GPT垂直领域相关模型 现有的开源领域大模型
对于ToC端来说,广大群众的口味已经被ChatGPT给养叼了,市场基本上被ChatGPT吃的干干净净。虽然国内大厂在紧追不舍,但目前绝大多数都还在实行内测机制,大概率是不会广泛开放的(毕竟,各大厂还是主盯ToB、ToG市场的,从华为在WAIC的汇报就可以看出)。而对于ToB和ToG端来说,本地化部署、领域or行业内效果绝群、国产化无疑就成为了重要的考核指标。
个人觉得垂直领域大模型或者说大模型领域化、行业化才是大模型落地的核心要素。恰好前几天ChatLaw(一款法律领域大模型产品)也是大火,当时也是拿到了一手内测资格测试了一阵,也跟该模型的作者聊了很久。正好利用周末的时间,好好思考、梳理、汇总了一些垂直领域大模型内容。
文章内容将从ChatLaw展开、到垂直领域大模型的一些讨论、最后汇总一下现有的开源领域大模型。
聊聊对ChatLaw的看法
ChatLaw的出现,让我更加肯定未来大模型落地需要具有领域特性。相较于目前领域大模型,ChatLaw不仅仅是一个模型,而是一个经过设计的大模型领域产品,已经在法律领域具有很好的产品形态。
Paper: https://arxiv.org/pdf/2306.16092.pdf
Github: https://github.com/PKU-YuanGroup/ChatLaw官网: https://www.chatlaw.cloud/
可能会有一些质疑,比如:不就是一个langchain吗?法律领域它能保证事实性问题吗?等等等。但,我觉得在否定一件事物的前提,是先去更深地了解它。
ChatLaw共存在两种模式:普通模型和专业模型。普通模式就是仅基于大模型进行问答。
而专业模式是借助检索的手段,对用户查询进行匹配从知识库中筛选出合适的证据,再根据大模型汇总能力,得到最终答案。
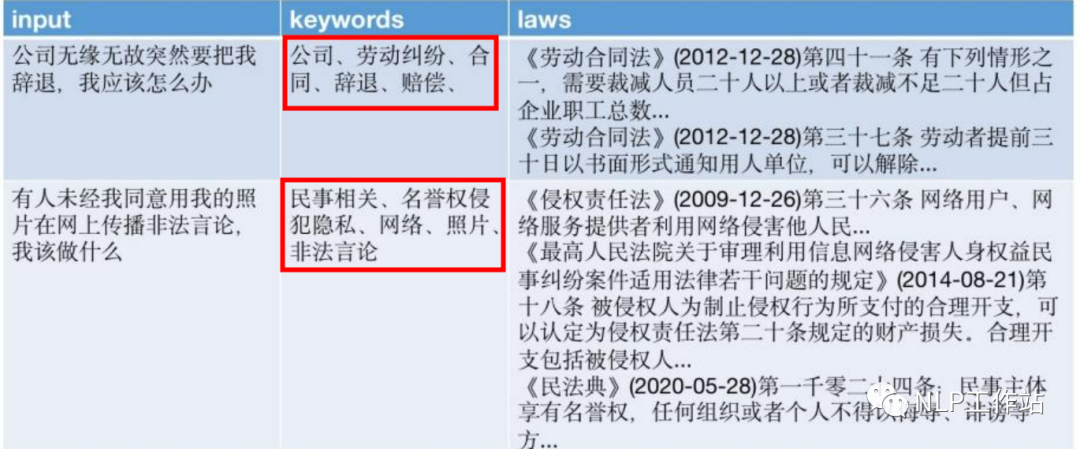
由于专业模式,借助了知识库的内容,也会使得用户得到的效果更加精准。而在专业版中,ChatLaw制定了一整套流程,如上图所示,存在反问提示进行信息补全,用户信息确认、相似案例检索、建议汇总等。
作者@JessyTsui(知乎) 也说过,其实ChatLaw=ChatLaw LLM + keyword LLM + laws LLM。而keyword LLM真的让我眼前一亮的,之前对关键词抽取的理解,一直是从文本中找到正确的词语,在传统检索中使用同义词等方法来提高检索效果。而keyword LLM利用大模型生成关键词,不仅可以找到文本中的重点内容,还可以总结并释义出一些词。使得整个产品在检索证据内容时,效果更加出色。
同时,由于不同模型对不同类型问题解决效果并不相同,所以在真正使用阶段,采用HuggingGPT作为调度器的方式,在每次用户请求的时候去选择调用更加适配的模型。也就是让适合的模型做更适合的事情。
聊聊对垂直领域大模型的看法
现在大模型的使用主要就是两种模型,第一种是仅利用大模型本身解决用户问题;第二种就是借助外部知识来解决用户问题。而我个人觉得是“借助外部知识进行问答”才是未来,虽然会对模型推理增加额外成本,但是外部知识是缓解模型幻觉的有效方法。
但随着通用大模型底层能力越来越强,以及可接受文本越来越长,在解决垂直领域问题时,完全可以采用ICL技术,来提升通用大模型在垂直领域上的效果,那么训练一个垂直领域大模型是否是一个伪命题,我们还有必要做吗?
个人认为是需要的,从几个方面来讨论:
-
1、个人觉得真正垂直领域大模型的做法,应该从Pre-Train做起。SFT只是激发原有大模型的能力,预训练才是真正知识灌输阶段,让模型真正学习领域数据知识,做到适配领域。但目前很多垂直领域大模型还停留在SFT阶段。
-
2、对于很多企业来说,领域大模型在某几个能力上绝群就可以了。难道我能源行业,还需要care模型诗写的如何吗?所以领域大模型在行业领域上效果是优于通用大模型即可,不需要“即要又要还要”。
-
3、不应某些垂直领域大模型效果不如ChatGPT,就否定垂直领域大模型。有没有想过一件可怕的事情,ChatGPT见的垂直领域数据,比你的领域大模型见的还多。但某些领域数据,ChatGPT还是见不到的。
-
4、考虑到部署成本得问题,我觉得在7B、13B两种规模的参数下,通用模型真地干不过领域模型。及时175B的领域大模型没有打过175B的通用模型又能怎么样呢?模型参数越大,需要数据量越大,领域可能真的没有那么多数据。
PS:很多非NLP算法人员对大模型产品落地往往会有一些疑问:
Q:我有很多的技术标准和领域文本数据,直接给你就能训练领域大模型了吧?
A:是也不是,纯文本只能用于模型的预训练,真正可以进行后续问答,需要的是指令数据。当然可以采用一些人工智能方法生成一些指数据,但为了保证事实性,还是需要进行人工校对的。高质量SFT数据,才是模型微调的关键。
