《数据分析方法论和业务实战》读书笔记
《数据分析方法和业务实战》读书笔记
共9章:前两章入门,3-7章介绍基本方法,8章从项目实战介绍数据分析,9章答疑常见问题。
1 数据分析基础
数据分析的完整流程
数据-》信息-〉了解现状-》发现原因-〉获取洞察-》问题机会-〉驱动改变-》迭代增长-〉回到数据
3个关键点
- 数据。数据时分析的基础。数据是由指标组成的,指标主要分成2种:绝对值指标(例活跃用户数、下单人数等)、比例型指标(例下单转化率、搜索渗透率等)。
- 数据分析的过程。要用专业的数据分析思维和方法来进行分析(例5W2H、相关性分析等)。
- 例如,某电商APP下单转化率降低20%,这就是数据呈现的业务现状,我们需要通过分析去发现原因,获取洞察
- 数据分析的结果。通过分析挖掘,定位出问题的原因,并且给出相对应的结论。
- 例如,我们发现下单转化率降低主要是由于用户活跃到浏览商品环节引起,可能是用户不喜欢我们推荐的商品。我们可以给业务方提出建议:优化推荐结果或搜索结果。也是流程中说的驱动改变、迭代增长。
数据分析的4个作用
- 分析原因
- 用户活跃度降低的原因?销售收入降低的原因?。。。
- 评估效果
- 评估投放不同金额优惠券的策略哪个有效。
- 可以通过核心指标的变化来评估不同策略的效果
- 产品迭代
- 分析产品功能升级对指标的变化
- 用户增长
- 利用用户增长模型AARRR,通过指标分析更好的增长策略
数据分析的步骤
-
明确分析目的
-
常见3种目的
-
指标波动型(某些指标下降、上涨或异常的分析,例如用户留存率降低)
-
评估决策型(某个功能、活动上线的效果评估)
-
专题探索型(例体验类的专题分析,如何提高用户查找表情的效率)。
-
-
-
数据获取
- 通常要注意提取的维度(例时间、设备、年龄性别地域、新老用户维度)和对应的指标(例活跃浏览比、浏览添加比、添加下单比、成功下单率)个数。
-
数据处理
- 常见有异常值处理、空值处理
-
数据分析
- 根据分析目标,选择合适的分析方法和分析思路
-
数据可视化
-
总结与建议
数据分析师的日常工作
- 数据体系的搭建
- 作用:帮助企业监控产品各个功能模块的情况
- 策略模型的搭建
- 作用:针对业务的需求,帮助业务方解决业务问题
- 专题分析评估
- 作用:针对业务中的一些问题,开展专题分析
2 数据指标体系
什么是数据指标?
数据指标是通过对数据进行分析的一个汇总结果,是使得业务目标可描述、可度量、可拆解的度量值。数据指标不仅是数据,而且要被数据分析利用。
数据指标由“维度”和“计算方式”组成。
- 常见的维度有平台(IOS、安卓)、时间(日期)、新/老客户、年龄群体、渠道来源。。。
- 常见的计算方式有求和、求差、取均值/中位数、相除/相乘、最大/最小
举例:“安卓用户的平均观看时长”,维度是安卓,计算方式是平均观看时长,即取时长的均值。
什么是数据指标体系?
数据指标体系是把数据指标系统地组织起来,它面向功能模块或者其他业务模块。
以微信APP为例,微信有表情、朋友圈等业务模块,所以每一个业务模块都有自己的指标体系,对应的,微信表情指标体系、朋友圈指标体系等。微信表情指标体系中包含表情相关的数据指标有:用于评估表情发送的,有表情发送人数/次数/个数、发送时长、发送渗透率等。
为什么搭建数据指标体系?
- 监控现状
- 反映问题
- 预测趋势
- 评估分析
- 决策支持
常见的数据指标体系
互联网产品典型的数据指标体系
- 拉新指标
- 活跃指标
- 留存指标
- 付费指标
- 传播指标
电商平台的数据指标体系
- 用户
- 平台
- 商品
3 如何搭建数据指标体系
什么是数据埋点?
埋点:就是在APP中特定的位置或者功能中埋下数据点,以收集一些信息,用于追踪APP使用的状况,为后续优化产品或者运营提供数据支撑。
一般利用埋点,我们想获取用户的基本信息/行为信息。行为信息有在什么时间、哪个用户点击了哪个按钮、浏览了哪个页面、浏览时长的数据等。
埋点有2种方式。1.自己公司的研发人员在产品中注入代码,通常有客户端埋点和后台埋点。2.第三方统计工具,如友盟、神策、Talkingdata等。
为什么埋点?
- 产品迭代
- 精准用户运营
- 完善用户画像
- 产品指标计算
- 算法依赖
如何设计埋点方案?
4个要素
- 明确埋点目标
- 确认上报变量。帮助我们获取和用户操作行为相关的数据,如userid、device。。。
- 明确上报时机。例,用户点赞行为的时间、用户停留时长的上报。
- 明确优先级。重要数据优先上报。
埋点的开发流程
在埋点工作中,产品经理、数据分析师、开发人员需要合作参与。
具体流程有:
- 需求提出。业务方应该了解自己负责的产品的功能,明确当下关注的数据指标,并且可以把这种数据指标的需求准确地传达给数据分析师。
- 埋点梳理和设计。可以通过5W2H框架(Why, What, Where, When, Who, How, How much)来完成。
- 埋点开发
- 数据校验
- 数据使用
指标体系搭建方法论
利用科学的数据指标体系搭建方法,如北极星、OSM、AARRR等,去搭建一个完整的、科学的、高效的、业务向的、分析型+监控型的指标体系。
- OSM模型(Object业务目标 Strategy业务策略 Measure业务的度量)
- 其中,业务目标要符合DUMB原则(Doable切实可行、Understandable易于理解、Manageable可干预可管理、Beneficial正向有益)
- 该模型从简洁的思路出发,以目的->方法->评估为线,协助企业。
- UJM模型(User Journey Map用户旅程地图)
- 梳理出完整的用户行为路径,在每个环节设计相对应的指标进行评估。
- AARRR模型(Acquisition获取、Activation活跃、Rentention留存、Revenue变现、Referral推荐)
- 从用户获取、用户活跃、用户留存、用户变现、用户推荐这5个阶段,设计数据指标体系。
数据指标体系搭建步骤
通常有以下步骤。
- 需求提出。明确业务方的需求,例如评估表情包业务的健康情况及用户的活跃度。
