Android 并发编程--阻塞队列和线程池
一、阻塞队列
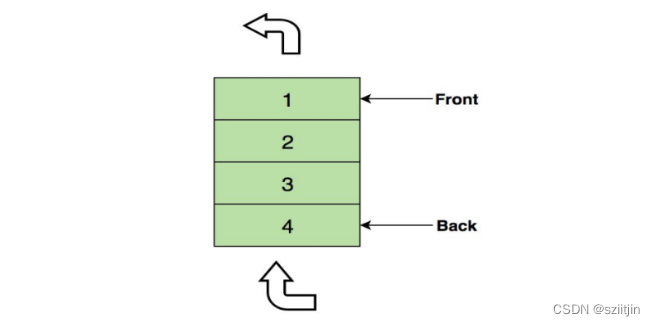
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO—first in first out)线性表。
什么是阻塞队列?
1)支持阻塞的插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不满。
2)支持阻塞的移除方法:意思是在队列为空时,获取元素的线程会等待队列变为非空。
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序整体处理数据的速度。
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。
为了解决这种生产消费能力不均衡的问题,便有了生产者和消费者模式。生产者和消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通信,而是通过阻塞队列来进行通信,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
阻塞队列常用于生产者和消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里取元素的线程。阻塞队列就是生产者用来存放元素、消费者用来获取元素的容器。

