基于注意力神经网络的深度强化学习探索方法:ARiADNE

ARiADNE:A Reinforcement learning approach using Attention-based Deep Networks for Exploration
文章目录
- ARiADNE:A Reinforcement learning approach using Attention-based Deep Networks for Exploration
- 机器人自主探索(ARE)
- ARE的传统边界法
- 非短视路径
- 深度强化学习的方法的积极意义
- 问题定义
- 方法
- 强化学习问题映射建模
- 策略网络
- 训练
- Soft Actor-critic
- 训练细节
参考论文:Cao Y, Hou T, Wang Y, et al. Ariadne: A reinforcement learning approach using attention-based deep networks for exploration[J]. arXiv preprint arXiv:2301.11575, 2023.
2023 IEEE International Conference on Robotics and Automation (ICRA 2023)
机器人自主探索(ARE)
ARE的传统边界法
自主机器人探索(Autonomous robot exploration, ARE)
目标: ARE的目标是规划完成探索的最短路径,其中最终地图中的小噪音/错误是可以容忍的
任务要点: ARE的任务要点是规划一条非短视路径,平衡探索环境(即在已经探索过的区域中优化地图)和探索新区域(通常是更远的区域)之间的权衡,最重要的是只对环境有部分了解。这样的勘探路径通常是增量在线规划的,因为局部地图会使用沿途的新测量来更新
传统基于边界的方法: 传统的基于边界的方法生成多条候选路径,每条路径覆盖一个边界(即已探索的自由区域与未探索区域之间的边界),并贪婪地选择具有最大收益的路径,通常定义为效用(即沿路径可观察的边界数量)和成本(即路径长度)的组合。
局限性:这种短视的边界选择并不能保证长期的最优性。由于环境只是部分已知的,所以之前的最佳路径往往会随着更多环境的暴露而变得次优,或者更糟的是,导致冗余的移动(例如,错过了两个房间之间未探索的捷径,而这两个房间之前并不知道是相连的)。
非短视路径
空间非短视要求规划者对当前的局部地图进行推理,以平衡探索与开发之间的权衡
时间非短视: 要求规划者估计当前决策对未来的影响(例如,预测可能源于给定路径规划决策的局部地图的变化)。
深度强化学习的方法的积极意义
发掘局部地图依赖关系:
基于深度强化学习(DRL)的ARE方法,在注意力机制的加持下,允许智能体在不同的空间尺度上推理局部地图中不同区域的依赖关系,从而允许智能体在不需要优化长路径的情况下有效地对空间非近视决策进行排序。
发掘潜在区域:
Critic网络隐含地为机器人提供了通过学习状态值来估计可能发现的潜在区域的能力,这进一步有助于做出有利于长期效率的决策,从而解决暂时非近视问题。
方法示例:
首先将自主探索表述为覆盖已知可穿越区域的无碰撞图上的顺序决策问题,其中一个节点是机器人的当前位置。然后,使用基于注意力的神经网络选择机器人当前位置的一个相邻节点作为机器人的下一个视点。
问题定义
环境 E \mathcal{E} E,由 x × y x\times y x×y的2D占据栅格地图表示
栅格地图 P P P,未知区域为 P u P_u Pu,已知区域为 P k P_k Pk,自由区域为 P f P_f Pf,障碍物区域 P o P_o Po,存在以下关系:
P f ∈ P k P o ∈ P k P u ∪ P k = P P f ∪ P o = P k P_f\in P_k\\P_o\in P_k\\P_{u} \cup P_{k}=P\\P_{f} \cup P_{o}=P_{k} Pf∈PkPo∈PkPu∪Pk=PPf∪Po=Pk
初始状态地图完全未知 P = P u P=P_u P=Pu
探索过程通过传感器的测量(测量范围为 d s d_s ds)将未知区域分类成自由区域和占据区域
机器人寻找最短的无碰撞轨迹 ψ ∗ \psi^{*} ψ∗
ψ ∗ = argmin ψ ∈ Ψ C ( ψ ) , s.t. P k = P g \psi^{*}=\underset{\psi \in \Psi}{\operatorname{argmin}} \mathrm{C}(\psi), \text { s.t. } P_{k}=P_{g} ψ∗=ψ∈ΨargminC(ψ), s.t. Pk=Pg