Q:你用领域数据微调过的大模型,为什么不直接问答,还要用你的知识库?
A:外部知识主要是为了解决模型幻觉、提高模型回复准确。
Q:为什么两次回复结果不一样?
A:大模型一般为了保证多样性,解码常采用Top-P、Top-K解码,这种解码会导致生成结果不可控。如果直接采用贪婪解码,模型生成结果会是局部最优。
Q:我是不是用开源6B、7B模型自己训练一个模型就够了?
A:兄弟,没有训练过33B模型的人,永远只觉得13B就够了。
以上是个人的一些想法,以及一些常见问题的回复,不喜勿喷,欢迎讨论,毕竟每个人对每件事的看法都不同。
开源垂直领域大模型汇总
目前有很多的垂直领域大模型已经开源,主要在医疗、金融、法律、教育等领域,本小节主要进行「中文开源」模型的汇总及介绍。
「PS:一些领域大模型,如未开源不在该汇总范围内;并且欢迎大家留言,查缺补漏。」
医疗领域
非中文项目:BioMedLM、PMC-LLaMA、ChatDoctor、BioMedGPT等,在此不做介绍。
MedicalGPT-zh
Github: https://github.com/MediaBrain-SJTU/MedicalGPT-zh
-
简介:基于ChatGLM-6B指令微调的中文医疗通用模型。
-
数据:通过对16组诊疗情景和28个科室医用指南借助ChatGPT构造182k条数据。数据也已开源。
-
训练方法:基于ChatGLM-6B,采用Lora&16bit方法进行模型训练。
DoctorGLM
Github: https://github.com/xionghonglin/DoctorGLM
-
简介:一个基于ChatGLM-6B的中文问诊模型。
-
数据:主要采用CMD(Chinese Medical Dialogue Data)数据。
-
训练方法:基于ChatGLM-6B模型,采用Lora和P-tuning-v2两种方法进行模型训练。
PS:数据来自Chinese-medical-dialogue-data项目。
Huatuo-Llama-Med-Chinese
Github: https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
-
简介:本草(原名:华驼-HuaTuo): 基于中文医学知识的LLaMA微调模型。
-
数据:通过医学知识图谱和GPT3.5 API构建了中文医学指令数据集,数据共开源9k条。
-
训练方法:基于Llama-7B模型,采用Lora方法进行模型训练。
Med-ChatGLM
Github: https://github.com/SCIR-HI/Med-ChatGLM
-
简介:基于中文医学知识的ChatGLM模型微调,与本草为兄弟项目。
-
数据:与Huatuo-Llama-Med-Chinese相同。
-
训练方法:基于ChatGLM-6B模型,采用Lora方法进行模型训练。
ChatMed
Github: https://github.com/michael-wzhu/ChatMed
-
简介:中文医疗大模型,善于在线回答患者/用户的日常医疗相关问题.
-
数据:50w+在线问诊+ChatGPT回复作为训练集。
-
训练方法:基于Llama-7B模型,采用Lora方法进行模型训练。
ShenNong-TCM-LLM
Github: https://github.com/michael-wzhu/ShenNong-TCM-LLM
-
简介:“神农”大模型,首个中医药中文大模型,与ChatMed为兄弟项目。
-
数据:以中医药知识图谱为基础,采用以实体为中心的自指令方法,调用ChatGPT得到11w+的围绕中医药的指令数据。
-
训练方法:基于Llama-7B模型,采用Lora方法进行模型训练。
BianQue
Github: https://github.com/scutcyr/BianQue
-
简介:扁鹊,中文医疗对话模型。
-
数据:结合当前开源的中文医疗问答数据集(MedDialog-CN、IMCS-V2、CHIP-MDCFNPC、MedDG、cMedQA2、Chinese-medical-dialogue-data),分析其中的单轮/多轮特性以及医生问询特性,结合实验室长期自建的生活空间健康对话大数据,构建了千万级别规模的扁鹊健康大数据BianQueCorpus。
-
训练方法:扁鹊-1.0以ChatYuan-large-v2作为底座模型全量参数训练得来,扁鹊-2.0以ChatGLM-6B作为底座模型全量参数训练得来。
SoulChat
Github: https://github.com/scutcyr/SoulChat
-
简介:中文领域心理健康对话大模型,与BianQue为兄弟项目。
-