抛出异常:当队列满时,如果再往队列里插入元素,会抛出IllegalStateException("Queuefull")异常。当队列空时,从队列里获取元素会抛出NoSuchElementException异常。
返回特殊值:当往队列插入元素时,会返回元素是否插入成功,成功返回true。如果是移除方法,则是从队列里取出一个元素,如果没有则返回null。
一直阻塞:当阻塞队列满时,如果生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到队列可用或者响应中断退出。当队列空时,如果消费者线程从队列里take元素,队列会阻塞住消费者线程,直到队列不为空。
超时退出:当阻塞队列满时,如果生产者线程往队列里插入元素,队列会阻塞生产者线程一段时间,如果超过了指定的时间,生产者线程就会退出。
常用阻塞队列:
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
以上的阻塞队列都实现了BlockingQueue接口,也都是线程安全的。
有界和无界?
有限队列就是长度有限,满了以后生产者会阻塞,无界队列就是里面能放无数的东西而不会因为队列长度限制被阻塞,当然空间限制来源于系统资源的限制,如果处理不及时,导致队列越来越大越来越大,超出一定的限制致使内存超限,会导致 OOM 。
无界也会阻塞?因为阻塞不仅仅体现在生产者放入元素时会阻塞,消费者拿取元素时,如果没有元素,同样也会阻塞。
ArrayBlockingQueue
是一个用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证线程公平的访问队列,所谓公平访问队列是指阻塞的线程,可以按照阻塞的先后顺序访问队列,即先阻塞线程先访问队列。非公平性是对先等待的线程是非公平的,当队列可用时,阻塞的线程都可以争夺访问队列的资格,有可能先阻塞的线程最后才访问队列。初始化时有参数可以设置。
LinkedBlockingQueue
是一个用链表实现的有界阻塞队列。此队列的默认和最大长度为Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。
Array实现和Linked实现的区别
1. 队列中锁的实现不同
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue实现的队列中的锁是分离的,即生产用的是putLock,消费是takeLock。
2. 在生产或消费时操作不同
ArrayBlockingQueue实现的队列中在生产和消费的时候,是直接将枚举对象插入或移除的;
LinkedBlockingQueue实现的队列中在生产和消费的时候,需要把枚举对象转换为Node<E>进行插入或移除,会影响性能。
3. 队列大小初始化方式不同
ArrayBlockingQueue实现的队列中必须指定队列的大小;
LinkedBlockingQueue实现的队列中可以不指定队列的大小,但是默认是Integer.MAX_VALUE。
PriorityBlockingQueue
PriorityBlockingQueue是一个支持优先级的无界阻塞队列。默认情况下元素采取自然顺序升序排列。也可以自定义类实现compareTo()方法来指定元素排序规则,或者初始化PriorityBlockingQueue时,指定构造参数Comparator来对元素进行排序。需要注意的是不能保证同优先级元素的顺序。
DelayQueue
是一个支持延时获取元素的无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。
DelayQueue运用在以下应用场景:
缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
SynchronousQueue
是一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合传递性场景。SynchronousQueue的吞吐量高于LinkedBlockingQueue和ArrayBlockingQueue。
二、线程池
为什么要用线程池?
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。在开发过程中,合理地使用线程池能够带来3个好处。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间。 如果:T1 + T3 远大于 T2,则可以采用线程池,以提高服务器性能。线程池技术正是关注如何缩短或调整T1,T3时间的技术,从而提高服务器程序性能的。它把T1,T3分别安排在服务器程序的启动和结束的时间段或者一些空闲的时间段,这样在服务器程序处理客户请求时,不会有T1,T3的开销了。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
ThreadPoolExecutor 的类关系
Executor是一个接口,它是Executor框架的基础,它将任务的提交与任务的执行分离开来。
ExecutorService接口继承了Executor,在其上做了一些shutdown()、submit()的扩展,可以说是真正的线程池接口;
AbstractExecutorService抽象类实现了ExecutorService接口中的大部分方法;
ThreadPoolExecutor是线程池的核心实现类,用来执行被提交的任务。
ScheduledExecutorService接口继承了ExecutorService接口,提供了带"周期执行"功能ExecutorService;
ScheduledThreadPoolExecutor是一个实现类,可以在给定的延迟后运行命令,或者定期执行命令。ScheduledThreadPoolExecutor比Timer更灵活,功能更强大。
线程池的创建各个参数含义
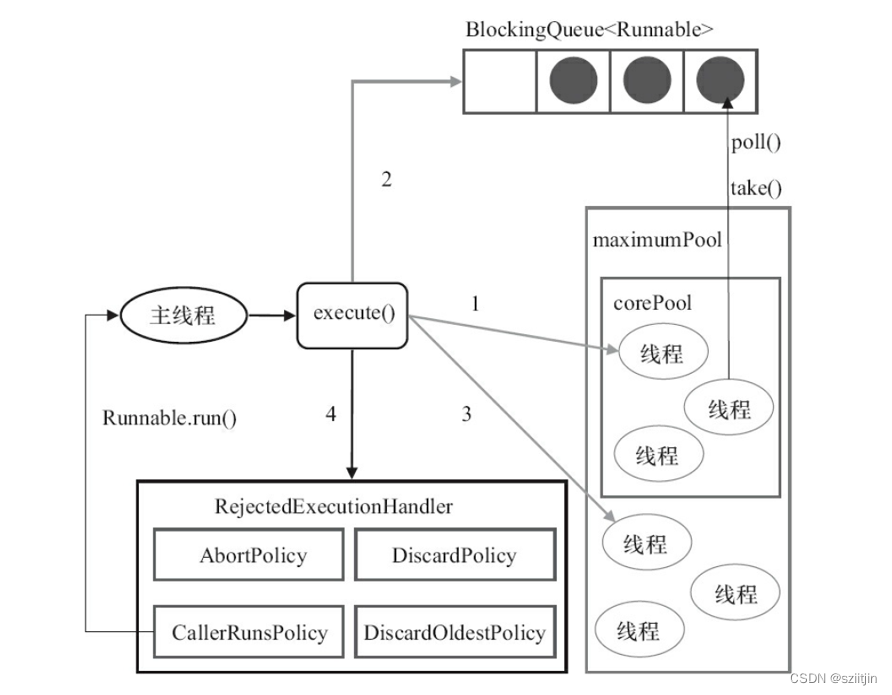
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)corePoolSize
线程池中的核心线程数,当提交一个任务时,线程池创建一个新线程执行任务,直到当前线程数等于corePoolSize;如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;如果执行了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有核心线程。
maximumPoolSize
线程池中允许的最大线程数。如果当前阻塞队列满了,且继续提交任务,则创建新的线程执行任务,前提是当前线程数小于maximumPoolSize。
keepAliveTime
线程空闲时的存活时间,即当线程没有任务执行时,继续存活的时间。默认情况下,该参数只在线程数大于corePoolSize时才有用。
TimeUnit
keepAliveTime的时间单位。
workQueue
workQueue必须是BlockingQueue阻塞队列。当线程池中的线程数超过它的corePoolSize的时候,线程会进入阻塞队列进行阻塞等待。通过workQueue,线程池实现了阻塞功能。
一般来说,我们应该尽量使用有界队列,因为使用无界队列作为工作队列会对线程池带来如下影响:
1)当线程池中的线程数达到corePoolSize后,新任务将在无界队列中等待,因此线程池中的线程数不会超过corePoolSize。
2)由于1,使用无界队列时maximumPoolSize将是一个无效参数。
3)由于1和2,使用无界队列时keepAliveTime将是一个无效参数。
4)更重要的,使用无界queue可能会耗尽系统资源,有界队列则有助于防止资源耗尽,同时即使使用有界队列,也要尽量控制队列的大小在一个合适的范围。
threadFactory
创建线程的工厂,通过自定义的线程工厂可以给每个新建的线程设置一个具有识别度的线程名,当然还可以更加自由的对线程做更多的设置,比如设置所有的线程为守护线程。
Executors静态工厂里默认的threadFactory,线程的命名规则是“pool-数字-thread-数字”。
RejectedExecutionHandler
线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略:
1)AbortPolicy:直接抛出异常,默认策略;
2)CallerRunsPolicy:用调用者所在的线程来执行任务;
3)DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
4)DiscardPolicy:直接丢弃任务;
当然也可以根据应用场景实现RejectedExecutionHandler接口,自定义饱和策略,如记录日志或持久化存储不能处理的任务。
线程池的工作机制
1)如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(注意,执行这一步骤需要获取全局锁)。
2)如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue。
3)如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务。
4)如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
提交任务
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。
submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
关闭线程池
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别,shutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
只要调用了这两个关闭方法中的任意一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。至于应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法。
合理地配置线程池
要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析:
1)任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
2)任务的优先级:高、中和低。
3)任务的执行时间:长、中和短。
4)任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。
CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*Ncpu。
混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。
建议使用有界队列。有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点。
如果当时我们设置成无界队列,那么线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题。
相关文章:
Android 并发编程--阻塞队列和线程池
一、阻塞队列 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作…...

