Spark基础-任务提交相关参数
整理一下用过的spark相关的参数
spark应用提交命令spark-submit的常用参数(使用spark-submit --help可以查看所有参数, 有一些参数在下面的spark配置属性定义了,也没有额外列出)
| 参数 | 默认值 | 含义 |
|---|---|---|
--master | local[*] | spark集群的master url,可以是yarn, local等值(master url取值列表 ) |
--deploy-mode | client | 有cluster和client两种模式,决定driver是在worker节点上,还是在本地作为一个外部client。 |
--name | / | 应用的名称 |
--conf | / | 额外的spark配置属性,以key=value的形式表示 |
--py-files | / | 用逗号分隔的.zip, .egg, .py文件,将其路径防止在PYTHONPATH给python应用使用 |
常用spark配置属性
| 参数 | 默认大小 | 含义 | 官方文档对应类别 |
|---|---|---|---|
spark.driver.memory | 1g | driver内存,在client模式下必须通过spark-submit的 --driver-memory来设置,而不能通过SparkConf来设置 | Application Properties |
spark.driver.cores | 1 | driver对应的核数,只有在cluster模式下可以设置 | Application Properties |
spark.driver.memoryOverhead | driverMemory * spark.driver.memoryOverheadFactor, 最小值为384M | 在cluster模式下driver被分配的non-heap 内存。这块内存是用于虚拟机的开销、内部的字符串、还有一些本地开销(比如python需要用到的内存)等。当spark.memory.offHeap.enabled=true时,非堆内存包括堆外内存和其他driver进程使用的内存(例如与PySpark driver一起使用的python进程)和其他在同一个容器中运行的非driver进程使用的内存 。 所以运行driver的容器的最大内存大小由spark.driver.memoryOverhead和spark.driver.memory之和确定。 | Application Properties |
spark.driver.memoryOverheadFactor | 0.1 | driver 内存被分配为non-heap内存的比例,如果出现了"Memory Overhead Exceeded",调大这个比例有助于预防这个错误。如果spark.driver.memoryOverhead被设置了这个参数就会被忽略。 | Application Properties |
spark.executor.memory | 1g | executor的内存大小 | Application Properties |
spark.executor.pyspark.memory | Not set | 每个executor被分配给pyspark使用的内存,如果设置了就限制了pyspark的内存上线;如果不设置spark不会限制python的内存使用,取决于应用本身是否会超出与其他non-JVM共享的overhead 内存。 | Application Properties |
spark.executor.memoryOverhead | executorMemory * spark.executor.memoryOverheadFactor, 最小值为384M | 每个executor被分配的额外内存。这块内存是用于虚拟机的开销、内部的字符串、还有一些本地开销(比如python需要用到的内存)等。当spark.executor.pyspark.memory没有配置时,额外内存还包括pyspark的executer内存, 也包括同一个容器中的其他non-executor进程。所以运行executor的容器的最大内存大小由spark.executor.memoryOverhead, spark.executor.memory, spark.memory.offHeap.size ,spark.executor.pyspark.memory之和确定。 | Application Properties |
spark.executor.memoryOverheadFactor | 0.1 | executor内存被分配为non-heap内存的比例,如果出现了"Memory Overhead Exceeded",调大这个比例有助于预防这个错误。如果spark.executor.memoryOverhead被设置了这个参数就会被忽略。 | Application Properties |
spark.driver.maxResultSize | 1g | 对于每个spark action(如collect)序列化结果的总大小限制,至少为1M,如果设为0则无限制。如果序列化结果的总大小限制超过这个限制,Job将会中断。将这个值设的很大,可能会造成driver的out-of-memory错误(取决与spark.driver.memory和JVM中对象的overhead内存),所以选取一个合适的值有助于driver产生out-of-memory错误。 | Application Properties |
spark.executor.extraJavaOptions | none | 传给executor的额外JVM选项,比如GC设置和其他日志。注意不能设置最大堆内存(-Xmx),最大推内存是通过spark.executor.memory来设置的。当应用出现堆栈溢出的时候,可能可以通过设置如--conf=spark.executor.extraJavaOptions=-Xss50M来解决 | Runtime Environment |
spark.executor.cores | yarn上为1 standalone模式时为所有可用核数 | executor的核数,一个应用的总核数就是num-executors 乘以executor-cores | Execution Behavior |
spark.default.parallelism | 对于分布式算子如reduceByKey和join,是父RDD里最大partition数,对于像parallelize等没有父RDD的算子,取决于集群模式:Local是机器上的核数;Mesos fine grained为8,其他则是max(2, 所有executor的总核数) | 默认的由transformation 算子如 join, reduceByKey, and parallelize 返回的RDD的分区数 | Execution Behavior |
spark.executor.heartbeatInterval | 10s | 每个executor与driver之间心跳的间隔。这个值需要比spark.network.timeout小很多 | Execution Behavior |
