预训练GNN:GPT-GNN Generative Pre-Training of Graph Neural Networks
一.文章概述
本文提出了一种自监督属性图生成任务来预训练GNN,使得其能捕图的结构和语义属性。作者将图的生成分为两个部分:属性生成和边生成,即给定观测到的边,生成节点属性;给定观测到的边和生成的节点属性,生成剩余的边。通过这种方式使得模型能捕获每个节点属性和结构之间的依赖关系。对于每个节点,GPT-GNN可以同时计算其属性生成和边生成损失。另外,为了使得GPT-GNN可以处理大图,作者采用了子图采样技术,并提出自适应嵌入队列来缓解负采样带来的不准确损失。
二.预备知识
之前关于图上预训练的工作可以分为两类:
- network/graph embedding:直接参数化节点嵌入向量,并通过保留一些相似度量来参数化的优化节点嵌入。但该种方式学到的嵌入不能用于初始化其他模型,以便对其他任务进行微调。
- transfer learning setting:预训练一个可用于处理不同任务的通用GNN。
三.GNN的生成式预训练
3.1 GNN预训练问题
为什么需要预训练?
获取足够的标注数据通常具有挑战性,尤其是对于大图,这阻碍了通用GNN的训练。为此,有必要探索GNN的预训练,它能用很少的标签进行泛化。
GNN预训练的正式定义:GNN预训练的目标是完全基于单个(大规模)图 G = ( V , E , X ) G=(\mathcal{V}, \mathcal{E}, \mathcal{X}) G=(V,E,X) 学习一个通用的GNN模型 f θ f_\theta fθ,而不需要标注数据,这使得 f θ f_\theta fθ对于同一个图或同一领域的图上的各种下游任务是一个良好的初始化。
3.2 生成式预训练框架
作者提出GPT-GNN,它通过重建/生成输入图的结构或属性来预训练GNN。
给定输入图 G = ( V , E , X ) G=(\mathcal{V}, \mathcal{E}, \mathcal{X}) G=(V,E,X),GNN模型 f θ f_\theta fθ,作者用GNN f θ f_\theta fθ建模图上的似然(likelihood)为 p ( G ; θ ) p(G;\theta) p(G;θ),其表示图 G G G中的节点是如何归属(attributed)和连接(connected)的。GPT-GNN旨在预训练GNN来最大化图似然,即 θ ∗ = max θ p ( G ; θ ) \theta^{*} = \text{max}_{\theta}\ p(G;\theta) θ∗=maxθ p(G;θ)。
3.2.1 如何建模 p ( G ; θ ) p(G;\theta) p(G;θ)
现有的大多数图生成方式采用自回归的方式对概率目标进行因式分解,即按图中的节点顺序来,通过将每个新到达的节点连接到现有节点来生成边。类似地,作者用排列(permutation)向量 π \pi π来确定节点顺序,其中 i π i^{\pi} iπ表示排列 π \pi π中第 i i i个位置的节点id。因此,图分布 p ( G , θ ) p(G,\theta) p(G,θ)等价于所有可能排列的期望的可能性,即:
p ( G ; θ ) = E π [ p θ ( X π , E π ) ] , p(G ; \theta)=\mathbb{E}_\pi\left[p_\theta\left(X^\pi, E^\pi\right)\right], p(G;θ)=Eπ[pθ(Xπ,Eπ)],
其中 X π ∈ R ∣ V ∣ × d X^\pi \in \mathbb{R}|\mathcal{V}| \times d Xπ∈R∣V∣×d表示排列的节点属性, E E E是边集, E i π E_i^\pi Eiπ表示与 i π i^{\pi} iπ相连的所有边。为了简化,作者假设观察任何节点排列 π \pi π的概率相同。给定一个排列顺序,可以自回归分解log四让,每次迭代生成一个节点:
log p θ ( X , E ) = ∑ i = 1 ∣ V ∣ log p θ ( X i , E i ∣ X < i , E < i ) \log p_\theta(X, E)=\sum_{i=1}^{|\mathcal{V}|} \log p_\theta\left(X_i, E_i \mid X_{<i}, E_{<i}\right) logpθ(X,E)=i=1∑∣V∣logpθ(Xi,Ei∣X<i,E<i)
在每一步 i i i,作者使用 i i i之前的所有生成的节点,以及其对应的属性 X < i X_{<i} X<i、节点间的结构 E < i E_{<i} E<i来生成新的节点 i i i,包括 i i i的属性 X i X_i Xi和与已有节点的连接 E i E_i Ei。
3.3 分解属性图生成
对于条件概率 p θ ( X i , E i ∣ X < i , E < i ) p_\theta\left(X_i, E_i \mid X_{<i}, E_{<i}\right) pθ(Xi,Ei∣X<i,E<i) 的建模,一个简单的解决方案是假设 X i X_i Xi和 E i E_i Ei是独立的,即:
p θ ( X i , E i ∣ X < i , E < i ) = p θ ( X i ∣ X < i , E < i ) ⋅ p θ ( E i ∣ X < i , E < i ) p_\theta\left(X_i, E_i \mid X_{<i}, E_{<i}\right)=p_\theta\left(X_i \mid X_{<i}, E_{<i}\right) \cdot p_\theta\left(E_i \mid X_{<i}, E_{<i}\right) pθ(Xi,Ei∣X<i,E<i)=pθ(Xi∣X<i,E<i)⋅pθ(Ei∣X<i,E<i)
