聊聊在集群环境中本地缓存如何进行同步
前言
之前有发过一篇文章聊聊如何利用redis实现多级缓存同步。有个读者就给我留言说,因为他项目的redis版本不是6.0+版本,因此他使用我文章介绍通过MQ来实现本地缓存同步,他的同步流程大概如下图
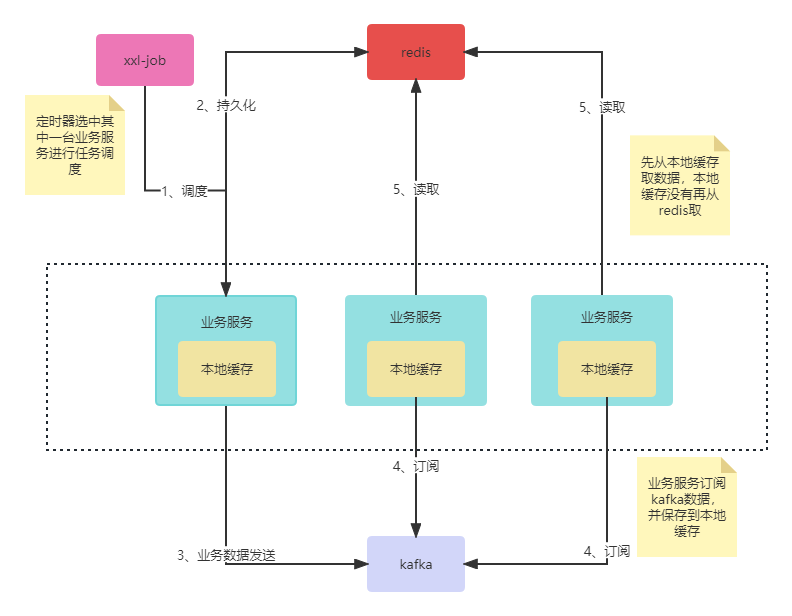
他原来的业务流程是每天凌晨开启定时器去爬取第三方的数据,并持久化到redis,后边因为redis发生过宕机事故,他碰巧看了我文章,就觉得可以用使用多级缓存的策略,用来做个兜底。他的业务流程就如上图,即每天凌晨开启定时器去爬取第三方数据,持久化到redis和其中一台服务的本地缓存,然后将爬取到的业务数据发送到kafka,其他业务服务通过订阅kafka,将业务数据保存到本地缓存。
他改造完,某天突然发现在集群环境中,只要其中一台服务消费了kafka数据,其他就消费不到。今天就借这个话题,来聊聊集群环境中本地缓存如何进行同步
前置知识
kafka消费topic-partitions模式分为subscribe模式和assign模式。subscribe模式需要指定group.id,该模式会为consumer自动分配partition,且同一个group.id下的不同consumer不会消费同样的分区。assign模式需要为consumer手动、显示的指定需要消费的topic-partitions,不受group.id限制,相当与指定的group.id无效。通俗一点讲就是assign模式下,所有消费者都可以订阅指定分区
我们要通过消息队列实现本地缓存同步,本质上就是需要利用消息队列提供广播能力,而kafka默认不具备。不过我们可以根据kafka提供的消费模式进行定制,从而是kafka也具备广播能力
集群本地缓存同步方案
方案一:利用MQ广播能力
因为读者项目是使用kafka,且项目是使用spring-kafka,我们也就以此为例
1、subscribe模式
通过前置知识,我们了解到在subscribe模式下,同一个group.id下的不同consumer不会消费同样的分区,这就意味我们可以通过指定不同group.id来消费同样分区达到广播的效果
那如何在同个集群服务实现不同的group.id?
此时Spring EL 表达式就派上用场了,我们通过 Spring EL 表达式,在每个消费者分组的名字上配合 UUID 生成其后缀。这样,就能保证每个项目启动的消费者分组不同,从而达到广播消费的目的
示例
@KafkaListener(topics = "${userCache.topic}",groupId = "${userCache.topic}_group_" + "#{T(java.util.UUID).randomUUID()})")public void receive(Acknowledgment ack, String data){System.out.println(String.format("serverPort:【%s】,接收到数据:【%s】",serverPort,data));ack.acknowledge();}
如果我们决定UUID不直观,我们也可以使用IP作为标识,只要能保证同个集群服务的group.id是唯一即可
不过如果要改成ip,我们得做一定的改造。改造步骤如下
a、 获取ip地址信息,并放入environment
public class ServerAddrEnvironmentPostProcessor implements EnvironmentPostProcessor{private String SERVER_ADDRESS = "server.addr";@Override@SneakyThrowspublic void postProcessEnvironment(ConfigurableEnvironment environment, SpringApplication application) {MutablePropertySources propertySources = environment.getPropertySources();Map<String, Object> source = new HashMap<>();String serverAddr = InetAddress.getLocalHost().getHostAddress();source.put(SERVER_ADDRESS,serverAddr);MapPropertySource mapPropertySource = new MapPropertySource("serverAddrProperties",source);propertySources.addFirst(mapPropertySource);}}b、 配置spi