- 指标规划。利用OSM模型+UJM模型。明确业务目标,例如提高表情发送次数;再思考出比较原始的大纲策略,例如“让用户可以更快找到表情”、“让用户有想发表情的欲望”;最后在M度量层面,利用UJM模型,列出业务的具体流程,得出相应的数据指标。
- 数据采集。把数据指标对应的埋点确定好,让开发人员采集。
- 指标计算。经过数据清洗、加工、汇总,获得可以被利用的数据。
- 搭建报表。
4 数据分析方法论
我们可能需要探究用户留存率降低、或活跃度降低的原因,能想出一些零散的解决方法。但是数据分析方法,能将这些零散的想法和经验整理成有条理的、系统的思路,从而快速解决问题。
营销管理方法论
下面介绍几个经典、传统的营销管理方法。
- SWOT分析
SWOT分析【Strengths, Weakness, Opportunity, Treats】来自企业管理理论中的战略规划,又名态势分析。
- PEST分析
PEST分析【Polirics, Economic, Society, Technology】是外部环境分析的一种方法。
- 4P理论
4P理论主要包括Product,Place渠道,Price,Promotion推广 。
常用数据分析方法论以及应用
对比&细分
细分相当于从多个维度分析,然后细化成多个类别。对比简单来说就是和先前同期等作对比。
假如活跃人数降低,可以细分的维度有时间(天、月、年?)、用户(新、老用户?不同设备用户?)、地区等。
然后需要对比,对比是在细分的基础上选择合适的指标进行对比,比如分析今天的朋友圈和上周同一天的转发情况如何。
其实在数据分析报告中,细分和对比也是贯穿整个数据报告的一种思维。
生命周期分析法
生命周期分析法主要目的是保留将要流失的用户。每一个用户在某个产品都存在生命周期——获取用户(首次转化)、用户成长(活跃拉升)、用户不断成熟(流失干预)、用户衰退(流失换回)。
但是挽留用户有成本,我们要干预即将流失的用户、以及刚流失不久的用户,因此要精准地识别出他们,否则会增加成本。这里有流失周期的概念,也就是用户在一定时期内没有活跃的时间点,这是干预用户的最佳时间段。
有2种寻找用户流失周期的方法:
- 分位数法
前提知识:分位数(Qunantile)的概念。
首先要计算一定数量的用户活跃的时间间隔,例如用户a使用该产品3天,用户b使用该产品23天等。。。我们可以取90%的用户的活跃时间间隔都在某个周期以内的时间点为流失周期。例如,72天以内,距首次注册到最后一次登录的用户数占比达90%,可以将72天作为用户的流失周期。
- 拐点法
以天、周或年为单位,统计每个单位时间点的留存人数(率)。一般来说,下降较大的时间点成为拐点,可以作为流失的分界点,也就是流失周期。之后时间里,留存人数(率)保持比较稳定的水平。
RFM用户分群法
RFM用户分群法用于划分用户,针对不同的用户采取不同的运营策略,称作精细化运营。它利用用户付费行为的多个特征来对用户的价值进行划分,可以有效地解决这种分群的问题。
- R-Recency-最近一次消费
- F- Frequency-消费频率
- M- Monetary-消费金额
根据数值的高低,一共有9种类别。例如,R值低,F值高,M值高,成为重要价值用户,这种用户价值度非常高,因为忠诚度高,付费频次高,付费金额也高。
根据不同的类别,需要采取不同的策略。比如重要召回用户(交易金额和次数多,但最近无交易),需要运营/业务人员对其进行召回(可用红包、奖励、优惠券等方式)。
相关性分析
以留存率为例,产品经理如果想关注用户留存率和哪些指标相关,就需要使用相关性分析,观察哪些指标有相关性,相关性程度多大。
相关性大小一般用相关系数R来描述,>0.95为显著性相关,>=0.8为高度相关,0.5<=R<0.8为中度相关,0.3<=R<0.5为低度相关,<0.3为不相关。
我们可以用python的seaborn.sns库进行相关性分析。
用户画像分析
作为企业方,他们想知道用户是什么样的,因此用年龄、性别、收入等特征描述用户,这就是用户画像分析。它能帮助产品策略人员发掘用户的价值、帮助产品运营人员利用群体特征寻找新用户、挽留老用户。
基于软件里统计到的数据;对数据进行处理,将用户进行聚合,再做成报表汇总数据;最后再应用在软件当中。
Aha时刻
Aha时刻也被称为惊喜时刻,是用户第一次使用产品时的惊喜体验。在渠道吸引了用户后,就需要APP做好相应的承接工作,让用户发现产品的价值,发现能让用户留存的Aha时刻。
5W2H分析法
5W2H为我们提供问题的分析框架。
- What?问题是什么?本质是什么?
- When?问题发生在什么时候?
- Where?何地?或者哪个功能有问题?
- Who?谁?哪个用户群体?
- Why?为什么会这样?出现什么问题?
- How?怎么做?策略?方法?
- How much?解决成本?解决到什么程度?
麦肯锡逻辑树分析法
逻辑树把已知的问题比作树干,然后考虑哪些问题或任务与已知问题有关,将这些问题或子任务比作逻辑树的树枝,一个大的树枝还可以继续延伸出更小的树枝,逐步列出所有与已知问题相关联的问题。
逻辑树满足以下3个原则:
- 要素化:把相同问题总结归纳成要素。
- 框架化:将各个要素组织成框架,遵守不重不漏的原则。
- 关联化:框架内的各要素保持必要的相互关系,简单而不孤立
逻辑树的作用:
- 将业务的整体目标进行结构化拆解,然后转化成可以量化的数据指标,再转变为指标体系。
- 分析数据问题。例,针对用户订单数减少的问题,从多个维度思考,定位可能的流失原因,再用数据验证。
- 它可以帮助分析DAU(日活跃)下降的因素。
漏斗分析法
漏斗分析是一种可以直观呈现用户行为步骤及各步骤之间转化率的分析方法。
以淘宝购物为例,从打开淘宝APP到搜索商品、查看商品详情、添加购物车、下单,到成功交易,漏斗分析法帮助我们计算每一个环节的转化率。
漏斗分析法的作用:
- 功能优化。在哪个阶段转化率特别低,可能是功能出现了问题。
- 运营投放。查看优惠投放对用户的效果,对没有效果的用户进行对照分析
- 用户流失。实质上还是分析哪个阶段/哪条路径出现问题
