【BERTopic应用 03/3】:微调参数

一、说明
一般来说,BERTopic 在开箱即用的模型中工作得很好。但是,当您有数百万个数据要处理时,使用基本模型处理数据可能需要一些时间。在这篇文章中,我将向您展示如何微调BERTopic中的一些参数并比较它们的结果。让我们潜入。
二、BERTopic 基本型号
我们首先检查类 BERTopic 中有哪些参数。有关详细检查,请查看此处的文件:BERTopic。在官方文档中,对每个参数及其默认值都有说明。在这里,我想挑一些参数来提及,因为这些参数在表示文档中的主题方面起着关键作用。
class BERTopic:def __init__(self,language: str = "english",top_n_words: int = 10,n_gram_range: Tuple[int, int] = (1, 1),min_topic_size: int = 10,nr_topics: Union[int, str] = None,low_memory: bool = False,calculate_probabilities: bool = False,seed_topic_list: List[List[str]] = None,embedding_model=None,umap_model: UMAP = None,hdbscan_model: hdbscan.HDBSCAN = None,vectorizer_model: CountVectorizer = None,ctfidf_model: TfidfTransformer = None,representation_model: BaseRepresentation = None,verbose: bool = False,)self.XXXself.XXX......- n_gram_range:默认为(1,1),即分别产生“新”和“约克”等主题词。如果要显示“纽约”,可以将此参数发送到 (1,2)。
- umap_model:UMAP(均匀流形近似和投影)是一种降维算法,通常用于高维数据的可视化。它的工作原理是查找保留原始高维空间结构的数据的低维表示形式。
- hdbscan_model:HDBSCAN(基于分层密度的带噪声应用程序空间聚类)是一种基于密度的聚类算法,可以识别数据集中任意形状和大小的聚类。它的工作原理是在数据中查找高密度区域并将其扩展为集群,同时还识别不属于任何集群的噪声点。
三、微调参数
我们已经了解了参数是什么以及它们的实际作用。现在,让我们对它们进行微调,并将结果与开箱即用的模型进行比较。同样,我们将使用我们之前准备的卡塔尔世界杯数据。如果您还没有下载 umap 和 hbdscan,请 pip 安装。
# Base Modelimport pandas as pd
import pickle
with open('world_cup_tweets.pkl', 'rb') as f:data = pickle.load(f)data = data.Tweet_processed.to_list()from bertopic import BERTopic
model_B = BERTopic(language="english", calculate_probabilities=True, verbose=True)
