机器学习重要内容:特征工程之特征抽取
目录
1、简介
2、⭐为什么需要特征工程
3、特征抽取
3.1、简介
3.2、特征提取主要内容
3.3、字典特征提取
3.4、"one-hot"编码
3.5、文本特征提取
3.5.1、英文文本
3.5.2、结巴分词
3.5.3、中文文本
3.5.4、Tf-idf
⭐所属专栏:人工智能
文中提到的代码如有需要可以私信我发给你噢😊
1、简介
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
意义:会直接影响机器学习的效果
特征工程是机器学习中至关重要的一步,它涉及将原始数据转换为适合机器学习模型的特征(也称为变量或属性)。好的特征工程可以显著提高模型性能,因为它能够揭示数据中的有用信息,降低噪音影响,甚至帮助模型更好地泛化到新数据。
特征工程包含内容
- 特征抽取
- 特征预处理
- 特征降维
以下是特征工程的一些常见方法和技巧:
- 特征选择(Feature Selection):从原始特征集中选择最相关、最有用的特征,以降低模型的复杂性和过拟合风险。
- 特征提取(Feature Extraction):通过数学变换,将原始特征转换为更具信息量的特征,例如主成分分析(PCA)、独立成分分析(ICA)等。
- 特征转换(Feature Transformation):对原始特征进行变换,以使其更适合模型,如对数、指数、归一化、标准化等。
- 多项式特征扩展(Polynomial Feature Expansion):将原始特征的多项式组合添加到特征集中,以捕获特征之间的非线性关系。
- 时间序列特征处理:针对时间序列数据,可以提取滞后特征(lag features)、移动平均、指数加权移动平均等。
- 文本特征处理:对文本数据进行词袋模型(Bag-of-Words)、TF-IDF(Term Frequency-Inverse Document Frequency)处理,或者使用词嵌入(Word Embeddings)等技术。
- 类别特征编码:将类别型特征转换为数值型特征,例如独热编码(One-Hot Encoding)、标签编码(Label Encoding)等。
- 缺失值处理:处理缺失值的方法包括删除含有缺失值的样本、填充缺失值、使用模型预测缺失值等。
- 特征交互与组合:通过对特征进行交互、组合,创建新的特征来捕获更高级的信息。
- 数据降维:使用降维技术(如PCA)减少数据维度,以减少计算复杂性和噪音的影响。
- 领域知识引导:利用领域专业知识来设计和选择特征,以更好地捕获问题的本质。
在进行特征工程时,需要注意以下几点:
- 理解数据:深入了解数据的含义、结构和背景,以便做出更明智的特征工程决策。
- 避免过拟合:特征工程可能导致过拟合问题,因此需要谨慎选择和处理特征。
- 实验和迭代:尝试不同的特征工程方法,并使用交叉验证等技术来评估模型性能,以确定哪些方法有效。
- 自动化:一些自动化特征选择和提取工具可以帮助你快速尝试不同的特征工程技术。
总之,特征工程是机器学习中一个关键且有创造性的阶段,它能够显著影响模型的性能和泛化能力。
2、⭐为什么需要特征工程
机器学习领域的大神Andrew Ng(吴恩达)老师说“Coming up with features is difficult, time-consuming, requires expert knowledge. “Applied machine learning” is basically feature engineering. ”
业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
以下是特征工程的重要性和原因:
- 提取有用信息:原始数据可能包含大量的冗余或无关信息,特征工程能够通过选择、提取或转换特征,从中抽取出对问题有用的信息,提高模型的预测能力。
- 降低维度:某些问题可能涉及大量的特征,而高维度数据会导致计算成本的增加和过拟合的风险。特征工程可以通过降维技术(如主成分分析)减少数据维度,从而提高模型效率和泛化性能。
- 改善模型泛化:好的特征工程有助于降低模型在新数据上的错误率,提高模型的泛化能力,使其能够更好地适应未见过的数据。
- 处理缺失值和异常值:特征工程可以帮助处理数据中的缺失值和异常值,选择合适的填充策略或移除异常值,从而减少对模型的不良影响。
- 解决非线性关系:原始数据可能包含复杂的非线性关系,特征工程可以通过多项式特征扩展、特征交互和转换等方法,使模型能够更好地捕获这些关系。
- 提高模型解释性:通过特征工程,可以将数据转换为更易解释的形式,使模型的预测结果更具可解释性,有助于理解模型的决策依据。
- 适应不同模型:不同的机器学习模型对特征的需求不同,通过特征工程,可以根据模型的特点和假设来调整特征,提高模型性能。
- 利用领域知识:特征工程可以融入领域专业知识,根据问题背景和领域特点,选择和设计适用的特征,更好地捕获数据的本质。
总之,特征工程是机器学习流程中的关键步骤,它可以帮助我们将原始数据转化为更有意义、更适合模型的特征,从而提高模型的性能、泛化能力和解释性。特征工程的好坏直接影响着模型的效果,因此在实际应用中,合适的特征工程往往能够为机器学习任务带来显著的提升。
3、特征抽取
3.1、简介
特征抽取(Feature Extraction)是指从原始数据中自动或半自动地提取出具有代表性和信息丰富度的特征,以用于机器学习和数据分析任务。在特征抽取过程中,原始数据的维度可能会被降低,从而减少计算成本并提高模型的性能和泛化能力。
特征抽取的目标是将原始数据转换为更具有判别性和表达力的特征表示,以便更好地捕获数据中的模式、关系和变异。这有助于提高模型的训练效果,并且可以使模型更好地适应新的未见过的数据。
特征抽取的方法可以包括以下几种:
- 主成分分析(PCA):PCA是一种降维技术,通过线性变换将原始特征投影到一个新的坐标系中,使得投影后的特征具有最大的方差。这样可以将数据的维度减少,同时保留最重要的信息。
- 独立成分分析(ICA):ICA是一种用于提取独立信号的技术,适用于信号分离和降噪等场景,可以用于音频处理、图像处理等领域。
