logstash 原理(含部署)
1、ES原理
原理 使⽤filebeat来上传⽇志数据,logstash进⾏⽇志收集与处理,elasticsearch作为⽇志存储与搜索引擎,最后使⽤kibana展现⽇志的可视化输出。所以不难发现,⽇志解析主要还 是logstash做的事情

从上图中可以看到,logstash主要包含三⼤模块:
1、INPUTS: 收集所有数据源的⽇志数据([源有file、redis、beats等,filebeat就是使⽤了beats源*);
2、FILTERS: 负责数据处理与转换、解析、整理⽇志数据(常⽤:grok、mutate、drop、clone、geoip)
3、OUTPUTS: 将解析的⽇志数据输出⾄存储器([elasticseach、file、syslog等);
通过配置Logstash的管道(pipeline),你可以定义数据的收集、处理和输出过程。每个管道由输入插件、过滤器插件和输出插件组成,它们一起协作来实现特定的数据流转
filters常用的过滤器插件如下:
-
grok 过滤器: 场景:解析包含时间戳、日志级别和消息的日志行。
rubyCopy codegrok {match => {"message" => "\[%{TIMESTAMP_ISO8601:time}\] \[%{WORD:level}\] %{GREEDYDATA:msg}"}} -
mutate 过滤器: 场景:清理字段,将 IP 地址字段重命名为 "client_ip"。
rubyCopy codemutate {rename => { "ip" => "client_ip" }} -
date 过滤器: 场景:将时间戳字段转换为可操作的日期类型。
rubyCopy codedate {match => ["timestamp", "yyyy-MM-dd HH:mm:ss"]target => "log_date"} -
json 过滤器: 场景:解析包含嵌套 JSON 数据的日志消息。
rubyCopy codejson {source => "message"target => "parsed_json"} -
kv 过滤器: 场景:解析 HTTP 查询字符串中的参数。
rubyCopy codekv {field_split => "&"value_split => "="source => "query_string"} -
xml 过滤器: 场景:解析包含 XML 数据的日志消息。
rubyCopy codexml {source => "message"store_xml => falsexpath => ["//user/name/text()", "username","//user/age/text()", "user_age"]} -
translate 过滤器: 场景:将日志中的状态码映射为更可读的状态描述。
rubyCopy codetranslate {field => "status_code"dictionary => ["200", "OK","404", "Not Found","500", "Internal Server Error"]} -
useragent 过滤器: 场景:解析用户代理字符串,提取浏览器和操作系统信息。
rubyCopy codeuseragent {source => "user_agent"target => "user_agent_info"} -
geoip 过滤器: 场景:将 IP 地址解析为地理位置信息。
rubyCopy codegeoip {source => "client_ip"target => "geoip"} -
multiline 过滤器: 场景:合并多行堆栈跟踪日志成单个事件。
rubyCopy codemultiline {pattern => "^\s"negate => truewhat => "previous"}
2.Logstash性能优化主要体现在以下几个方面:
1.多pipeline配置
多pipeline配置。可以将不同的输入分割到不同的pipeline,每个pipeline有独立的过滤器和输出,这可以提高处理效率。pipeline之间的数据交互可以通过队列实现。
ruby# 管道1:接收日志输入input { stdin { } } filter { grok { } }output { stdout { } }# 管道2:从Kafka读取数据input { kafka { } }filter { json { } } output { elasticsearch { } }
2.Grok过滤器配置
rubyfilter {grok {match => { "message" => "%{COMBINEDAPACHELOG}" }add_field => { "timestamp" => "%{DATE:timestamp}" }}}
3.Elasticsearch输出配置
ruby output {elasticsearch { hosts => ["http://localhost:9200"]index => "logstash-%{+YYYY.MM.dd}"}}
4.Redis队列配置
rubyoutput {redis { host => "127.0.0.1"port => 6379db => 0key => "logstash" }}
5.batching编辑模式配置
rubyinput {file {path => "/var/log/messages"start_position => "beginning" sincedb_path => "/dev/null"codec => "json"mode => "batch" # 配置batching模式batch_size => 1000 # 每1000条记录批量读取}}
6.调整JVM内存配置在 jvm.options文件中配置,例如:
-Xms2g-Xmx2g
7.并行处理配置 在 logstash.yml中配置:
yml
pipeline.workers: 2 #配置工作线程数为2
pipeline.output.workers: 2 #输出线程也配置为2
logstash 配置文件
logstash 配置文件配置
vim logstash.conf
input {
kafka {
bootstrap_servers => ["192.168.190.159:9092"]
topics_pattern => ["hwb\.test|ywyth-sc|zj_test"]
consumer_threads => 5
codec => json
auto_offset_reset => latest
group_id => "hwb"
}
}filter {
ruby {
code => "event.timestamp.time.localtime"
}
mutate {
remove_field => ["beat"]
}
mutate {
split => ["message"," "]
add_field => { "level" => "%{[message][3]}" }
}
mutate {
add_field => {
"index_name" => "hwb.test,%{[ywyth-sc]}"
}
}
grok {
match => {"message" => "\[(?<time>\d+-\d+-\d+\s\d+:\d+:\d+)\] \[(?<level>\w+)\] (?<thread>[\w|-]+) (?<class>[\w|\.]+) (?<lineNum>\d+):(?<msg>.+)"
}
}
}output {
elasticsearch {
hosts => ["192.168.190.161:9200"]
index => "%{[fields][log_topic]}"
codec => "json"
}
}
启动logstash
nohup ./logstash -f ../config/logstash.conf &
相关文章:
logstash 原理(含部署)
1、ES原理 原理 使⽤filebeat来上传⽇志数据,logstash进⾏⽇志收集与处理,elasticsearch作为⽇志存储与搜索引擎,最后使⽤kibana展现⽇志的可视化输出。所以不难发现,⽇志解析主要还 是logstash做的事情 从上图中可以看到&#x…...

