Elasticsearch-查询
一、查询和过滤
1.1 相关性分数 :_score
默认情况下,Elasticsearch 按相关性得分对匹配的搜索结果进行排序,相关性得分衡量每个文档与查询的匹配程度。
相关性分数是一个正浮点数,在搜索的数据字段中返回。_score越高,文档的相关性越高。虽然每种查询类型可以以不同的方式计算相关性分数,但分数计算还取决于查询子句是在查询上下文中运行还是在过滤器上下文中运行。
查询
在查询内容中,查询子句判断”此文档与此查询子句的匹配程度如何” 除了判断文档是否匹配之外,查询子句还计算 _score元数据字段中的相关性分数。
过滤
在过滤器中,查询子句判断“此文档是否与此查询子句匹配”。” 答案很简单,是或否。
不计算分数。过滤器上下文主要用于过滤结构化数据
1.2 查询和过滤示例
年龄age为28,balance小于40000
{"query": {"bool": {"must": [{ "match": { "age": 28 }}],"filter": [ { "range": { "balance": { "lte": 40000 }}}]}}
}
二、简单查询
2.1 查询所有–match_all
{"query": {"match_all": {}}
}
2.2 term 查询
{"query": {"term": {"email": {"value": "hattie"}}}
}2.3 分页查询
默认返回前 10 条数据,es 中也可以像关系型数据库一样,给一个分页参数:
from:从第几条开始。
size:多少条数据。
{"query": {"match": {"gender": "F"}},"from": 10,"size": 20
}
2.4 过滤返回字段
如果返回的字段比较多,又不需要这么多字段,此时可以使用"_source"指定返回的字段:
{"query": {"match": {"gender": "F"}},"_source": ["firstname"],
}
2.5 最小评分
部分文档得分特别低,说明这些文档和我们查询的关键字相关度很低。我们可以使用"min_score"设置一个最低分,只有得分超过最低分的文档才会被返回。
{"query": {"match": {"gender": "F"}},"min_score":1.2
}
2.6 高亮
{"query": {"match": {"firstname": "Nanette"}},"highlight": {"fields": {"firstname": {}}}
}
三、复合查询
复合查询是一种将多个查询组合起来进行检索的方式,可以根据用户的需求进行灵活的组合和定制,常见的复合查询包括 bool、boosting、constant_score、dis_max、function_score 。
3.1 bool查询
bool查询包括四种子句:must, filter, should, must_not
must:返回的文档必须满足must子句的条件,并且参与计算分值
filter:返回的文档必须满足filter子句的条件。但是不会像Must一样,参与计算分值
should:返回的文档可能满足should子句的条件。在一个Bool查询中,如果没有must或者filter,有一个或者多个should子句,那么只要满足一个就可以返回。minimum_should_match参数定义了至少满足几个子句。
must_not:返回的文档必须不满足must_not定义的条件。
{"query": {"bool" : {"must" : {"term" : { "user.id" : "kimchy" }},"filter": {"term" : { "tags" : "production" }},"must_not" : {"range" : {"age" : { "gte" : 10, "lte" : 20 }}},"should" : [{ "term" : { "tags" : "env1" } },{ "term" : { "tags" : "deployed" } }],"minimum_should_match" : 1,"boost" : 1.0}}
}
3.2 boosting查询(增强查询)
返回与查询匹配的文档,同时降低也与查询匹配的文档的 相关性得分。
您可以使用boosting查询来降级某些文档,而不将它们从搜索结果中排除。
{"query": {"boosting": {"positive": {"term": {"text": "apple"}},"negative": {"term": {"text": "pie tart fruit crumble tree"}},"negative_boost": 0.5}}
}
顶级参数boosting
positive
(必需,查询对象)运行的查询。任何返回的文档都必须与此查询匹配。
negative
(必填,查询对象)用于降低匹配文档的相关性得分的查询。
negative_boost
(必需,float) 0 和 1之间的浮点数,用于降低与negative查询匹配的文档的相关性分数。
3.3 Constant score查询(恒定分数)
包含过滤器查询并返回相关性得分等于boost参数值的每个匹配文档。
{"query": {"constant_score": {"filter": {"term": { "title": "计算机" }},"boost": 1.2}}