Playwright快速上手-1
前言 随着近年来对UI自动化测试的要求越来越高,,功能强大的测试框架也不断的涌现。本系列主讲的Playwright作为一款新兴的端到端测试框架,凭借其独特优势,正在逐渐成为测试工程师的热门选择。 本系列文章将着重通过示例讲解 Playwright python开发环境的搭建 …...
PPT颜色又丑又乱怎么办?
一、设计一套PPT时,可以从这5个方面进行设计 二、PPT颜色 (一)、PPT常用颜色分类 一个ppt需要主色、辅助色、字体色、背景色即可。 (二)、搭建PPT色彩系统 设计ppt时,根据如下几个步骤,依次选…...

python计算相关系数R
方法一: import numpy as np# 计算相关系数R def r(y_true, y_pred):y_true np.array(y_true)y_pred np.array(y_pred)corr np.corrcoef(y_true, y_pred)[0][1]return corrcorr r(yture, ypred)方法二 import scipy.stats # 计算皮尔逊相关指数,并…...

黑马项目一阶段面试 自我介绍篇
面试官你好,我叫xxx,是来自xxxx的本科毕业生。我通过招聘网站/内推/线下招聘了解到的贵司,我具有扎实的Java后端的基础功底,基本掌握JavaSE、JavaEE流行技术的使用,并且我比较好学,心态也很乐观积极&#x…...

