YOLOv5、YOLOv8改进:MobileViT:轻量通用且适合移动端的视觉Transformer
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
论文:https://arxiv.org/abs/2110.02178

1简介
MobileviT是一个用于移动设备的轻量级通用可视化Transformer,据作者介绍,这是第一次基于轻量级CNN网络性能的轻量级ViT工作,性能SOTA!。性能优于MobileNetV3、CrossviT等网络。
轻量级卷积神经网络(CNN)是移动视觉任务的实际应用。他们的空间归纳偏差允许他们在不同的视觉任务中以较少的参数学习表征。然而,这些网络在空间上是局部的。为了学习全局表征,采用了基于自注意力的Vision Transformer(ViTs)。与CNN不同,ViT是heavy-weight。
在本文中,本文提出了以下问题:是否有可能结合CNN和ViT的优势,构建一个轻量级、低延迟的移动视觉任务网络?
为此提出了MobileViT,一种轻量级的、通用的移动设备Vision Transformer。MobileViT提出了一个不同的视角,以Transformer作为卷积处理信息。
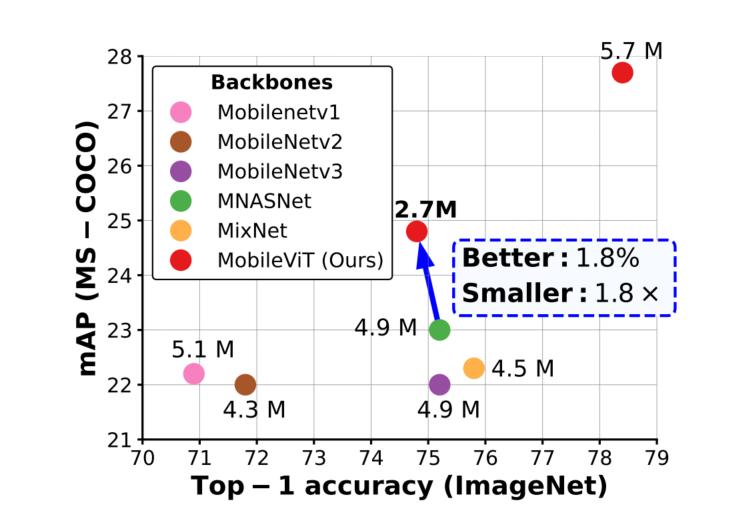
实验结果表明,在不同的任务和数据集上,MobileViT显著优于基于CNN和ViT的网络。
在ImageNet-1k数据集上,MobileViT在大约600万个参数的情况下达到了78.4%的Top-1准确率,对于相同数量的参数,比MobileNetv3和DeiT的准确率分别高出3.2%和6.2%。
在MS-COCO目标检测任务中,在参数数量相近的情况下,MobileViT比MobileNetv3的准确率高5.7%。
2.Mobile-ViT
MobileViT Block如下图所示,其目的是用较少的参数对输入张量中的局部和全局信息进行建模。
形式上,对于一个给定的输入张量, MobileViT首先应用一个n×n标准卷积层,然后用一个一个点(或1×1)卷积层产生特征。n×n卷积层编码局部空间信息,而点卷积通过学习输入通道的线性组合将张量投影到高维空间(d维,其中d>c)。
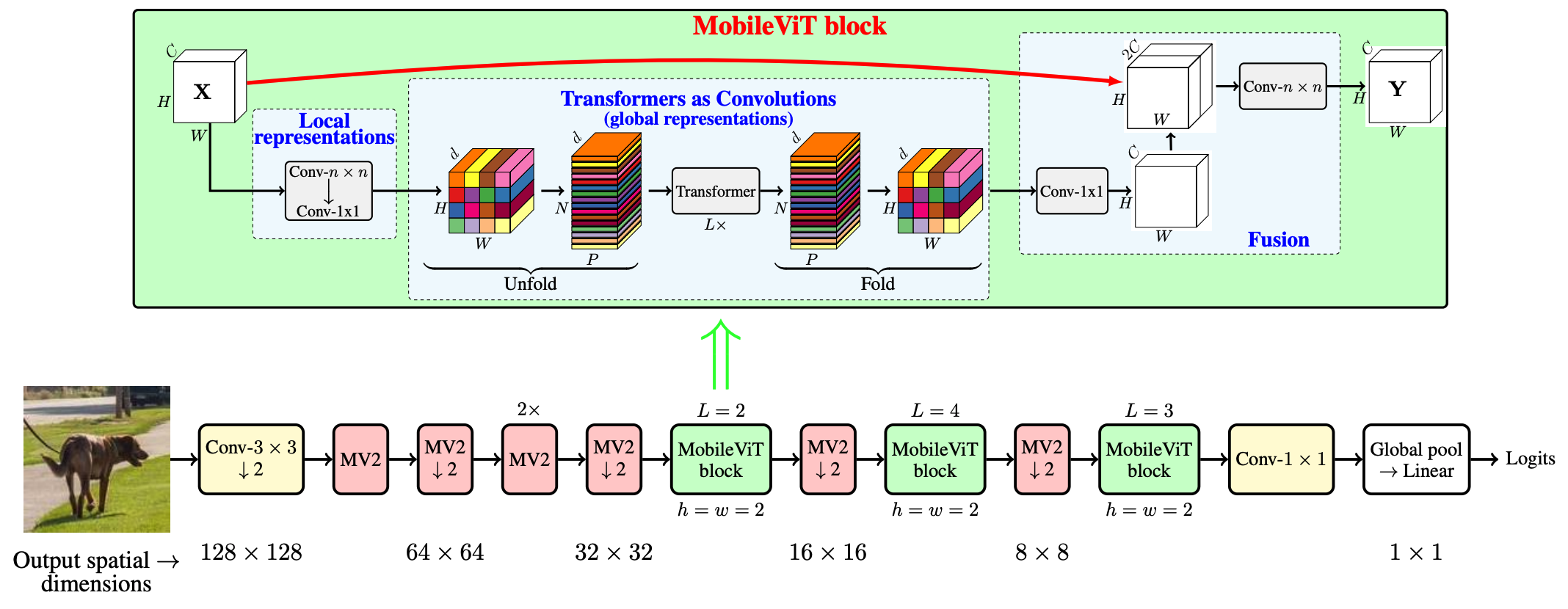
通过MobileViT,希望在拥有有效感受野的同时,对远距离非局部依赖进行建模。一种被广泛研究的建模远程依赖关系的方法是扩张卷积。然而,这种方法需要谨慎选择膨胀率。否则,权重将应用于填充的零而不是有效的空间区域。
另一个有希望的解决方案是Self-Attention。在Self-Attention方法中,具有multi-head self-attention的vision transformers(ViTs)在视觉识别任务中是有效的。然而,vit是heavy-weight,并由于vit缺乏空间归纳偏差,表现出较差的可优化性。
下面附上改进代码
---------------------------------------------分割线--------------------------------------------------
在common中加入如下代码
需要安装一个einops模块
pip --default-timeout=5000 install -i https://pypi.tuna.tsinghua.edu.cn/simple einops
这边建议直接兴建一个 
import torch
import torch.nn as nnfrom einops import rearrangedef conv_1x1_bn(inp, oup):return nn.Sequential(nn.Conv2d(inp, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),nn.SiLU())def conv_nxn_bn(inp, oup, kernal_size=3, stride=1):return nn.Sequential(nn.Conv2d(inp, oup, kernal_size, stride, 1, bias=False),nn.BatchNorm2d(oup),nn.SiLU())class PreNorm(nn.Module):def __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout=0.):super().__init__()self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.SiLU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)class Attention(nn.Module):def __init__(self, dim, heads=8, dim_head=64, dropout=0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.attend = nn.Softmax(dim = -1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):qkv = self.to_qkv(x).chunk(3, dim=-1)q, k, v = map(lambda t: rearrange(t, 'b p n (h d) -> b p h n d', h = self.heads), qkv)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scaleattn = self.attend(dots)out = torch.matmul(attn, v)out = rearrange(out, 'b p h n d -> b p n (h d)')return self.to_out(out)class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PreNorm(dim, Attention(dim, heads, dim_head, dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout))]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn xclass MV2Block(nn.Module):def __init__(self, inp, oup, stride=1, expansion=4):super().__init__()self.stride = strideassert stride in [1, 2]hidden_dim = int(inp * expansion)self.use_res_connect = self.stride == 1 and inp == oupif expansion == 1:self.conv = nn.Sequential(# dwnn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),nn.BatchNorm2d(hidden_dim),nn.SiLU(),# pw-linearnn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),)else:self.conv = nn.Sequential(# pwnn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),nn.BatchNorm2d(hidden_dim),nn.SiLU(),# dwnn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),nn.BatchNorm2d(hidden_dim),nn.SiLU(),# pw-linearnn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),)def forward(self, x):if self.use_res_connect:return x + self.conv(x)else:return self.conv(x)class MobileViTBlock(nn.Module):def __init__(self, dim, depth, channel, kernel_size, patch_size, mlp_dim, dropout=0.):super().