}
顶级参数constant_score
filter
(必需,查询对象)您希望运行的过滤器查询。任何返回的文档都必须与此查询匹配。
boost
(可选,浮点数)浮点数,用作与filter查询匹配的每个文档的恒定相关性得分。默认为1.0.
3.4 Dis_max 查询
Dis_max 查询是 Elasticsearch 中一种用于多个查询子句的组合查询方式。
它会同时执行多个查询,并将每个查询的分值进行比较,取最高分值作为文档的最终分值
{"query": {"dis_max": {"queries": [{ "term": { "title": "计算机" } },{ "term": { "body": "计算机" } }],"tie_breaker": 0.7}}
}
其中,queries 字段包含了多个查询子句,以数组的形式列出。在上面的例子中,使用了两个 match 查询子句,分别匹配 title 和 body字段中包含“计算机”的文档。当有多个查询子句时,Dis_max 查询会返回所有查询的结果并进行分值计算,选取分值最高的文档。tie_breaker 字段是可选参数,其取值为一个介于 0 到 1 之间的浮点数,代表除了分值以外的因素影响程度。当多个查询子句得分相等时,使用该参数指定的权重进行打分。
3.5 function_score查询
场景:例如想要搜索附近的肯德基,搜索的关键字是肯德基,但是我希望能够将评分较高的肯德基优先展示出来。但是默认的评分策略是没有办法考虑到餐厅评分的,他只是考虑相关性,这个时候可以通过 function_score query 来实现
PUT kfc
{"mappings": {"properties": {"name":{"type": "text","analyzer": "ik_max_word"},"votes:":{"type": "integer"}}}
}PUT kfc/_doc/1
{"name":"评分高的肯德基餐厅1","votes":100
}
PUT kfc/_doc/2
{"name":"肯德基餐厅2,评分最低的肯德基餐厅","votes":10
}/*按名称name搜索*/GET kfc/_search
{"query": {"match": {"name": "肯德基"}}
}
搜索结果默认情况下,id 为 2 的记录得分较高,因为他的 title 中包含两个肯德基。
如果我们在查询中,希望能够充分考虑 votes 字段,将 votes 较高的文档优先展示,就可以通过function_score 来实现。
具体的思路,就是在旧的得分基础上,根据 votes 的数值进行综合运算,重新得出一个新的评分。
具体有几种不同的计算方式:
- weight
- random_score
- script_score
- field_value_factor
(1)weight
weight 可以对评分设置权重,就是在旧的评分基础上乘以 weight,他其实无法解决我们上面所说的问题。具体用法如下:
{"query": {"function_score": {"query": {"match": {"name": "肯德基"}},"functions": [{"weight": 10}]}}
}
(2)random_score
为每个用户都使用一个不同的随机评分对结果排序,但对某一具体用户来说,看到的顺序始终是一致的
GET kfc/_search
{"query": {"function_score": {"query": {"match": {"name": "肯德基"}},"functions": [{"random_score": {"seed": 100,"field": "_seq_no"}}]}}
}
(3)field_value_factor
field_value_factor函数允许您使用文档中的一个字段来影响分数。
GET kfc/_search
{"query": {"function_score": {"query": {"match": {"name": "肯德基"}},"functions": [{"field_value_factor": {"field": "votes","factor": 1.2,"modifier": "none"}}]}}
}
field:文档中的字段。
factor:用于与字段值相乘的可选因子,默认为1。
modifier:应用于字段值的修饰符可以是以下之一:none、log、 log1p、log2p、ln、ln1p、ln2p、square、sqrt、 或reciprocal。默认为none.
| 项目 | Value |
|---|---|
| log | 取字段值的常用对数。由于此函数如果用于 0 到 1 之间的值,将返回负值并导致错误,因此建议改为使用log1p。 |
| log1p | 字段值加1,取常用对数 |
| log2p | 字段值加2,取常用对数 |
| ln | 取字段值的自然对数。由于此函数如果用于 0 到 1 之间的值,将返回负值并导致错误,因此建议改为使用ln1p。 |
| ln1p | 字段值加1,取自然对数 |
| ln2p | 字段值加2,取自然对数 |
| square | 字段值的平方(与其自身相乘) |
| sqrt | 取字段值的平方根 |
| reciprocal | 将字段值取倒数1/x |
运行结果