数据:构建了超过15万规模的单轮长文本心理咨询指令数据,并利用ChatGPT与GPT4,生成总共约100万轮次的多轮回答数据。
-
训练方法:基于ChatGLM-6B模型,采用全量参数微调方法进行模型训练。
法律领域
LaWGPT
Github: https://github.com/pengxiao-song/LaWGPT
-
简介:基于中文法律知识的大语言模型。
-
数据:基于中文裁判文书网公开法律文书数据、司法考试数据等数据集展开,利用Stanford_alpaca、self-instruct方式生成对话问答数据,利用知识引导的数据生成,引入ChatGPT清洗数据,辅助构造高质量数据集。
-
训练方法:(1)Legal-Base-7B模型:法律基座模型,使用50w中文裁判文书数据二次预训练。(2)LaWGPT-7B-beta1.0模型:法律对话模型,构造30w高质量法律问答数据集基于Legal-Base-7B指令精调。(3)LaWGPT-7B-alpha模型:在Chinese-LLaMA-7B的基础上直接构造30w法律问答数据集指令精调。(4)LaWGPT-7B-beta1.1模型:法律对话模型,构造35w高质量法律问答数据集基于Chinese-alpaca-plus-7B指令精调。
ChatLaw
Github: https://github.com/PKU-YuanGroup/ChatLaw
-
简介:中文法律大模型
-
数据:主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据。
-
训练方法:(1)ChatLaw-13B:基于姜子牙Ziya-LLaMA-13B-v1模型采用Lora方式训练而来。(2)ChatLaw-33B:基于Anima-33B采用Lora方式训练而来。
LexiLaw
Github: https://github.com/CSHaitao/LexiLaw
-
简介:中文法律大模型
-
数据:BELLE-1.5M通用数据、LawGPT项目中52k单轮问答数据和92k带有法律依据的情景问答数据、Lawyer LLaMA项目中法考数据和法律指令微调数据、华律网20k高质量问答数据、百度知道收集的36k条法律问答数据、法律法规、法律参考书籍、法律文书。
-
训练方法:基于ChatGLM-6B模型,采用Freeze、Lora、P-Tuning-V2三种方法进行模型训练。
LAW-GPT
Github: https://github.com/LiuHC0428/LAW-GPT
-
简介:中文法律大模型(獬豸)
-
数据:现有的法律问答数据集和基于法条和真实案例指导的self-Instruct构建的高质量法律文本问答数据。
-
训练方法:基于ChatGLM-6B,采用Lora&16bit方法进行模型训练。
lawyer-llama
Github: https://github.com/AndrewZhe/lawyer-llama
-
简介:中文法律LLaMA
-
数据:法考数据7k、法律咨询数据14k
-
训练方法:以Chinese-LLaMA-13B为底座,未经过法律语料continual training,使用通用instruction和法律instruction进行SFT。
金融领域
非中文较好的项目:BloombergGPT、PIXIU等,在此不做介绍。
FinGPT
Github: https://github.com/AI4Finance-Foundation/FinGPT
-
简介:金融大模型
-
数据:来自东方财富
-
训练方法:基于ChatGLM-6B,采用Lora方法训练模型。
FinTuo
Github: https://github.com/qiyuan-chen/FinTuo-Chinese-Finance-LLM
-
简介:一个中文金融大模型项目,旨在提供开箱即用且易于拓展的金融领域大模型工具链。
-
数据:暂未完成。
-
训练方法:暂未完成。
教育领域
EduChat
Github: https://github.com/icalk-nlp/EduChat
-
简介:以预训练大模型为基底的教育对话大模型相关技术,提供教育场景下自动出题、作业批改、情感支持、课程辅导、高考咨询等丰富功能,服务于广大老师、学生和家长群体,助力实现因材施教、公平公正、富有温度的智能教育。
-
数据:混合多个开源中英指令、对话数据,并去重后得到,约400w。
-
训练方法:基于LLaMA模型训练而来。
相关文章:
GPT垂直领域相关模型 现有的开源领域大模型
对于ToC端来说,广大群众的口味已经被ChatGPT给养叼了,市场基本上被ChatGPT吃的干干净净。虽然国内大厂在紧追不舍,但目前绝大多数都还在实行内测机制,大概率是不会广泛开放的(毕竟,各大厂还是主盯ToB、ToG市…...

