LoRA微调方法详解
本文要介绍的是大模型的微调训练方法之一----LoRA。
0 背景
现在大模型非常火爆,大家都在想方设法应用大模型。 当前很多大模型虽说可以zero-shot直接使用, 但是在具体应用上一般还是微调一下效果更好, 也就是常说的finetune。 在小模型时代, finetune不是个问题。 但大模型时代, finetune是个大问题。 这是因为现在的大模型参数动辄10B起, 训练的代价非常高昂,即使是finetune也对计算资源有很高要求(finetune只是训练的步数少, 对显存等计算资源的占用并没有少)。 没个上百G的显存是玩不动的, 这对普通人的门槛实在太高了。
那么高效的finetune方式就非常必要了。LoRA就是高效finefune方法的一种。
1 LoRA原理
LoRA论文: LoRA: Low-Rank Adaptation of Large Language Models
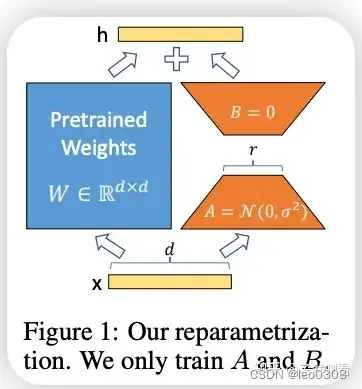
LoRA的原理非常简单, 先上一张图, 其实从图上已经能清楚地看到大致的原理的。 通俗地讲, 它的原理是这样的:大模型都是过参数化的, 当用于特定任务时, 其实只有一小部分参数起主要作用。 也就是参数矩阵维度很高, 但可以用低维矩阵分解近似。其实这个思想与矩阵特征向量, 主成分分析, 压缩感知等有异曲同工之妙。
具体做法是, 在网络中增加一个旁路结构,旁路是A和B两个矩阵相乘。 A矩阵的维度是dxr, B 矩阵的维度是rxd, 其中r<<d, 一般r取1,2,4,8就够了。那么这个旁路的参数量将远远小于原来网络的参数W。LoRA训练时, 我们冻结原来网络的参数W, 只训练旁路参数A和B。 由于A和B的参数量远远小于W, 那么训练时需要的显存开销就大约等于推理时的开销。 对采用Adam优化器来说, 需要的显存就大约相当于全参数finetune的1/3, 极大地减小了训练的代价。
论文中作者的实验也证明了这一点。 在GPT-3 175B的finetune中, 采用LoRA微调显存的消耗从1.2TB 降低到了350GB, 大约是三分之一
其实采用这种旁路相加的方式, 与ResNet的跳连方式也有异曲同工之妙。 原网络的参数不变, 在旁路上做些微小改变, 适应特定新任务。 这样就可以让网络基本保持原来的能力, 在特定任务上更精进了一步。
值得注意的是, LoRA微调并没有改变原有的预训练参数, 只是针对特定任务微调出了新的少量参数, 新的这些参数要与原有的预训练参数配合使用(实际使用时, 都是把旁路的参数和原来的参数直接合并, 也就是参数相加, 这样就完全不会增加推理时间)。这是非常方便的, 针对不同的任务, 都可以训练出自己的LoRA参数, 然后与原本的预训练参数结合, 做成插件式的应用。 这就是最近大火的SD + LoRA。全参数微调一般没这个条件, 但LoRA微调还是可以的。 目前Civitai上有上万LoRA的模型, 并且还在迅速增加。
2 代码详解
LoRA代码: https://github.com/microsoft/LoRA
LoRA原理很简单, 代码实现也不复杂。 简单地说,在模型实现上, 要在特定的模块上加一个旁路, 这个旁路就是两个矩阵相乘的形式。这些特定的模块理论上可以是任何模块, 目前作者实现的是在Linear, Embeding, Conv, Attention(只改其中的q和v)这些模块上加。
具体实现见:https://github.com/microsoft/LoRA/blob/main/loralib/layers.py
拿其中的Linear做个简单分析吧, 其他都是类似的。
class LoRALayer():def __init__(self, r: int, lora_alpha: int, lora_dropout: float,merge_weights: bool,):self.r = rself.lora_alpha = lora_alpha# Optional dropoutif lora_dropout > 0.:self.lora_dropout = nn.Dropout(p=lora_dropout)else:self.lora_dropout = lambda x: x# Mark the weight as unmergedself.merged = Falseself.merge_weights = merge_weightsclass Linear(nn.Linear, LoRALayer):# LoRA implemented in a dense layerdef __init__(self, in_features: int, out_features: int, r: int = 0, lora_alpha: int = 1, lora_dropout: float = 0.,fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)merge_weights: bool = True,**kwargs):nn.Linear.__init__(self, in_features, out_features, **kwargs)LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,merge_weights=merge_weights)self.fan_in_fan_out = fan_in_fan_out# Actual trainable parametersif r > 0:self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))self.scaling = self.lora_alpha / self.r# Freezing the pre-trained weight matrixself.weight.requires_grad = Falseself.reset_parameters()if fan_in_fan_out:self.weight.data = self.weight.data.transpose(0, 1)def reset_parameters(self):nn.Linear.reset_parameters(self)if hasattr(self, 'lora_A'):# initialize A the same way as the default for nn.Linear and B to zeronn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))nn.init.zeros_(self.lora_B)def train(self, mode: bool = True):def T(w):return w.transpose(0, 1) if self.fan_in_fan_out else wnn.Linear.train(self, mode)if mode:if self.merge_weights and self.merged:# Make sure that the weights are not mergedif self.r > 0:self.weight.data -= T(self.lora_B @ self.lora_A) * self.scalingself.merged = Falseelse:if self.merge_weights and not self.merged:# Merge the weights and mark itif self.r > 0:self.weight.data += T(self.lora_B @ self.lora_A) * self.scalingself.merged = True def forward(self, x: torch.Tensor):def T(w):return w.transpose(0, 1) if self.fan_in_fan_out else wif self.r > 0 and not self.merged:result = F.linear(x, T(self.weight), bias=self.bias) result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scalingreturn resultelse:return F.linear(x, T(self.weight), bias=self.bias)在Linear层的实现上,多继承了一个LoRALayer, LoRALayer中就是设置了一些参数, 最主要的就是上面的讲道的矩阵的秩r了,其他就是一些辅助参数, 如控制训练和推理时主路参数和旁路参数是否合并等等。 在Linear层中, 多定义了A和B两个可训练的参数矩阵, 然后在forward中把主路和旁路输出相加, 基本上就是完全按照原理来的。
3 使用
实际使用LoRA微调时, 也不用自己向上面那样实现了。上面的loralib库已经实现好了, 直接使用就好了。具体而言, 就是把网络中原来使用nn.Linear用loralib库中的Linear替换就可以了, 其他的模块同理。
实际上, 还有更简洁的方式,huggingface pert库很贴心地把各种finetune方式都做了集成, 更加简单和方便。
相关文章:
LoRA微调方法详解
本文要介绍的是大模型的微调训练方法之一----LoRA。 0 背景 现在大模型非常火爆,大家都在想方设法应用大模型。 当前很多大模型虽说可以zero-shot直接使用, 但是在具体应用上一般还是微调一下效果更好, 也就是常说的finetune。 在小模型时代…...
redis-数据类型及样例
一.string 类型数据的基本操作 1.添加/修改数据 set key value2.获取数据 get key3.删除数据 del key4.添加/修改多个数据 mset key1 value1 key2 value25.获取多个数据 mget key1 key2二.list类型的基本操作 数据存储需求:存储多个数据,并对数据…...

