【解读Spikingjelly】使用单层全连接SNN识别MNIST
原文档:使用单层全连接SNN识别MNIST — spikingjelly alpha 文档
代码地址:完整的代码位于
activation_based.examples.lif_fc_mnist.pyGitHub - fangwei123456/spikingjelly: SpikingJelly is an open-source deep learning framework for Spiking Neural Network (SNN) based on PyTorch.
ZhengyuanGao/spikingjelly: 开源脉冲神经网络深度学习框架 - spikingjelly - OpenI - 启智AI开源社区提供普惠算力! (pcl.ac.cn)a
本文补充一些细节代码以解决运行报错问题,并提供可视化代码,解释核心代码作用以辅助SNN初学者快速入门!
目录
1.网络定义
2.主函数
2.1参数设置
2.2主循环
3.可视化
3.1准确率
3.2测试图片与发放脉冲
3.3脉冲发放与电压
4.完整代码
lif_fc_mnist.py(为减少运行耗时,迭代次数设置为1)
lif_fc_mnist_test.py
1.网络定义
class SNN(nn.Module):def __init__(self, tau):super().__init__()self.layer = nn.Sequential(layer.Flatten(),layer.Linear(28 * 28, 10, bias=False),neuron.LIFNode(tau=tau, surrogate_function=surrogate.ATan()),)def forward(self, x: torch.Tensor):return self.layer(x)(1)super:继承父类torch.nn.Module的初始化方法
(2)Sequential:顺序方式连接网络结构,首先将输入展平为一维,定义全连接层,输入格式28*28,输出10个神经元。Neuron.LIFNode为脉冲神经元层,用于对全连接层的激活,指定膜时间常数与替代函数(解决不可导问题)
(3)forward:重写前向传播函数,返回网络输出结果
2.主函数
2.1参数设置
(1)使用命令行设置LIF神经网络的超参数
parser = argparse.ArgumentParser(description='LIF MNIST Training')parser.add_argument('-T', default=100, type=int, help='simulating time-steps')parser.add_argument('-device', default='cuda:0', help='device')parser.add_argument('-b', default=64, type=int, help='batch size')parser.add_argument('-epochs', default=100, type=int, metavar='N',help='number of total epochs to run')parser.add_argument('-j', default=4, type=int, metavar='N',help='number of data loading workers (default: 4)')
# 添加 default='./MNIST' 以解决无下载所需文件夹问题----------------------------------------parser.add_argument('-data-dir', type=str, default='./MNIST', help='root dir of MNIST dataset')
# -----------------------------------------------------------------------------------------parser.add_argument('-out-dir', type=str, default='./logs', help='root dir for saving logs and checkpoint')parser.add_argument('-resume', type =str, help='resume from the checkpoint path')parser.add_argument('-amp', action='store_true', help='automatic mixed precision training')parser.add_argument('-opt', type=str, choices=['sgd', 'adam'], default='adam', help='use which optimizer. SGD or Adam')parser.add_argument('-momentum', default=0.9, type=float, help='momentum for SGD')parser.add_argument('-lr', default=1e-3, type=float, help='learning rate')parser.add_argument('-tau', default=2.0, type=float, help='parameter tau of LIF neuron')
注:在代码上述标记位置添加 default='./MNIST' 以解决无下载所需文件夹问题
超参数含义如下图所示:

(2) 参数代入:是否自动混合精度训练(PyTorch的自动混合精度(AMP) - 知乎 (zhihu.com))
scaler = Noneif args.amp:scaler = amp.GradScaler()
(3)参数代入:优化器类型
optimizer = Noneif args.opt == 'sgd':optimizer = torch.optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum)elif args.opt == 'adam':optimizer = torch.optim.Adam(net.parameters(), lr=args.lr)else:raise NotImplementedError(args.opt)(4)是否恢复断点训练(if args.resume:从断点处开始继续训练模型)
if args.resume:checkpoint = torch.load(args.resume, map_location='cpu')net.load_state_dict(checkpoint['net'])optimizer.load_state_dict(checkpoint['optimizer'])start_epoch = checkpoint['epoch'] + 1max_test_acc = checkpoint['max_test_acc'](5)泊松编码
encoder = encoding.PoissonEncoder()2.2主循环
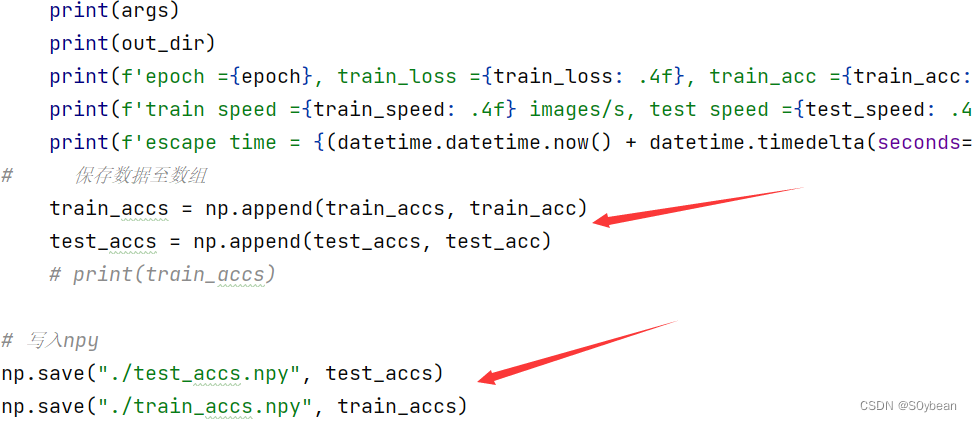
(1)在主循环之前补充创建两个空数组,用于保存训练过程中的准确率,以便后续绘制曲线