在src/main/resource目录下配置META-INF/spring.factories,配置内容如下
org.springframework.boot.env.EnvironmentPostProcessor=\
com.github.lybgeek.comsumer.ip.ServerAddrEnvironmentPostProcessor
c、 @KafkaListener配置如下内容
@KafkaListener(topics = "${userCache.topic}",groupId = "${userCache.topic}_group_" + "${server.addr}" + "_${server.port}")
小结
该方式的实现优点是比较简单,但如果需要对服务进行运维监控统计,那就不怎么友好了,虽然指定IP会比随机UUID好点,但如果是容器化部署,每次部署其IP也是会变化,这样跟随机指定UUID,差别也不大了。其次如果是使用云产品,比如阿里云对comsume group是有数量上限,且消费者组需要提前创建,这种情况使用该方案就不是很合适了
assign模式
通过assign模式手动消费对应的分区
示例
@KafkaListener(topicPartitions ={@TopicPartition(topic = "${userCache.topic}", partitions = "0")})public void receive(Acknowledgment ack, ConsumerRecord record){System.out.println(String.format("serverPort:【%s】,接收到数据:【%s】",serverPort,record));ack.acknowledge();}小结
该方式实现也是很简单,如果我们不需要动态创建新的分区,用该方案实现广播,会是一个不错的选择。不过该方式的缺点很明显,因为是手动指定分区,当该分区有问题,也挺麻烦的
方案二:通过定时器触发
该方案主要基于读者目前的同步进行改造,改造后如下图
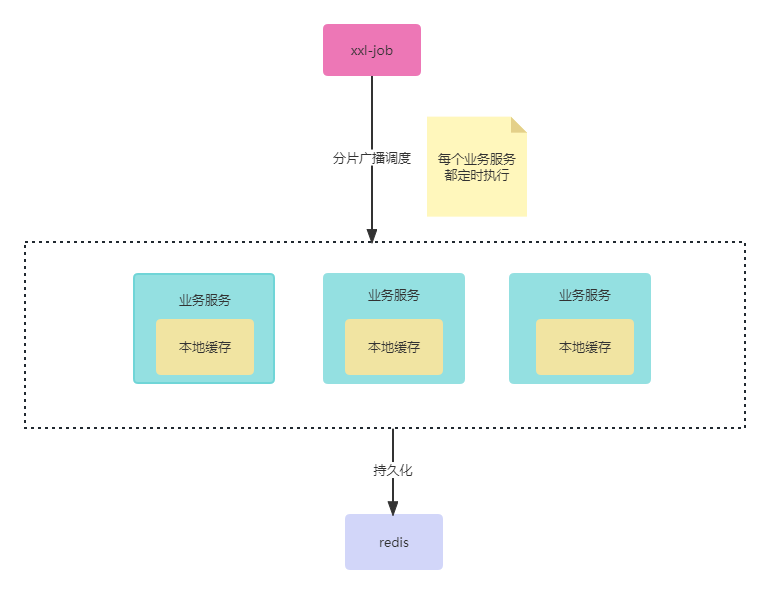
核心就是根据读者业务的特性,因为他是定时每天晚上同步爬取,那就意味着他这个数据至少在当天基本不变,就可以让集群里的服务都定时执行,此时仅需将xxl-job的调度策略改成分片广播就行,这样就可以持久化到redis的同时,也持久化到本地缓存
小结
该方案改动量比较小,有个小缺点就是,因为集群内所有服务都执行调度,这样就会使redis重复持久化,不过问题也不大就是好。最后读者选择该方案
总结
本文主要阐述集群环境中本地缓存如何进行同步,之前还有读者问我说,使用了多级缓存,数据一致性要如何保证?以前我可能会从技术角度来回答,比如你可以延迟双删,或者如果你是mysql,你可以使用canal+mq,更甚者你可以使用分布式锁来保证。但现在我更多从业务角度来思考这件事情,你都考虑使用缓存,是不是意味着你在业务上是可以容忍一定不一致性,既然可以容忍,是不是最终可以通过一些补偿方案来解决这个不一致性
没有完美的方案,你此时感觉的完美方案,可能是当时在那个业务场景下,做了一个贴合业务的权衡
demo链接
https://github.com/lyb-geek/springboot-learning/tree/master/springboot-kafka-broadcast
相关文章:
聊聊在集群环境中本地缓存如何进行同步
前言 之前有发过一篇文章聊聊如何利用redis实现多级缓存同步。有个读者就给我留言说,因为他项目的redis版本不是6.0版本,因此他使用我文章介绍通过MQ来实现本地缓存同步,他的同步流程大概如下图 他原来的业务流程是每天凌晨开启定时器去爬取…...
【C++深入浅出】初识C++上篇(关键字,命名空间,输入输出,缺省参数,函数重载)
目录 一. 前言 二. 什么是C 三. C关键字初探 四. 命名空间 4.1 为什么要引入命名空间 4.2 命名空间的定义 4.3 命名空间使用 五. C的输入输出 六. 缺省参数 6.1 缺省参数的概念 6.2 缺省参数的分类 七. 函数重载 7.1 函数重载的概念 7.2 函数重载的条件 7.3 C支…...

