百日筑基篇——Pandas学习三(pyhton入门八)
百日筑基篇——Pandas学习三(pyhton入门八)
文章目录
- 前言
- 一、数据排序
- 二、字符串处理
- 三、数据合并方法
- 1. merge方法
- 2. concat方法
- 四、分组数据统计
- 五、数据重塑
- 1. stack
- 2. pivot
- 总结
前言
上一篇文章介绍了一下pandas库中的一些函数,而本章则继续介绍库中的函数在数据处理中的应用。
一、数据排序
运用sort_values方法,
import pandas as pdpath = r"C:\Users\王浩天\Desktop\beijing_tianqi_2018.csv"
df = pd.read_csv(path)
df.loc[:, "bWendu"] = df["bWendu"].str.replace("℃", "").astype("int32")
df.loc[:, "yWendu"] = df["yWendu"].str.replace("℃", "").astype("int32")print(df.head(4))
#Series的排序
print(df["bWendu"].sort_values(ascending=True,inplace=False))
#DataFrame的排序
df1 = df.sort_values(by=["aqiLevel","bWendu"],ascending=[True,False],inplace=False)
print(df1.head(6))ymd bWendu yWendu tianqi fengxiang fengli aqi aqiInfo aqiLevel
178 2018-06-28 35 24 多云~晴 北风 1-2级 33 优 1
149 2018-05-30 33 18 晴 西风 1-2级 46 优 1
206 2018-07-26 33 25 多云~雷阵雨 东北风 1-2级 40 优 1
158 2018-06-08 32 19 多云~雷阵雨 西南风 1-2级 43 优 1
205 2018-07-25 32 25 多云 北风 1-2级 28 优 1
226 2018-08-15 32 24 多云 东北风 3-4级 33 优 1在数据框的排序中,sort_values()函数的参数"by"用来指定根据排序的列名,“ascending” 参数则填布尔值或由布尔值形成的列表,用来指定是升序还是降序 ,且与"by"一一对应。
列如,在上述代码中,是先根据"aqiLevel"升序排序,再在此基础上按"bWendu"来降序排序。
二、字符串处理
使用 .str方法,获取Series的str属性,以便在属性上调用所需函数。
#使用str的startswith 、contains 等得到bool的Series,可以用来做条件查询
#例如,提取出六月份的数据
condition = df["ymd"].str.startswith("2018-06")
print(df.loc[condition,:])#多次str处理,只展示月份
df1["ymd"]=df1["ymd"].str.replace("-","").str[4:6]
print(df1.head(3))ymd bWendu yWendu tianqi fengxiang fengli aqi aqiInfo aqiLevel
178 06 35 24 多云~晴 北风 1-2级 33 优 1
149 05 33 18 晴 西风 1-2级 46 优 1
206 07 33 25 多云~雷阵雨 东北风 1-2级 40 优 1#使用split对ymd进行拆分为列表
def func(df):year,month,day = df["ymd"].split("-")return f"{year}年{month}月{day}日"
df["日期"] = df.apply(func,axis=1)
print(df.head(3))ymd bWendu yWendu tianqi ... aqi aqiInfo aqiLevel 日期
0 2018-01-01 3 -6 晴~多云 ... 59 良 2 2018年01月01日
1 2018-01-02 2 -5 阴~多云 ... 49 优 1 2018年01月02日
2 2018-01-03 2 -5 多云 ... 28 优 1 2018年01月03日#若要将年月日去掉,可使用正则表达式
df["日期"]=df["日期"].str.replace("[年月日]","",regex = True)
print(df.head(2))
三、数据合并方法
1. merge方法
根据一列或多列的值将两个DataFrame对象按行或列合并到一起
import pandas as pddf1 = pd.DataFrame({'学号': ['A0', 'A1', 'A2', 'A3'],'姓名': ['B0', 'B1', 'B2', 'B3'],'学生': ['K0', 'K1', 'K2', 'K3']})df2 = pd.DataFrame({'成绩': ['C0', 'C1', 'C2', 'C3'],'导师': ['D0', 'D1', 'D2', 'D3'],'学生': ['K0', 'K1', 'K2', 'K3']})print(df1)
print(df2)
df_merge = pd.merge(df1,df2,on="学生")
print(df_merge)学号 姓名 学生 成绩 导师
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K2 C2 D2
3 A3 B3 K3 C3 D3笔记如下:

2. concat方法
用于按行或列将多个DataFrame对象连接到一起。它可以用于沿着行或列轴将DataFrame对象堆叠在一起
import pandas as pddf1 = pd.read_csv(r"D:\python\PycharmProjects\pythonProject1\pachou\result_dir\yaxibao0.csv",encoding="utf-8")
df2 = pd.read_csv(r"D:\python\PycharmProjects\pythonProject1\pachou\result_dir\yaxibao1.csv",encoding="utf-8")
df1 = pd.DataFrame(df1)
df2 = pd.DataFrame(df2)
#print(df1)
#print(df2)
DF= pd.concat([df1,df2],axis=0) #默认按行合并
print(DF)AA_ID yaxibao
0 LaggChr1G00000010.1 chlo
1 LaggChr1G00000020.1 cyto
2 LaggChr1G00000030.1 nucl
3 LaggChr1G00000040.1 nucl
4 LaggChr1G00000050.1 mito
.. ... ...
533 LaggChr1G00010360.1 nucl
534 LaggChr1G00010370.1 cyto
535 LaggChr1G00010380.1 cyto
536 LaggChr1G00010390.1 chlo
537 LaggChr1G00010400.1 plas[1040 rows x 2 columns]笔记如下:

四、分组数据统计
主要运用groupby方法,通常与agg()方法联用。也可以自定义方法,并使用apply应用于数据框
import numpy as np
df["ymd"] = df["ymd"].str[:7]
print(df.head(3)ymd bWendu yWendu tianqi fengxiang fengli aqi aqiInfo aqiLevel
0 2018-01 3 -6 晴~多云 东北风 1-2级 59 良 2
1 2018-01 2 -5 阴~多云 东北风 1-2级 49 优 1
2 2018-01 2 -5 多云 北风 1-2级 28 优 1#可传入多个分组依据列;as_index=False ,表示不使分组列变为索引,后面的agg函数,传入字典可对不同的列使用指定的聚合方法
print(df.groupby(["fengxiang","ymd"],as_index=False).agg({"bWendu":np.max,"yWendu": np.min,"aqi": np.mean}))fengxiang ymd bWendu yWendu aqi
0 东北风 2018-01 3 -11 45.200000
1 东北风 2018-02 10 -4 45.000000
2 东北风 2018-03 15 -4 141.666667
3 东北风 2018-04 19 1 56.200000
4 东北风 2018-05 25 13 121.000000
.. ... ... ... ... ...
68 西南风 2018-12 2 -8 78.000000
69 西风 2018-02 8 -4 78.000000
70 西风 2018-05 33 10 74.500000
71 西风 2018-07 27 23 28.000000
72 西风 2018-10 21 7 77.000000df4 = df[["ymd","bWendu","yWendu","aqi","aqiLevel"]]
print(df4.groupby("ymd").agg([np.sum,np.mean,np.std]))
print(df4.groupby("ymd").agg({"bWendu":np.max,"yWendu": np.min,"aqi": np.mean}))#使用自定义方法
def guiyihua(df):df["bWendu_new"] = df["bWendu"].apply(lambda x: (x - df["bWendu"].min())/ (df["bWendu"].max() - df["bWendu"].min()))return df