四、Es 全文查询
4.1 match
match query 会对查询语句进行分词,分词后,如果查询语句中的任何一个词项被匹配,则文档就会被索引到。
{"query": {"match": {"name": "肯德基评分"}}
}
4.2 match_phrase
match_phrase 也会对查询的关键字进行分词,但是它分词后有两个特点:
- 分词后的词项顺序必须和文档中词项的顺序一致
- 所有的词都必须出现在文档中
{"query": {"match_phrase": {"name": {"query": "肯德基评分","slop": 9}}}
}
slop 配置中间可以隔多少字符
4.3 combined fields
combined_fields查询支持搜索多个文本字段
{"query": {"combined_fields" : {"query": "计算机","fields": [ "title", "content", "body"],"operator": "and"}}
}
operator默认为or
4.4 multi_match
match 查询的升级版,可以指定多个查询域(意思就是查询多个字段)
{"query": {"multi_match" : {"query": "Will Smith","fields": [ "title", "*_name" ] }}
}
查询title、first_name、last_name字段。
五、Es 地理位置查询
创建一个索引:
PUT city
{"mappings": {"properties": {"name": {"type": "keyword"},"location": {"type": "geo_point"}}}
}
Elasticsearch 支持两种类型的地理数据: geo_point支持纬度/经度对的字段,以及 geo_shape支持点、线、圆、多边形、多多边形等的字段。
{"index":{"_index":"geo","_id":1}}
{"name":"西安","location":"34.288991865037524,108.9404296875"}{"index":{"_index":"geo","_id":2}}
{"name":"北京","location":"39.926588421909436,116.43310546875"}{"index":{"_index":"geo","_id":3}}
{"name":"上海","location":"31.240985378021307,121.53076171875"}{"index":{"_index":"geo","_id":4}}
{"name":"天津","location":"39.13006024213511,117.20214843749999"}{"index":{"_index":"geo","_id":5}}
{"name":"杭州","location":"30.259067203213018,120.21240234375001"}{"index":{"_index":"geo","_id":6}}
{"name":"武汉","location":"30.581179257386985,114.3017578125"}{"index":{"_index":"geo","_id":7}}
{"name":"合肥","location":"31.840232667909365,117.20214843749999"}{"index":{"_index":"geo","_id":8}}
{"name":"重庆","location":"29.592565403314087,106.5673828125"}使用postman导入数据 可参考

