| 0| 4| 2| 4| null| 2| 0| null|
| 10912| 0| 4| 2| 4| 2| 3| 0| null|
| 10996| 0| 5| 2| 5| null| 3| 0| 4|
| 11256| 8| 2| 2| 2| 1| 3| 0| 3|
| 11310| 31| 4| 2| 4| 1| 3| 0| 4|
+------+---------+------------+-----------------+---------+------------+--------------+----------+---------------------+
# 注意:这里的null会直接被pyspark识别为None数据,也就是na数据,所以这里可以直接利用schema导入数据from pyspark.sql.types import StructType, StructField, StringType, IntegerType, LongType, FloatType# 构建表结构schema对象
schema = StructType([StructField("userId", IntegerType()),StructField("cms_segid", IntegerType()),StructField("cms_group_id", IntegerType()),StructField("final_gender_code", IntegerType()),StructField("age_level", IntegerType()),StructField("pvalue_level", IntegerType()),StructField("shopping_level", IntegerType()),StructField("occupation", IntegerType()),StructField("new_user_class_level", IntegerType())
])
# 利用schema从hdfs加载
user_profile_df = spark.read.csv("hdfs://localhost:8020/csv/user_profile.csv", header=True, schema=schema)
user_profile_df.printSchema()
user_profile_df.show()
显示结果:
root|-- userId: integer (nullable = true)|-- cms_segid: integer (nullable = true)|-- cms_group_id: integer (nullable = true)|-- final_gender_code: integer (nullable = true)|-- age_level: integer (nullable = true)|-- pvalue_level: integer (nullable = true)|-- shopping_level: integer (nullable = true)|-- occupation: integer (nullable = true)|-- new_user_class_level: integer (nullable = true)+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
|userId|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
| 234| 0| 5| 2| 5| null| 3| 0| 3|
| 523| 5| 2| 2| 2| 1| 3| 1| 2|
| 612| 0| 8| 1| 2| 2| 3| 0| null|
| 1670| 0| 4| 2| 4| null| 1| 0| null|
| 2545| 0| 10| 1| 4| null| 3| 0| null|
| 3644| 49| 6| 2| 6| 2| 3| 0| 2|
| 5777| 44| 5| 2| 5| 2| 3| 0| 2|
| 6211| 0| 9| 1| 3| null| 3| 0| 2|
| 6355| 2| 1| 2| 1| 1| 3| 0| 4|
| 6823| 43| 5| 2| 5| 2| 3| 0| 1|
| 6972| 5| 2| 2| 2| 2| 3| 1| 2|
| 9293| 0| 5| 2| 5| null| 3| 0| 4|
| 9510| 55| 8| 1| 2| 2| 2| 0| 2|
| 10122| 33| 4| 2| 4| 2| 3| 0| 2|
| 10549| 0| 4| 2| 4| 2| 3| 0| null|
| 10812| 0| 4| 2| 4| null| 2| 0| null|
| 10912| 0| 4| 2| 4| 2| 3| 0| null|
| 10996| 0| 5| 2| 5| null| 3| 0| 4|
| 11256| 8| 2| 2| 2| 1| 3| 0| 3|
| 11310| 31| 4| 2| 4| 1| 3| 0| 4|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
only showing top 20 rows
- 显示特征情况
print("分类特征值个数情况: ")
print("cms_segid: ", user_profile_df.groupBy("cms_segid").count().count())
print("cms_group_id: ", user_profile_df.groupBy("cms_group_id").count().count())
print("final_gender_code: ", user_profile_df.groupBy("final_gender_code").count().count())
print("age_level: ", user_profile_df.groupBy("age_level").count().count())
print("shopping_level: ", user_profile_df.groupBy("shopping_level").count().count())
print("occupation: ", user_profile_df.groupBy("occupation").count().count())print("含缺失值的特征情况: ")
user_profile_df.groupBy("pvalue_level").count().show()
user_profile_df.groupBy("new_user_class_level").count().show()t_count = user_profile_df.count()
pl_na_count = t_count - user_profile_df.dropna(subset=["pvalue_level"]).count()
print("pvalue_level的空值情况:", pl_na_count, "空值占比:%0.2f%%"%(pl_na_count/t_count*100))
nul_na_count = t_count - user_profile_df.dropna(subset=["new_user_class_level"]).count()
print("new_user_class_level的空值情况:", nul_na_count, "空值占比:%0.2f%%"%(nul_na_count/t_count*100))
显示内容:
分类特征值个数情况:
cms_segid: 97
cms_group_id: 13
final_gender_code: 2
age_level: 7
shopping_level: 3
occupation: 2
含缺失值的特征情况:
+------------+------+
|pvalue_level| count|
+------------+------+
| null|575917|
| 1|154436|
| 3| 37759|
| 2|293656|
+------------+------++--------------------+------+
|new_user_class_level| count|
+--------------------+------+
| null|344920|
