InnoDB引擎
1 逻辑存储结构
InnoDB的逻辑存储结构如下图所示:
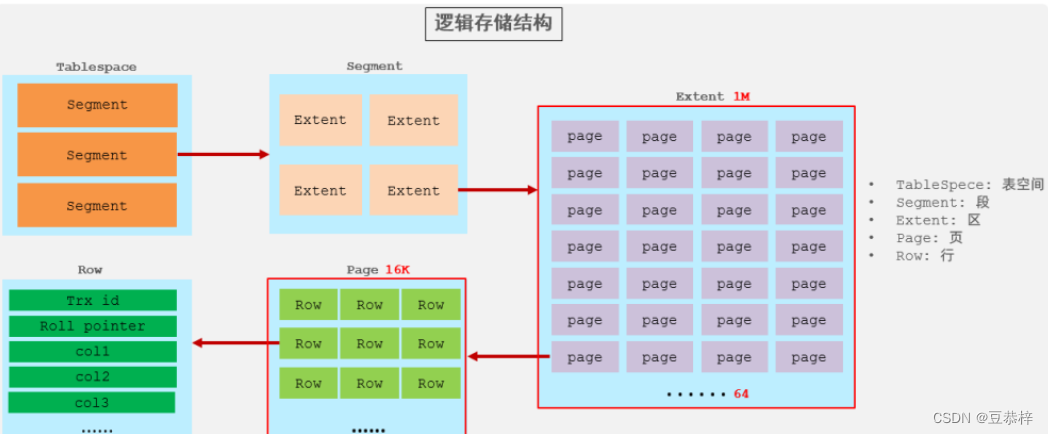
1). 表空间
表空间是InnoDB存储引擎逻辑结构的最高层, 如果用户启用了参数 innodb_file_per_table(在8.0版本中默认开启) ,则每张表都会有一个表空间(xxx.ibd),一个mysql实例可以对应多个表空 间,用于存储记录、索引等数据。
2). 段
段,分为数据段(Leaf node segment)、索引段(Non-leaf node segment)、回滚段 (Rollback segment),InnoDB是索引组织表,数据段就是B+树的叶子节点, 索引段即为B+树的 非叶子节点。段用来管理多个Extent(区)。
3). 区
区,表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一 个区中一共有64个连续的页。
4)页
页,是InnoDB 存储引擎 磁盘管理的最小单元,每个页的大小默认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。
5). 行
行,InnoDB 存储引擎数据是按行进行存放的。 在行中,默认有两个隐藏字段:
Trx_id:每次对某条记录进行改动时,都会把对应的事务id赋值给trx_id隐藏列。
Roll_pointer:每次对某条引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
2 架构
2.1 概述
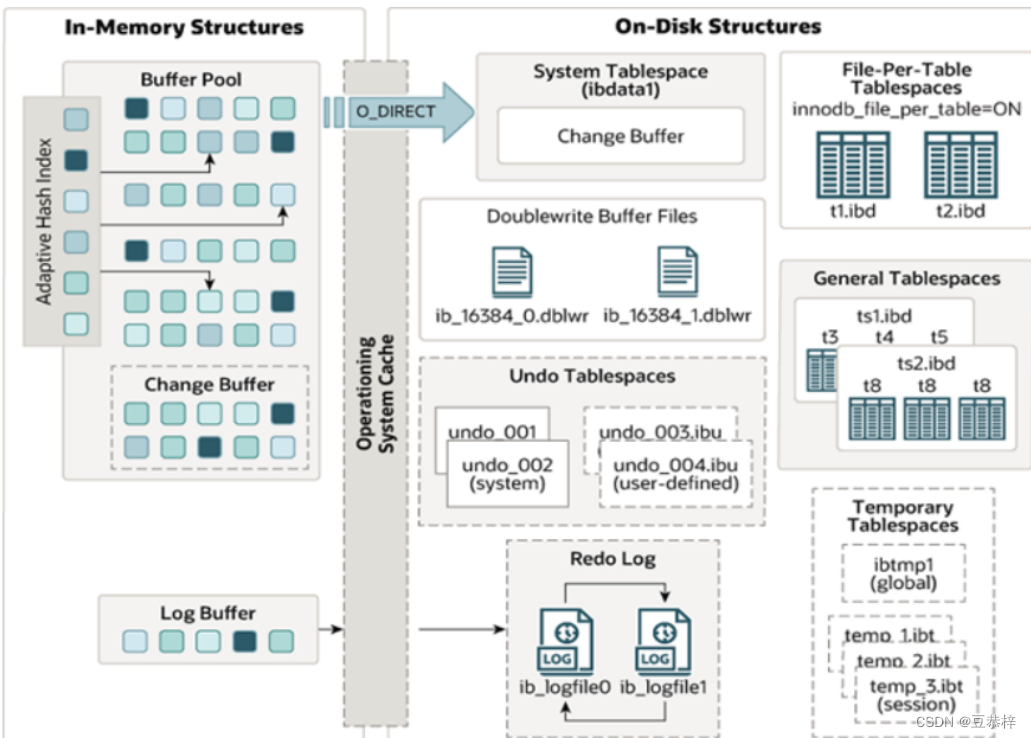
MySQL5.5 版本开始,默认使用InnoDB存储引擎,它擅长事务处理,具有崩溃恢复特性,在日常开发 中使用非常广泛。下面是InnoDB架构图,左侧为内存结构,右侧为磁盘结构。
2.2 内存结构
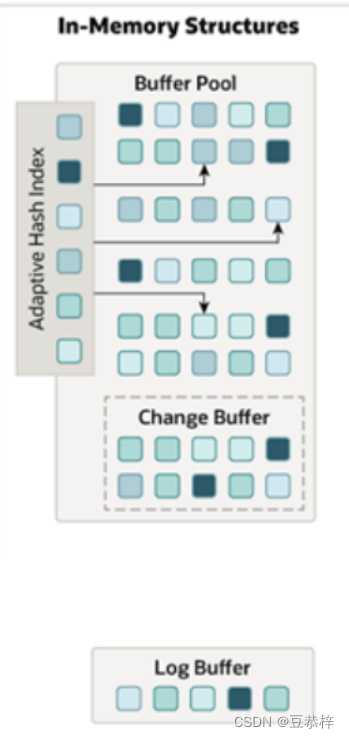
在左侧的内存结构中,主要分为这么四大块儿:
-
Buffer Pool、
-
Change Buffer、
-
Adaptive Hash Index、
-
Log Buffer。
接下来介绍一下这四个部分。
1). Buffer Pool (缓冲池)
InnoDB存储引擎基于磁盘文件存储,访问物理硬盘和在内存中进行访问,速度相差很大,为了尽可能 弥补这两者之间的I/O效率的差值,就需要把经常使用的数据加载到缓冲池中,避免每次访问都进行磁 盘I/O。 在InnoDB的缓冲池中不仅缓存了索引页和数据页,还包含了undo页、插入缓存、自适应哈希索引以及InnoDB的锁信息等等。
缓冲池 Buffer Pool,是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增 删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
缓冲池以Page页为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三种类型:
• free page:空闲page,未被使用。
• clean page:被使用page,数据没有被修改过。
• dirty page:脏页,被使用page,数据被修改过,也中数据与磁盘的数据产生了不一致。
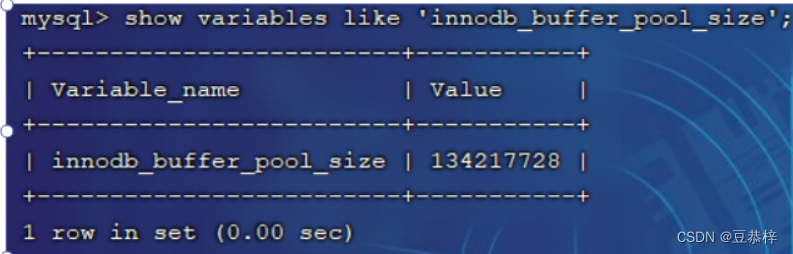
在专用服务器上,通常将多达80%的物理内存分配给缓冲池 。
参数设置: show variables like ‘innodb_buffer_pool_size’;
2). Change Buffer (更改缓冲区)
更改缓冲区(针对于非唯一二级索引页),在执行DML语句时,如果这些数据Page
没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存在更改缓冲区 Change Buffer 中,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。
Change Buffer的意义是什么呢?
先来看一幅图,这个是二级索引的结构图:
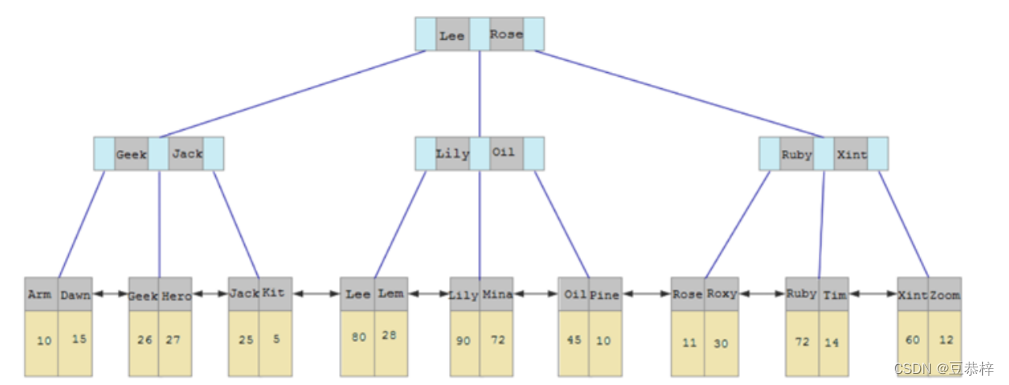
与聚集索引不同,二级索引通常是非唯一的,并且以相对随机的顺序插入二级索引。同样,删除和更新 可能会影响索引树中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了ChangeBuffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
3). Adaptive Hash Index
自适应hash索引,用于优化对Buffer Pool数据的查询。MySQL的innoDB引擎中虽然没有直接支持hash索引,但是给我们提供了一个功能就是这个自适应hash索引。因为前面我们讲到过,hash索引在 进行等值匹配时,一般性能是要高于B+树的,因为hash索引一般只需要一次IO即可,而B+树,可能需 要几次匹配,所以hash索引的效率要高,但是hash索引又不适合做范围查询、模糊匹配等。
InnoDB存储引擎会监控对表上各索引页的查询,如果观察到在特定的条件下hash索引可以提升速度, 则建立hash索引,称之为自适应hash索引。
自适应哈希索引,无需人工干预,是系统根据情况自动完成。
参数: adaptive_hash_index
4). Log Buffer Log Buffer日志缓冲区
日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log 、undo log), 默认大小为 16MB,**日志缓冲区的日志会定期刷新到磁盘中。**如果需要更新、插入或删除许多行的事 务,增加日志缓冲区的大小可以节省磁盘 I/O。
参数: innodb_log_buffer_size:缓冲区大小
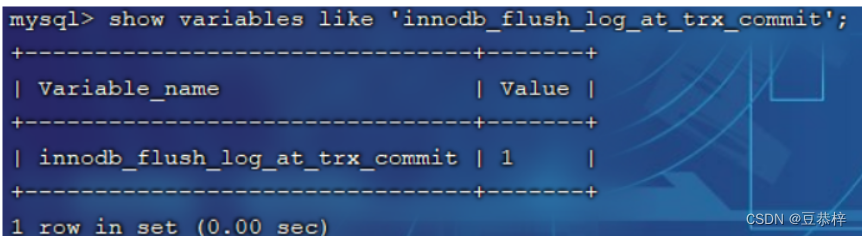
innodb_flush_log_at_trx_commit:日志刷新到磁盘时机,取值主要包含以下三个:
-
1: 日志在每次事务提交时写入并刷新到磁盘,默认值。
-
0: 每秒将日志写入并刷新到磁盘一次。
-
2: 日志在每次事务提交后写入,并每秒刷新到磁盘一次。
2.3 磁盘结构
接下来,再来看看InnoDB体系结构的右边部分,也就是磁盘结构:
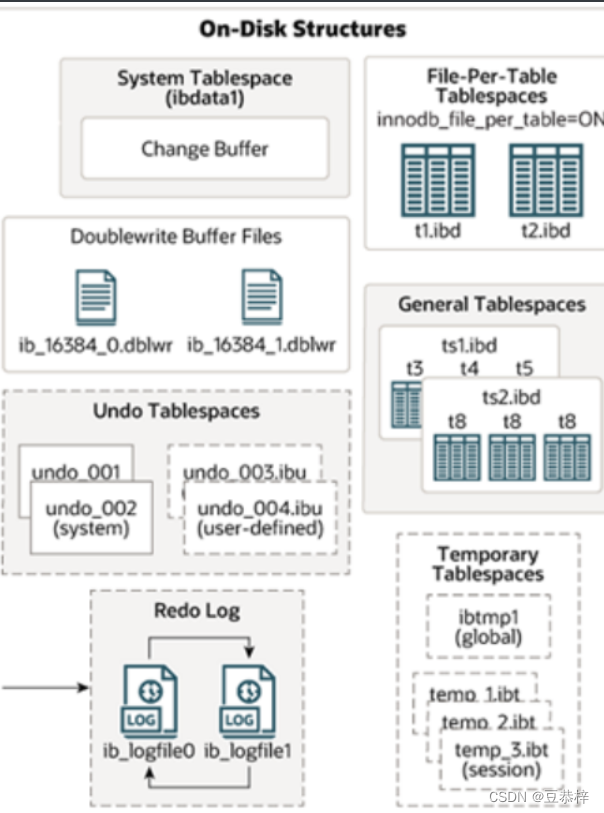
1). System Tablespace(系统表空间)
系统表空间是更改缓冲区的存储区域。如果表是在系统表空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undolog等)
参数:innodb_data_file_path
系统表空间,默认的文件名叫 ibdata1。
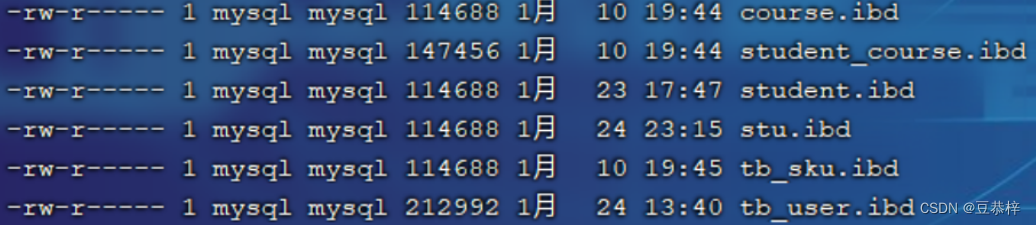
2). File-Per-Table Tablespaces
如果开启了innodb_file_per_table开关 ,则每个表的文件表空间包含单个InnoDB表的数据和索 引 ,并存储在文件系统上的单个数据文件中。 开关参数:innodb_file_per_table ,该参数默认开启。
那也就是说,我们每次创建一个表,都会产生一个表空间文件,如图:
3). General Tablespaces
通用表空间,需要通过 CREATE TABLESPACE 语法创建通用表空间,在创建表时,可以指定该表空 间。
A. 创建表空间
CREATE TABLESPACE ts_name ADD DATAFILE 'file_name' ENGINE = engine_name;B. 创建表时指定表空间
CREATE TABLE xxx ... TABLESPACE ts_name;
4). Undo Tablespaces
撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
5). Temporary Tablespaces
InnoDB 使用 会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
6). Doublewrite Buffer Files
双写缓冲区,innoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件 中,便于系统异常时恢复数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BsifMsAX-1692020601866)(D:/typora图片/image-20221015153843420.png)]](https://img-blog.csdnimg.cn/1ca1930a74314ecaa1bd0a8ce2dc00db.png)
7). Redo Log
重做日志,是用来实现事务的持久性。该日志文件由两部分组成:
- 重做日志缓冲(redo log buffer)以及重做日志文件(redo log)
- 前者是在内存中,后者在磁盘中。