(2)加载训练数据(测试数据代码大同小异,不另外分析)
for img, label in train_data_loader:optimizer.zero_grad()img = img.to(args.device)label = label.to(args.device)label_onehot = F.one_hot(label, 10).float()- 循环读取训练数据,在每次循环前,清空优化器梯度
- 将img、label放置到GPU上训练
- 对标签进行独热编码,10个类别(独热编码(One-Hot Encoding) - 知乎 (zhihu.com))
(3)判断是否使用混合精度训练
if scaler is not None:with amp.autocast():out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()else:out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)loss.backward()optimizer.step()如果使用:
- 用amp.autocast()包裹前向计算,使其在浮点16位计算
- 用scaler缩放损失scale(loss)
- 损失回传
- 通过scaler更新优化器
如果不使用混合精度:
- 正常进行前向计算
- 损失函数计算
- 反向传播
- 优化器更新
(4)重置网络
functional.reset_net(net)SNN中的脉冲神经元在前向传播时会积累状态,比如膜电位、释放的脉冲等。重置可以清空这些状态,使网络回到初始状态。
(5)在下图位置添加对应代码保存.npy文件
3.可视化
3.1准确率
在examples文件夹下创建一个.py文件,用于对结果的可视化
代码如下:
import numpy as np
import matplotlib.pyplot as plttest_accs = np.load("./train_accs.npy")
x = []
y = []
maxy = -1
maxx = -1
for t in range(len(test_accs)):if test_accs[t] > maxy:maxy = test_accs[t]maxx = tx.append(t)y.append(test_accs[t])
plt.plot(x, y)
# plt.plot(test_accs)
plt.xlabel('Iteration')
plt.ylabel('Acc')
plt.title('Train Acc')
plt.annotate(r'(%d,%f)' % (maxx, maxy), xy=(maxx, maxy), xycoords='data', xytext=(+10, +20), fontsize=16,arrowprops=dict(arrowstyle='->'), textcoords='offset points')
plt.show()
test_accs = np.load("./test_accs.npy")
x = []
y = []
maxy = -1
maxx = -1
for t in range(len(test_accs)):if test_accs[t] > maxy:maxy = test_accs[t]maxx = tx.append(t)y.append(test_accs[t])
# plt.plot(x, y)
plt.plot(test_accs)
plt.xlabel('Epoch')
plt.ylabel('Acc')
plt.title('Test Acc')
plt.annotate(r'(%d,%f)' % (maxx, maxy), xy=(maxx, maxy), xycoords='data', xytext=(+10, +20), fontsize=16,arrowprops=dict(arrowstyle='->'), textcoords='offset points')
plt.show()
效果:
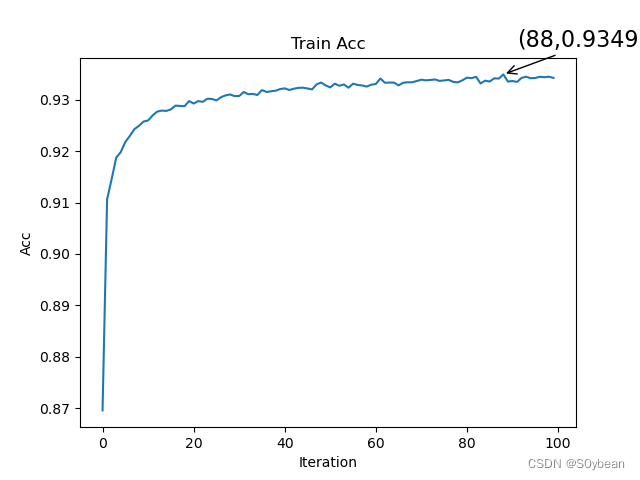
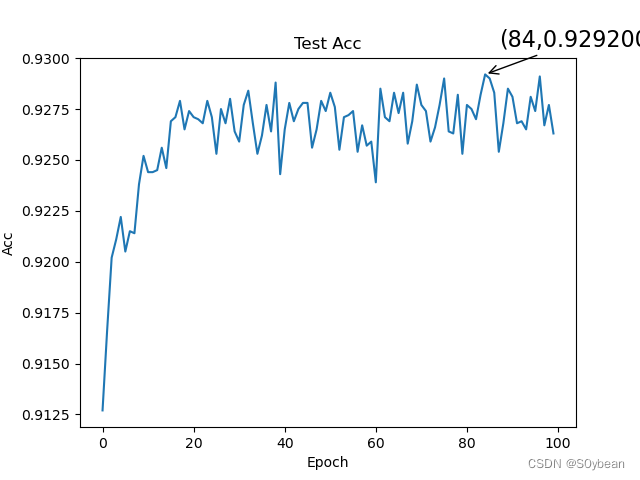
3.2测试图片与发放脉冲
添加如下代码至main()函数的末尾:
img = img.cpu().numpy().reshape(28, 28)plt.subplot(221)plt.imshow(img)plt.subplot(222)plt.imshow(img, cmap='gray')plt.subplot(223)plt.imshow(img, cmap=plt.cm.gray)plt.subplot(224)plt.imshow(img, cmap=plt.cm.gray_r)plt.show()效果:
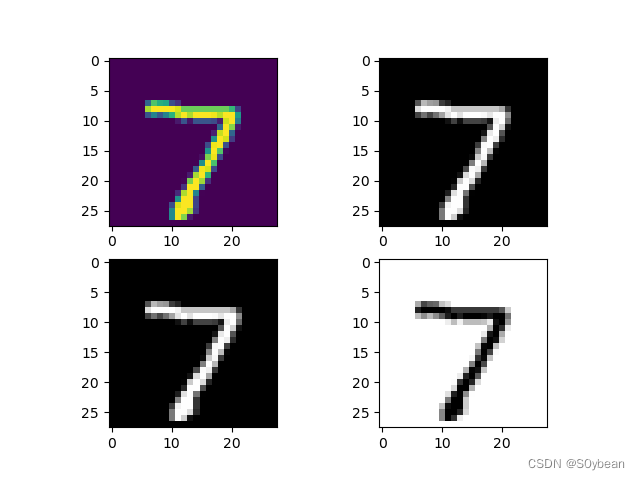
![]()
3.3脉冲发放与电压
新建文件夹,运行如下代码:
test_spike = np.load("./s_t_array.npy")test_mem = np.load('./v_t_array.npy')visualizing.plot_2d_heatmap(array=np.asarray(test_mem), title='Membrane Potentials', xlabel='Simulating Step',ylabel='Neuron Index', int_x_ticks=True, x_max=100, dpi=200)visualizing.plot_1d_spikes(spikes=np.asarray(test_spike), title='Membrane Potentials', xlabel='Simulating Step',ylabel='Neuron Index', dpi=200)plt.show()
效果: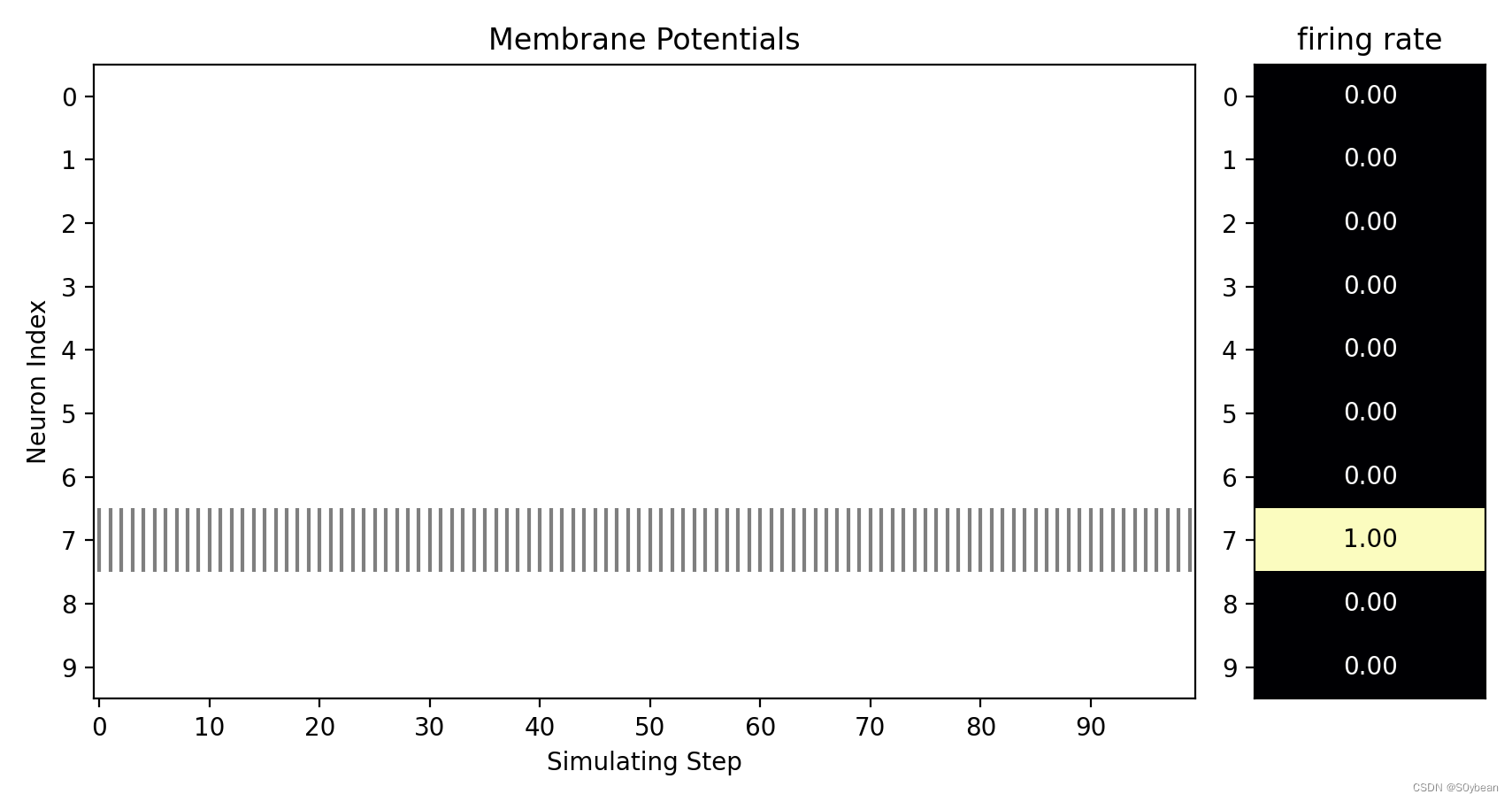
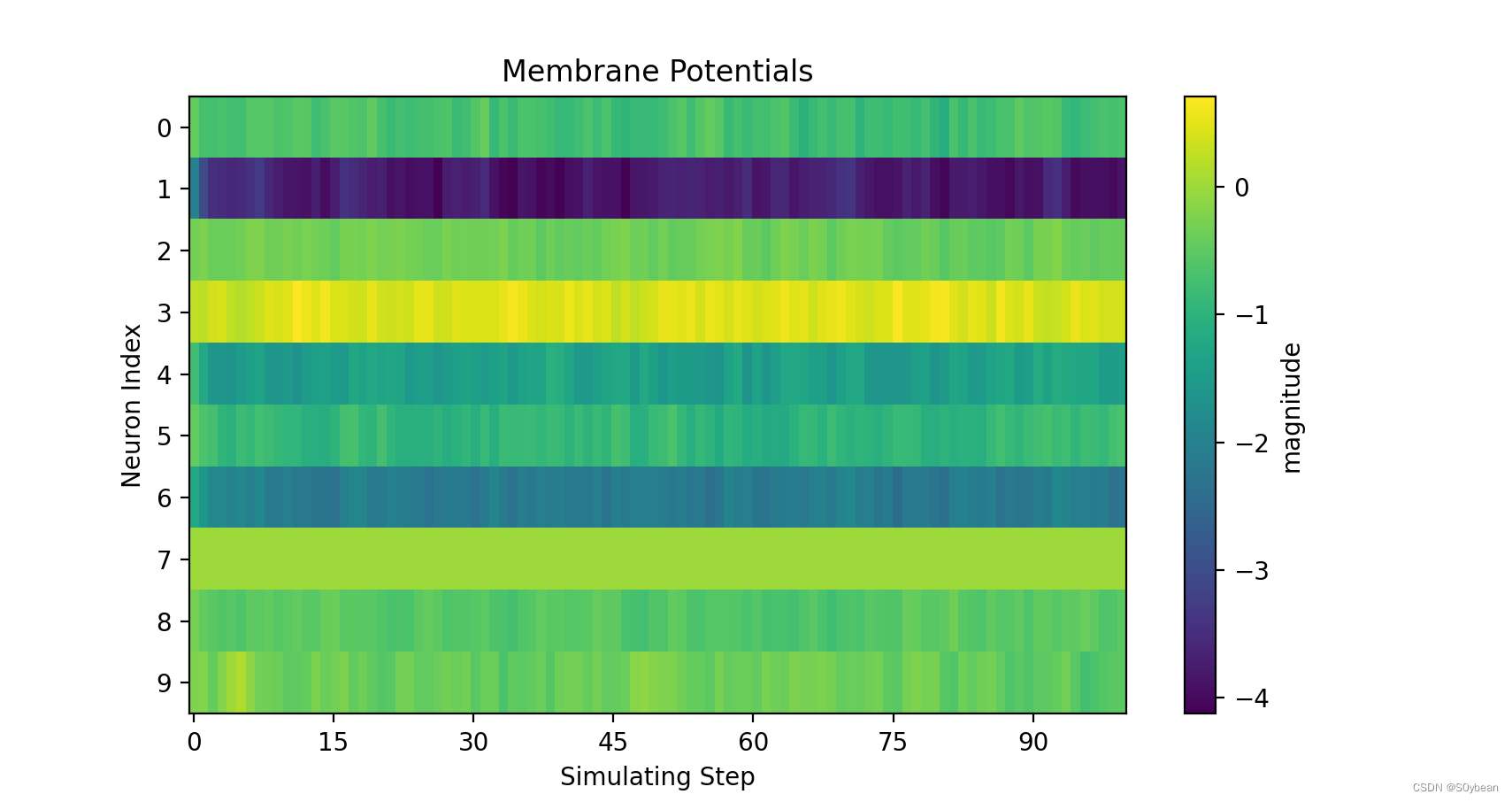
4.完整代码
lif_fc_mnist.py(为减少运行耗时,迭代次数设置为1)
import os
import time
import argparse
import sys
import datetimeimport torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
from torch.cuda import amp
from torch.utils.tensorboard import SummaryWriter
import torchvision
import numpy as np
import matplotlib.pyplot as pltfrom spikingjelly.activation_based import neuron, encoding, functional, surrogate, layerclass SNN(nn.Module):def __init__(self, tau):super().__init__()self.layer = nn.Sequential(layer.Flatten(),layer.Linear(28 * 28, 10, bias=False),neuron.LIFNode(tau=tau, surrogate_function=surrogate.ATan()),)def forward(self, x: torch.Tensor):return self.layer(x)def main():''':return: None* :ref:`API in English <lif_fc_mnist.main-en>`.. _lif_fc_mnist.main-cn:使用全连接-LIF的网络结构,进行MNIST识别。\n这个函数会初始化网络进行训练,并显示训练过程中在测试集的正确率。* :ref:`中文API <lif_fc_mnist.main-cn>`.. _lif_fc_mnist.main-en:The network with FC-LIF structure for classifying MNIST.\nThis function initials the network, starts trainingand shows accuracy on test dataset.'''parser = argparse.ArgumentParser(description='LIF MNIST Training')parser.add_argument('-T', default=100, type=int, help='simulating time-steps')parser.add_argument('-device', default='cuda:0', help='device')parser.add_argument('-b', default=64, type=int, help='batch size')# 100parser.add_argument('-epochs', default=1, type=int, metavar='N',help='number of total epochs to run')parser.add_argument('-j', default=4, type=int, metavar='N',help='number of data loading workers (default: 4)')parser.add_argument('-data-dir', type=str, default='./MNIST', help='root dir of MNIST dataset')parser.add_argument('-out-dir', type=str, default='./logs', help='root dir for saving logs and checkpoint')parser.add_argument('-resume', type =str, help='resume from the checkpoint path')parser.add_argument('-amp', action='store_true', help='automatic mixed precision training')parser.add_argument('-opt', type=str, choices=['sgd', 'adam'], default='adam', help='use