学习Vue:slot使用
在Vue.js中,组件高级特性之一是插槽(Slots)。插槽允许您在父组件中插入内容到子组件的特定位置,从而实现更灵活的组件复用和布局控制。本文将详细介绍插槽的使用方法和优势。 什么是插槽? 插槽是一种让父组件可以向子…...
【Linux】Shell脚本之流程控制语句 if判断、for循环、while循环、case循环判断 + 实战详解[⭐建议收藏!!⭐]
👨🎓博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支…...
【数据结构】“栈”的模拟实现
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
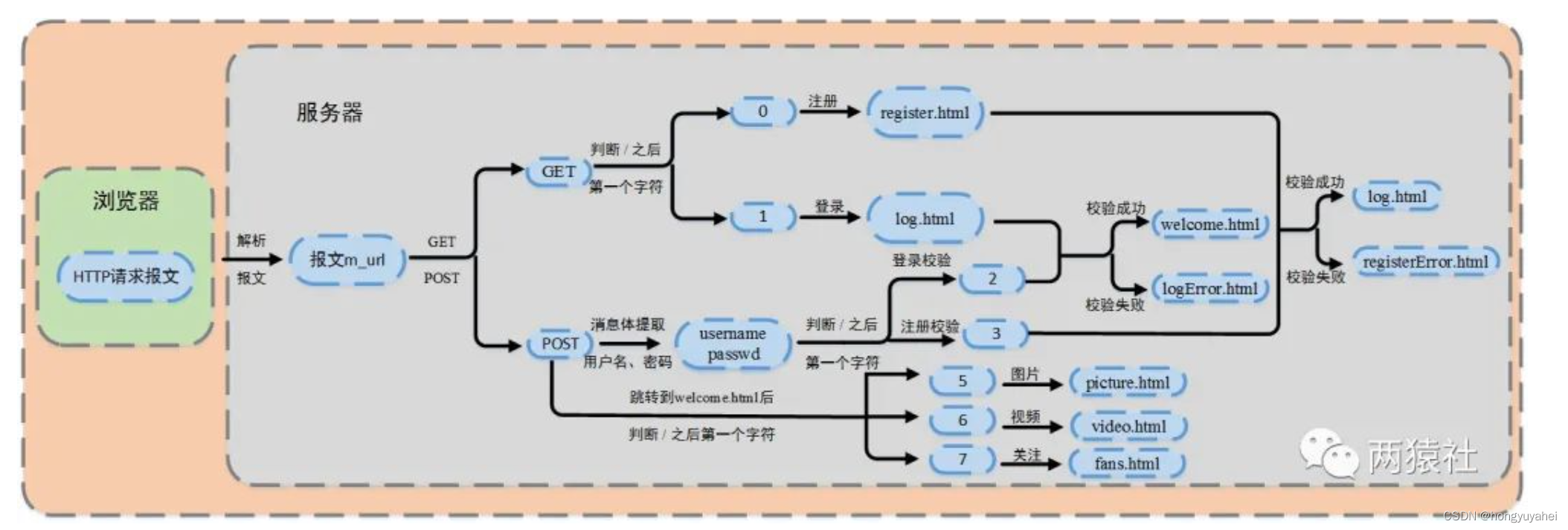
12 注册登录
12 注册登录 整体概述 使用数据库连接池实现服务器访问数据库的功能,使用POST请求完成注册和登录的校验工作。 本文内容 介绍同步实现注册登录功能,具体涉及到流程图、载入数据库表、提取用户名和密码、注册登录流程与页面跳转的代码实现。 流程图&a…...