CSS中的position属性有哪些值,并分别描述它们的作用。
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ static⭐ relative⭐ absolute⭐ fixed⭐ sticky⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那…...

视频联网报警厂家怎么找?
视频联网报警厂家怎么找?要找到联网报警设备厂家,可以按照以下步骤进行: 1. 在互联网上搜索:可以使用搜索引擎,如谷歌或百度,搜索关键词,如“联网报警设备厂家”、“安防设备厂家”等ÿ…...

配置文件优先级解读
目录 概述 同级目录application配置文件优先级 application 以及bootstrap 优先级 不同级目录配置文件优先级 外部配置加载顺序 概述 SpringBoot除了支持properties格式的配置文件,还支持另外两种格式的配置文件。三种配置文件格式分别如下: properties格式…...
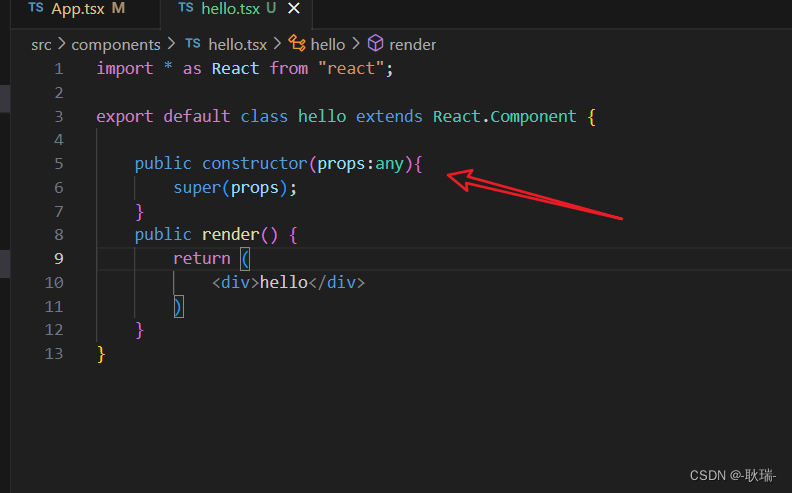
在 React+Typescript 项目环境中创建并使用组件
上文 ReactTypescript清理项目环境 我们将自己创建的项目环境 好好清理了一下 下面 我们来看组件的创建 组件化在这种数据响应式开发中肯定是非常重要的。 我们现在src下创建一个文件夹 叫 components 就用他专门来处理组件业务 然后 我们在下面创建一个 hello.tsx 注意 是t…...