spark.memory.fraction | 0.6 | 用来执行和存储的堆内存比例,越小就涉及越频繁的spills和cached data eviction。此配置的目的是为内部元数据、用户数据结构以及稀疏、异常大的数据的不精确大小估计留出内存。推荐使用默认值,如要设置参考调优文档 | Memory Management |
spark.memory.storageFraction | 0.5 | 不受驱逐的存储内存量,是由spark.memory.fraction预留的区域大小的一部分。 该值越高,可用于执行的工作内存就越少,任务可能会更频繁地溢出到磁盘。推荐使用默认值,如要设置参考调优文档 | Memory Management |
spark.memory.offHeap.enabled | false | 如果设置为true, spark将对某些操作使用off-heap内存,此时需要将spark.memory.offHeap.size设置为正数 | Memory Management |
spark.memory.offHeap.size | 0 | off-heap内存,对于堆内存没有影响,如果executor的总内存有硬限制注意缩减JVM堆内存的大小。 | Memory Management |
spark.network.timeout | 120s | 所有网络交互的默认超时时间,以下的参数如果没有被设置会用这个参数来代替:spark.storage.blockManagerHeartbeatTimeoutMs, spark.shuffle.io.connectionTimeout, spark.rpc.askTimeout ,spark.rpc.lookupTimeout | networking |
spark.shuffle.io.retryWait | 5s | (Netty only)重试提取之间等待的时间。重试造成的最大延迟默认为15秒,计算方式为maxRetries * retryWait | shuffle behavior |
spark.shuffle.io.maxRetries | 3 | (Netty only)如果将其设置为非零值,则由于 IO 相关异常而失败的提取将自动重试。在面对长时间 GC 暂停或暂时性网络连接问题时,此重试逻辑有助于稳定大shuffle。 | shuffle behavior |
spark.sql.broadcastTimeout | 300 | 在广播join中广播等待时间的超时时间(s) | runtime sql configuration |
spark.sql.adaptive.enabled | true | 当设置为true时,启用自适应查询执行,这会根据运行时的统计信息在查询执行过程中重新优化查询计划。 | runtime sql configuration |
spark.sql.adaptive.skewJoin.enabled | true | 当true且spark.sql.adaptive.enabled=true,spark会在shuffled join中通过切分倾斜的分区来动态的处理数据倾斜 | runtime sql configuration |
spark.sql.adaptive.coalescePartitions.enabled | true | 当true且spark.sql.adaptive.enabled=true,Spark将根据目标大小(由spark.sql.adaptive.advisoryPartitionSizeInBytes指定)合并连续的shuffle分区,以避免太多的小任务 | runtime sql configuration |
spark.sql.execution.arrow.pyspark.enabled | false | 如果为 true,则在 PySpark 中使用 Apache Arrow 进行列式数据传输。优化应用于1.pyspark.sql.DataFrame.toPandas。2. pyspark.sql.SparkSession.createDataFrame 当其输入是 Pandas DataFrame 或 NumPy ndarray. 以下数据类型不支持: TimestampType的ArrayType | runtime sql configuration |
spark.sql.shuffle.partitions | 200 | 为join或聚合而shuffle数据时使用的默认分区数 | runtime sql configuration |
spark.sql.hive.convertMetastoreParquet | true | 当设置为 true 时,内置 Parquet 读取器和写入器用于处理使用 HiveQL 语法创建的 Parquet 表,而不是 Hive serde | runtime sql configuration |
一个yarn模式下cluster提交,并且使用自定义python环境的例子
spark-submit \
--deploy-mode cluster \
--master yarn \
--driver-memory 4g \
--num-executors 4 \
--executor-memory 2g \
--executor-cores 2 \
--conf spark.sql.broadcastTimeout=36000 \
--conf spark.driver.maxResultSize=1g \
--conf spark.sql.shuffle.partitions=1000 \
--conf spark.yarn.dist.archives=s3a://path/py37-pyarrow.zip#python37 \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./python37/mypython/bin/python3 \
--conf spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON=./python37/mypython/bin/python3 \
--py-files s3a://path/companymapping.zip \
--queue default \
--name predict_task \
s3a://path/predict.py 20230813参考资料:
- https://spark.apache.org/docs/latest/configuration.html
- https://spark.apache.org/docs/latest/submitting-applications.html
- https://spark.apache.org/docs/latest/running-on-yarn.html#configuration
- https://zhuanlan.zhihu.com/p/63187650
相关文章:

Spark基础-任务提交相关参数
整理一下用过的spark相关的参数 spark应用提交命令spark-submit的常用参数(使用spark-submit --help可以查看所有参数, 有一些参数在下面的spark配置属性定义了,也没有额外列出) 参数默认值含义--master local[*]spark集群的mast…...
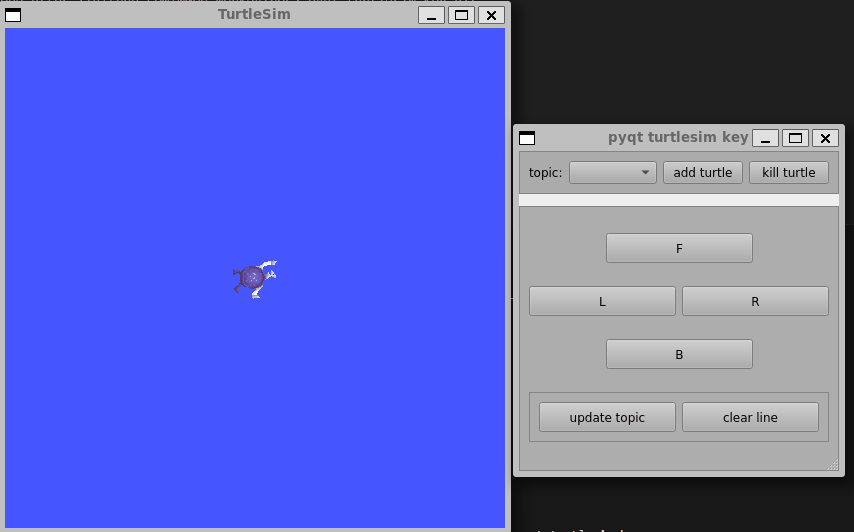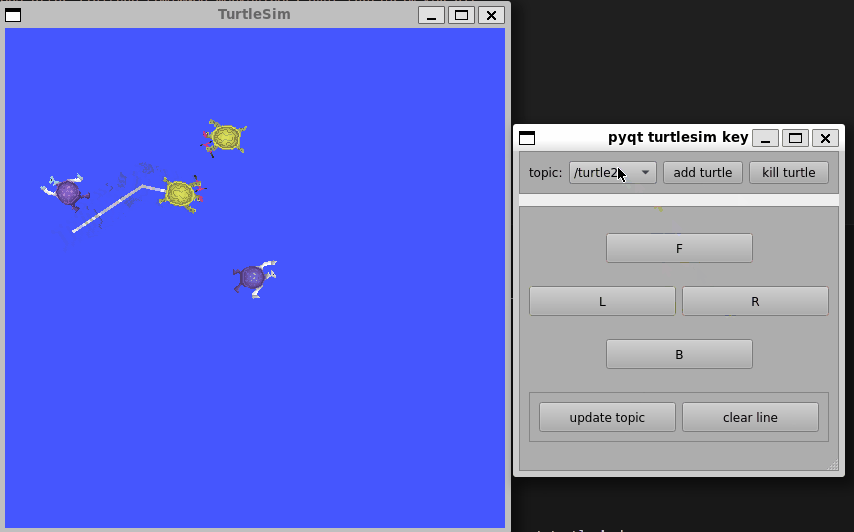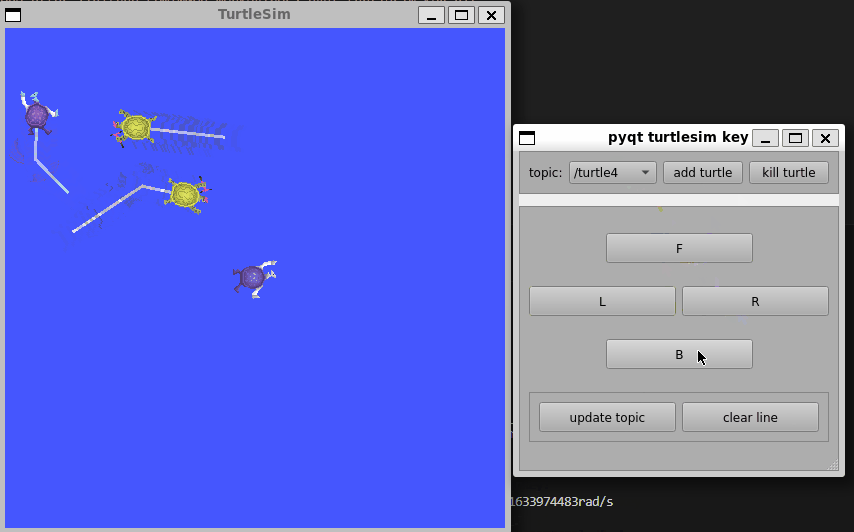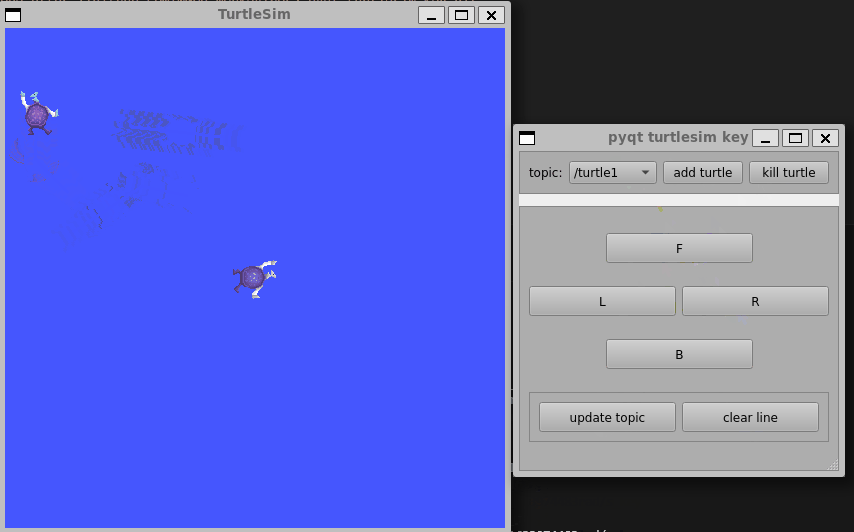
ROS-PyQt小案例
前言:目前还在学习ROS无人机框架中,,, 更多更新文章详见我的个人博客主页【前往】 ROS与PyQt5结合的小demo,用于学习如何设计一个界面,并与ROS中的Service和Topic结合,从而控制多个小乌龟的运动…...