公司电脑三维图纸加密、机械图挡加密软件
机械图纸加密软件的问世,让很多的网络公司都大受其带来的工作中的便利。在安装了机械图纸加密软件后,不仅可以很好的管理员工在工作时的上网娱乐,在对整个公司员工的工作效率上也有着明显的提高,那么对于机械图纸加密软件的具体特…...
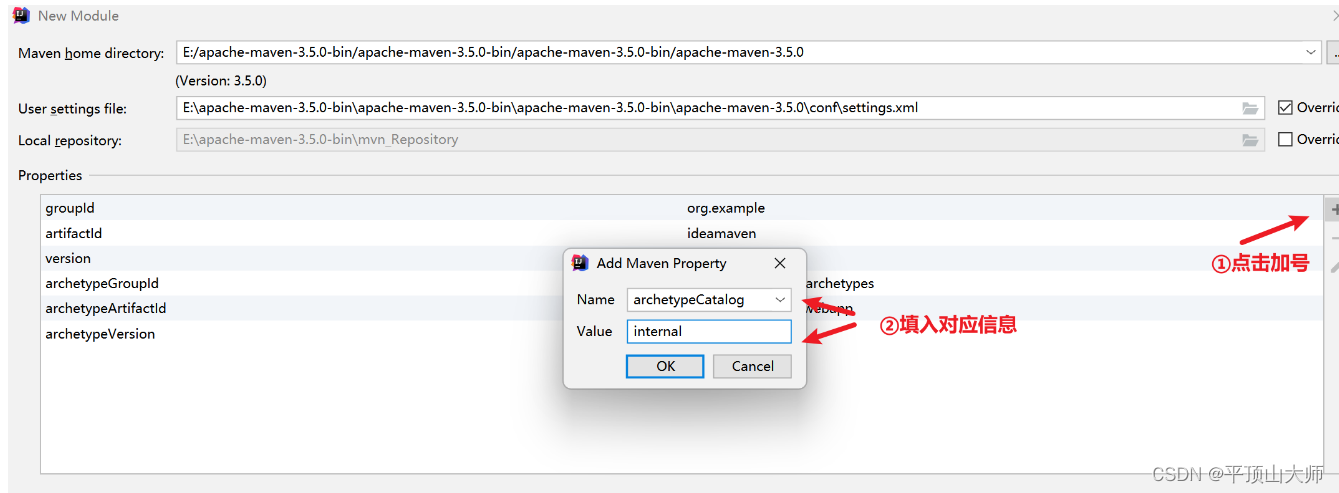
安装使用IDEA,修改样式,配置服务,构建Maven项目(超级详细版)
目录 前言: 一,安装 1.1打开官网JetBrains: Essential tools for software developers and teams点击 Developer Tools,再点击 Intellij IDEA 2.点击下载编辑 3.选择对应的版本,左边的 Ultimate 版本为旗舰版,需要…...
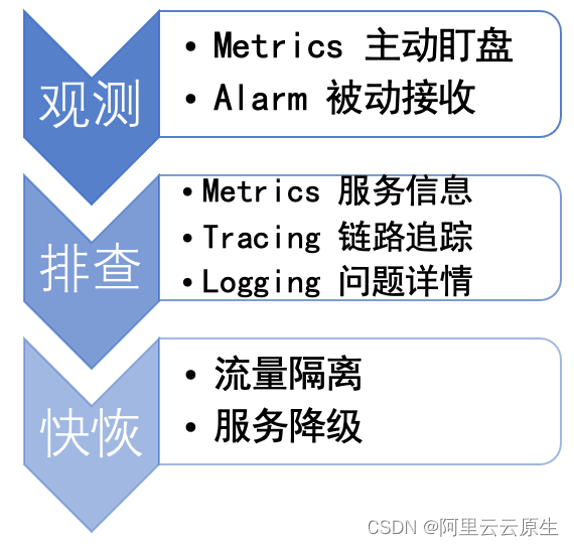
Apache Dubbo 云原生可观测性的探索与实践
作者:宋小生 - 平安壹钱包中间件资深工程师 Dubbo3 可观测能力速览 Apache Dubbo3 在云原生可观测性方面完成重磅升级,使用 Dubbo3 最新版本,你只需要引入 dubbo-spring-boot-observability-starter 依赖,微服务集群即原生具备以…...
DaVinci Resolve Studio 18 for Mac 达芬奇调色
DaVinci Resolve Studio 18是一款专业的视频编辑和调色软件,适用于电影、电视节目、广告等各种视觉媒体的制作。它具有完整的后期制作功能,包括剪辑、调色、特效、音频处理等。 以下是DaVinci Resolve Studio 18的主要特点: - 提供了全面的视…...

