机器学习:基本介绍
机器学习介绍

Hnad-crafted rules
Hand-crafted rules,叫做人设定的规则。那假设今天要设计一个机器人,可以帮忙打开或关掉音乐,那做法可能是这样:
- 设立一条规则,就是写一段程序。如果输入的句子里面看到**“turn off”**这个词汇,那chat-bot要做的事情就是把音乐关掉。这个时候,之后对chat-bot说,
Please turn off the music或can you turn off the music, Smart? 它就会帮你把音乐关掉。看起来好像很聪明。别人就会觉得果然这就是人工智能。但是如果今天想要欺负chat-bot一下,就可以说please don‘t turn off the music,但是还是会把音乐关掉。这是个真实的例子。相同的例子在车上面也体现,打开车窗,不要打开车窗,最终都会打开车窗。身边有很多这种类似的chat-bot,然后去真的对它说这种故意欺负它的话,它其实是会答错的。
使用hand-crafted rules有什么样的坏处呢,它的坏处就是:hand-crafted rules没办法考虑到所有的可能性,它非常的僵化,而用hand-crafted rules创造出来的machine,它永远没有办法超过它的创造者人类。 人类想不到东西,就没办法写规则,没有写规则,机器就不知道要怎么办。所以如果一个机器,它只能够按照人类所设定好的hand-crafted rules,它整个行为都是被规定好的,没有办法freestyle。如果是这样的话,它就没有办法超越创造它的人类。
你好像看到很多chat-bot看起来非常的聪明。如果你是有一个是一个非常大的企业,他给以派给成千上万的工程师,用血汗的方式来建出数以万计的规则,然后让他的机器看起来好像很聪明。但是对于中小企业来说,这样建规则的方式反而是不利的。
要做的其实是让机器它有自己学习的能力,也就我们要做的应该machine learning的方向。讲的比较拟人化一点,所谓machine learning的方向,就是你就写段程序,然后让机器人变得了很聪明,他就能够有学习的能力。接下来,你就像教一个婴儿、教一个小孩一样的教他,你并不是写程序让他做到这件事,你是写程序让它具有学习的能力。然后接下来,你就可以用像教小孩的方式告诉它。
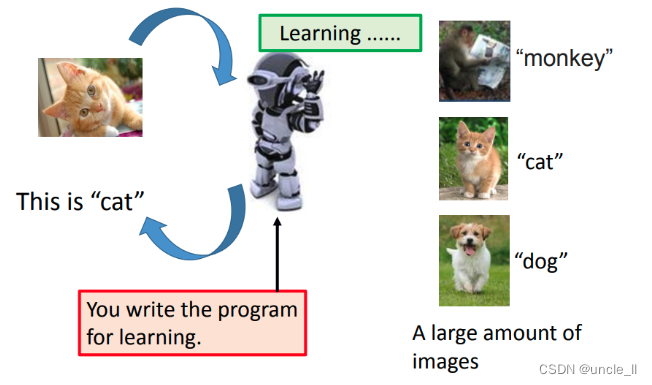
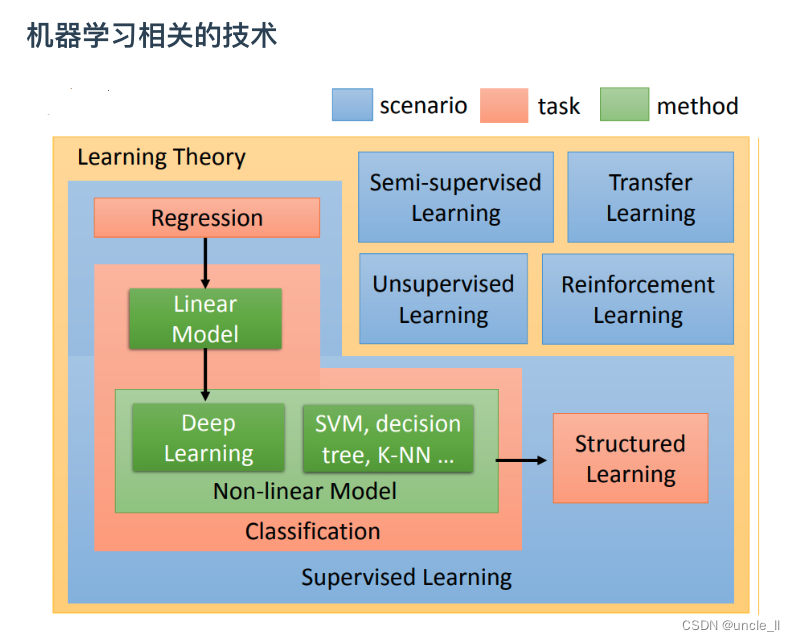
machine learning所做的事情,可以想成就是在寻找一个function,要让机器具有一个能力,这种能力是根据你提供给它的资料去寻找要寻找的function。