- 特征选择器(Feature Selectors):通过选择最相关或最重要的特征来降低维度,例如选择方差较大的特征、基于统计方法的特征选择等。
- 词袋模型(Bag-of-Words):在自然语言处理中,将文本数据转换为一个表示每个单词频次的向量,从而构建文本的特征表示。
- 傅里叶变换(Fourier Transform):用于将信号从时间域转换到频率域,常用于信号处理和图像处理领域。
- 小波变换(Wavelet Transform):类似于傅里叶变换,但可以同时提供时间和频率信息,适用于分析非平稳信号。
- 自编码器(Autoencoders):是一种神经网络结构,通过训练模型来学习数据的低维表示,常用于无监督学习任务。
特征抽取的选择取决于问题的性质、数据的类型以及任务的要求。它在处理高维数据、降低计算成本、提高模型泛化能力等方面具有重要作用,是特征工程的一个关键组成部分。
3.2、特征提取主要内容
1、将任意数据(如文本或图像)转换为可用于机器学习的数字特征
特征值化是为了计算机更好的去理解数据
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习将介绍)
2、特征提取API:sklearn.feature_extraction
3.3、字典特征提取
作用:对字典数据进行特征值化
sklearn.feature_extraction.DictVectorizer(sparse=True,…)
DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器返回值:返回sparse矩阵
DictVectorizer.inverse_transform(X) X:array数组或者sparse矩阵 返回值:转换之前数据格式
DictVectorizer.get_feature_names() 返回类别名称
from sklearn.feature_extraction import DictVectorizer # 实例化'''
sklearn.feature_extraction.DictVectorizer(sparse=True,…)DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器返回值:返回sparse矩阵DictVectorizer.inverse_transform(X) X:array数组或者sparse矩阵 返回值:转换之前数据格式DictVectorizer.get_feature_names() 返回类别名称
'''
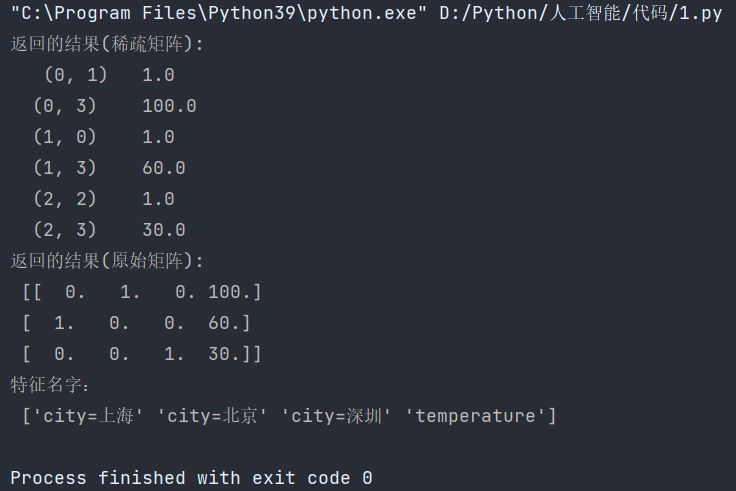
def dict_demo():"""对字典类型的数据进行特征抽取:return: None"""data = [{'city': '北京', 'temperature': 100},{'city': '上海', 'temperature': 60},{'city': '深圳', 'temperature': 30}]# 1、实例化一个转换器类transfer1 = DictVectorizer(sparse=False)transfer2 = DictVectorizer()# 2、调用fit_transformdata2 = transfer2.fit_transform(data)data1 = transfer1.fit_transform(data)print("返回的结果(稀疏矩阵):\n", data2)print("返回的结果(原始矩阵):\n", data1)# 打印特征名字print("特征名字:\n", transfer1.get_feature_names_out())if __name__ == '__main__':dict_demo()结果:
3.4、"one-hot"编码
"One-Hot"编码是一种常用的分类变量(也称为类别变量、离散变量)到数值变量的转换方法,用于将类别型数据表示为二进制向量的形式。这种编码方法在机器学习中广泛应用于处理类别型特征,以便将其用于各种算法和模型中。
在"One-Hot"编码中,每个类别被转换为一个唯一的二进制向量,其中只有一个元素为1,其余元素为0。这个元素的位置表示类别的索引或标签。这样做的目的是消除类别之间的顺序关系,以及用离散的0和1表示类别信息,使算法能够更好地处理类别型特征。
以下是一个简单的示例来解释"One-Hot"编码:
假设我们有一个表示动物种类的类别特征,包括猫、狗和鸟。"One-Hot"编码将这三个类别转化为如下形式的向量:
- 猫:[1, 0, 0]
- 狗:[0, 1, 0]
- 鸟:[0, 0, 1]
这样,每个类别都被表示为一个唯一的二进制向量,其中对应的位置为1,其余位置为0。
在Python中,可以使用各种工具和库来进行"One-Hot"编码,其中最常用的是Scikit-Learn(sklearn)库的OneHotEncoder类。
以下是一个简单的代码示例:
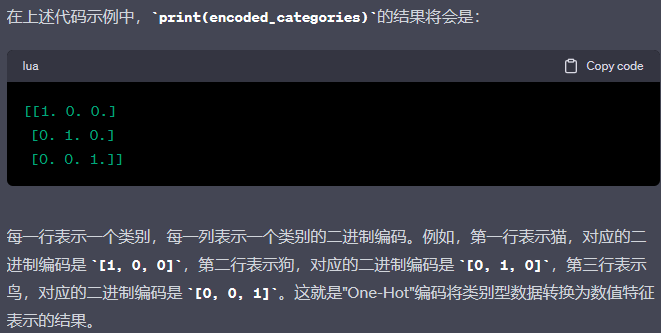
from sklearn.preprocessing import OneHotEncoder# 创建OneHotEncoder对象
encoder = OneHotEncoder()# 假设有一个包含动物种类的数组
animal_categories = [['猫'], ['狗'], ['鸟']]# 进行One-Hot编码
encoded_categories = encoder.fit_transform(animal_categories).toarray()# 打印编码结果
print(encoded_categories)结果:
3.5、文本特征提取
作用:对文本数据进行特征值化
sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) 返回词频矩阵
CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象 返回值:返回sparse矩阵