在用户增长分析中最著名的漏斗模型叫做AARRR,即从用户获取、用户激活、用户留存、用户付费到用户传播。从上往下的漏斗。
以拼多多为例,用户获取上,利用“帮朋友砍一刀”功能激励其他用户下载APP;在用户激活上,发放拼多多百亿补贴,促使用户与其他平台比价,尝试消费;用户留存上,采取签到白嫖小商品的策略,激励用户每天登录。。。
5 用户留存分析
什么是用户留存?
留存用户,即经过一段时间后,仍然继续使用该应用的用户。这部分用户占当时新增用户的比例,即用户留存率,会按照每个单位时间(例如日、周、月)来进行统计。
以第1日留存率(即“次留”)为例:(当天新增店小二用户中,新增日之后的第1天还登录的用户数)/第1天新增总用户数。
为什么要用户留存分析?
我们在加大广告投放,提高APP曝光,带来新用户的同时。也需要关注用户的留存情况。避免一边不断地获取新用户,一边用户不断地流失的情况。
留存是一方面帮助拉新和激活,把用户沉下来,另一边牵着转化和口碑,让真正沉下来的用户,更好地转化和传播。
5个关注留存的理由:
- 10%的用户在下载APP的一周后仍继续使用,一个月后,这个数字只有2.3%。
- 52%的APP会在3个月后失去至少一半的重度用户。
- 获取新用户的成本比留存现有用户的成本高5倍以上。
- 老用户比新用户尝试新功能的可能性高50%。
- 公司未来80%的收入将来自20%的现有用户。
用户留存分析方法论
一共有4步:
1 关键行为特征数据的提取
自己思考有哪些用户的行为回影响到用户留存率,然后将猜想的因素与相关的业务人员进行沟通,再完整地提取数据。
2 相关性分析
挖掘与留存率相关的用户行为,以及把这些相关性量化。
3 因果分析
利用因果推断方法(例如Granger Test因果检验),分析哪些行为是造成用户留存率高的原因。
4 Aha时刻
当我们已经判断了某个行为就是用户留存率高的原因时,挖掘出用户的Aha时刻,然后针对用户的Aha时刻涉及的产品模块去优化。
以直播APP用户留存分析为例,
- 猜想与留存率相关的行为有登录行为、观看行为、弹幕行为、付费行为。然后再细化数据指标,例观看行为有:30天观看主播数;30天观看品类个数;30日日均观看时长。
- 使用pandas库的corr()等方法,分析用户留存率与这些特征的相关性。假设与留存相关最大的4个因素如下:30天或者7天登录天数;30天观看品类个数;30天观看主播数;30天日均观看时长。
- 相关性不等于因果相,目前还无法判断登录活跃和用户留存率高哪个是因、哪个是果。使用格兰杰因果关系检验,可知因果关系如下:30天登录天数、30天日均观看时长、30天观看品类个数是留存的原因;30天充值次数是留存的原因,但留存不是30天充值次数的原因。
- 寻找这些行为达到一个怎样的值后,会大大影响留存率。以因果数据指标为横坐标,用户留存率为纵坐标,寻找大幅增加留存率的转折点。例:月登录4天,周登录3天,月观看7个主播数,月日均观看时长4分钟是促进留存的Magic Number。
6 用户特征分析
为什么要用户特征分析?
想要做一个成功的产品,就要了解产品面向用户的需求,根据用户的需求,更好地解决用户痛点,更好地满足用户需求。
用户需求分析的3大应用场景:
1 寻找目标客户(我们的用户是谁、活跃的用户是谁、流失的用户是谁)
分为2种:
1.1 虚拟的目标用户分析
业务方希望按照业务逻辑假设确定一部分人群作为目标用户,在这个新产品研发出来后,先让这些目标用户体验。根据他们的反馈来迭代和改进产品。
1.2 真实的目标用户分析
利用产品上线以后真正使用产品的用户数据,分析这些用户的基础属性特征,包括年龄、性别、城市,以及用户的行为特征等。起初,分析用户是谁,发现现在的主流群体是不是产品最开始的定位;上线一段时间后,可以对用户进行不同活跃等级的划分;再过一段时间,分析留存和流失的用户在行为特征上的差异。
2 寻找运营抓手(拉新、减流、促活)
根据用户特征分析的结论,运营方从这些结论中寻找可以施加策略的地方,这些地方就是所谓的抓手。为了增加活跃度,分析留存用户具有的典型行为特征,使用抓手针对性地让用户具有这些行为特征。
3 精细化运营(活跃分层、付费分层、潜力分层)
粗放式运营是让所有用户看到的东西都是一样的,根据大众最终的实验效果去反馈运营策略。
而精细化运营会比较细致,针对不同生命周期的用户、同一生命周期的不同类用户,甚至是每个用户,展示不同的内容,采取不同的运营策略,完成最终的转化。
用户特征分析的方法
常见方法有用户画像分析、聚类分析(k-means算法)、监督模型(决策树)、RFM用户分群。
评估用户特征
- 要与业务方的目标一致
- 结论要被业务方理解
- 圈出用户数量要足够。为了达到定向运营的标准,需要筛选足够的用户基数。
- 用户特征分析足够置信
7 用户流失分析
什么是用户流失?
首先介绍,用户的活跃、沉默、唤醒,它们是客观存在的。而流失是主观定义的。
- 活跃:一段时间内的用户活跃次数,比如日活、周活、月活。
- 沉默:一段时间内用户活跃次数为0,比如沉默一周、沉默30天。
- 唤醒:沉默一段时间后的用户又重新活跃。
由此,定义流失:是指沉默超过一定时长的用户,且该时长之后用户的自然回流率很低。流失时长可以参考用户的沉默时长曲线,横轴是沉默时长,纵轴是用户数,沉默曲线的拐点就是用户流失的时间点。
沉默时长超过流失时长的用户,为流失用户。流失之后又被唤醒的用户,定义为回流用户。当然也可以简单地定义流失用户(周流失、月流失【或者说周沉默、月沉默用户】)
我们还需要预测哪些用户会流失,提前针对这批用户进行运营。常见的方法有基础属性分析(对比非流失用户的年龄、性别、地域等特征)和行为属性分析(登录、观看、订阅等行为的特征规律)。
如何召回流失用户?
- RFM分析。通过用户分群识别优质用户,确定用户流失类别来采取合适的召回策略。
- 消息推送和发送邮件。发送感兴趣的东西,比如内容型产品推送感兴趣的视频、小说、音乐等。或者推送优惠券等福利类的推送。
- 邀请用户填写反馈信息,并采取措施。当决定采纳任何修改建议后,让用户知道你在听取他们的意见。
- 提供个性化服务。指派专门的服务代表随时为用户提供疑难解答。为用户提供各种联系渠道。
相关文章:

《数据分析方法论和业务实战》读书笔记
《数据分析方法和业务实战》读书笔记 共9章:前两章入门,3-7章介绍基本方法,8章从项目实战介绍数据分析,9章答疑常见问题。 1 数据分析基础 数据分析的完整流程 数据-》信息-〉了解现状-》发现原因-〉获取洞察-》问题机会-〉驱动…...
)
华为OD机试 - 射击比赛(Python)
射击比赛 题目 给定一个射击比赛成绩单 包含多个选手若干次射击的成绩分数 请对每个选手按其最高三个分数之和进行降序排名 输出降序排名后的选手 ID 序列 条件如下: 一个选手可以有多个射击成绩的分数 且次序不固定如果一个选手成绩小于三个 则认为选手的所有成绩无效 排名忽…...

uniapp自定义验证码输入框,隐藏光标
一. 前言 先看下使用场景效果图: 点击输入框唤起键盘,蓝框就相当于input的光标,验证码输入错误或者不符合格式要求会将字体以及边框改成红色提示,持续1s,然后清空数据,恢复原边框样式;5位验证…...
基于SSM框架的生活论坛系统的设计与实现
基于SSM框架的生活论坛系统的设计与实现 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景…...

spring注解使用中常见的概念性问题
Spring注解使用中常见的概念性问题Configuration有什么用?Configuration和XML有什么区别?哪种好?Autowired 、 Inject、Resource 之间有什么区别?Value、PropertySource 和 Configuration?Spring如何处理带Configurati…...