对于 C C C函数, ψ → R + \psi \rightarrow \mathbb{R}^{+} ψ→R+将轨迹映射成为其长度和groud-truth P g P_g Pg。
尽管在真实世界的部署中无法获得基本事实,但它是已知的,并且可以用于评估测试中的计划器的性能。在实际中,大多数工作将占用区域的闭集视为 P k = P g P_k = P_g Pk=Pg
方法
强化学习问题映射建模
问题定义:
由于自由区域的更新视基于机器人的移动,在线的ARE的规划实际上是一个序贯决策问题,根据之前的工作[20]进行信息路径规划,我们将机器人轨迹 ψ ψ ψ视为视点序列 ψ = ( ψ 0 , ψ 1 , … ) , ψ i ∈ P f ψ = (ψ_0, ψ_1,…),ψ_i∈P_f ψ=(ψ0,ψ1,…),ψi∈Pf
序贯决策问题:
在每个决策步骤t中,首先在当前自由区域 P f P_f Pf中均匀分布候选视点 V t = { v 0 , v 1 , … } , ∀ v i = ( x i , y i ) ∈ P f Vt=\{v_0,v_1,\ldots\},∀v_i=(x_i, y_i)∈P_f Vt={v0,v1,…},∀vi=(xi,yi)∈Pf。然后,为了找到视点之间的无碰撞路径,通过一条直线将每个视点与其k个最近的邻居连接起来,并去除与已占用或未知区域碰撞的边缘。在此过程中,构建一个无碰撞图 G t = ( V t , E t ) G_t = (V_t, E_t) Gt=(Vt,Et),其中 V t V_t Vt是自由区域上均匀分布的一组节点(即视点),而是 E t E_t Et一组可遍历的边。最后让机器人选择其当前位置的一个相邻节点作为下一个视点。由于决策将在到达最后选定的视点时做出,因此轨迹是一系列航路点,使得 ψ i ∈ V ψ_i∈V ψi∈V。
观测:
智能体的观测值 o t = ( G t ′ , ψ t ) o_t=(G_t^{\prime},\psi_t) ot=(Gt′,ψt), G t ′ = ( V t ′ , E t ) G^\prime_t=(V_t^{\prime},E_t) Gt′=(Vt′,Et)是无碰撞图 G t G_t Gt的增广图,其中 ψ t \psi_t ψt是机器人当前的位置, G t ′ G_t^{\prime} Gt′与 G t G_t Gt共享边集 E t E_t Et,增广图节点 v i ′ v_i^{\prime} vi′不仅包含 v i = ( x i , y i ) v_i=(x_i,y_i) vi=(xi,yi)的属性,同时还包含了二值的 b i b_i bi属性,表示节点是否已经被智能体访问过,再与效用 u i u_i ui 联系起来, v i ′ = ( x i , y i , u i , b i ) v_i^{\prime}=(x_i,y_i,u_i,b_i) vi′=(xi,yi,ui,bi)。
b i b_i bi的作用:作者通过实验证明,添加二进制访问位可以更好地感知之前的移动过程
u i u_i ui的作用:效用 u i u_i ui代表了节点 v i v_i vi的可观测边界的数量,可观测边界即为在节点到无碰撞边界的连线在传感器范围内的边界,的 u i u_i ui定义为
u i = ∣ F o , i ∣ , ∀ f j ∈ F o , i , ∥ f j − v i ∥ ≤ d s , L ( v i , f j ) ∩ ( P − P f ) = ∅ \begin{array}{c}u_{i}=\left|F_{o, i}\right|, \forall f_{j} \in F_{o, i},\left\|f_{j}-v_{i}\right\| \leq d_{s}, L\left(v_{i}, f_{j}\right) \cap\left(P-P_{f}\right)=\emptyset\end{array} ui=∣Fo,i∣,∀fj∈Fo,i,∥fj−vi∥≤ds,L(vi,fj)∩(P−Pf)=∅
F o , i F_{o,i} Fo,i表示 v i v_i vi的可观测边界集, d s d_s ds表示传感器的范围, L ( v i , f j ) L(v_i,f_j) L(vi,fj)表示节点 v i v_i vi到边界 f j f_j fj的连线,在输入神经网络之前将节点坐标系和效用归一化
动作:
在每个决策步骤 t t t,给定智能体的观测值 o t o_t ot,基于注意力的神经网络输出一个随机策略,从所有邻近节点中选择一个节点作为下一个要访问的视点。其定义为:
π θ ( a t ∣ o t ) = π θ ( ψ t + 1 = v i , ( ψ t , v i ) ∈ E t ∣ o t ) \pi_{\theta}\left(a_{t} \mid o_{t}\right)=\pi_{\theta}\left(\psi_{t+1}=v_{i},\left(\psi_{t}, v_{i}\right) \in E_{t} \mid o_{t}\right) πθ(at∣ot)=πθ(ψt+1=vi,(ψt,vi)∈Et∣ot)
θ \theta θ是神经网络的权重,机器人沿直线移动到下一个视点,并根据沿途收集的数据更新部分地图。
奖励:
r o = ∣ F o , ψ t + 1 ∣ r_{o}=\left|F_{o, \psi_{t+1}}\right| ro=∣Fo,ψt+1∣ ,在新的视点观测到的边界数量
r c = − C ( ψ t , ψ t + 1 ) r_{c}=-\mathrm{C}\left(\psi_{\mathrm{t}}, \psi_{\mathrm{t}+1}\right) rc=−C(ψt,ψt+1),上一个视点和新视点之间的距离惩罚
r f = { 20 , P k = P g 0 , otherwise r_{f}=\left\{\begin{array}{ll}20, & P_{k}=P_{g} \\0, & \text { otherwise }\end{array}\right. rf={20,0,Pk=Pg otherwise ,一个episoid后,探索任务完成得奖励
总奖励 r t ( o t , a t ) = a ⋅ r o + b ⋅ r c + r f r_{t}\left(o_{t}, a_{t}\right)=a \cdot r_{o}+b \cdot r_{c}+r_{f} rt(ot,at)=a⋅ro+b⋅rc+rf, a a a和 b b b是标量参数(参考值 a = 1 / 50 a=1/50 a=1/50, b = 1 / 64 b=1/64 b=1/64)
策略网络
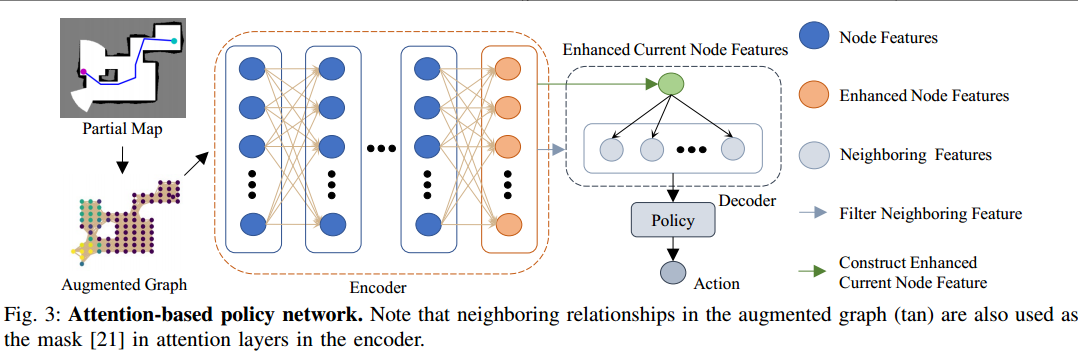
由编码器和解码器构成的基于注意力的神经网络输出策略 ψ θ \psi_\theta ψθ,由编码器从部分地图中提取显著性特征,尤其是增广图中 G ′ G^{\prime} G′节点的之间的依赖关系;由解码器基于这些显著性特征和机器人当前的位置输出在邻近节点上的决定下一个访问点的策略。
Pointer Network的使用
基于策略的RL代理通常具有固定的动作空间,解码器受到指针网络的启发,允许动作空间取决于网络中输入的邻近节点的数量。这允许网络自然地适应无碰撞图,其中节点具有任意数量的邻居。
Attention Layer
使用注意力模块作为基础的构建模块,注意力层的输入包括一个查询向量 h q h^q hq和键值向量 h k , v h^{k,v} hk,v,注意力层的输出是 h i ′ h_i^{\prime} hi′,它是值向量的加权和,权重系数取决于键和值之间的相似度
Encoder
边集的掩膜 M M M的元素由 m i j = { 0 , ( v i , v j ) ∈ E t 1 , ( v i , v j ) ∉ E t m_{i j}=\begin{array}{l}\left\{\begin{array}{l}0,\left(v_{i}, v_{j}\right) \in E_{t} \\1,\left(v_{i}, v_{j}\right) \notin E_{t}\end{array}\right.\\\end{array} mij={0,(vi,vj)∈Et1,(vi,vj)∈/Et计算,节点的特征然后被传递多层注意力层(实际中取6层,其中) h q = h k , v = h n h^q=h^{k,v}=h^n hq=hk,v=hn,每一层的输入是上一层的输出,通过设置 w i j = 0 , ∀ ( i , j ) , m i j = 1 w_{ij}=0,\forall(i,j),m_{ij}=1 wij=0,∀(i,j),mij=1边集掩膜用于准许每个节点访问相邻节点的特征,尽管每一层的注意力被限制在相邻节点上,但通过这种堆叠的注意力结构,节点仍然可以通过多次聚集节点特征来获得非相邻节点的特征。我们的经验发现,这种结构比图transformer更适合在具有杂乱障碍物的地图中学习寻路。我们将编码器的输出称为增强的节点特征 h ^ e \hat{h}^e h^e,因为每个更新的节点特征 h ^ i n \hat{h}_i^n h^in都包含与 v i ′ v_i^{\prime} vi′其他节点的依赖关系。
