变形金刚:从零开始【01/2】

一、说明
在我们的日常生活中,无论你是否是数据科学家,你都在单向地使用变压器模型。例如。如果您使用的是 ChatGPT 或 GPT-4 或任何 GPT,那么在为您回答问题的框中是变压器的一部分。如果您是数据科学家或数据分析师,则可能正在使用转换器执行文本分类、令牌分类、问答、Text2text 或任何与此相关的任务,您正在使用转换器模型。我们确实为我们的面试学习理论,每个人都这样做,但你有没有想过如何从头开始创建一个变压器模型。
先从变压器开始,我们先来看看整个架构:
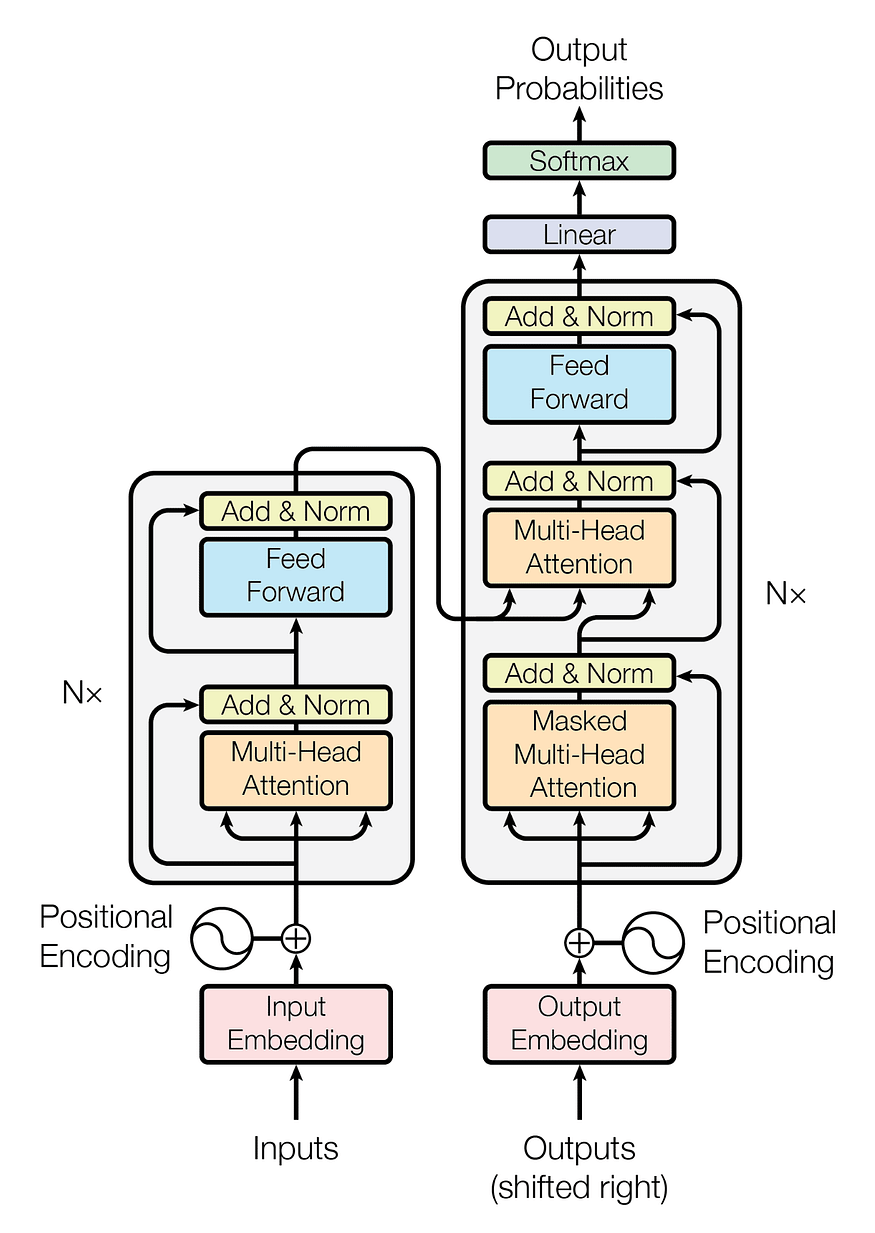
图1.变压器模型体系结构
已经挠头了?让我们分解一下,以便我们可以更好地理解。
- 我们可以并排两个盒子(Nx),它们是左侧的编码器和右侧的解码器。
二、从编码器开始
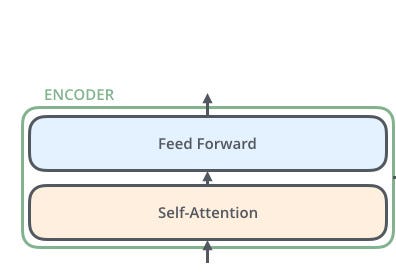
编码器内有两个块。我们只需要用python编写自我注意和前馈块。
为了更好地理解它,让我们使用一个分词器。因此,我们可以通过一个例子来理解该模型。
from transformers import AutoTokenizer
tokenizer = Autotokenizer.from_pretrained('bert-base-uncased')
text = 'I love data science.'
print(tokenizer(text, add_special_tokens=False, return_tensors='pt'))
inputs = tokenizer(text, add_special_tokens=False, return_tensors='pt')# The above code will produce the following output
# {'input_ids': tensor([[1045, 2293, 2951, 2671, 1012]]),
# 'token_type_ids': tensor([[0, 0, 0, 0, 0]]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1]])}现在,在上面的单元格中,我们可以看到分词器已将句子“我爱数据科学”标记为标记 (input_ids)。现在请注意,我没有使用任何特殊令牌,如 [CLS] 或 [SEP]。
三、配置Bert
标记化我们的文本后,让我们尝试获取“bert-base-model”的配置,以便我们可以尝试制作可以像 BERT 模型一样产生结果的模型。听起来很有趣?赤穗让我们深入了解BERT的配置。
from transformers import AutoConfig
config = AutoConfig.from_pretrained('bert-base-uncased')
print(config)# The above cell should output as:
BertConfig {"_name_or_path": "bert-base-uncased","architectures": ["BertForMaskedLM"],"attention_probs_dropout_prob": 0.1,"classifier_dropout": null,"gradient_checkpointing": false,"hidden_act": "gelu","hidden_dropout_prob": 0.1,"hidden_size": 768,"initializer_range": 0.02,"intermediate_size": 