__init__()self.ph, self.pw = patch_sizeself.conv1 = conv_nxn_bn(channel, channel, kernel_size)self.conv2 = conv_1x1_bn(channel, dim)self.transformer = Transformer(dim, depth, 4, 8, mlp_dim, dropout)self.conv3 = conv_1x1_bn(dim, channel)self.conv4 = conv_nxn_bn(2 * channel, channel, kernel_size)def forward(self, x):y = x.clone()# Local representationsx = self.conv1(x)x = self.conv2(x)# Global representations_, _, h, w = x.shapex = rearrange(x, 'b d (h ph) (w pw) -> b (ph pw) (h w) d', ph=self.ph, pw=self.pw)x = self.transformer(x)x = rearrange(x, 'b (ph pw) (h w) d -> b d (h ph) (w pw)', h=h//self.ph, w=w//self.pw, ph=self.ph, pw=self.pw)# Fusionx = self.conv3(x)x = torch.cat((x, y), 1)x = self.conv4(x)return xclass MobileViT(nn.Module):def __init__(self, image_size, dims, channels, num_classes, expansion=4, kernel_size=3, patch_size=(2, 2)):super().__init__()ih, iw = image_sizeph, pw = patch_sizeassert ih % ph == 0 and iw % pw == 0L = [2, 4, 3]self.conv1 = conv_nxn_bn(3, channels[0], stride=2)self.mv2 = nn.ModuleList([])self.mv2.append(MV2Block(channels[0], channels[1], 1, expansion))self.mv2.append(MV2Block(channels[1], channels[2], 2, expansion))self.mv2.append(MV2Block(channels[2], channels[3], 1, expansion))self.mv2.append(MV2Block(channels[2], channels[3], 1, expansion)) # Repeatself.mv2.append(MV2Block(channels[3], channels[4], 2, expansion))self.mv2.append(MV2Block(channels[5], channels[6], 2, expansion))self.mv2.append(MV2Block(channels[7], channels[8], 2, expansion))self.mvit = nn.ModuleList([])self.mvit.append(MobileViTBlock(dims[0], L[0], channels[5], kernel_size, patch_size, int(dims[0]*2)))self.mvit.append(MobileViTBlock(dims[1], L[1], channels[7], kernel_size, patch_size, int(dims[1]*4)))self.mvit.append(MobileViTBlock(dims[2], L[2], channels[9], kernel_size, patch_size, int(dims[2]*4)))self.conv2 = conv_1x1_bn(channels[-2], channels[-1])self.pool = nn.AvgPool2d(ih//32, 1)self.fc = nn.Linear(channels[-1], num_classes, bias=False)def forward(self, x):x = self.conv1(x)x = self.mv2[0](x)x = self.mv2[1](x)x = self.mv2[2](x)x = self.mv2[3](x) # Repeatx = self.mv2[4](x)x = self.mvit[0](x)x = self.mv2[5](x)x = self.mvit[1](x)x = self.mv2[6](x)x = self.mvit[2](x)x = self.conv2(x)x = self.pool(x).view(-1, x.shape[1])x = self.fc(x)return xdef mobilevit_xxs():dims = [64, 80, 96]channels = [16, 16, 24, 24, 48, 48, 64, 64, 80, 80, 320]return MobileViT((256, 256), dims, channels, num_classes=1000, expansion=2)def mobilevit_xs():dims = [96, 120, 144]channels = [16, 32, 48, 48, 64, 64, 80, 80, 96, 96, 384]return MobileViT((256, 256), dims, channels, num_classes=1000)def mobilevit_s():dims = [144, 192, 240]channels = [16, 32, 64, 64, 96, 96, 128, 128, 160, 160, 640]return MobileViT((256, 256), dims, channels, num_classes=1000)def count_parameters(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)if __name__ == '__main__':img = torch.randn(5, 3, 256, 256)vit = mobilevit_xxs()out = vit(img)print(out.shape)print(count_parameters(vit))vit = mobilevit_xs()out = vit(img)print(out.shape)print(count_parameters(vit))vit = mobilevit_s()out = vit(img)print(out.shape)print(count_parameters(vit))yolo.py中导入并注册
加入MV2Block, MobileViTBlock