UNIAPP中开发企业微信小程序
概述 需求为使用uni-app开发企业微信小程序。希望可以借助现成的uni-app框架,快速开发。遇到的问题是uni-app引入jweixin-1.2.0.js提示异常: Reason: TypeError: Cannot read properties of undefined (reading ‘title’)。本文中描述了如何解决该问题,…...
NGINX负载均衡及LVS-DR负载均衡集群
目录 LVS-DR原理搭建过程nginx 负载均衡 LVS-DR原理 原理: 1. 当用户向负载均衡调度器(Director Server)发起请求,调度器将请求发往至内核空间 2. PREROUTING链首先会接收到用户请求,判断目标IP确定是本机IPÿ…...

由于目标计算机积极拒绝,无法连接。 Could not connect to Redis at 127.0.0.1:6379
项目在启动时候报出redis连接异常 然后查看是redis 连接被计算机拒绝 解决方法 打开redis安装文件夹 先打开redis-servce.exe挂着,再打开redis-cli.exe 也不会弹出被拒接的问题了。而且此方法不用每次都去cmd里输入命令。...
电脑提示数据错误循环冗余检查怎么办?
有些时候,我们尝试在磁盘上创建分区或清理硬盘时,还可能会遇到这个问题:数据错误循环冗余检查。这是如何导致的呢?我们又该如何解决这个问题呢?下面我们就来了解一下。 导致冗余检查错误的原因有哪些? 数据…...
剑指offer62.圆圈中最后剩下的数字
这道题在算法课上的一个小故事上有一个类似的,就是一个军官打了败仗,带着他的几个兵逃到一个山洞,他们不想当俘虏想自杀,但是军官不想自杀但是又不好意思走,于是军官想了个办法,他们几个人围成一个圈&#…...

Python分享之 Spider
一、网络爬虫 网络爬虫又被称为网络蜘蛛,我们可以把互联网想象成一个蜘蛛网,每一个网站都是一个节点,我们可以使用一只蜘蛛去各个网页抓取我们想要的资源。举一个最简单的例子,你在百度和谷歌中输入‘Python,会有大量和…...

Golang项目中如何轻松实现私有仓库pkg包的引入
在企业内部创建一个公共的Golang模块工程可以帮助提高代码复用性和开发效率。本文将从如何创建一个公共的Golang工程开始,指导你一步步创建它、并引入到你的工程中。 1、公共模块规范 下面是一个简单的步骤指南来创建这样一个公共模块项目。 创建版本控制仓库&am…...
Python项目实战:基于napari的3D可视化(点云+slice)
文章目录 一、napari 简介二、napari 安装与更新三、napari【巨巨巨大的一个BUG】四、napari 使用指南4.1、菜单栏(File View Plugins Window Help)4.2、Window:layer list(参数详解)4.3、Window:layer…...