- 当事务提交之后会把所 有修改信息都会存到该日志中, 用于在刷新脏页到磁盘时,发生错误时, 进行数据恢复使用,后面会介绍。 以循环方式写入重做日志文件,涉及两个文件:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IR24n2qd-1692020601866)(D:/typora图片/image-20221015154000480.png)]](https://img-blog.csdnimg.cn/5168ed852a7f4a59b252c1f831c83d3b.png)
前面我们介绍了InnoDB的内存结构,以及磁盘结构,那么内存中我们所更新的数据,又是如何到磁盘 中的呢? 此时,就涉及到一组后台线程,接下来,就来介绍一些InnoDB中涉及到的后台线程。
2.4 后台线程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bXcr5m4d-1692020601867)(D:/typora图片/image-20221015154039246.png)]](https://img-blog.csdnimg.cn/b406750ba4c74374afa2844e408c4add.png)
在InnoDB的后台线程中,分为4类,分别是:Master Thread 、IO Thread、Purge Thread、Page Cleaner Thread。
1). Master Thread
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中, 保持数据的一致性, 还包括脏页的刷新、合并插入缓存、undo页的回收 。
2). IO Thread
在InnoDB存储引擎中大量使用了AIO来处理IO请求, 这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XjFXyGyl-1692020601867)(D:/typora图片/image-20221015154127964.png)]](https://img-blog.csdnimg.cn/e5c9829bde1c46a09f2d4fa43af7ece1.png)
我们可以通过以下的这条指令,查看到InnoDB的状态信息,其中就包含IO Thread信息。.
show engine innodb status \G;
3). Purge Thread
主要用于回收事务已经提交了的undo log,在事务提交之后,undo log可能不用了,就用它来回 收。
4). Page Cleaner Thread
协助 Master Thread 刷新脏页到磁盘的线程,它可以减轻 Master Thread 的工作压力,减少阻 塞。
相关文章:
InnoDB引擎
1 逻辑存储结构 InnoDB的逻辑存储结构如下图所示: 1). 表空间 表空间是InnoDB存储引擎逻辑结构的最高层, 如果用户启用了参数 innodb_file_per_table(在8.0版本中默认开启) ,则每张表都会有一个表空间(xxx.ibd),一个…...