which optimizer. SGD or Adam')parser.add_argument('-momentum', default=0.9, type=float, help='momentum for SGD')parser.add_argument('-lr', default=1e-3, type=float, help='learning rate')parser.add_argument('-tau', default=2.0, type=float, help='parameter tau of LIF neuron')args = parser.parse_args()print(args)net = SNN(tau=args.tau)print(net)net.to(args.device)# 初始化数据加载器train_dataset = torchvision.datasets.MNIST(root=args.data_dir,train=True,transform=torchvision.transforms.ToTensor(),download=True)test_dataset = torchvision.datasets.MNIST(root=args.data_dir,train=False,transform=torchvision.transforms.ToTensor(),download=True)train_data_loader = data.DataLoader(dataset=train_dataset,batch_size=args.b,shuffle=True,drop_last=True,num_workers=args.j,pin_memory=True)test_data_loader = data.DataLoader(dataset=test_dataset,batch_size=args.b,shuffle=False,drop_last=False,num_workers=args.j,pin_memory=True)scaler = Noneif args.amp:scaler = amp.GradScaler()start_epoch = 0max_test_acc = -1optimizer = Noneif args.opt == 'sgd':optimizer = torch.optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum)elif args.opt == 'adam':optimizer = torch.optim.Adam(net.parameters(), lr=args.lr)else:raise NotImplementedError(args.opt)if args.resume:checkpoint = torch.load(args.resume, map_location='cpu')net.load_state_dict(checkpoint['net'])optimizer.load_state_dict(checkpoint['optimizer'])start_epoch = checkpoint['epoch'] + 1max_test_acc = checkpoint['max_test_acc']out_dir = os.path.join(args.out_dir, f'T{args.T}_b{args.b}_{args.opt}_lr{args.lr}')if args.amp:out_dir += '_amp'if not os.path.exists(out_dir):os.makedirs(out_dir)print(f'Mkdir {out_dir}.')with open(os.path.join(out_dir, 'args.txt'), 'w', encoding='utf-8') as args_txt:args_txt.write(str(args))writer = SummaryWriter(out_dir, purge_step=start_epoch)with open(os.path.join(out_dir, 'args.txt'), 'w', encoding='utf-8') as args_txt:args_txt.write(str(args))args_txt.write('\n')args_txt.write(' '.join(sys.argv))encoder = encoding.PoissonEncoder()# 创建保存数组train_accs = []test_accs = []for epoch in range(start_epoch, args.epochs):start_time = time.time()net.train()train_loss = 0train_acc = 0train_samples = 0for img, label in train_data_loader:optimizer.zero_grad()img = img.to(args.device)label = label.to(args.device)label_onehot = F.one_hot(label, 