topics_B, probs_B = topic_model.fit_transform(data)# Fine-tuned Modelimport pandas as pd
import pickle
with open('world_cup_tweets.pkl', 'rb') as f:data = pickle.load(f)data = data.Tweet_processed.to_list()from umap import UMAP
from hdbscan import HDBSCANumap_model = UMAP(n_neighbors=3, n_components=3, min_dist=0.05)
hdbscan_model = HDBSCAN(min_cluster_size=80, min_samples=40,gen_min_span_tree=True,prediction_data=True)
from bertopic import BERTopicmodel_A = BERTopic(umap_model=umap_model,hdbscan_model=hdbscan_model,top_n_words=10,language='english',calculate_probabilities=True,verbose=True,n_gram_range=(1, 2)
)
topics_A, probs_A = model.fit_transform(data)UMAP:
- n_neighbors=3:此参数确定 UMAP 用于近似数据局部结构的最近邻数。在这种情况下,UMAP将在构造嵌入时查看每个数据点的三个最近邻。
- n_components=3:指定嵌入空间中的维数。默认情况下,UMAP 会将数据的维数减少到 2 维,但在这种情况下,它会将其减少到 3 维。
- min_dist=0.05:此参数控制嵌入空间中点之间的最小距离。较高的min_dist值将导致点之间的空间越大,这可以改善聚类的分离。
HDBSCAN:
- min_cluster_size=80:此参数指定形成聚类所需的最小点数。点少于此阈值的聚类将被标记为噪声。
- min_samples=40:此参数确定将点视为核心点所需的邻域样本数。核心点用于构建聚类,非核心点的点被归类为噪声。
- gen_min_span_tree=True:此参数告诉 HDBSCAN 在聚类之前构造输入数据的最小生成树。这有助于识别仅由几个点连接的聚类,其他聚类算法可能会遗漏这些点。
- prediction_data=True:此参数指示 HDBSCAN 存储有关数据的其他信息,例如每个群集中每个点的成员资格概率。此信息可用于下游分析和可视化。
四、比较结果
基本型号:
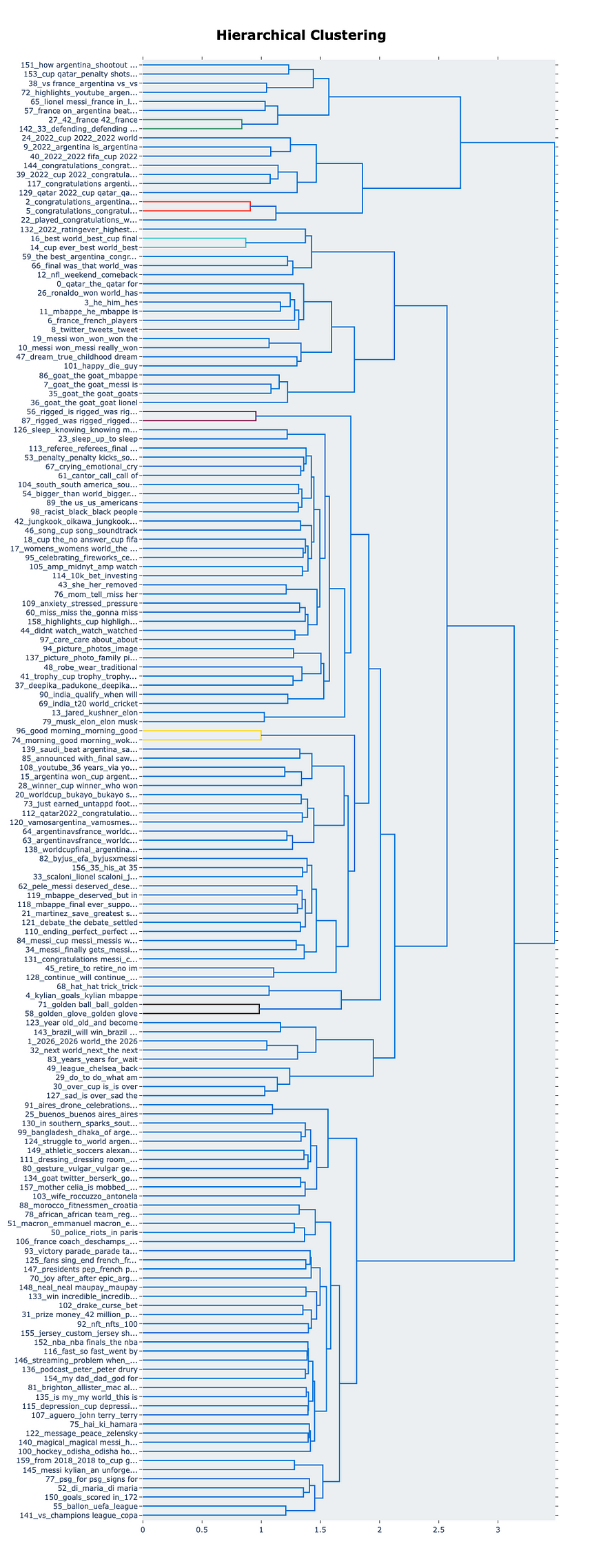
作者创建的基本模型
微调模型:
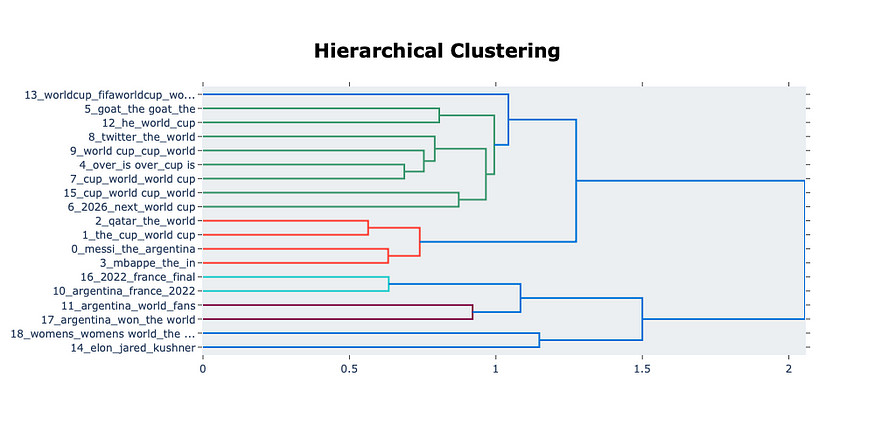
作者创建的微调模型
显然,在基本模型中生成了更多主题,这解释了处理大量文本需要很长时间的事实。同时,在微调模型中,根据参数中的设置创建的主题较少。
对于那些对结果如何随参数设置的不同组合而变化感兴趣的人。我将示例代码放在这里,您可以更改参数以检查不同的结果。
from bertopic import BERTopic
from umap import UMAP