采用该种方式时,对每个节点其属性和连接之间的依赖关系被完全忽略了,但这种忽略的依赖性确是属性图的核心属性,也是GNN中卷积聚合的基础,因此,这种朴素的分解不能为预训练GNN提供指导。
为了解决这一问题,作者提出了依赖感知(dependency-aware)分解机制来进行属性图的生成。具体来说,在估计一个新节点的属性时,其结构信息会被给定,反之亦然,即属性图的生成可以分为两步:
- 给定观测到的边,生成节点属性;
- 给定观察到的边和生成的节点属性,生成剩余的边。
通过这种方式,模型可以捕获每个节点的属性和结构之间的依赖关系。
令 o o o表示 E i E_i Ei中所有观察到的边的索引向量,则 E i , o E_{i,o} Ei,o表示观测到的边。 ¬ o \neg o ¬o表示所有掩去边的索引,即待生成的边。基于此,条件概率可以重写为所有观察到的边的期望可能性:
p θ ( X i , E i ∣ X < i , E < i ) = ∑ o p θ ( X i , E i , ¬ o ∣ E i , o , X < i , E < i ) ⋅ p θ ( E i , o ∣ X < i , E < i ) = E o [ p θ ( X i , E i , ¬ o ∣ E i , o , X < i , E < i ) ] = E o [ p θ ( X i ∣ E i , o , X < i , E < i ) ⏟ 1) generate attributes ⋅ p θ ( E i , ¬ o ∣ E i , o , X ≤ i , E < i ) ⏟ 2) generate edges ] . \begin{aligned} & p_\theta\left(X_i, E_i \mid X_{<i}, E_{<i}\right) \\ = & \sum_o p_\theta\left(X_i, E_{i, \neg o} \mid E_{i, o}, X_{<i}, E_{<i}\right) \cdot p_\theta\left(E_{i, o} \mid X_{<i}, E_{<i}\right) \\ = & \mathbb{E}_o\left[p_\theta\left(X_i, E_{i, \neg o} \mid E_{i, o}, X_{<i}, E_{<i}\right)\right] \\ = & \mathbb{E}_o[\underbrace{p_\theta\left(X_i \mid E_{i, o}, X_{<i}, E_{<i}\right)}_{\text {1) generate attributes }} \cdot \underbrace{p_\theta\left(E_{i, \neg o} \mid E_{i, o}, X_{\leq i}, E_{<i}\right)}_{\text {2) generate edges }}] . \end{aligned} ===pθ(Xi,Ei∣X<i,E<i)o∑pθ(Xi,Ei,¬o∣Ei,o,X<i,E<i)⋅pθ(Ei,o∣X<i,E<i)Eo[pθ(Xi,Ei,¬o∣Ei,o,X<i,E<i)]Eo[1) generate attributes pθ(Xi∣Ei,o,X<i,E<i)⋅2) generate edges pθ(Ei,¬o∣Ei,o,X≤i,E<i)].
其中 p θ ( X i ∣ E i , o , X < i , E < i ) p_\theta\left(X_i \mid E_{i, o}, X_{<i}, E_{<i}\right) pθ(Xi∣Ei,o,X<i,E<i)表示节点 i i i的属性生成,基于观测到的边 E i , o E_{i, o} Ei,o,可以聚集目标节点 i i i的邻域信息来生成属性 X i X_i Xi。 p θ ( E i , ¬ o ∣ E i , o , X ≤ i , E < i ) p_\theta\left(E_{i, \neg o} \mid E_{i, o}, X_{\leq i}, E_{<i}\right) pθ(Ei,¬o∣Ei,o,X≤i,E<i)表示生成掩去的边,基于观测到的边 E i , o E_{i, o} Ei,o和生成的属性 X i X_i Xi,可以生成目标节点 i i i的表示,然后预测 E i , ¬ o E_{i, \neg o} Ei,¬o内的每条边是否存在。
3.4 高效的属性和边生成
作者希望同时进行属性生成和边生成,但边的生成需要节点属性作为输入,可以泄露给属性生成。为了避免信息泄露,作者将每个节点设计为两种类型:
- Attribute Generation Nodes:作者将这些节点的属性掩去,并使用dummy token代替它们的属性,并学得一个共享的向量 X i n i t X^{init} Xinit来表示它。
- Edge Generation Nodes:对这些节点保持其属性,并将其作为GNN的输入。
作者使用 h A t t r h^{A t t r} hAttr和 h E d g e h^{E d g e} hEdge来分别表示Attribute Generation和Edge Generation节点,由于Attribute Generation Nodes被掩去, h Attr h^{\text {Attr }} hAttr 比 h E d g e h^{E d g e} hEdge包含更少的信息。因此,在进行GNN的消息传递的时候,仅使用Edge Generation Nodes的输出 h E d g e h^{E d g e} hEdge作为对外信息。然后,使用这两组节点的表示来生成具有不同解码器的属性和边。