print(df.groupby("ymd").apply(guiyihua))五、数据重塑
这里是引用
1. stack
stack函数用于将数据框的列转换为行,从而生成一个新的数据框
它会将数据框的列标签转换为新的索引层级,并将对应的值放入新的列中。这个过程被称为"堆叠"。
unstack是与stack相反的操作,用于将行索引转换为列。
#print(df.dtypes)
df["ymd"] = pd.to_datetime(df["ymd"])
#print(df.dtypes)
#根据月份分组
df_group = df.groupby([df["ymd"].dt.month,"fengxiang"])["bWendu"].agg(pv = np.max)
print(df_group)pv
ymd fengxiang
1 东北风 3东南风 2东风 3北风 2南风 7
... ..
11 西南风 14
12 东北风 9东南风 7西北风 10西南风 2[73 rows x 1 columns]#将行索引转化为列
df_stack = df_group.unstack()
print(df_stack)pv
fengxiang 东北风 东南风 东风 北风 南风 西北风 西南风 西风
ymd
1 3.0 2.0 3.0 2.0 7.0 6.0 5.0 NaN
2 10.0 NaN 7.0 6.0 8.0 5.0 12.0 8.0
3 15.0 14.0 25.0 18.0 27.0 NaN 25.0 NaN
4 19.0 26.0 NaN 26.0 30.0 26.0 27.0 NaN
5 25.0 28.0 29.0 25.0 35.0 31.0 32.0 33.0
6 37.0 37.0 36.0 35.0 37.0 NaN 38.0 NaN
7 33.0 37.0 32.0 32.0 35.0 NaN 35.0 27.0
8 32.0 35.0 35.0 32.0 36.0 NaN 28.0 NaN
9 NaN NaN NaN 30.0 29.0 27.0 31.0 NaN
10 17.0 NaN NaN 25.0 25.0 24.0 19.0 21.0
11 8.0 13.0 NaN 15.0 18.0 11.0 14.0 NaN
12 9.0 7.0 NaN NaN NaN 10.0 2.0 NaN#将列索引转换为行
ymd fengxiang
1 东北风 pv 3东南风 pv 2东风 pv 3北风 pv 2南风 pv 7..
11 西南风 pv 14
12 东北风 pv 9东南风 pv 7西北风 pv 10西南风 pv 2
Length: 73, dtype: int322. pivot
pivot函数会重新安排数据框的行和列,使之对应于新的行和列标签。这个过程被称为"旋转"
import pandas as pd# 创建一个简单的数据框
data = {'Name': ['wht', 'xingshi'],'Subject': 'Maths','Score': [90, 85]}
df = pd.DataFrame(data)
print(df)Name Subject Score
0 wht Maths 90
1 xingshi Maths 85# 使用pivot函数进行数据重塑
pivoted_df = df.pivot(index='Name', columns='Subject', values='Score')# 打印重塑后的数据框
print(pivoted_df)
Subject Maths
Name
wht 90
xingshi 85
总结
本章主要总结了有关pandas库中的一些函数,有排序函数sort_values; 数据合并函数merge、concat;分组统计函数groupby;以及数据重塑函数stack、pivot。
子非鱼,安知鱼之乐;
–2023-8-14 筑基篇
相关文章:
百日筑基篇——Pandas学习三(pyhton入门八)
百日筑基篇——Pandas学习三(pyhton入门八) 文章目录 前言一、数据排序二、字符串处理三、数据合并方法1. merge方法2. concat方法 四、分组数据统计五、数据重塑1. stack2. pivot 总结 前言 上一篇文章介绍了一下pandas库中的一些函数,而本…...