【算法】双指针——leetcode盛最多水的容器、剑指Offer57和为s的两个数字
盛水最多的容器 (1)暴力解法 算法思路:我们枚举出所有的容器大小,取最大值即可。 容器容积的计算方式: 设两指针 i , j ,分别指向水槽板的最左端以及最右端,此时容器的宽度为 j - i 。由于容器…...
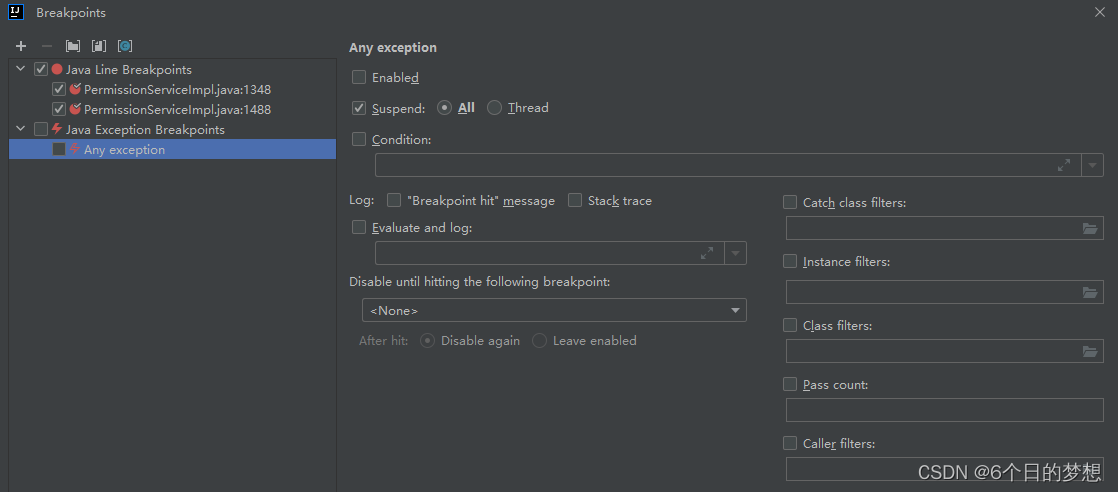
idea 使用debug 启动项目的时候 出现 Method breakpoints may dramatically slow down debugging
问题: 1. 写了一段时间的代码,在debug启动项目后提示:Method breakpoints may dramatically slow down debugging 但是正常启动是可以的,debug不行。 2. idea 里面的项目,很多地方都有断点,现在想要取消全部的断点…...
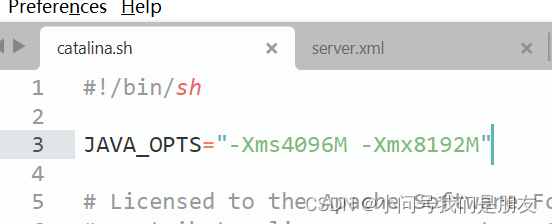