go的gin和gorm框架实现切换身份的接口
使用go的gin和gorm框架实现切换身份的接口,接收前端发送的JSON对象,查询数据库并更新,返回前端信息 接收前端发来的JSON对象,包含由openid和登陆状态组成的一个string和要切换的身份码int型 后端接收后判断要切换的身份是否低于该…...
仓库库存管理难点在哪?有哪些仓库库存管理软件?
仓库库存管理常见的难点有:库存数据混乱、库存成本较高、库存积压严重等问题 使用仓库管理软件,企业可以更好地管理库存、优化供应链、提高操作效率,并基于准确的数据进行决策和规划,从而解决许多仓库库存管理中的难题。 一、仓库…...
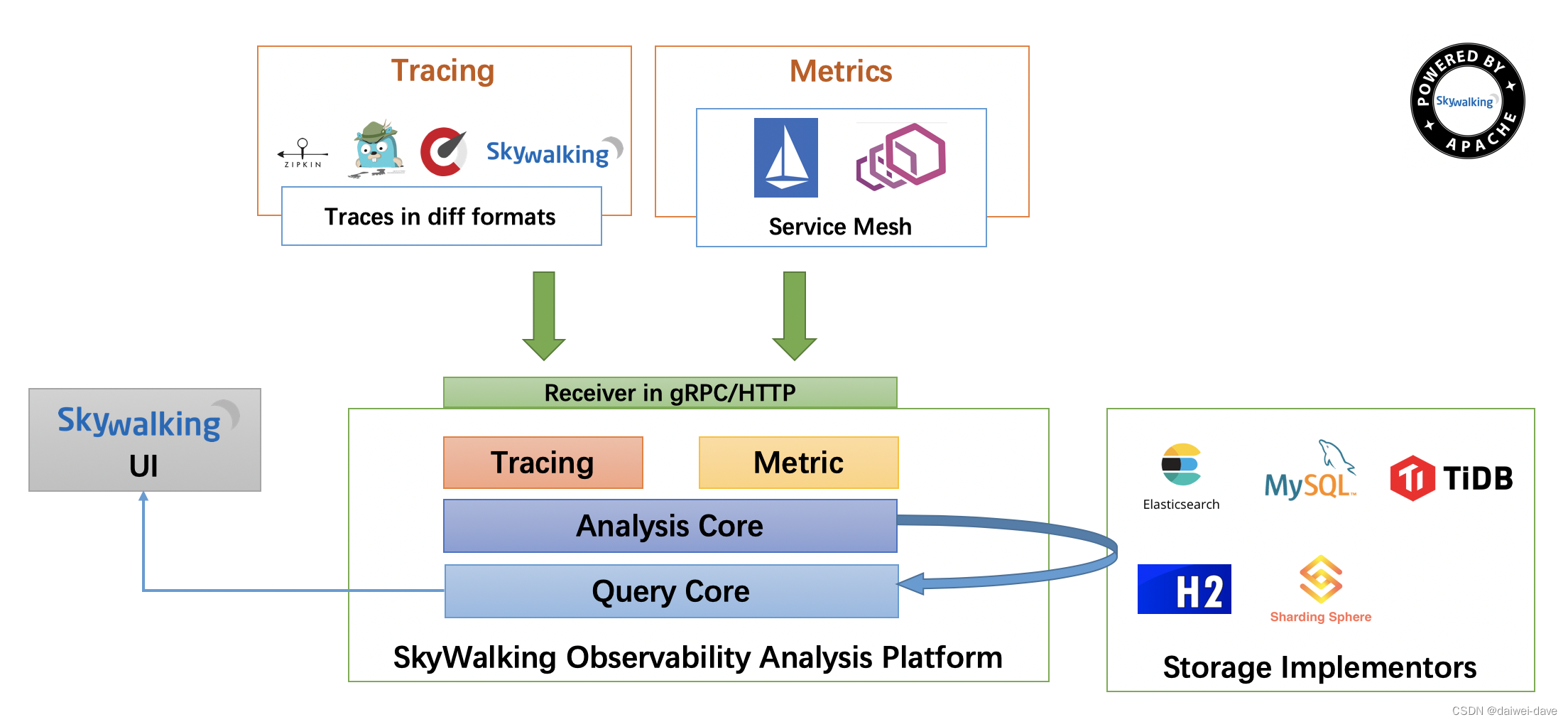
服务链路追踪
一、基础概念 1.背景 对于一个大型的几十个、几百个微服务构成的微服务架构系统,通常会遇到下面一些问题,比如: 如何串联整个调用链路,快速定位问题?如何理清各个微服务之间的依赖关系?如何进行各个微服…...