Excelize Go语言操作 Office Excel文档基础库
Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准。可以使用它来读取、写入由 Microsoft Excel™ 2007 及以上版本创建的电子表格文档。支持 XLAM / XLSM / XLSX / XLTM / XLTX 等多种文档格式…...

SpringBoot、Java 使用 Jsoup 解析 HTML 页面
使用 Jsoup 解析 HTML 页面 什么是 Jsoup? Jsoup 是一个用于处理 HTML 页面的 Java 库,它提供了简单的 API,使得从 HTML 中提取数据变得非常容易。无论是获取特定标签的内容还是遍历整个页面的元素,Jsoup 都能轻松胜任。 如何使…...

C# 随心记
#region 批量保存到数据库 public bool InsertDB(DataTable dt) { bool bResult true; LogInfo.WriteTextToFile("使用Bulk插入的实现方式"); Stopwatch sw new Stopwatch(); using (SqlConnecti…...

华为OD机试-字符串分割
题目描述 给定一个非空字符串S,其被N个‘-’分隔成N1的子串,给定正整数K,要求除第一个子串外,其余的子串每K个字符组成新的子串,并用‘-’分隔。对于新组成的每一个子串,如果它含有的小写字母比大写字母多…...

element-ui的el-dialog,简单的封装。
el-dialog是使用率很高的组件 使用el-dialog很多都是按照文档的例子,用一个变量控制是否显示,再来一个变量控制标题。 如果我这个对话框多个地方使用的话还要创建多个变量,甚至关闭之后还要清空一些变量,应该可以简化一点。我写…...
SpringBoot引入外部jar打包失败解决,SpringBoot手动引入jar打包war后报错问题
前言 使用外部手动添加的jar到项目,打包时出现jar找不到问题解决 处理 例如项目结构如下 引入方式换成这种 <!-- 除了一下这两种引入外部jar,还是可以将外部jar包添加到maven中(百度查)--><!-- pdf转word --><…...

HTTP基础:学习HTTP协议的基本知识,了解请求和响应的过程
HTTP(Hypertext Transfer Protocol,超文本传输协议)是一种用于传输超媒体文档(如HTML)的应用层协议,它是Web中最基本的协议。 HTTP请求和响应都是由客户端和服务器之间进行的。 一个完整的HTTP请求由以下几…...