租房合同范本
房屋租赁合同 甲方(出租方): 身份证: 联系电话: 乙方(承租方): 身份证: 联系电话: …...

轻薄的ESL电子标签有哪些特性?
在智慧物联逐渐走进千万家的当下,技术变革更加日新月异。ESL电子标签作为科技物联的重要组成部分,是推动千行百业数字化转型的重要技术,促进物联网产业的蓬勃发展。在智慧零售、智慧办公、智慧仓储等领域,ESL电子标签在未来是不可…...

AI 实力:利用 Docker 简化机器学习应用程序的部署和可扩展性
利用 Docker 的强大功能:简化部署解决方案、确保可扩展性并简化机器学习模型的 CI/CD 流程。 近年来,机器学习 (ML) 出现了爆炸性增长,导致对健壮、可扩展且高效的部署方法的需求不断增加。由于训练和服务环境之间的差异或扩展的困难等因素&a…...
商用汽车转向系统常见故障解析
摘要: 车辆转向系统是用于改变或保持汽车行驶方向的专门机构。其作用是使汽车在行驶过程中能按照驾驶员的操纵意图而适时地改变其行驶方向,并在受到路面传来的偶然冲击及车辆意外地偏离行驶方向时,能与行驶系统配合共同保持车辆继续稳定行驶…...