| 1| 80548|
| 3|173047|
| 4|138833|
| 2|324420|
+--------------------+------+pvalue_level的空值情况: 575917 空值占比:54.24%
new_user_class_level的空值情况: 344920 空值占比:32.49%
-
缺失值处理
-
注意,一般情况下:
- 缺失率低于10%:可直接进行相应的填充,如默认值、均值、算法拟合等等;
- 高于10%:往往会考虑舍弃该特征
- 特征处理,如1维转多维
但根据我们的经验,我们的广告推荐其实和用户的消费水平、用户所在城市等级都有比较大的关联,因此在这里pvalue_level、new_user_class_level都是比较重要的特征,我们不考虑舍弃
-
-
缺失值处理方案:
- 填充方案:结合用户的其他特征值,利用随机森林算法进行预测;但产生了大量人为构建的数据,一定程度上增加了数据的噪音
- 把变量映射到高维空间:如pvalue_level的1维数据,转换成是否1、是否2、是否3、是否缺失的4维数据;这样保证了所有原始数据不变,同时能提高精确度,但这样会导致数据变得比较稀疏,如果样本量很小,反而会导致样本效果较差,因此也不能滥用
-
填充方案
- 利用随机森林对pvalue_level的缺失值进行预测
from pyspark.mllib.regression import LabeledPoint# 剔除掉缺失值数据,将余下的数据作为训练数据
# user_profile_df.dropna(subset=["pvalue_level"]): 将pvalue_level中的空值所在行数据剔除后的数据,作为训练样本
train_data = user_profile_df.dropna(subset=["pvalue_level"]).rdd.map(lambda r:LabeledPoint(r.pvalue_level-1, [r.cms_segid, r.cms_group_id, r.final_gender_code, r.age_level, r.shopping_level, r.occupation])
)# 注意随机森林输入数据时,由于label的分类数是从0开始的,但pvalue_level的目前只分别是1,2,3,所以需要对应分别-1来作为目标值
# 自然那么最终得出预测值后,需要对应+1才能还原回来# 我们使用cms_segid, cms_group_id, final_gender_code, age_level, shopping_level, occupation作为特征值,pvalue_level作为目标值
- Labeled point
A labeled point is a local vector, either dense or sparse, associated with a label/response. In MLlib, labeled points are used in supervised learning algorithms. We use a double to store a label, so we can use labeled points in both regression and classification. For binary classification, a label should be either 0 (negative) or 1 (positive). For multiclass classification, labels should be class indices starting from zero: 0, 1, 2, ….
标记点是与标签/响应相关联的密集或稀疏的局部矢量。在MLlib中,标记点用于监督学习算法。我们使用double来存储标签,因此我们可以在回归和分类中使用标记点。对于二进制分类,标签应为0(负)或1(正)。对于多类分类,标签应该是从零开始的类索引:0, 1, 2, …。
Python
A labeled point is represented by LabeledPoint.
标记点表示为 LabeledPoint。
Refer to the LabeledPoint Python docs for more details on the API.
有关API的更多详细信息,请参阅LabeledPointPython文档。
from pyspark.mllib.linalg import SparseVector
from pyspark.mllib.regression import LabeledPoint# Create a labeled point with a positive label and a dense feature vector.
pos = LabeledPoint(1.0, [1.0, 0.0, 3.0])# Create a labeled point with a negative label and a sparse feature vector.
neg = LabeledPoint(0.0, SparseVector(3, [0, 2], [1.0, 3.0]))
- 随机森林:pyspark.mllib.tree.RandomForest
from pyspark.mllib.tree import RandomForest
# 训练分类模型
# 参数1 训练的数据
#参数2 目标值的分类个数 0,1,2
#参数3 特征中是否包含分类的特征 {2:2,3:7} {2:2} 表示 在特征中 第二个特征是分类的: 有两个分类
#参数4 随机森林中 树的棵数
model = RandomForest.trainClassifier(train_data, 3, {}, 5)
- 随机森林模型:pyspark.mllib.tree.RandomForestModel
# 预测单个数据
# 注意用法:https://spark.apache.org/docs/latest/api/python/pyspark.mllib.html?highlight=tree%20random#pyspark.mllib.tree.RandomForestModel.predict
model.predict([0.0, 4.0 ,2.0 , 4.0, 1.0, 0.0])
显示结果:
1.0
- 筛选出缺失值条目
pl_na_df = user_profile_df.na.fill(-1).where("pvalue_level=-1")
pl_na_df.show(10)def row(r):return r.cms_segid, r.cms_group_id, r.final_gender_code, r.age_level, r.shopping_level, r.occupation# 转换为普通的rdd类型
rdd = pl_na_df.rdd.map(row)
# 预测全部的pvalue_level值:
predicts = model.predict(rdd)
# 查看前20条
print(predicts.take(20))
print("预测值总数", predicts.count())# 这里注意predict参数,如果是预测多个,那么参数必须是直接有列表构成的rdd参数,而不能是dataframe.rdd类型
# 因此这里经过map函数处理,将每一行数据转换为普通的列表数据
显示结果:
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
|userId|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
| 234| 0| 5| 2| 5| -1| 3| 0| 3|
| 1670| 0| 4| 2| 4| -1| 1| 0| -1|
| 2545| 0| 10| 1| 4| -1| 3| 0| -1|
| 6211| 0| 9| 1| 3| -1| 3| 0| 2|
| 9293| 0| 5| 2| 5| -1| 3| 0| 4|
| 10812| 0| 4| 2| 4| -1| 2| 0| -1|
| 10996| 0| 5| 2| 5| -1| 3| 0| 4|
| 11602| 0| 5| 2| 5| -1| 3| 0| 2|
| 11727| 0| 3| 2| 3| -1| 3| 0| 1|
| 12195| 0| 10| 1| 4| -1| 3| 0| 2|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