Spark基础-任务提交相关参数
整理一下用过的spark相关的参数 spark应用提交命令spark-submit的常用参数(使用spark-submit --help可以查看所有参数, 有一些参数在下面的spark配置属性定义了,也没有额外列出) 参数默认值含义--master local[*]spark集群的mast…...
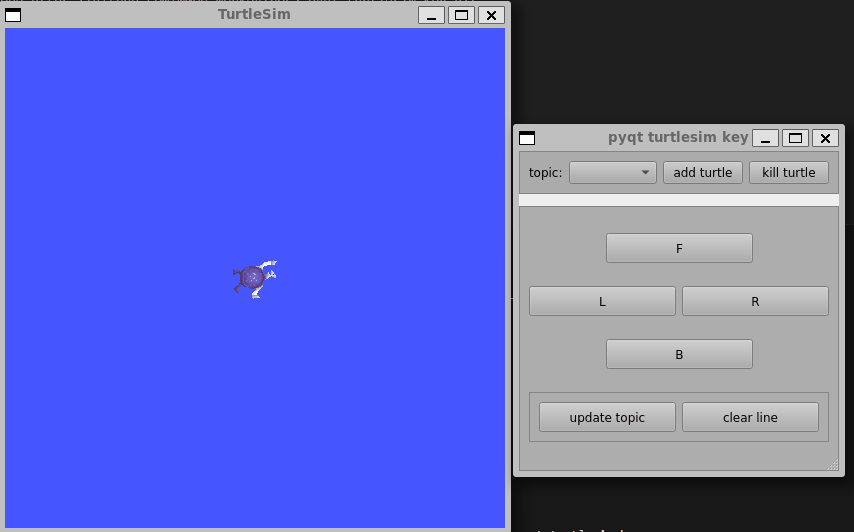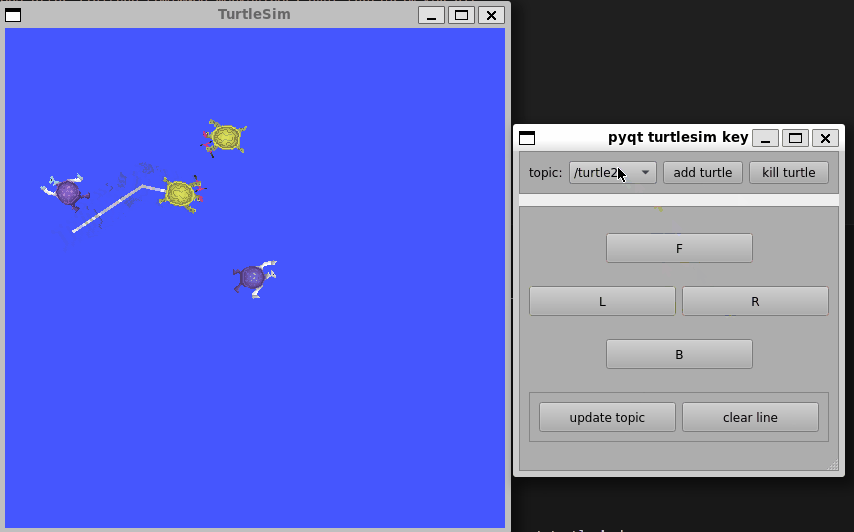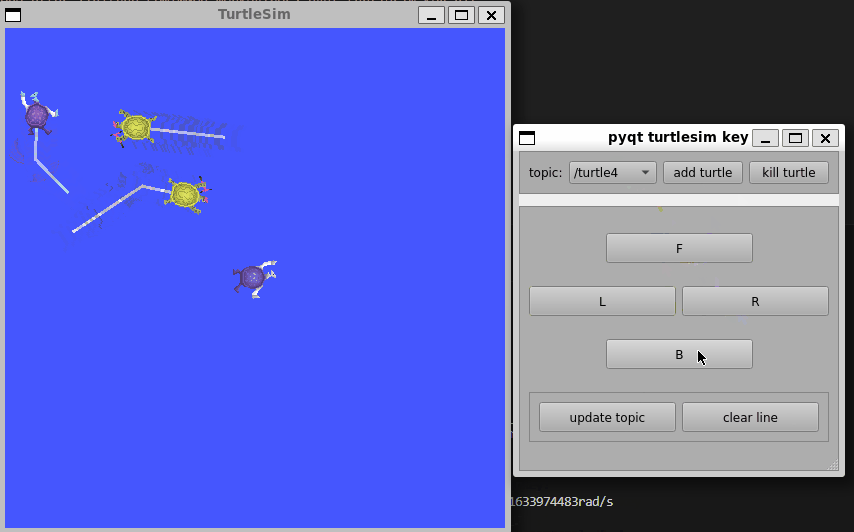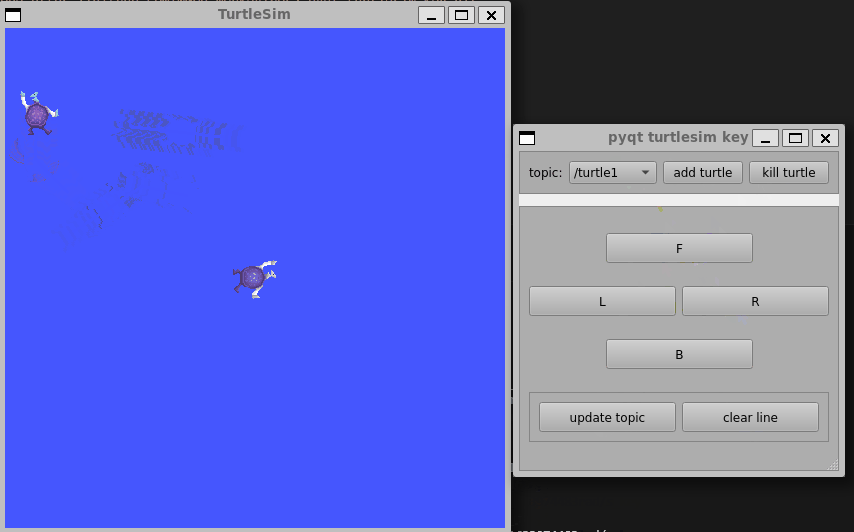
ROS-PyQt小案例
前言:目前还在学习ROS无人机框架中,,, 更多更新文章详见我的个人博客主页【前往】 ROS与PyQt5结合的小demo,用于学习如何设计一个界面,并与ROS中的Service和Topic结合,从而控制多个小乌龟的运动…...
【算法】双指针——leetcode盛最多水的容器、剑指Offer57和为s的两个数字
盛水最多的容器 (1)暴力解法 算法思路:我们枚举出所有的容器大小,取最大值即可。 容器容积的计算方式: 设两指针 i , j ,分别指向水槽板的最左端以及最右端,此时容器的宽度为 j - i 。由于容器…...