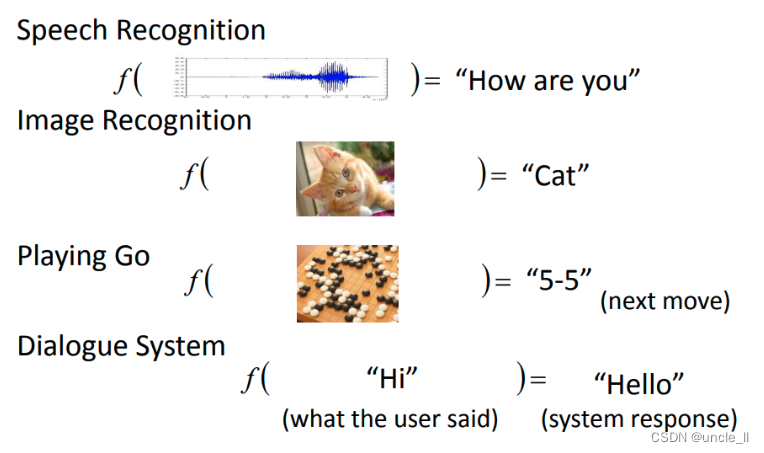

要先准备一个function set(集合),这个function里面有成千上万的function。举例来说,这个function在里面,有一个f1,你给它看一只猫,它就告诉你输出猫,看一只狗就输出狗。有一个function f2它很怪,你给它看猫,它说是猴子;你给他看狗,它说是蛇。所以要准备一个function set,这个function set里面有成千上万的function。先假设手上有一个function set,这个function set就叫做model(模型)。

有了这个function set,接下来机器要做的事情是:它有一些训练的资料,这些训练资料告诉机器说一个好的function,它的输入输出应该长什么样子,有什么样关系。你告诉机器说呢,现在在这个影像辨识的问题里面,如果看到这个猴子,看到这个猴子图也要输出猴子,看到这个猫的图也要输出猴子猫,看到这个狗的图,就要输出猴子猫狗,这样才是对的。只有这些训练资料,拿出一个function,机器就可以判断说,这个function是好的还是不好的。

机器可以根据训练资料判断一个function是好的,还是不好的。举例来说:在这个例子里面显然 f 1 f_1 f1,他比较符合training data的叙述,比较符合我们的知识。所以f1看起来是比较好的。 f 2 f_2 f2看起来是一个荒谬的function。这种task叫做supervised learning

现在机器有办法决定一个function的好坏。但光能够决定一个function的好坏是不够的,因为在function set里面有成千上万的function,它有会无穷无尽的function,所以需要一个有效率的评估算法,可以从function的set里面挑出最好的function。一个一个衡量function的好坏太花时间,实际上做不到。所以需要有一个好的评价算法,从function set里面挑出一个最好的的function,这个最好的function将它记为 f ∗ f^* f∗∗
machine learning里面非常重要的问题:机器有举一反三的能力
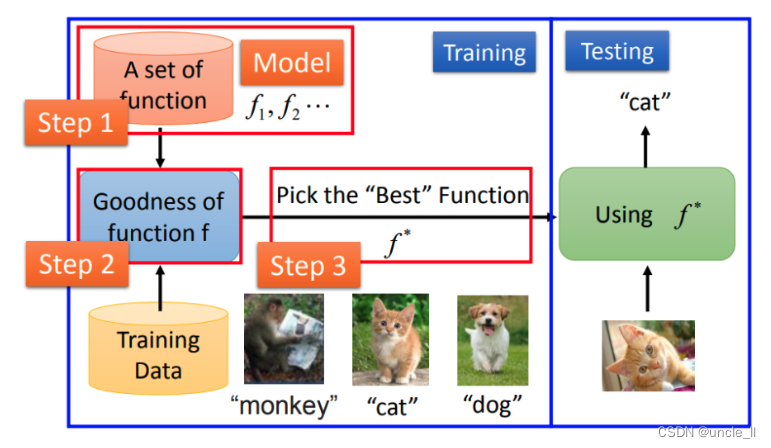
左边这个部分叫training,就是学习的过程;右边这个部分叫做testing,学好以后就可以拿它做应用。所以在整个machine learning framework整个过程分成了三个步骤:
- 第一个步骤就是找一个function
- 第二个步骤让machine可以衡量一个function是好还是不好
