多线程(进阶)
一、常见的锁策略
1.1读写锁
多线程之间,数据的读取方之间不会产生线程安全问题,但数据的写入方互相之间以及和读者之间都需 要进行互斥。如果两种场景下都用同一个锁,就会产生极大的性能损耗。所以读写锁因此而产生。
读写锁(readers-writer lock),看英文可以顾名思义,在执行加锁操作时需要额外表明读写意图,复数读者之间并不互斥,而写者则要求与任何人互斥。
一个线程对于数据的访问, 主要存在两种操作: 读数据 和 写数据.
两个线程都只是读一个数据, 此时并没有线程安全问题. 直接并发的读取即可.
两个线程都要写一个数据, 有线程安全问题.
一个线程读另外一个线程写, 也有线程安全问题.
读写锁就是把读操作和写操作区分对待.
Java 标准库提供了 ReentrantReadWriteLock 类, 实现了读写锁.(reentrant-可重入的)
ReentrantReadWriteLock.ReadLock 类表示一个读锁. 这个对象提供了 lock / unlock 方法进行 加锁解锁.
ReentrantReadWriteLock.WriteLock 类表示一个写锁. 这个对象也提供了 lock / unlock 方法进行加锁解锁.
其中,
读加锁和读加锁之间, 不互斥.
写加锁和写加锁之间, 互斥.
读加锁和写加锁之间, 互斥.
读写锁特别适合于 “频繁读, 不频繁写” 的场景中. (这样的场景其实也是非常广泛存在的).
1.2公平锁 vs 非公平锁
假设三个线程 A, B, C. A 先尝试获取锁, 获取成功. 然后 B 再尝试获取锁, 获取失败, 阻塞等待; 然后 C 也尝试获取锁, C 也获取失败, 也阻塞等待.当线程 A 释放锁的时候, 会发生啥呢?
公平锁: 遵守 “先来后到”. B 比 C 先来的. 当 A 释放锁的之后, B 就能先于 C 获取到锁.
非公平锁: 不遵守 “先来后到”. B 和 C 都有可能获取到锁.
操作系统内部的线程调度就可以视为是随机的. 如果不做任何额外的限制, 锁就是非公平锁. 如果要 想实现公平锁, 就需要依赖额外的数据结构, 来记录线程们的先后顺序.
公平锁和非公平锁没有好坏之分, 关键还是看适用场景
synchronized 是非公平锁.
1.3可重入锁 vs 不可重入锁
可重入锁的字面意思是“可以重新进入的锁”,即允许同一个线程多次获取同一把锁。
比如一个递归函数里有加锁操作,递归过程中这个锁会阻塞自己吗?如果不会,那么这个锁就是可重入 锁(因为这个原因可重入锁也叫做递归锁)。
Java里只要以Reentrant开头命名的锁都是可重入锁,而且JDK提供的所有现成的Lock实现类,包括 synchronized关键字锁都是可重入的。
而 Linux 系统提供的 mutex 是不可重入锁.
synchronized 是可重入锁
那么什么时候会是死锁呢?面试官问你:举个例子说一下死锁吧!
答:你发我offer我就和你说一说死锁。(可以去看java初阶部分,那里我详细说明了自己把自己锁死是怎么回事!)
1.4乐观锁 vs 悲观锁
悲观锁:
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。
乐观锁:
假设数据一般情况下不会产生并发冲突,所以在数据进行提交更新的时候,才会正式对数据是否产生并 发冲突进行检测,如果发现并发冲突了,则让返回用户错误的信息,让用户决定如何去做。
举个栗子: 同学 A 和 同学 B 想请教老师一个问题.
同学 A 认为 “老师是比较忙的, 我来问问题, 老师不一定有空解答”. 因此同学 A 会先给老师发消息: “老师 你忙嘛? 我下午两点能来找你问个问题嘛?” (相当于加锁操作) 得到肯定的答复之后, 才会真的来问问题. 如果得到了否定的答复, 那就等一段时间, 下次再来和老师确定时间. 这个是悲观锁.
同学 B 认为 “老师是比较闲的, 我来问问题, 老师大概率是有空解答的”. 因此同学 B 直接就来找老师.(没加锁, 直接访问资源) 如果老师确实比较闲, 那么直接问题就解决了. 如果老师这会确实很忙, 那么同学 B 也不会打扰老师, 就下次再来(虽然没加锁, 但是能识别出数据访问冲突). 这个是乐观锁.
这两种思路不能说谁优谁劣, 而是看当前的场景是否合适.
Synchronized 初始使用乐观锁策略. 当发现锁竞争比较频繁的时候, 就会自动切换成悲观锁策略.
乐观锁的一个重要功能就是要检测出数据是否发生访问冲突. 我们可以引入一个 “版本号” 来解决。
假设我们需要多线程修改 “用户账户余额”.