3072,"layer_norm_eps": 1e-12,"max_position_embeddings": 512,"model_type": "bert","num_attention_heads": 12,"num_hidden_layers": 12,"pad_token_id": 0,"position_embedding_type": "absolute","transformers_version": "4.29.2","type_vocab_size": 2,"use_cache": true,"vocab_size": 30522
}如我们所见,BERT模型具有上述配置。
四、嵌入层
接下来,我们需要创建一些密集嵌入。在此上下文中,密集意味着嵌入中的每个条目都包含一个非零值。相比之下,独热编码是稀疏的,因为除了一个之外的所有条目都是零。在 PyTorch 中,我们可以通过使用一个层来做到这一点,该层充当每个输入 ID 的查找表:torch.nn.Embedding
from torch import nn
token_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
print(token_embeddings)
# output:
# Embedding(30522, 768)现在我们有了查找表,我们可以通过输入 ID 来生成嵌入:
inputs_embeds = token_embeddings(inputs.input_ids)
print(inputs_embeds.size())
# output:
# torch.Size([1, 5, 768]) 这给了我们一个 形状张量 .现在让我们计算注意力分数[batch_size, seq_len, hidden_dim]
要计算注意力权重,有四个步骤:
- 将嵌入的每个令牌投影到三个向量中,分别称为查询、键和值。
- 计算注意力分数。我们使用相似性函数确定查询和键向量之间的关联程度。顾名思义,缩放点积注意力的相似性函数是点积,使用嵌入的矩阵乘法高效计算。相似的查询和键将具有较大的点积,而那些没有太多共同点的查询和键将几乎没有重叠。此步骤的输出称为注意力分数,对于具有 n 个输入标记的序列,有一个相应的 n x n 个注意力分数矩阵。
- 计算注意力权重。点积通常可以产生任意大的数字,这可能会破坏训练过程的稳定性。为了解决这个问题,首先将注意力分数乘以比例因子以规范化其方差,然后使用 softmax 进行归一化,以确保所有列值的总和为 1。生成的 n × n 矩阵现在包含所有注意力权重。
- 更新令牌嵌入。一旦计算出注意力权重,我们将它们乘以值向量以获得嵌入的更新表示。
import torch
import torch.nn.functional as F
from math import sqrtquery = key = value = inputs_embedsdef scaled_dot_product_attention(query, key, value):dim_k = query.size(-1)scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k) # torch.bmm is batch matrix - matrix multiplication. # Basically a dot product.weights = F.softmax(scores, dim=-1)return torch.bmm(weights, value)这就是我们计算自我注意力的方式。看起来很简单吧?到目前为止还好吗?赤穗现在让我们计算多头注意力。