Decoder
解码器用于输出基于增强节点特征 h ^ e \hat{h}^e h^e和当前机器人的位置 ψ t \psi_t ψt。
当前机器人的位置表示为节点 v c = ψ t v_c=\psi_t vc=ψt,首先选择当前节点特征 h c h^c hc和邻点特征 h n b h^{nb} hnb,其中 ∀ h ^ i n b , ( v c , v i ) ∈ E t \forall \hat{h}_{i}^{n b},\left(v_{c}, v_{i}\right) \in E_{t} ∀h^inb,(vc,vi)∈Et相应地是增强节点特征,将当前节点特征和增强节点特征传入注意力层 h q = h k , v = h n h^q=h^{k,v}=h^n hq=hk,v=hn,将其输出和 h c h^c hcconcatenate并将其投影为d维向量,将这个向量命名为增强的当前节点向量 h ^ c \hat{h}^c h^c,在那之后,将增强的当前节点特征和邻节点特征传入pointer层,注意力层直接输出注意力权重 w w w和 h q = h ^ c , h k , v = h n b h^q=\hat{h}^c,h^{k,v}=h^{nb} hq=h^c,hk,v=hnb作为输出。最终将pointer层的输出作为机器人的策略(即 π θ ( a t ∣ o t ) = w i \pi_\theta(a_t|o_t)=w_i πθ(at∣ot)=wi)
策略网络训练方式
soft actor critic(SAC)
评判网络
训练目的:预测状态-行动的价值
状态-动作价值:由于状态-动作价值的值是对长期回报的近似,所以其有隐性的对于潜在收益的预测(即可能发现潜在的区域),这个性质可以帮助机器人的序列做非近视决策。实际上训练一个评判网络近似软更新状态-动作价值 Q ϕ ( o t , a t ) Q_{\phi}\left(o_{t}, a_{t}\right) Qϕ(ot,at), ϕ \phi ϕ表示评判网络的权重集。
网络结构:评判网络的网络结构与策略网络近乎相同,除了在最后没有pointer层。最后是直接将增强当前节点特征与邻近特征concatenate,并将其投影成状态-动作值
训练
Soft Actor-critic
SAC的目标是学习一种策略,使回报最大化,同时使其熵尽可能高:
π ∗ = argmax E ( o t , a t ) [ ∑ t = 0 T γ t ( r t + α H ( π ( . ∣ o t ) ) ) ] \pi^{*}=\operatorname{argmax} \mathbb{E}_{\left(o_{t}, a_{t}\right)}\left[\sum_{t=0}^{T} \gamma^{t}\left(r_{t}+\alpha \mathcal{H}\left(\pi\left(. \mid o_{t}\right)\right)\right)\right] π∗=argmaxE(ot,at)[t=0∑Tγt(rt+αH(π(.∣ot)))]
π ∗ \pi^{*} π∗是优化策略, T T T是决策的步数, γ \gamma γ是折扣系数, α \alpha α是调节交叉熵对于回报的重要性参数。
软状态价值
V ( o t ) = E a t [ Q ( o t , a t ) ] − α log ( π ( a t ∣ o t ) ) V(o_t)=\mathbb{E}_{a_{t}}\left[Q\left(o_{t}, a_{t}\right)\right]-\alpha \log \left(\pi\left(a_{t} \mid o_{t}\right)\right) V(ot)=Eat[Q(ot,at)]−αlog(π(at∣ot))
critic损失函数
J Q ( ϕ ) = E o t [ 1 2 ( Q ϕ ( o t , a t ) − ( r t + γ E o t + 1 [ V ( o t + 1 ) ] ) ) 2 ] J_{Q}(\phi)=\mathbb{E}_{o_{t}}\left[\frac{1}{2} \left(Q_{\phi}\left(o_{t}, a_{t}\right)-\right.\right.\left.\left.\left(r_{t}+\gamma \mathbb{E}_{o_{t+1}}\left[V\left(o_{t+1}\right)\right]\right)\right)^{2}\right] JQ(ϕ)=Eot[21(Qϕ(ot,at)−(rt+γEot+1[V(ot+1)]))2]