only showing top 10 rows[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.0, 1.0, 0.0, 1.0, 1.0, 1.0]
预测值总数 575917
- 转换为pandas dataframe
# 这里数据量比较小,直接转换为pandas dataframe来处理,因为方便,但注意如果数据量较大不推荐,因为这样会把全部数据加载到内存中
temp = predicts.map(lambda x:int(x)).collect()
pdf = pl_na_df.toPandas()
import numpy as np# 在pandas df的基础上直接替换掉列数据
pdf["pvalue_level"] = np.array(temp) + 1 # 注意+1 还原预测值
pdf
- 与非缺失数据进行拼接,完成pvalue_level的缺失值预测
new_user_profile_df = user_profile_df.dropna(subset=["pvalue_level"]).unionAll(spark.createDataFrame(pdf, schema=schema))
new_user_profile_df.show()# 注意:unionAll的使用,两个df的表结构必须完全一样显示结果:
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
|userId|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
| 523| 5| 2| 2| 2| 1| 3| 1| 2|
| 612| 0| 8| 1| 2| 2| 3| 0| null|
| 3644| 49| 6| 2| 6| 2| 3| 0| 2|
| 5777| 44| 5| 2| 5| 2| 3| 0| 2|
| 6355| 2| 1| 2| 1| 1| 3| 0| 4|
| 6823| 43| 5| 2| 5| 2| 3| 0| 1|
| 6972| 5| 2| 2| 2| 2| 3| 1| 2|
| 9510| 55| 8| 1| 2| 2| 2| 0| 2|
| 10122| 33| 4| 2| 4| 2| 3| 0| 2|
| 10549| 0| 4| 2| 4| 2| 3| 0| null|
| 10912| 0| 4| 2| 4| 2| 3| 0| null|
| 11256| 8| 2| 2| 2| 1| 3| 0| 3|
| 11310| 31| 4| 2| 4| 1| 3| 0| 4|
| 11739| 20| 3| 2| 3| 2| 3| 0| 4|
| 12549| 33| 4| 2| 4| 2| 3| 0| 2|
| 15155| 36| 5| 2| 5| 2| 1| 0| null|
| 15347| 20| 3| 2| 3| 2| 3| 0| 3|
| 15455| 8| 2| 2| 2| 2| 3| 0| 3|
| 15783| 0| 4| 2| 4| 2| 3| 0| null|
| 16749| 5| 2| 2| 2| 1| 3| 1| 4|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
only showing top 20 rows
- 利用随机森林对new_user_class_level的缺失值进行预测
from pyspark.mllib.regression import LabeledPoint# 选出new_user_class_level全部的
train_data2 = user_profile_df.dropna(subset=["new_user_class_level"]).rdd.map(lambda r:LabeledPoint(r.new_user_class_level - 1, [r.cms_segid, r.cms_group_id, r.final_gender_code, r.age_level, r.shopping_level, r.occupation])
)
from pyspark.mllib.tree import RandomForest
model2 = RandomForest.trainClassifier(train_data2, 4, {}, 5)
model2.predict([0.0, 4.0 ,2.0 , 4.0, 1.0, 0.0])
# 预测值实际应该为2
显示结果:
1.0
nul_na_df = user_profile_df.na.fill(-1).where("new_user_class_level=-1")
nul_na_df.show(10)def row(r):return r.cms_segid, r.cms_group_id, r.final_gender_code, r.age_level, r.shopping_level, r.occupationrdd2 = nul_na_df.rdd.map(row)
predicts2 = model.predict(rdd2)
predicts2.take(20)
- 显示结果:
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
|userId|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
| 612| 0| 8| 1| 2| 2| 3| 0| -1|
| 1670| 0| 4| 2| 4| -1| 1| 0| -1|
| 2545| 0| 10| 1| 4| -1| 3| 0| -1|
| 10549| 0| 4| 2| 4| 2| 3| 0| -1|
| 10812| 0| 4| 2| 4| -1| 2| 0| -1|
| 10912| 0| 4| 2| 4| 2| 3| 0| -1|
| 12620| 0| 4| 2| 4| -1| 2| 0| -1|
| 14437| 0| 5| 2| 5| -1| 3| 0| -1|
| 14574| 0| 1| 2| 1| -1| 2| 0| -1|
| 14985| 0| 11| 1| 5| -1| 2| 0| -1|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
only showing top 10 rows[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,0.0,1.0,1.0,1.0,1.0,1.0,1.0,0.0,1.0,0.0,0.0,1.0]- 总结:可以发现由于这两个字段的缺失过多,所以预测出来的值已经大大失真,但如果缺失率在10%以下,这种方法是比较有效的一种
user_profile_df = user_profile_df.na.fill(-1)
user_profile_df.show()
# new_df = new_df.withColumn("pvalue_level", new_df.pvalue_level.cast(StringType()))\
# .withColumn("new_user_class_level", new_df.new_user_class_level.cast(StringType()))
显示结果:
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
|userId|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
| 234| 0| 5| 2| 5| -1| 3| 0| 3|
| 523| 5| 2| 2| 2| 1| 3| 1| 2|
| 612| 0| 8| 1| 2| 2| 3| 0| -1|
| 1670| 0| 4| 2| 4| -1| 1| 0| -1|
| 2545| 0| 10| 1| 4| -1| 3| 0| -1|
| 3644| 49| 6| 2| 6| 2| 3| 0| 2|
| 5777| 44| 5| 2| 5| 2| 3| 0| 2|
| 6211| 0| 9| 1| 3| -1| 3| 0| 2|
| 6355| 2| 1| 2| 1| 1| 3| 0| 4|
| 6823| 43| 5| 2| 5| 2| 3| 0| 1|
| 6972| 5| 2| 2| 2| 2| 3| 1| 2|