好吧,你可能会想,如果我们有一个关注,那么我们为什么不停在那里呢?为什么要使用多头注意力?好吧,原因是一个头的softmax倾向于主要关注相似性的一个方面。拥有多个头部允许模型同时关注多个方面。例如,一个头可以专注于主谓互动,而另一个头可以找到附近的形容词。显然,我们不会将这些关系手工制作到模型中,它们是从数据中完全学习的。如果您熟悉计算机视觉模型,您可能会看到它与卷积神经网络中的过滤器相似,其中一个过滤器可以负责检测人脸,另一个过滤器可以在图像中发现汽车车轮。
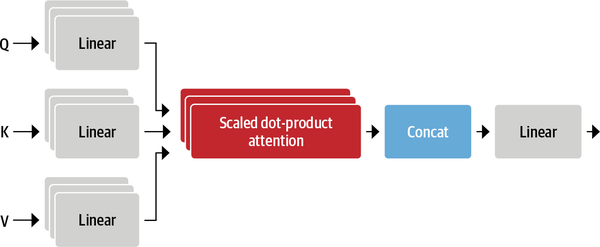
图 3 清楚地说明了我们将如何为多头注意力层编写代码。让我们从那开始:
class AttentionHead(nn.Module):def __init__(self, embed_dim, head_dim):super().__init__()self.q = nn.Linear(embed_dim, head_dim)self.k = nn.Linear(embed_dim, head_dim)self.v = nn.Linear(embed_dim, head_dim)def forward(self, hidden_state):attn_outputs = scaled_dot_product_attention(self.q(hidden_state), self.k(hidden_state), self.v(hidden_state))return attn_outputs 在这里,我们已经初始化了三个独立的线性层,它们将矩阵乘法应用于嵌入向量以产生形状的张量,其中是我们投影到的维度数。虽然不必小于令牌的嵌入维度数 (),但在实践中,它被选择为的倍数,以便每个头的计算是恒定的。例如,BERT 有 12 个注意力头,因此每个头的尺寸为 768/12 = 64[batch_size, seq_len, head_dim]head_dimhead_dimembed_dimembed_dim
五、多头注意力
这就是我们如何创建一个单一的头部注意力层。现在让我们制作多头注意力层:
class MultiHeadAttention(nn.Module):def __init__(self, config):super().__init__()embed_dim = config.hidden_sizenum_heads = config.num_attention_headshead_dim = embed_dim // num_headsself.heads = nn.ModuleList([AttentionHead(embed_dim, head_dim) for _ in range(num_heads)])self.output_linear = nn.Linear(embed_dim, embed_dim)def forward(self, hidden_state):x = torch.cat([h(hidden_state) for h in self.heads], dim=-1)x = self.output_linear(x)return x让我们检查一下到目前为止的代码。
multihead_attn = MultiHeadAttention(config)
attn_output = multihead_attn(inputs_embeds)
print(attn_output.size())