from hdbscan import HDBSCAN# Define a list of parameters to try for UMAP
umap_params = [{'n_neighbors': 15, 'n_components': 2, 'min_dist': 0.1},{'n_neighbors': 10, 'n_components': 2, 'min_dist': 0.01},{'n_neighbors': 3, 'n_components': 2, 'min_dist': 0.001}
]# Define a list of parameters to try for HDBSCAN
hdbscan_params = [{'min_cluster_size': 100, 'min_samples': 100},{'min_cluster_size': 50, 'min_samples': 70},{'min_cluster_size': 5, 'min_samples': 50}
]# Loop over the parameter combinations and fit BERTopic models
for umap_param in umap_params:for hdbscan_param in hdbscan_params:# Create UMAP and HDBSCAN models with the current parameter combinationumap_model = UMAP(**umap_param)hdbscan_model = HDBSCAN(**hdbscan_param, gen_min_span_tree=True, prediction_data=True)# Fit a BERTopic model with the current parameter combinationmodel = BERTopic(umap_model=umap_model,hdbscan_model=hdbscan_model,top_n_words=10,language='english',calculate_probabilities=True,verbose=True,n_gram_range=(1, 2))topics, probs = model.fit_transform(data)# Visualize the hierarchy and save the figure to an HTML filefig = model.visualize_hierarchy()fig.write_html(f'model_umap_{umap_param}_hdbscan_{hdbscan_param}.html')
五、后记
相关文章:
【BERTopic应用 03/3】:微调参数
一、说明 一般来说,BERTopic 在开箱即用的模型中工作得很好。但是,当您有数百万个数据要处理时,使用基本模型处理数据可能需要一些时间。在这篇文章中,我将向您展示如何微调BERTopic中的一些参数并比较它们的结果。让我们潜入。 二…...
2023年上半年数学建模竞赛题目汇总与难度分析
2023年上半年数学建模竞赛题目汇总与难度分析 由于近年来国赛ABC题出题方式漂浮不定,没有太大的定性,目前总体的命题方向为,由之前的单一模型问题变为数据分析评价优化或者预测类题目是B、C题的主要命题方向。为了更好地把握今年命题的主方…...