CSS3中的var()函数
目录 定义: 语法: 用法: 定义: var()函数是一个 CSS 函数用于插入自定义属性(有时也被称为“CSS 变量”)的值 语法: var(custom-property-name, value) 函数的第一个参数是要替换的自定义属性…...
opencv图片换背景色
#include <iostream> #include<opencv2/opencv.hpp> //引入头文件using namespace cv; //命名空间 using namespace std;//opencv这个机器视觉库,它提供了很多功能,都是以函数的形式提供给我们 //我们只需要会调用函数即可in…...
JAVA语言:什么是懒加载机制?
JVM没有规定什么时候加载,一般是什么时候使用这个class才会什么时候加载,但是JVM规定了什么时候必须初始化(初始化是第三步、装载、连接、初始化),只要加载之后,那么肯定是要进行初始化的,所以我们就可以通过查看这个类有没有进行初始化,从而判断这个类有没有被加载。 …...
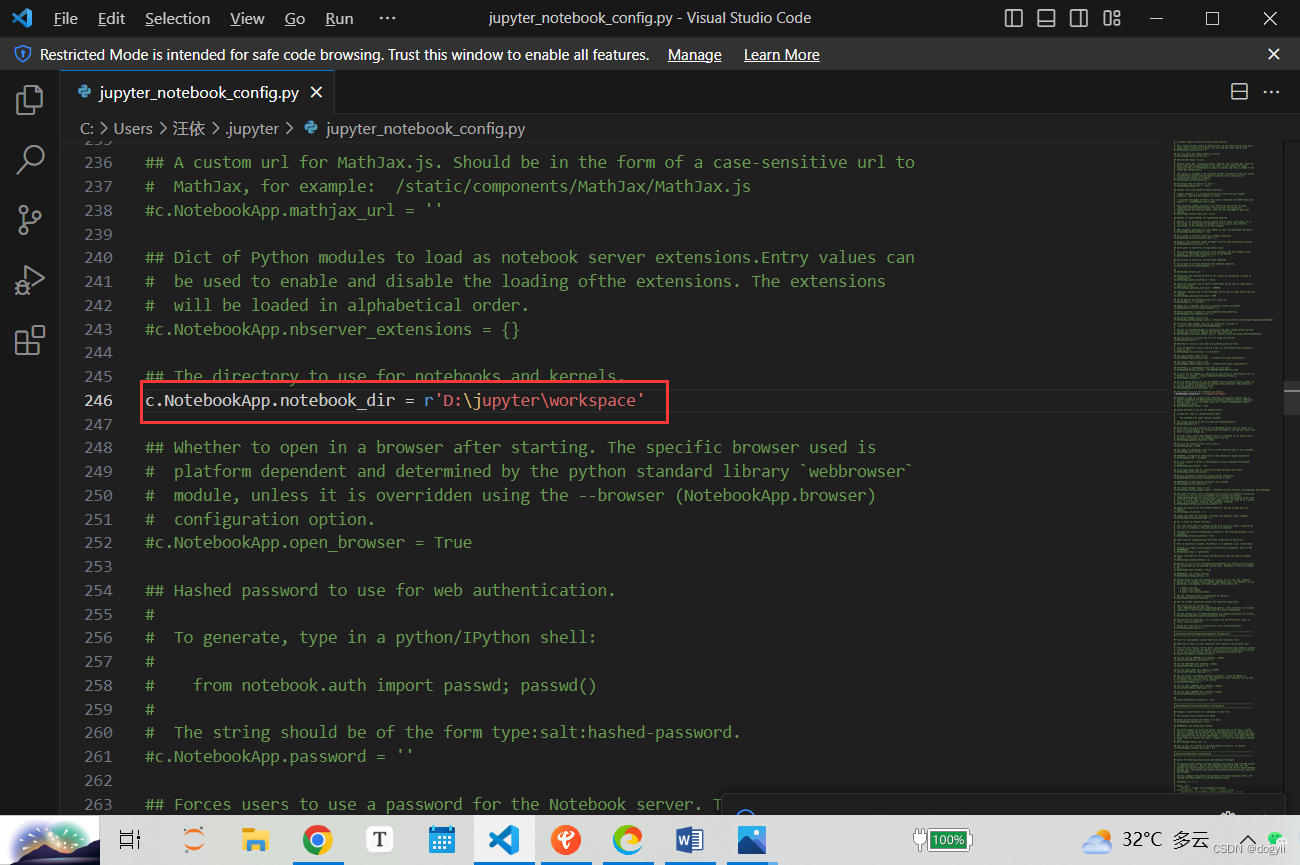
jupyter默认工作目录的更改
1、生成配置文件:打开Anaconda Prompt,输入如下命令 jupyter notebook --generate-config询问[y/N]时输入y 2、配置文件修改:根据打印路径打开配置文件jupyter_notebook_config.py,全文搜索找到notebook_dir所在位置。在单引号中…...
Flutter系列文章-Flutter UI进阶
在本篇文章中,我们将深入学习 Flutter UI 的进阶技巧,涵盖了布局原理、动画实现、自定义绘图和效果、以及 Material 和 Cupertino 组件库的使用。通过实例演示,你将更加了解如何创建复杂、令人印象深刻的用户界面。 第一部分:深入…...