- 第三个步骤是让machine有一个自动的方法,有一个好评估算法可以挑出最好的function。
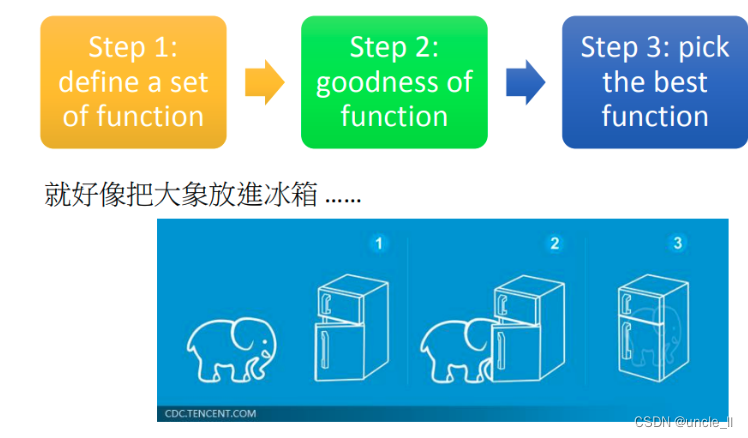
机器学习其实只有三个步骤,这三个步骤简化了整个process。可以类比为:把大象放进冰箱。把大象塞进冰箱,其实也是三个步骤:把门打开;象塞进去;后把门关起来,然后就结束了。所以说,机器学习三个步骤,就好像是说把大象放进冰箱,也只需要三个步骤。
监督学习
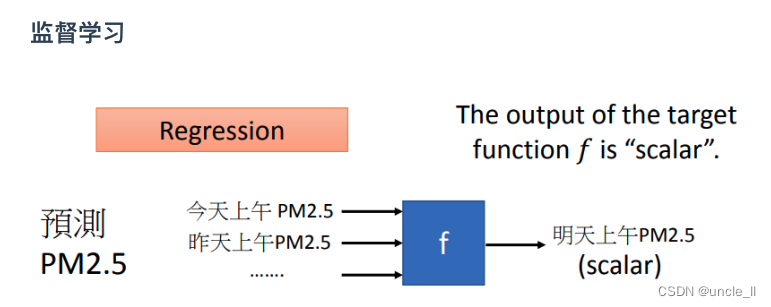
Regression是一种machine learning的task,当我们说:要做regression时的意思是,machine找到的function,它的输出是一个scalar,这个叫做regression。举例来说,在作业一里面会做PM2.5的预测(比如说预测明天上午的PM2.5) ,也就是说要找一个function,这个function的输出是未来某一个时间PM2.5的一个数值,这个是一个regression的问题。
机器要判断function明天上午的PM2.5输出,你要提供给它一些资讯,它才能够猜出明天上午的PM2.5。你给他数据可能是今天上的PM2.5、昨天上午的PM2.5等等。这是一个function,它吃我们给它过去PM2.5的资料,它输出的是预测未来的PM2.5。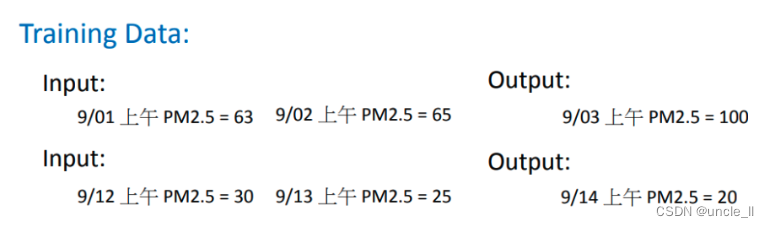
若要训练这种machine,如同在Framework中讲的,需要准备一些训练资料,就告诉它是根据过去从政府的open data上搜集下来的资料。九月一号上午的PM2.5是63,九月二号上午的PM2.5是65,九月三号上午的PM2.5是100。所以一个好的function输入九月一号、九月二号的PM2.5,它应该输出九月三号的PM2.5;若给function九月十二号的PM2.5、九月十三号的PM2.5,它应该输出九月十四号的PM2.5。若收集更多的data,那就可以做一个气象预报的系统
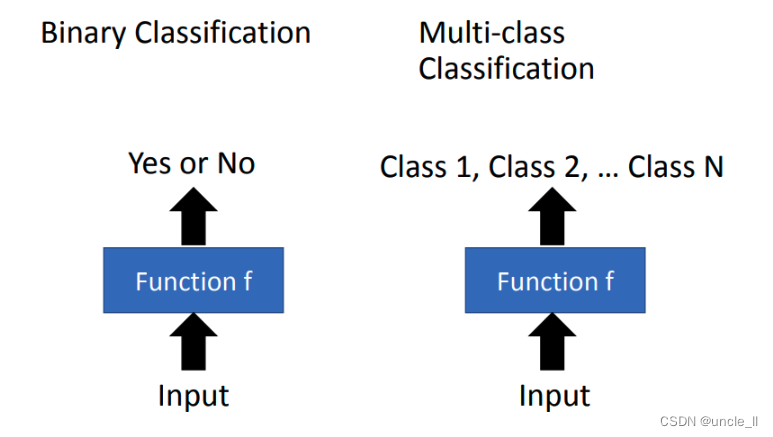
classification(分类)的问题。Regression和Classification的差别就是要机器输出的东西的类型是不一样。在Regression中机器输出的是一个数值,在Classification里面机器输出的是类别。假设Classification问题分成两种,一种叫做二分类输出的是是或否(Yes or No);另一类叫做多分类(Multi-class),在Multi-class中是让机器做一个选择题,等于是给他数个选项,每个选项都是一个类别,让从数个类别里选择正确的类别。