idea 使用debug 启动项目的时候 出现 Method breakpoints may dramatically slow down debugging
问题: 1. 写了一段时间的代码,在debug启动项目后提示:Method breakpoints may dramatically slow down debugging 但是正常启动是可以的,debug不行。 2. idea 里面的项目,很多地方都有断点,现在想要取消全部的断点…...
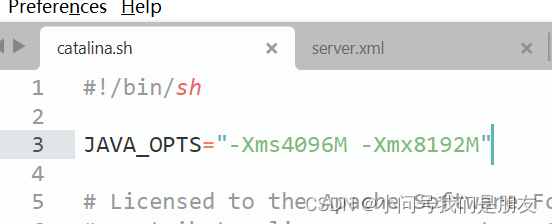
Tomcat的一些配置问题(server.xml/catalina.sh)
在同一机器中运行多个Tomcat时,如果不修改server.xml的端口参数,会出现端口冲突使得Tomcat异常;Tomcat默认配置中,JAVA_OPTS不会设置太大,一般需要在catalina.sh中增加一行配置来加大该参数值。 目录 1.Server.xml配置…...
飞天使-jenkins进行远程linux机器修改某个文件的思路
文章目录 jenkins配置的方式jenkins中执行shell的思路 jenkins配置的方式 jenkins中执行shell的思路 下面的脚本别照抄,只是一个思路 ipall"$ips"# 将文本参数按行输出为变量 while IFS read -r line; doecho "$line" if [[ ! -z $line ]] &…...