# output
# torch.Size([1, 5, 768])如果我们得到类似的输出,那就干得好!
长话短说,这个模块接受一个输入张量(hidden_state),独立地应用多个“注意力头”,连接它们的输出并将它们传递到最终的线性层中。每个“注意力头”都学会“注意”数据中的不同部分/特征。理解?如果是,那么就是这样。您已经创建了自己的多头注意力图层,全部由您自己创建。太棒了!
六、前馈层
现在,让我们制作编码器的下一个块,即前馈层。编码器和解码器中的前馈子层只是一个简单的两层全连接神经网络,但有一个转折点:它不是将整个嵌入序列作为单个向量处理,而是独立处理每个嵌入。因此,该层通常称为按位置的前馈层。
class FeedForward(nn.Module):def __init__(self, config):super().__init__()self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)self.gelu = nn.GELU()self.dropout = nn.Dropout(config.hidden_dropout_prob)def forward(self, x):x = self.linear_1(x)x = self.gelu(x)x = self.linear_2(x)x = self.dropout(x)return x 注意,前馈层通常应用于形状张量,它独立作用于批量维度的每个元素。这实际上适用于除最后一个维度以外的任何维度,因此当我们传递形状张量时,该层将独立地应用于批处理和序列的所有标记嵌入,这正是我们想要的。nn.Linear(batch_size, input_dim)(batch_size, seq_len, hidden_dim)
七、输出正确性检查
让我们检查一下我们编写的代码是否产生了正确的输出。
feed_forward = FeedForward(config)
ff_outputs = feed_forward(attn_output)
print(ff_outputs.size())
# output
# torch.Size([1, 5, 768])如果您获得相同的输出,那么您走在正确的道路上。
它将变得太大而无法阅读。所以我把它分成两部分。如果您觉得这很有趣,请在评论中或关注我时告诉我。我将很快发布第二部分。
八、后记
注意:在第二部分中,我们将研究层规范化的实现,位置嵌入以及如何向模型添加最后一层以使模型执行不同的任务,如文本分类,标记分类等。然后我们将研究解码器部分。希望你和我一样兴奋。在那之前,祝您编码愉快!
参考资料:
BERTopic: Fine-tune Parameters. In general, BERTopic works fine with… | by DamenC | Medium
Transformer’s from scratch in simple python. Part-I | by Harshad Patil | Aug, 2023 | Medium
相关文章:
变形金刚:从零开始【01/2】
一、说明 在我们的日常生活中,无论你是否是数据科学家,你都在单向地使用变压器模型。例如。如果您使用的是 ChatGPT 或 GPT-4 或任何 GPT,那么在为您回答问题的框中是变压器的一部分。如果您是数据科学家或数据分析师,则可能正在使…...
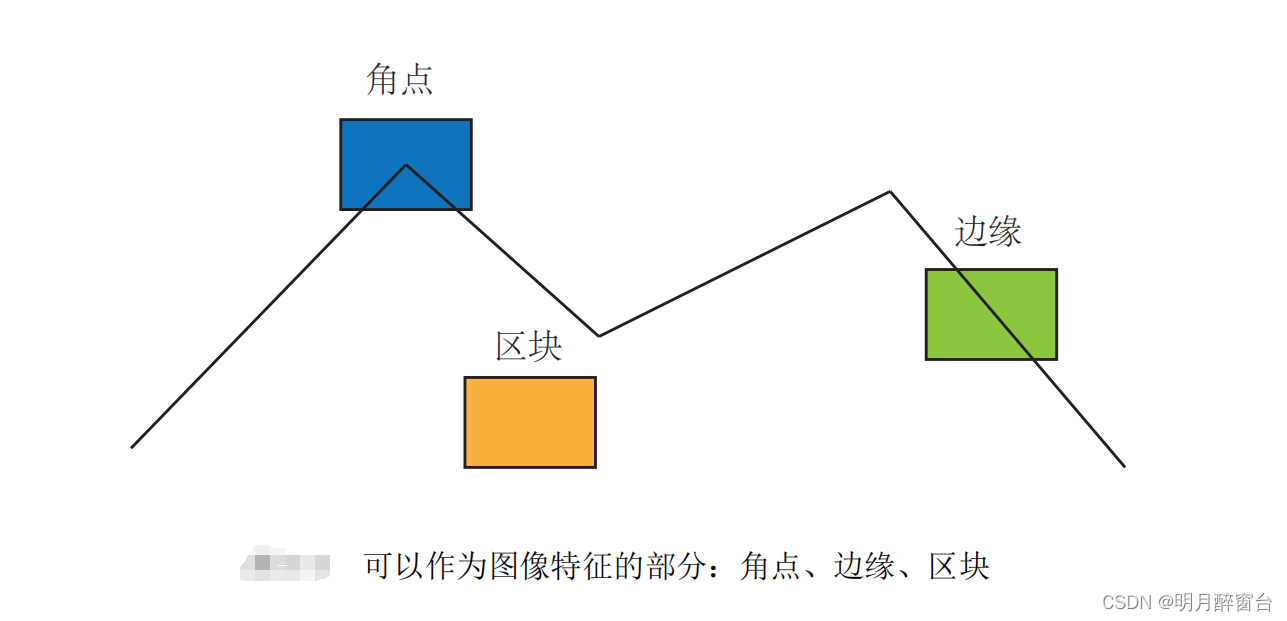
Opencv特征检测之ORB算法原理及应用详解
Opencv特征检测之ORB算法原理及应用详解 特征是图像信息的另一种数字表达形式。一组好的特征对于在指定 任务上的最终表现至关重要。视觉里程 (VO) 的主要问题是如何根据图像特征来估计相机运动。但是,整幅图像用来计算分析通常比较耗时,故而转换为分析图像中的特征点的运动…...