Tomcat的一些配置问题(server.xml/catalina.sh)
在同一机器中运行多个Tomcat时,如果不修改server.xml的端口参数,会出现端口冲突使得Tomcat异常;Tomcat默认配置中,JAVA_OPTS不会设置太大,一般需要在catalina.sh中增加一行配置来加大该参数值。 目录 1.Server.xml配置…...
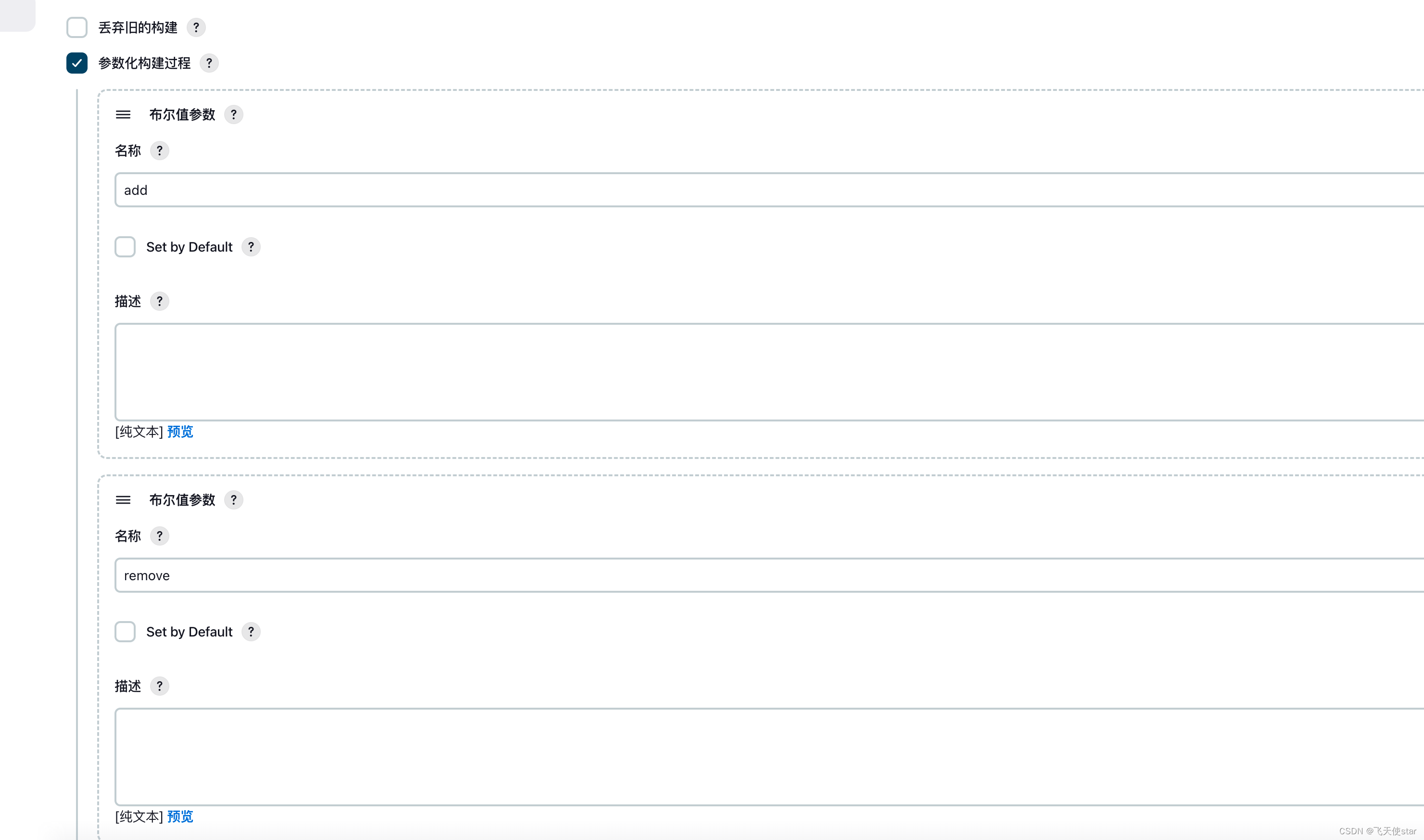
飞天使-jenkins进行远程linux机器修改某个文件的思路
文章目录 jenkins配置的方式jenkins中执行shell的思路 jenkins配置的方式 jenkins中执行shell的思路 下面的脚本别照抄,只是一个思路 ipall"$ips"# 将文本参数按行输出为变量 while IFS read -r line; doecho "$line" if [[ ! -z $line ]] &…...