设当前余额为 100. 引入一个版本号 version, 初始值为 1. 并且我们规定 “提交版本必须大于记录
当前版本才能执行更新余额”
- 线程 A 此时准备将其读出( version=1, balance=100 ),线程 B 也读入此信息( version=1, balance=100 )。
 2) 线程 A 操作的过程中并从其帐户余额中扣除 50( 100-50 ),线程 B 从其帐户余额中扣除 20 (100-20 )
2) 线程 A 操作的过程中并从其帐户余额中扣除 50( 100-50 ),线程 B 从其帐户余额中扣除 20 (100-20 )
 3) 线程 A 完成修改工作,将数据版本号加1( version=2 ),连同帐户扣除后余额( balance=50 ),写回到内存中;
3) 线程 A 完成修改工作,将数据版本号加1( version=2 ),连同帐户扣除后余额( balance=50 ),写回到内存中;
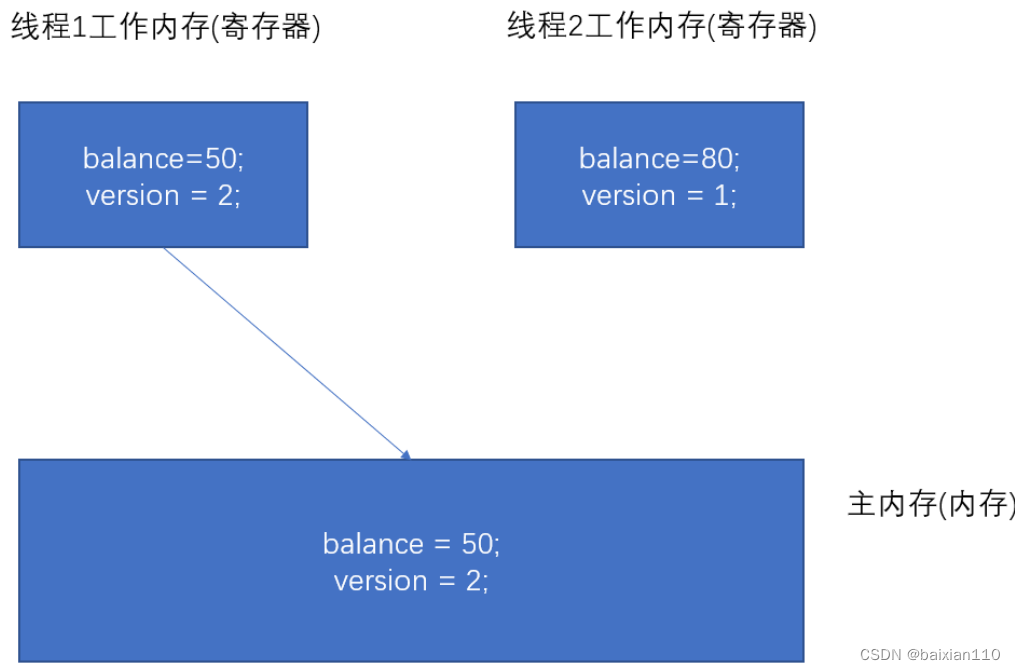
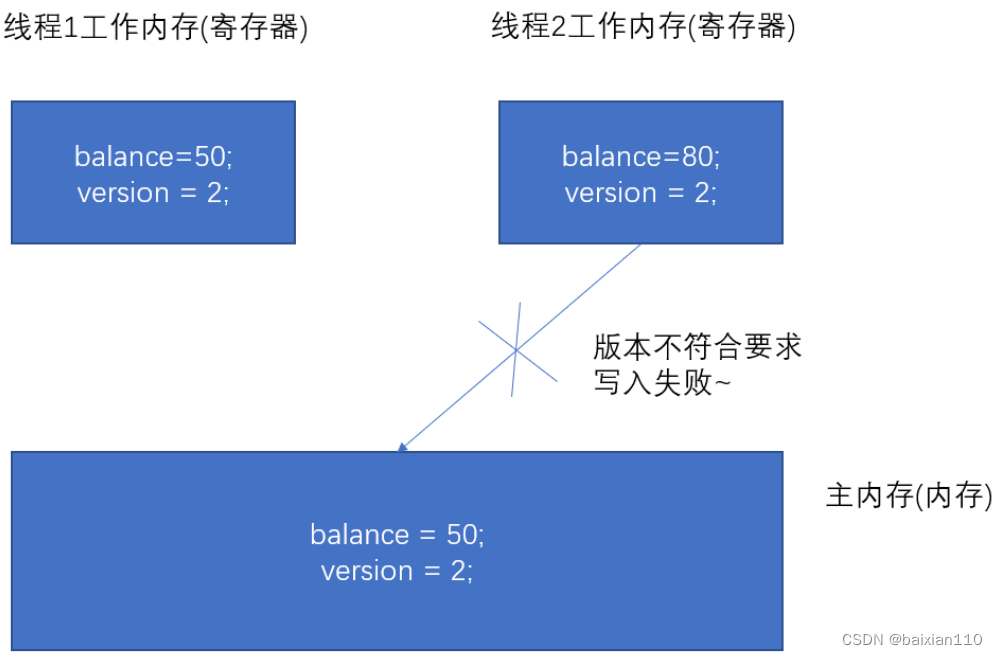
- 线程 B 完成了操作,也将版本号加1( version=2 )试图向内存中提交数据( balance=80 ),但此时比对版本发现,操作员 B 提交的数据版本号为 2 ,数据库记录的当前版本也为 2 ,不 满足 “提交版本必须大于记录当前版本才能执行更新“ 的乐观锁策略。就认为这次操作失败.
1.5重量级锁 vs 轻量级锁
锁的核心特性 “原子性”, 这样的机制追根溯源是 CPU 这样的硬件设备提供的.
- CPU 提供了 “原子操作指令”.
- 操作系统基于CPU的原子指令实现了mutex互斥锁
- JVM基于操作系统提供的互斥锁,实现了synchronized和reenttrantlock等关键字和类
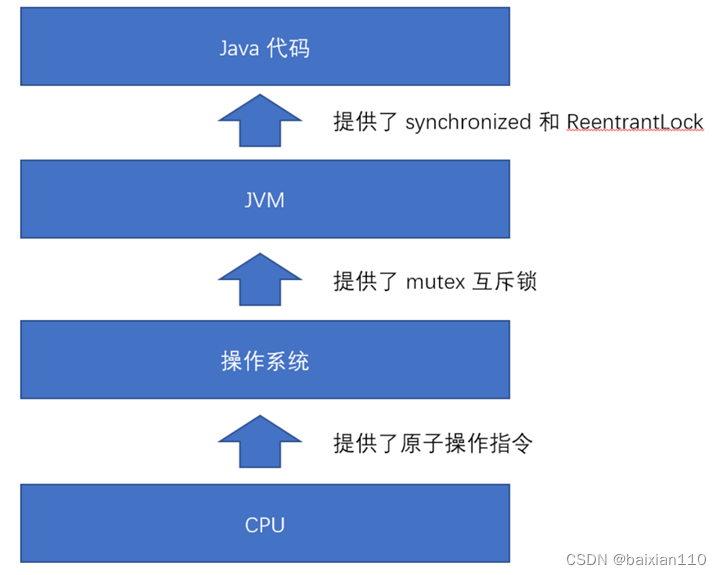
重量级锁: 加锁机制重度依赖了 OS 提供了 mutex
大量的内核态用户态切换,很容易引发线程的调度
这两个操作, 成本比较高. 一旦涉及到用户态和内核态的切换, 就意味着 “沧海桑田”.
轻量级锁: 加锁机制尽可能不使用 mutex, 而是尽量在用户态代码完成. 实在搞不定了, 再使用 mutex.,少量的内核态用户态切换.
不太容易引发线程调度.
理解用户态 vs 内核态
想象去银行办业务.在窗口外, 自己做, 这是用户态. 用户态的时间成本是比较可控的.在窗口内, 工作人员做, 这是内核态. 内核态的时间成本是不太可控的. 如果办业务的时候反复和工作人员沟通, 还需要重新排队, 这时效率是很低的.
synchronized 开始是一个轻量级锁. 如果锁冲突比较严重, 就会变成重量级锁.
1.6自旋锁(Spin Lock)与挂起等待锁
按之前的方式,线程在抢锁失败后进入阻塞状态,放弃 CPU,需要过很久才能再次被调度.但实际上, 大部分情况下,虽然当前抢锁失败,但过不了很久,锁就会被释放。没必要就放弃 CPU. 这个 时候就可以使用自旋锁来处理这样的问题.
自旋锁伪代码
while (抢锁(lock) == 失败) {}
如果获取锁失败, 立即再尝试获取锁, 无限循环, 直到获取到锁为止. 第一次获取锁失败, 第二次的尝试会在极短的时间内到来.一旦锁被其他线程释放, 就能第一时间获取到锁.