macOS - 安装使用 libvirt、virsh
文章目录 关于 libvirt使用安装启动服务virsh 交互模式virsh 帮助命令 关于 libvirt libvirt 官网: https://libvirt.org/gitlab : https://gitlab.com/libvirt/libvirtgithub : https://github.com/libvirt/libvirt 只读,gitlab 的镜像 libvirt是一套…...
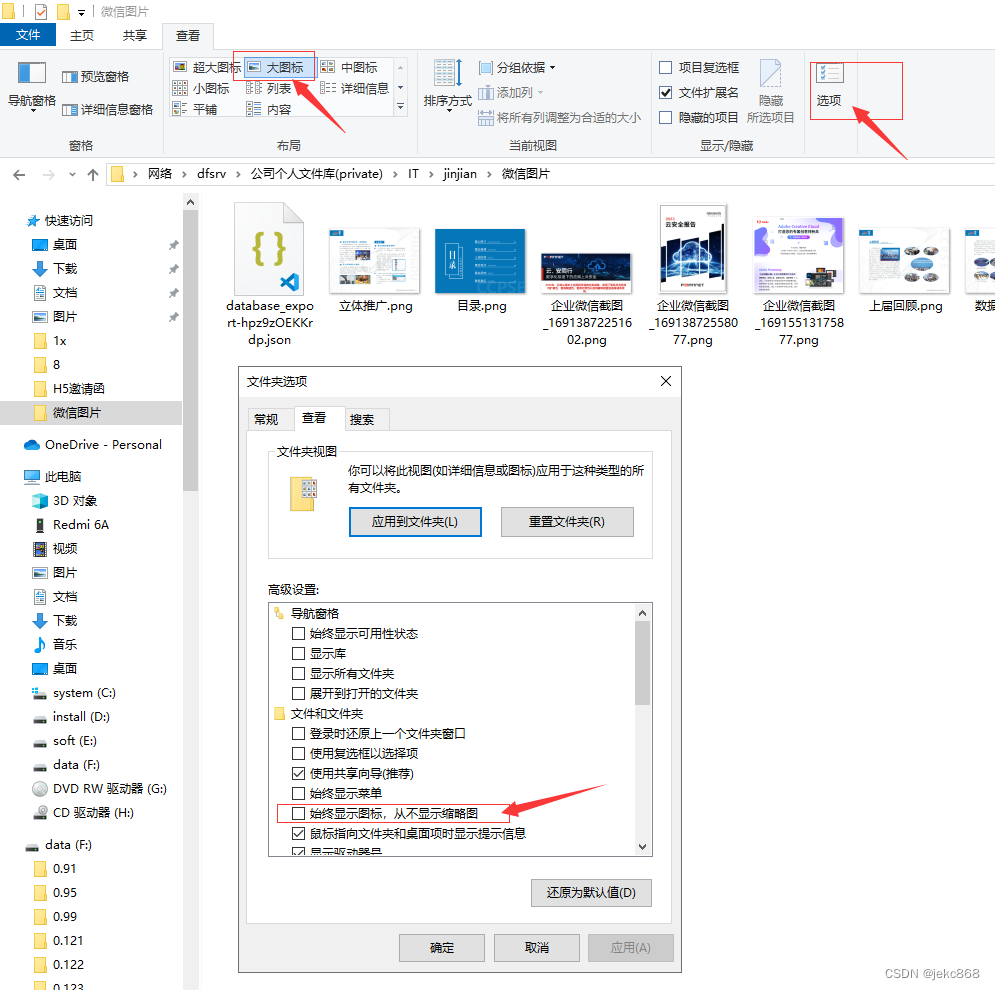
Windows Server 2019设置使用照片查看器查看图片的设置方法
1、使用winR快捷键快速打开运行,输入regedit打开注册表: 2、在注册表中找到:HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Photo Viewer\Capabilities\FileAssociations 3、在右侧新建字符串项: 4、例如新建两项.jpg 和.png值…...
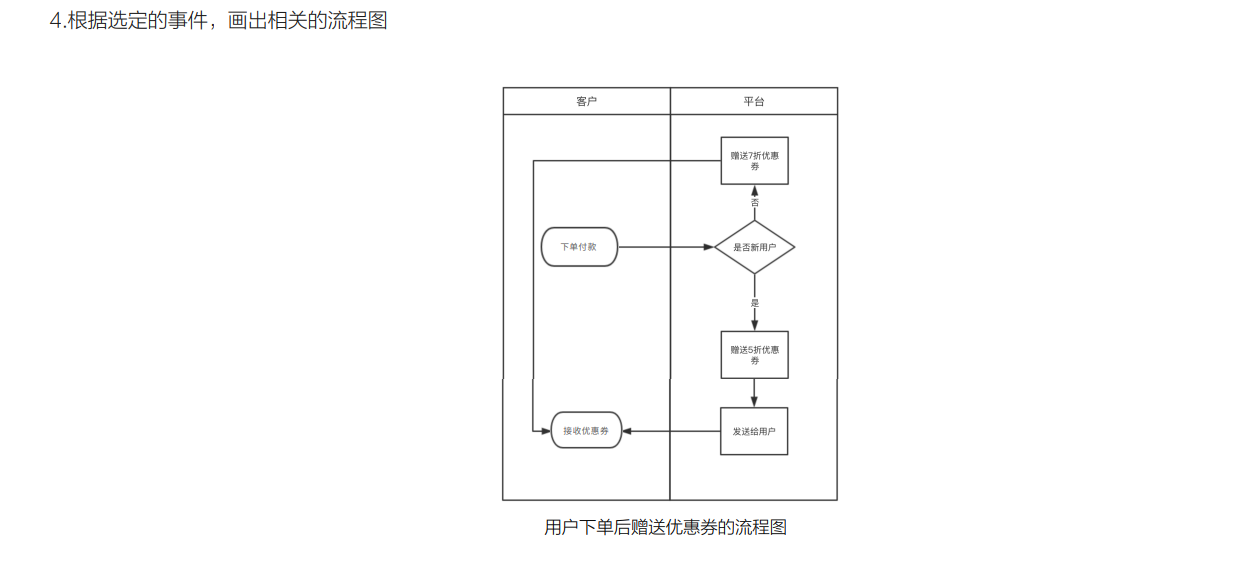
【需求输出】流程图输出
文章目录 1、什么是流程图2、绘制流程图的工具和基本要素3、流程图的分类和应用场景4、如何根据具体场景输出流程图 1、什么是流程图 2、绘制流程图的工具和基本要素 3、流程图的分类和应用场景 4、如何根据具体场景输出流程图...
opencv+ffmpeg+QOpenGLWidget开发的音视频播放器demo
前言 本篇文档的demo包含了 1.使用OpenCV对图像进行处理,对图像进行置灰,旋转,抠图,高斯模糊,中值滤波,部分区域清除置黑,背景移除,边缘检测等操作;2.单纯使用opencv播放…...