【es6】函数柯里化(Currying)
柯里化(Currying):把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数。 柯里化由 Christopher Strachey 以逻辑学家 Haskell Curry 命名的,它是 Mos…...

线上多域名实战
本文博主给大家分享线上多域名实战,当线上主域名不可用的情况下,启用备用域名完成网站高可用保障。 网站的高可用性一直是网站运维的重中之重。一旦网站宕机,不仅会造成巨大的经济损失,也会严重影响用户体验。备份域名就是一种实现…...

【C语言】上手实验
实验1 顺序、分支结构 程序填空 1. 题目描述:输入三个整数存放在变量a、b、c中,找出三个数中的最大值放于max中,并将其输出。以下是完成此项工作的程序,请将未完成的部分填入,实现其功能,并在计算机上…...

设计HTML5表单
HTML5基于Web Forms 2.0标准对HTML4表单进行全面升级,在保持简便、易用的基础上,新增了很多控件和属性,从而减轻了开发人员的负担。表单为访问者提供了与网站进行互动的途径,完整的表单一般由控件和脚本两部分组成。 1、认识HTML…...
使用Kaptcha生成验证码
说明:验证码,是登录流程中必不可少的一环,一般企业级的系统,使用都是专门制作验证码、审核校验的第三方SDK(如极验)。本文介绍,使用谷歌提供的Kaptcha技术,制作一个简单的验证码。 …...
【vue】vue中的插槽以及使用方法
插槽 普通插槽 1、在父组件中直接调用子组件的标签,是可以渲染出子组件的内容;如果在子组件标签中添加了内容,父组件就渲染不出来了; ParentComponent.vue: <template><div><h1>Parent Componen…...
javaScript:分支语句的理解与使用(附带案例)
目录 前言 补充 另一种说法 分支语句 1.if语句 a.单分支语句 注意 b.双分支语句 注意点 c.多分支语句(分支语句的联级语句) 补充 2.三元运算符 三元运算符 ? : 使用场景 3.switch语句 解释 释义:…...
事务的并发问题和隔离级别)
MySQL高阶知识点(一)事务的并发问题和隔离级别
简单来说,事务就是要保证一组数据库操作,要么全部成功,要么全部失败。 在 MySQL 中,事务支持是在引擎层实现的。 MySQL 是一个支持多引擎的系统,但并不是所有的引擎都支持事务。 如 MySQL 原生的 MyISAM 引擎就不支持…...
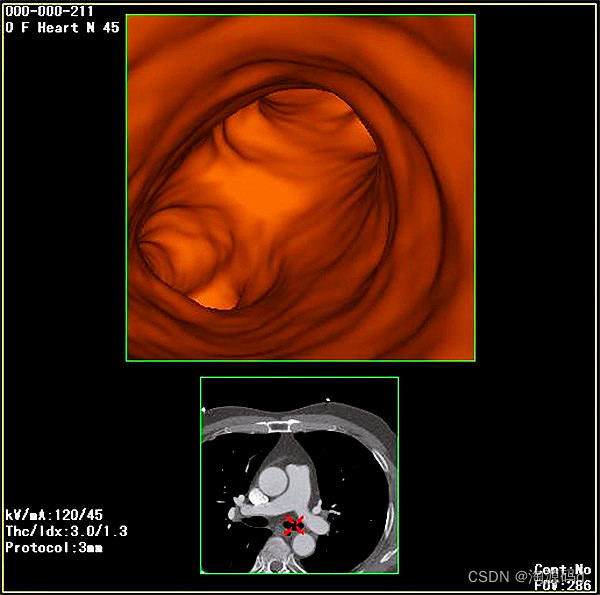
医疗PACS源码,支持三维多平面重建、三维容积重建、三维表面重建、三维虚拟内窥镜