修改yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 backbone
backbone:# [from, number, module, args] 640 x 640
# [[-1, 1, Conv, [32, 6, 2, 2]], # 0-P1/2 320 x 320[[-1, 1, Focus, [32, 3]],[-1, 1, MV2Block, [32, 1, 2]], # 1-P2/4[-1, 1, MV2Block, [48, 2, 2]], # 160 x 160[-1, 2, MV2Block, [48, 1, 2]],[-1, 1, MV2Block, [64, 2, 2]], # 80 x 80[-1, 1, MobileViTBlock, [64,96, 2, 3, 2, 192]], # 5 out_dim,dim, depth, kernel_size, patch_size, mlp_dim[-1, 1, MV2Block, [80, 2, 2]], # 40 x 40[-1, 1, MobileViTBlock, [80,120, 4, 3, 2, 480]], # 7[-1, 1, MV2Block, [96, 2, 2]], # 20 x 20[-1, 1, MobileViTBlock, [96,144, 3, 3, 2, 576]], # 11-P2/4 # 9]# YOLOv5 head
head:[[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [256, False]], # 13[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [128, False]], # 17 (P3/8-small)[-1, 1, Conv, [128, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [256, False]], # 20 (P4/16-medium)[-1, 1, Conv, [256, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [512, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
-
修改mobilevit.py

补充说明
einops.EinopsError: Error while processing rearrange-reduction pattern "b d (h ph) (w pw) -> b (ph pw) (h w) d".
Input tensor shape: torch.Size([1, 120, 42, 42]). Additional info: {'ph': 4, 'pw': 4}
是因为输入输出不匹配造成
记得关掉rect哦!一个是在参数里,另一个在下图。如果要在test或者val中跑,同样要改
相关文章:
YOLOv5、YOLOv8改进:MobileViT:轻量通用且适合移动端的视觉Transformer
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer 论文:https://arxiv.org/abs/2110.02178 1简介 MobileviT是一个用于移动设备的轻量级通用可视化Transformer,据作者介绍,这是第一次基于轻量级CNN网络性…...
06-4_Qt 5.9 C++开发指南_MDI应用程序设计
文章目录 1. MDI简介2. 文档窗口类 QFormDoc 的设计3. MDI主窗口设计与子窗口的使用3.1 主窗口界面设计3.2 MDI子窗口的创建与加入3.3 QMdiArea 常用功能函数3.4 MDI的信号 4. 源码4.1 qwmainwindow.h4.2 qwmainwindow.cpp 1. MDI简介 传统的应用程序设计中有多文档界面(Multi…...