CountVectorizer.inverse_transform(X) X:array数组或者sparse矩阵 返回值:转换之前数据格
CountVectorizer.get_feature_names() 返回值:单词列表
sklearn.feature_extraction.text.TfidfVectorizer
3.5.1、英文文本
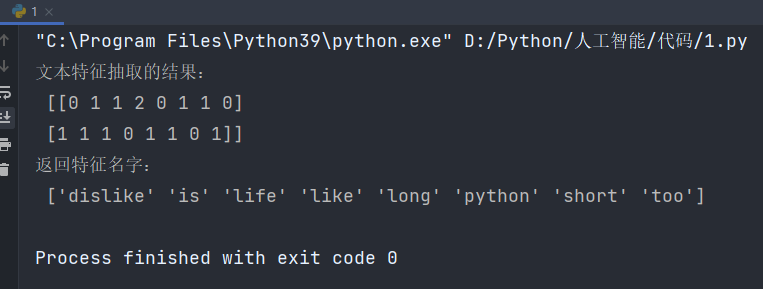
下面对以下文本进行分析:["life is short,i like python","life is too long,i dislike python"]
流程分析:
实例化类CountVectorizer
调用fit_transform方法输入数据并转换 (注意返回格式,利用toarray()进行sparse矩阵转换array数组)
from sklearn.feature_extraction.text import CountVectorizer # 文本特征提取'''
sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) 返回词频矩阵CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象 返回值:返回sparse矩阵CountVectorizer.inverse_transform(X) X:array数组或者sparse矩阵 返回值:转换之前数据格CountVectorizer.get_feature_names() 返回值:单词列表sklearn.feature_extraction.text.TfidfVectorizer
'''
def text_count_demo():"""对文本进行特征抽取,countvetorizer:return: None"""data = ["life is short,i like like python","life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata = transfer.fit_transform(data)print("文本特征抽取的结果:\n", data.toarray())print("返回特征名字:\n", transfer.get_feature_names_out())if __name__ == '__main__':text_count_demo()输出结果:
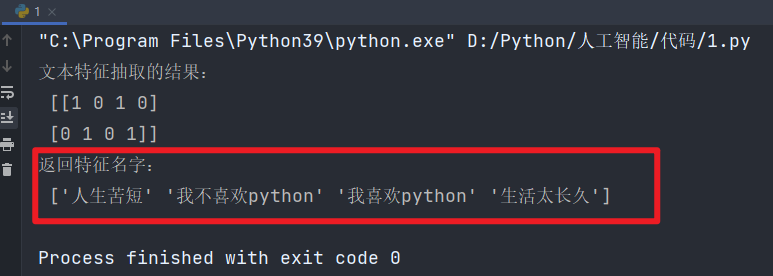
🔺如果替换成中文,则会出问题:"人生苦短,我喜欢Python" "生活太长久,我不喜欢Python"
为什么会得到这样的结果呢,仔细分析之后会发现英文默认是以空格分开的。
其实就达到了一个分词的效果,所以我们要对中文进行分词处理。
这里需要用到“结巴分词”
3.5.2、结巴分词
结巴分词(jieba)是一个流行的中文文本分词工具,被广泛应用于自然语言处理(NLP)任务中,如文本分析、信息检索、情感分析、机器翻译等。结巴分词是基于Python开发的开源项目,它提供了一种可靠高效的中文分词解决方案。
以下是结巴分词的一些特点和功能:
- 中文分词:结巴分词可以将中文文本切分成一个一个有意义的词语(词汇),从而为后续的文本处理和分析提供基础。
- 支持多种分词模式:结巴分词提供了不同的分词模式,包括精确模式、全模式、搜索引擎模式等,以适应不同的分词需求。
- 支持用户自定义词典:用户可以根据需要添加自定义的词典,用于识别领域特定的术语、词汇,从而提高分词的准确性。
- 高性能:结巴分词在分词速度上表现出色,可以处理大规模的文本数据。
- 支持繁体字分词:除了简体中文,结巴分词还支持繁体中文文本的分词。
- 词性标注:结巴分词可以对分词结果进行词性标注,帮助识别每个词语的词性,如名词、动词等。
- 适应多种任务:结巴分词不仅可以用于分词,还可以用于关键词提取、文本去重、文本相似度计算等任务。
3.5.3、中文文本
案例分析:
对以下三句话进行特征值化:
今天很残酷,明天更残酷,后天很美好,
但绝对大部分是死在明天晚上,所以每个人不要放弃今天。
我们看到的从很远星系来的光是在几百万年之前发出的,
这样当我们看到宇宙时,我们是在看它的过去。
如果只用一种方式了解某样事物,你就不会真正了解它。
了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。
分析:
准备句子,利用jieba.cut进行分词
实例化CountVectorizer
将分词结果变成字符串当作fit_transform的输入值
from sklearn.feature_extraction.text import CountVectorizer # 文本特征提取
import jieba # 结巴分词'''
使用结巴分词,对中文特征进行提取
'''
def text_chinese_count_demo2():"""对中文进行特征抽取:return: None"""data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]# 将原始数据转换成分好词的形式text_list = []for sent in data:text_list.append(" ".join(list(jieba.cut(sent)))) # 这里使用结巴分词print(text_list)# 1、实例化一个转换器类# transfer = CountVectorizer(sparse=False)transfer = CountVectorizer()# 2、调用fit_transformdata = transfer.fit_transform(text_list)print("文本特征抽取的结果:\n", data.toarray())print("返回特征名字:\n", transfer.get_feature_names_out())if __name__ == '__main__':text_chinese_count_demo2()结果:

但如果把这样的词语特征用于分类,会出现什么问题?
该如何处理某个词或短语在多篇文章中出现的次数高这种情况?
这种情况下,我们需要用到"Tf-idf文本特征提取"。
3.5.4、Tf-idf

TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征提取方法,用于将文本数据转换为数值特征表示,以便用于机器学习和信息检索任务。
TF-IDF反映了一个词在文本中的重要性,同时考虑了词频和文档频率的影响。
TF-IDF文本特征提取的原理如下:
- 词频(Term Frequency,TF):表示一个词在一篇文档中出现的频率。计算方法为:一个词在文档中出现的次数除以文档的总词数。
- 逆文档频率(Inverse Document Frequency,IDF):表示一个词在所有文档中的普遍程度。计算方法为:总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数。IDF的目的是降低常见词对文档区分能力的影响。
- TF-IDF:将词频和逆文档频率相乘,得到一个词在文档中的重要性得分。高频出现但在其他文档中不常见的词,得分会相对较高。
公式:

TF-IDF的优点在于它可以凸显文本中的关键词,过滤掉一些无意义的常见词,并为文本赋予数值特征,使得文本数据适用于各种机器学习算法。
案例:
from sklearn.feature_extraction.text import TfidfVectorizer # TF-IDF特征提取
import jieba # 结巴分词'''
提取TF-IDF特征
'''
def text_chinese_tfidf_demo():"""对中文进行特征抽取:return: None"""data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]# 将原始数据转换成分好词的形式text_list = []for sent in data:text_list.append(" ".join(list(jieba.cut(sent)))) # 这里使用结巴分词print(text_list)transfer = TfidfVectorizer(stop_words=['一种', '不会', '不要'])# 2、调用fit_transformdata = transfer.fit_transform(text_list)print("文本特征抽取的结果:\n", data.toarray())print("返回特征名字:\n", transfer.get_feature_names_out())if __name__ == '__main__':text_chinese_tfidf_demo()TF-IDF特征提取如下:
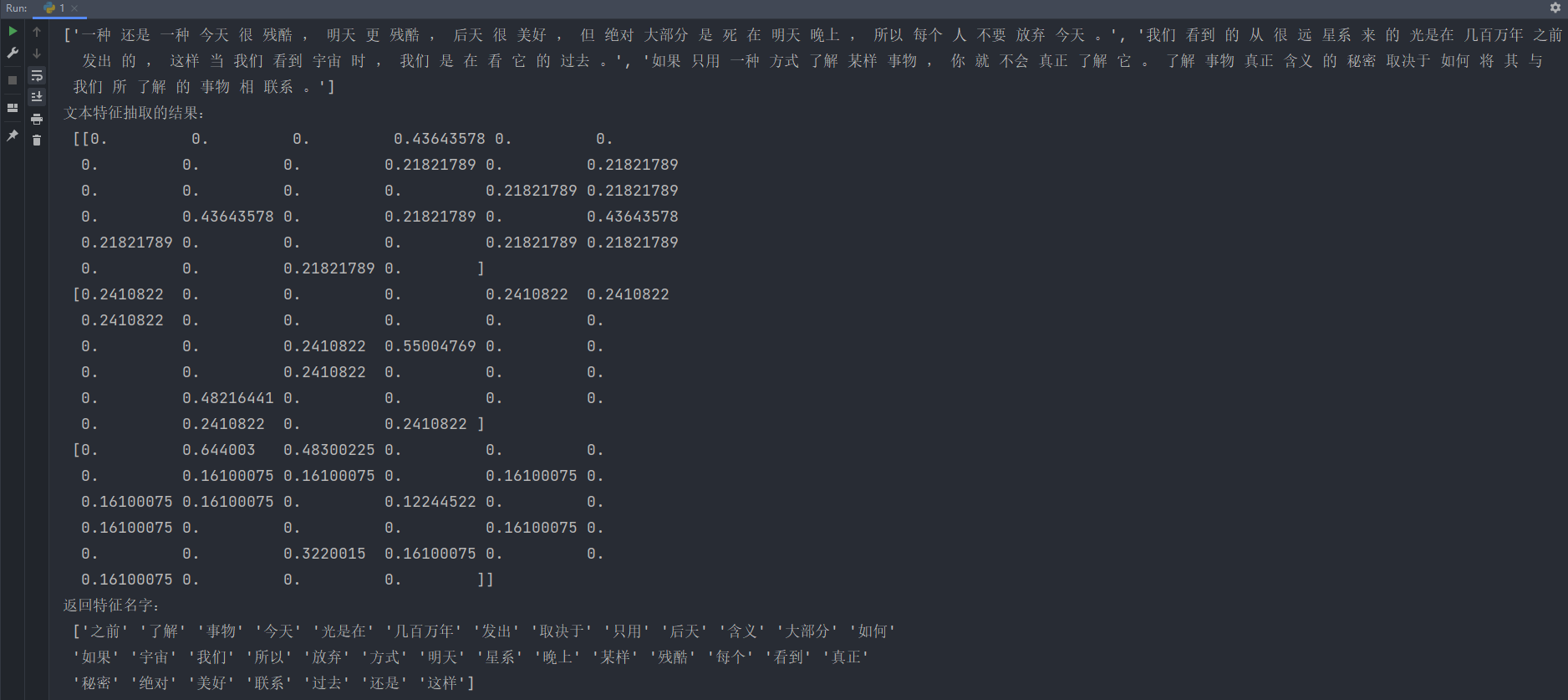
这段输出表示TF-IDF文本特征抽取的结果,是一个特征矩阵,其中每一行代表一个文本样本,每一列表示一个单词的TF-IDF得分。
TF-IDF(词频-逆文档频率)是一种用于衡量一个词在文本中的重要性的指标,结合了词频(TF)和逆文档频率(IDF)。TF-IDF越高,说明该词在当前文本中越重要且越不常见于其他文本。
以下是对输出矩阵的解释:
- 第一行:表示第一篇文本样本的TF-IDF特征向量。特征向量中的每个元素表示对应单词的TF-IDF得分。例如,"今天"的TF-IDF得分是0.43643578,"很"的得分是0.21821789。
- 第二行:表示第二篇文本样本的TF-IDF特征向量。例如,"我们"的TF-IDF得分是0.2410822,"光"的得分是0.55004769。
- 第三行:表示第三篇文本样本的TF-IDF特征向量。例如,"了解"的TF-IDF得分是0.644003,"事物"的得分是0.3220015。
在这个特征矩阵中,每一行表示一个文本样本,每一列对应一个单词(词汇表中的词)。
每个元素表示对应单词在对应文本中的TF-IDF得分。
这个矩阵将文本数据转换为数值特征表示,可以作为机器学习算法的输入。
通常情况下,为了方便理解,这些得分会在实际应用中进行归一化或者规范化处理。
Tf-idf的重要性:分类机器学习算法进行文章分类中前期数据处理方式
相关文章:
机器学习重要内容:特征工程之特征抽取
目录 1、简介 2、⭐为什么需要特征工程 3、特征抽取 3.1、简介 3.2、特征提取主要内容 3.3、字典特征提取 3.4、"one-hot"编码 3.5、文本特征提取 3.5.1、英文文本 3.5.2、结巴分词 3.5.3、中文文本 3.5.4、Tf-idf ⭐所属专栏:人工智能 文中提…...
Logic 2逻辑分析器捉到的CAN帧
代码开发环境 逻辑分析仪环境 MCU芯片环境:RH850/U2A16 逻辑分析器(LA)抓到的CAN帧 <完>...