理解自旋锁 vs 挂起等待锁
想象一下, 去追求一个女神. 当男生向女神表白后, 女神说: 你是个好人, 但是我有男朋友了~~
挂起等待锁: 陷入沉沦不能自拔… 过了很久很久之后, 突然女神发来消息, “咱俩要不试试?” (注意,这个很长的时间间隔里, 女神可能已经换了好几个男票了).
自旋锁: 死皮赖脸坚韧不拔. 仍然每天持续的和女神说早安晚安. 一旦女神和上一任分手, 那么就能立刻抓住机会上位.
自旋锁是一种典型的 轻量级锁 的实现方式.
优点: 没有放弃 CPU, 不涉及线程阻塞和调度, 一旦锁被释放, 就能第一时间获取到锁.
缺点: 如果锁被其他线程持有的时间比较久, 那么就会持续的消耗 CPU 资源. (而挂起等待的时候是 不消耗 CPU 的).
synchronized 中的轻量级锁策略大概率就是通过自旋锁的方式实现的.
1.7Synchronized所用到的锁策略
结合上面的锁策略, 我们就可以总结出, Synchronized 具有以下特性(只考虑 JDK 1.8):
- 开始时是乐观锁, 如果锁冲突频繁, 就转换为悲观锁.
- 开始是轻量级锁实现, 如果锁被持有的时间较长, 就转换成重量级锁.
- 实现轻量级锁的时候大概率用到的自旋锁策略,实现重量级锁大概率是使用挂起等待锁
- 是一种不公平锁
- 是一种可重入锁
- 不是读写锁
二、CAS
现在寄存器里面有两个值旧的预期值A,需要修改的新值B。而内存中有一个值是原数据V。我们要做以下操作
- 比较 A 与 V 是否相等。(比较)
- 如果比较相等,将 B 写入 V。(交换)
- 返回操作是否成功。
此处最特别的地方,上述CAS的过程不是通过一段代码实现(不是通过多个指令完成),而是一条指令完成,这就保证了操作的原子性。,这样就可以在一定程度上规避了线程安全问题。
所以这里给了我们另外一种解决线程安全问题的途径,我们之前都是从代码层面用加锁和解锁的方式保证操作的原子性,但是现在我们还从指令的原子性入手。
所以CAS可以理解为CPU给我们提供了原生指令,这个指令可以帮助我们解决线程安全问题。
2.1CAS的应用场景
1.基于CAS实现原子类
标准库准库中提供了 java.util.concurrent.atomic 包, 里面的类都是基于这种方式来实现的.
典型的就是 AtomicInteger 类. 其中的 getAndIncrement 相当于 i++ 操作,incrementAndGet相当于++i
所以我们的之前线程不安全的自增程序可以这样修改
package thread;import java.util.concurrent.atomic.AtomicInteger;public class ThreadDemo30 {public static void main(String[] args) {//这些原子类,就是基于CSA实现了原子性的自增、自减,此时这些类的操作不需要加锁,也是线程安全的AtomicInteger count = new AtomicInteger(0);Thread thread1 = new Thread(()->{for(int i = 0;i<500;i++) {
// count++;//count是AtomicInteger类型,自增就不再使用++了count.getAndIncrement();//相当于count++
// count.incrementAndGet();//相当于++count}});Thread thread2 = new Thread(()->{for(int i = 0;i<500;i++) {count.getAndIncrement();}});thread1.start();thread2.start();try {thread1.join();} catch (InterruptedException e) {e.printStackTrace();}try {thread2.join();} catch (InterruptedException e) {e.printStackTrace();}System.out.println(count.get());}}
AtomicInteger.getAndIncrement 的过程详解
class AtomicInteger { private int value;public int getAndIncrement() { int oldValue = value;while ( CAS(value, oldValue, oldValue+1) != true) { oldValue = value;}return oldValue; }
}
这里是伪代码,这里的oldValue 等变量应该理解为寄存器里面的值,value代表内存中的值,另外两个代表寄存器里的值。
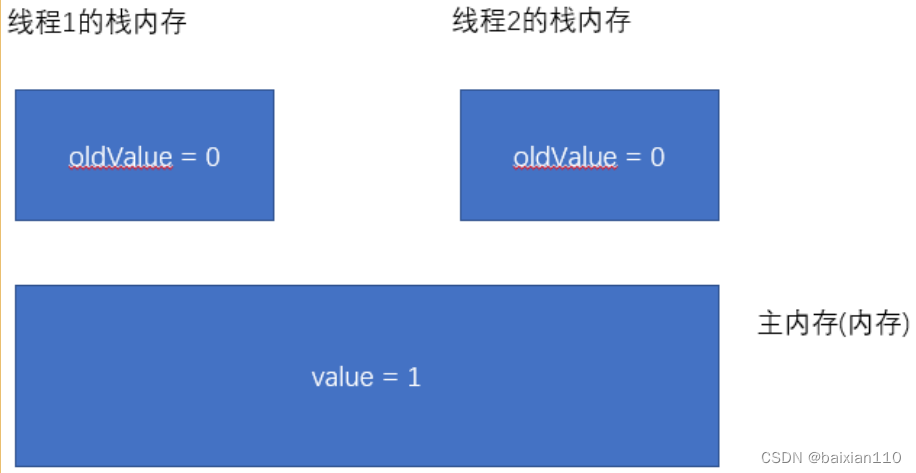
假设两个线程同时调用 getAndIncrement
- 两个线程都读取 value 的值到 oldValue 中. (oldValue 是一个局部变量, 在栈上. 每个线程有自己的栈)

-
线程1 先执行 CAS 操作. 由于 oldValue 和 value 的值相同, 直接进行对 value 赋值.
注意:
CAS 是直接读写内存的, 而不是操作寄存器.
CAS 的读内存, 比较, 写内存操作是一条硬件指令, 是原子的.