C/S架构的PACS系统源码,PACS主要进行病人信息和影像的获取、处理、存储、调阅、检索、管理,并通过网络向全院提供病人检查影像及诊断报告;各影像科室之间共享不同设备的病人检查影像及诊断报告;在诊断工作站上,调阅HIS中病人的其它…...
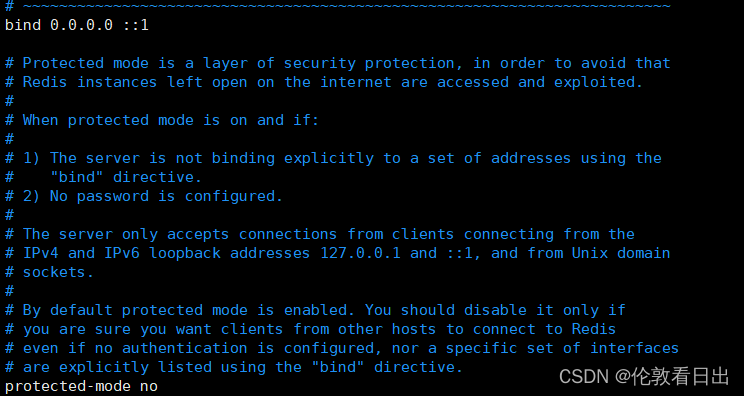
Ubuntu安装Redis
首先要切换到root用户 1.apt安装 apt install redis 2.⽀持远程连接 修改 /etc/redis/redis.conf • 修改 bind 127.0.0.1 为 bind 0.0.0.0 • 修改 protected-mode yes 为 protected-mode no 3.控制 Redis 启动 1.启动 Redis 服务 service redis-server start 2.停⽌ Redis …...

“深入解析JVM内部机制:探索Java虚拟机的奥秘“
标题:深入解析JVM内部机制:探索Java虚拟机的奥秘 JVM(Java虚拟机)是Java程序的核心执行环境,它负责将Java字节码转换为机器码并执行。了解JVM的内部机制对于理解Java程序的执行过程和性能优化至关重要。本文将深入解析…...

vim打开文件中文是乱码
vim打开文件中文是乱码 问题:在Linux系统下,使用cat查看含有中文的文本文件正常,但是使用vim打开却是乱码 解决方法: 方法一: 在文件中设定 在vim的退出模式下 :set encodingutf8 方法二: 直接写入/etc/…...

【正点原子STM32连载】 第七章 Geehy标准库版本MDK工程创建 摘自【正点原子】APM32F407最小系统板使用指南
1)实验平台:正点原子stm32f103战舰开发板V4 2)平台购买地址:https://detail.tmall.com/item.htm?id609294757420 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html# 第七…...
的不同用法)
SQL中count()的不同用法
1.count(*):统计所有列的行数,包括均为null值的行; 2.count(1):统计所有列的行数,包括均为null值的行; 3.count(列名):统计指定列的行数,不包括null值; 实例:…...

go_细节注意
go细节 一、使用指针接受者和不使用指针接受者1,不使用指针接受者:2,使用指针接受者3,区别与优劣势 一、使用指针接受者和不使用指针接受者 1,不使用指针接受者: func (d dog) move() {fmt.Println("…...