动态规划之最长上升子序列模板
今天开始更新动态规划的模板(动态规划哪有模板呀!!!)话是这么说,但我们经常做题会发现有些题目有些共性,我们抽取共性总结出来,应付动态规划基础题目还是可以的。 回归正题…...

Python源码05:使用Pyecharts画词云图图
**Pyecharts是一个用于生成 Echarts 图表的 Python 库。Echarts 是一个基于 JavaScript 的数据可视化库,提供了丰富的图表类型和交互功能。**通过 Pyecharts,你可以使用 Python 代码生成各种类型的 Echarts 图表,例如折线图、柱状图、饼图、散…...
)
MariaDB 10.11.4 安装教程(zip格式,Windows环境)
前言 MariaDB 10.11.4 这个版本是目前最新的长期支持版,下面来安装下 下载 官网:MariaDB 10.11.4 打开上面链接,点Download 安装 解压缩下载的 zip 文件,到 bin 目录,管理员运行cmd,执行如下命令 mys…...

【Python国内源】pip换源终极方法【Windows】
1、为什么要pip换源下载 安装第三方库时,很多库来自于国外,下载速度慢得感人! 2、常见的国内源 https://pypi.tuna.tsinghua.edu.cn/simple #清华 http://mirrors.aliyun.com/pypi/simple/ #阿里云 https://pypi.mirrors.ustc.e…...
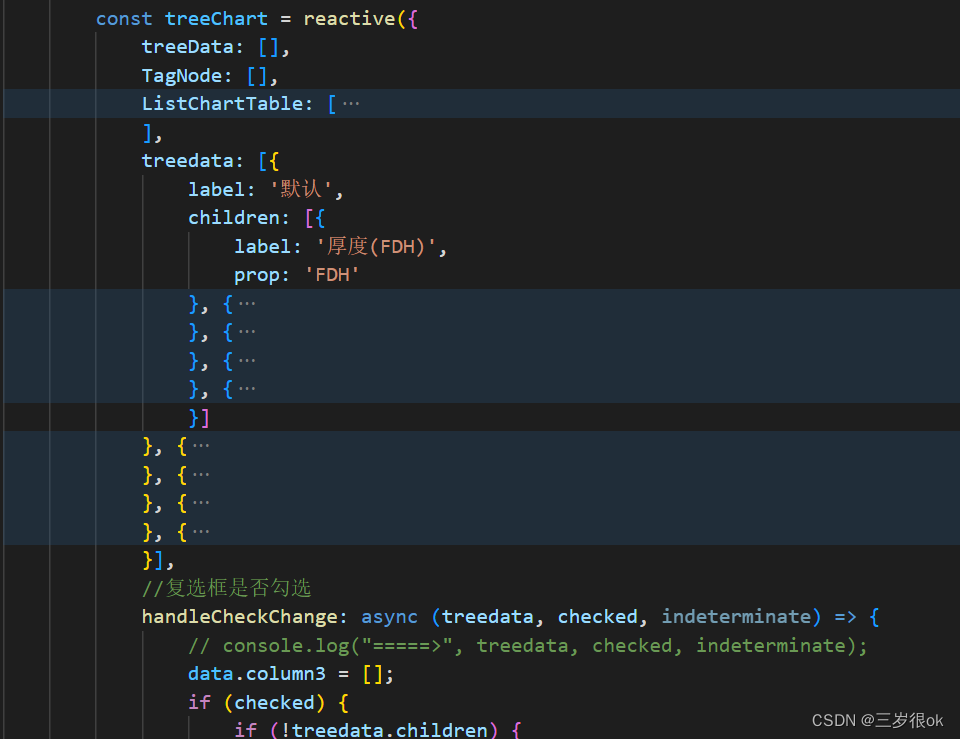
【elementUi】绘制自定义表格、绘制曲线表格
要求绘制下图系列表格: 实现步骤: 1.绘制树,实现树勾选字段—>表格绘制字段 逻辑: 树:check-change“treeChart.handleCheckChange” 绑定点击选择事件,改变data.column3数据项;表格:columns"data…...