Linux下搭建java环境
文章目录 一,xshell链接linux二,linux安装jdk环境 一,xshell链接linux 这里用到的工具,VMware搭配CentOS7 64位Xshell5 操作之前确保,传输Xshell连接了虚拟机 打开Xshell,文件->新建 主机ip—>进入虚拟机,右键打开终端,输入命令:ifco…...

String、StringBuffer、StringBuilder三者的异同?
String字符串 不可变的字符序列在 jdk1.8,我们底层用 char [ ] 存储在 jdk 17,我们底层用 byte [ ] 存储 StringBuffer字符串缓冲区类 可变的字符序列,线程安全的(synchronized),效率低在 jdk1.8…...

htmlCSS-----弹性布局案例展示
目录 前言 效果展示 编辑 代码 思路分析 前言 上一期我们学习了弹性布局,那么这一期我们用弹性布局来写一个小案例,下面看代码(上一期链接html&CSS-----弹性布局_灰勒塔德的博客-CSDN博客) 效果展示 代码 html代码&am…...

Fiddler模拟请求发送和修改响应数据
fiddler模拟伪造请求 方法一:打断点模拟HTTP请求 1、浏览器页面填好内容后(不要操作提交),打开fiddler,设置请求前断点,点击菜单fiddler,”Rules”\”Automatic Breakpoints”\”Before Requests” 2、在…...

RH850从0搭建Autosar开发环境【23】- Davinci Configurator之DCM实操实现DID的读取写入
配置DID 一、Developer中创建SWC1.1 创建Application Component Type1.2 实例化Component二、在SWC中创建接口以及Runnable2.1 创建DID的Service Ports2.2 创建DID的Service Runnable三、在Configurator连接接口以及生成代码3.1 连接DCM与SWC3.2 生成RTE3.3 生成SWC的DID的模板…...
ChatGPT收录
VSCode插件-ChatGPT 多磨助手 多磨助手 (domore.run) Steamship Steamship 免费合集 免费chatGPT - Ant Design Pro 免费AI聊天室 (xyys.one)...

Nginx随笔
Nginx下载链接 安装命令: apt update apt install nginx 一、基础命令(Ubuntu) 1、在全局 nginx -t //检查Nginx的配置文件是否有错 systemctl start nginx //启动Nginx systemctl stop nginx //停止Nginx systemctl status nginx //查…...
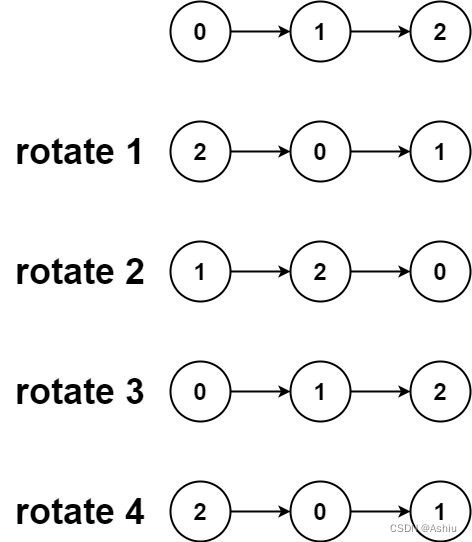
61. 旋转链表
61. 旋转链表 题目-中等难度示例1. 快慢指针找到分割位置2. 连成环后截断 题目-中等难度 相关企业 给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。 示例 示例 1: 输入:head [1,2,3,4,5], k 2 输出…...

Python实现动态调用Matlab自定义函数
首先需要下载与python版本对应的matlab,并成功执行matlab中的setup.py文件 参考流程如下 https://blog.csdn.net/s1k9y9/article/details/127793053 完成上述步骤即可开始实现动态调用matlab文件。 文件目录如下 D://call/ |–matlab |–test1 |–main.m |–test2 |…...

redis集群和分片-Redis Cluster:分布式环境中的数据分片、主从复制和 Sentinel 哨兵
当涉及到 Redis 中的集群、分片、主从复制和 Sentinel 哨兵时,这些是构建分布式 Redis 环境中非常重要的概念和组件。下面详细介绍这些概念以及它们在分布式环境中的作用。 Redis Cluster Redis Cluster 是 Redis 官方提供的分布式解决方案,用于管理和…...
【数据库基础】Mysql下载安装及配置
下载 下载地址:https://downloads.mysql.com/archives/community/ 当前最新版本为 8.0版本,可以在Product Version中选择指定版本,在Operating System中选择安装平台,如下 安装 MySQL安装文件分两种 .msi和.zip [外链图片转存失…...

iptables安全与防火墙
防火墙 防火墙主要作用是隔离功能,它是部署在网络边缘或主机边缘;另外在生产中防火墙的主要作用是:决定哪些数据可以被外网访问以及哪些数据可以进入内网访问;顾名思义防火墙处于TCP协议中的网络层。 防火墙分类: 软…...

Linux 内核线程启动以及内核调用应用层程序
#include <linux/kthread.h> //内核线程头文件 static task_struct *test_task; test_task kthread_run(thread_function, NULL, "test_thread_name"); if(IS_ERR(test_task)) { pr_err("test_thread_name create fail\n"); } static int th…...
React+Typescript清理项目环境
上文 创建一个 ReactTypescript 项目 我们创建出了一个 React配合Ts开发的项目环境 那么 本文 我们先将环境清理感觉 方便后续开发 我们先来聊一下React的一个目录结构 跟我们之前开发的React项目还是有一些区别 public 主要是存放一些静态资源文件 例如 html 图片 icon之类的 …...