时序预测 | MATLAB实现CNN-BiGRU-Attention时间序列预测
时序预测 | MATLAB实现CNN-BiGRU-Attention时间序列预测 目录 时序预测 | MATLAB实现CNN-BiGRU-Attention时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现CNN-BiGRU-Attention时间序列预测,CNN-BiGRU-Attention结合注意力机制时…...
开发过程中遇到的问题以及解决方法
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 开发过程中遇到的问题以及解决方法 简单易用的git命令 git命令: 查看有几个分支:git branch -a 切换分支&#…...
本地oracle登录账号锁定处理,the account is locked
1.打开cmd命令窗口 2.打开sqlplus: sqlplus /nolog(加/nolog是不登录服务器的意思,不加就需要输账号密码) 3.切换到管理员:conn / as sysdba; 第2步第3步可以合并,直接使用sysdba登录:sqlplus / as sysdba; 4.解锁账号&#x…...

redission自定义hessian序列化
一。技术改造背景 由于之前的比较陈旧的技术,后面发起了技术改造,redis整体改后使用redisson框架。 二。问题 改造完成后,使用方反馈 缓存获取异常 异常信息如下 Caused by: java.io.CharConversionException: Unexpected EOF in the mid…...
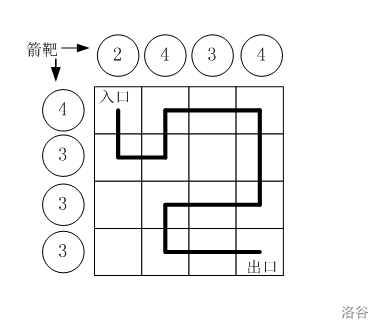
P8642 [蓝桥杯 2016 国 AC] 路径之谜
[蓝桥杯 2016 国 AC] 路径之谜 题目描述 小明冒充 X X X 星球的骑士,进入了一个奇怪的城堡。 城堡里边什么都没有,只有方形石头铺成的地面。 假设城堡地面是 n n n\times n nn 个方格。如图所示。 按习俗,骑士要从西北角走到东南角。 …...
oracle sql developer批量删除某个用户
随着navicate收费,还得破解,pl/sql developer配置麻烦,最近使用oracle sql developer来试试oracle的操作如何; 用着还行,没有卡顿现象, 最近要oracle sql developer批量删除某个用户下所有的表࿰…...
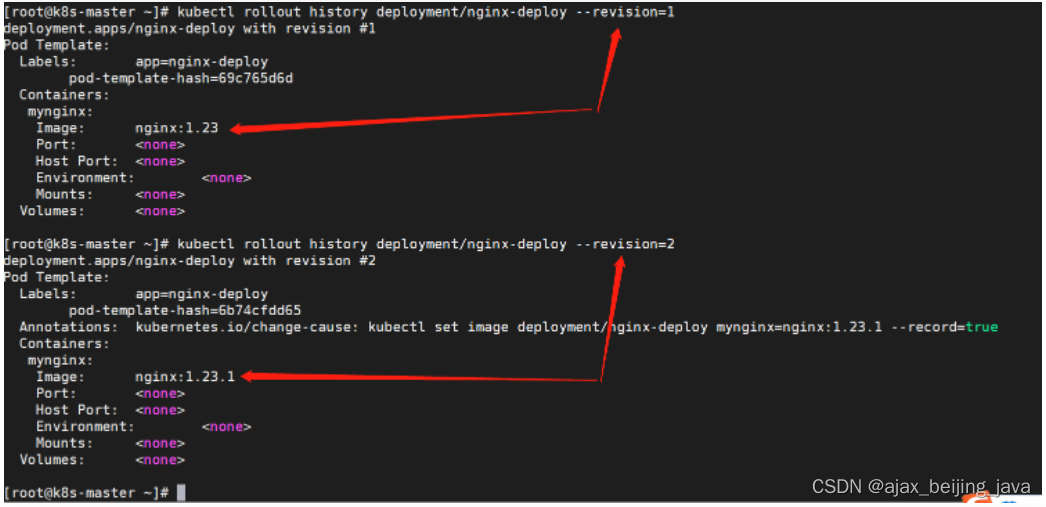
k8s 滚动更新控制(一)
在传统的应用升级时,通常采用的方式是先停止服务,然后升级部署,最后将新应用启动。这个过程面临一个问题,就是在某段时间内,服务是不可用的,对于用户来说是非常不友好的。而kubernetes滚动更新,…...