policy损失函数
J π ( θ ) = E ( o t , a t ) [ α log ( π θ ( a t ∣ o t ) ) − Q ϕ ( o t , a t ) ] J_{\pi}(\theta)=\mathbb{E}_{\left(o_{t}, a_{t}\right)}\left[\alpha \log \left(\pi_{\theta}\left(a_{t} \mid o_{t}\right)\right)-Q_{\phi}\left(o_{t}, a_{t}\right)\right] Jπ(θ)=E(ot,at)[αlog(πθ(at∣ot))−Qϕ(ot,at)]
训练中自调节的 α \alpha α损失
J ( α ) = E a t [ − α ( log π t ( a t ∣ o t ) + H ‾ ) ] J(\alpha)=\mathbb{E}_{a_{t}}\left[-\alpha\left(\log \pi_{t}\left(a_{t} \mid o_{t}\right)+\overline{\mathcal{H}}\right)\right] J(α)=Eat[−α(logπt(at∣ot)+H)]
H \mathcal{H} H表示目标熵。在实际中使用双目标critic网络进行训练
训练细节
基础工作
利用引用中提供的相同环境进行训练,这些环境由随机地下城生成器生成。每个环境是一个640 × 480网格地图,而传感器范围 d s = 80 d_s=80 ds=80
F. Chen, S. Bai, T. Shan, and B. Englot, “Self-learning exploration
and mapping for mobile robots via deep reinforcement learning,” in
Aiaa scitech 2019 forum, 2019, p. 0396.
无碰撞图构建过程
为了构建无碰撞图,均匀分布900个点以覆盖整个环境,将已知自由区域内的所有点视为候选视点 V V V。我们检查每个视点的k = 20最近的邻居,如果这样一条边是无碰撞的,将它们连接起来,形成边缘集 E E E。
任务完成判断标准
我们认为一旦探测到99%以上的groud-truth(|Pk|/|Pg| > 0.99),勘探任务就完成了。
参数
在训练期间,将最大集长度设置为128个决策步骤,折扣因子设置为γ = 1,批大小设置为256,episoid buffer大小设置为10,000。
训练在episoid buffer收集到超过2000步的数据后开始。目标熵设为 0.01 ⋅ l o g ( k ) 0.01·log(k) 0.01⋅log(k)。每个训练步骤包含1次迭代,并在1 个episoid完成后进行。对于策略网络和批评网络,我们使用学习率为 1 0 − 5 10^{−5} 10−5的Adam优化器。目标critic网络每256个训练步骤更新一次。
训练时间
模型在配备i9-10980XE CPU和NVIDIA GeForce RTX 3090 GPU的工作站上进行训练。我们使用Ray(一种用于机器学习的分布式框架)来训练我们的模型,以并行化和加速数据收集(实践中有32个实例)。训练需要24小时左右才能完成。
代码参考https://github.com/marmotlab/ARiADNE
相关文章:
基于注意力神经网络的深度强化学习探索方法:ARiADNE
ARiADNE:A Reinforcement learning approach using Attention-based Deep Networks for Exploration 文章目录 ARiADNE:A Reinforcement learning approach using Attention-based Deep Networks for Exploration机器人自主探索(ARE)ARE的传统边界法非短视路径深度强化学习的方…...
Martin_DHCP_V3.0 (DHCP自动化泛洪攻击GUI)
Github>https://github.com/MartinxMax/Martin_DHCP_V3.0 首页 Martin_DHCP_V3.0 自动化DHCP洪泛攻击 Martin_DHCP_V3.0 使用方法 安装三方库 #python3 1.RunMe_Install_Packet.py 攻击路由器 #python3 Martin_DHCP_Attack.py 填写网卡 填写攻击次数 开始运行...