【linux学习】linux的模块机制
文章目录 前言模块的Hello World! 前言 Linux允许用户通过插入模块,实现干预内核的目的。一直以来,对linux的模块机制都不够清晰,因此本文对内核模块的加载机制进行简单地分析。 ref:https://www.cnblogs.com/fanzhidongyzby/p/…...

用 oneAPI 实现 AI 欺诈检测:一款智能图像识别工具
简介 虚假图像和视频日益成为社交媒体、新闻报道以及在线内容中的一大隐患。在这个信息爆炸的时代,如何准确地识别和应对这些虚假内容已经成为一个迫切的问题。为了帮助用户更好地辨别虚假内容,我开发了一款基于 oneAPI、TensorFlow 和 Neural Compress…...

云计算的发展前景怎么样
云计算是当前科技领域中最受关注的领域之一,它的出现改变了传统的计算模式,使得企业和个人能够更加便捷地访问和使用计算资源。随着云计算技术的不断发展,它的前景也变得更加光明。 以下是云计算的发展前景: 云计算的市场份额将继续增长:根据市场研究机构的报告,云计算的市场份…...
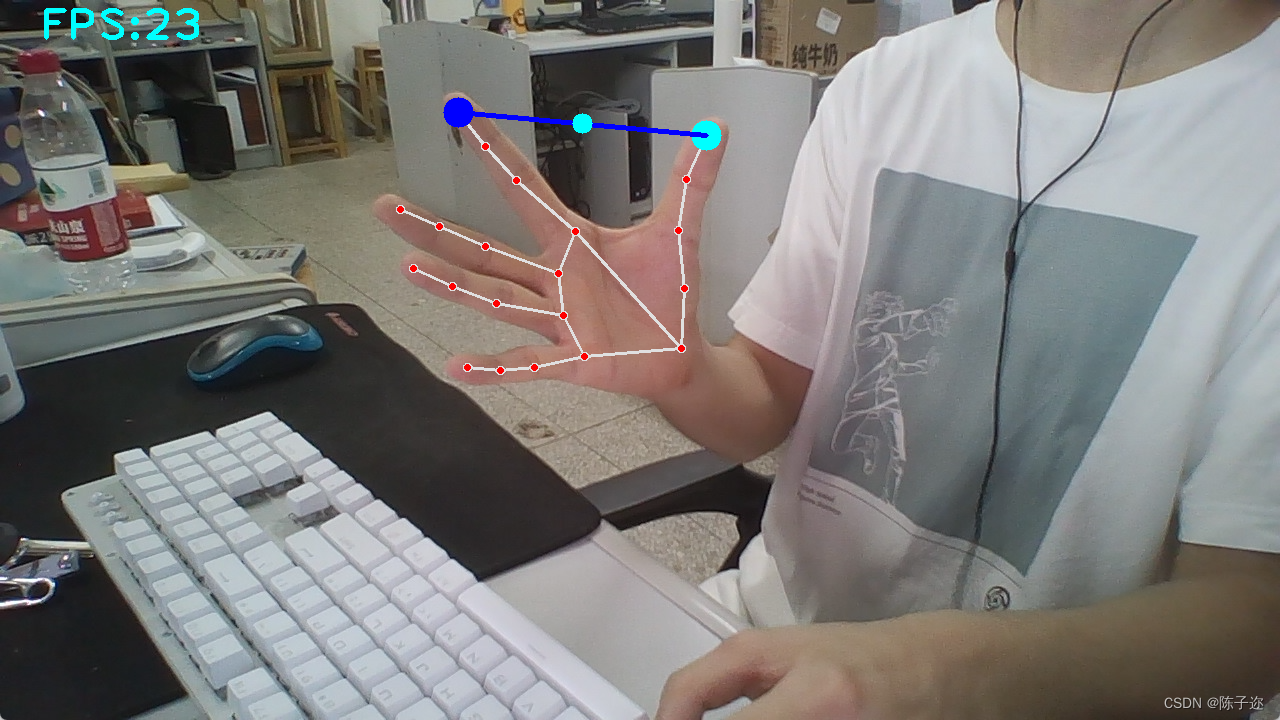
opencv实战项目 手势识别-手势音量控制(opencv)
本项目是使用了谷歌开源的框架mediapipe,里面有非常多的模型提供给我们使用,例如面部检测,身体检测,手部检测等。 手势识别系列文章 1.opencv实现手部追踪(定位手部关键点) 2.opencv实战项目 实现手势跟踪…...