【SCI征稿】3区SCI,正刊,智能传感、机器学习、智能检测与测量等均可
影响因子:IF:2.0-3.0 期刊分区:JCR3区,中科院4区 检索情况:SCIE在检,正刊 征稿领域:智能技术在测量与检测中的应用研究,如: ● 复杂系统的智能传感和高级故障诊断 ●…...
,CNN以及RNN区别和应用)
神经网络ANN(MLP),CNN以及RNN区别和应用
1. Artificial Neural Network(ANN) 又称为Multilayer Perception Model(MLP) 2. CNN AAA 3. RNN 22 先占坑,后期再整理 References [1] CNN vs.RNN vs.ANN——浅析深度学习中的三种神经网络 - 知乎 [2] https://www.youtube.com/watch?vu7obuspdQu4 [3] 深…...
CUDA、cuDNN以及Pytorch介绍
文章目录 前言一、CUDA二、cuDNN三、Pytorch 前言 在讲解cuda和cuDNN之前,我们首先来了解一下英伟达(NVIDA)公司。 NVIDIA是一家全球领先的计算机技术公司,专注于图形处理器(GPU)和人工智能(…...

使用shift关键字,写一个带二级命令的脚本(如:docker run -a -b -c中的run)
省流:shift关键字 探索思路 最近有一个小小的需求,写一个类似于docker run -a -b -c这样的脚本,这个脚本名为doline,它本身可以执行(doline -a -b -c),同时又带有几个如run、init、start这样的…...

MySQL学习笔记 - 进阶部分