对于属性生成,将其对应解码器表示为 Dec A t t r ( ⋅ ) \text{Dec}^{Attr}(\cdot) DecAttr(⋅),它以 h Attr h^{\text {Attr }} hAttr 作为输入,生成被掩去的属性。建模的选择取决于属性的类型。例如如果一个节点的输入属性是文本,则使用文本生成器模型(例如,LSTM)来生成它。此外,作者定义距离函数来作为生成属性和真实值间的度量,即属性生成损失定义为:
L i Attr = Distance ( Dec Attr ( h i Attr ) , X i ) . \mathcal{L}_i^{\text {Attr }}=\text { Distance }\left(\text { Dec }^{\text {Attr }}\left(h_i^{\text {Attr }}\right), X_i\right) . LiAttr = Distance ( Dec Attr (hiAttr ),Xi).
对于边的生成,作者假设每条边的生成都是独立的,然后可以隐式分解似然:
p θ ( E i , ¬ o ∣ E i , o , X ≤ i , E < i ) = ∏ j + ∈ E i , ¬ o p θ ( j + ∣ E i , o , X ≤ i , E < i ) . p_\theta\left(E_{i, \neg o} \mid E_{i, o}, X_{\leq i}, E_{<i}\right)=\prod_{j^{+} \in E_{i, \neg o}} p_\theta\left(j^{+} \mid E_{i, o}, X_{\leq i}, E_{<i}\right) . pθ(Ei,¬o∣Ei,o,X≤i,E<i)=j+∈Ei,¬o∏pθ(j+∣Ei,o,X≤i,E<i).
在获取到Edge Generation node表示 h E d g e h^{E d g e} hEdge后,可以通过 Dec E d g e ( h i E d g e , h j E d g e ) \operatorname{Dec}^{E d g e}\left(h_i^{E d g e}, h_j^{E d g e}\right) DecEdge(hiEdge,hjEdge)来建模节点 i i i与节点 j j j连接的可能性,其中 D e c E d g e Dec^{E d g e} DecEdge表示成对(pairwise)得分函数。最后,采用负对比估计(negative contrastive estimation)来计算每个链接节点 j + j^{+} j+的似然。作者将为连接的节点表示为 S i − S_i^{-} Si−,对比损失计算公式如下:
L i E d g e = − ∑ j + ∈ E i , ¬ o log exp ( Dec E d g e ( h i E d g e , h j + E d g e ) ) ∑ j ∈ S i − ∪ { j + } exp ( Dec E d g e ( h i E d g e , h j E d g e ) ) \mathcal{L}_i^{E d g e}=-\sum_{j^{+} \in E_{i, \neg o}} \log \frac{\exp \left(\operatorname{Dec}^{E d g e}\left(h_i^{E d g e}, h_{j^{+}}^{E d g e}\right)\right)}{\sum_{j \in S_i^{-} \cup\left\{j^{+}\right\}} \exp \left(\operatorname{Dec}^{E d g e}\left(h_i^{E d g e}, h_j^{E d g e}\right)\right)} LiEdge=−j+∈Ei,¬o∑log∑j∈Si−∪{j+}exp(DecEdge(hiEdge,hjEdge))exp(DecEdge(hiEdge,hj+Edge))
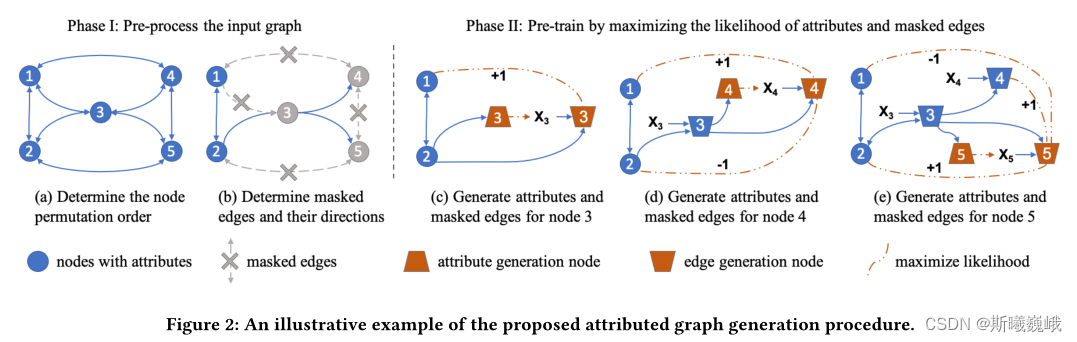
下图便展示了属性图生成的过程:
- 确定输入图的节点排列顺序;
- 随机选取目标节点边的一部分作为观测边 E i , o E_{i,o} Ei,o,剩下的边掩去作为 E i , ¬ o E_{i, \neg o} Ei,¬o,需要将被掩去的边从图中删除。
- 将节点划分为Attribute Generation和Edge Generation节点。
- 使用修改的邻接矩阵来计算节点3、4和5的表示,包括它们的Attribute和Edge Generation节点。
- 通过每个节点的属性预测和掩去边预测任务并行训练GNN模型。
3.5 扩展到异配和大图
本节主要介绍如何在大图和异配图上应用GPT-GNN进行预训练。
异配图:对于异配图,所提出的GPT-GNN框架可以直接应用于预训练异构GNN。唯一的区别是每种类型的节点和边都可以有自己的解码器,这是由异构gnn指定的,而不是预训练框架。所有其他组件保持完全相同。
大图:对于大图,则需要使用子图采样进行训练。为了估计GPT-GNN提出的对比损失,需要遍历输入图的所有节点。然而,只能访问子图中的采样节点来估计这个损失,使得(自)监督只关注局部信号。为了缓解这个问题,作者提出了自适应队列(Adaptive Queue),它将之前采样的子图中的节点表示存储为负样本。每次处理一个新的子图,可以通过添加最新的节点表示并删除最旧的节点表示来逐步更新这个队列。自适应队列可以使用更大的负样本池 S i − S_i^{-} Si−,此外,不同采样子图上的节点可以为对比学习带来全局结构指导。
相关文章:
预训练GNN:GPT-GNN Generative Pre-Training of Graph Neural Networks
一.文章概述 本文提出了一种自监督属性图生成任务来预训练GNN,使得其能捕图的结构和语义属性。作者将图的生成分为两个部分:属性生成和边生成,即给定观测到的边,生成节点属性;给定观测到的边和生成的节点属性…...