Python中的MetaPathFinder
MetaPathFinder 是 Python 导入系统中的一个关键组件,它与 sys.meta_path 列表紧密相关。sys.meta_path 是一个包含 MetaPathFinder 实例的列表,这些实例用于自定义模块的查找和加载逻辑。当使用 import 语句尝试导入一个模块时,Python 会遍历…...

工控机防病毒
2月3日,作为全球最大的半导体制造设备和服务供应商,美国应用材料公司(Applied Materials)表示,有一家上游供应商遭到勒索软件攻击,由此产生的关联影响预计将给下季度造成2.5亿美元(约合人民币17…...
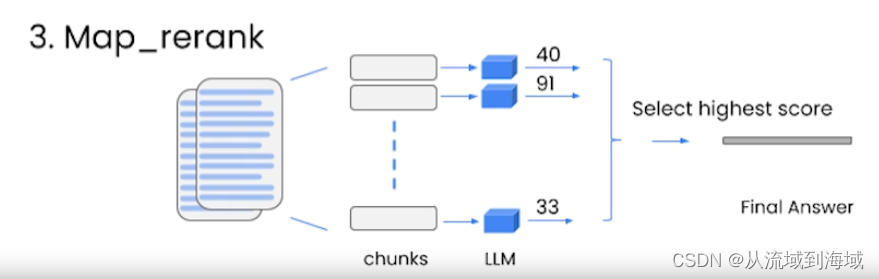
LangChain手记 Question Answer 问答系统
整理并翻译自DeepLearning.AILangChain的官方课程:Question Answer(源代码可见) 本节介绍使用LangChian构建文档上的问答系统,可以实现给定一个PDF文档,询问关于文档上出现过的某个信息点,LLM可以给出关于该…...

如何优化css中的一些昂贵属性
如何优化css中的一些昂贵属性 就性能而言,某些 CSS 属性比其他属性的成本更高。如果使用不当,它们可能会减慢我们的网页速度并降低对用户的响应速度。在本文中,我们将探讨一些成本最高的 CSS 属性以及如何优化它们。 box-shadow box-shado…...
基于安防监控EasyCVR视频汇聚融合技术的运输管理系统的分析
一、项目背景 近年来,随着物流行业迅速发展,物流运输费用高、运输过程不透明、货损货差率高、供应链协同能力差等问题不断涌现,严重影响了物流作业效率,市场对于运输管理数字化需求愈发迫切。当前运输行业存在的难题如下…...
)
在WordPress站点中展示阅读量等流量分析数据(超详细实现)
这篇文章也可以在我的博客中查看 关于本文 专业的流量统计系统能够相对真实地反应网站的访问情况。 这些数据可以在后台很好地进行分析统计,但有时我们希望在网站前端展示一些数据 最常见的情景就是:展示页面的浏览量 这简单的操作当然也可以通过简单…...
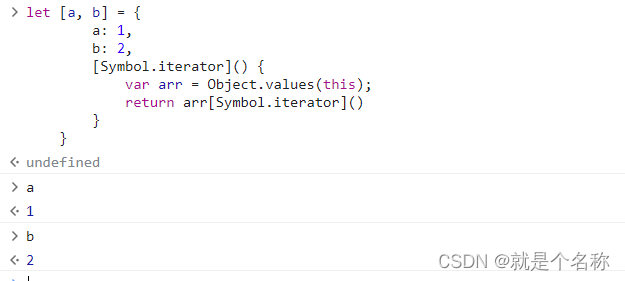
学习 Iterator 迭代器
今天看到一个面试题, 让下面解构赋值成立。 let [a,b] {a:1,b:2} 如果我们直接在浏览器输出这行代码,会直接报错,说是 {a:1,b:2} 不能迭代。 看了es6文档后,具有迭代器的就一下几种类型,没有Object类型,…...

