【并发编程】自研数据同步工具的优化:创建线程池多线程异步去分页调用其他服务接口获取海量数据
文章目录
- 场景:
- 解决方案
场景:
前段时间在做一个数据同步工具,其中一个服务的任务是调用A服务的接口,将数据库中指定数据请求过来,交给kafka去判断哪些数据是需要新增,哪些数据是需要修改的。
刚开始的设计思路是,,我创建多个服务同时去请求A服务的接口,每个服务都请求到全量数据,由于这些服务都注册在xxl-job上,而且采用的是分片广播的路由策略,那么每个服务就可以只处理请求到的所有数据中id%服务总数==分片索引的部分数据,然后交给kafka,由kafka决定这条数据应该放到哪个分区上。
解决方案
最近学了线程池后,回过头来思考,认为之前的方案还有很大的优化空间。
- 1.当数据量很大时,一次性查询所有数据会导致数据库的负载过大,而使用分页查询,每次只查询部分数据,可以减轻数据库的负担,从而提高数据库的性能和响应速度,所以请求数据方每次分页查询少量数据,这样可以整体降低请求数据的时间。
- 第一次优化.之前是每个服务都要把全量数据请求过来,假设全量数据1000w条,一个服务请求数据需要100s,我开5个服务,那请求数据的总时长就是500s。现在把1000w条数据均分给5个服务,那1个服务就只需要请求200w条数据,耗时20s,那所有服务的请求总时长就是100s。总体耗时缩小了5倍。上面说的分页查询就可以实现:页面大小假设10w(也就是将1000w/10w,逻辑上分成了100页),每个服务自己的分片索引作为页号,每次请求完,都给索引加上分片总数(例如:当前注册了五个服务,那分片总数=5,对于分片索引为1的服务来说,请求的页号为1,6,11,16,21。。。,对于分片索引为2的服务来说,请求的页号为2,7,12,17。。。,对于分片索引为3的服务来说,请求的页号为3,8,13,18,。。。。,对于分片索引为4的服务来说,请求的页号为4,9,14,19。。。。,对于分片索引为5的服务来说,请求的页号为5,10,15,20.。。)这样1000w条数据就均分到每个服务上了。对于每个服务都是单线程去请求数据,就可以将请求操作以及(页号+总服务数)的操作写在一个while循环里,一直请求数据,直到请求的数据为空时(也就是页号超过100了),退出while。
//单线程情况下while(true){String body = HttpUtil.get(remoteURL+"?pageSize=100000&pageNum="+shardIndex);
// logger.info("body:{}",body);//2.获取返回结果的messageJSONObject jsonObject = new JSONObject();
// if (StrUtil.isNotBlank(body)) {jsonObject = JSONUtil.parseObj(body);
// logger.info("name:{}",Thread.currentThread().getName());
// }
// logger.info("jsonObject:{}",jsonObject);//3.从body中获取dataList<TestPO> tests = JSONUtil.toList(jsonObject.getJSONArray("data"), TestPO.class);if(CollectionUtil.isEmpty(tests)){break;}shardIndex+=shardTotal;}
- 第二次优化: 了解了线程池后,还可以再优化。之前是一个服务单线程循环请求需要20s(假设),每次请求10w条,需要请求200w/10w,也就是20次,那一次请求就需要1s。如果使用线程池的话,那么耗时还会更小,因为当你将任务都交给线程池去执行时,多个线程会同时(并行)去请求各自页的数据,假如你只设置了4个线程,那这4个线程会同时发起请求获取数据,1s会完成4次请求,那分给服务的200w,5s就请求完了。那5个服务从总耗时500s,降到了总耗时5s*5=25s。
这次优化,第一版代码(只展示了请求数据的代码,其他业务代码没有展示)
一直向线程池里扔请求数据的任务,当某个任务请求到的数据是空的时候,意味着要请求的数据已经没了,那就结束循环,不再扔请求数据的任务。
//线程共享变量static volatile boolean flag = true;@XxlJob(value = "fenpian")public void fenpian() {int shardIndex = XxlJobHelper.getShardIndex();
// int shardTotal = XxlJobHelper.getShardTotal();//分片总数int shardTotal = 4;AtomicInteger pageNum = new AtomicInteger(shardIndex);//多线程情况下