Java智慧工地APP源码带AI识别
智慧工地为建筑全生命周期赋能,用创新的可视化与智能化方法,降低成本,创造价值。 一、智慧工地APP概述 智慧工地”立足于互联网,采用云计算,大数据和物联网等技术手段,针对当前建筑行业的特点,…...

ME3116电源小板
最近设计一款PCB的时候使用微盟的dc dc电源ic踩了一个坑。 在使用me3116作为24v到5v的降压ic作为esp32系统前级的降压电路时,再没有铂电阻采样负载的情景下工作正常,带上负载后,ic工作不正常,过一段时间,后级电路会烧…...
摸准天气“小心思”,躲避恶劣天气“偷袭”
打开天气预报一看,天气真的很“善变”,既是高温又暴雨,偶尔还有台风路过,“蒸”的让人太太太难受了。看着天气在放晴和即将下雨之间“徘徊”,总是纠结带不带雨伞,让我的每次出门都成了一场冒险之旅。 持…...
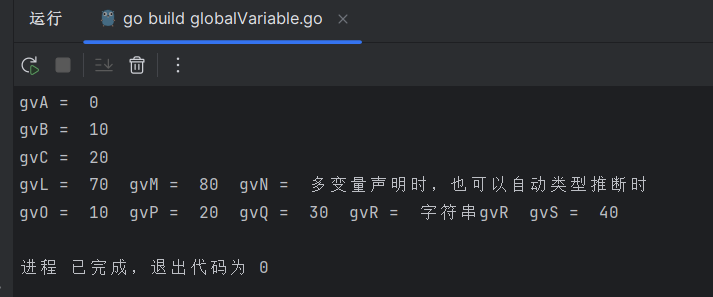
Golang 局部变量、全局变量 声明
文章目录 一、局部变量二、全局变量 一、局部变量 四种声明方式 多变量声明: package mainimport "fmt"//局部变量声明 func main() {//方法一: 声明一个变量和数据类型,不初始化值;默认值为0;var lvA intfmt.Printl…...
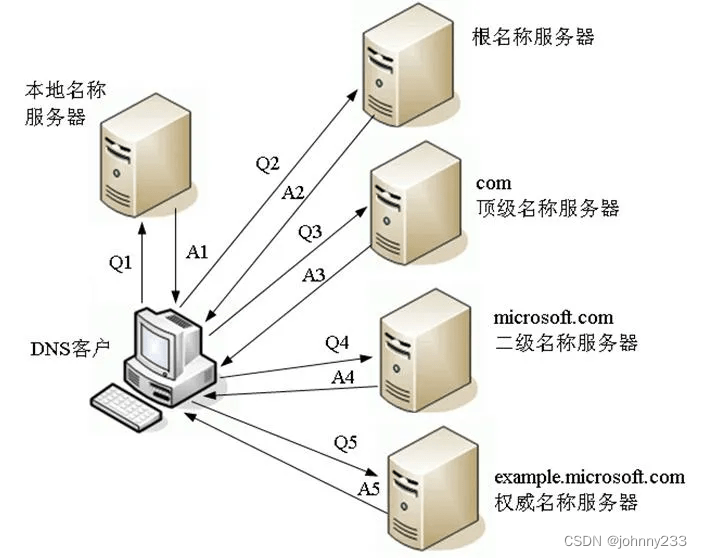
软考高级之系统架构师之数据通信与计算机网络
概念 OSPF 在划分区域之后,OSPF网络中的非主干区域中的路由器对于到外部网络的路由,一定要通过ABR(区域边界路由器)来转发,既然如此,对于区域内的路由器来说,就没有必要知道通往外部网络的详细路由,只要由…...
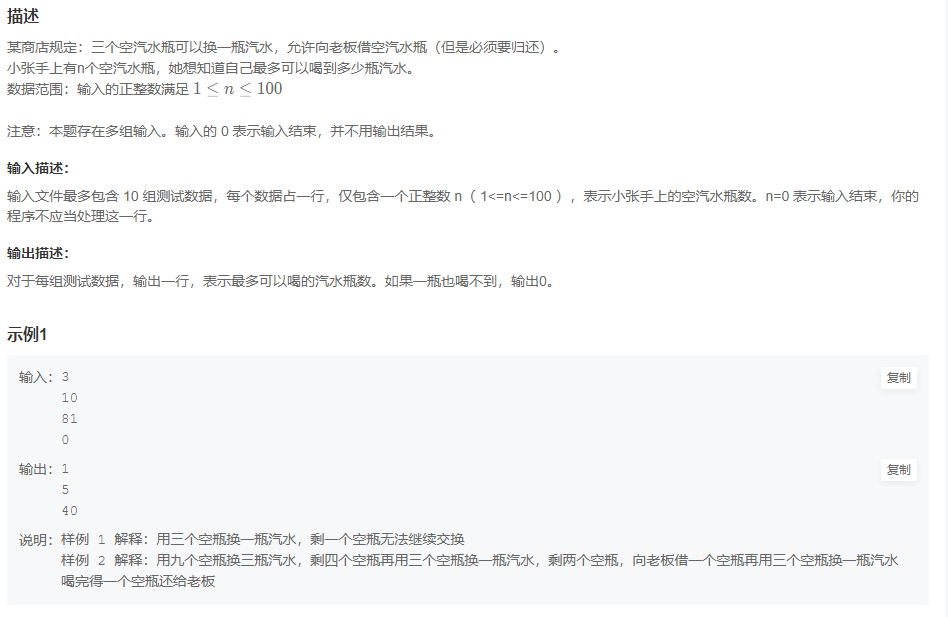
牛客网华为OD前端岗位,面试题库练习记录01
题目一 质数因子 功能:输入一个正整数,按照从小到大的顺序输出它的所有质因子(重复的也要列举)(如180的质因子为2 2 3 3 5 ) JavaScript Node ACM模式 const rl require("readline").createInterface({ i…...