JVM---垃圾回收算法介绍
目录 分代收集理论 三种垃圾回收算法 标记-清除算法(最基础的、基本不用) 标记-复制算法 标记-整理算法 正式因为jvm有了垃圾回收机制,作为java开发者不会去特备关注内存,不像C和C。 优点:开发门槛低、安全 缺点…...
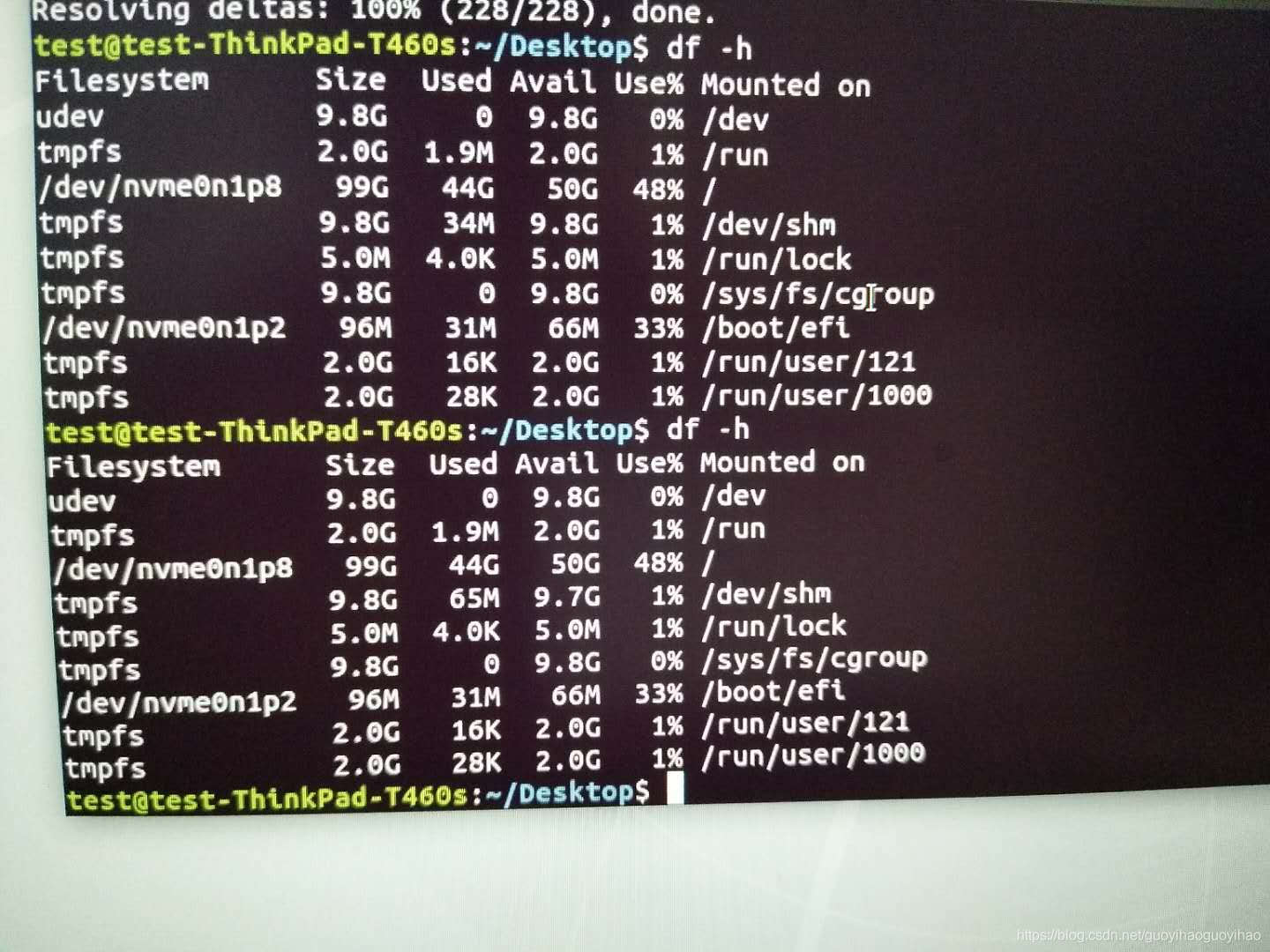
Ubuntu一直卡死的问题(20.04)
Ubuntu一直卡死的问题(18.04)_ubuntu频繁死机_Mr.Yi的博客-CSDN博客 我自己的解决方法: 1、首先强制关机重启后,直接打开命令行查看磁盘的使用: df -h发现/dev/loop都沾满了,我们能需要做的就是把他们清理干净 sud…...