Module理解及使用
ES6的模块化设计思想是静态化,也就是说,在编译的时候确定模块的依赖关系,以及输出输出入的变量。而CommonJS和AMD模块都是在运行时确定的。ES6的模块不是对象,而是通过export显示指定输出的代码,再通过import命令输入。…...

ngix 常用配置之 location 匹配规则
大家好,我是 17。 今天和大家详细聊聊 nginx 的 location 匹配规则 location 匹配规则 匹配规则在后面的 try_files 中有举例 location 按如下优先级匹配 绝对匹配,一个字符也不能差^~ 前缀匹配~(区分大小写), ~*(不…...
chatGPT与人形机器人,高泽龙接受中国经营报采访谈二者发展
1.相较于Chatgpt,人形机器人的市场前景有多大?答:人形机器人的市场前景可以用“无限大”来形容,这看起来很夸张而且并不合理,其实是客观而且中肯的。因为这个问题就仿佛是五十年前,人们问“未来的电脑市场有…...

进程同步——读者-写者问题
读者-写者问题 互斥制约与合作制约双重关系的进程同步问题描述是: 一个被多个进程共享的文件、记录或数据结构,允许进程对其执行读、写操作。读进程称为读者,写进程称为写者。其允许多个进程同时读取,但只要有一个进程在读&#…...
Android自动化配置
1 搭建APPIUM环境 1.1 安装node.js Appium是使用nodejs实现的,所以node是解释器,需要第一步安装好 node.js的安装包下载地址: https://nodejs.org/en/download/ 注意:node.js的安装包的下载在官网有两种版本,建议大…...

Java程序怎么运行?final、static用法小范围类型转大范围数据类型可以吗?
文章目录1.能将int强制转换为byte类型的变量吗?如果该值大于byte类型的范围,将会出现什么现象?2. Java程序是如何执行的?3.final 在 Java 中有什么作用?4.final有哪些用法?5.static都有哪些用法?1.能将int强制转换为…...
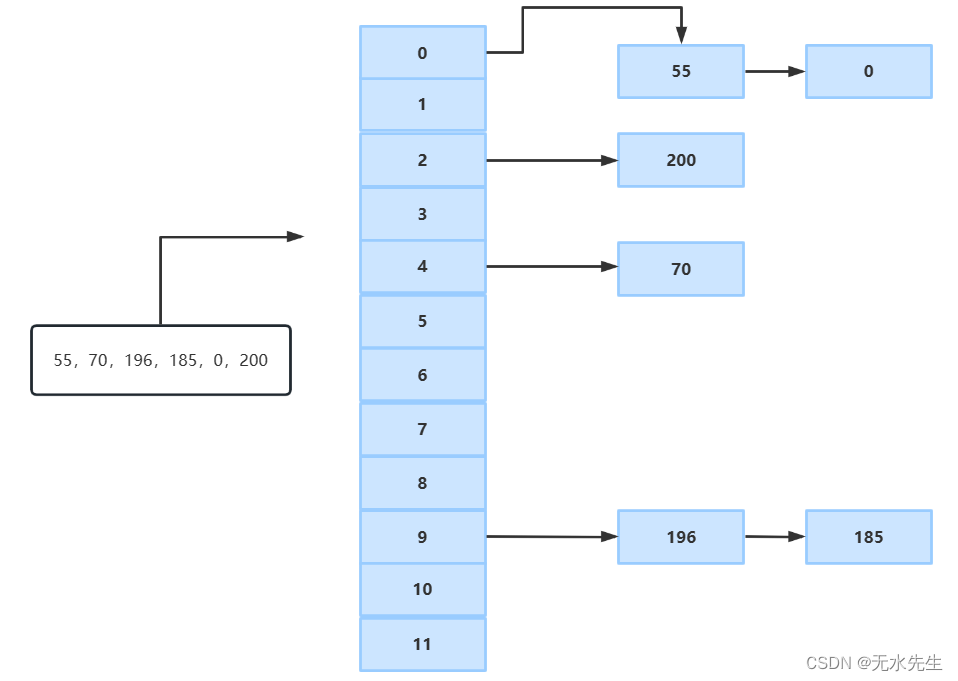
【数据管理】谈谈哈希原理和散列表
一、说明 提起哈希,有人要说:不就是一个稀疏表格么,谈的上什么原理?我说:非也,哈希是是那种看似无物,其实解决大问题的东西。如何提高数据管理效率?这是个问题,随着这个问…...