-
线程2 再执行 CAS 操作, 第一次 CAS 的时候发现 oldValue 和 value 不相等, (要注意第一步说了是线程1和2一起读的value,所以这里oldvalue值为0,然后cas是value的值为1)不能进行赋值. 因此需要 进入循环.在循环里重新读取 value 的值赋给 oldValue
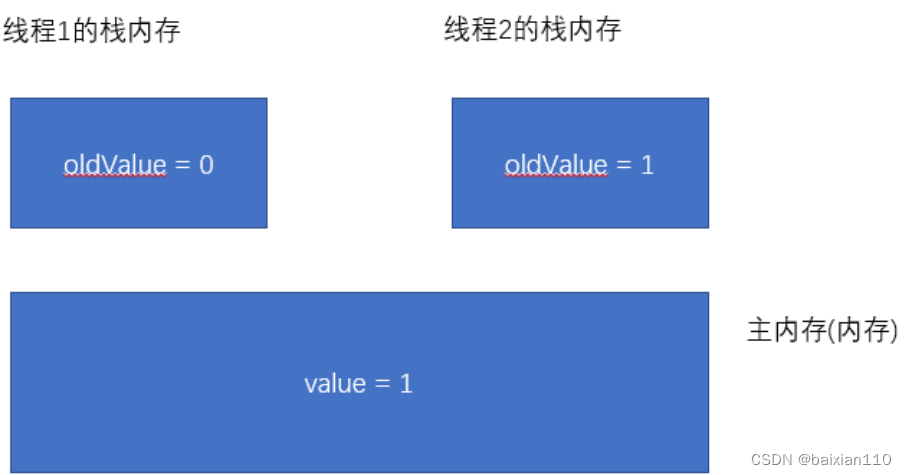
-
线程2 接下来第二次执行 CAS, 此时 oldValue 和 value 相同, 于是直接执行赋值操作.
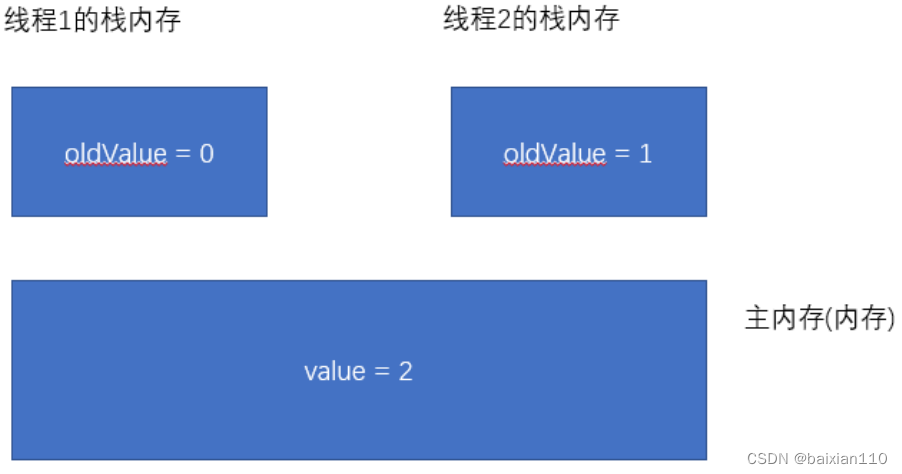
-
线程1 和 线程2 返回各自的 oldValue 的值即可.
通过形如上述代码就可以实现一个原子类. 不需要使用重量级锁, 就可以高效的完成多线程的自增操作.
2.2 实现自旋锁
基于 CAS 实现更灵活的锁, 获取到更多的控制权.
自旋锁伪代码
public class SpinLock {private Thread owner = null; public void lock(){// 通过 CAS 看当前锁是否被某个线程持有.// 如果这个锁已经被别的线程持有, 那么就自旋等待.// 如果这个锁没有被别的线程持有, 那么就把 owner 设为当前尝试加锁的线程. while(!CAS(this.owner, null, Thread.currentThread())){} }public void unlock (){ this.owner = null; }
}
2.3CAS的典型问题
CAS运行的核心就在于检查value值和oldValue值是否一致,如果一致,就视作value中途么有被修改,所以进行下一步操作是没有问题的。
但是这里就有一个问题了,如果是vlue值被修改了,然后又被修改回原来的值了呢?
这就是ABA的问题
针对上述问题,很好解决,引入版本号就可以,之前是以内存中的值是不是变动了来确定内存中的值有没有被修改,但是这样会有回退的情况,但是版本号只会增不会减,也就避免了上述的ABA情况了。
在 Java 标准库中提供了 AtomicStampedReference 类. 这个类可以对某个类进行包装, 在内部就提 供了上面描述的版本管理功能.
三、Synchronized原理
3.1基本特点
结合上面的锁策略, 我们就可以总结出, Synchronized 具有以下特性(只考虑 JDK 1.8):
- 开始时是乐观锁, 如果锁冲突频繁, 就转换为悲观锁.
- 开始是轻量级锁实现, 如果锁被持有的时间较长, 就转换成重量级锁.
- 实现轻量级锁的时候大概率用到的自旋锁策略
- 是一种不公平锁
- 是一种可重入锁
- 不是读写锁
3.2加锁工作过程(锁升级)
JVM 将 synchronized 锁分为 无锁、偏向锁、轻量级锁、重量级锁 状态。会根据情况,进行依次升级。
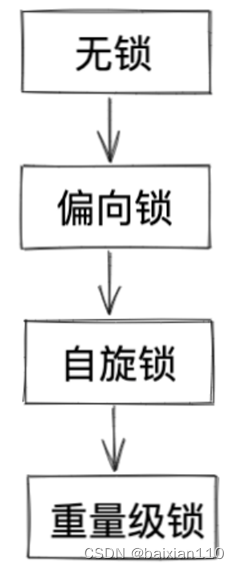
当第一个线程访问的时候,Sychronized先进入偏向锁的形式
但是,实际上偏向锁并不是锁,
偏向锁不是真的 “加锁”, 只是给对象头中做一个 “偏向锁的标记”, 记录这个锁属于哪个线程.
如果后续没有其他线程来竞争该锁, 那么就不用进行其他同步操作了(避免了加锁解锁的开销)
如果后续有其他线程来竞争该锁(刚才已经在锁对象中记录了当前锁属于哪个线程了, 很容易识别当前申请锁的线程是不是之前记录的线程), 那就取消原来的偏向锁状态, 进入一般的轻量级锁状态.
偏向锁本质上相当于 “延迟加锁” . 能不加锁就不加锁, 尽量来避免不必要的加锁开销.但是该做的标记还是得做的, 否则无法区分何时需要真正加锁.
当sycchronized发生锁竞争的时候,就会从偏向锁升级成轻量级锁,此时sysycchronized就是采用类似CAS的方式通过自旋的方式来加锁。所以此时这个线程还是大部分时间占用着CPU的,如果此时锁竞争比较小,自旋对于系统而言是合理的,但是一旦锁竞争开始逐步加大,这个线程开始长时间竞争不到锁,那就不能保持自旋状态了,需要变为重量级锁,也就是以挂起等待的方式去实现,此时就要释放CPU资源了。
重量级锁是基于操作系统API实现的,也就是前面说过的JVM通过调用Linux(以linux系统为例)系统的原生API mutex进行加锁和解锁,而这个API底层的实现依靠的就CPU线程的调度。此时如果这个线程竞争不到锁,就会放到阻塞对列中
四、JVM中的其他的锁优化
4.1消除锁
这是编译器自动的优化的,程序员是感知不到的,就是如果JVM判断当前情况下没有加锁的需要,那么即使程序员在代码里有加锁的操作,JVM也会对这个锁进行优化。
比如说我们都知道StringBuffer是线程安全的,本质就是因为它里面的每个操作都有sychronize修饰,也就是都有加锁操作,但是如果我只是在单线程的情况下去使用StringBuffer,那么实际JVM在背后是消除了这个锁的。
StringBuffer sb = new StringBuffer();
sb.append("a");
sb.append("b");
sb.append("c");
sb.append("d");
4.2锁粗化
一段逻辑中如果出现多次加锁解锁, 编译器 + JVM 会自动进行锁的粗化.