【Android Framework系列】第10章 PMS之Hook实现广播的调用
1 前言 前面章节我们学习了【Android Framework系列】第4章 PMS原理我们了解了PMS原理,【Android Framework系列】第9章 AMS之Hook实现登录页跳转我们知道AMS可以Hook拦截下来实现未注册Activity页面的跳转,本章节我们来尝试一下HookPMS实现广播的发送。…...

Mysql锁实战
mysql版本:8.0.32 通过实战验证mysql的Record lock 与 Gap lock原理 准备工作 设置隔离级别为:RR,以及innodb状态输出锁相关信息 show variables like %innodb_status_output_locks%; show variables like %isolation%;set global innodb_…...
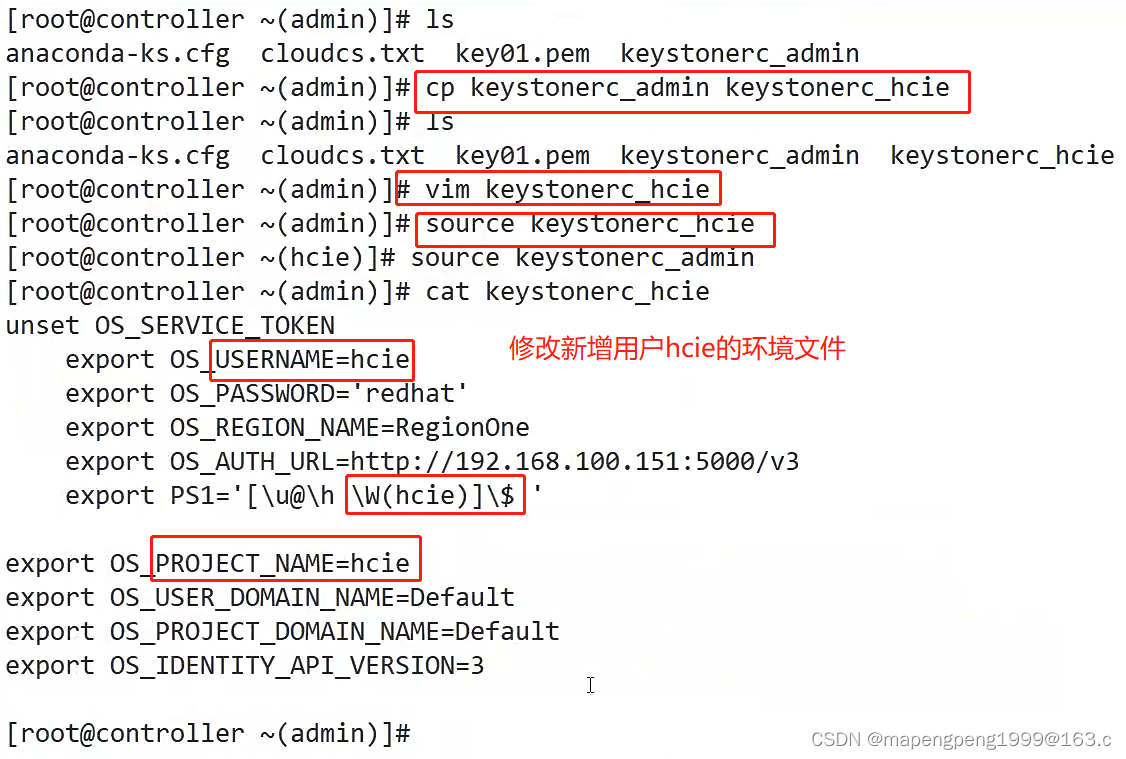
HCIP-OpenStack发放云主机
1、云中的概念 在云平台注册了一个账号,这个账号对于云平台来说,就是一个租户或者一个项目。 租户/项目(tenant/project),租户就是项目的意思。主机聚合就是主机组的意思。 region(区域)&…...