自动化测试用例设计实例
在编写用例之间,笔者再次强调几点编写自动化测试用例的原则: 1、一个脚本是一个完整的场景,从用户登陆操作到用户退出系统关闭浏览器。 2、一个脚本脚本只验证一个功能点,不要试图用户登陆系统后把所有的功能都进行验证再退出系统…...
CSS3基础
CSS3在CSS2的基础上增加了很多功能,如圆角、多背景、透明度、阴影等,以帮助开发人员解决一些实际问题。 1、初次使用CSS 与HTML5一样,CSS3也是一种标识语言,可以使用任意文本编辑器编写代码。下面简单介绍CSS3的基本用法。 1.1…...

【栈】 735. 行星碰撞
735. 行星碰撞 解题思路 如果数组元素大于0 说明向右移动 那么不管 左边元素是不是大于0 都不会碰撞 如果数组元素小于0 说明想左边移动 那么判断左边元素 如果左边元素大于0 碰撞 那么遍历数组 当前元素大于0 直接入栈 如果当前元素小于0 判断栈顶元素是不是大于0 如果大…...
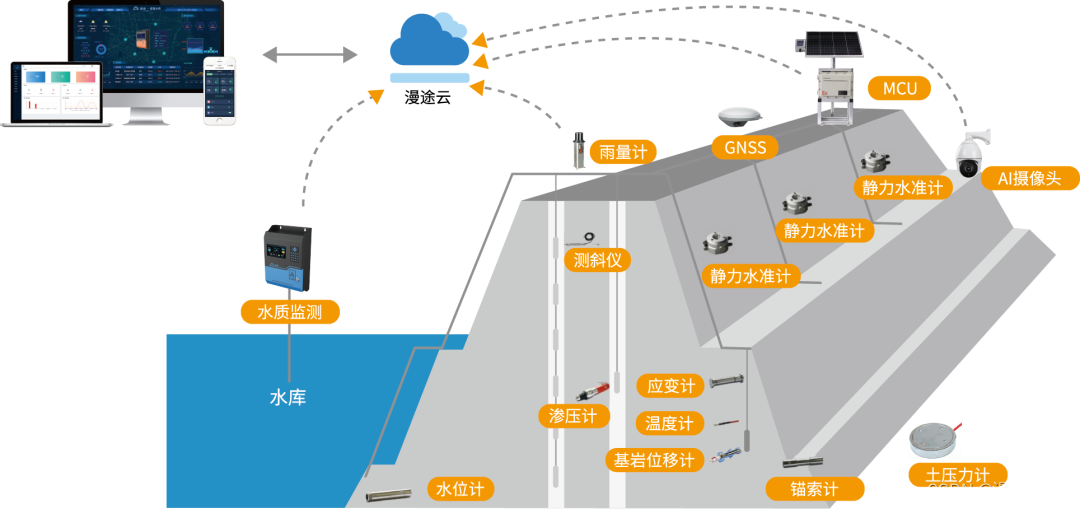
水库大坝安全监测MCU,提升大坝管理效率的利器!
水库大坝作为防洪度汛的重要设施,承担着防洪抗旱,节流发电的重要作用。大坝的安全直接关系到水库的安全和人民群众的生命财产安全。但因为水库大坝的隐患不易被察觉,发现时往往为时已晚。因此,必须加强对大坝的安全管理。其安全监…...