| 9293| 0| 5| 2| 5| -1| 3| 0| 4|
| 9510| 55| 8| 1| 2| 2| 2| 0| 2|
| 10122| 33| 4| 2| 4| 2| 3| 0| 2|
| 10549| 0| 4| 2| 4| 2| 3| 0| -1|
| 10812| 0| 4| 2| 4| -1| 2| 0| -1|
| 10912| 0| 4| 2| 4| 2| 3| 0| -1|
| 10996| 0| 5| 2| 5| -1| 3| 0| 4|
| 11256| 8| 2| 2| 2| 1| 3| 0| 3|
| 11310| 31| 4| 2| 4| 1| 3| 0| 4|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
only showing top 20 rows
- 低维转高维方式
- 我们接下来采用将变量映射到高维空间的方法来处理数据,即将缺失项也当做一个单独的特征来对待,保证数据的原始性
由于该思想正好和热独编码实现方法一样,因此这里直接使用热独编码方式处理数据
- 我们接下来采用将变量映射到高维空间的方法来处理数据,即将缺失项也当做一个单独的特征来对待,保证数据的原始性
from pyspark.ml.feature import OneHotEncoder
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline# 使用热独编码转换pvalue_level的一维数据为多维,其中缺失值单独作为一个特征值# 需要先将缺失值全部替换为数值,与原有特征一起处理
from pyspark.sql.types import StringType
user_profile_df = user_profile_df.na.fill(-1)
user_profile_df.show()# 热独编码时,必须先将待处理字段转为字符串类型才可处理
user_profile_df = user_profile_df.withColumn("pvalue_level", user_profile_df.pvalue_level.cast(StringType()))\.withColumn("new_user_class_level", user_profile_df.new_user_class_level.cast(StringType()))
user_profile_df.printSchema()# 对pvalue_level进行热独编码,求值
stringindexer = StringIndexer(inputCol='pvalue_level', outputCol='pl_onehot_feature')
encoder = OneHotEncoder(dropLast=False, inputCol='pl_onehot_feature', outputCol='pl_onehot_value')
pipeline = Pipeline(stages=[stringindexer, encoder])
pipeline_fit = pipeline.fit(user_profile_df)
user_profile_df2 = pipeline_fit.transform(user_profile_df)
# pl_onehot_value列的值为稀疏向量,存储热独编码的结果
user_profile_df2.printSchema()
user_profile_df2.show()
显示结果:
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
|userId|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
| 234| 0| 5| 2| 5| -1| 3| 0| 3|
| 523| 5| 2| 2| 2| 1| 3| 1| 2|
| 612| 0| 8| 1| 2| 2| 3| 0| -1|
| 1670| 0| 4| 2| 4| -1| 1| 0| -1|
| 2545| 0| 10| 1| 4| -1| 3| 0| -1|
| 3644| 49| 6| 2| 6| 2| 3| 0| 2|
| 5777| 44| 5| 2| 5| 2| 3| 0| 2|
| 6211| 0| 9| 1| 3| -1| 3| 0| 2|
| 6355| 2| 1| 2| 1| 1| 3| 0| 4|
| 6823| 43| 5| 2| 5| 2| 3| 0| 1|
| 6972| 5| 2| 2| 2| 2| 3| 1| 2|
| 9293| 0| 5| 2| 5| -1| 3| 0| 4|
| 9510| 55| 8| 1| 2| 2| 2| 0| 2|
| 10122| 33| 4| 2| 4| 2| 3| 0| 2|
| 10549| 0| 4| 2| 4| 2| 3| 0| -1|
| 10812| 0| 4| 2| 4| -1| 2| 0| -1|
| 10912| 0| 4| 2| 4| 2| 3| 0| -1|
| 10996| 0| 5| 2| 5| -1| 3| 0| 4|
| 11256| 8| 2| 2| 2| 1| 3| 0| 3|
| 11310| 31| 4| 2| 4| 1| 3| 0| 4|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+
only showing top 20 rowsroot|-- userId: integer (nullable = true)|-- cms_segid: integer (nullable = true)|-- cms_group_id: integer (nullable = true)|-- final_gender_code: integer (nullable = true)|-- age_level: integer (nullable = true)|-- pvalue_level: string (nullable = true)|-- shopping_level: integer (nullable = true)|-- occupation: integer (nullable = true)|-- new_user_class_level: string (nullable = true)root|-- userId: integer (nullable = true)|-- cms_segid: integer (nullable = true)|-- cms_group_id: integer (nullable = true)|-- final_gender_code: integer (nullable = true)|-- age_level: integer (nullable = true)|-- pvalue_level: string (nullable = true)|-- shopping_level: integer (nullable = true)|-- occupation: integer (nullable = true)|-- new_user_class_level: string (nullable = true)|-- pl_onehot_feature: double (nullable = false)|-- pl_onehot_value: vector (nullable = true)+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+-----------------+---------------+
|userId|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level|pl_onehot_feature|pl_onehot_value|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+-----------------+---------------+
| 234| 0| 5| 2| 5| -1| 3| 0| 3| 0.0| (4,[0],[1.0])|
| 523| 5| 2| 2| 2| 1| 3| 1| 2| 2.0| (4,[2],[1.0])|
| 612| 0| 8| 1| 2| 2| 3| 0| -1| 1.0| (4,[1],[1.0])|
| 1670| 0| 4| 2| 4| -1| 1| 0| -1| 0.0| (4,[0],[1.0])|