浙江工业大学关于2023年MBA考试初试成绩查询及复试阶段说明
根据往年的情况,2023浙江工业大学MBA考试初试成绩可能将于2月21日公布,为了广大考生可以及时查询到自己的分数,杭州达立易考教育为大家汇总了信息。 1、初试成绩查询:考生可登录中国研究生招生信息网“全国硕士研究生招生考…...

08:进阶篇 - CTK 插件元数据
作者: 一去、二三里 个人微信号: iwaleon 微信公众号: 高效程序员 元数据 元数据用于准确描述一个插件的特征,这样才能让 CTK Plugin Framework 适当地对 Plugin 进行各种处理(例如:依赖解析)。 CTK Plugin Framework 本身提供了一些清单头(元数据属性、条目),在 c…...
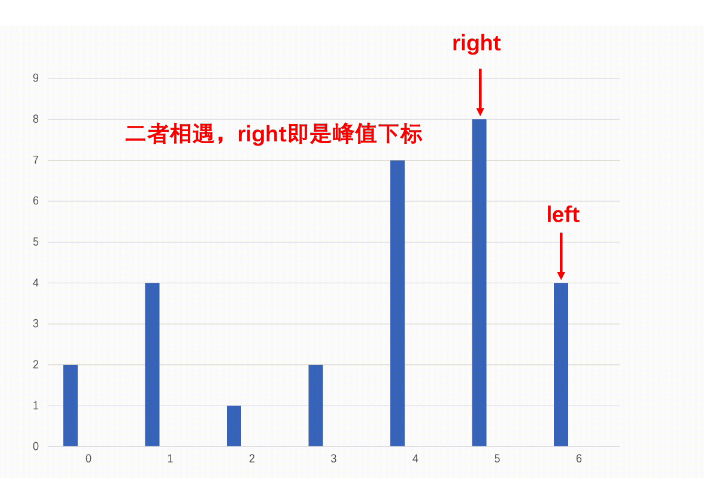
数据结构与算法之数组寻找峰值分而治之
这一篇分享一道在数组中寻找峰值的题目,使用到分而治之,二分查找等思想。本文章会讲解这个二分查找的本质,以及为什么要用二分查找,它能解决哪一类题目?目录:一.题目及其要求1.分而治之2.题目思路3.具体做法…...
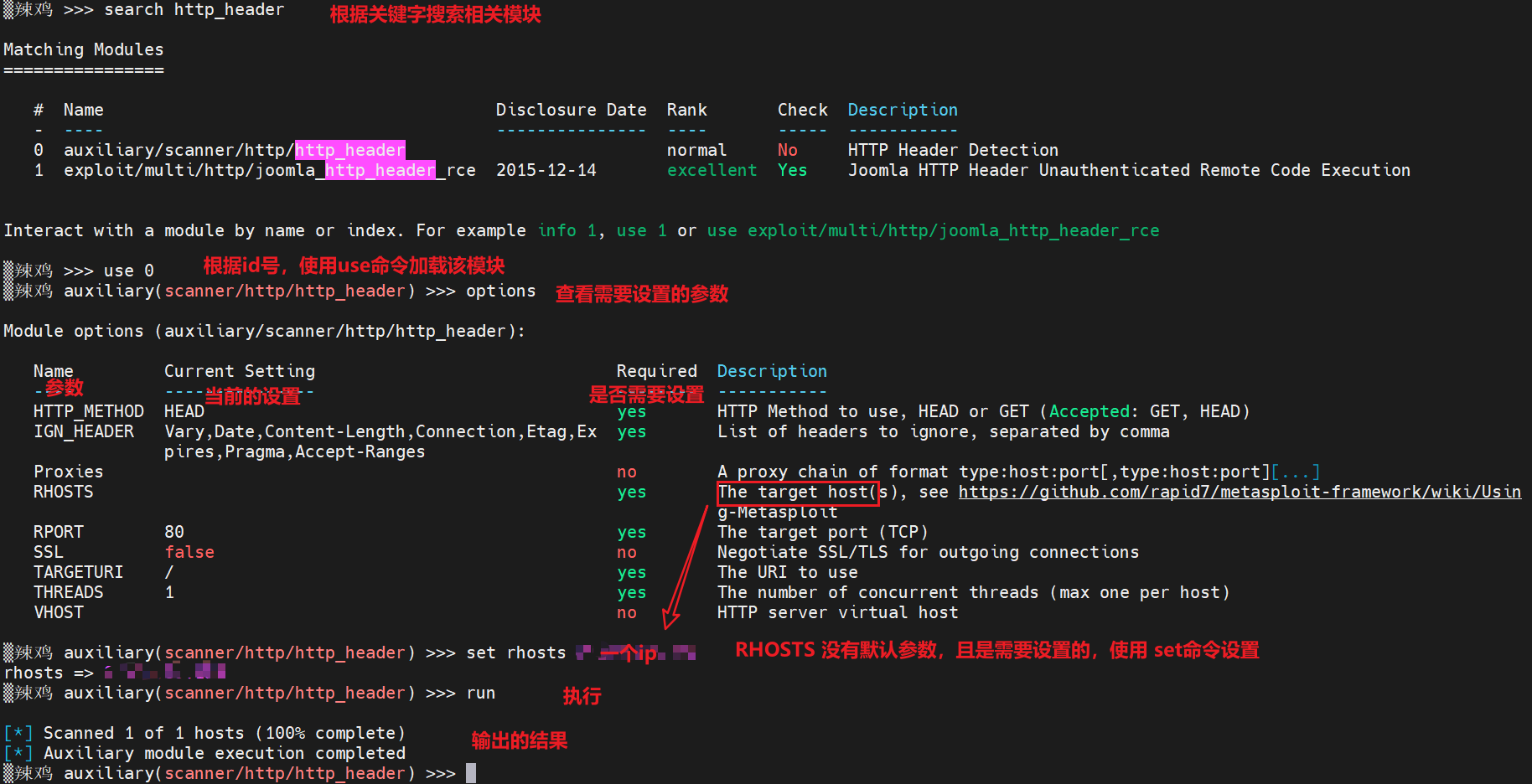