Elasticsearch在部署时,对Linux的设置有哪些优化方法?
部署Elasticsearch时,可以通过优化Linux系统的设置来提升性能和稳定性。以下是一些常见的优化方法: 1.文件描述符限制 Elasticsearch需要大量的文件描述符来处理数据和连接,所以确保调整系统的文件描述符限制。可以通过修改 /etc/security/…...
【网络基础】应用层协议
【网络基础】应用层协议 文章目录 【网络基础】应用层协议1、协议作用1.1 应用层需求1.2 协议分类 2、HTTP & HTTPS2.1 HTTP/HTTPS 简介2.2 HTTP工作原理2.3 HTTPS工作原理2.4 区别 3、URL3.1 编码解码3.2 URI & URL 4、HTTP 消息结构4.1 HTTP请求方法4.2 HTTP请求头信…...

面试八股文Mysql:(1)事务实现的原理
1. 什么是事务 事务就是一组数据库操作,这些操作是一个atomic(原子性的操作) ,不可分割,要么都执行,要么回滚(rollback)都不执行。这样就避免了某个操作成功某个操作失败࿰…...

Linux学习之sed多行模式
N将下一行加入到模式空间 D删除模式空间中的第一个字符到第一个换行符 P打印模式空间中的第一个字符到第一个换行符 doubleSpace.txt里边的内容如下: goo d man使用下边的命令可以实现把上边对应的内容放到doubleSpace.txt。 echo goo >> doubleSpace.txt e…...
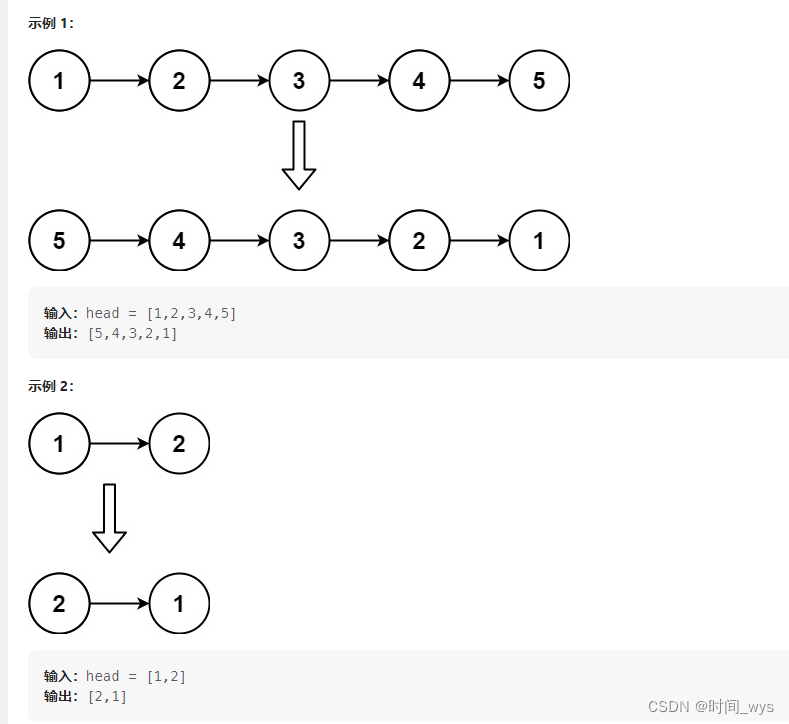
【刷题笔记8.15】【链表相关】LeetCode:合并两个有序链表、反转链表
LeetCode:【链表相关】合并两个有序链表 题目1:合并两个有序链表 题目描述 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 输入:l1 [1,2,4], l2 [1,3,4] 输出:[1,1,2,3…...