训练这样的function很简单,给它一大堆的Data并告诉它,现在输入这封邮件,应该说是垃圾邮件,输入这封邮件,应该说它不是垃圾邮件。足够多的这种资料去学就可以自动找出一个可以侦测垃圾邮件的function。

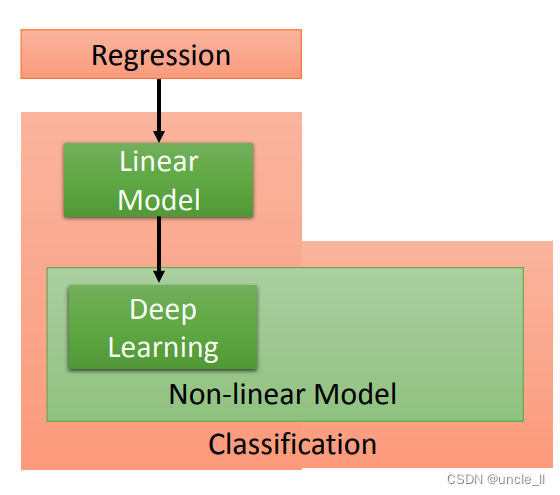
刚才讲的都是让machine去解的任务,接下来要讲的是在解任务的过程中第一步就是要选择function set,选不同的function set就是选不同的model。Model有很多种,最简单的就是线性模型,但会花很多时间在非线性的模型上。在非线性的模型中最耳熟能详的就是Deep learning。
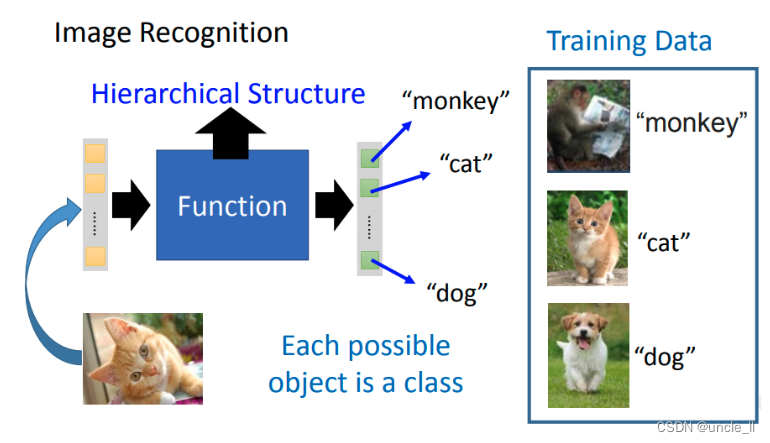
在做Deep learning时,它的function是特别复杂的,所以它可以做特别复杂的事情。比如它可以做图像识别,这个复杂的function可以描述pixel和class之间的关系。
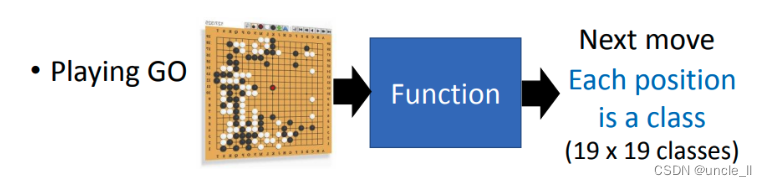
用Deep learning的技术也可以让机器下围棋, 下围棋这个task 其实就是一个分类的问题。对分类问题需要一个很复杂的function,输入是一个棋盘的格子,输出就是下一步应该落子的位置。知道一个棋盘上有十九乘十九的位置可以落子,所以今天下围棋这件事情就可以把它想成是一个十九乘十九个类别的分类问题,或者是可以把它想成是一个有十九乘十九个选项的选择题。
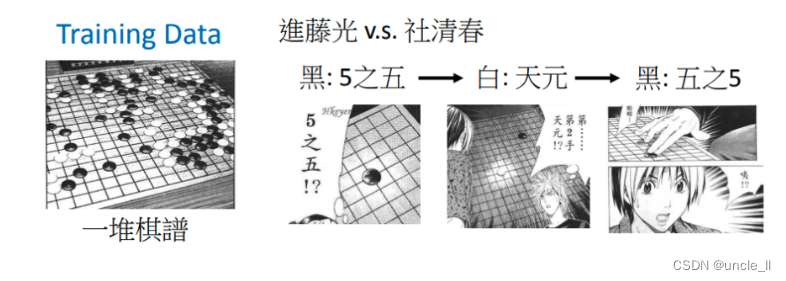
所以若你有了这样的棋谱之后,可以告诉machine如果现在有人落子下5之五,下一步就落子在天元;若五之五和天元都有落子,那就要落子在另外一个五之5上。然后你给它足够多的棋谱,它就能学会下围棋了。

刚才讲的都是supervised learning(监督学习),监督学习的问题是需要大量的training data。training data告诉要找的function的input和output之间的关系。如果在监督学习下进行学习,需要告诉机器function的input和output是什么。这个output往往没有办法用很自然的方式取得,需要人工的力量把它标注出来,这些function的output叫做label。
半监督学习

假设先想让机器鉴别猫狗的不同,想做一个分类器让它告诉你,图片上是猫还是狗。有少量的猫和狗的labelled data,但是同时又有大量的Unlabeled data,但是又没有力气去告诉机器说哪些是猫哪些是狗。在半监督学习的技术中,这些没有label的data,这些数据可能也是对学习有帮助,之后会讲为什么这些没有label的data对学习会有帮助。
另外一个减少data用量的方向是迁移学习。
迁移学习