Python实现透明隧道爬虫ip:不影响现有网络结构
作为一名专业爬虫程序员,我们常常需要使用隧道代理来保护个人隐私和访问互联网资源。本文将分享如何使用Python实现透明隧道代理,以便在保护隐私的同时不影响现有网络结构。通过实际操作示例和专业的解析,我们将带您深入了解透明隧道代理的工…...
并发编程系列-CompletableFuture
利用多线程来提升性能,实质上是将顺序执行的操作转化为并行执行。仔细观察后,你还会发现在顺序转并行的过程中,一定会牵扯到异步化。举个例子,现在下面这段示例代码是按顺序执行的,为了优化性能,我们需要将…...

锁粒度的粗细与时空损耗互换
1 空间换时间的cases 1.1 redis的用户分组限流和用户定制的限流器 Redis 用户分组限流和用户定制的限流器:使用 Redis 进行用户分组限流或用户定制的限流意味着你使用 Redis 数据库来维护用户的访问限制。可以通过计数器、滑动窗口或令牌桶等算法来实现限流。用户…...
:演示用AS编译错误问题)
[Android 11]使用Android Studio调试系统应用之Settings移植(七):演示用AS编译错误问题
文章目录 1. 篇头语2. 系列文章3. AS IDE的配置3.1 AS版本3.2 Gradle JDK 版本4. JDK的下载5. AS演示工程地址6.其他版本JDK导致的错误1. 篇头语 距离2021年开始,系列文章发表已经有近两年了,依旧有网友反馈一些gitee上演示源码编译的一些问题,这里就记录一下。 2. 系列文章…...