神经网络基础-神经网络补充概念-11-向量化逻辑回归
概念 通过使用 NumPy 数组来进行矩阵运算,将循环操作向量化。 向量化的好处在于它可以同时处理多个样本,从而加速计算过程。在实际应用中,尤其是处理大规模数据集时,向量化可以显著提高代码的效率。 代码实现-以逻辑回归为例 i…...

openGauss学习笔记-40 openGauss 高级数据管理-锁
文章目录 openGauss学习笔记-40 openGauss 高级数据管理-锁40.1 语法格式40.2 参数说明40.3 示例 openGauss学习笔记-40 openGauss 高级数据管理-锁 如果需要保持数据库数据的一致性,可以使用LOCK TABLE来阻止其他用户修改表。 例如,一个应用需要保证表…...
勘探开发人工智能技术:机器学习(6)
0 提纲 7.1 循环神经网络RNN 7.2 LSTM 7.3 Transformer 7.4 U-Net 1 循环神经网络RNN 把上一时刻的输出作为下一时刻的输入之一. 1.1 全连接神经网络的缺点 现在的任务是要利用如下语料来给apple打标签: 第一句话:I like eating apple!(我喜欢吃苹…...

代理类型中的 HTTP、HTTPS 和 SOCKS 有什么区别?
HTTP、HTTPS 和 SOCKS 都是代理(Proxy)协议,用于在网络通信中转发请求和响应,但它们在工作原理和用途上有一些区别。下面是它们之间的主要区别: HTTP代理: 工作原理: HTTP 代理主要用于转发 HTT…...
【STM32RT-Thread零基础入门】 3. PIN设备(GPIO)的使用
硬件:STM32F103ZET6、ST-LINK、usb转串口工具、4个LED灯、1个蜂鸣器、4个1k电阻、2个按键、面包板、杜邦线 文章目录 前言一、PIN设备介绍1. 引脚编号获取2. 设置引脚的输入/输出模式3. 设置引脚的电平值4. 读取引脚的电平值5. 绑定引脚中断回调函数6. 脱离引脚中断…...
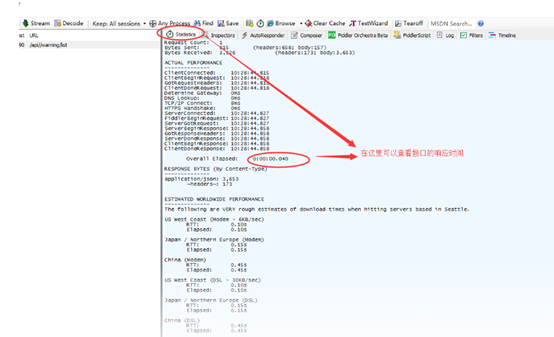
fiddler抓包工具的用法以及抓取手机报文定位bug
前言: fiddler抓包工具是日常测试中常用的一种bug定位工具 一 抓取https报文步骤 使用方法: 1 首先打开fiddler工具将证书导出 点击TOOLS------Options------Https-----Actions---选中第二个选项 2 把证书导出到桌面后 打开谷歌浏览器 设置---高级…...

spring中时间格式化的两种方式
方法一:自己格式化 自己写一个格式化的类,把date类型的时间传进去: public class DateUtil {public static String formatDate(Date date){SimpleDateFormat simpleDateFormatnew SimpleDateFormat("yyyy-MM-dd HH:mm:ss");retur…...
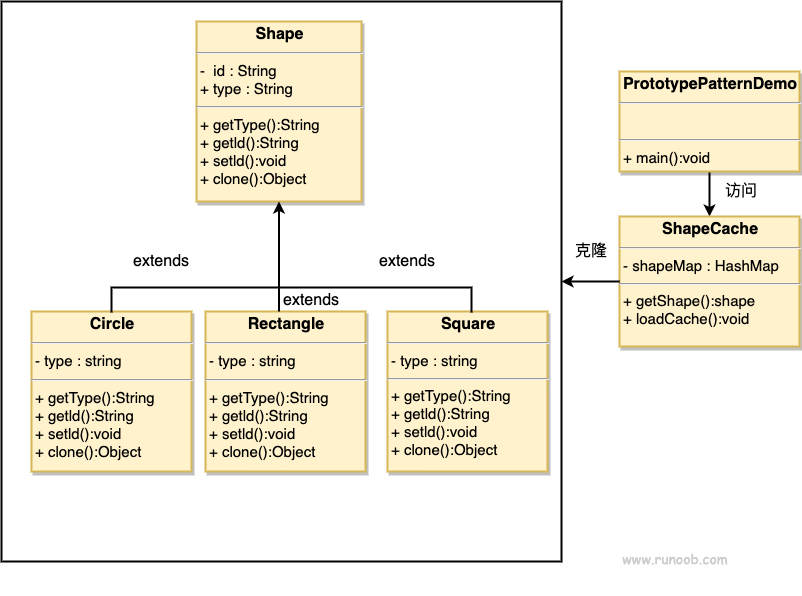
【设计模式】原型模式
原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式之一。 这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接…...
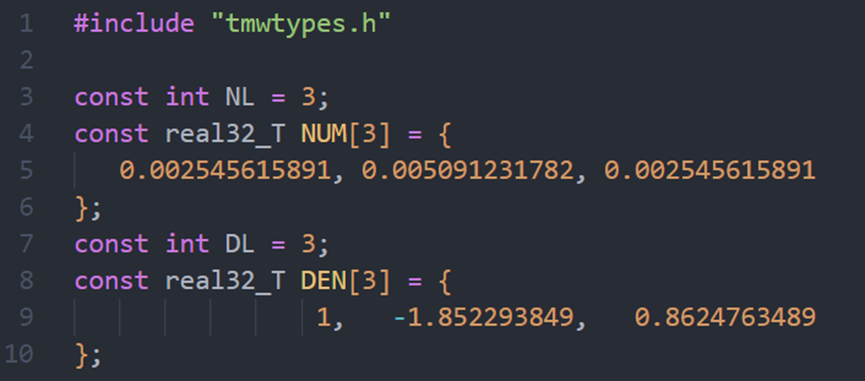
Matlab的Filter Designer工具设计二阶低通滤波器
Matlab版本:2018b 本文要求:设计一个二阶巴特沃斯低通滤波器用于嵌入式软件滤波,传感器采样频率是20KHz,截止频率是333Hz,获取滤波系数,本文不包括二阶滤波推导和代码编写。 打开Matlab->APP->Filt…...