Revit SDK 介绍:PanelSchedule 配电盘明细表
前言 这个例子介绍 Revit 的配电盘明细表,PanelSchedule。Revit 的电器专业在国内用的并不是十分广泛,但从功能上来说还是比较完整的。 内容 这个例子里有三个命令: PanelScheduleExport - 导出配电盘明细表InstanceViewCreation - 创建配…...

分布式/集群/微服务
分布式:将一个系统划分为多个子系统,每个子系统在不同的服务器上运行,并通过网络通信进行协作集群:一组相互独立的计算机系统协同工作,共同提供服务或处理任务,它们之间可以共享资源和负载均衡微服务&#…...

小红书内容采集终极指南:一键下载无水印图文视频的完整教程
小红书内容采集终极指南:一键下载无水印图文视频的完整教程 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接…...

Triton+KServe构建高稳定性AI模型服务架构
1. 项目概述:当模型走出Jupyter,真正开始呼吸真实世界空气“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题本身就像一句暗号,专为那些在Jupyter里调通了模型、画出了漂亮ROC曲线、却在把模型推上服务器…...

Gemini 3.5十大应用场景:从代码生成到视频创作
一、软件开发场景 1.1 代码自动生成 Gemini 3.5 Flash在编码基准测试中达到76.2%,可以: 理解复杂技术文档生成高质量代码自动编写测试用例 # 代码生成示例 prompt """ 根据以下需求编写Python代码: 1. 创建一个REST API服…...

AI教材编写必备:低查重AI工具,助力快速完成教材创作!
教材编写工具的选择与使用 在开始写教材之前,选择合适的工具几乎就像是一场“纠结大赛”!如果使用办公软件,功能通常很有限,框架和格式都需要手动去调整;而使用专业的编写工具,又往往因操作繁琐和学习曲线…...

PowerToys汉化指南:3步让英文效率工具变成你的中文助手
PowerToys汉化指南:3步让英文效率工具变成你的中文助手 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是不是曾经因为PowerToys的英文界面…...

Akebi-GC 实战指南:掌握游戏功能修改与自动化测试技术
Akebi-GC 实战指南:掌握游戏功能修改与自动化测试技术 【免费下载链接】Akebi-GC (Fork) The great software for some game that exploiting anime girls (and boys). 项目地址: https://gitcode.com/gh_mirrors/ak/Akebi-GC 作为一款专注于游戏功能修改与自…...

csp信奥赛C++高频考点专项训练之前缀和差分 --【二维前缀和】:领地选择
csp信奥赛C高频考点专项训练之前缀和&差分 --【二维前缀和】:领地选择 题目描述 作为在虚拟世界里统帅千军万马的领袖,小 Z 认为天时、地利、人和三者是缺一不可的,所以,谨慎地选择首都的位置对于小 Z 来说是非常重要的。 首…...
海洋涡旋分析难题破解:Py Eddy Tracker 中尺度涡旋识别与追踪完整指南
海洋涡旋分析难题破解:Py Eddy Tracker 中尺度涡旋识别与追踪完整指南 【免费下载链接】py-eddy-tracker Eddy identification and tracking 项目地址: https://gitcode.com/gh_mirrors/py/py-eddy-tracker 海洋中尺度涡旋研究面临三大核心挑战:人…...

观察Taotoken在不同网络环境下API调用的延迟表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在不同网络环境下API调用的延迟表现 在将大模型API集成到实际应用时,网络环境是影响开发者体验的关键因素…...