MyBatis面试题
MyBatis面试题: 1、MyBatis是什么? Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,加载驱动、创建连接、创建statement等繁杂的过程,开发者开发时只需要关注如何编写SQL语句…...
Lorenz系统最大lyapunov exponent的求解
首先看下Lorenz混沌系统: 赋予初始值,例如: 当然,初始值可以根据需要设定。 看下他的吸引子,很美: 看下他的分叉图:...

c#实现策略模式
下面是一个使用C#实现策略模式的示例代码: using System;// 策略接口 public interface IStrategy {void Execute(); }// 具体策略类A public class ConcreteStrategyA : IStrategy {public void Execute(){Console.WriteLine("具体策略A的执行逻辑");} …...
家纺行业小程序商城搭建指南
家纺行业作为一个不可或缺的消费领域,近年来备受关注。随着互联网的发展,小程序商城成为家纺行业拓展市场的新利器。搭建一个家纺行业小程序商城并不是一件困难的事情,只需要按照以下几个步骤进行操作,就能轻松上手。 首先&#x…...

Python语法基础--条件选择
学习目标 使用比较运算符编写布尔表达式。使用random.randint(a,b)或者random.random()函数来生成随机数。编写布尔表达式(AdditionQuiz)。使用单向if语句实现选择控制。使用单向if语句编程。使用双向if-else语句实现选择控制。使用嵌套if和多向if-elif-else语句实现选择控制。…...
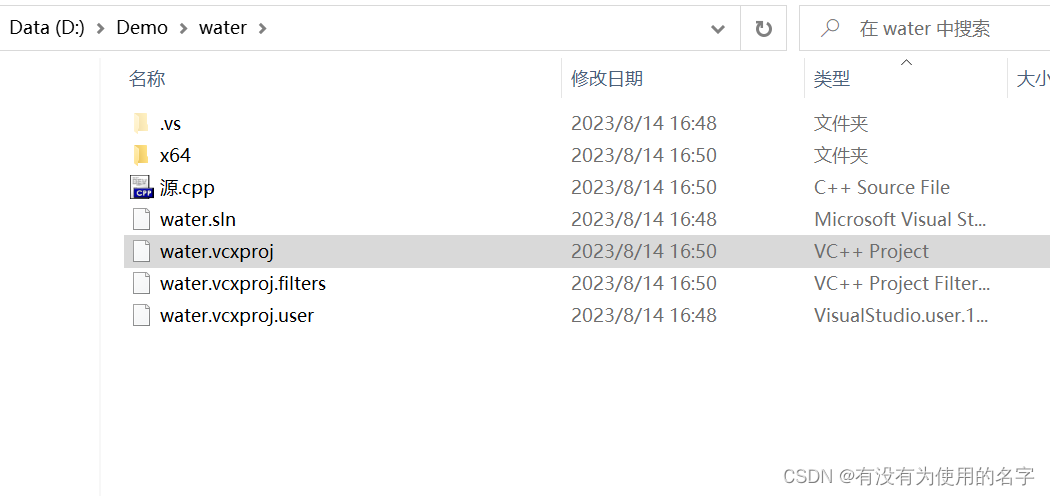
visual studio 2017 运行的程序关闭后不能再运行?(visual studio建立项目之后退出,如何再次完整打开项目?)
在你储存项目的文件夹里面应该是这样的 里面.vcxproj后缀名的就是原来创建的项目,直接打开这个头文件源文件就会一起出来了! 真的管用,亲测有效。...
亚马逊feedback和review有什么区别
在亚马逊上,"Feedback"(反馈)和"Review"(评论)是两个不同的概念,它们在购物体验中起着不同的作用。 Feedback(反馈): 亚马逊的"Feedback"…...