5.1 geo_distance
给出一个中心点,查询距离该中心点指定范围内的文档:
以(34.28,108.94) 为圆心,以 600KM 为半径,这个范围内的数据。
GET /city/_search
{"query": {"bool": {"must": {"match_all": {}},"filter": {"geo_distance": {"distance": "600km","location": {"lat": 34.28,"lon": 108.94}}}}}
}
5.2 geo_bounding_box
通过两个点锁定一个矩形,查询在这个矩形内的点
GET /city/_search
{"query": {"bool": {"must": {"match_all": {}},"filter": {"geo_bounding_box": {"location": {"top_left": {"lat": 32.06,"lon": 118.78},"bottom_right": {"lat": 29.98,"lon": 122.02}}}}}}
}
{ “lat”: 32.06,“lon”: 118.78 } 和 {“lat”: 29.98, “lon”: 122.02 },构造出来的矩形中,包含上海和杭州两个城市
5.3 geo_polygon
在某一个多边形范围内的查询。
GET /geo/_search
{"query": {"bool": {"must": {"match_all": {}},"filter": {"geo_polygon": {"location": {"points": [{ "lat": 23, "lon": 100 },{ "lat": 30, "lon": 80 },{ "lat": 30, "lon": 120 }]}}}}}
}
5.4 geo_shape
PUT /geo_shape
{"mappings": {"properties": {"name":{"type": "keyword"},"location": {"type": "geo_shape"}}}
}
增加一条线
POST /geo_shape/_doc/1
{"name": "西安-郑州","location": {"type":"linestring","coordinates": [[ 108.94, 34.27 ],[ 113.66, 34.67 ]]}
}接下来查询相交的线:
GET /geo_shape/_search
{"query": {"bool": {"must": {"match_all": {}},"filter": {"geo_shape": {"location": {"shape": {"type": "envelope","coordinates": [[106,36],[155,32]]},"relation": "intersects"}}}}}
}
relation 属性有三个:
- within:包含
- intersects:相交
- disjoint:不相交
六、嵌套查询
Elasticsearch 提供了旨在水平扩展的联接形式。
- nested 查询
- has_child 和 has_parent 查询
6.1 nested 查询
要使用nested查询,您的索引必须包含嵌套字段映射
PUT /product
{"mappings": {"properties": {"phone": {"type": "nested"}}}
}PUT /product/_doc/1
{"name":"华为","phone":[{"color":"红色","memory":"128g"},{"color":"红色","memory":"256g"},{"color":"黑色","memory":"128"},{"color":"黑色","memory":"256g"}]
}
GET /product/_search
{"query": {"nested": {"path": "phone","query": {"bool": {"must": [{"match": {"phone.color": "黑色"}},{"match": {"phone.memory": "128g"}}]}}}}
}
6.2 父子文档、has_child查询 和 has_parent查询
6.2.1 父子文档
相比于嵌套文档,父子文档主要有如下优势:
- 更新父文档时,不会重新索引子文档
- 创建、修改或者删除子文档时,不会影响父文档或者其他的子文档。
- 子文档可以作为搜索结果独立返回。
创建父子文档
部门和员工之间的关系
PUT /department_employee
{"mappings": {"properties": {"name":{"type": "keyword"},"d_e":{"type": "join","relations": {"department":"employee"}}}}
}
d_e表示父子文档关系的名字,可以自定义。join 表示这是一个父子文档。relations 里边,department这个位置是 parent,employee这个位置是 child。
父子文档需要注意的地方:
- 每个索引只能定义一个 join filed
- 父子文档需要在同一个分片上(查询,修改需要routing)
- 可以向一个已经存在的 join filed 上新增关系
添加父文档
POST /department_employee/_doc/1
{"name":"人事部","d_e":{"name":"department"}
}POST /department_employee/_doc/2
{"name":"市场部","d_e":{"name":"department"}
}POST /department_employee/_doc/3
{"name":"信息部","d_e":{"name":"department"}
}
添加子文档
POST /department_employee/_doc?routing=1
{"name":"张三","d_e":{"name":"employee","parent": 1}
}
POST /department_employee/_doc?routing=1
{"name":"李四","d_e":{"name":"employee","parent": 1}
}
POST /department_employee/_doc?routing=2
{"name":"王五","d_e":{"name":"employee","parent": 2}
}
POST /department_employee/_doc?routing=3
{"name":"赵六","d_e":{"name":"employee","parent": 3}
}6.2.2 has_child 查询
查询 张三 所属的部门。
GET department_employee/_search
{"query": {"has_child": {"type": "employee","query": {"match": {"name": "张三"}}}}
}
6.2.3 has_parent 查询
查询人事部有哪些员工
GET department_employee/_search
{"query": {"has_parent": {"parent_type": "department","query": {"match": {"name": "人事部"}}}}
}
七、聚合查询
7.1 指标聚合
7.1.1 max aggregation统计最大值
GET /accounts/_search
{"aggs": {"max_balance": {"max": {"field": "balance"}}}
}
7.1.2 min aggregation统计最小值
GET /accounts/_search
{"aggs": {"min_balance": {"min": {"field": "balance"}}}
}
7.1.3 avg aggregation平均值
GET /accounts/_search
{"aggs": {"avg_balance": {"avg": {"field": "balance"}}}
}
7.1.4 sum aggregation求和
GET /accounts/_search
{"aggs": {"sum_balance": {"sum": {"field": "balance"}}}
}
7.1.5 Stats aggregation基本统计
基本统计,一次性返回 count、max、min、avg、sum
GET /accounts/_search
{"aggs": {"exp_stats": {"stats": {"field": "age"}}}
}
7.1.6 Extends Stats aggregation高级统计