首先说一个概念叫做锁的粒度
Sychronized中所包含的代码越多,粒度就会越粗,反之则越细。
通常情况下锁的粒度是细一点比较好的,锁越粗就代表不能并发执行的代码很多,所以锁细一点代码并发程度理论上会高一点。
但是有的情况反而会对锁进行粗化
比如说

在一段时间内,一个锁的加锁解锁间隔时间很短,那么不如直接用一把大锁将这三段代码包含进去。这就是锁粗化。
实际开发过程中, 使用细粒度锁, 是期望释放锁的时候其他线程能使用锁.
但是实际上可能并没有其他线程来抢占这个锁. 这种情况 JVM 就会自动把锁粗化, 避免频繁申请释放锁.
五、JUC常见类
JUC 为 java.until.concurrent,这个包里存的就是并发编程的相关工具类
5.1Callable接口
- Callable接口与Runable接口的作用的是一样的,但是Callable是带泛型型参数的,重写里面的call方法(与run方法类似)返回的就是泛型类型的数据。
- callable是不能直接作为new thread()的参数的,这一点与runable不同。而是要在封装在futureTask类中,在传入new thread中。
比如说现在我想要从1+2+3 。。。。。。如果用runable我只能使用一个类进行实例化,采用引用的方式在不同在线程中记录加过的值
package thread;
class Counter3{int sum ;}public class ThreadDemo31 {public static void main(String[] args) {Object locker = new Object();Counter3 counter = new Counter3();Thread thread1 = new Thread(){@Overridepublic void run() {counter.sum = 0;synchronized (locker){for(int i = 1; i <= 4; i++) {counter.sum= counter.sum+i;}locker.notify();}}};thread1.start();synchronized (locker){try {locker.wait();} catch (InterruptedException e) {e.printStackTrace();}System.out.println(counter.sum);}}
}
但是如果使用callable就不一样了
- 创建一个匿名内部类, 实现 Callable 接口. Callable 带有泛型参数. 泛型参数表示返回值的类型.
- 重写 Callable 的 call 方法, 完成累加的过程. 直接通过返回值返回计算结果.把 callable 实例使用 FutureTask 包装一下.
- 创建线程, 线程的构造方法传入 FutureTask . 此时新线程就会执行 FutureTask 内部的 Callable 的 call 方法, 完成计算. 计算结果就放到了 FutureTask 对象中.
- 在主线程中调用 futureTask.get() 能够阻塞等待新线程计算完毕. 并获取到 FutureTask 中的结 果.
package thread;import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask;public class ThreadDemo32 {public static void main(String[] args) throws ExecutionException, InterruptedException {Callable<Integer> callable = new Callable<Integer>() {@Overridepublic Integer call() throws Exception {int sum= 0;for (int i = 1; i <= 4; i++) {sum = sum+i;}return sum;}};FutureTask<Integer> futureTask = new FutureTask<Integer>(callable);Thread thread1 = new Thread(futureTask);thread1.start();System.out.println(futureTask.get());}
}
5.2 RentrantLock
可重入互斥锁. 和 synchronized 定位类似, 都是用来实现互斥效果, 保证线程安全.ReentrantLock 也是可重入锁. “Reentrant” 这个单词的原意就是 “可重入”
ReentrantLock 的用法:
lock(): 加锁, 如果获取不到锁就死等.
trylock(超时时间): 加锁, 如果获取不到锁, 等待一定的时间之后就放弃加锁.
unlock(): 解锁
package thread;import java.util.concurrent.locks.ReentrantLock;public class TreadDemo33 {public static void main(String[] args) {ReentrantLock reentrantLock = new ReentrantLock();reentrantLock.lock();//解锁//需要加锁的代码reentrantLock.unlock();//解锁}
}
与Sychronized第一个不同就在于ReentrantLock的加锁解锁是依据代码的顺序执行,而Sychronized则是以代码块形式。这有好有坏。
好处在于ReentratLock比Sychronized更加灵活(更灵活一方卖弄体现在这里另一方ReentratLock可以自主决定什么时候解锁,而Sy是一直死等的,如果到代码块结束才会解锁)。
那么这样的坏处也很明显,就是解锁可能存在根本执行不到的情况。
不如说要加锁的代码中有return,有循环等都可能导致代码执行中途就停止执行了,导致锁并没有释放。
所以使用ReentrantLock必须搭配try finally使用,把解锁操作放入finally中,才能保证无论如何一定会被解锁
package thread;import java.util.concurrent.locks.ReentrantLock;public class TreadDemo33 {public static void main(String[] args) {ReentrantLock reentrantLock = new ReentrantLock();try{reentrantLock.lock();//解锁//需要加锁的代码}finally {reentrantLock.unlock();//解锁}}
}
此外ReentrantLock比Sychronized更有优势的地方在于
- ReentrantLock构造方法中提供了实现公平锁的版本,所以ReentrantLock可以实现公平锁,只需要输入true即可
ReentrantLock reentrantLock = new ReentrantLock(true);
- 对于Sychronized而言加不上锁只会死等,但是ReentrantLock并不是,提供了trylock方法,而trylock也有有参数版本,和无参数版本无参版本表示能加锁就加锁,不能加锁就直接放弃,不执行了。
而有参版本表示在规定时间内尝试加锁,如果得到规定时间还是没有获取到所,就放弃。
trylock本身也有返回值,我们可以通过返回值确定到底有没有加锁从而确定要不要解锁。
reentrantLock.lock();//死等加锁reentrantLock.tryLock();//尝试加锁reentrantLock.tryLock();//规定时间尝试加锁
ReentrantLock 和 synchronized 的区别:
- synchronized 是一个关键字, 是 JVM 内部实现的(大概率是基于 C++ 实现). ReentrantLock 是标准 库的一个类, 在 JVM 外实现的(基于 Java 实现).
- synchronized 使用时不需要手动释放锁. ReentrantLock 使用时需要手动释放. 使用起来更灵活, 但是也容易遗漏 unlock,同时还要搭配try-finally使用
- synchronized 在申请锁失败时, 会死等. ReentrantLock 可以通过 trylock 的方式等待一段时间就 放弃.
- synchronized 是非公平锁, ReentrantLock 默认是非公平锁. 可以通过构造方法传入一个 true 开启 公平锁模式.