vscode vue3+vite 配置eslint
vue2webpackeslint配置 目前主流项目都在使用vue3vite,因此针对eslint的配置做了一下总结。 引入ESlint、pritter 安装插件,执行以下命令 // eslint // prettier // eslint-plugin-vue // eslint-config-prettier // eslint-plugin-prettier yarn ad…...

【C++学习手札】一文带你初识运算符重载
食用指南:本文在有C基础的情况下食用更佳 🍀本文前置知识: C类 ♈️今日夜电波:クリームソーダとシャンデリア—Edo_Ame江户糖 1:20 ━━━━━━️💟──────── 3:40 …...

javaScript:数组检测
目录 一.前言 二.数组检测方法 1.every() 2.some() 3.filter() 一.前言 数组检测是指在编程中对数组进行验证和检查的过程。数组检测可以涉及以下方面: 确定数组的存在:在使用数…...

【JavaEE基础学习打卡02】是时候了解Java EE了!
目录 前言一、为什么要学习Java EE二、Java EE规范介绍1.什么是规范?2.什么是Java EE规范?3.Java EE版本 三、Java EE应用程序模型1.模型前置说明2.模型具体说明 总结 前言 📜 本系列教程适用于 Java Web 初学者、爱好者,小白白。…...

LeetCode 2813. Maximum Elegance of a K-Length Subsequence【反悔贪心】2582
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

日常BUG——SpringBoot模糊映射
😜作 者:是江迪呀✒️本文关键词:日常BUG、BUG、问题分析☀️每日 一言 :存在错误说明你在进步! 一、问题描述 SpringBoot在启动时报出如下错误: Caused by: java.lang.IllegalStateExceptio…...
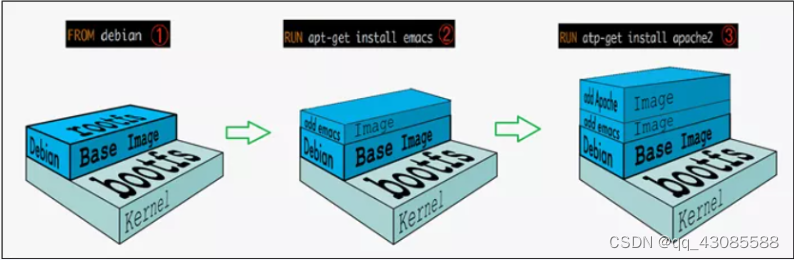
Docker 镜像
1. 什么是镜像? 镜像 是一种轻量级、可执行的独立软件包,它包含运行某个软件所需的所有内容,我们把应用程序和配置依赖打包好形成一个可交付的运行环境(包括代码、运行时需要的库、环境变量和配置文件等),这个打包好的运行环境就…...