Revit SDK 介绍:PanelSchedule 配电盘明细表
前言 这个例子介绍 Revit 的配电盘明细表,PanelSchedule。Revit 的电器专业在国内用的并不是十分广泛,但从功能上来说还是比较完整的。 内容 这个例子里有三个命令: PanelScheduleExport - 导出配电盘明细表InstanceViewCreation - 创建配…...

Java后端实现不用pagehelper。手写分页如何实现?
Java后端实现不用pagehelper。手写分页如何实现? 如果你不使用PageHelper这样的分页插件,你可以手动实现分页逻辑。下面是一个使用Java后端手写分页的示例: 首先,确定每页显示的数据量和当前页码。 int pageSize 10; // 每页显示的数据量…...

spring 缓存
1.spring缓存注解,可以丢在controller,也可以丢在service,也可以丢在mapper。 2.手动操作缓存使用: Autowiredprivate CacheManager cacheManager;3.添加缓存 //添加缓存 Override Cacheable(cacheNames "test", key…...

vue3.0 element-plus 不同版本 el-popover 循环优化
表格内循环el-popover 渲染以后的页面,数据量很大的时候页面会卡,生成的代码: 解决思路:将el-popover提出来,不参与循环,让el-popover只渲染一次 1、以1.1.0-beta.24版为例(低版本)…...
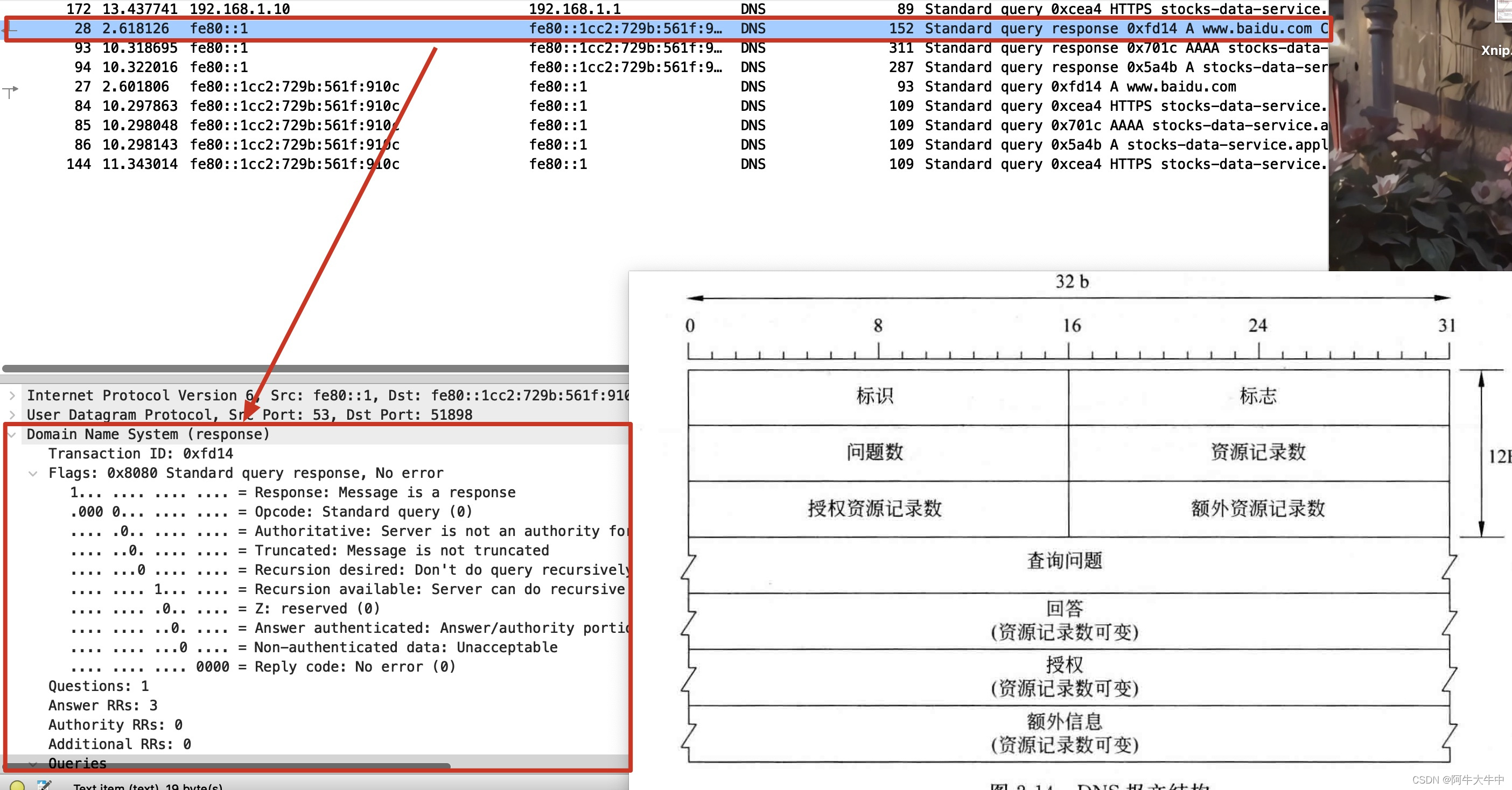
计算机网络实验4:HTTP、DNS协议分析
文章目录 1. 主要教学内容2. HTTP协议3. HTTP分析实验【实验目的】【实验原理】【实验内容】【实验思考】 4. HTTP分析实验可能遇到的问题4.1 捕捉不到http报文4.2 百度是使用HTTPS协议进行传输4.3 Wireshark获得数据太多如何筛选4.4 http报文字段含义不清楚General(…...
敏捷项目管理如何做好Sprint Backlog?迭代管理
什么是Sprint Backlog? Sprint Backlog是Scrum的主要工件之一。在Scrum中,团队按照迭代的方式工作,每个迭代称为一个Sprint。在Sprint开始之前,PO会准备好产品Backlog,准备好的产品Backlog应该是经过梳理、估算和优先…...