新疆大学841软件工程考研
1.软件生产的发展经历了三个阶段,分别是____、程序系统时代和软件工程时代时代。 2.可行性研究从以下三个方面研究每种解决方法的可行性:经济可行性、社会可行性和_____。 3.HIPO图的H图用于描述软件的层次关系&…...

Vue: el-form 自定义校验规则
Vue 的 el-form 组件可以使用自定义校验规则进行表单验证。自定义校验规则可以通过传递一个函数来实现,该函数接受要校验的字段的值作为参数,并返回一个布尔值或一个 Promise 对象。 下面是一个示例,演示如何在 el-form 中使用自定义校验规则…...
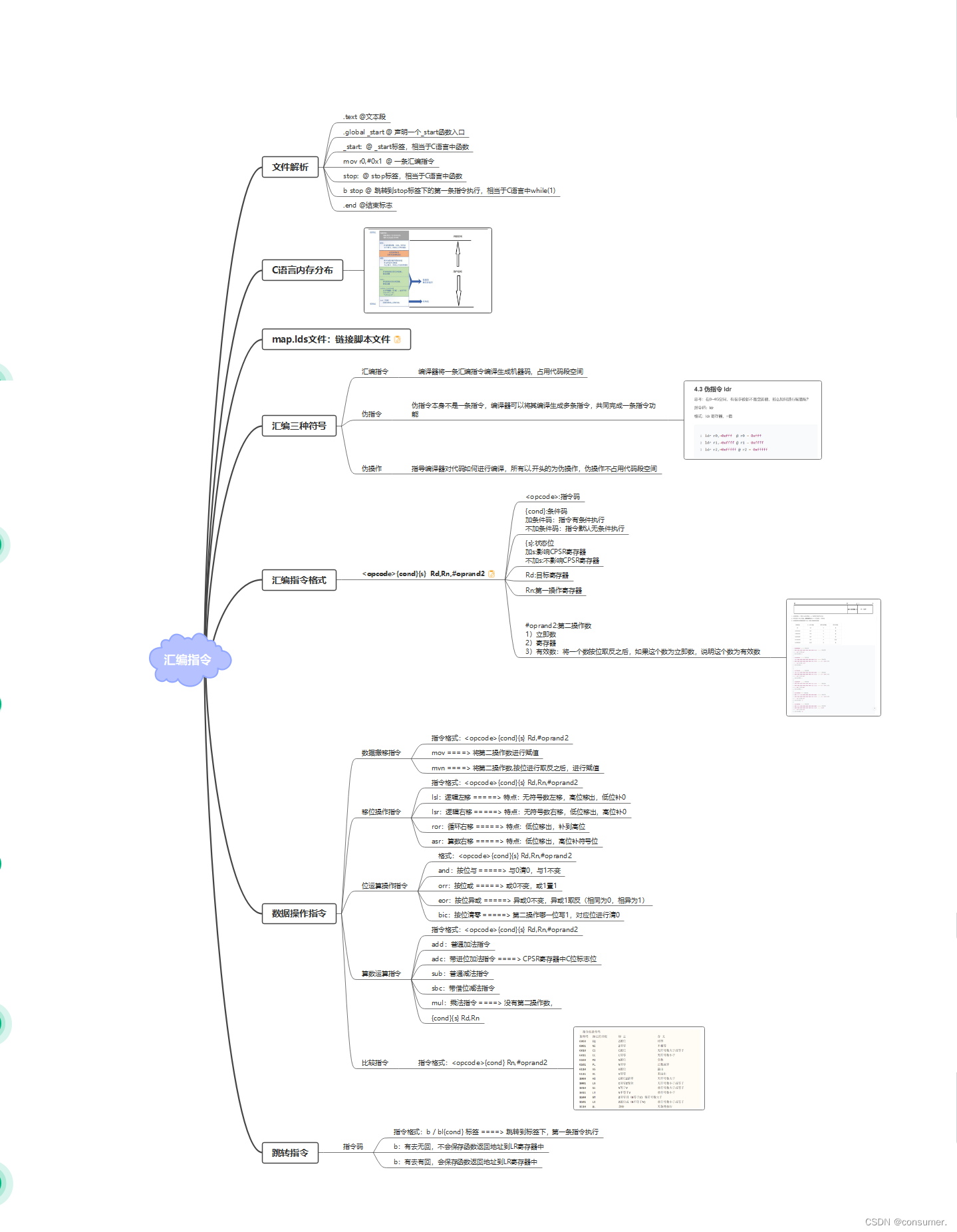
8.14 ARM
1.练习一 .text 文本段 .global _start 声明一个_start函数入口 _start: _start标签,相当于C语言中函数mov r0,#0x2mov r1,#0x3cmp r0,r1beq stopsubhi r0,r0,r1subcc r1,r1,r0stop: stop标签,相当于C语言中函数b stop 跳转到stop标签下的第一条…...