Metasploit 使用篇
文章目录前言一、msfconsole启动msfconsole命令分类核心命令模块命令作业命令资源脚本命令后台数据库命令二、使用案例更改提示和提示字符运行shell命令信息收集:HTTP头检测前言 理解了Meatasploit框架架构、原理之后,自然就很好理解它的使用逻辑 find…...
Java岗面试题--Java并发(日积月累,每日三题)
目录面试题一:并行和并发有什么区别?面试题二:线程和进程的区别?追问:守护线程是什么?面试题三:创建线程的几种方式?1. 继承 Thread 类创建线程,重写 run() 方法2. 实现 …...
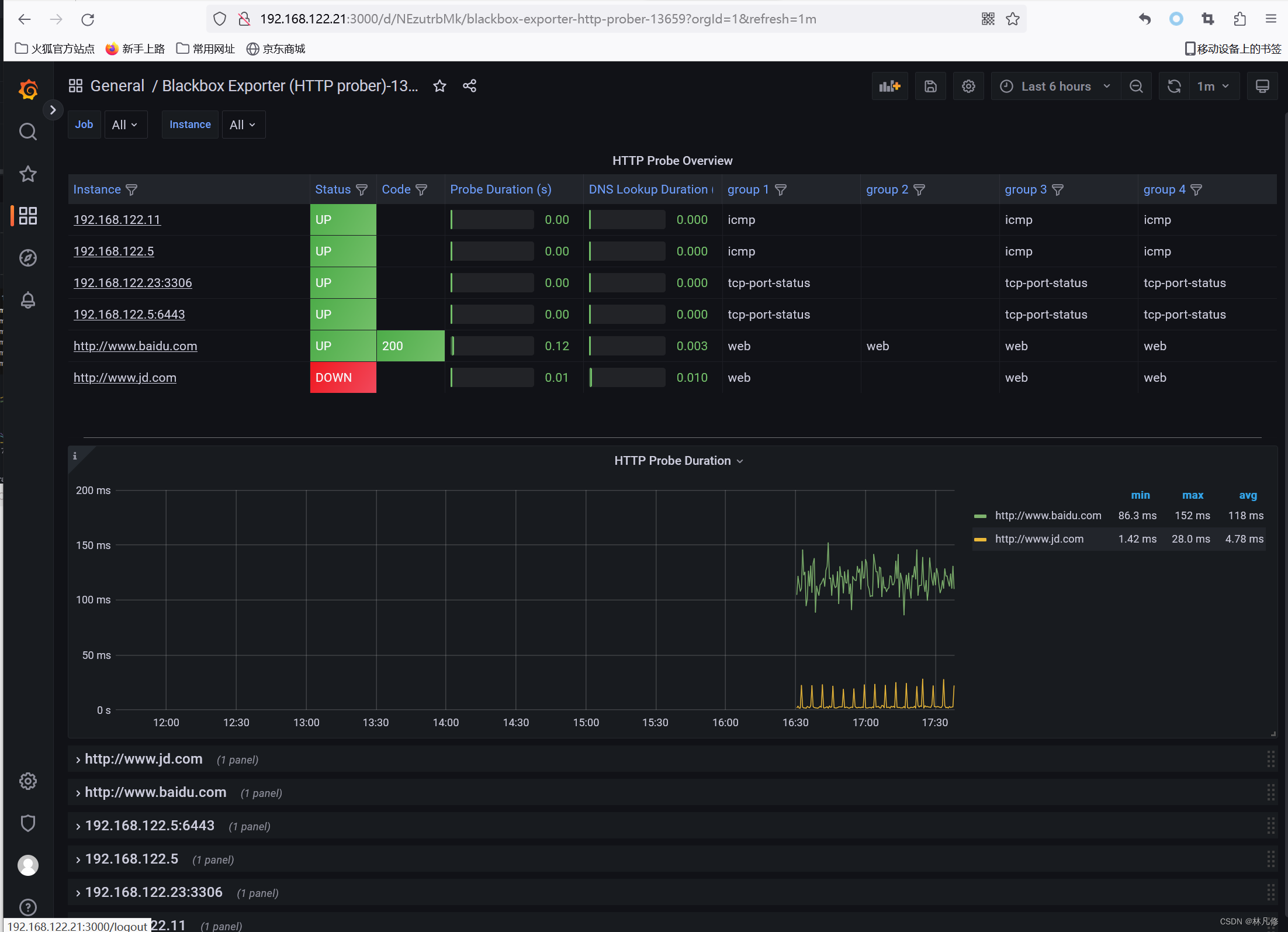
Prometheus监控案例之blackbox-exporter
blackbox-exporter简介 blackbox-exporter项目地址:https://github.com/prometheus/blackbox_exporter blackbox-exporter是Prometheus官方提供的一个黑盒监控解决方案,可以通过HTTP、HTTPS、DNS、ICMP、TCP和gRPC方式对目标实例进行检测。可用于以下使…...