手机的发展历史
目录 一.人类的通信方式变化 二.手机对人类通信的影响 三.手机的发展过程 四.手机对现代人的影响 一.人类的通信方式变化 人类通信方式的变化是一个非常广泛和复杂的话题,随着技术的进步和社会的发展,人类通信方式发生了许多重大的变化。下面是一些主…...
为什么要分库分表?
不急于上手实战 ShardingSphere 框架,先来复习下分库分表的基础概念,技术名词大多晦涩难懂,不要死记硬背理解最重要,当你捅破那层窗户纸,发现其实它也就那么回事。 什么是分库分表 分库分表是在海量数据下࿰…...

Unity游戏源码分享-中国象棋Unity5.6版本
Unity游戏源码分享-中国象棋Unity5.6版本 项目地址: https://download.csdn.net/download/Highning0007/88215699...
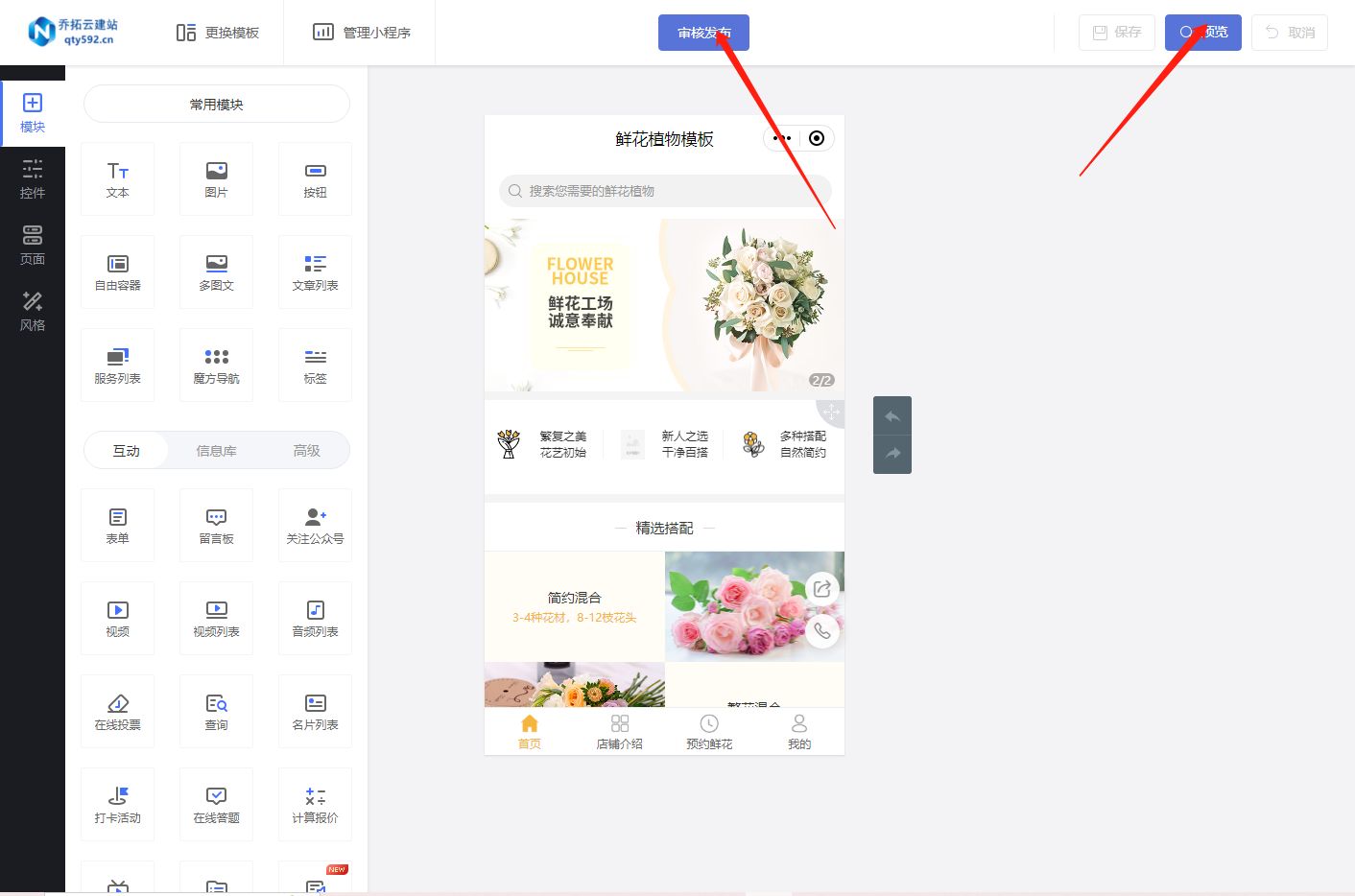
打造专属花店展示小程序
在当今社会,微信小程序已经成为了各行各业拓展客户资源的利器,而花店行业也不例外。通过打造一个独特的花店小程序,你可以为你的花店带来更多的曝光和客户资源。那么,如何制作一个专属的花店小程序呢?下面我们就来一步…...
SpringBoot整合、SpringBoot与异步任务
目录 一、背景描述二、简单使用方法三、原理五、使用自定义线程池1、默认使用2、如何使用自定义线程池 六、Async失效情况1、同一个类中,一个方法调用 Async标注的方法 一、背景描述 java 的代码是同步顺序执行,当我们需要执行异步操作时我们通常会去创…...

复习1-2天【80天学习完《深入理解计算机系统》】第六天
专注 效率 记忆 预习 笔记 复习 做题 欢迎观看我的博客,如有问题交流,欢迎评论区留言,一定尽快回复!(大家可以去看我的专栏,是所有文章的目录) 文章字体风格: 红色文字表示&#…...
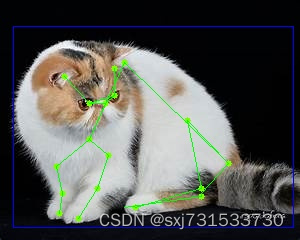
62、华为昇腾开发板Atlas 200I DK A2配置mmpose的hrnet模型推理python/c++
基本思想:适配mmpose模型,记录一下流水帐,环境配置和模型来自,请查看参考链接。 链接: https://pan.baidu.com/s/1IkiwuZf1anyKX1sZkYmD1g?pwdi51s 提取码: i51s 一、转模型 (base) rootdavinci-mini:~/sxj731533730# atc --mo…...