Python web实战之Django 的缓存机制详解
关键词:Python、Web 开发、Django、缓存 1. 缓存是什么?为什么需要缓存? 在 Web 开发中,缓存是一种用于存储数据的临时存储区域。它可以提高应用程序的性能和响应速度,减轻服务器的负载。 当用户访问网页时ÿ…...

chatserver服务器开发笔记
chatserver服务器开发笔记 1 chatserver2 开发环境3 编译 1 chatserver 集群聊天服务器和客户端代码,基于muduo、redis、mysql实现。 学习于https://fixbug.ke.qq.com/ 本人已经挂github:https://github.com/ZixinChen-S/chatserver/tree/main 需要该项…...

AI大模型应用开发全攻略:从入门到精通,掌握LLM、RAG、Agent核心技能!“
本文全面介绍了AI大模型应用开发的核心技术和实践。从大模型API交互基础,到关键参数Messages和Tools的作用,深入解析了RAG、ReAct、Agent等应用范式。文章还探讨了Fine-tuning微调和Prompt提示词工程的重要性,强调工程实践与业务需求相结合。…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

Unity Visual Scripting不是拖拽玩具:中阶开发者的编程范式重构指南
1. 为什么Unity官方Visual Scripting不是“拖拽完就能跑”的玩具,而是一套需要重新理解的编程范式很多人第一次点开Unity的Visual Scripting(VS)面板时,看到那些五颜六色的节点和丝滑的连线,下意识觉得:“这…...