10).float()if scaler is not None:with amp.autocast():out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()else:out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)loss.backward()optimizer.step()train_samples += label.numel()train_loss += loss.item() * label.numel()train_acc += (out_fr.argmax(1) == label).float().sum().item()functional.reset_net(net)train_time = time.time()train_speed = train_samples / (train_time - start_time)train_loss /= train_samplestrain_acc /= train_sampleswriter.add_scalar('train_loss', train_loss, epoch)writer.add_scalar('train_acc', train_acc, epoch)net.eval()test_loss = 0test_acc = 0test_samples = 0with torch.no_grad():for img, label in test_data_loader:img = img.to(args.device)label = label.to(args.device)label_onehot = F.one_hot(label, 10).float()out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_fr = out_fr / args.Tloss = F.mse_loss(out_fr, label_onehot)test_samples += label.numel()test_loss += loss.item() * label.numel()test_acc += (out_fr.argmax(1) == label).float().sum().item()functional.reset_net(net)test_time = time.time()test_speed = test_samples / (test_time - train_time)test_loss /= test_samplestest_acc /= test_sampleswriter.add_scalar('test_loss', test_loss, epoch)writer.add_scalar('test_acc', test_acc, epoch)save_max = Falseif test_acc > max_test_acc:max_test_acc = test_accsave_max = Truecheckpoint = {'net': net.state_dict(),'optimizer': optimizer.state_dict(),'epoch': epoch,'max_test_acc': max_test_acc}if save_max:torch.save(checkpoint, os.path.join(out_dir, 'checkpoint_max.pth'))torch.save(checkpoint, os.path.join(out_dir, 'checkpoint_latest.pth'))print(args)print(out_dir)print(f'epoch ={epoch}, train_loss ={train_loss: .4f}, train_acc ={train_acc: .4f}, test_loss ={test_loss: .4f}, test_acc ={test_acc: .4f}, max_test_acc ={max_test_acc: .4f}')print(f'train speed ={train_speed: .4f} images/s, test speed ={test_speed: .4f} images/s')print(f'escape time = {(datetime.datetime.now() + datetime.timedelta(seconds=(time.time() - start_time) * (args.epochs - epoch))).strftime("%Y-%m-%d %H:%M:%S")}\n')# 保存数据至数组train_accs = np.append(train_accs, train_acc)test_accs = np.append(test_accs, test_acc)# print(train_accs)# 写入npynp.save("./test_accs.npy", test_accs)np.save("./train_accs.npy", train_accs)# 保存绘图用数据net.eval()# 注册钩子output_layer = net.layer[-1] # 输出层output_layer.v_seq = []output_layer.s_seq = []def save_hook(m, x, y):m.v_seq.append(m.v.unsqueeze(0))m.s_seq.append(y.unsqueeze(0))output_layer.register_forward_hook(save_hook)with torch.no_grad():img, label = test_dataset[0]img = img.to(args.device)out_fr = 0.for t in range(args.T):encoded_img = encoder(img)out_fr += net(encoded_img)out_spikes_counter_frequency = (out_fr / args.T).cpu().numpy()print(f'Firing rate: {out_spikes_counter_frequency}')output_layer.v_seq = torch.cat(output_layer.v_seq)output_layer.s_seq = torch.cat(output_layer.s_seq)v_t_array = output_layer.v_seq.cpu().numpy().squeeze() # v_t_array[i][j]表示神经元i在j时刻的电压值np.save("v_t_array.npy",v_t_array)s_t_array = output_layer.s_seq.cpu().numpy().squeeze() # s_t_array[i][j]表示神经元i在j时刻释放的脉冲,为0或1np.save("s_t_array.npy",s_t_array)img = img.cpu().numpy().reshape(28, 28)plt.subplot(221)plt.imshow(img)plt.subplot(222)plt.imshow(img, cmap='gray')plt.subplot(223)plt.imshow(img, cmap=plt.cm.gray)plt.subplot(224)plt.imshow(img, cmap=plt.cm.gray_r)plt.show()if __name__ == '__main__':main()
lif_fc_mnist_test.py
import numpy as np
import matplotlib.pyplot as plttest_accs = np.load("./train_accs.npy")
x = []
y = []
maxy = -1
maxx = -1
for t in range(len(test_accs)):if test_accs[t] > maxy:maxy = test_accs[t]maxx = tx.append(t)y.append(test_accs[t])
plt.plot(x, y)
# plt.plot(test_accs)
plt.xlabel('Iteration')
plt.ylabel('Acc')
plt.title('Train Acc')
plt.annotate(r'(%d,%f)' % (maxx, maxy), xy=(maxx, maxy), xycoords='data', xytext=(+10, +20), fontsize=16,arrowprops=dict(arrowstyle='->'), textcoords='offset points')
plt.show()
test_accs = np.load("./test_accs.npy")
x = []
y = []
maxy = -1
maxx = -1
for t in range(len(test_accs)):if test_accs[t] > maxy:maxy = test_accs[t]maxx = tx.append(t)y.append(test_accs[t])
# plt.plot(x, y)
plt.plot(test_accs)
plt.xlabel('Epoch')
plt.ylabel('Acc')
plt.title('Test Acc')
plt.annotate(r'(%d,%f)' % (maxx, maxy), xy=(maxx, maxy), xycoords='data', xytext=(+10, +20), fontsize=16,arrowprops=dict(arrowstyle='->'), textcoords='offset points')
plt.show()相关文章:
【解读Spikingjelly】使用单层全连接SNN识别MNIST
原文档:使用单层全连接SNN识别MNIST — spikingjelly alpha 文档 代码地址:完整的代码位于activation_based.examples.lif_fc_mnist.py GitHub - fangwei123456/spikingjelly: SpikingJelly is an open-source deep learning framework for Spiking Neur…...