Flink笔记
下面是你提供的文字整理后的结果: 1. Flink是一个针对流数据和批数据的分布式处理引擎,同时支持原生流处理的开源框架。 - 延迟低(毫秒级),且能够保证消息传输不丢失不重复。 - 具有非常高的吞吐(每秒千万级)。 - 支持原生流处理。…...

深度学习在MRI运动校正中的应用综述
运动是MRI中的主要挑战之一。由于MR信号是在频率空间中获取的,因此除了其他MR成像伪影之外,成像对象的任何运动都会导致重建图像中产生伪影。深度学习被提出用于重建过程的几个阶段的运动校正。广泛的MR采集序列、感兴趣的解剖结构和病理学以及运动模式&…...

内存不足V4L2 申请DMC缓存报错问题
当内存不足时,V4L2可能存在申请DMA缓存报错,如下日志: 13:36:54:125 [15070.640862] rkcifhw fdfe0000.rkcif: swiotlb buffer is full (sz: 1843200 bytes) 13:36:54:125 [15070.640891] rkcifhw fdfe0000.rkcif: swiotlb: coherent allocation failed, size=1843200 13:3…...
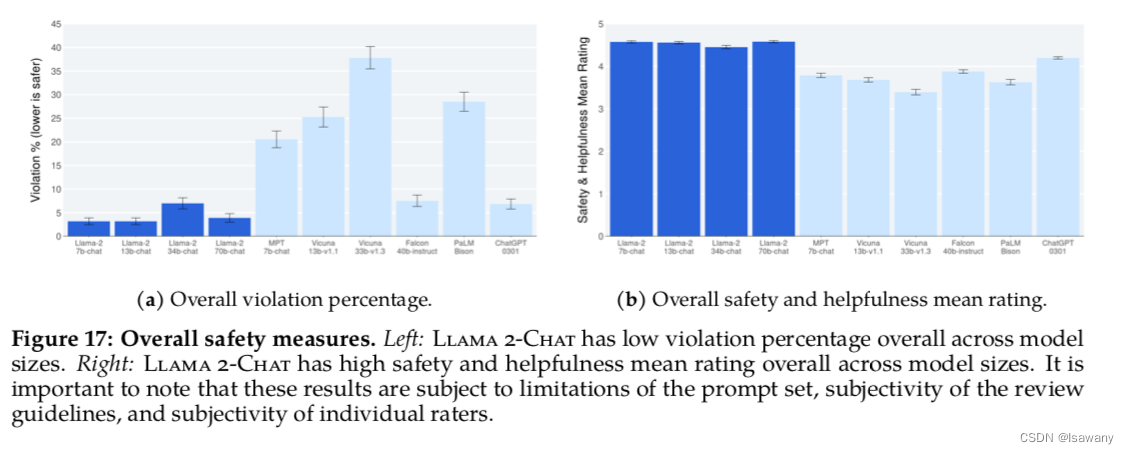
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models 1. 文章简介2. 文章概括3 文章重点技术3.1 预训练Pretraining3.1.1 预训练细节3.1.2 Llama2模型评估 3.2 微调Fine-tuning3.2.1 Supervised Fine-Tuning(FT)3.2.2 Reinforcement Learning with Human Feedback(…...
客达天下项目案例
本资料转载于传智播客https://www.itheima.com/ https://space.bilibili.com/3493265607232348 黑马程序员主办的全日制统招大学——大同互联网职业技术学院 预计2024年开始招生,敬请持续关注! B站视频入口:002_接口项目介绍_哔哩哔哩_bili…...