【vue2类型助手】vue2-cli 实现为 vue2 项目中的组件添加全局类型提示
实现 vue2 全局组件提示 vue2 项目全局注册组件直接使用没有提示 由于vue2中使用volar存在很大的性能问题,所以只能继续使用vetur,但是这样全局组件会没有提示,这对于开发来说,体验十分不友好,所以开发此cli并借助ve…...

RK3562核心板深度解析:10路UART与1TOPS NPU在工业边缘计算的应用
1. 项目概述:为什么RK3562核心板值得关注?最近在给一个工业网关项目做硬件选型,市面上各种核心板看得人眼花缭乱。从传统的ARM Cortex-A系列到各种专用SoC,性能和接口的平衡点一直很难找。直到接触到迅为电子这款基于瑞芯微RK3562…...

记录人生第一个Linux内核Patch被采纳的经历
最近运气不错,提交的一个关于 Linux 内核 SMMUv3 驱动的补丁(Patch)被采纳了。虽然只是一个边界条件的微调,但作为自己的第一个 Patch,过程还挺有意思的,中间也暴露出自己不少技术盲区。趁着记忆热乎&#…...

微信聊天记录丢了怎么找回?这份教程很实用
你是否经历过这样的崩溃瞬间:手机清理空间时不小心删了微信聊天记录,或者重装微信后发现重要的对话全部消失?别慌,本文将系统梳理微信聊天记录丢失的常见原因,并提供多种经过验证的恢复方案,从微信官方自带…...

Halcon形状匹配实战:从`get_domain`到`add_channels`,手把手教你处理复杂背景下的目标定位
Halcon形状匹配实战:从get_domain到add_channels的工业级解决方案 在工业视觉检测中,目标定位的准确性直接影响着整个生产线的质量把控效率。当面对低对比度、复杂背景或干扰物密集的场景时,传统全图搜索策略往往表现不佳——这正是Halcon区域…...

CANN/asc-devkit同步通知API文档
asc_sync_notify 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcod…...

Prompt 缓存,一次讲明白
每当一个 AI Agent 往前走一步,它其实都在交一笔税。它会重新读取所有内容。系统提示词。 工具定义。 项目上下文。 三轮前已经加载过的内容。每一轮都重新读一遍。这就是 context tax。对长时间运行的 Agent 工作流来说,它往往是整个 AI 基础设施里最贵…...

JMeter断言实战:从误配到分层校验的避坑指南
1. 为什么断言不是“加个检查框”就完事了?很多人第一次在 JMeter 里点开“添加 → 断言 → 响应断言”,填上“包含文本:success”,跑完看绿色小勾就以为接口测试闭环了。我带过三届测试团队,新同事交来的脚本里&#…...

LeetCode 15:三数之和 | 双指针法详解与进阶应用
LeetCode 15:三数之和 | 双指针法详解与进阶应用 引言 三数之和(3Sum)是 LeetCode 中一道经典的高频面试题,编号为 15,属于 Medium 难度范畴。这道题的核心要求是在一个整数数组中找出所有不重复的三元组,使…...

什么是虚拟化
什么是虚拟化? 什么是虚拟化 虚拟化长期以来一直是一项基础 IT 技术,使企业能够在一台物理机器上运行多个独立的系统。 虚拟化是一种允许从单个物理机创建多个虚拟环境的技术。这些虚拟环境基本上是以前与硬件绑定的功能的逻辑(虚拟ÿ…...
超精密反射镜技术壁垒)
0602光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)超精密反射镜技术壁垒
第2小节:超精密反射镜技术壁垒(基底加工镀膜检测,全量化死磕)前置硬核声明EUV整机90%的成像误差、波像差、良率波动,最终全部归因于超精密反射镜的制造壁垒。EUV不是“普通光学抛光”,是原子级表面重构、皮…...