Java8 Stream 之groupingBy 分组讲解
本文主要讲解:Java 8 Stream之Collectors.groupingBy()分组示例
Collectors.groupingBy() 分组之常见用法
功能代码:
/**
* 使用java8 stream groupingBy操作,按城市分组list
*/
public void groupingByCity() {
Map<String, List<Employee>> map = employees.stream().collect(Collectors.groupingBy(Employee::getCity));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
Collectors.groupingBy() 分组之统计每个分组的count
功能代码:
/**
* 使用java8 stream groupingBy操作,按城市分组list统计count
*/
public void groupingByCount() {
Map<String, Long> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getCity, Collectors.counting()));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
Collectors.groupingBy() 分组之统计分组平均值
功能代码:
/**
* 使用java8 stream groupingBy操作,按城市分组list并计算分组年龄平均值
*/
public void groupingByAverage() {
Map<String, Double> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getCity, Collectors.averagingInt(Employee::getAge)));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
Collectors.groupingBy() 分组之统计分组总值
功能代码:
/**
* 使用java8 stream groupingBy操作,按城市分组list并计算分组销售总值
*/
public void groupingBySum() {
Map<String, Long> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getCity, Collectors.summingLong(Employee::getAmount)));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
// 对Map按照分组销售总值逆序排序
Map<String, Long> sortedMap = new LinkedHashMap<>();
map.entrySet().stream().sorted(Map.Entry.<String, Long> comparingByValue().reversed())
.forEachOrdered(e -> sortedMap.put(e.getKey(), e.getValue()));
sortedMap.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
Collectors.groupingBy() 分组之Join分组List
功能代码:
/**
* 使用java8 stream groupingBy操作,按城市分组list并通过join操作连接分组list中的对象的name 属性使用逗号分隔
*/
public void groupingByString() {
Map<String, String> map = employees.stream().collect(Collectors.groupingBy(Employee::getCity,
Collectors.mapping(Employee::getName, Collectors.joining(", ", "Names: [", "]"))));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
Collectors.groupingBy() 分组之转换分组结果List -> List
功能代码:
/**
* 使用java8 stream groupingBy操作,按城市分组list,将List转化为name的List
*/
public void groupingByList() {
Map<String, List<String>> map = employees.stream().collect(
Collectors.groupingBy(Employee::getCity, Collectors.mapping(Employee::getName, Collectors.toList())));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
v.stream().forEach(item -> {
System.out.println("item = " + item);
});
});
}
Collectors.groupingBy() 分组之转换分组结果List -> Set
功能代码:
/**
* 使用java8 stream groupingBy操作,按城市分组list,将List转化为name的Set
*/
public void groupingBySet() {
Map<String, Set<String>> map = employees.stream().collect(
Collectors.groupingBy(Employee::getCity, Collectors.mapping(Employee::getName, Collectors.toSet())));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
v.stream().forEach(item -> {
System.out.println("item = " + item);
});
});
}
Collectors.groupingBy() 分组之使用对象分组List
功能代码:
/**
* 使用java8 stream groupingBy操作,通过Object对象的成员分组List
*/
public void groupingByObject() {
Map<Manage, List<Employee>> map = employees.stream().collect(Collectors.groupingBy(item -> {
return new Manage(item.getName());
}));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
Collectors.groupingBy() 分组之使用两个成员分组List