比 stats 多出来:平方和、方差、标准差、平均值加减两个标准差的区间
GET /accounts/_search
{"aggs": {"exp_stats": {"extended_stats": {"field": "age"}}}
}
7.2 桶聚合
7.2.1 Terms aggregation 分组聚合
Terms Aggregation 用于分组聚合,例如,统计各个年龄的客户:
GET /accounts/_search
{"aggs": {"age_count": {"terms": {"field": "age","size": 20}}}
}
在 terms 分桶的基础上,还可以对每个桶进行指标聚合,统计各个年龄段客户的平均存款数
GET /accounts/_search
{"aggs": {"age_count": {"terms": {"field": "age","size": 20},"aggs": {"avg_balance": {"avg": {"field": "balance"}}}}}
}
7.2.2 Filter Aggregation 过滤器聚合
如统计年龄为31岁客户的平均存款余额
GET /accounts/_search
{"aggs": {"age_count": {"filter": {"term": {"age": 31}},"aggs": {"avg_balance": {"avg": {"field": "balance"}}}}}
}
7.2.3 Range Aggregation 范围聚合
统计各个年龄段的客户数量
GET /accounts/_search
{"aggs": {"age_range": {"range": {"field": "","ranges": [{"to": 20},{"from": 20,"to": 40},{"from": 40,"to": 50},{"from": 50,"to": 100}]}}}
}
7.2.4 Date Range Aggregation 统计日期
统计12个月前到一年后
{"aggs": {"date_range_count": {"date_range": {"field": "createtime","ranges": [{"from": "now-12M/M","to": "now+1y/y"}]}}}
}
12M/M表示12个月
1y/y表示一年
d表示天
7.2.5 Date Histogram Aggregation 时间直方图聚合
例如统计各个月份的客户数量
GET /accounts/_search
{"aggs": {"date_his_count": {"date_histogram": {"field": "date","calendar_interval": "month"}}}
}
7.2.6 Missing Aggregation 空值聚合
GET /accounts/_search
{"aggs": {"miss_balance": {"missing": {"field": "balance"}}}
}
7.2.7 Children Aggregation 根据父子关系分桶
GET department_employee/_search
{"aggs": {"d_e": {"children": {"type": "employee"}}}
}
7.2.8 Geo Distance Aggregation
地理位置,统计 {lat: 52.376, lon: 4.894}坐标方圆100km,100km-300km,300km以上的数目
GET geo/_search
{"aggs": {"geo_range": {"geo_distance": {"field": "location","origin": {"lat": 52.376,"lon": 4.894},"unit": "km", "ranges": [{"to": 100},{"from": 100,"to": 300},{"from": 300}]}}}
}
7.2.9 IP Range Aggregation
GET geo/_search
{"aggs": {"ip_count": {"ip_range": {"field": "ip","ranges": [{"from": "10.0.0.5","to": "10.0.0.10"}]}}}
}
7.3 管道聚合
管道聚合相当于在之前聚合的基础上,再次聚合。
7.3.1 Avg Bucket Aggregation
统计每个年龄客户存款的平均值,然后再统计平均值的平均值:
GET /accounts/_search
{"aggs": {"age_count": {"terms": {"field": "age","size": 20},"aggs": {"avg_balance": {"avg": {"field": "balance"}}}},"avg_avg":{"avg_bucket": {"buckets_path": "age_count>avg_balance"}}}
}
7.3.2 max Bucket Aggregation
统计每个年龄客户存款的平均值,然后再统计平均值中的最大值:
GET /accounts/_search
{"aggs": {"age_count": {"terms": {"field": "age","size": 20},"aggs": {"avg_balance": {"avg": {"field": "balance"}}}},"max_avg":{"max_bucket": {"buckets_path": "age_count>avg_balance"}}}
}
7.3.3 min Bucket Aggregation
统计每个年龄客户存款的平均值,然后再统计平均值中的最小值:
GET /accounts/_search
{"aggs": {"age_count": {"terms": {"field": "age","size": 20},"aggs": {"avg_balance": {"avg": {"field": "balance"}}}},"min_avg":{"min_bucket": {"buckets_path": "age_count>avg_balance"}}}
}
7.3.4 sum Bucket Aggregation
统计每个年龄客户存款的平均值,然后再统计平均值之和:
GET /accounts/_search
{"aggs": {"age_count": {"terms": {"field": "age","size": 20},"aggs": {"avg_balance": {"avg": {"field": "balance"}}}},"sum_avg":{"sum_bucket": {"buckets_path": "age_count>avg_balance"}}}
}
7.3.5 sum Bucket Aggregation
统计每个年龄客户存款的平均值,然后再统计平均值之和:
GET /accounts/_search
{"aggs": {"age_count": {"terms": {"field": "age","size": 20},"aggs": {"avg_balance": {"avg": {"field": "balance"}}}},"sum_avg":{"sum_bucket": {"buckets_path": "age_count>avg_balance"}}}
}
7.3.6 Stats Bucket Aggregation
统计每个年龄客户存款的平均值,然后再统计平均值的各项数值:
GET /accounts/_search
{"aggs": {"age_count": {"terms": {"field": "age","size": 20},"aggs": {"avg_balance": {"avg": {"field": "balance"}}}},"stats_avg":{"stats_bucket": {"buckets_path": "age_count>avg_balance"}}}
}
相关文章:
Elasticsearch-查询
一、查询和过滤 1.1 相关性分数 :_score 默认情况下,Elasticsearch 按相关性得分对匹配的搜索结果进行排序,相关性得分衡量每个文档与查询的匹配程度。 相关性分数是一个正浮点数,在搜索的数据字段中返回。_score越高࿰…...
首发 | FOSS分布式全闪对象存储系统白皮书
一、 产品概述 1. 当前存储的挑战 随着云计算、物联网、5G、大数据、人工智能等新技术的飞速发展,数据呈现爆发式增长,预计到2025年中国数据量将增长到48.6ZB,超过80%为非结构化数据。 同时,数字经济正在成为我国经济发展的新…...