MySQL进阶部分 字符集的相关操作:字符集和比较规则:utf8与utf8mb4:比较规则:常见的字符集和对应的Maxlen: Centos7中linux下配置字符集:各个级别的字符集:执行show variables like %character%语…...
微信小程序实现左滑删除
一、效果 二、代码 实现思路使用的是官方提供的 movable-area:注意点,需要设置其高度,否则会出现列表内容重叠的现象。由于movable-view需要向右移动,左滑的时候给删除控件展示的空间,故 movable-area 需要左移 left:…...
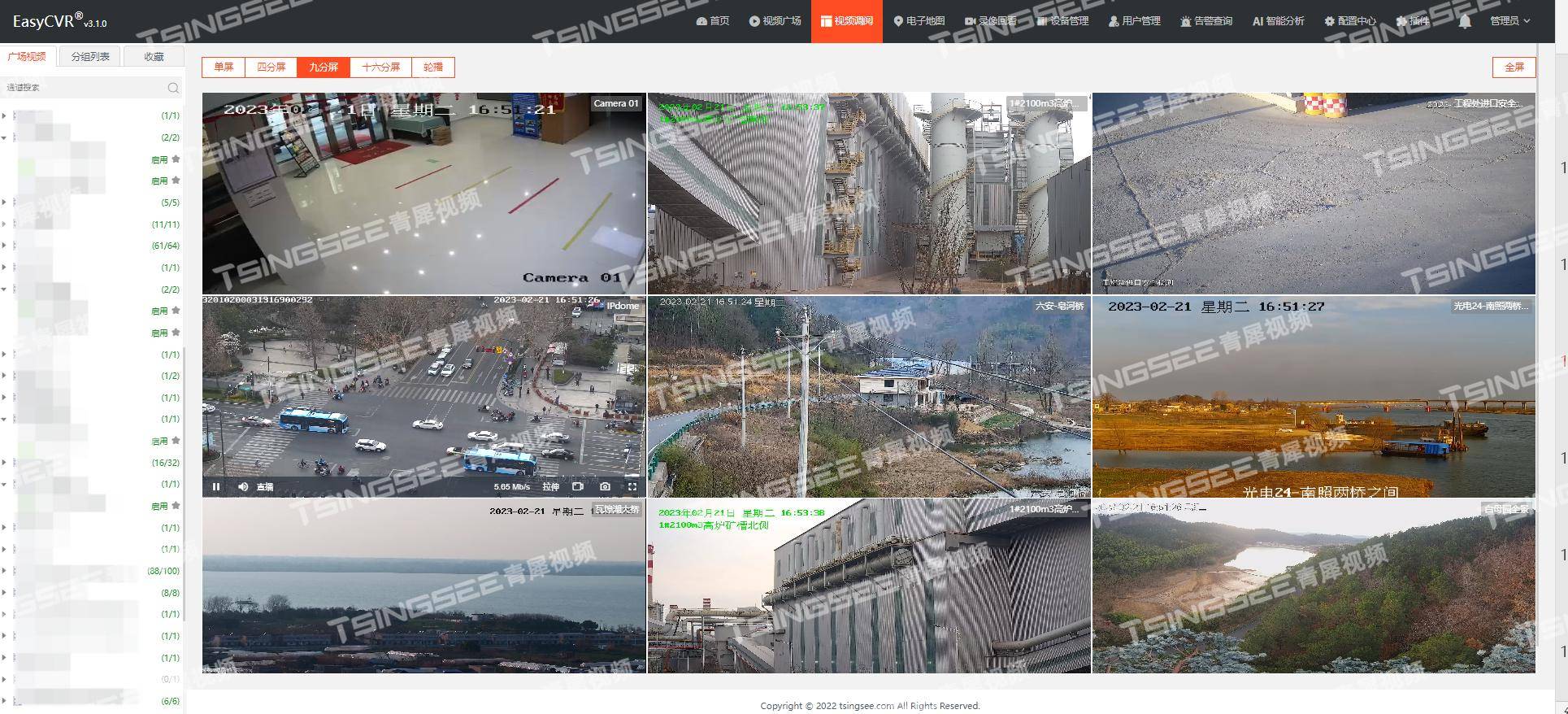
安防视频监控有哪些存储方式?哪种存储方式最优?
视频监控系统涉及到大量的视频数据,需要对这些数据进行存储,以备日后查看或备份。视频监控的存储需求需要根据场所的实际情况进行选择,以保证监控数据的有效存储和日后的调阅、回溯。 当前视频监控的存储方式,通常有以下几种&…...
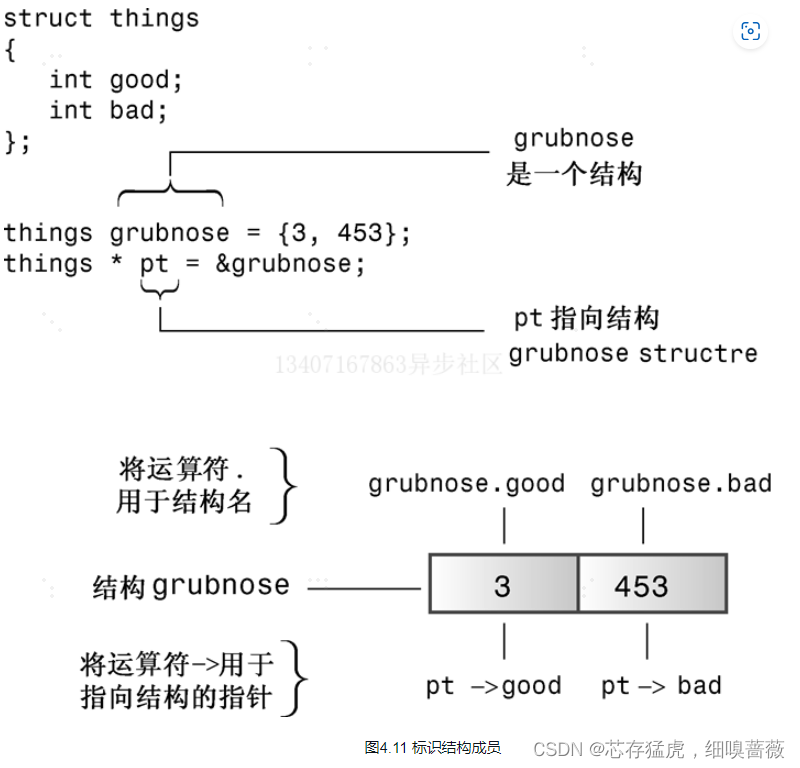
02-C++数据类型-高级
数据类型-高级 4、复合类型 4.4、结构简介 struct inflatable {char name[20];float vol;double price; };inflatable vincent; //C struct inflatable goose; //C例子 // structur.cpp -- a simple structure #include <iostream> struct inflatable // structu…...