Python发送QQ邮件
使用Python的smtplib可以发送QQ邮件,代码如下 #!/usr/bin/python3 import smtplib from email.mime.text import MIMEText from email.header import Headersender 111qq.com # 发送邮箱 receivers [222qq.com] # 接收邮箱 auth_code "abc" # 授权…...

梯度下降求极值,机器学习深度学习
目录 梯度下降求极值 导数 偏导数 梯度下降 机器学习&深度学习 学习形式分类...

【业务功能篇62】Spring boot maven多模块打包时子模块报错问题
程序包 com.xxx.common.utils不存在或者xxx找不到符号 我们项目中一般都是会分成多个module模块,做到解耦,方便后续做微服务拆分模块,可以直接就每个模块进行打包拎出来执行部署这样就会有模块之间的调用,比如API模块会被Service…...
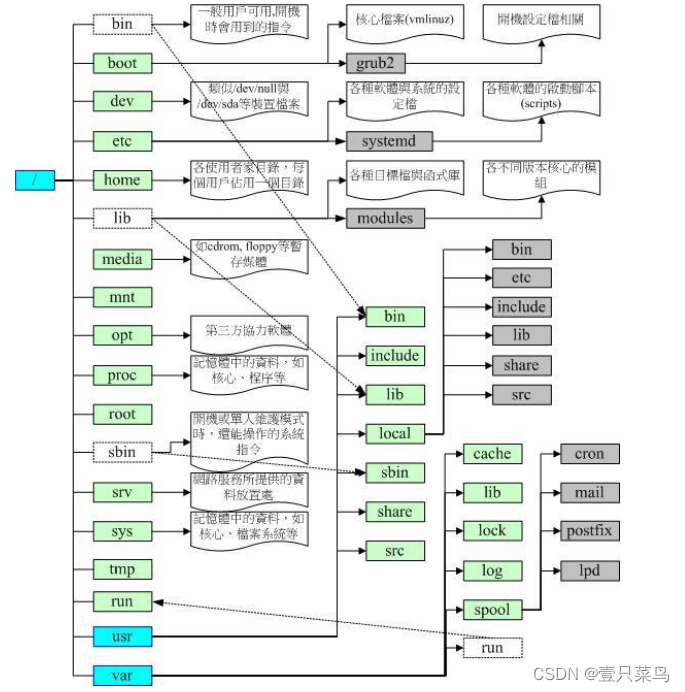
【BASH】回顾与知识点梳理(二十一)
【BASH】回顾与知识点梳理 二十一 二十一. Linux 的文件权限与目录配置21.1 使用者与群组属主(文件拥有者)属组(群组概念)其他人的概念root(万能的天神)Linux 用户身份与群组记录的文件 21.2 Linux 文件权限概念Linux 文件属性Linux 文件权限的重要性 21.3 如何改变文件属性与权…...

从针尖对麦芒,到丝滑入扣,记录那些BT需求
前言: 最近被一个“简单”的需求,搞的有点难受。需求其实很简单,就是记录某成品生产过程数据,然后进行展示,但因需求部门是管理部门。为了能获取足够多的参数来提高生产效率和研发进度。因此需要生产来统计收集对应生产…...

封装vue2局部组件都要注意什么
一. 关于局部组件组成的三个部分(template, script, style) template > 组件的模板结构 (必选) 每个组件对应的模板结构,需要定义到template节点中 <template><!-- 当前组件的dom结构,需…...
第三章 算法从0开始】)
【深入浅出程序设计竞赛(基础篇)第三章 算法从0开始】
深入浅出程序设计竞赛(基础篇)第三章 算法从0开始 第三章 例题例3-1例3-2例3-3例3-4例3-5例3-6例3-7例3-8例3-9例3-10例3-11例3-12 第三章 课后习题3-13-23-33-43-53-63-73-83-9 第三章 例题 例3-1 #include<iostream> using namespace std;int …...
博客目录导读)
安全之安全(security²)博客目录导读
研究方向:安全之安全 研究内容:ARM/RISC-V安全架构、TF-A/TEE之安全、GP安全认证、静态代码分析、FUZZ模糊测试、IDA逆向分析、安全与功耗等,欢迎您的关注💖💖 一、ARM安全架构 1、ARM安全架构及其发展趋势࿰…...

ubuntu安装opencv4
apt 安装 sudo apt install libopencv-dev python3-opencvpkg-config查看安装 sudo apt install pkg-configpkg-config --modversion opencv4pkg-config --libs --cflags opencv4参考 如何在 Ubuntu 20.04 上安装 OpenCV pkg-config 详解...