实验三 图像分割与描述
一、实验目的: (1)进一步掌握图像处理工具Matlab,熟悉基于Matlab的图像处理函数。 (2)掌握图像分割方法,熟悉常用图像描述方法。 二、实验原理 1.肤色检测 肤色是人类皮肤重要特征之一ÿ…...
)
npm使用国内淘宝镜像的方法(两种)
一、通过命令配置 1、设置淘宝镜像源 npm config set registry https://registry.npm.taobao.org/ 2、设置官方镜像源 npm config set registry https://registry.npmjs.org 3、查看镜像使用状态: npm config get registry 如果返回https://registry.npm.taobao.org…...
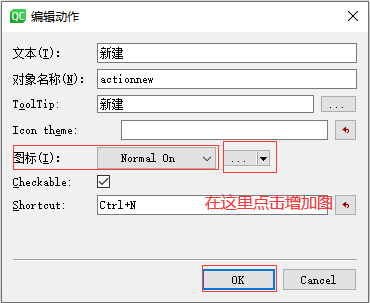
05应用程序设计和文件操作
一、 给应用程序设置菜单栏 比如: 在qt中,如果想要使用菜单栏功能,那么界面的基类要选择QMainWindow,不能选择QWidget QDialog 实现菜单栏步骤如下: 第一步:在UI设计师,直接双击菜单栏 第二步:在UI设计师,修改文本内容和其他设置 进行设置 设置的效果图如下: …...

【果树农药喷洒机器人】Part8:果树对靶变量喷药实验
📢:博客主页 【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍 收藏 ⭐不迷路🙉 📢:内容若有错误,敬请留言 📝指正…...
})
framework.beans.factory.annotation.Autowired(required=true)}
将其它项目复制过来,启动后会报错 15:24:55.880 [main] ERROR o.s.b.SpringApplication - [reportFailure,843] - Application run failed org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name containerDataHandleC…...
【应用笔记】使用 CW32 实现电池备份(VBAT)功能
前言 电池备份(VBAT)功能的实现方法,一般是使用 MCU 自带的 VBAT 引脚,通过在该引脚连接钮扣电池,当系统电源因故掉电时,保持 MCU 内部备份寄存器内容和 RTC 时间信息不会丢失。 本文档介绍了如何基于 C…...
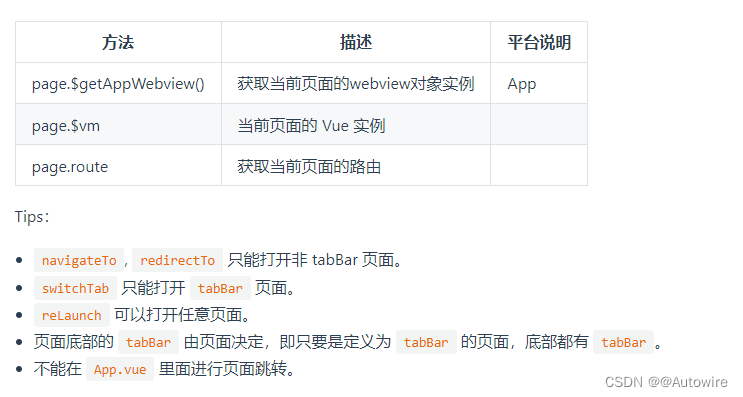
探讨uniapp的navigator 页面跳转问题
navigator 页面跳转。该组件类似HTML中的<a>组件,但只能跳转本地页面。目标页面必须在pages.json中注册。 "tabBar": {"color": "#7A7E83","selectedColor": "#3cc51f","borderStyle": "bl…...