功能代码:
/**
* 使用java8 stream groupingBy操作, 基于city 和name 实现多次分组
*/
public void groupingBys() {
Map<String, Map<String, List<Employee>>> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getCity, Collectors.groupingBy(Employee::getName)));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
v.forEach((i, j) -> {
System.out.println(i + " = " + j);
});
});
}
自定义Distinct对结果去重
功能代码
/**
* 使用java8 stream groupingBy操作, 基于Distinct 去重数据
*/
public void groupingByDistinct() {
List<Employee> list = employees.stream().filter(distinctByKey(Employee :: getCity))
.collect(Collectors.toList());;
list.stream().forEach(item->{
System.out.println("city = " + item.getCity());
});
}
/**
* 自定义重复key 规则
* @param keyExtractor
* @return
*/
private static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {
Set<Object> seen = ConcurrentHashMap.newKeySet();
return t -> seen.add(keyExtractor.apply(t));
}
完整源代码:
package com.stream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
import java.util.function.Function;
import java.util.function.Predicate;
import java.util.stream.Collectors;
/**
* Java 8 Stream 之groupingBy 分组讲解
*
* @author zzg
*
*/
public class Java8GroupBy {
List<Employee> employees = new ArrayList<Employee>();
/**
* 数据初始化
*/
public void init() {
List<String> citys = Arrays.asList("湖南", "湖北", "江西", "广西 ");
for (int i = 0; i < 10; i++) {
Random random = new Random();
Integer index = random.nextInt(4);
Employee employee = new Employee(citys.get(index), "姓名" + i, (random.nextInt(4) * 10 - random.nextInt(4)),
(random.nextInt(4) * 1000 - random.nextInt(4)));
employees.add(employee);
}
}
/**
* 使用java8 stream groupingBy操作,按城市分组list
*/
public void groupingByCity() {
Map<String, List<Employee>> map = employees.stream().collect(Collectors.groupingBy(Employee::getCity));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
/**
* 使用java8 stream groupingBy操作,按城市分组list统计count
*/
public void groupingByCount() {
Map<String, Long> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getCity, Collectors.counting()));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
/**
* 使用java8 stream groupingBy操作,按城市分组list并计算分组年龄平均值
*/
public void groupingByAverage() {
Map<String, Double> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getCity, Collectors.averagingInt(Employee::getAge)));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
/**
* 使用java8 stream groupingBy操作,按城市分组list并计算分组销售总值
*/
public void groupingBySum() {
Map<String, Long> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getCity, Collectors.summingLong(Employee::getAmount)));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
// 对Map按照分组销售总值逆序排序
Map<String, Long> sortedMap = new LinkedHashMap<>();
map.entrySet().stream().sorted(Map.Entry.<String, Long> comparingByValue().reversed())
.forEachOrdered(e -> sortedMap.put(e.getKey(), e.getValue()));
sortedMap.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
/**
* 使用java8 stream groupingBy操作,按城市分组list并通过join操作连接分组list中的对象的name 属性使用逗号分隔
*/
public void groupingByString() {
Map<String, String> map = employees.stream().collect(Collectors.groupingBy(Employee::getCity,