Kotlin实战之获取本地配置文件、远程Apollo配置失败问题排查
背景 Kotlin作为一门JVM脚本语言,收到很多Java开发者的青睐。 项目采用JavaKotlin混合编程。Spring Boot应用开发,不会发生变动的配置放在本地配置文件,可能会变化的配置放在远程Apollo Server。 问题 因为业务需要,需要增加一…...
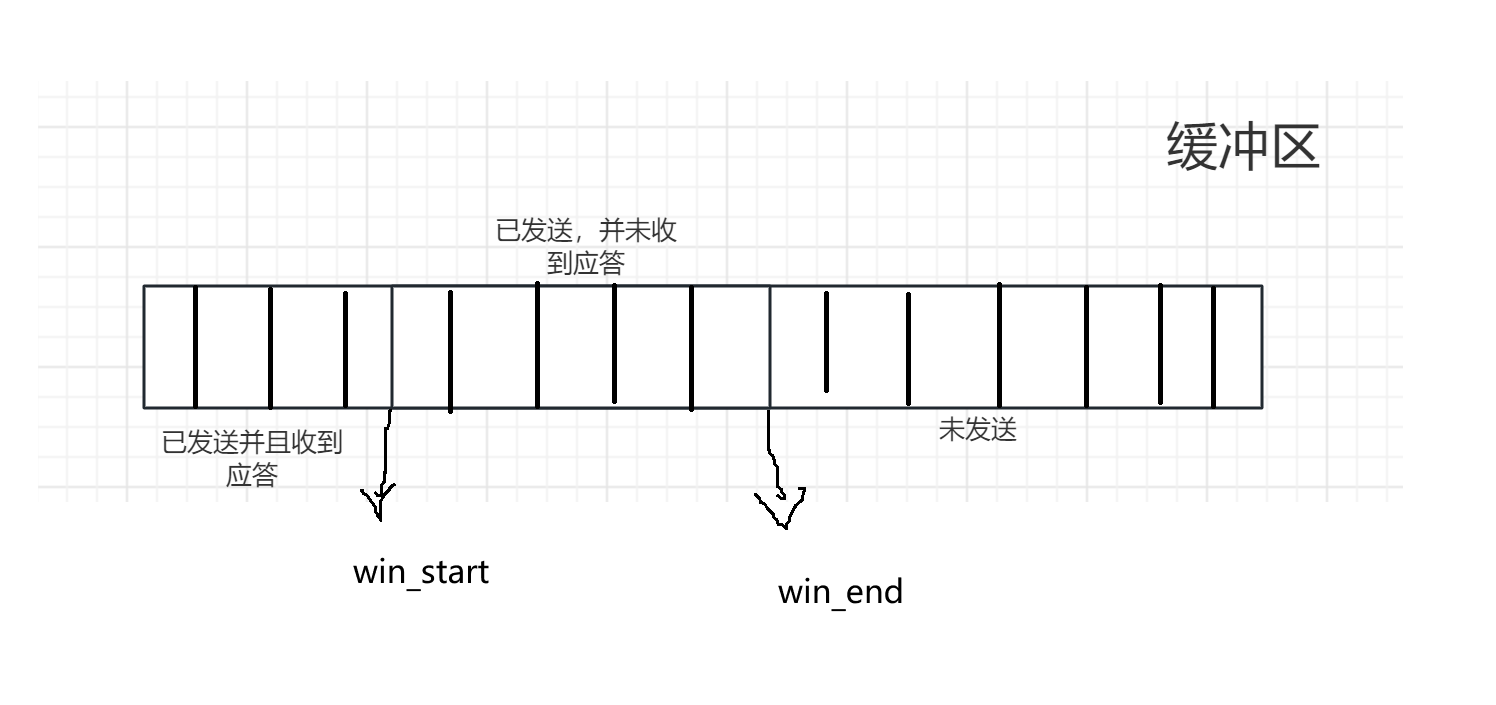
TCP协议的报头格式和滑动窗口
文章目录 TCP报头格式端口号序号和确认序号确认应答(ACK)机制超时重传机制 首部长度窗口大小报文类型URGACKSYNPSHFINRST 滑动窗口滑动窗口的大小怎么设定怎么变化滑动窗口变化问题 TCP报头格式 端口号 两个端口号比较好理解,通过端口号来找…...
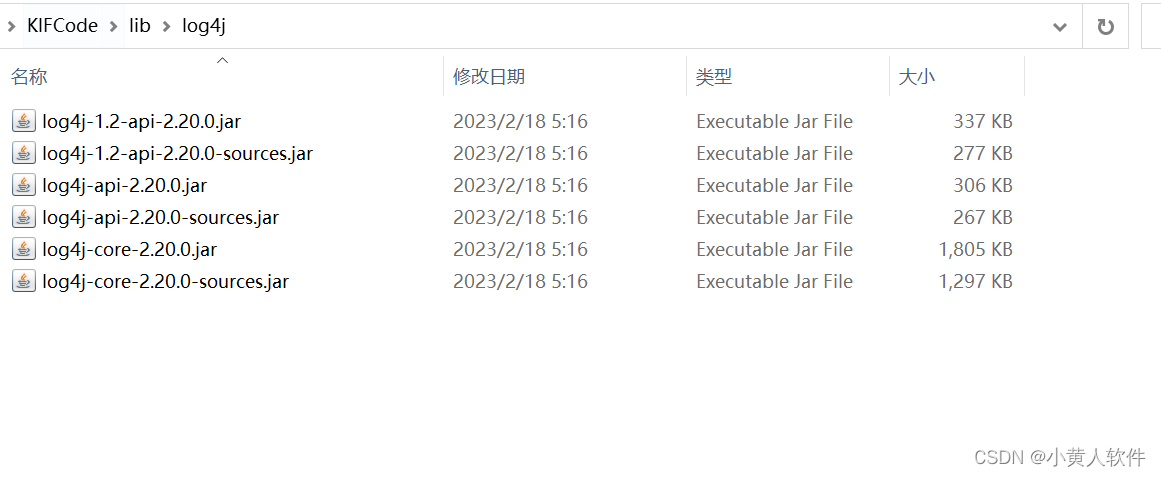
java 使用log4j显示到界面和文件 并格式化
1.下载log4j jar包https://dlcdn.apache.org/logging/log4j/2.20.0/apache-log4j-2.20.0-bin.zip 2. 我只要到核心包 ,看需要 sources是源码包,可以看到说明。在IDEA里先加入class jar后,再双击这个class jar包或或右键选Navigate ,Add ,…...