使用Epoll实现高效的多路I/O转接
文章目录 概述1. 理解Epoll机制2. Epoll的三个主要函数3. 基于Epoll实现多路I/O转接4. 总结 概述 在网络编程中,高效地处理大量并发连接是提升系统性能的关键。传统的多线程或多进程模型在这种情况下可能会导致资源消耗过大,而Epoll(事件驱动…...

Godot开源RPG框架选型与状态契约构建指南
1. 这不是又一个“Godot入门教程”,而是一套可落地的RPG世界构建方法论 你有没有试过打开Godot,新建一个项目,拖进几个精灵,写两行 move_and_slide() ,然后卡在“接下来该做什么”上?我做过——整整三年前…...

Unity版本降级实战指南:从2021.1回退到2019.4的四步硬核操作
1. 为什么Unity版本降级不是“回退安装”那么简单 在Unity项目开发中,很多人把“降级”理解成卸载新版本、重装旧版本、再拖进工程——就像换手机系统时刷回上个固件。但Unity的版本管理机制远比这复杂得多。我第一次遇到从2021.1.7f1c1往回降到2019.4.17f1c1的问题…...

ANI-RSS界面美化终极指南:5个技巧打造专属追番体验
ANI-RSS界面美化终极指南:5个技巧打造专属追番体验 【免费下载链接】ani-rss 基于RSS自动追番、订阅、下载、刮削、洗版 项目地址: https://gitcode.com/gh_mirrors/an/ani-rss 你是否厌倦了千篇一律的软件界面?想要让你的追番工具拥有独一无二的…...

基于Python + LLM的AI客服协作系统设计与实现
🧑💻 博主介绍 & 诚邀关注 作者:专注于 Java、Python、前端开发的技术博主 | 全网粉丝 30 万 在校期间协助导师完成毕业设计课题分类、论文格式初审及代码整理工作;工作后持续分享毕设思路,助力毕业生顺利完成…...

15万个科技岗位消失的真相
周四早上7点43分,我的手机震动了一下,是一位同行的消息——另一位我认识了五年的数据团队负责人。他管理的团队规模是我的两倍,所在的公司你一定听说过。 消息只有四个字:“你的人安全吗?” 我立刻明白他的意思。Met…...

人脑记忆机制与神经形态计算应用解析
1. 记忆存储的神经机制解析 人脑的记忆系统是一个精密的层级结构,从短暂的感官印象到持久的经验存储,整个过程涉及多个脑区的协同工作。短期记忆(Short-Term Memory, STM)就像一块随时会被擦除的白板,容量有限且易受干…...

使用curl命令直接调试taotoken大模型api接口的详细方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令直接调试Taotoken大模型API接口的详细方法 对于需要在无SDK环境下进行底层调试、自动化脚本编写或快速验证接口的开发…...

Go语言实战:构建高可用API + HASH上链存证服务,这不是妥协而是最优解
关键词:Go, 区块链, 存证, SHA256, 签名, 高并发 前言 在关于区块链落地的技术讨论中,"链下计算 + 链上存证"模式常常被贴上"妥协方案"的标签。很多人认为,只有把数据完全搬到链上,才能体现区块链的价值。 然而,经过大规模生产环境的验证,我们发现…...

单北斗GNSS变形监测系统在地质灾害监测中的应用与维护
北斗 GNSS 变形监测系统在地质灾害监测中发挥着重要作用。它通过高精度定位,实时捕捉地面形变,为防灾减灾提供精准数据支持。系统的定制化设计能适应不同环境,同时具备稳定性与可靠性。随着技术发展,监测和维护也变得更高效。这种…...

抖音批量下载工具:免费无水印下载完整指南
抖音批量下载工具:免费无水印下载完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量…...