Collectors.mapping(Employee::getName, Collectors.joining(", ", "Names: [", "]"))));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
/**
* 使用java8 stream groupingBy操作,按城市分组list,将List转化为name的List
*/
public void groupingByList() {
Map<String, List<String>> map = employees.stream().collect(
Collectors.groupingBy(Employee::getCity, Collectors.mapping(Employee::getName, Collectors.toList())));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
v.stream().forEach(item -> {
System.out.println("item = " + item);
});
});
}
/**
* 使用java8 stream groupingBy操作,按城市分组list,将List转化为name的Set
*/
public void groupingBySet() {
Map<String, Set<String>> map = employees.stream().collect(
Collectors.groupingBy(Employee::getCity, Collectors.mapping(Employee::getName, Collectors.toSet())));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
v.stream().forEach(item -> {
System.out.println("item = " + item);
});
});
}
/**
* 使用java8 stream groupingBy操作,通过Object对象的成员分组List
*/
public void groupingByObject() {
Map<Manage, List<Employee>> map = employees.stream().collect(Collectors.groupingBy(item -> {
return new Manage(item.getName());
}));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
/**
* 使用java8 stream groupingBy操作, 基于city 和name 实现多次分组
*/
public void groupingBys() {
Map<String, Map<String, List<Employee>>> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getCity, Collectors.groupingBy(Employee::getName)));
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
v.forEach((i, j) -> {
System.out.println(i + " = " + j);
});
});
}
/**
* 使用java8 stream groupingBy操作, 基于Distinct 去重数据
*/
public void groupingByDistinct() {
List<Employee> list = employees.stream().filter(distinctByKey(Employee :: getCity))
.collect(Collectors.toList());;
list.stream().forEach(item->{
System.out.println("city = " + item.getCity());
});
}
/**
* 自定义重复key 规则
* @param keyExtractor
* @return
*/
private static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {
Set<Object> seen = ConcurrentHashMap.newKeySet();
return t -> seen.add(keyExtractor.apply(t));
}
public static void main(String[] args) {
// TODO Auto-generated method stub
Java8GroupBy instance = new Java8GroupBy();
instance.init();
instance.groupingByCity();
instance.groupingByCount();
instance.groupingByAverage();
instance.groupingBySum();
instance.groupingByString();
instance.groupingByList();
instance.groupingBySet();
instance.groupingByObject();
instance.groupingBys();
instance.groupingByDistinct();
}
class Employee {
private String city;
private String name;
private Integer age;
private Integer amount;
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getAmount() {
return amount;
}
public void setAmount(Integer amount) {
this.amount = amount;
}
public Employee(String city, String name, Integer age, Integer amount) {
super();
this.city = city;
this.name = name;
this.age = age;
this.amount = amount;
}
public Employee() {
super();
}
}
class Manage {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Manage(String name) {
super();
this.name = name;
}
public Manage() {
super();
}
}
}
github 地址: 待补全
本文参考:
————————————————
版权声明:本文为CSDN博主「在奋斗的大道」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhouzhiwengang/article/details/112319054
相关文章:

Java8 Stream 之groupingBy 分组讲解
本文主要讲解:Java 8 Stream之Collectors.groupingBy()分组示例 Collectors.groupingBy() 分组之常见用法 功能代码: /** * 使用java8 stream groupingBy操作,按城市分组list */ public void groupingByCity() { Map<String, List<Em…...

优哲SSD大文件写性能测试
SDD磁盘性能测试: 空盘: 大文件读,写,读写(4/6)性能测试,删除性能测试,N进程,N线程 小文件读,写,读写(4/6)性能测试&am…...

Python基础教程: json序列化详细用法介绍
前言 嗨喽,大家好呀~这里是爱看美女的茜茜呐 Python内置的json模块提供了非常完善的对象到JSON格式的转换。 废话不多说,我们先看看如何把Python对象变成一个JSON: d dict(nameKaven, age17, sexMale) print(json.dumps(d)) # {"na…...

一张图看懂 USDT三种类型地址 Omni、ERC20、TRC20的区别
USDT是当前实用最广泛,市值最高的稳定币,它是中心化的公司Tether发行的。在今年的4月17日之前,市场上存在着2种不同类型的USDT。4月17日又多了一种波场TRC20协议发行的USDT,它们各自有什么区别呢?哪个转账最快到账?哪…...
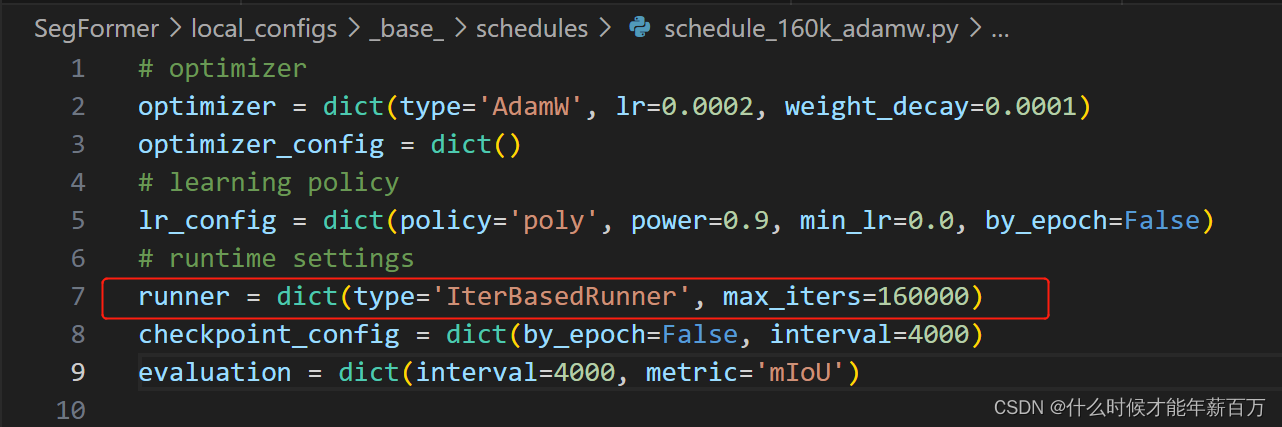
SegFormer之模型训练
单卡训练,所有配置文件里的【SyncBN】改为【BN】 启动训练 (1)终端直接运行 python tools/train.py local_configs/segformer/B1/segformer.b1.512x512.ade.160k.py (2)在编辑器中运行 在 [config] 前面加上’–‘将…...
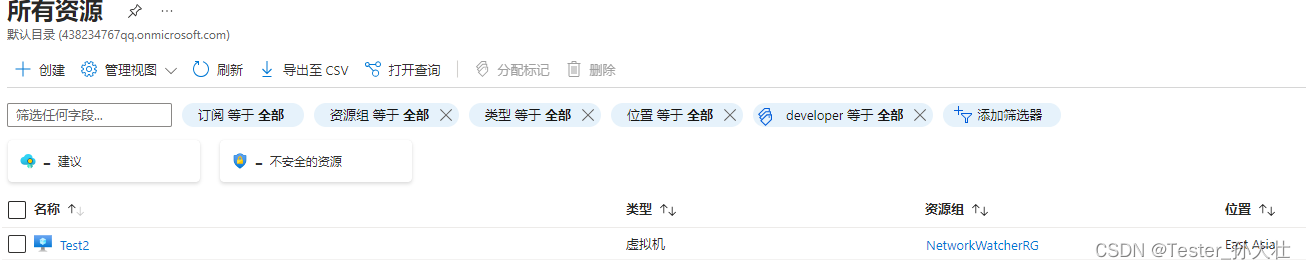
Azure资源命名和标记决策指南
参考 azure创建虚拟机在虚拟机中选择编辑标签,并添加标记,点击应用 3.到主页中转到所有资源 4. 添加筛选器并应用 5.查看结果,筛选根据给服务器定义的标签筛选出结果。 参考链接: https://learn.microsoft.com/zh-cn/azure/cloud-adoption…...

【在一个升序数组中插入一个数仍升序输出】
在一个升序数组中插入一个数仍升序输出 题目举例: 有一个升序数组nums,给一个数字data,将data插入数组nums中仍旧保证nums升序,返回数组中有效元素个数。 比如:nums[100] {1, 2, 3, 5, 6, 7, 8, 9} size 8 data 4 …...