Java反射获取所有Controller和RestController类的方法
Java反射获取所有Controller和RestController类的方法 引入三方反射工具Reflections <dependency><groupId>org.reflections</groupId><artifactId>reflections</artifactId><version>0.10.2</version> </dependency>利用反…...

设计模式--策略模式
目录 一.场景 1.1场景 2.2 何时使用 2.3个人理解 二. 业务场景练习 2.1业务: 2.2具体实现 2.3思路 三.总结 3.1策略模式的特点: 3.2策略模式优点 3.3策略模式缺点 一.场景 1.1场景 许多相关的类仅仅是行为有异,也就是说业务代码需要根据场景不…...
VSCode使用SSH无密码连接Ubuntu
VSCode使用SSH无密码连接Ubuntu 前提条件: 1. 能够正常使用vscode的Remote-ssh连接Ubuntu 2. Ubuntu配置静态ip(否则经常需要修改Remote-ssh的配置文件里的IP) 1. windows下 打开Win下的PowerShell,生成公钥和私钥 ssh-keygen…...
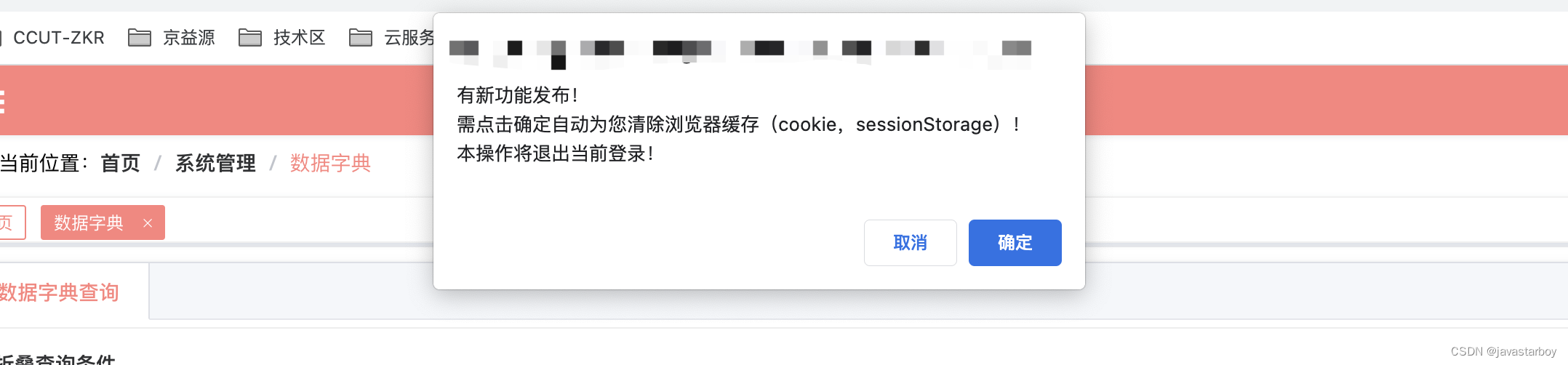
通过版本号控制强制刷新浏览器或清空浏览器缓存
背景介绍 在我们做 web 项目时,经常会遇到一个问题就是,需要 通知业务人员(系统用户)刷新浏览器或者清空浏览器 cookie 缓存的情况。 而对于用户而言,很多人一方面不懂如何操作,另一方面由于执行力问题&am…...
Redis系列(二):深入解读Redis的两种持久化方式
博客地址:blog.zysicyj.top Redis为什么要引入持久化机制 Redis引入持久化机制是为了解决内存数据库的数据安全性和可靠性问题。虽然内存数据库具有高速读写的优势,但由于数据存储在内存中,一旦服务器停止或崩溃,所有数据将会丢失…...
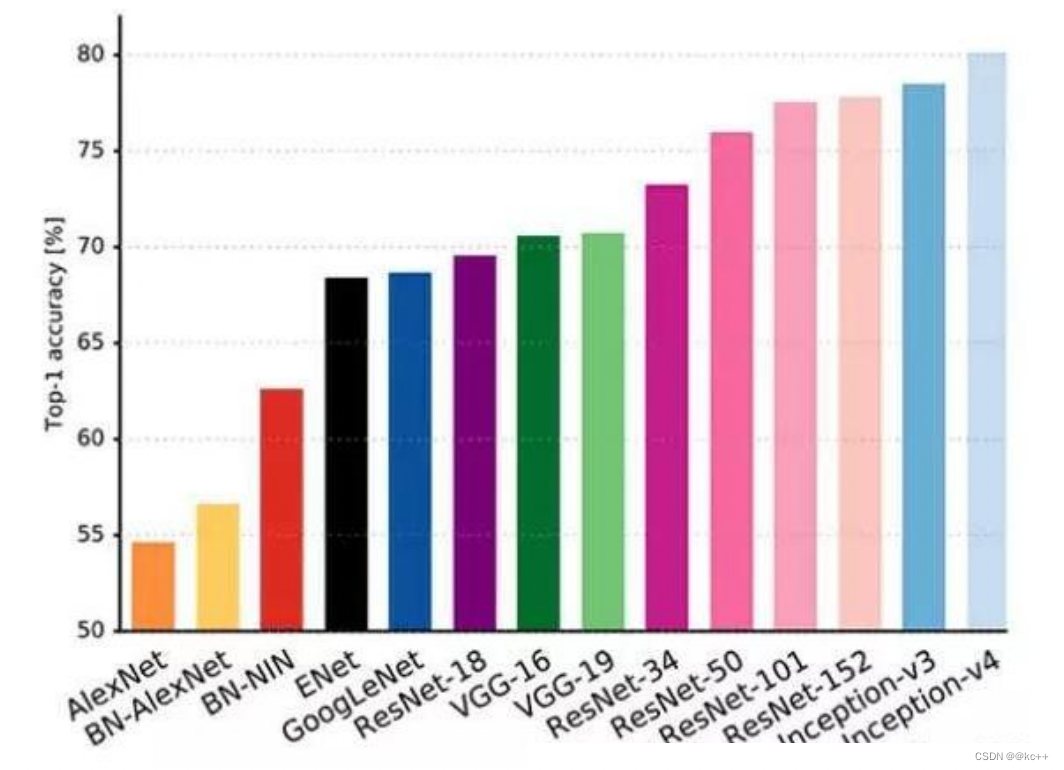
CNN之图像识别
文章目录 1. 图像识别1.1 模式识别1.2 图像识别的过程1.3 图像识别的应用 2. 深度学习发展2.1 深度学习为何崛起2.2 分类与检测2.3 常见的卷积神经网络 3. VGG3.1 VGG163.2 VGG16的结构:3.3 使用卷积层代替全连接3.4 1*1卷积的作用3.5 VGG16代码示例 4. 残差模型-Re…...