使用 Python 中的 Langchain 从零到高级快速进行工程
大型语言模型 (LLM) 的一个重要方面是这些模型用于学习的参数数量。模型拥有的参数越多,它就能更好地理解单词和短语之间的关系。这意味着具有数十亿个参数的模型有能力生成各种创造性的文本格式,并以信息丰富的方式回答开放式和挑战性的问题。 ChatGPT 等法学硕士利用 T...

神经网络基础-神经网络补充概念-07-使用计算图求导
步骤 定义计算节点和操作: “x” 是输入变量。 “Add” 表示加法操作。 “Sub” 表示减法操作。 “Multiply” 表示乘法操作。 计算函数值: 首先,我们将 x0 的值代入计算图中,计算出函数的值。 反向传播计算导数: 我…...

docker常用指令
一、Docker指令 1、启动Docker :systemctl start docker 2、查看Docker状态:systemctl status docker 状态为active表示正在运行中 3、停止运行Docker:systemctl stop docker 4、重启Docker:systemctl restart docker 5、开机启动Docker:systemctl enable docker 二…...

【金融量化】对企业进行估值的方法有哪些?
估值的方法有哪些? 如何对企业进行估值?有2个方法估算。 1 绝对估值法 它是一种定价模型,用于计算企业的内在价值。 比如说你可以根据公司近N年的现金流情况。借此去预测未来N年的现金流情况。所有的现金流数据都可以在年报上查询到。最后…...

Qt+C++自定义控件仪表盘动画仿真
程序示例精选 QtC自定义控件仪表盘动画仿真 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对<<QtC自定义控件仪表盘动画仿真>>编写代码,代码整洁,规则&…...
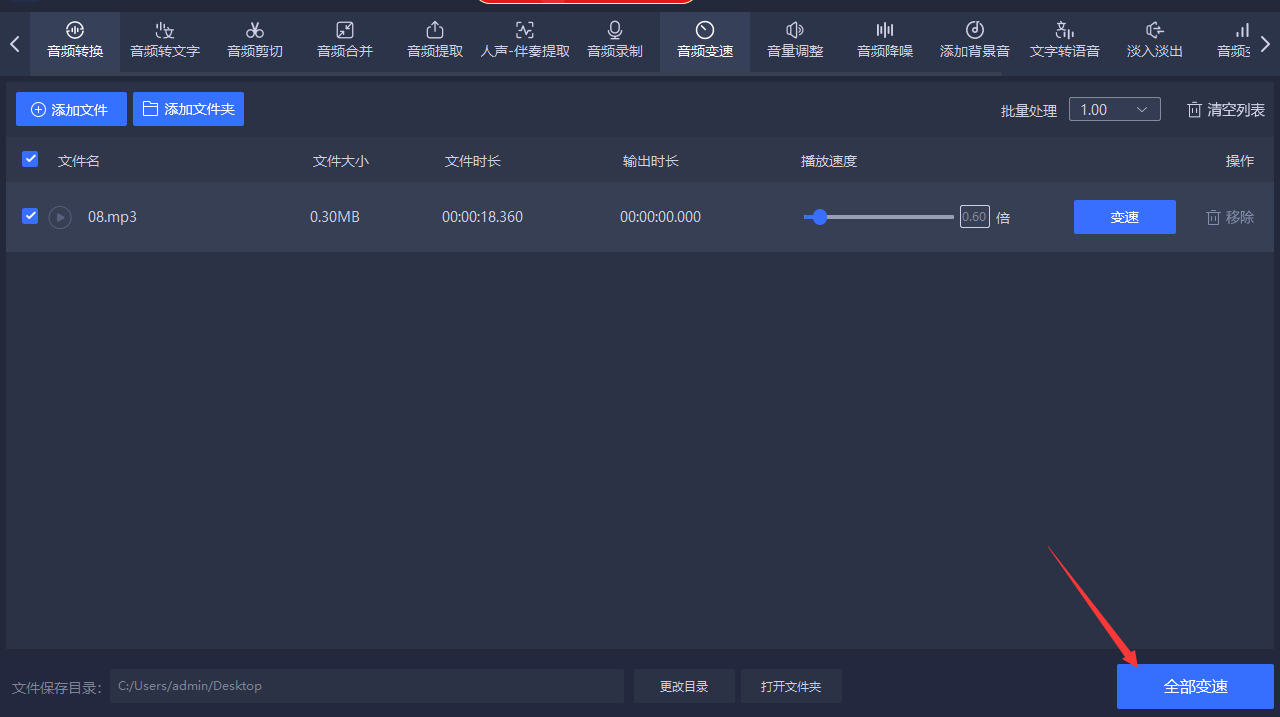
怎样让音频速度变慢?请跟随以下方法进行操作
怎样让音频速度变慢?在会议录音过程中,经常会遇到主讲人语速过快,导致我们无法清晰听到对方说的内容。如果我们能够减慢音频速度,就能更好地记录对方的讲话内容。此外,在听到快速播放的外语或方言时,我们也…...