【数据结构】双链表
大家好!今天我们来学习数据结构中的双链表。(我们这里讲解的是带头(哨兵位)双向循环链表哦~) 目录 1.双链表的概念 2. 双链表的逻辑结构 3. 双链表的定义 4. 双链表的接口实现 4.1 动态申请一个新结点 4.2 双链表…...

android设置竖屏仍然跟随屏幕旋转怎么办
如题所问,我最近遇到一个bug,就是设置了摇感,然后有用户反馈说设置了手机下拉的系统设置-屏幕旋转-关闭。然后屏幕还是会旋转的问题。 首先,我们先从如何设置横竖屏了解下好了 设置横屏和竖屏的方法: 方法一&#x…...
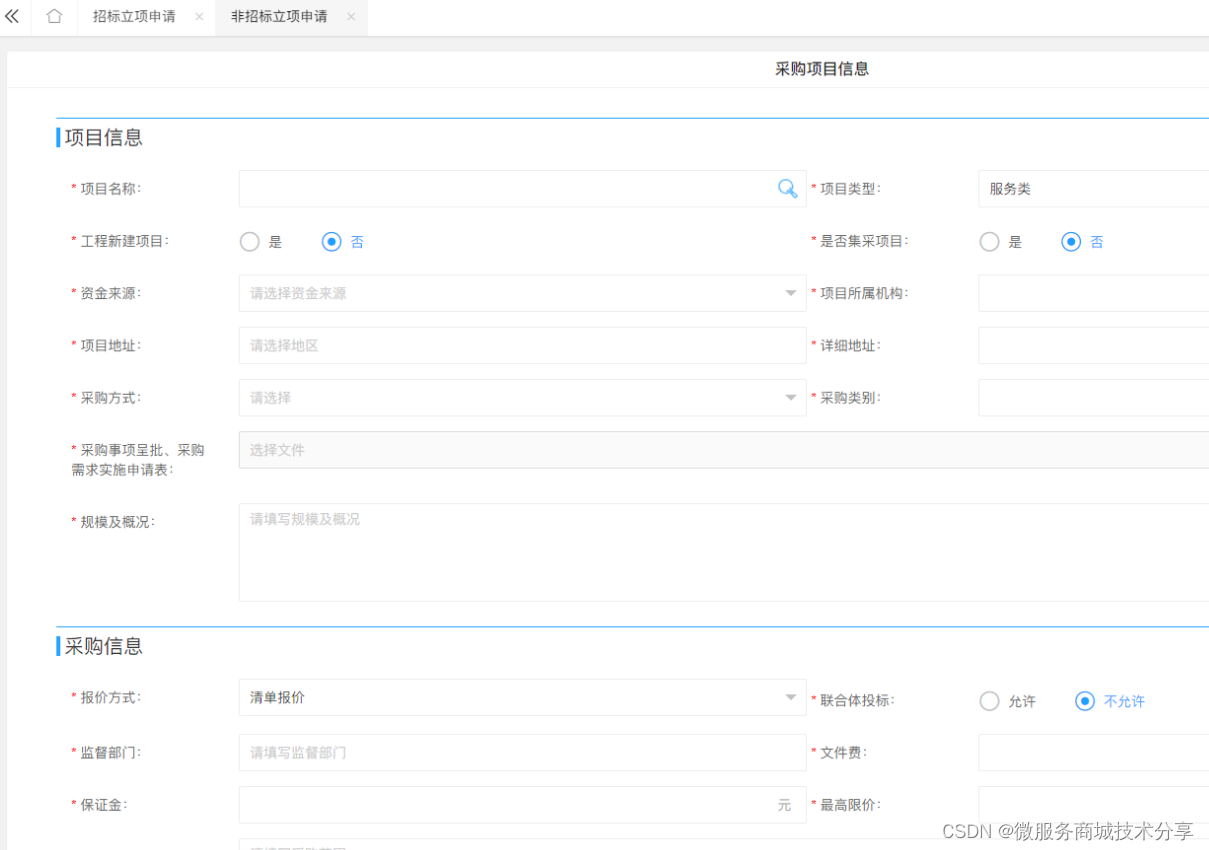
java spring cloud 企业电子招标采购系统源码:营造全面规范安全的电子招投标环境,促进招投标市场健康可持续发展 tbms
项目说明 随着公司的快速发展,企业人员和经营规模不断壮大,公司对内部招采管理的提升提出了更高的要求。在企业里建立一个公平、公开、公正的采购环境,最大限度控制采购成本至关重要。符合国家电子招投标法律法规及相关规范,以…...

【Java】2021 RoboCom 机器人开发者大赛-高职组(初赛)题解
7-1 机器人打招呼 机器人小白要来 RoboCom 参赛了,在赛场中遇到人要打个招呼。请你帮它设置好打招呼的这句话:“ni ye lai can jia RoboCom a?”。 输入格式: 本题没有输入。 输出格式: 在一行中输出 ni ye lai can jia Robo…...

汽车制造业上下游协作时 外发数据如何防泄露?
数据文件是制造业企业的核心竞争力,一旦发生数据外泄,就会给企业造成经济损失,严重的,可能会带来知识产权剽窃损害、名誉伤害等。汽车制造业,会涉及到重要的汽车设计图纸,像小米发送汽车设计图纸外泄事件并…...
H13-922题库 HCIP-GaussDB-OLAP V1.5
**H13-922 V1.5 GaussDB(DWS) OLAP题库 华为认证GaussDB OLAP数据库高级工程师HCIP-GaussDB-OLAP V1.0自2019年10月18日起,正式在中国区发布。当前版本V1.5 考试前提: 掌握基本的数据库基础知识、掌握数据仓库运维的基础知识、掌握基本Linux运维知识、…...
美团视觉GPU推理服务部署架构优化实战
🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁 🦄 个人主页——libin9iOak的博客🎐 🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~ἳ…...