nvcc not found
检查cuda 安装成功 nvidia-smiCommand ‘nvcc’ not found, apt install nvidia-cuda-toolkitnvcc fatal : No input files specified; use option --help for more information # 注意是大写 V nvcc -V export PATH"/usr/local/cuda/bin:$PATH" expor…...
pdf怎么转换成jpg图片?这几个转换方法了解一下
pdf怎么转换成jpg图片?转换PDF文件为JPG图片格式在现代工作中是非常常见的需求,比如将PDF文件中的图表、表格或者图片转换为JPG格式后使用在PPT演示、网页设计等场景中。 【迅捷PDF转换器】是一款非常实用的工具,可以将PDF文件转换成多种不同…...
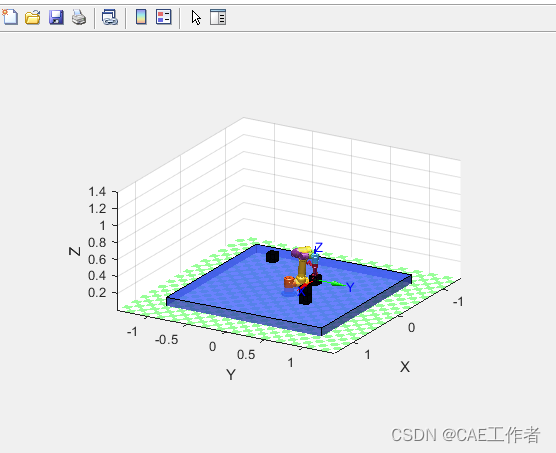
六轴机械臂码垛货物堆叠仿真
六轴机械臂码垛货物堆叠仿真 1、建立模型与仿真 clear,clc,close all addpath(genpath(.)) %建立模型参数如下: L(1) Link( d, 0.122, a , 0 , alpha, pi/2,offset,0); L(2) Link( d, 0.019 , a ,0.408 , alpha, 0,offset,pi/2); L(3) Link( d, …...