开源堡垒机Guacamole二次开发实战:SFTP与录屏功能深度优化
1. Guacamole堡垒机二次开发背景与挑战 Guacamole作为一款优秀的开源堡垒机,在企业远程办公和运维管理中扮演着重要角色。但在实际生产环境中,我们常常会遇到一些原生功能无法满足需求的情况。比如在分布式部署场景下,guacd服务与Java后端分离…...

从‘梯度裁剪’到‘权重初始化’:一份预防梯度爆炸的PyTorch/TensorFlow实操清单
从‘梯度裁剪’到‘权重初始化’:一份预防梯度爆炸的PyTorch/TensorFlow实操清单 训练深度神经网络时,梯度爆炸问题就像一颗定时炸弹——它可能在你最意想不到的时候突然引爆,导致损失函数值瞬间变为NaN,或者权重更新出现剧烈震荡…...

SYSU-MM01跨模态行人重识别:Python评估实战指南
1. SYSU-MM01数据集与跨模态行人重识别基础 如果你正在研究行人重识别(ReID),尤其是跨模态场景下的挑战,SYSU-MM01绝对是一个绕不开的基准数据集。这个由中山大学发布的权威数据集,最大的特点就是同时包含了可见光&…...

数据库智能运维:利用PyTorch LSTM预测数据库性能瓶颈
数据库智能运维:利用PyTorch LSTM预测数据库性能瓶颈 1. 引言:当数据库遇上AI预测 凌晨三点,运维工程师小李被刺耳的报警声惊醒——核心数据库又崩溃了。这已经是本月第三次因为性能瓶颈导致的业务中断,每次损失都超过百万。传统…...

Phi-4-reasoning-vision-15B多场景落地:OCR/图表分析/GUI理解三类任务统一部署
Phi-4-reasoning-vision-15B多场景落地:OCR/图表分析/GUI理解三类任务统一部署 1. 模型介绍 Phi-4-reasoning-vision-15B是微软推出的视觉多模态推理模型,能够处理多种视觉理解任务。这个模型特别擅长从图像中提取和理解信息,无论是文档文字…...

华为交换机MAC地址漂移检测与风暴抑制联动配置指南
1. 华为交换机MAC地址漂移检测原理与实战 刚接触网络运维时,第一次遇到MAC地址漂移报警简直一头雾水。后来才发现,这其实是交换机在提醒我们:"兄弟,你的网络里可能有环路!" MAC地址漂移的本质是同一个MAC地址…...

颠覆传统投资分析:TradingAgents-CN智能交易系统零门槛部署指南
颠覆传统投资分析:TradingAgents-CN智能交易系统零门槛部署指南 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN 在金融科技迅猛发展的…...

从线索到成交,陀螺匠帮我打通了客户管理全流程
作为一个从业多年销售,我觉得我在管理客户过程中遇到的这些问题,很多企业多多少少也出现过。比如销售小王跟了一个月的客户,最后发现小李早就联系过了,经常白忙活;好不容易谈成的单子,合同改来改去…...

全能视频下载工具:Video-Downloader让在线视频轻松保存
全能视频下载工具:Video-Downloader让在线视频轻松保存 【免费下载链接】Video-Downloader 下载youku,letv,sohu,tudou,bilibili,acfun,iqiyi等网站分段视频文件,提供mac&win独立App。 项目地址: https://gitcode.com/gh_mirrors/vi/Video-Downloa…...

如何用Obsidian Image Converter实现图像高效管理?超实用技巧分享
如何用Obsidian Image Converter实现图像高效管理?超实用技巧分享 【免费下载链接】obsidian-image-converter ⚡️ Convert, compress, resize, annotate, markup, draw, crop, rotate, flip, align images directly in Obsidian. Drag-resize, rename with variab…...