时序预测 | MATLAB基于扩散因子搜索的GRNN广义回归神经网络时间序列预测(多指标,多图)
时序预测 | MATLAB基于扩散因子搜索的GRNN广义回归神经网络时间序列预测(多指标,多图) 目录 时序预测 | MATLAB基于扩散因子搜索的GRNN广义回归神经网络时间序列预测(多指标,多图)效果一览基本介绍程序设计学习小结参考资料效果一览...
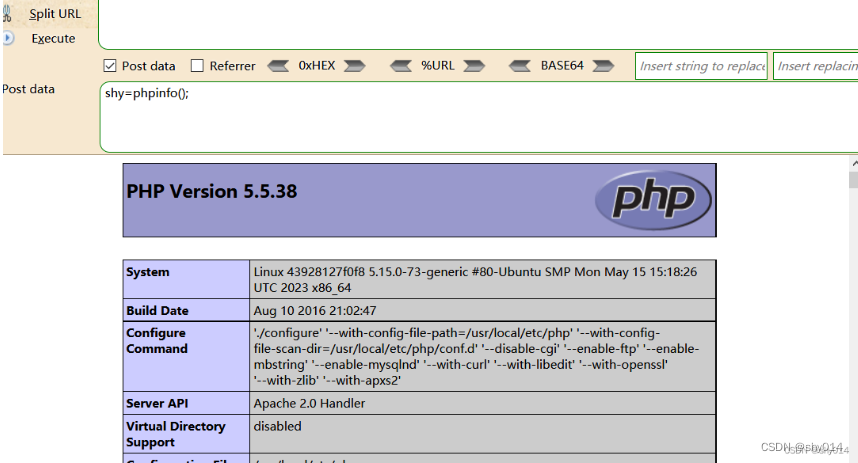
Vulhub之Apache HTTPD 换行解析漏洞(CVE-2017-15715)
Apache HTTPD是一款HTTP服务器,它可以通过mod_php来运行PHP网页。其2.4.0~2.4.29版本中存在一个解析漏洞,在解析PHP时,1.php\x0A将被按照PHP后缀进行解析,导致绕过一些服务器的安全策略。 1、docker-compose build、docker-compo…...
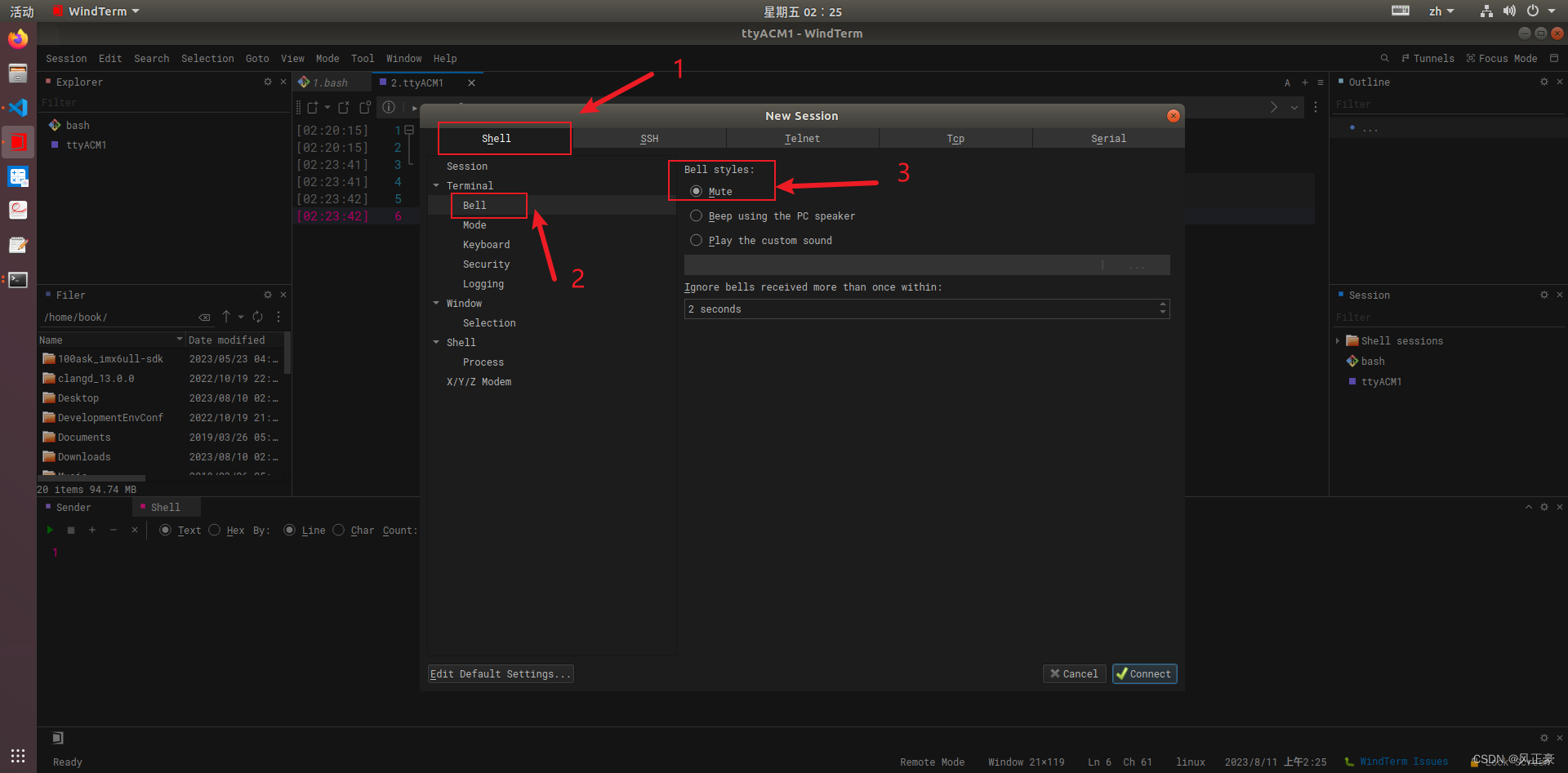
ARTS 挑战打卡的第7天 --- Ubuntu中的WindTerm如何设置成中文,并且关闭shell中Tab键声音(Tips)
前言 (1)Windterm是一个非常优秀的终端神器。关于他的下载我就不多说了,网上很多。今天我就分享一个国内目前没有找到的这方面的资料——Ubuntu中的WindTerm如何设置成中文,并且关闭shell中Tab键声音。 将WindTerm设置成中文 &…...