【C语言】常用的库和作用以及对应的函数
常规编程时: <stdio.h>:提供标准输入输出函数,例如printf、scanf、fprintf、fscanf等。 <stdlib.h>:提供常用的通用函数,例如内存管理函数(malloc、calloc、realloc、free)、随机数…...

Android 12.0 系统systemui下拉通知栏的通知布局相关源码分析
1.前言 在android12.0的系统rom开发中,在进行systemui中的下拉通知栏的布局自定义的时候,对于原生systemui的 系统的下拉通知栏的通知布局的了解也是非常重要的,接下来就来分析下相关的下拉通知栏的通知布局的相关 源码流程,了解这些才方便对通知栏的布局做修改 2.系统sy…...
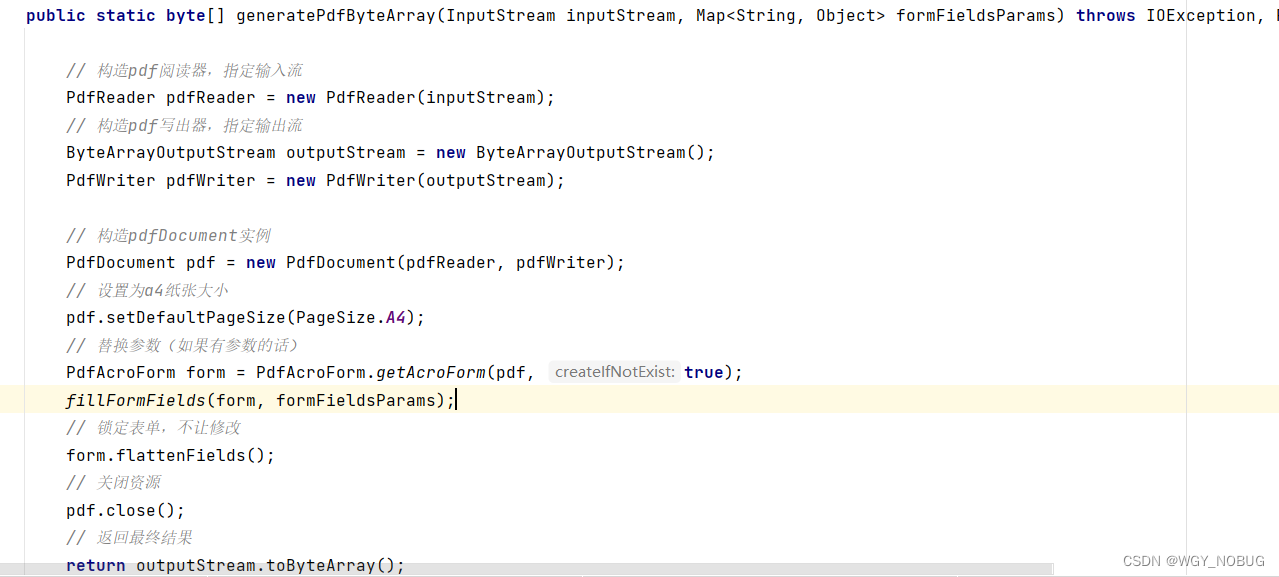
java实现docx,pdf文件动态填充数据
一,引入pom 根据需求引入自己所需pom org.apache.poi poi 4.1.1 org.apache.poi poi-ooxml 4.1.1 org.jxls jxls 2.6.0 ch.qos.logback logback-core org.jxls jxls-poi 1.2.0 fr.opensagres.xdocreport fr.opensagres.xdocreport.core 2.0.2 fr.opensagres.xdocrep…...