// List<CompletableFuture>completableFutureList=new ArrayList<>();while (flag){CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {String body = HttpUtil.get(remoteURL + "?pageSize=1000&pageNum=" + pageNum.getAndAdd(shardTotal));JSONObject jsonObject = new JSONObject();jsonObject = JSONUtil.parseObj(body);List<TestPO> tests = JSONUtil.toList(jsonObject.getJSONArray("data"), TestPO.class);logger.info("tests的size:{}",tests.size());if(CollectionUtil.isEmpty(tests)){flag=false;}},executorService);completableFutureList.add(future);}CompletableFuture[] completableFutures = completableFutureList.toArray(new CompletableFuture[completableFutureList.size()]);CompletableFuture.allOf(completableFutures).join();logger.info("任务结束");executorService.shutdown();
上面代码会有一个问题,就是while循环往线程池里扔任务,所有线程在执行时,会在请求数据那里”停留“一段时间,“停留期间”还会一直循环向线程池扔任务,当线程执行完某次请求得到空数据结束循环时,等待队列中还排着大堆任务等着去请求数据。
为了解决这个问题,我改用了for循环提交任务,提前根据请求数据总量、每次读取的条数,以及服务总数得到每个服务需要执行的任务数。
第二版代码
@XxlJob(value = "fenpian")public void fenpian() {int shardIndex = XxlJobHelper.getShardIndex()+1;int shardTotal = XxlJobHelper.getShardTotal();//分片总数
// int shardTotal = 4;AtomicInteger pageNum = new AtomicInteger(shardIndex);//多线程情况下List<CompletableFuture>completableFutureList=new ArrayList<>();//总条数double total = 10000000;//读取的条数double pageSize=1000;double tasks = Math.ceil( total / (double) shardTotal / pageSize);logger.info("任务数{}",tasks);for(double i=0;i<tasks;i++){CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {String url = remoteURL + "?pageSize=1000&pageNum=" + pageNum.getAndAdd(shardTotal);logger.info("url:{},threadName:{}",url,Thread.currentThread().getName());String body = HttpUtil.get(url);JSONObject jsonObject = new JSONObject();jsonObject = JSONUtil.parseObj(body);List<TestPO> tests = JSONUtil.toList(jsonObject.getJSONArray("data"), TestPO.class);logger.info("tests的size:{}",tests.size());},executorService);completableFutureList.add(future);}CompletableFuture[] completableFutures = completableFutureList.toArray(new CompletableFuture[completableFutureList.size()]);CompletableFuture.allOf(completableFutures).join();logger.info("任务结束");
如有问题,请求指正(^^ゞ
相关文章:

【并发编程】自研数据同步工具的优化:创建线程池多线程异步去分页调用其他服务接口获取海量数据
文章目录 场景:解决方案 场景: 前段时间在做一个数据同步工具,其中一个服务的任务是调用A服务的接口,将数据库中指定数据请求过来,交给kafka去判断哪些数据是需要新增,哪些数据是需要修改的。 刚开始的设…...
)
python函数、运算符等简单介绍3(无顺序)
set(集合) 集合(set) -> 负责存储【不重复的数据】,并且是【无序存储】 的容器,主要用来去重和逻辑比较 set1 {1,2,3,4,58,7,4,1,2,3,5} print(set1) print(type(set1)) # 输出结果: {1, 2, 3, 4, 5, 7, 58} <…...
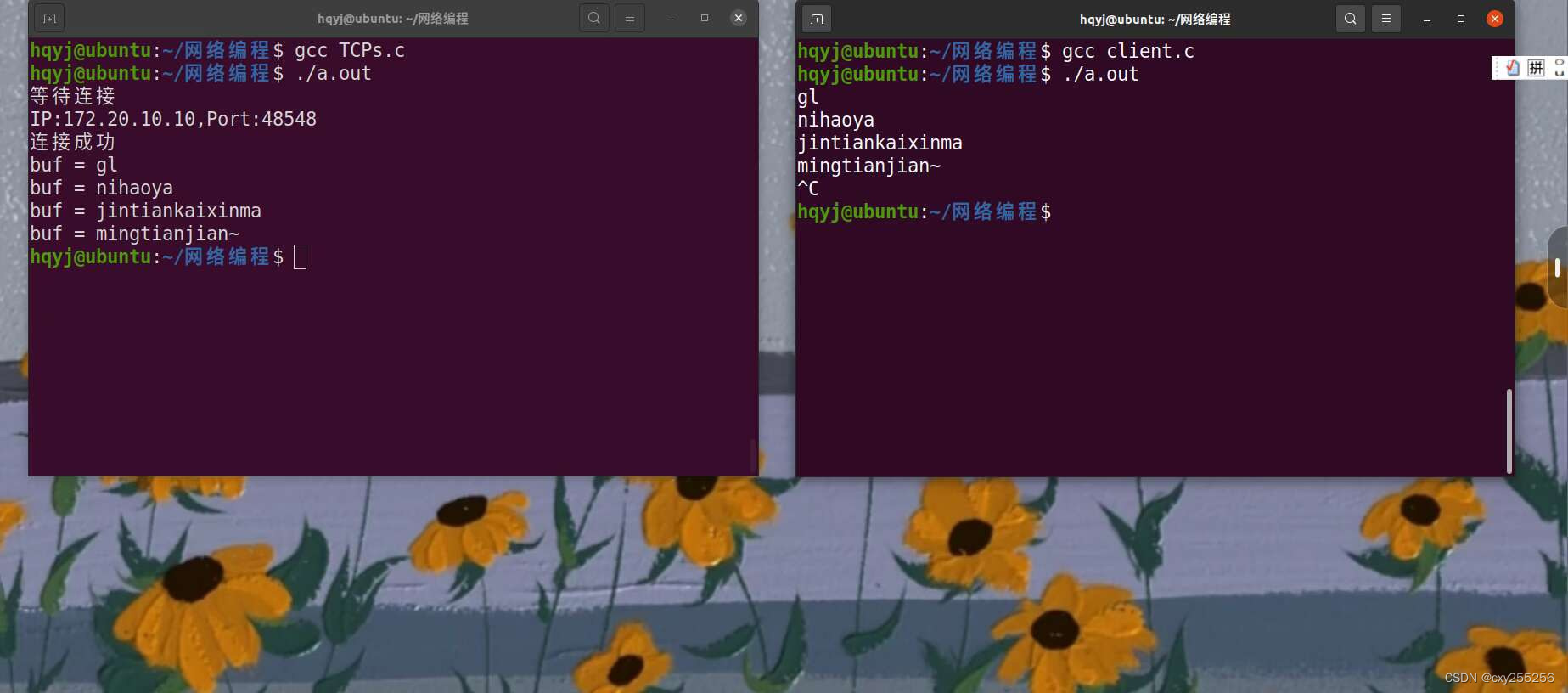
TCP服务器(套接字通信)
服务器 客户端 结果...