图像去雨、去雪、去雾论文学习记录
All_in_One_Bad_Weather_Removal_Using_Architectural_Search 这篇论文发表于CVPR2020,提出一种可以应对多种恶劣天气的去噪模型,可以同时进行去雨、去雪、去雾操作。但该部分代码似乎没有开源。 提出的问题: 当下的模型只能针对一种恶劣天气…...
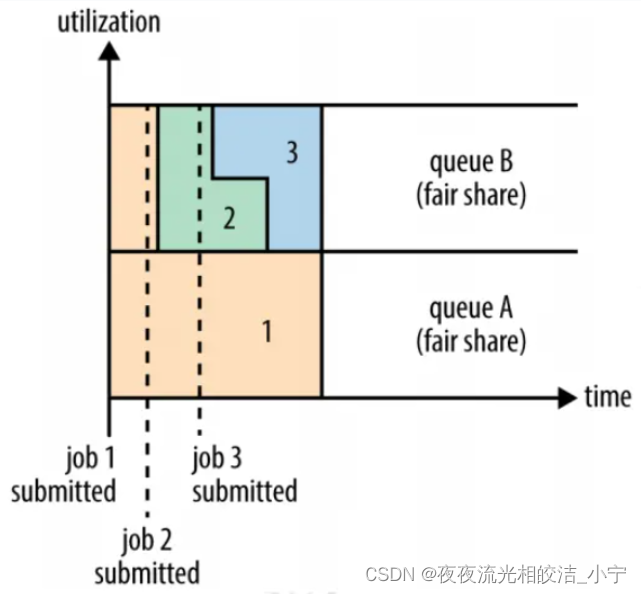
YARN框架和其工作原理流程介绍
目录 一、YARN简介 二、YARN的由来 三、YARN的基本设计思想 四、YARN 的基本架构 4.1 基本架构图 4.2 基本组件介绍 4.2.1 ResourceManager 4.2.1.1 任务调度器(Resource Scheduler) 4.2.1.2 应用程序管理器(Applications Manager) 4.2.1.3 其他…...

多维时序 | MATLAB实现ZOA-CNN-BiGRU-Attention多变量时间序列预测
多维时序 | MATLAB实现ZOA-CNN-BiGRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现ZOA-CNN-BiGRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.Matlab基于ZOA-CNN-BiGRU-Attention斑马优化卷积双向门控循环单元网络…...

centos上下载redis
1.redis 特点 Redis特性(8个) 1 速度快:10w ops(每秒10w读写),数据存在内存中,c语言实现,单线程模型 2 持久化:rdb和aof 3 多种数据结构: 5大数据结构 …...
)
黑马项目一阶段面试58题 Web14题(二)
八、内连接和外连接查询有什么区别 内连接 获取两表的交集部分 外连接 获取某表的所有数据,以及两表的交集数据 九、事务管理的作用,四大特性 作用 保证多个增删改的操作,要么同时成功,要么同时失败 四大特性 1.原子性 事…...

软考高项-思维导图34-36(计算机高级系统项目管理师)
陆续更新一些软考高项的思维导图,都是一些必背知识点,希望可以帮助大家早日考过高项,早日当上高工,早日成为杭州E类人才。全部完整导图快速获取链接:计算机高级系统项目管理师-思维导图汇总 三十四、需求按层次分 三十…...

C++的stack和queue+优先队列
文章目录 什么是容器适配器底层逻辑为什么选择deque作为stack和queue的底层默认容器优先队列优先队列的模拟实现stack和queue的模拟实现 什么是容器适配器 适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总 结),…...

Ubuntu 18.04.6 Android Studio Giraffe adb logcat 无法使用
在 Ubuntu 18.04.6 上 在链接上设备以后,发现可以用 Android Studio 安装应用 但无法用 Android Studio 看 logcat 手动从命令行停止,启动 adb 会报错如下: daemon not running. starting it now on port 5037 ADB server didnt ACK fail…...