- 更强大的唤醒机制. synchronized 是通过 Object 的 wait / notify 实现等待-唤醒. 每次唤醒的是一 个随机等待的线程. ReentrantLock 搭配 Condition 类实现等待-唤醒, 可以更精确控制唤醒某个指定的线程
实际开发还是使用Sychronied居多。
有么有可能Sychronied和ReentrantLock能不能加锁同一个对象呢?
答案是不可能,原因两个机制是完全不同的,Sy是这对{}里面的对象,本质是操作对象的“对象头”里的特殊的数据结构,这个部分是JVM内部C++实现的代码
而ReentrantLock锁的对象实际就是我们定义的ReentrantLock实例,这是在java代码层面实现的对锁对象的控制。
如何选择使用哪个锁?
- 锁竞争不激烈的时候, 使用 synchronized, 效率更高, 自动释放更方便.
- 锁竞争激烈的时候, 使用 ReentrantLock, 搭配 trylock 更灵活控制- 加锁的行为, 而不是死等. 如果需要使用公平锁, 使用 ReentrantLock.
5.3原子类
原子类内部用的是 CAS 实现,所以性能要比加锁实现 i++ 高很多。原子类有以下几个
AtomicBoolean
AtomicInteger
AtomicIntegerArray
AtomicLong
AtomicReference
AtomicStampedReference
以 AtomicInteger 举例,常见方法有
addAndGet(int delta); i += delta;
decrementAndGet(); --i;
getAndDecrement(); i--;
incrementAndGet(); ++i;
getAndIncrement(); i++;
这个我们之前提过,这里就不过多赘述了
5.4信号量 Semaphore
信号量, 用来表示 “可用资源的个数”. 本质上就是一个计数器.
操作系统里面也有信号量的概念,这里的信号量确实就是操作系统里面那个信号量,只不过这里多了一个java的封装。
理解信号量
可以把信号量想象成是停车场的展示牌: 当前有车位 100 个. 表示有 100 个可用资源. 当有车开进去的时候, 就相当于申请一个可用资源, 可用车位就 -1 (这个称为信号量的 P 操作) 当有车开出来的时候, 就相当于释放一个可用资源, 可用车位就 +1 (这个称为信号量的 V 操作) 如果计数器的值已经为 0 了, 还尝试申请资源, 就会阻塞等待, 直到有其他线程释放资源.Semaphore 的 PV 操作中的加减计数器操作都是原子的, 可以在多线程环境下直接使用.
代码示例
创建 Semaphore 示例, 初始化为 4, 表示有 4 个可用资源.
acquire 方法表示申请资源(P操作),
release 方法表示释放资源(V操作)
创建 20 个线程, 每个线程都尝试申请资源, sleep 1秒之后, 释放资源. 观察程序的执行效果.
Semaphore semaphore = new Semaphore(4);
Runnable runnable = new Runnable() {@Overridepublic void run() { try {System.out.println("申请资源"); semaphore.acquire();System.out.println("我获取到资源了"); Thread.sleep(1000);System.out.println("我释放资源了"); semaphore.release();} catch (InterruptedException e) { e.printStackTrace();} }
};
for (int i = 0; i < 20; i++) {Thread t = new Thread(runnable); t.start();
}
六、线程安全的集合类
原来的集合类, 大部分都不是线程安全的.
Vector, Stack, HashTable, 是线程安全的(不建议用), 其他的集合类不是线程安全的.
多线程环境使用 ArrayList
- 自己使用同步机制 (synchronized 或者 ReentrantLock)
前面做过很多相关的讨论了. 此处不再展开. - Collections.synchronizedList(new ArrayList);
synchronizedList 是标准库提供的一个基于 synchronized 进行线程同步的 List. synchronizedList 的关键操作上都带有 synchronized - 使用 CopyOnWriteArrayList
CopyOnWrite容器即写时复制的容器(COW写时拷贝)
当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy, 复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。
所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
优点:
在读多写少的场景下, 性能很高, 不需要加锁竞争.
缺点:
- 占用内存较多.
- 新写的数据不能被第一时间读取到.
- 只适用于队列内存比较小的时候,如果很大拷贝所带来的系统开销很大
所以这种方式很适合服务器程序的配置的维护。因为修改配置可能需要重启服务器才能生效,所以很多服务器都有热部署(热加载)。而热加载使用的就是写时拷贝的思路,新的配置加入到新的对象中,加载过程中,请求仍然需要基于旧的配置进行,在新的对象加载完毕后,再替换。
多线程环境使用队列
- ArrayBlockingQueue
基于数组实现的阻塞队列 - LinkedBlockingQueue
基于链表实现的阻塞队列 - PriorityBlockingQueue
基于堆实现的带优先级的阻塞队列 - TransferQueue
最多只包含一个元素的阻塞队列
多线程环境使用哈希表
HashMap 本身不是线程安全的.
在多线程环境下使用哈希表可以使用:
Hashtable
ConcurrentHashMap(更推荐)
ConcurrentHashMap VS Hashtable
相比于 Hashtable 做出了一系列的改进和优化.
- 最大的优化在于ConcurrentHashMap 相较于Hashtable大大降低锁冲突的概率,把一把大锁,转换成了多把小锁。HashTable线程安全就是在每个方法上加上Sychronized,换句话说,他就是简单粗暴对this加锁,所以基本上只要调用HashTable的方法就有存在加锁和解锁问题。但是实际上hashTable本身在设计上读写冲突就 比一般的数据结构要小。
假如说元素A 和元素B都在同一个链表上(指的是HashTable的每一个hashcode对应一个链表),那么两个不同线程分别对AB元素增删改确实会存在线程安全问题。但是如果AB两个元素在不同链表上,实际不会有线程安全问题。
所以如果是使用hashTable,他是对整个对象都加了锁,随意我对不同链表上AB元素操作也是不能同时进行的。但是他们本身是可以并行的。
那么ConcurentHashmap是怎么做的呢?他是每个链表都会有一个锁,只有申请同一个对象的锁才会有锁竞争,这样就大大降低了锁竞争。
相关文章:
多线程(进阶)
一、常见的锁策略 1.1读写锁 多线程之间,数据的读取方之间不会产生线程安全问题,但数据的写入方互相之间以及和读者之间都需 要进行互斥。如果两种场景下都用同一个锁,就会产生极大的性能损耗。所以读写锁因此而产生。 读写锁(r…...

端口输入的数据为什么要打拍?
一次作者在开发图像时候,对输入的图像没有打拍,直接输出给显示终端,时好时坏,或者图像颜色不正确,最终经过打拍解决了此问题。 //配置为16-Bit SDR ITU-R BT.656模式时pixel_data[23:16]为高阻。always (posedge pixe…...