穿越数字奇境:探寻元宇宙中的科技奇迹
随着科技的迅速发展,元宇宙正逐渐成为一个备受关注的话题,它不仅是虚拟现实的延伸,更是将现实世界与数字世界融合的未来典范。在这个神秘而充满活力的数字奇境中,涉及了众多领域和技术,为我们呈现出了一个无限的创新和…...

2024」预备研究生mem-阴影图形
一、阴影图形 二、课后题...

【设计模式】责任链模式
顾名思义,责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。 在这种模式中,通常每个接收者…...

解密人工智能:线性回归 | 逻辑回归 | SVM
文章目录 1、机器学习算法简介1.1 机器学习算法包含的两个步骤1.2 机器学习算法的分类 2、线性回归算法2.1 线性回归的假设是什么?2.2 如何确定线性回归模型的拟合优度?2.3 如何处理线性回归中的异常值? 3、逻辑回归算法3.1 什么是逻辑函数?…...

【FFMPEG应用篇】使用FFmpeg的常见问题
拼接视频的问题 在使用ffmpeg进行视频拼接时,可能会遇到一些常见问题。以下是这些问题及其解决方法: 1. 视频格式不兼容:如果要拼接的视频格式不同,ffmpeg可能会报错。解决方法是使用ffmpeg进行格式转换,将所有视频转…...
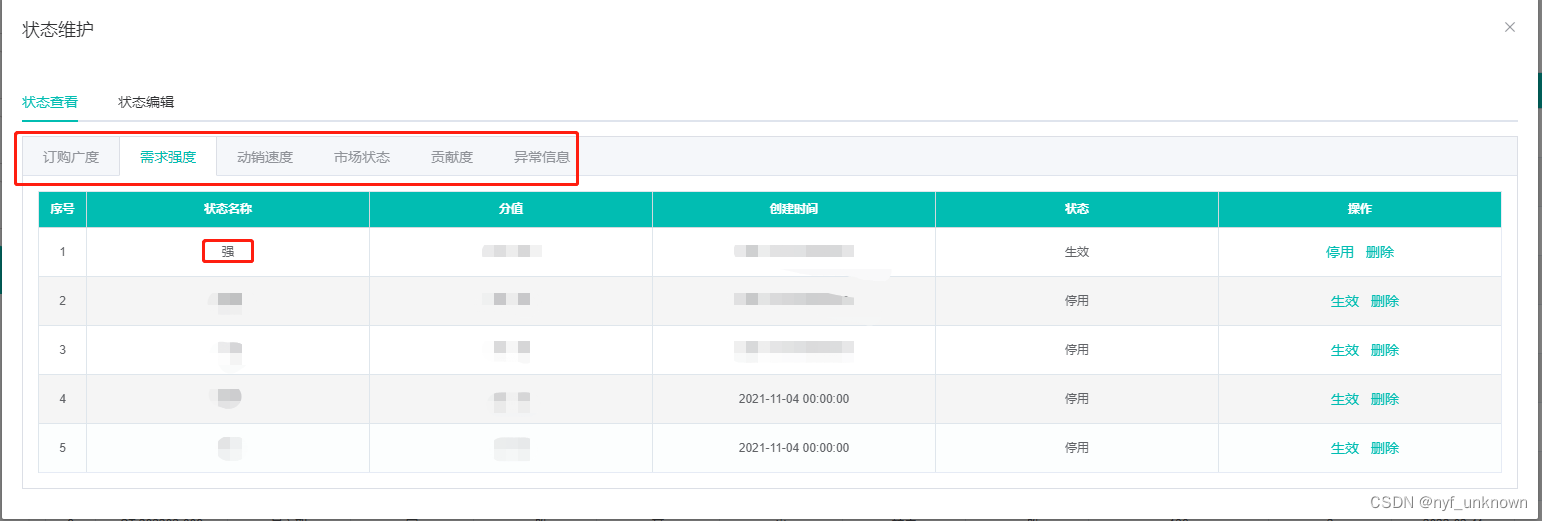
(vue)获取对象的键遍历,同时循环el-tab页展示key及内容
(vue)获取对象的键遍历,同时循环el-tab页展示key及内容 效果: 数据结构: "statusData": {"订购广度": [ {"id": 11, "ztName": "广", …...

【严重】Smartbi未授权设置Token回调地址获取管理员权限
漏洞描述 Smartbi是一款商业智能应用,提供了数据集成、分析、可视化等功能,帮助用户理解和使用他们的数据进行决策。 在 Smartbi 受影响版本中存在Token回调地址漏洞,未授权的攻击者可以通过向目标系统发送POST请求/smartbix/api/monitor/s…...

北京鸟巢门票多少,里面有什么好玩的
北京鸟巢门票多少,里面有什么好玩的 北京鸟巢的门票是100元,里面有很多运动设施,“鸟巢”结构设计奇特新颖,而这次搭建它的钢结构的Q460也有很多独到之处:Q460是一种低合金高强度钢,它在受力强度达到460兆帕…...
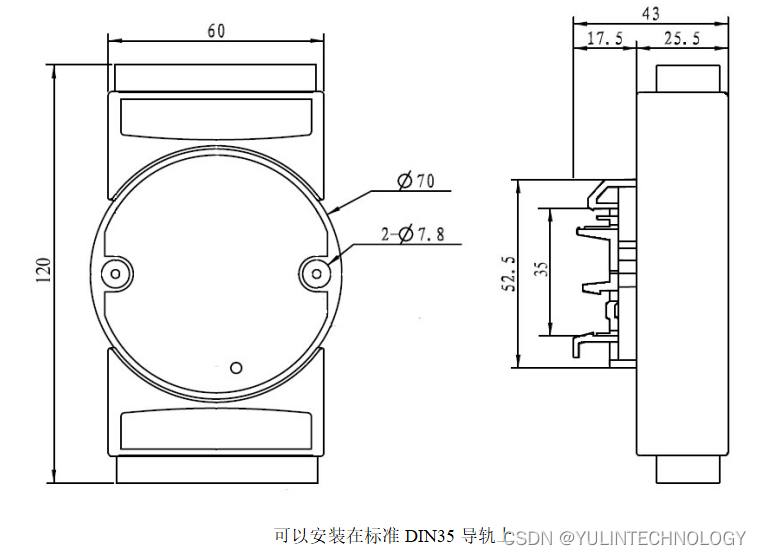
4路光栅尺磁栅尺编码器5MHz高速差分信号转Modbus TCP网络模块 YL97
特点: ● 光栅尺磁栅尺解码转换成标准Modbus TCP协议 ● 光栅尺5V差分信号直接输入,4倍频计数 ● 模块可以输出5V的电源给光栅尺供电 ● 高速光栅尺磁栅尺计数,频率可达5MHz ● 支持4个光栅尺同时计数,可识别正反转 ● 可网…...

金蝶云星空对接打通旺店通·企业奇门组装拆卸单查询接口与创建其他出库单接口
金蝶云星空对接打通旺店通企业奇门组装拆卸单查询接口与创建其他出库单接口 编辑 源系统:金蝶云星空 金蝶K/3Cloud(金蝶云星空)是移动互联网时代的新型ERP,是基于WEB2.0与云技术的新时代企业管理服务平台。金蝶K/3Cloud围绕着“生态、人人…...