text-decoration 使用
text-decoration text-decoration 用于设置文本上的装饰性线条的外观。 它是 text-decoration-line、text-decoration-style、text-decoration-color 和text-decoration-thickness的缩写。 text-decoration: underline wavy red;text-decoration-line 设置文本装饰类型 可以…...

linux shell快速入门
linux shell快速入门 0 、前置1、简单使用 0 、前置 一安装linux的虚拟环境 1、简单使用 1、新建/usr/shell目录 2、新建hello.sh 文件 3、编写脚本文件# !/bin/bashecho "hello world"查看是否具备执行权限 新增执行权限 chomd x hello.sh执行hello.sh文件 /b…...

【Spring源码】小白速通解析Spring源码,从0到1,持续更新!
Spring源码 参考资料 https://www.bilibili.com/video/BV1Tz4y1a7FM https://www.bilibili.com/video/BV1iz4y1b75q bean的生命周期 bean–>推断构造方法(默认是无参构造,或指定的构造方法)–>实例化成普通对象(相当于ne…...
Unity 鼠标实现对物体的移动、缩放、旋转
文章目录 1. 代码2. 测试场景 1. 代码 using UnityEngine;public class ObjectManipulation : MonoBehaviour {// 缩放比例限制public float MinScale 0.2f;public float MaxScale 3.0f;// 缩放速率private float scaleRate 1f;// 新尺寸private float newScale;// 射线pri…...

67Class 的基本语法
Class 的基本语法 类的由来[constructor() 方法](https://es6.ruanyifeng.com/#docs/class#constructor() 方法)类的实例实例属性的新写法取值函数(getter)和存值函数(setter)属性表达式[Class 表达式](https://es6.ruanyifeng.c…...

企业数字化转型:无形资产占比测算(2007-2021年)
在本次数据中,参考张永珅老师的做法,利用无形资产占比测算数字化转型程度。 一、数据介绍 数据名称:企业数字化转型:无形资产占比 数据年份:2007-2021年 样本数量:32960条 数据说明:包括数…...

[centos]设置主机名
1、设置 hostnamectl set-hostname 名字 2、查看是否生效 hostnamectl status 3、打开一个新链接就可以了...

华为OD真题--新学习选址--带答案
2023华为OD统一考试(AB卷)题库清单-带答案(持续更新)or2023年华为OD真题机考题库大全-带答案(持续更新) 为了解新学期学生暴涨的问题,小乐村要建立所新学校 考虑到学生上学安全问题,需要所有学生家到学校的…...
Qt自定义对话框
介绍 自定义框主要通过对现有对话框QDialog类的派生,根据需求编写成员函数、重载信号函数、槽函数,进而实现在主QWidget中点击某个按钮后,一个对话框的弹出 流程 简化创建派生类 最后点击完成即可。 自定义ui界面,编写成员函数…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

Taotoken的稳定性与低延迟在实时对话应用中的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的稳定性与低延迟在实时对话应用中的实际体验 在开发需要快速响应的AI聊天应用时,后端API的稳定性和延迟表现是…...

抖音批量下载助手:一键构建你的专属视频素材库
抖音批量下载助手:一键构建你的专属视频素材库 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为手动保存抖音视频而烦恼吗?想要批量获取心仪创作者的精彩内容却无从下手&#x…...
)
市面上有哪些是真正安全的降AIGC网站(轻松压低AI生成疑似率)
最崩溃的不是查重难题,而是查重达标却AI率超标亮红灯!很多工具只会简单同义词替换、浅层改字,根本洗不掉AI专属句式、行文逻辑和高频模板话术,学校AIGC检测一查一个准,论文直接凉凉。 本篇结合全网实测数据,…...

Windows 11终极优化指南:一键清理系统,释放51%性能潜力
Windows 11终极优化指南:一键清理系统,释放51%性能潜力 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to decl…...

忆阻储层计算:预处理优化与硬件实现
1. 项目概述在当今人工智能快速发展的时代,神经形态计算正成为突破传统冯诺依曼架构瓶颈的重要方向。储层计算(Reservoir Computing,RC)作为一种特殊的循环神经网络架构,因其仅需训练输出层而显著降低了计算开销&#…...