迁移学习的意思是:假设要做猫和狗的分类问题,只有少量的有label的data。但是现在有大量的data,这些大量的data中可能有label也可能没有label。但是跟我们现在要考虑的问题是没有什么特别的关系的,分辨的是猫和狗的不同,但是这边有一大堆其他动物的图片还是动画图片。
更加进阶的就是无监督学习,希望机器可以学到无师自通。
无监督学习
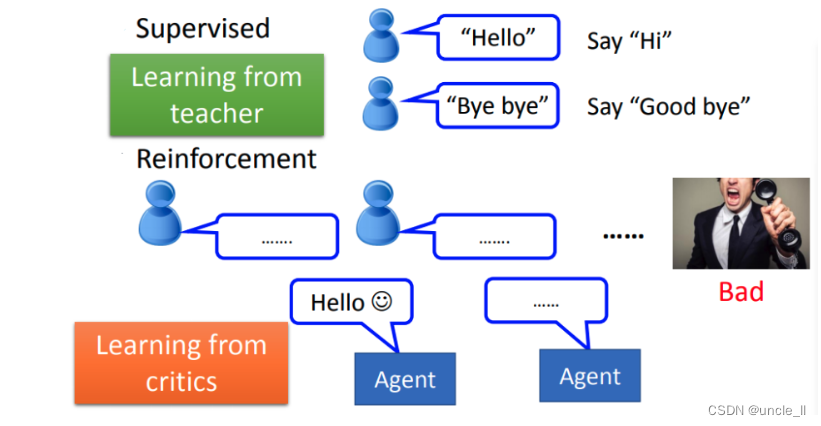
在reinforcement learning里面,没有告诉机器正确的答案是什么,机器所拥有的只有一个分数,就是他做的好还是不好。若现在要用reinforcement learning方法来训练一个聊天机器人的话,训练的方法会是这样:就把机器发到线下,让它和进来的客人对话,然后对话半天以后呢,最后客人勃然大怒把电话挂掉了。那机器就学到一件事情就是刚才做错了。但是它不知道哪边错了,它就要回去自己想道理,是一开始就不应该打招呼吗?还是中间不应该在骂脏话了之类。它不知道,也没有人告诉它哪里做的不好,它要回去反省检讨哪一步做的不好。机器要在reinforcement learning的情况下学习,机器是非常intelligence的。 reinforcement learning也是比较符合人类真正的学习的情景,这是在学校里面的学习老师会告诉你答案,但在真实社会中没人回告诉你正确答案。只知道做得好还是做得不好,如果机器可以做到reinforcement learning,那确实是比较intelligence。
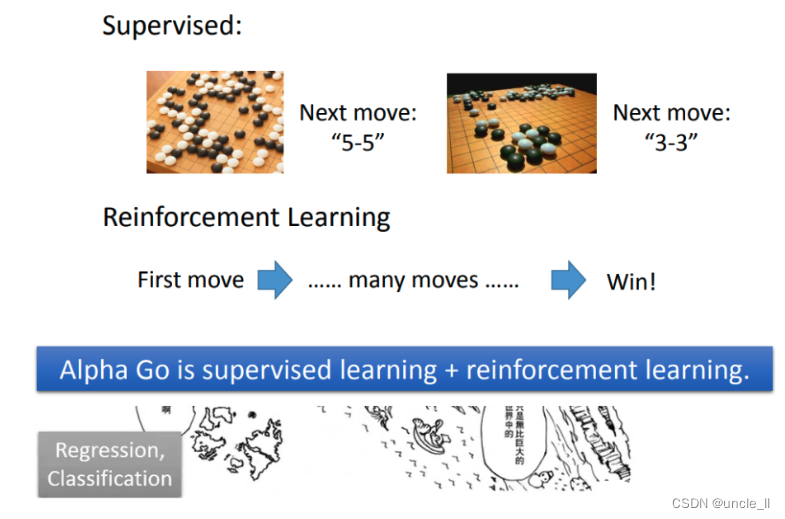
Alpha Go其实是用监督学习加上reinforcement learning去学习的。先用棋谱做监督学习,然后在做reinforcement learning,但是reinforcement learning需要一个对手,如果使用人当对手就会很让费时间,所以机器的对手是另外一个机器。
相关文章:
机器学习:基本介绍
机器学习介绍 Hnad-crafted rules Hand-crafted rules,叫做人设定的规则。那假设今天要设计一个机器人,可以帮忙打开或关掉音乐,那做法可能是这样: 设立一条规则,就是写一段程序。如果输入的句子里面看到**“turn of…...