Oracle之执行计划
1、查看执行计划 EXPLAIN PLAN FOR SELECT * FROM temp_1 a ; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY); 2、执行计划说明 2.1、执行顺序 根据缩进来判断,缩进最多的最先执行;(缩进相同时,最上面的最先执行) 2.2…...

【Vue框架】菜单栏权限的使用与显示
前言 在 【Vue框架】Vue路由配置 中的getters.js里,可以看到有一个应用程序的状态(变量)叫 permission_routes,这个就是管理前端菜单栏的状态。具体代码的介绍,都以注释的形式来说明。 1、modules\permission.js 1…...

案例研究|大福中国通过JumpServer满足等保合规和资产管理双重需求
“大福中国为了满足安全合规要求引入堡垒机产品,在对比了传统型堡垒机后,发现JumpServer使用部署更加灵活,功能特性丰富,能够较好地满足公司在等保合规和资产管理方面的双重需求。” ——大福(中国)有限公…...
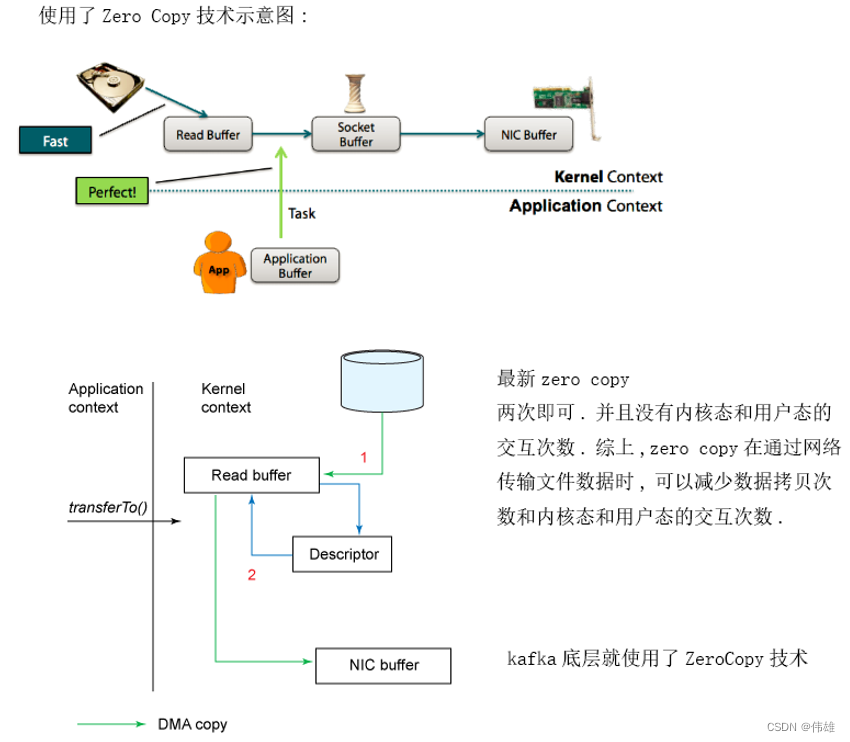
大数据课程I4——Kafka的零拷贝技术
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Kafka的零拷贝技术; ⚪ 了解常规的文件传输过程; 一、常规的网络传输原理 表面上一个很简单的网络文件输出的过程,在OS底层&…...
红日ATT&CK VulnStack靶场(三)
网络拓扑 web阶段 1.扫描DMZ机器端口 2.进行ssh和3306爆破无果后访问web服务 3.已知目标是Joomla,扫描目录 4.有用的目录分别为1.php 5.configuration.php~中泄露了数据库密码 6.administrator为后台登录地址 7.直接连接mysql 8.找到管理员表,密码加密了…...

JavaScript之BOM+window对象+定时器+location,navigator,history对象
一.BOM概述 BOM即浏览器对象模型,它提供了独立于内容而与窗口进行交互的对象 BOM的顶级对象是window 二.window对象的常见事件 1.窗口加载事件window.onload window.onload function(){} 或者 window.addEventListener("onload" , function(){}); window.onlo…...