在内容生成流水线中集成多模型 API 以提升创作多样性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在内容生成流水线中集成多模型 API 以提升创作多样性 对于新媒体运营、营销或内容创作团队而言,保持内容的新鲜感与多样…...

诚邀您参加 2026 Google Cloud Startup Day
以下文章来源于谷歌云服务,作者 Google Cloud...

联想集团第一季营收216亿美元:净利5.9亿美元 股价上涨19% 市值近2000亿港元
雷递网 雷建平 5月22日联想集团(HKSE:0992;ADR:LNVGY)今日公布截至2026年3月31日的2025/26财年第四季度暨全年业绩。财报显示,联想集团2026年第一季度营收为215.88亿美元,较上年同期的169.84亿美…...

调查研究-142 全球机器人产业深度调研报告【04篇】机器人产业利润池全景:谁最容易赚钱与十大判断指标
TL;DR 场景:关注机器人产业投资、创业、就业方向的投资者、从业者、分析师结论:医疗机器人耗材/服务>高端核心零部件>系统集成>物流RaaS>工业本体>软件AI平台;人形机器人长期空间大但短期商业化仍早产出:三档利润池…...

GROMACS分子动力学结果分析过程中的一些问题
为什么已经进行了周期性矫正还是会有如下问题:gmx trjconv -s step7_1.tpr -f step7_1.xtc -n index.ndx -o step7_1_center.xtc -pbc mol -center -ur compact...

从B73到5000个RILs:手把手拆解玉米NAM群体构建的完整流程与关键决策
玉米NAM群体构建全流程解析:从亲本筛选到RILs优化的科学决策 站在玉米遗传研究的十字路口,我们常常面临一个核心挑战:如何在有限资源下构建既能捕获广泛遗传多样性,又能实现精准定位的群体?2009年,Buckler团…...

寄存器文件与SRAM:芯片设计中存储层次的核心差异与选型指南
1. 项目概述:从“存储”到“访问”的鸿沟在数字电路和处理器设计的核心地带,有两个名字经常被提及,却又常常让初学者甚至一些从业者感到混淆:Register File(寄存器文件)和SRAM(静态随机存取存储…...

终结拟合式智能:记忆博弈心智架构重塑硅基生命进化逻辑
当前全球AGI研发赛道,正陷入一场难以破局的同质化内卷。无论是头部科技企业的超大参数模型,还是轻量化垂直AI产品,核心底层始终沿用Transformer概率拟合逻辑。这套技术体系虽然实现了人工智能的规模化落地,却从根源上锁死了AI的智…...

测试工程师必知的数据库知识:这4个数据库技能,测试必备
在软件开发的全生命周期中,数据库是支撑所有业务逻辑运转的核心骨架——用户的每一次点击、每一笔交易、每一条信息的展示,最终都会转化为数据库中数据的增删改查。对于软件测试工程师而言,数据库知识早已不是面试中的加分项,而是…...

网盘直链解析工具:多平台文件下载的实用解决方案
网盘直链解析工具:多平台文件下载的实用解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...