基于长短期神经网络LSTM的碳排量预测,基于LSTM的碳排放量预测
目录 背影 摘要 LSTM的基本定义 LSTM实现的步骤 基于长短期神经网络LSTM的碳排放量预测 完整代码: 基于长短期神经网络LSTM的碳排放量预测,基于LSTM的碳排放量预测资源-CSDN文库 https://download.csdn.net/download/abc991835105/88184632 效果图 结果分析 展望 参考论文 背…...
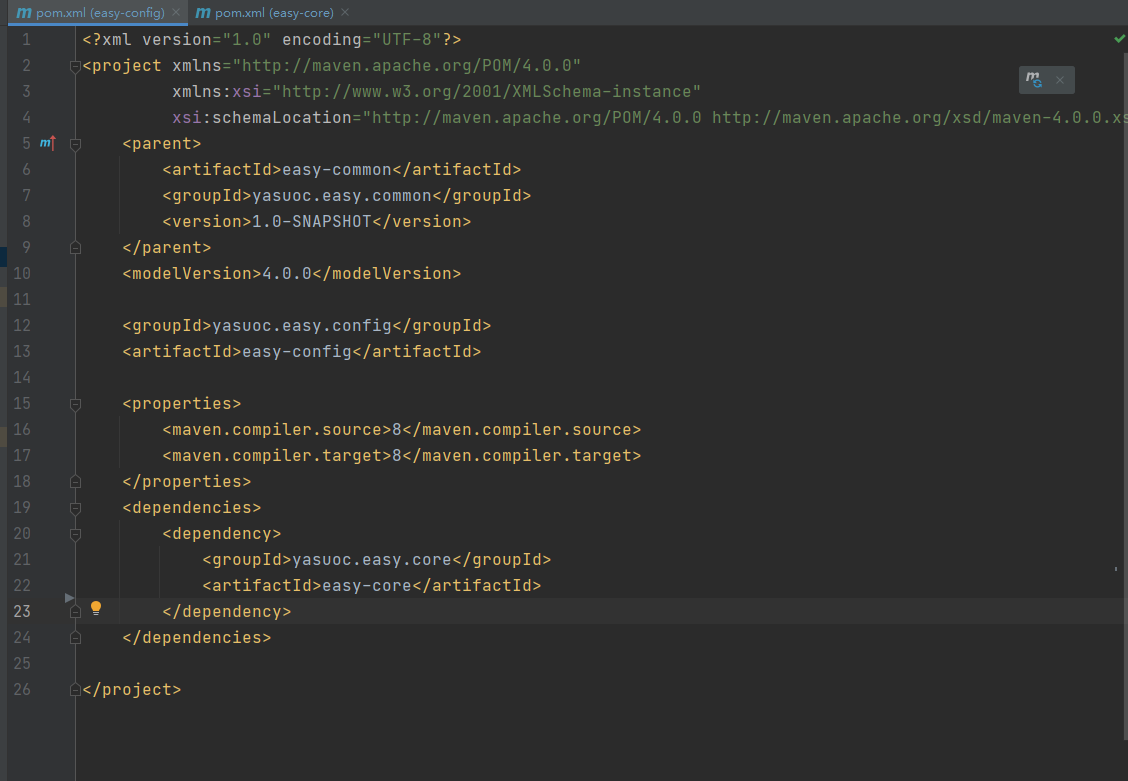
日常BUG——SpringBoot关于父子工程依赖问题
😜作 者:是江迪呀✒️本文关键词:日常BUG、BUG、问题分析☀️每日 一言 :存在错误说明你在进步! 一、问题描述 在父子工程A和B中。A依赖于B,但是A中却无法引入B中的依赖,具体出现的…...
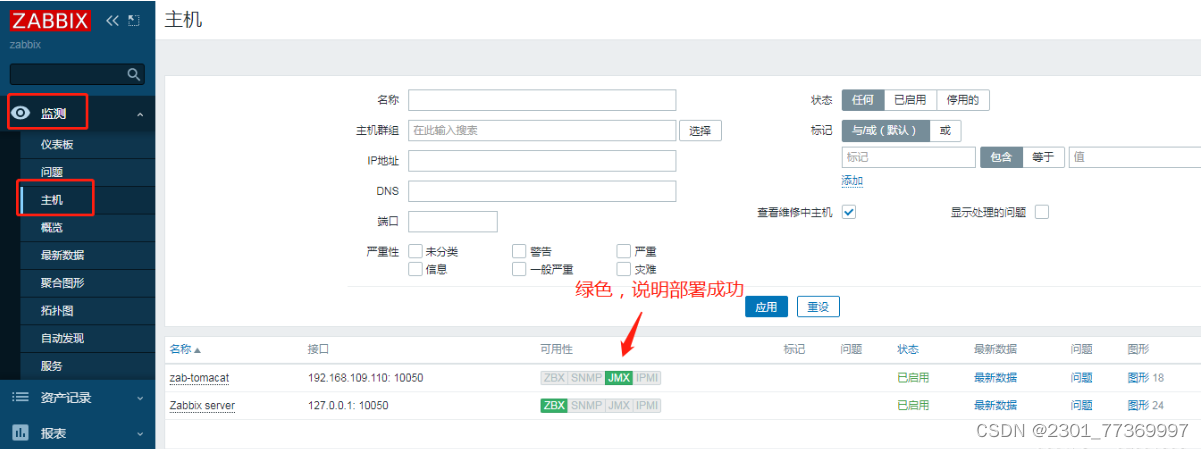
Zabbix监控tomcat
文章目录 一、安装部署TomcatTomcat二、安装Tomcat1.安装zabbix-agent收集监控数据(192.168.40.104)2.安装部署Zabbix-server(192.168.40.105)3.配置数据库 三、Zabbix监控Tomcat页面设置 实验环境 主机用途Centos7:192.168.40.105zabbix-server,zabbix-java-gatew…...
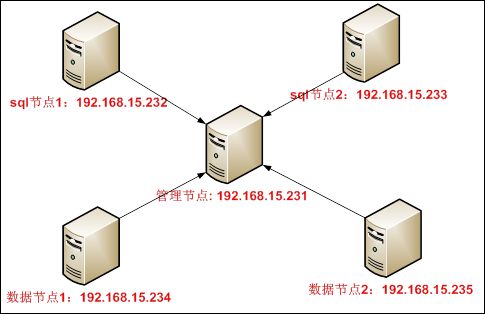
CentOS-6.3安装MySQL集群
安装要求 安装环境:CentOS-6.3 安装方式:源码编译安装 软件名称:mysql-cluster-gpl-7.2.6-linux2.6-x86_64.tar.gz 下载地址:http://mysql.mirror.kangaroot.net/Downloads/ 软件安装位置:/usr/local/mysql 数据存放位…...

项目管理的艺术:掌握成本效益分析
引言 在项目管理中,我们经常面临着如何有效地使用有限的资源来实现项目目标的挑战。为了解决这个问题,我们需要使用一种强大的工具——成本效益分析。通过成本效益分析,我们可以评估和比较不同的项目选项,选择最具成本效益的项目…...