卫星--夏令营
几何问题:就是用几何数学知识解题即可 但是越是数学编程题,越容易忽略数学题中的细节 1.地球半径你算进去了吗? 2.sin三角函数,M_PI标准圆周率在cmath文件里 3.有可能给出的夹角超过180呢,没给数据要求,就要自己考…...
Kafka的下载安装以及使用
一、Kafka下载 下载地址:https://kafka.apache.org/downloads 二、Kafka安装 因为选择下载的是 .zip 文件,直接跳过安装,一步到位。 选择在任一磁盘创建空文件夹(不要使用中文路径),解压之后把文件夹内容…...
数据库相关面试题
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 mysql怎么优化 : MySQL的优化可以从以下几个方面入手: 数据库设计优化:合理设计表结构,选择合适的数…...
Ubuntu常用配置
文章目录 1. 安装VMware虚拟机软件2. 下载Ubuntu镜像3. 创建Ubuntu虚拟机4. 设置屏幕分辨率5. 更改系统语言为中文6. 切换中文输入法7. 修改系统时间8. 修改锁屏时间9. 通过系统自带的应用商店安装软件10. 安装JDK11. 安装 IntelliJ IDEA12. 将左侧任务栏自动隐藏13. 安装docke…...

win10MySQLServer安装过程+解决MySQL服务无法启动问题
本次使用的版本是 Server version: 8.0.33 MySQL Community Server 安装详解 首先去官网下载社区版,比如我用的是mysql-8.0.33-winx64.zip,解压到文件夹:D:\Program Files\mysql-8.0.33-winx64 用管理员身份运行cmd,进到bin目录…...
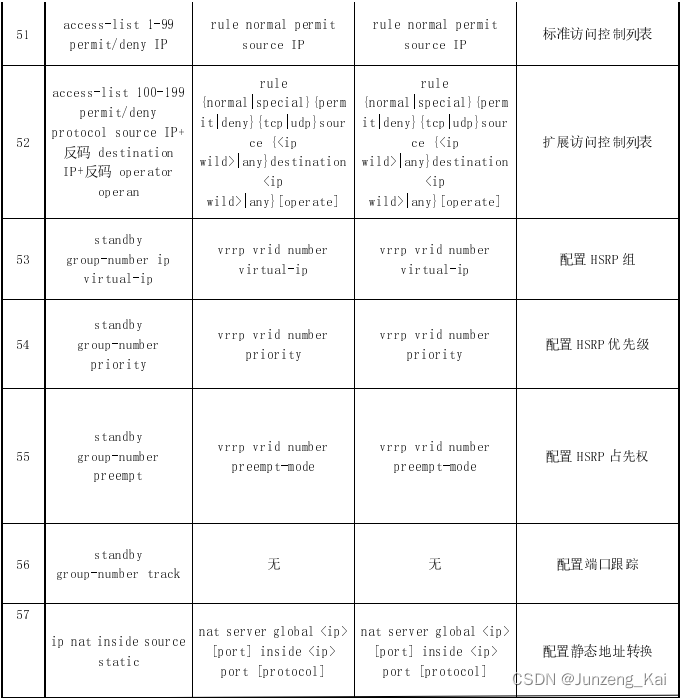
网络:CISCO、Huawei、H3C命令对照
思科、华为、锐捷命令对照表 编号思科华为锐捷命令解释1 2writesavesave保存3456 如果你所处的视图为非系统视图,需要查看配置的时候,需要在该配置命令前加do。 在特定的视图之下,有对应的特定命令。例如,在接口视图下的ip addre…...

题目:2319.判断矩阵是否是 X 矩阵
题目来源: leetcode题目,网址:2319. 判断矩阵是否是一个 X 矩阵 - 力扣(LeetCode) 解题思路: 遍历矩阵,对于每一个节点,先判断是否处于主对角线或副对角线上,然后判…...

2023年大厂前端面试题汇总
一、58同城前端面试题27道 1. css盒模型 2. css画三角形 3. 盒子水平垂直居中(所有方式) 4. 重绘、重排 重绘就是重新绘制(repaint):是在一个元素的外观被改变所触发的浏览器行为,浏览器会根据元素的新属性…...

如何在Linux中查找Nginx安装目录
一、通过which命令查找 $ which nginx /usr/sbin/nginxwhich命令会在系统环境变量PATH中查找nginx可执行文件,并返回路径。因此,通过which命令可以很容易地找到系统中nginx的安装位置。 二、通过whereis命令查找 $ whereis nginx nginx: /usr/sbin/ng…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

零基础轻松拿捏!魔珐星云青少年健康运动教学数字人搭建全流程指南
大家好!本次给大家分享一款面向青少年体育教育的AI创意实践项目——青少年健康运动教学智能数字交互系统。本项目聚焦青少年体质健康痛点,围绕体育教学智能化升级需求,打造集健康知识教学、运动动作陪练、健康知识考核、运动能力评测于一体的…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

免费抓包工具选型指南:Wireshark、Fiddler、mitmproxy、Charles实战对比
1. 抓包工具不是“黑科技”,而是网络世界的显微镜很多人第一次听说“抓包”,脑子里立刻浮现出黑客电影里满屏滚动的绿色代码、键盘敲得噼啪作响、三秒破解银行防火墙的画面。其实完全不是这样——抓包(Packet Capture)本质上就是把…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...