【js】链接中有多余的怎么取出参数值
https://pq.equalearning.net/assessment/379208869278126080?userId23ebb&originhttps://www.equalearning.net&fnameIm&lnamehappy在上面的例子中,fnameI’m,其中单引号’被转义为, 而如果使用下面的代码,因为在UR…...
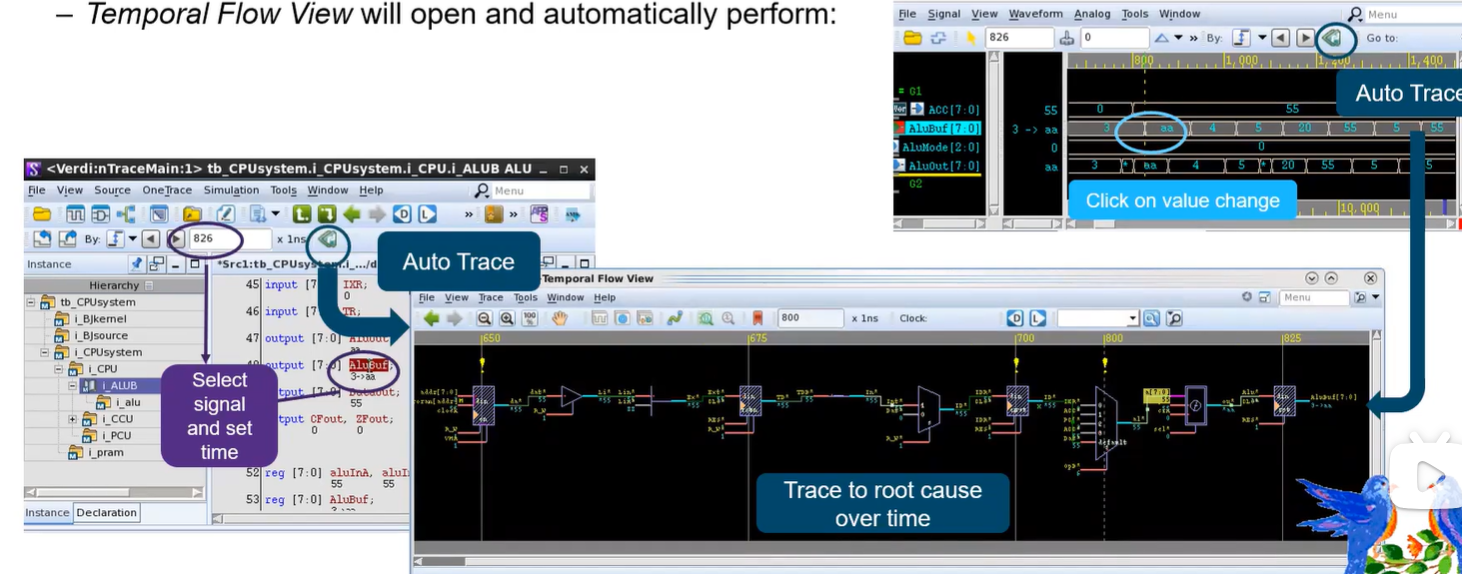
Verdi_traceX and autotrace
Verdi_traceX and autotrace Trace X From nWave/nTrace of from the Teporal Flow View. Show Paths on Flow ViewShow Paths on nWave 若Waveform中有X态,鼠标右键会有Trace X的选项; 会自动打开Temporal Flow View窗口,展示对应路径&am…...
安卓逆向 - 某严选app sign算法还原
本文仅供学习交流,只提供关键思路不会给出完整代码,严禁用于非法用途,若有侵权请联系我删除! 目标app: 5ouN5ouN5Lil6YCJMy45LjY 目标接口:aHR0cHM6Ly9hcGkubS5qZC5jb20vYXBp 一、引言 1、本篇分析某二手交易平台 …...
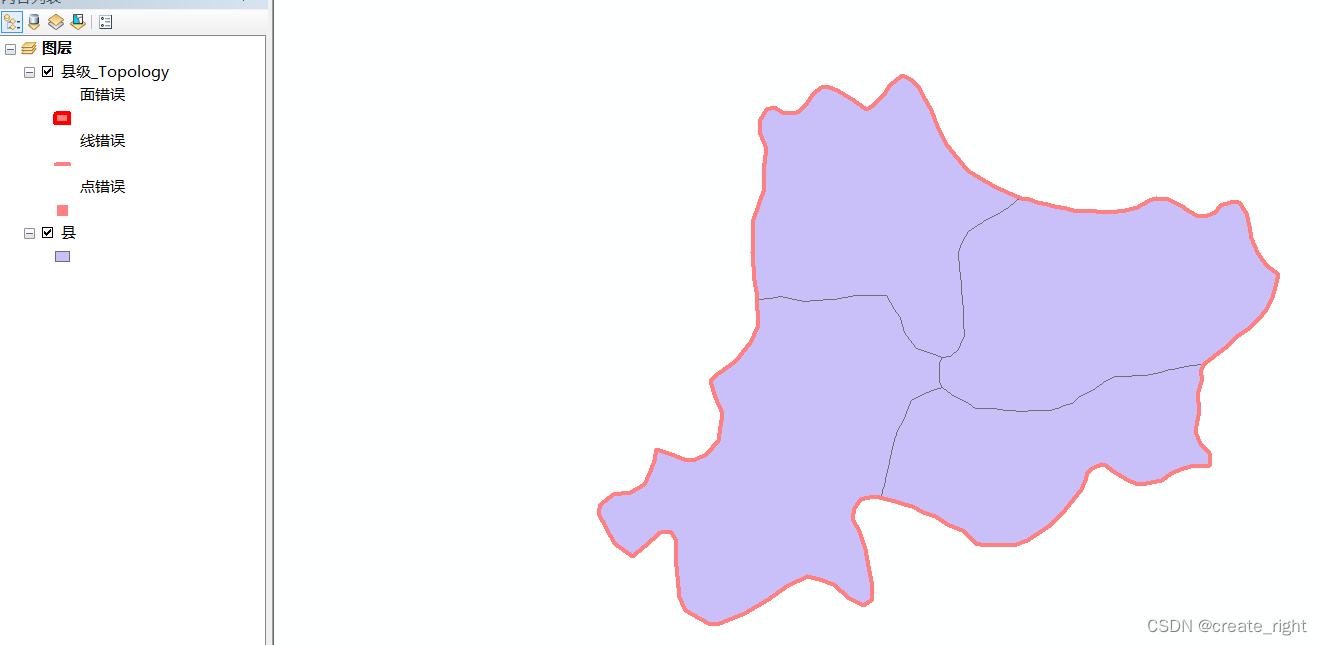
arcgis数据采集与拓扑检查
1、已准备好一张配准好的浙江省行政区划图,如下: 2、现在需要绘制湖州市县级行政区划。需要右击文件夹新建文件地理数据库,如下: 其余步骤均默认即可。 创建好县级要素数据集后,再新建要素类,命名为县。 为…...
【前端 | CSS】滚动到底部加载,滚动监听、懒加载
背景 在日常开发过程中,我们会遇到图片懒加载的功能,基本原理是,滚动条滚动到底部后再次获取数据进行渲染。 那怎么判断滚动条是否滚动到底部呢?滚动条滚动到底部触发时间的时机和方法又该怎样定义? 针对以上问题我…...