护眼灯值不值得买?什么护眼灯对眼睛好
想要选好护眼台灯首先我们要知道什么是护眼台灯,大的方向来看,护眼台灯就是可以保护视力的台灯,深入些讲就是具备让灯发出接近自然光特性的光线,同时光线不会伤害人眼而出现造成眼部不适甚至是视力降低的照明设备。 从细节上看就…...
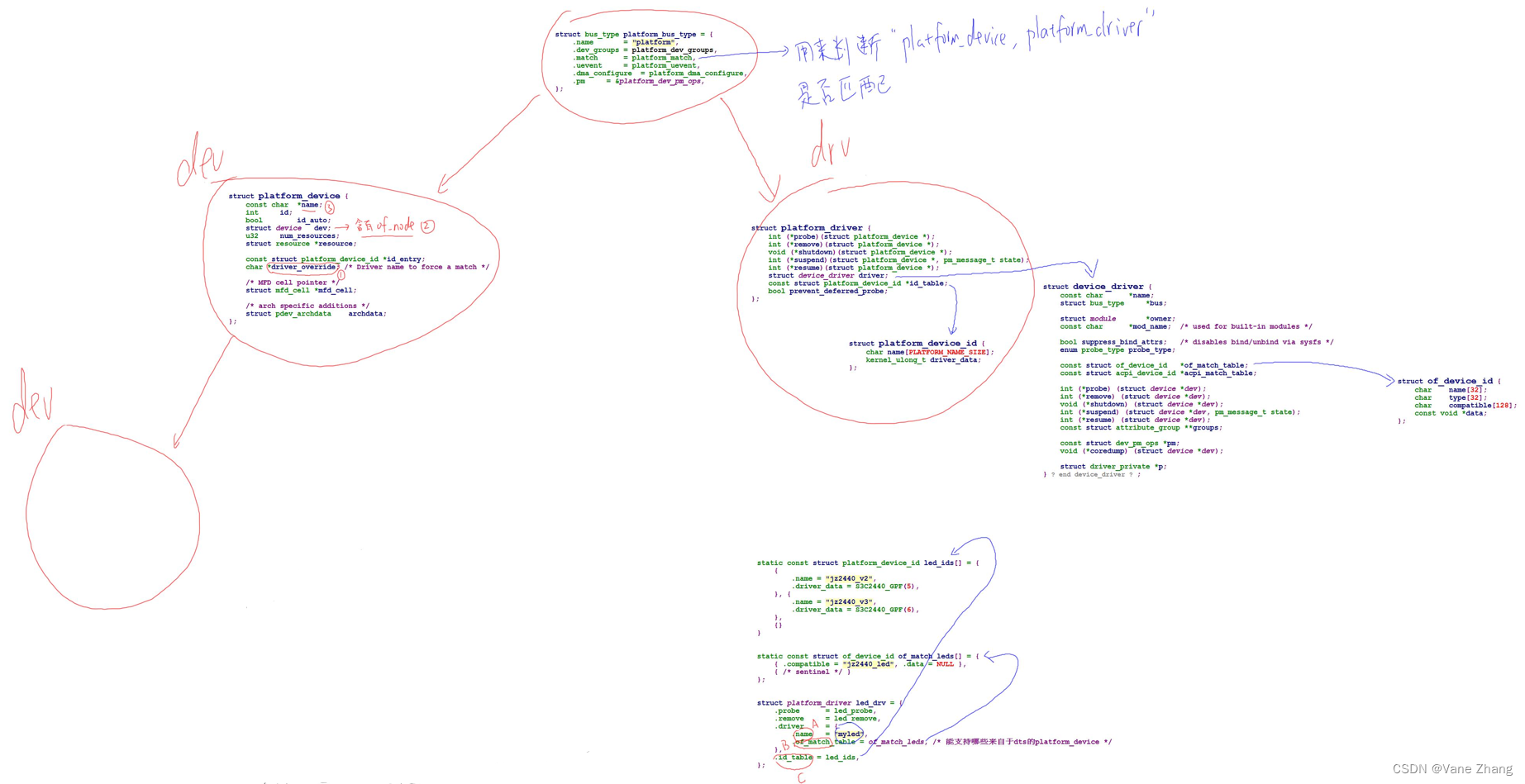
【设备树笔记整理4】内核对设备树的处理
1 从源头分析_内核head.S对dtb的简单处理 1.1 bootloader向内核传递的参数 (1)bootloader启动内核时,会设置r0,r1,r2三个寄存器: r0一般设置为0;r1一般设置为machine_id (在使用设备树时该参数没有被使用…...

算法通关村第七关——递归和迭代实现二叉树前中后序遍历
1.递归 1.1 熟悉递归 所有的递归有两个基本特征: 执行时范围不断缩小,这样才能触底反弹。终止判断在调用递归的前面。 写递归的步骤: 从小到大递推。分情况讨论,明确结束条件。组合出完整方法。想验证就从大到小画图推演。 …...
Datawhale Django后端开发入门Task01 Vscode配置环境
首先呢放一张运行成功的截图纪念一下,感谢众多小伙伴的帮助呀,之前没有配置这方面的经验 ,但还是一步一步配置成功了,所以在此以一个纯小白的经验分享如何配置成功。 1.选择要建立项目的文件夹,打开文件找到目标文件夹…...