【Python2】实现异步进程的创建、终止与资源回收
章节索引 前言〇、问题与难点一、进程、异步进程、线程 / 进程池二、最终的代码构成三、代码逻辑讲解四、扩展的知识后记 前言 由于业务需求,需要在服务中加入一个异步任务,执行大量的耗时计算操作,需求细节如下: Handler处理器…...

论文写到头秃?书匠策AI这套“毕业论文急救包“我劝你现在就存好!
同学们,我做论文写作科普这么久,后台私信最多的一句话就是:"老师,我论文一个字都没动,还有救吗?" 有。今天就给你们安利一个我最近实测了一圈、觉得确实有点东西的工具——书匠策AI(…...

在数据分析和报告自动化场景中集成Taotoken调用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据分析和报告自动化场景中集成Taotoken调用大模型 数据分析与报告生成是许多团队日常工作中的高频任务。传统流程中࿰…...

OBS-VST插件完整指南:5分钟让直播音频秒变专业的终极方案
OBS-VST插件完整指南:5分钟让直播音频秒变专业的终极方案 【免费下载链接】obs-vst Use VST plugins in OBS 项目地址: https://gitcode.com/gh_mirrors/ob/obs-vst 想在OBS Studio中免费获得专业级音频处理效果吗?OBS-VST插件正是你需要的解决方…...

Pipeline五大核心要素拆解:从输入到输出的自动化流程设计
1. 项目概述:为什么我们需要拆解Pipeline的基本要素?在任何一个涉及流程化、自动化处理的领域,无论是软件开发中的CI/CD(持续集成/持续部署),还是数据科学中的数据预处理与分析,甚至是制造业中的…...

ceph的块存储如何骗过服务器,让服务器把它当做真实的硬盘
ceph的块存储,就是一块远程网络硬盘。操作系统为啥会读写这块假硬盘呢? 一台服务器要使用CEPH提供的块存储,也是需要ceph的驱动软件来和ceph通讯吧 是的,你的理解完全正确。一台服务器想要使用 Ceph 提供的块存储,必须…...

由一次构建 OpenEuler 22.03 dnf源所了解到的
零、说在前面今天在安装 Milvus 的时候,因为部分插件下载过慢,需要重建国内 yum/dnf 源,按照常规的方式重建后报出了一些奇怪的报错。通过这些报错让我了解到了 OpenEuler 22.03 的不同版本在构建 yum/dnf 源的时候是存在区别的。因此将我的处…...

Lemur性能优化:10个提升证书管理平台响应速度的技巧
Lemur性能优化:10个提升证书管理平台响应速度的技巧 【免费下载链接】lemur Repository for the Lemur Certificate Manager 项目地址: https://gitcode.com/gh_mirrors/le/lemur Lemur作为一款开源证书管理平台,能够帮助用户轻松管理SSL/TLS证书…...

FLUX.1-dev FP8量化模型:让中低端显卡畅享专业级AI图像生成的终极方案
FLUX.1-dev FP8量化模型:让中低端显卡畅享专业级AI图像生成的终极方案 【免费下载链接】flux1-dev 项目地址: https://ai.gitcode.com/hf_mirrors/Comfy-Org/flux1-dev 在AI图像生成技术快速发展的今天,硬件限制成为许多开发者和创作者面临的主要…...

简单掌握C++中的函数模板
1.函数模板的声明和模板函数的生成 1.1函数模板的声明 函数模板可以用来创建一个通用的函数,以支持多种不同的形参,避免重载函数的函数体重复设计。它的最大特点是把函数使用的数据类型作为参数。 函数模板的声明形式为: template<typenam…...

手写NumPy版RBM:从能量函数到吉布斯采样的可调试实现
1. 项目概述:这不是又一个“RBM扫盲帖”,而是一次亲手拆解神经网络祖师爷级模型的实操复盘Restricted Boltzmann Machine(受限玻尔兹曼机),简称RBM,不是教科书里那个被反复引用却没人真去跑通的抽象符号&am…...