word将mathtype公式批量转为latex公式
最近,由于工作学习需要,要将word里面的mathype公式转为latex公式。 查了查资料,有alt\的操作,这样太慢了。通过下面链接的操作,结合起来可以解决问题。 某乎:https://www.zhihu.com/question/532353646 csd…...
docker-compose部署nacos 2.2.3
1、编写docker-compose.yml文件 version: "3.1" services:nacos:restart: alwaysimage: nacos/nacos-server:v2.2.3container_name: nacosenvironment:- NACOS_AUTH_ENABLEtrue- MODEstandalone- NACOS_AUTH_TOKEN8b92c609089f74db3c5ee04bd7d4d89e8b92c609089f74db…...

Play Integrity API Checker:三步快速检测你的Android设备安全完整指南 [特殊字符]
Play Integrity API Checker:三步快速检测你的Android设备安全完整指南 🔐 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-i…...

重尾分布采样的SMTM算法:原理与实践
1. 重尾分布采样的挑战与MCMC方法演进 在贝叶斯统计和统计物理领域,我们经常需要从复杂的概率分布中采样。想象一下,你手里有一袋形状各异的糖果(代表数据点),但袋子是不透明的,你只能通过摸取来了解糖果的…...

在Node.js后端服务中集成Taotoken,调用多模型API完成内容生成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken,调用多模型API完成内容生成 将大模型能力集成到后端服务是现代应用开发的常见需求。…...

REXROTH VT3006S35R1比例控制卡
REXROTH VT3006S35R1 是博世力士乐生产的一款模拟放大器卡(比例控制卡),专门用于控制先导式比例方向阀和比例压力阀,是液压比例控制系统中的核心控制组件。产品定位:模拟放大器卡,用于驱动和控制工业液压比…...

【紧急预警】你还在裸用ChatGPT写生产代码?这4类高危漏洞已致37家团队线上事故
更多请点击: https://kaifayun.com 第一章:ChatGPT编程辅助的底层风险认知与责任边界界定 当开发者将ChatGPT嵌入编码工作流时,其输出常被误认为具备工程级可靠性。然而,模型生成的代码本质上是统计拟合结果,不具备形…...

跨平台串口调试终极指南:SSCom让硬件开发更简单
跨平台串口调试终极指南:SSCom让硬件开发更简单 【免费下载链接】sscom Linux/Mac版本 串口调试助手 项目地址: https://gitcode.com/gh_mirrors/ss/sscom 作为硬件开发的必备工具,串口调试工具SSCom凭借其跨平台特性和高效性能,为Lin…...

Joy-Con Toolkit:3大核心功能让你的Switch手柄重获新生
Joy-Con Toolkit:3大核心功能让你的Switch手柄重获新生 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 你是否曾为Switch手柄的摇杆漂移而烦恼?是否想过让千篇一律的手柄颜色变得与众不同…...

TensorFlow+GCP+Firebase构建生产级AI Web应用
1. 项目概述:这不是一个“AI玩具”,而是一套可上线、可运维、可迭代的生产级Web应用工作流你有没有遇到过这样的情况:用TensorFlow训练好一个模型,本地Jupyter里跑得飞起,准确率98%,但一想到要把它变成网页…...

异常检测实战:从面试陷阱到产线落地的20个关键问题
1. 项目概述:这不是刷题手册,而是一张通往机器学习工程现场的“通关地图”“Crack ML Interviews with Confidence: Anomaly Detection (20 Q&A)”——这个标题里藏着三个被绝大多数求职者严重低估的关键信号:Crack不是“背答案”&#x…...

茉莉花插件:5分钟掌握Zotero中文文献管理终极方案
茉莉花插件:5分钟掌握Zotero中文文献管理终极方案 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献管理…...