| 2545| 0| 10| 1| 4| -1| 3| 0| -1| 0.0| (4,[0],[1.0])|
| 3644| 49| 6| 2| 6| 2| 3| 0| 2| 1.0| (4,[1],[1.0])|
| 5777| 44| 5| 2| 5| 2| 3| 0| 2| 1.0| (4,[1],[1.0])|
| 6211| 0| 9| 1| 3| -1| 3| 0| 2| 0.0| (4,[0],[1.0])|
| 6355| 2| 1| 2| 1| 1| 3| 0| 4| 2.0| (4,[2],[1.0])|
| 6823| 43| 5| 2| 5| 2| 3| 0| 1| 1.0| (4,[1],[1.0])|
| 6972| 5| 2| 2| 2| 2| 3| 1| 2| 1.0| (4,[1],[1.0])|
| 9293| 0| 5| 2| 5| -1| 3| 0| 4| 0.0| (4,[0],[1.0])|
| 9510| 55| 8| 1| 2| 2| 2| 0| 2| 1.0| (4,[1],[1.0])|
| 10122| 33| 4| 2| 4| 2| 3| 0| 2| 1.0| (4,[1],[1.0])|
| 10549| 0| 4| 2| 4| 2| 3| 0| -1| 1.0| (4,[1],[1.0])|
| 10812| 0| 4| 2| 4| -1| 2| 0| -1| 0.0| (4,[0],[1.0])|
| 10912| 0| 4| 2| 4| 2| 3| 0| -1| 1.0| (4,[1],[1.0])|
| 10996| 0| 5| 2| 5| -1| 3| 0| 4| 0.0| (4,[0],[1.0])|
| 11256| 8| 2| 2| 2| 1| 3| 0| 3| 2.0| (4,[2],[1.0])|
| 11310| 31| 4| 2| 4| 1| 3| 0| 4| 2.0| (4,[2],[1.0])|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+-----------------+---------------+
only showing top 20 rows- 使用热编码转换new_user_class_level的一维数据为多维
stringindexer = StringIndexer(inputCol='new_user_class_level', outputCol='nucl_onehot_feature')
encoder = OneHotEncoder(dropLast=False, inputCol='nucl_onehot_feature', outputCol='nucl_onehot_value')
pipeline = Pipeline(stages=[stringindexer, encoder])
pipeline_fit = pipeline.fit(user_profile_df2)
user_profile_df3 = pipeline_fit.transform(user_profile_df2)
user_profile_df3.show()
显示结果:
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+-----------------+---------------+-------------------+-----------------+
|userId|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level|pl_onehot_feature|pl_onehot_value|nucl_onehot_feature|nucl_onehot_value|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+-----------------+---------------+-------------------+-----------------+
| 234| 0| 5| 2| 5| -1| 3| 0| 3| 0.0| (4,[0],[1.0])| 2.0| (5,[2],[1.0])|
| 523| 5| 2| 2| 2| 1| 3| 1| 2| 2.0| (4,[2],[1.0])| 1.0| (5,[1],[1.0])|
| 612| 0| 8| 1| 2| 2| 3| 0| -1| 1.0| (4,[1],[1.0])| 0.0| (5,[0],[1.0])|
| 1670| 0| 4| 2| 4| -1| 1| 0| -1| 0.0| (4,[0],[1.0])| 0.0| (5,[0],[1.0])|
| 2545| 0| 10| 1| 4| -1| 3| 0| -1| 0.0| (4,[0],[1.0])| 0.0| (5,[0],[1.0])|
| 3644| 49| 6| 2| 6| 2| 3| 0| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|
| 5777| 44| 5| 2| 5| 2| 3| 0| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|
| 6211| 0| 9| 1| 3| -1| 3| 0| 2| 0.0| (4,[0],[1.0])| 1.0| (5,[1],[1.0])|
| 6355| 2| 1| 2| 1| 1| 3| 0| 4| 2.0| (4,[2],[1.0])| 3.0| (5,[3],[1.0])|
| 6823| 43| 5| 2| 5| 2| 3| 0| 1| 1.0| (4,[1],[1.0])| 4.0| (5,[4],[1.0])|
| 6972| 5| 2| 2| 2| 2| 3| 1| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|
| 9293| 0| 5| 2| 5| -1| 3| 0| 4| 0.0| (4,[0],[1.0])| 3.0| (5,[3],[1.0])|
| 9510| 55| 8| 1| 2| 2| 2| 0| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|
| 10122| 33| 4| 2| 4| 2| 3| 0| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|
| 10549| 0| 4| 2| 4| 2| 3| 0| -1| 1.0| (4,[1],[1.0])| 0.0| (5,[0],[1.0])|
| 10812| 0| 4| 2| 4| -1| 2| 0| -1| 0.0| (4,[0],[1.0])| 0.0| (5,[0],[1.0])|
| 10912| 0| 4| 2| 4| 2| 3| 0| -1| 1.0| (4,[1],[1.0])| 0.0| (5,[0],[1.0])|
| 10996| 0| 5| 2| 5| -1| 3| 0| 4| 0.0| (4,[0],[1.0])| 3.0| (5,[3],[1.0])|
| 11256| 8| 2| 2| 2| 1| 3| 0| 3| 2.0| (4,[2],[1.0])| 2.0| (5,[2],[1.0])|
| 11310| 31| 4| 2| 4| 1| 3| 0| 4| 2.0| (4,[2],[1.0])| 3.0| (5,[3],[1.0])|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+-----------------+---------------+-------------------+-----------------+
only showing top 20 rows
- 用户特征合并
from pyspark.ml.feature import VectorAssembler
feature_df = VectorAssembler().setInputCols(["age_level", "pl_onehot_value", "nucl_onehot_value"]).setOutputCol("features").transform(user_profile_df3)
feature_df.show()
显示结果:
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+-----------------+---------------+-------------------+-----------------+--------------------+
|userId|cms_segid|cms_group_id|final_gender_code|age_level|pvalue_level|shopping_level|occupation|new_user_class_level|pl_onehot_feature|pl_onehot_value|nucl_onehot_feature|nucl_onehot_value| features|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+-----------------+---------------+-------------------+-----------------+--------------------+
| 234| 0| 5| 2| 5| -1| 3| 0| 3| 0.0| (4,[0],[1.0])| 2.0| (5,[2],[1.0])|(10,[0,1,7],[5.0,...|
| 523| 5| 2| 2| 2| 1| 3| 1| 2| 2.0| (4,[2],[1.0])| 1.0| (5,[1],[1.0])|(10,[0,3,6],[2.0,...|
| 612| 0| 8| 1| 2| 2| 3| 0| -1| 1.0| (4,[1],[1.0])| 0.0| (5,[0],[1.0])|(10,[0,2,5],[2.0,...|
| 1670| 0| 4| 2| 4| -1| 1| 0| -1| 0.0| (4,[0],[1.0])| 0.0| (5,[0],[1.0])|(10,[0,1,5],[4.0,...|
| 2545| 0| 10| 1| 4| -1| 3| 0| -1| 0.0| (4,[0],[1.0])| 0.0| (5,[0],[1.0])|(10,[0,1,5],[4.0,...|
| 3644| 49| 6| 2| 6| 2| 3| 0| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|(10,[0,2,6],[6.0,...|
| 5777| 44| 5| 2| 5| 2| 3| 0| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|(10,[0,2,6],[5.0,...|
| 6211| 0| 9| 1| 3| -1| 3| 0| 2| 0.0| (4,[0],[1.0])| 1.0| (5,[1],[1.0])|(10,[0,1,6],[3.0,...|
| 6355| 2| 1| 2| 1| 1| 3| 0| 4| 2.0| (4,[2],[1.0])| 3.0| (5,[3],[1.0])|(10,[0,3,8],[1.0,...|
| 6823| 43| 5| 2| 5| 2| 3| 0| 1| 1.0| (4,[1],[1.0])| 4.0| (5,[4],[1.0])|(10,[0,2,9],[5.0,...|
| 6972| 5| 2| 2| 2| 2| 3| 1| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|(10,[0,2,6],[2.0,...|
| 9293| 0| 5| 2| 5| -1| 3| 0| 4| 0.0| (4,[0],[1.0])| 3.0| (5,[3],[1.0])|(10,[0,1,8],[5.0,...|
| 9510| 55| 8| 1| 2| 2| 2| 0| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|(10,[0,2,6],[2.0,...|
| 10122| 33| 4| 2| 4| 2| 3| 0| 2| 1.0| (4,[1],[1.0])| 1.0| (5,[1],[1.0])|(10,[0,2,6],[4.0,...|
| 10549| 0| 4| 2| 4| 2| 3| 0| -1| 1.0| (4,[1],[1.0])| 0.0| (5,[0],[1.0])|(10,[0,2,5],[4.0,...|
| 10812| 0| 4| 2| 4| -1| 2| 0| -1| 0.0| (4,[0],[1.0])| 0.0| (5,[0],[1.0])|(10,[0,1,5],[4.0,...|
| 10912| 0| 4| 2| 4| 2| 3| 0| -1| 1.0| (4,[1],[1.0])| 0.0| (5,[0],[1.0])|(10,[0,2,5],[4.0,...|
| 10996| 0| 5| 2| 5| -1| 3| 0| 4| 0.0| (4,[0],[1.0])| 3.0| (5,[3],[1.0])|(10,[0,1,8],[5.0,...|
| 11256| 8| 2| 2| 2| 1| 3| 0| 3| 2.0| (4,[2],[1.0])| 2.0| (5,[2],[1.0])|(10,[0,3,7],[2.0,...|
| 11310| 31| 4| 2| 4| 1| 3| 0| 4| 2.0| (4,[2],[1.0])| 3.0| (5,[3],[1.0])|(10,[0,3,8],[4.0,...|
+------+---------+------------+-----------------+---------+------------+--------------+----------+--------------------+-----------------+---------------+-------------------+-----------------+--------------------+
only showing top 20 rows
feature_df.select("features").show()
显示结果:
+--------------------+
| features|
+--------------------+
|(10,[0,1,7],[5.0,...|
|(10,[0,3,6],[2.0,...|
|(10,[0,2,5],[2.0,...|
|(10,[0,1,5],[4.0,...|
|(10,[0,1,5],[4.0,...|
|(10,[0,2,6],[6.0,...|
|(10,[0,2,6],[5.0,...|
|(10,[0,1,6],[3.0,...|
|(10,[0,3,8],[1.0,...|
|(10,[0,2,9],[5.0,...|
|(10,[0,2,6],[2.0,...|
|(10,[0,1,8],[5.0,...|
|(10,[0,2,6],[2.0,...|
|(10,[0,2,6],[4.0,...|
|(10,[0,2,5],[4.0,...|
|(10,[0,1,5],[4.0,...|
|(10,[0,2,5],[4.0,...|
|(10,[0,1,8],[5.0,...|
|(10,[0,3,7],[2.0,...|
|(10,[0,3,8],[4.0,...|
+--------------------+
only showing top 20 rows
- 特征选取
除了前面处理的pvalue_level和new_user_class_level需要作为特征以外,(能体现出用户的购买力特征),还有:
前面分析的以下几个分类特征值个数情况:
- cms_segid: 97
- cms_group_id: 13
- final_gender_code: 2
- age_level: 7
- shopping_level: 3
- occupation: 2
-pvalue_level
-new_user_class_level
-price
根据经验,以上几个分类特征都一定程度能体现用户在购物方面的特征,且类别都较少,都可以用来作为用户特征
相关文章:

三 、CTR预估数据准备
三 CTR预估数据准备 3.1 分析并预处理raw_sample数据集 # 从HDFS中加载样本数据信息 df spark.read.csv("hdfs://localhost:9000/datasets/raw_sample.csv", headerTrue) df.show() # 展示数据,默认前20条 df.printSchema()显示结果: ------------…...