Qt读写Excel--QXlsx编译为静态库2
1、概述🥔 在使用QXlsx时由于源码文件比较多,如果直接加载进项目里面,会增加每次编译的时间; 直接将源码加载进项目工程中,会导致项目文件非常多,结构变得更加臃肿; 所以在本文中将会将QXlsx编译…...
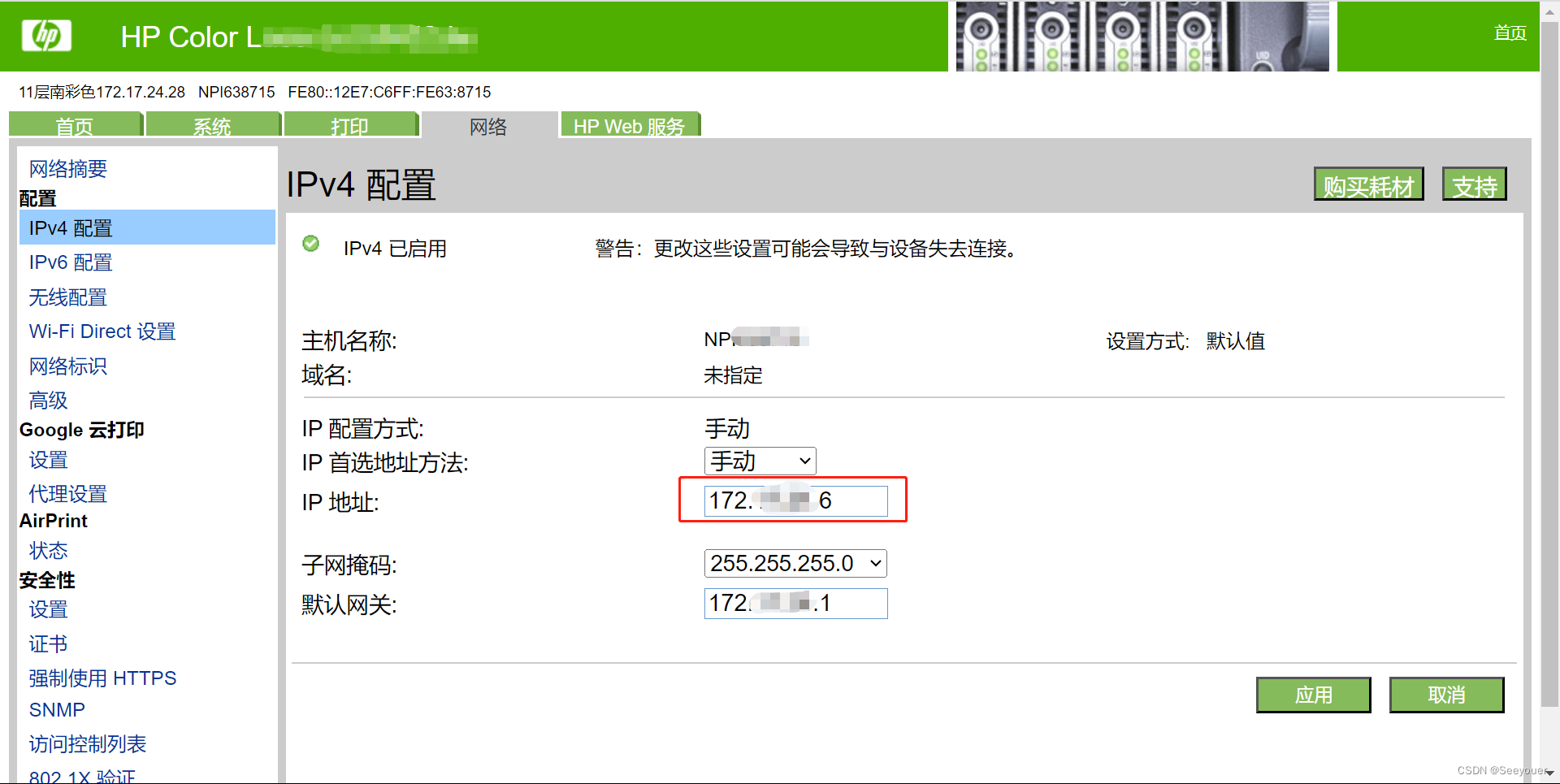
win11电脑查找已连接打印机ip的方法
此方法适用于驱动打印机,windows 11操作系统。 方法一:直接查看法 首先大家可以看看自己的打印机有没有lcd屏幕。有些直接在屏幕显示ip;另一种进入菜单,然后可以在里面的选项中显示“ip地址”。 方法二:设置中查看 …...
测试开发探索:“WeTalk“网页聊天室的测试流程与自动化
目录 引言: 测试开发目标: "WeTalk"项目背景 关于登录测试用例的设计 测试开发策略与流程 集成测试:Selenium JUnit 接口测试:Postman 测试用例的设计与实现 自动化测试演示: 用例一:登…...

图片增强组件实现
设计并实现了一个图片增强的组件,具体功能如下: 图片数据增强,包括且不限于:图片旋转、比例增强、高斯噪声、饱和度变换等若图片包含对应标注boundingbox,也支持对应变换,保证圈选内容的不变性实现多种方式…...

go.sum are different when using go mod vendor/download
本地Golang配置 今天本地编译一个项目,遇到以下错误 PS D:\Code\Golang\jiankunking\k8s-ext> go mod tidy go: downloading github.com/huaweicloud/huaweicloud-sdk-go-obs v3.23.4incompatible verifying github.com/gin-gonic/ginv1.7.3: checksum mismat…...

Docker技术入门教程
Docker技术入门教程 一、docker概念 一款产品从开发到上线,从操作系统,到运行环境,再到应用配置。作为开发运维之间的协作我们需要关心很多东西,这也是很多互联网公司都不得不面对的问题,特别是各种版本的迭代之后&a…...
Vue2-组件,组件的使用及注意点,组件嵌套,VueComponent构造函数,单文件组件
🥔:功不唐捐 更多Vue知识请点击——Vue.js VUE-Day5 组件与使用组件的三大步1、定义组件(创建组件)2、注册组件①局部注册②全局注册 3、使用组件小案例: 使用组件的一些注意点1.关于组件名2.关于组件标签3.一个简写方式 组件的嵌套VueCompon…...
IntelliJ IDEA Bookmark使用
1 增加 右键行号栏 2 查看 从favorite这里查看 参考IntelliJ IDEA 小技巧:Bookmark(书签)的使用_bookmark idea 使用_大唐冠军侯的博客-CSDN博客...
kriging-contour前端克里金插值
先看效果: 本项目在kriging-contour插件基础上进行了封装,增加了自定义区域插值,gitbub地址。...