机器学习模型评估避坑指南:过调优与数据泄露的识别与防范
1. 项目概述与核心问题界定在机器学习项目的落地过程中,超参数调优几乎是每个从业者都会经历的环节。我们花费大量时间,尝试各种搜索策略——从网格搜索到贝叶斯优化,目标很明确:让模型在验证集上的指标再好看那么一点点。然而&am…...

实战揭秘:3步解锁你的微信聊天记忆宝库
实战揭秘:3步解锁你的微信聊天记忆宝库 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 你是否曾因为手机丢失或更换设备,眼睁睁看着珍贵的微信聊天记录消失无踪?那些承…...

射电天文数据处理:致密源扣除与系统误差量化实战指南
1. 项目概述:从宇宙网节点探测说起在射电天文学领域,我们常常扮演宇宙的“收音机”调谐师,试图从充满噪声的宇宙背景中,分离出那些微弱却至关重要的天体物理信号。最近,一项关于宇宙网节点射电辐射的研究,再…...
)
别再只用top了!用nload实时监控Linux服务器网卡流量(CentOS 7/8安装配置详解)
别再只用top了!用nload实时监控Linux服务器网卡流量(CentOS 7/8安装配置详解)在Linux服务器运维中,网络流量监控是日常工作的核心环节。许多管理员习惯使用top或iftop等工具,但这些工具要么缺乏直观的流量可视化&#…...

CSS Animations实战指南:打造流畅的用户体验
CSS Animations实战指南:打造流畅的用户体验 引言 CSS Animations是创建流畅动画效果的强大工具,无需JavaScript即可实现丰富的视觉效果。本文将深入探讨CSS动画的核心概念、实用技巧和最佳实践。 一、CSS动画基础 1.1 keyframes定义动画 keyframes slid…...

Z变换与数字滤波器设计:从零极点分析到Python实战
1. 从理论到代码:Z变换如何成为数字信号处理的“瑞士军刀”如果你刚开始接触数字信号处理,可能会觉得Z变换是个有点抽象的数学工具。但在我十多年的音频算法和通信系统开发经历里,Z变换远不止是教科书上的公式——它是我们设计、分析和调试数…...

RTX51实时系统任务抢占与邮箱机制深度解析
1. RTX51实时系统中的任务抢占与邮箱机制解析在嵌入式实时操作系统领域,任务间通信与优先级调度是核心机制。RTX51作为Keil C51开发环境中的经典实时内核,其抢占行为与邮箱通信的交互方式直接影响系统实时性表现。本文将深入剖析当低优先级任务向高优先级…...
)
别光背公式了!用Python的NumPy和SciPy手把手带你玩转SVD(附实战代码与可视化)
别光背公式了!用Python的NumPy和SciPy手把手带你玩转SVD(附实战代码与可视化)在数据科学和机器学习领域,奇异值分解(SVD)就像一把瑞士军刀——它可能不是你每天都会用到的工具,但当遇到棘手问题…...

大语言模型作为人类行为研究工具:从原理到实践
1. 从“模仿”到“理解”:AI研究范式的悄然转向最近和几位做社会学和心理学研究的朋友聊天,发现一个挺有意思的现象:他们实验室的电脑屏幕上,除了SPSS、R语言的分析窗口,越来越多地出现了像ChatGPT、Claude这样的对话界…...
)
【2024播客降本增效终极方案】:单人团队如何用开源TTS实现月产60期高保真节目(附实测MOS分对比表)
更多请点击: https://codechina.net 第一章:AI语音合成在播客制作中的应用 AI语音合成技术正深刻重塑播客内容的生产流程,从脚本转语音、多角色配音到个性化音色定制,已实现端到端自动化与高质量听感的统一。相比传统录音方式&am…...