netty学习分享 二
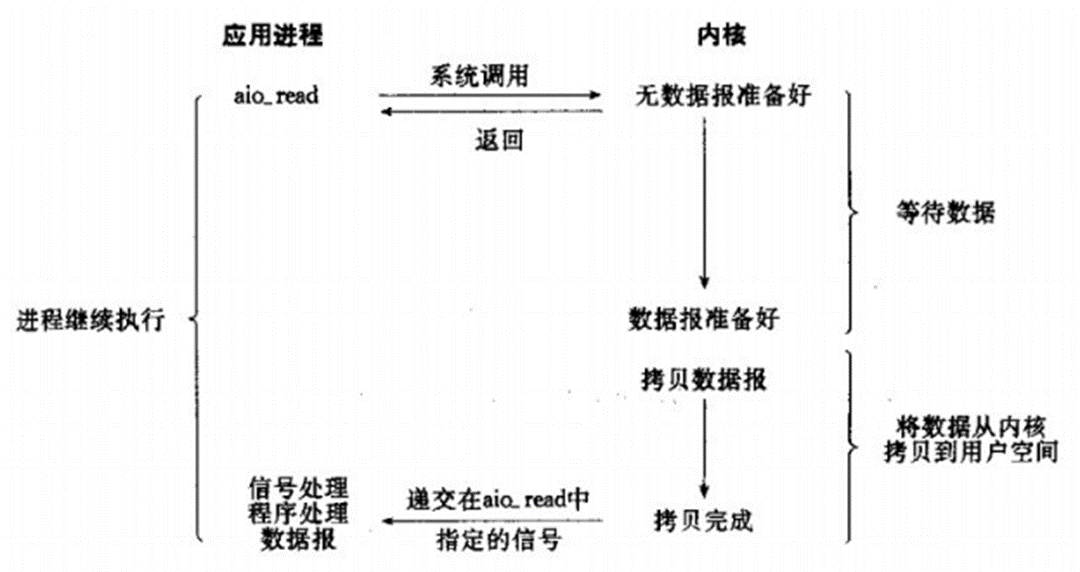
操作系统IO模型与实现原理 阻塞IO 模型 应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。如果数据没有准备好,一直等待….数据准备好了,从内核拷贝到用户空间,IO函数返回成功指示。 当调用recv()函数时,系…...

聊聊web服务器NGINX
文章目录 聊聊web服务器NGINXNGINX的起源NGINX早期阶段首次发布快速扩展模块化架构逐步增加功能商业收购 NGINX能做什么NGINX的优势NGINX为何能兴起 聊聊web服务器NGINX NGINX的起源 NGINX是一个 HTTP 和反向代理服务器,一个邮件代理服务器,以及一个通…...

【hello C++】特殊类设计
目录 一、设计一个类,不能被拷贝 二、设计一个类,只能在堆上创建对象 三、设计一个类,只能在栈上创建对象 四、请设计一个类,不能被继承 五、请设计一个类,只能创建一个对象(单例模式) C🌷 一、设计一个类&…...
js实现按创建时间戳1609459200000 开始往后开始显示运行时长-demo
运行时长 00日 00时 17分 59秒 代码 function calculateRuntime(timestamp) {const startTime Date.now(); // 获取当前时间戳//const runtimeElement document.getElementById(runtime); // 获取显示运行时长的元素function updateRuntime() {const currentTimestamp Date…...
latex三线表按页面大小填充
latex三线表按页面大小填充 使用Latex表格时会出现下图情况,表格没有填充整个页面,导致不美观。 解决方法: 在\begin{tabular}前加上\resizebox{\linewidth}{!}{ , 在\end{tabular} 后加 ‘}’ 如下:\resizebox{…...
佛祖保佑,永不宕机,永无bug
当我们的程序编译通过,能预防的bug也都预防了,其它的就只能交给天意了。当然请求佛祖的保佑也是必不可少的。 下面是一些常用的保佑图: 佛祖保佑图 ——————————————————————————————————————————…...

redis分布式集群-redis+keepalived+ haproxy
redis分布式集群架构(RedisKeepalivedHaproxy)至少需要3台服务器、6个节点,一台服务器2个节点。 redis分布式集群架构中的每台服务器都使用六个端口来实现多路复用,最终实现主从热备、负载均衡、秒级切换的目标。 redis分布式集…...