)
第八章 CUDA内存应用与性能优化篇(中篇)
cuda教程目录 第一章 指针篇 第二章 CUDA原理篇 第三章 CUDA编译器环境配置篇 第四章 kernel函数基础篇 第五章 kernel索引(index)篇 第六章 kenel矩阵计算实战篇 第七章 kenel实战强化篇 第八章 CUDA内存应用与性能优化篇 第九章 CUDA原子(atomic)实战篇 第十章 CUDA流(strea…...
的远距离、低功耗、低速率WiFi—Wi-Fi HaLow)
适用于物联网 (IoT)的远距离、低功耗、低速率WiFi—Wi-Fi HaLow
1. Wi-Fi 简介 Wi-Fi(Wireless Fidelity)是目前较为常见的无线通信方式,承载着一半以上的互联网流量。Wi-Fi是一个总称,涵盖了802.11通信协议系列,由Wi-Fi联盟持有并推动其发展。802.11通信协议发展至今已逾二十年&am…...
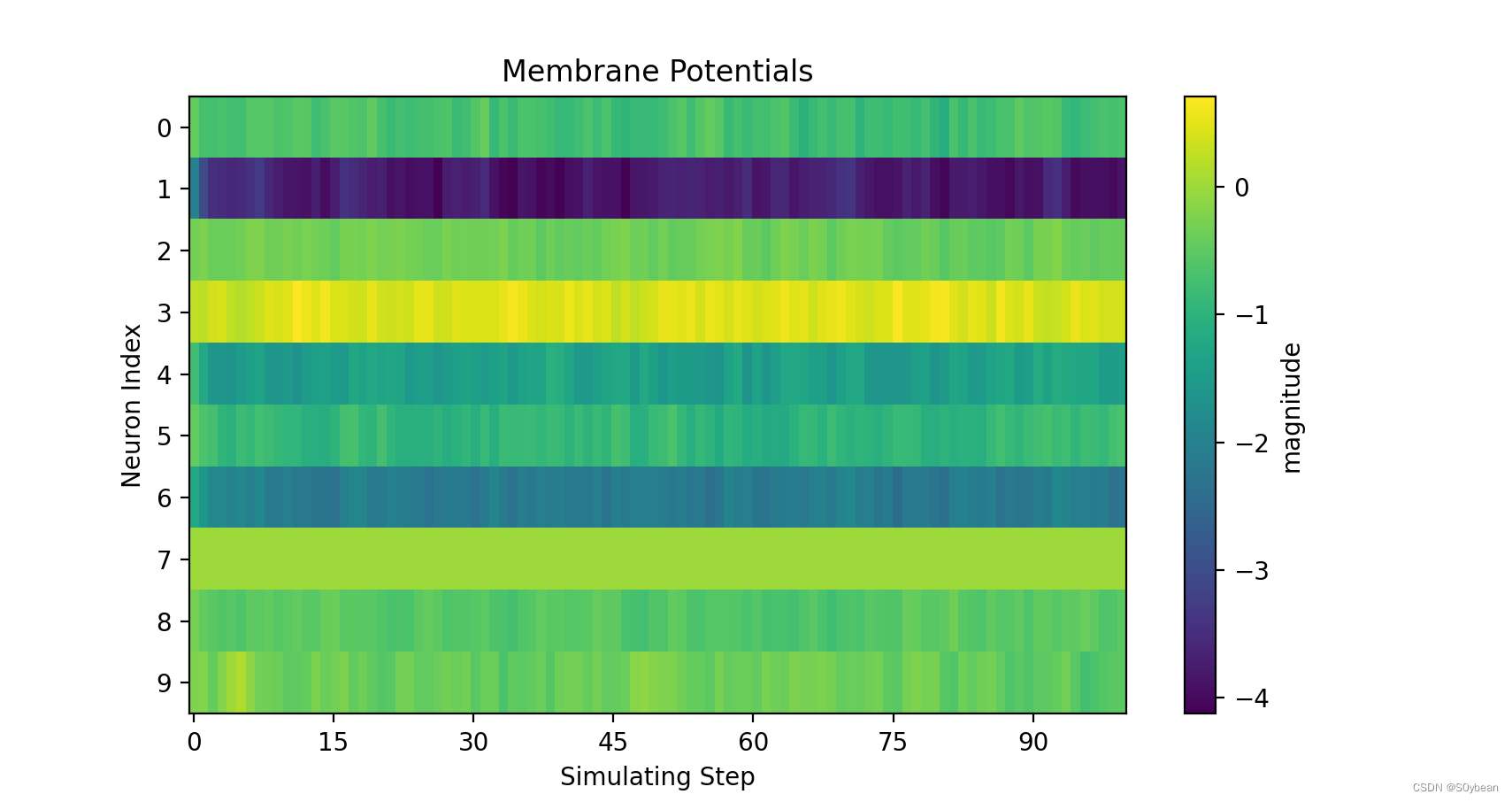
【解读Spikingjelly】使用单层全连接SNN识别MNIST
原文档:使用单层全连接SNN识别MNIST — spikingjelly alpha 文档 代码地址:完整的代码位于activation_based.examples.lif_fc_mnist.py GitHub - fangwei123456/spikingjelly: SpikingJelly is an open-source deep learning framework for Spiking Neur…...

穿越数字奇境:探寻元宇宙中的科技奇迹
随着科技的迅速发展,元宇宙正逐渐成为一个备受关注的话题,它不仅是虚拟现实的延伸,更是将现实世界与数字世界融合的未来典范。在这个神秘而充满活力的数字奇境中,涉及了众多领域和技术,为我们呈现出了一个无限的创新和…...

2024」预备研究生mem-阴影图形
一、阴影图形 二、课后题...

【设计模式】责任链模式
顾名思义,责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。 在这种模式中,通常每个接收者…...

解密人工智能:线性回归 | 逻辑回归 | SVM
文章目录 1、机器学习算法简介1.1 机器学习算法包含的两个步骤1.2 机器学习算法的分类 2、线性回归算法2.1 线性回归的假设是什么?2.2 如何确定线性回归模型的拟合优度?2.3 如何处理线性回归中的异常值? 3、逻辑回归算法3.1 什么是逻辑函数?…...

【FFMPEG应用篇】使用FFmpeg的常见问题
拼接视频的问题 在使用ffmpeg进行视频拼接时,可能会遇到一些常见问题。以下是这些问题及其解决方法: 1. 视频格式不兼容:如果要拼接的视频格式不同,ffmpeg可能会报错。解决方法是使用ffmpeg进行格式转换,将所有视频转…...
(vue)获取对象的键遍历,同时循环el-tab页展示key及内容
(vue)获取对象的键遍历,同时循环el-tab页展示key及内容 效果: 数据结构: "statusData": {"订购广度": [ {"id": 11, "ztName": "广", …...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

179个核心职位,50个公司分类,中国大模型产业全栈
最后 对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大? 答案只有一个:人工智能(尤其是大模型方向)…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...