屏蔽恶意域名的DNS查询
因为有一些恶意域名, 已经在防火墙上做了封禁了, 但是如果收到中毒主机的请求, 还是要去做一次DNS查询, 因此被上级单位通告, 因此想把恶意域名的DNS查询封禁做到防火墙下联的AC上面, 一方面因为防火墙的策略优先级DNS代理比较靠后, 另一方面也是为了减小防火墙压力, 简化配置:…...
SQL-每日一题【1251. 平均售价】
题目 Table: Prices Table: UnitsSold 编写SQL查询以查找每种产品的平均售价。average_price 应该四舍五入到小数点后两位。 查询结果格式如下例所示: 解题思路 1.题目要求查询每种产品的平均售价。给出了两个表,我们用聚合查询来解决此问题。 2.首先我…...
Win11中使用pip或者Cython报错 —— error: Microsoft Visual C++ 14.0 is required.
第一步:下载Visual Studio 2019 下载地址: https://learn.microsoft.com/zh-cn/visualstudio/releases/2019/release-notes 第二步:安装组件 选择单个组件,勾选以下两个组件 其他错误: 无法打开文件“python37.li…...

Windows RTMP流媒体服务器搭建完整指南:nginx-rtmp-win32终极教程
Windows RTMP流媒体服务器搭建完整指南:nginx-rtmp-win32终极教程 【免费下载链接】nginx-rtmp-win32 Nginx-rtmp-module Windows builds. 项目地址: https://gitcode.com/gh_mirrors/ng/nginx-rtmp-win32 想要在Windows系统上快速搭建自己的RTMP直播服务器…...

为什么说Ohook重新定义了Office激活的技术边界?
为什么说Ohook重新定义了Office激活的技术边界? 【免费下载链接】ohook An universal Office "activation" hook with main focus of enabling full functionality of subscription editions 项目地址: https://gitcode.com/gh_mirrors/oh/ohook 当…...

110页PPT的大数据产品设计和应用,含整体方案和多个行业案例,满分PPT
📘【文档介绍】🌐《大数据应用型产品设计方法及行业案例介绍》PPT共110页可编辑文档,它将是你招投标、行业解决方案的重要参考资料。 🔑【掌握大数据,引领企业未来】 作为企业管理者,需要的不仅是管理智慧&…...
:基于1372组AB测试的材质Token黄金配比公式)
Midjourney材质质感翻车实录(金属发灰/皮革失真/玻璃无折射):基于1372组AB测试的材质Token黄金配比公式
更多请点击: https://kaifayun.com 第一章:Midjourney材质表现方法论总纲 Midjourney 作为以语义驱动的图像生成模型,其对材质(Texture)的表达并非依赖显式参数控制,而是通过提示词(Prompt&…...

通过Taotoken用量看板清晰掌握各模型调用成本与消耗趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板清晰掌握各模型调用成本与消耗趋势 在将大模型能力集成到实际项目时,除了关注功能实现࿰…...

从绿光到深紫外:手把手教你选对BBO、LBO、CLBO晶体,搞定激光倍频实验
从绿光到深紫外:非线性晶体选型与倍频实验实战指南 当实验室的1064nm激光器发出那束熟悉的近红外光时,许多研究者脑海中会立刻浮现两个问题:如何高效获得532nm的翠绿光束?又该如何进一步压缩波长至266nm的深紫外区域?…...

终极视频修复神器UNTRUNC:如何免费恢复损坏的MP4/MOV文件
终极视频修复神器UNTRUNC:如何免费恢复损坏的MP4/MOV文件 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 你是否…...

17 ThingsBoard网关设备-子设备数据模型实战:核心价值+完整落地指南
ThingsBoard网关设备-子设备数据模型实战:核心价值完整落地指南 一、任务说明 1.1 场景必要性 在物联网(IoT)/工业物联网(IIoT)场景中,「网关设备-子设备」层级数据模型是解决异构设备批量接入、统一管理…...

ViGEmBus:让Windows游戏外设兼容性不再是难题
ViGEmBus:让Windows游戏外设兼容性不再是难题 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过心爱的游戏手柄在Windows上无法被…...

KVM网络配置踩坑记:从virt-install的`--network`参数到virsh管理虚拟网桥
KVM网络配置实战:从virt-install到virsh的深度解析 当你在本地环境搭建KVM虚拟机时,网络配置往往是第一个拦路虎。不同于物理机插上网线就能用的简单体验,虚拟化环境中的网络需要经过多层抽象和配置才能正常工作。本文将带你深入KVM网络配置的…...