Python采集天气数据,做可视化分析【附源码】
嗨害大家好鸭!我是小熊猫~ 毕业设计大家着急吗? 没事,我来替大家着急 源码、素材python永久安装包:点击此处跳转文末名片获取 本文知识点: 动态数据抓包 requests发送请求 结构化非结构化数据解析 开发环境: python 3.8 运行代码 pycharm 2…...
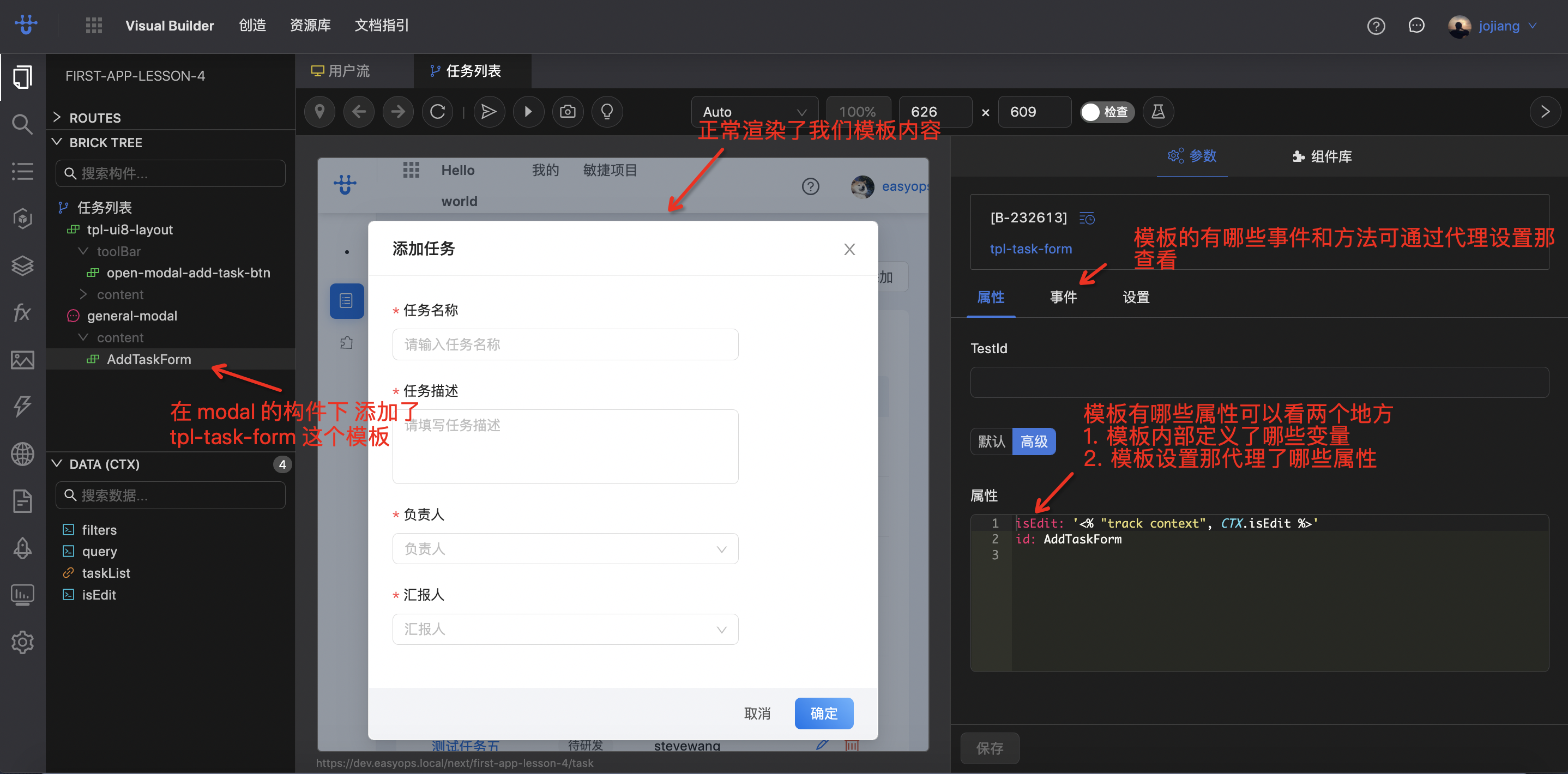
优维低代码实践:自定义模板
优维低代码技术专栏,是一个全新的、技术为主的专栏,由优维技术委员会成员执笔,基于优维7年低代码技术研发及运维成果,主要介绍低代码相关的技术原理及架构逻辑,目的是给广大运维人提供一个技术交流与学习的平台。 优维…...
电商3D产品渲染简明教程
3D 渲染让动作电影看起来更酷,让建筑设计变得栩栩如生,现在还可以帮助营销人员推广他们的产品。 从最新的《阿凡达》电影到 Spotify 的上一次营销活动,3D 的应用让一切变得更加美好。 在营销领域,3D 产品渲染可帮助品牌创建产品的…...