什么是前端框架?怎么学习? - 易智编译EaseEditing
前端框架是一种用于开发Web应用程序界面的工具集合,它提供了一系列预定义的代码和结构,以简化开发过程并提高效率。 前端框架通常包括HTML、CSS和JavaScript的库和工具,用于构建交互式、动态和响应式的用户界面。 学习前端框架可以让您更高效…...

logstash 原理(含部署)
1、ES原理 原理 使⽤filebeat来上传⽇志数据,logstash进⾏⽇志收集与处理,elasticsearch作为⽇志存储与搜索引擎,最后使⽤kibana展现⽇志的可视化输出。所以不难发现,⽇志解析主要还 是logstash做的事情 从上图中可以看到&#x…...

CSS中的position属性有哪些值,并分别描述它们的作用。
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ static⭐ relative⭐ absolute⭐ fixed⭐ sticky⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那…...

视频联网报警厂家怎么找?
视频联网报警厂家怎么找?要找到联网报警设备厂家,可以按照以下步骤进行: 1. 在互联网上搜索:可以使用搜索引擎,如谷歌或百度,搜索关键词,如“联网报警设备厂家”、“安防设备厂家”等ÿ…...

A51汇编器Error 21解析与8051开发实践
1. 解析A51汇编器Error 21的根源与应对策略在8051单片机开发过程中,使用Keil C51工具链的A51汇编器时,开发者常会遇到一个令人困惑的报错:"ERROR #21: EXPRESSION WITH FORWARD REFERENCE NOT PERMITTED"。这个错误看似简单&#x…...

AzurLaneAutoScript:碧蓝航线自动化管理的完整解决方案
AzurLaneAutoScript:碧蓝航线自动化管理的完整解决方案 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧…...

UCD9081 GUI实战:电源时序管理与故障记录配置详解
1. 项目概述:为什么我们需要一个智能的电源监控与序列管理器?在复杂的多轨电源系统设计中,比如服务器主板、通信基站或者高端测试仪器,工程师们常常面临一个共同的挑战:如何确保十几路甚至几十路电源在上电、下电以及运…...

OpenAI 与 Anthropic 财务大比拼:一家亏损求上市,一家盈利逆袭在望!
57亿 vs 48亿5月中旬,两家AI巨头同时亮出底牌,OpenAI秘密提交IPO申请,Anthropic拿出首个盈利季度财务预测。OpenAI第一季度营收57亿美元,每赚1美元亏1.22美元;Anthropic同期营收48亿美元,落后近10亿&#x…...

因果本是叙事
因果本是叙事人类总习惯于追问“为什么”。战争为什么爆发,企业为什么衰落,一个人为什么成功,一段关系为什么破裂。我们仿佛天然相信,每个结果背后都存在一个明确的原因,像齿轮咬合般推动世界运行。然而,当…...

AutoGen 框架深度使用指南
AutoGen 框架深度使用指南:从零搭建多智能体协作系统 1. 引入与连接:你为什么需要AutoGen? 1.1 开场:每个开发者都遇到过的痛点 你有没有过这样的经历:用ChatGPT写了一段Python数据分析代码,复制到本地运行报错,再把报错信息粘贴回去让它改,来回折腾5、6次才跑通;要…...

技术人的黄金十年:软件测试从业者25到35岁每一年该怎么规划?
对于每一位进入软件行业的技术人而言,25岁到35岁这十年几乎决定了整个职业生涯的上限,而软件测试作为产品质量的最后一道防线,这个岗位的能力积累、职业路径选择,更需要在这黄金十年里做好清晰的规划。不同于开发岗的技术迭代焦虑…...

机器学习赋能粒子物理全局拟合:破解B介子衰变反常之谜
1. 项目概述:当粒子物理遇上机器学习 如果你在粒子物理领域,特别是味物理和超出标准模型(BSM)物理的探索前线工作过,那么对“全局拟合”这个词一定不会陌生。它就像是我们理论家和实验家之间的翻译官,把对撞…...
)
DeepSeek服务网格选型决策树(Istio vs. eBPF轻量方案深度对比:延迟压降42%、资源开销降低68%实测数据)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek微服务架构建议 在构建面向大语言模型推理与训练任务的微服务系统时,DeepSeek系列模型对计算密集型服务、高吞吐API网关及弹性资源编排提出了明确要求。推荐采用分层解耦、异步协同…...

免费卸载软件再推荐!支持多款软件同时卸载、注册表清理、垃圾文件清理、空文件查找、进程管理、启动管理等等功能!强制卸载+系统清理,绝了
前言 电脑里总有那么几个“钉子户”软件!卸载按钮灰色、控制面板里找不到、残留注册表像牛皮癣一样反复出现今天推荐的这款卸载工具,不管程序多顽固、卸载器多残废,都能一键连根拔起,顺带把垃圾文件、空文件夹、无效快捷方式打包带走&#x…...