对比直接使用厂商api体验taotoken在延迟与可用性上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在延迟与可用性上的差异 在构建依赖大模型能力的应用时,开发者通常会直接调用特定…...

华为麒麟芯片不外售背后的商业逻辑与技术护城河
1. 从一则新闻说起:麒麟芯片的“不对外”意味着什么前几天,华为轮值董事长徐直军先生在一次公开场合的发言,在科技圈里又激起了一阵讨论。他明确表示,华为“没有任何想法把麒麟芯片对外销售”。这句话乍一听,可能让不少…...

高性能混合数据聚类算法:k-prototypes架构设计与性能优化深度解析
高性能混合数据聚类算法:k-prototypes架构设计与性能优化深度解析 【免费下载链接】kmodes Python implementations of the k-modes and k-prototypes clustering algorithms, for clustering categorical data 项目地址: https://gitcode.com/gh_mirrors/km/kmod…...

Office RibbonX Editor:免费开源的Office界面定制终极指南
Office RibbonX Editor:免费开源的Office界面定制终极指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-ed…...

TinyRS-R1:轻量级遥感视觉语言模型的技术解析与应用
1. TinyRS-R1:轻量级遥感视觉语言模型的技术解析 在遥感图像分析领域,视觉语言模型(Vision-Language Models, VLMs)正逐渐成为关键技术。这类模型能够同时理解图像内容和自然语言描述,为卫星和航拍图像的分析提供了全新…...

5个高级技巧:掌握Dark Reader动态主题修复的最佳实践
5个高级技巧:掌握Dark Reader动态主题修复的最佳实践 【免费下载链接】darkreader Dark Reader Chrome and Firefox extension 项目地址: https://gitcode.com/gh_mirrors/da/darkreader Dark Reader是一款广受欢迎的浏览器扩展,它通过智能算法将…...

Bebas Neue 开源字体深度解析:几何美学的技术实现与实战应用
Bebas Neue 开源字体深度解析:几何美学的技术实现与实战应用 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue Bebas Neue 作为全球最受欢迎的开源几何无衬线字体,以其极简设计、高度统一的…...

医疗可穿戴跨界创新:从连续监测到专业检测的硬件设计实践
1. 项目概述:当可穿戴设备“走出”身体这几年,医疗可穿戴设备已经不是什么新鲜词了。从最初只能计步的手环,到如今能监测心率、血氧、心电图甚至血糖趋势的智能手表,它们正变得越来越“贴身”,也越来越“懂”我们的身体…...

生成式AI初学者本地部署实操指南:从报错诊断到模型运行
1. 这不是又一篇“AI科普文”,而是一份写给真实初学者的实操手记Generative AI: A Beginner’s Viewpoint Part 2——这个标题乍看像课程续集,但如果你正站在ChatGPT第一次弹出对话框的那一刻、刚下载完Stable Diffusion却卡在WebUI启动界面、或对着Jupy…...

OpenAI通用推理模型攻克近80年数学难题,打脸7个月前虚假突破质疑
【导语:5月21日,OpenAI宣布其一款未对外发布的内部通用推理模型独立完成原创数学证明,推翻了匈牙利数学家保罗埃尔德什1946年提出的“平面单位距离猜想”,这是AI首次独立攻克数学领域核心著名公开难题。】AI攻克近80年几何猜想Ope…...