快递管理系统springboot 寄件物流仓库java jsp源代码mysql
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 快递管理系统springboot 系统有1权限:管…...
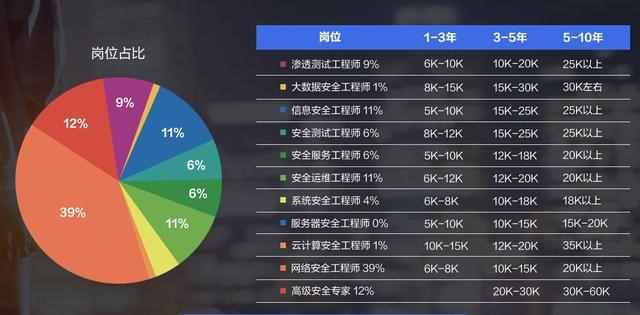
自学黑客/网络安全(学习路线+教程视频+工具包+经验分享)
一、为什么选择网络安全? 这几年随着我国《国家网络空间安全战略》《网络安全法》《网络安全等级保护2.0》等一系列政策/法规/标准的持续落地,网络安全行业地位、薪资随之水涨船高。 未来3-5年,是安全行业的黄金发展期,提前踏入…...
如何进行游戏平台搭建?
游戏平台搭建涉及多个步骤和技术,下面是一个大致的指南: 市场调研和定位:首先,要了解游戏市场和受众的需求,选择适合的游戏类型和定位。 选择平台类型:决定是要搭建网页平台、移动应用平台还是其他类型的…...

安全防御问题
SSL VPN的实现,防火墙需要放行哪些流量? 实现 SSL VPN 时,在防火墙上需要放行以下流量, SSL/TLS 流量:SSL VPN 通过加密通信来确保安全性,因此防火墙需要允许 SSL/TLS 流量通过。一般情况下,SSL…...
x-www-form-urlencoded、application/json到底是什么
在http协议中规定了GET、HEAD、POST、PUT、DELETE、CONNECT 等请求方式,其中比较常用的就是post和get,其中post用来向服务器提交数据,post只规定了提交的数据必须放在请求的主体中,但是并没有规定传输数据的编码方式。比较主流的有如下的几种…...
LeetCode 33题:搜索旋转排序数组
目录 题目 思路 代码 暴力解法 分方向法 二分法 题目 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 …...
用python来爬取某鱼的商品信息(1/2)
目录 前言 第一大难题——找到网站入口 曲线救国 模拟搜索 第二大难题——登录 提一嘴 登录cookie获取 第一种 第二种 第四大难题——无法使用导出的cookie 原因 解决办法 最后 出现小问题 总结 下一篇博客(大部分代码实现) 前言 本章讲理…...
网工最常犯的9大错误,越早知道越吃香
下午好,我的网工朋友 我们常说,人要学会避免错误,尤其是对在职场生活的打工人来说,更是如此。 学生时代,我们通过错题本收集错误,提高刷题正确率和分数,但到了职场,因为没有量化的…...
Windows - UWP - 网络不好的情况下安装(微软商店)MicrosoftStore的应用
Windows - UWP - 网络不好的情况下安装(微软商店)MicrosoftStore的应用 前言 UWP虽然几乎被微软抛弃了,但不得不否认UWP应用给用户带来的体验。沙箱的运行方式加上微软的审核,用户使用起来非常放心,并且完美契合Wind…...

1040:输出绝对值
【题目描述】 输入一个浮点数,输出这个浮点数的绝对值,保留到小数点后两位。 【输入】 输入一个浮点数,其绝对值不超过10000。 【输出】 输出这个浮点数的绝对值,保留到小数点后两位。 【输入样例】 -3.14 【输出样例】 …...

[Docker精进篇] Docker部署和实践 (二)
前言: Docker部署是通过使用Docker容器技术,将应用程序及其所有相关依赖项打包为一个可移植、自包含的镜像,然后在任何支持Docker的环境中快速部署和运行应用程序的过程。 文章目录 Docker部署1️⃣为什么需要?2️⃣有什么作用&am…...
、459.重复的子字符串)
day9 | 28. 实现 strStr()、459.重复的子字符串
目录: 解题及思路学习 28. 实现 strStr() https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string/ 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

CPU架构启发的智能仓储布局优化实践
1. 仓库布局优化的核心挑战与创新机遇在物流仓储领域,拣货环节通常占据运营成本的55%-65%,而其中约50%的时间消耗在无效行走路径上。传统矩形仓库布局虽然易于规划和施工,但其正交的通道设计导致拣货员需要频繁进行90度转向,这种&…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...

ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍
ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...

AWS DevOps Agent 完全指南
AWS DevOps Agent 是 AWS 推出的前沿 AI 运维代理,自主调查和解决事件、持续预防故障、提升系统可靠性。本文档覆盖从原理到实战的全生命周期管理。 一、定位与价值 一句话定义 AWS DevOps Agent = AI 驱动的 SRE 队友,724 自主调查告警、定位根因、生成修复方案、预防未来…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...

量子机器学习与傅里叶分析:革新期权定价的混合计算范式
1. 项目概述:当量子机器学习遇见金融定价在金融工程的核心地带,期权定价一直是个计算密集型的硬骨头。传统的蒙特卡洛模拟虽然通用,但为了达到足够的精度,动辄需要百万甚至千万次的路径模拟,计算成本高昂。近年来&…...