Qt 当磁盘可用空间小于指定大小时删除早期的文件
1. 需求 用户反应,电脑由于自身磁盘空间只有128G,由于软件执行一次任务,就要录视频记录,导致磁盘空间爆满,电脑卡,无法再次生成视频 2. 分析:当时软件没有写自动删除视频的代码导致的。 可以…...

浙大数据结构第七周之07-图6 旅游规划
题目详情: 有了一张自驾旅游路线图,你会知道城市间的高速公路长度、以及该公路要收取的过路费。现在需要你写一个程序,帮助前来咨询的游客找一条出发地和目的地之间的最短路径。如果有若干条路径都是最短的,那么需要输出最便宜的…...

个人开发者如何通过TaoToken以更低成本体验多种主流大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 个人开发者如何通过TaoToken以更低成本体验多种主流大模型 对于预算有限的个人开发者和学生而言,直接接入和使用多个主…...

Cadence Virtuoso计算器函数面板:从仿真波形到关键指标,手把手教你提取运放GBW和相位裕度
Cadence Virtuoso计算器函数实战:运放AC特性自动化评估指南 在模拟电路设计的日常工作中,我们常常需要面对这样的场景:完成运放AC仿真后,面对密密麻麻的波形曲线,如何快速准确地提取出增益带宽积(GBW)和相位裕度(PM)这…...

Anubis质检报告XTR文件:从数据字段到质量评估的实战解析
1. XTR文件基础:GNSS质检报告的核心载体 第一次拿到Anubis生成的XTR文件时,我盯着满屏的缩写和数据愣了半天。这种看似晦涩的文本文件,实际上是GNSS数据质量的"体检报告单"。就像医院的血常规化验单需要专业解读一样,XT…...

FontForge终极指南:免费开源字体编辑器从零到精通
FontForge终极指南:免费开源字体编辑器从零到精通 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge FontForge是一款完全免费的开源字体编辑器,…...

VSCode里Code Runner跑Python总报9009?别慌,检查一下你的setting.json文件
VSCode中Code Runner执行Python报错9009的终极排查指南 当你第一次在VSCode中用Code Runner插件运行Python脚本,满心期待看到输出结果时,终端却弹出"Process exited with code 9009"的红色错误提示——这种挫败感我深有体会。这个看似神秘的错…...

终极虚拟定位指南:FakeLocation让你的Android设备位置自由
终极虚拟定位指南:FakeLocation让你的Android设备位置自由 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 你是否厌倦了应用的位置限制?想要在社交软件中保…...

免费开源!掌握AMD Ryzen处理器深度调试:SMUDebugTool终极指南
免费开源!掌握AMD Ryzen处理器深度调试:SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项…...
)
零基础转专业计算机机试,我用这5道题帮你摸清浙工大出题套路(附C++代码)
零基础转专业计算机机试:5道真题破解浙工大出题密码(附C实战代码) 第一次面对计算机转专业机试时,我盯着屏幕上闪烁的光标,手指悬在键盘上方却不知从何下手。那种面对陌生题型的茫然感,至今记忆犹新。现在作…...

更全面的 Token 套餐来了:Agent Plan
作为一名 Token 消耗大户,各模型厂商和云厂商的套餐我基本都有入手:智谱、MiniMax、小米 Mimo,以及最早推出 Coding Plan 的火山引擎,这些都是我目前在订的。以前 Coding Plan 基本能够覆盖日常工作,但是随着越来越多场…...

Jenkins 安装Publish over SSH插件远程发布执行shell脚本
1.在jenkins安装Publish over SSH插件,在Manage Jenkins–Plugins–Available plugins中搜索Publish over SSH,然后安装即可。2.安装成功以后,需要到系统设置DashBoard—Manage Jenkins—System中进行配置,如图 可以通过密码链接也…...