django部署到centos服务器上
具体的操作步骤 步骤一 更新系统和安装依赖, sudo yum update sudo yum install python3 python3-pip python3-devel git步骤二:创建并激活虚拟环境 在终端中执行以下命令: python3 -m venv myenv source myenv/bin/activate可以不创建虚拟…...
IOS开发-XCode14介绍与入门
IOS开发-XCode14介绍与入门 1. XCODE14的小吐槽2. XCODE的功能bar一览3. XCODE项目配置一览4. XCODE更改DEBUG/RELEASE模式5. XCODE单元测试 1. XCODE14的小吐槽 iOS开发工具一直有个毛病,就是新版本的开发工具的总会有一些奇奇怪怪的bug。比如在我的Mac-Pro&#…...
)
Interactive Marker Publish Pose All the Time (Interactive Marker通过topic一直发送其状态)
以下代码实现了:Interactive Marker通过topic一直发送其状态,而不只是交互时才发送。 几个要点: 通过定时器rospy.Timer实现PublishInteractiveMarkerServer feedback.pose的类型是geometry_msgs/Pose,而不是geometry_msgs/PoseS…...
前后端分离------后端创建笔记(04)前后端对接
本文章转载于【SpringBootVue】全网最简单但实用的前后端分离项目实战笔记 - 前端_大菜007的博客-CSDN博客 仅用于学习和讨论,如有侵权请联系 源码:https://gitee.com/green_vegetables/x-admin-project.git 素材:https://pan.baidu.com/s/…...
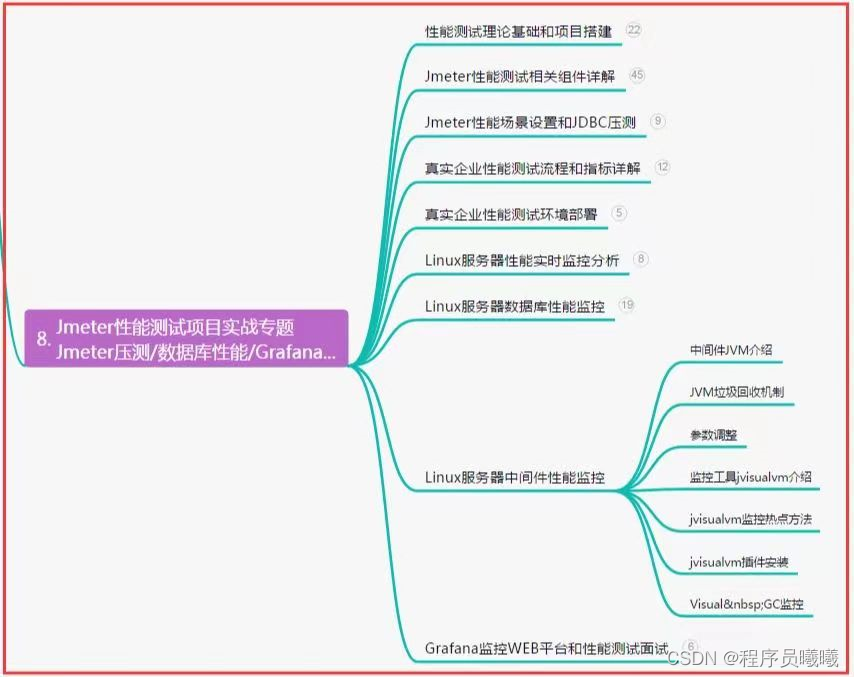
一站式自动化测试平台-Autotestplat
3.1 自动化平台开发方案 3.1.1 功能需求 3.1.3 开发时间计划 如果是刚入门、但有一点代码基础的测试人员,大概 3 个月能做出演示版(Demo)进行自动化测试,6 个月内胜任开展工作中项目的自动化测试。 如果是有自动化测试基础的测试人员,大概 …...

Ansible Service模块,使用 Ansible Service模块进行服务管理
Ansible 是一种自动化工具,它可以简化配置管理、应用程序部署和任务自动化等操作。Ansible 的 Service 模块是其中一个重要的模块,它提供了管理服务的功能,使得在远程主机上启动、停止、重启和重新加载服务变得简单和可靠。本文将介绍 Ansibl…...

共识算法初探
共识机制的背景 加密货币都是去中心化的,去中心化的基础就是P2P节点众多,那么如何吸引用户加入网络成为节点,有那些激励机制?同时,开发的重点是让多个节点维护一个数据库,那么如何决定哪个节点写入&#x…...

Oracle查询表字段名并拼接
在数据库使用中,我们常常需要,获取一张表的全部字段,那该如何查询呢? 查询表字段名 SELECT column_name FROM all_tab_columns WHERE table_name table_name; 只需将引号中的table_name,替换为自己的表名࿰…...
8 张图 | 剖析 Eureka 的首次同步注册表
注册表对于注册中心尤为重要,所有的功能都是围绕这个注册表展开。比如服务 A 要想访问服务 B,就得知道服务 B 的 IP 地址和端口号吧。如下图所示,传统的方式就是服务 A 知道了服务 B 的地址后,发送 HTTP 请求到对应的 API 地址上。…...

github ssh配置
1、生成公钥 用下面的命令生成公钥 ssh-keygen -t rsa -b 4096 -C 邮箱 生成的公钥默认在文件夹 ~/.ssh/ 下的 id_rsa.pub 2、在github配置本地的公钥 先复制本地公钥文件中的内容 cat ~/.ssh/id_rsa.pub 打开github的settings > SSH and GPG keys > new SSH key …...
P2P聊天程序)
基于C#实现(WinForm)P2P聊天程序
♻️ 资源 大小: 29.8MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430269 p2p聊天程序 一、功能介绍 1.1 登录 用户凭用户名和密码登录系统,可以更换服务器 IP 和端口,以防网络不畅通,连接服务…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

昇腾NPU模型服务化——从离线模型到高可用推理服务
模型训练完只是第一步。真正产生业务价值的是把模型部署成724小时在线服务——毫秒级延迟、支持动态Batching、能扛住流量洪峰,且具备高可用性。 这篇将手把手教你基于昇腾NPU构建生产级模型推理服务,涵盖框架选型、服务化架构、动态Batching优化、热加载…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...

如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南
如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南 【免费下载链接】genshin-impact-script 原神脚本,包含自动钓鱼、自动拾取、自动跳过对话等多项实用功能。A Genshin Impact script includes many useful features such as automatic fishing…...

混合物理-ML辐射方案:攻克气候模型中次网格云效应的新范式
1. 项目概述与核心挑战在气候模拟这个庞大的数字沙盘中,地球系统模型(ESM)是我们理解未来气候演变的核心工具。然而,这个沙盘有一个长期存在的“颗粒度”难题:受限于计算资源,模型的水平分辨率通常在100到2…...

视频转PPT终极指南:3分钟自动化提取教学视频中的幻灯片内容
视频转PPT终极指南:3分钟自动化提取教学视频中的幻灯片内容 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 还在为从海量教学视频中手动截取PPT页面而苦恼吗?…...

终极跨平台空洞骑士模组管理器:Lumafly如何让模组管理变得简单高效
终极跨平台空洞骑士模组管理器:Lumafly如何让模组管理变得简单高效 【免费下载链接】Lumafly A cross platform mod manager for Hollow Knight written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/lu/Lumafly 你是否曾经因为空洞骑士模组安装…...