Makefile基础使用和实战详解
Makefile基础使用和实战详解一、基础1.1、简单的Makefile1.2、多文件编译1.3、伪对象.PHONY二、变量2.1、自动变量2.2、特殊变量2.3、变量的类别2.4、变量及其值的来源2.5、变量引用的高级功能2.6、override 指令三、模式四、函数4.1、addprefix 函数4.2、filter函数4.3、filte…...

Go基础-变量
文章目录1 Go中的变量2 声明一个变量3 声明变量并初始化4 变量推断5 声明多个变量5.1 多个变量相同类型5.2 多个变量不同类型6 简短声明7 Go语言变量不能把一种类型赋值给其他类型1 Go中的变量 Go中变量指定了某存储单元的名称,该存储单元会存储特定类型的值&#…...

RocketMQ Dashboard 部署实战:从源码到生产可用的控制台
1. RocketMQ Dashboard 是什么? RocketMQ Dashboard 是 Apache RocketMQ 官方提供的可视化监控管理工具,相当于给 RocketMQ 装上了"仪表盘"。想象一下开车没有仪表盘,不知道油量、车速、发动机状态有多可怕?RocketMQ Da…...

移步皆海景处处可停留,读懂大连海岸的松弛质感
沿着大连的滨海路漫步,你会遇见这座城市最从容的一面。这条贯穿海滨风景线的道路,串联起星海广场、森林动物园、老虎滩海洋公园等多个开放型景观区域,核心特点在于它并不急于展示某个单一景点,而是将城市生活与自然海岸融为一体—…...

基于Circuit Playground Express与3D打印的机械心脏制作指南
1. 项目概述:一个会“呼吸”的机械心脏如果你对创客、STEAM教育或者互动艺术装置感兴趣,那么亲手制作一个能模拟真实心跳、并且心率可以手动调节的解剖心脏模型,绝对是一个能让你成就感爆棚的项目。这不仅仅是一个静态的展示品,它…...

基于Keel-Kit的GitOps自动化:轻量级镜像更新与部署实践
1. 项目概述:一个为现代应用交付而生的“舵手工具箱”如果你和我一样,长期在云原生和微服务架构的浪潮里扑腾,那你一定对“应用交付”这四个字背后的复杂性深有体会。从代码提交到最终服务上线,中间横亘着构建、打包、部署、配置、…...

朋升爱生活
我爱生活。...

DLSS Swapper终极指南:5分钟快速上手游戏性能优化神器
DLSS Swapper终极指南:5分钟快速上手游戏性能优化神器 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾为游戏中的DLSS版本过旧而烦恼?是否厌倦了手动下载、替换DLSS文件的繁琐过程&…...

从MC1496乘法器到DSB调制:一个经典电路的设计实践与参数解析
1. DSB调制基础与MC1496乘法器简介 第一次接触DSB调制电路时,我被那个看似简单的波形变换背后精妙的数学原理深深吸引。DSB(Double Sideband)双边带调制,本质上是用低频信号去控制高频载波的幅度,但与传统AM调制不同&a…...

如何快速上手MuseTalk:从零开始的实时高质量唇语同步完整指南
如何快速上手MuseTalk:从零开始的实时高质量唇语同步完整指南 【免费下载链接】MuseTalk MuseTalk: Real-Time High Quality Lip Synchorization with Latent Space Inpainting 项目地址: https://gitcode.com/gh_mirrors/mu/MuseTalk 想要为静态人物图像添加…...

Laravel-admin 数据权限审计终极指南:完整权限变更记录解决方案 [特殊字符]️
Laravel-admin 数据权限审计终极指南:完整权限变更记录解决方案 🛡️ 【免费下载链接】laravel-admin Build a full-featured administrative interface in ten minutes 项目地址: https://gitcode.com/gh_mirrors/la/laravel-admin 想要确保你的…...

Publify SEO优化完全指南:提升博客排名的7个关键策略
Publify SEO优化完全指南:提升博客排名的7个关键策略 【免费下载链接】publify A self hosted Web publishing platform on Rails. 项目地址: https://gitcode.com/gh_mirrors/pu/publify Publify是一款基于Ruby on Rails的自托管Web发布平台,也是…...