为MySQL新增一张performance_schema表 | StoneDB 技术分享会 #4
StoneDB开源地址 https://github.com/stoneatom/stonedb 设计:小艾 审核:丁奇、李浩 编辑:宇亭 作者:王若添 中国科学技术大学-软件工程-在读硕士、StoneDB 内核研发实习生 performance_schema 简介 MySQL 启动后会自动创建四…...
2023/8/12总结
增加了管理员功能点:(管理标签和分类) 另外加了一个转换成pdf的功能 主要是通过wkhtmltopdf实现的,之前看过很多说用adobe的还有其他但是都没成功。 然后就是在学习websocket和协同过滤算法实现,还只是初步了解了这些。…...

win10电脑npm run dev报错解决
npm run dev报错解决 出现错误前的操作步骤错误日志解决步骤 出现错误前的操作步骤 初始化Vue项目 $ npm create vue3.6.1创建项目文件夹client Vue.js - The Progressive JavaScript Framework✔ Project name: › client ✔ Add TypeScript? › No ✔ Add JSX Support? …...

如何使用PHP编写爬虫程序
在互联网时代,信息就像一条无休无止的河流,源源不断地涌出来。有时候我们需要从Web上抓取一些数据,以便分析或者做其他用途。这时候,爬虫程序就显得尤为重要。爬虫程序,顾名思义,就是用来自动化地获取Web页…...
分布式 - 服务器Nginx:一小时入门系列之HTTP反向代理
文章目录 1. 正向代理和反向代理2. 配置代理服务3. proxy_pass 命令解析4. 设置代理请求headers 1. 正向代理和反向代理 正向代理是客户端通过代理服务器访问互联网资源的方式。在这种情况下,客户端向代理服务器发送请求,代理服务器再向互联网上的服务器…...
)
Android Fragment (详细版)
经典好文推荐,通过阅读本文,您将收获以下知识点: 一、Fragment 简介 二、Fragment的设计原理 三、Fragment 生命周期 四、Fragment 在Activity中的使用方法 五、动态添加Fragment到Activity的方法 六、Activity 中获取Fragment 七、Fragment 获取宿主Activity的方法 八、两个…...

如何使用Flask-RESTPlus构建强大的API
如何使用Flask-RESTPlus构建强大的API 引言: 在Web开发中,构建API(应用程序接口)是非常常见和重要的。API是一种允许不同应用程序之间交互的方式,它定义了如何请求和响应数据的规范。Flask-RESTPlus是一个基于Flask的…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

国内大学生常用的AI写作辅助平台有哪些?
国内高校学生常用的 AI 写作辅助平台,以本土化全流程工具为主,结合通用大模型与专项功能模块,覆盖选题构思、大纲搭建、初稿撰写、语言润色、降重处理、查重检测及格式排版等关键环节,以下是主流平台详解与对比: 一、本…...

AutoPentest:面向红队的渗透测试决策引擎架构解析
1. 这不是又一个“自动化扫描器”,而是一套能替你做决策的渗透测试工作流引擎AutoPentest这个名字,第一眼容易让人联想到Nmap加个for循环、或者Burp Suite里点几下Intruder——但实际用过的人很快会意识到:它根本不在同一个维度上。我第一次在…...

CA-CFAR、GO-CFAR、SO-CFAR怎么选?一张图看懂三种恒虚警检测算法的适用场景与避坑指南
CA-CFAR、GO-CFAR、SO-CFAR工程选型指南:从算法原理到场景适配 雷达信号处理工程师常常面临一个经典难题:在复杂环境中如何选择合适的恒虚警检测算法?当海面杂波、多目标干扰或低信噪比条件同时出现时,CA、GO、SO三种CFAR变体的性…...

3步开启Windows 11安卓应用新体验:WSA完整使用指南
3步开启Windows 11安卓应用新体验:WSA完整使用指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android(简…...

机器学习力场攻克Peierls相变动力学:从对称性描述符到畴生长标度律
1. 项目概述:当机器学习遇见Peierls相变在凝聚态物理和材料科学的前沿,我们常常被一个核心问题所困扰:如何精确地模拟那些由电子和晶格(原子)强烈耦合所驱动的复杂动力学过程?这类系统,比如电荷…...

D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析
D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 当…...

如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器
如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为想和朋友一起玩游戏却只有一台电脑而烦…...