探索未来:元宇宙与Web3的无限可能
随着科技的奇迹般发展,互联网已经成为了我们生活的不可分割的一部分。然而,尽管它的便利性和普及性带来了巨大的影响,但我们仍然面临着传统互联网体验的诸多限制。 购物需要不断在实体店与电商平台间切换,教育依然受制于时间与地…...
登录态校验Directive)
GraphQL(六)登录态校验Directive
GraphQL Directive(指令)是GraphQL中的一种特殊类型,它允许开发者在GraphQL schema中添加元数据,以控制查询和解析操作的行为 Directive的详细说明及使用可见GraphQL(五)指令[Directive]详解 本文将介绍通过…...

HsMod深度解析:基于BepInEx的炉石传说全方位模改进阶指南
HsMod深度解析:基于BepInEx的炉石传说全方位模改进阶指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod 你是否厌倦了炉石传说中繁琐的动画等待?是否渴望更高效的游…...

在微服务架构中集成Taotoken实现智能客服路由与成本控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在微服务架构中集成Taotoken实现智能客服路由与成本控制 1. 场景与挑战 在电商这类业务场景中,智能客服能力通常被拆分…...

王小川All in医疗大模型:从通用赛道抽身,“造AI医生”能否突围?
All in医疗有它的代价一年前,王小川带着百川智能大幅缩减通用模型团队,关闭多条行业线,All in医疗大模型。当时整个大模型行业热闹非凡,平均3天就有一个新版本的通用大模型面世。而百川在5月22日交出答卷,发布新医疗大…...

迷拟极速飞车——极致竞速新体验,重塑线下轻娱新标杆
随着国内文旅休闲、商业游乐行业的快速发展,消费者的线下娱乐审美与体验标准持续升级。传统游乐项目模式固化、玩法单一,同质化问题愈发突出,千篇一律的休闲设施早已无法满足全年龄段游客的多元化游玩需求。无论是城市商业综合体、城郊文旅景…...

Unity热更新本质与分层设计原理
1. 热更新不是“打补丁”,而是游戏生命周期的呼吸系统很多人第一次听说“Unity热更新”,脑子里立刻蹦出一个画面:玩家正在打Boss,突然弹出“检测到新版本,正在后台下载……3秒后重启生效”。然后下意识觉得——这不就是…...

PDF补丁丁文本替换功能深度解析:从基础操作到高级自动化
PDF补丁丁文本替换功能深度解析:从基础操作到高级自动化 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https://…...

TPT线下工作坊:AIGC、云原生与数据合规的深度实践与碰撞
1. 活动缘起与核心价值:为什么一场线下工作坊如此重要?在数字营销和内容创作领域,我们每天都被海量的线上信息包围。线上会议、直播、社群讨论,这些形式高效且便捷,但总感觉隔着一层屏幕,少了些温度与深度。…...

Cursor Free VIP终极指南:5步轻松实现AI编程助手永久免费使用
Cursor Free VIP终极指南:5步轻松实现AI编程助手永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached y…...

PyTorch RMSprop优化器报错怎么办?教你一招避坑
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 PyTorch RMSprop优化器报错深度解析:一招解决常见陷阱目录PyTorch RMSprop优化器报错深度解析:一招解决常…...

极速净化Windows 11:Win11Debloat一键释放系统潜能
极速净化Windows 11:Win11Debloat一键释放系统潜能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custo…...