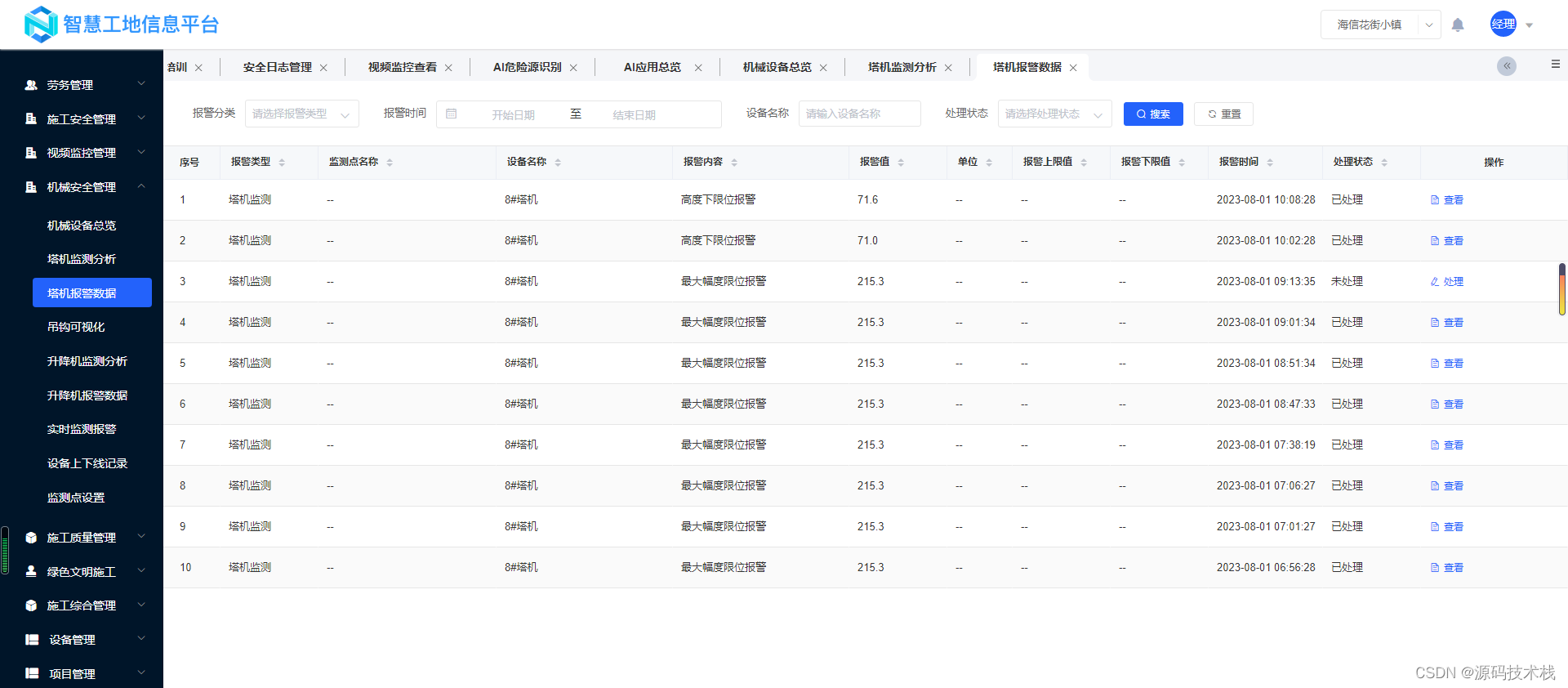
【智慧工地源码】:人工智能、BIM技术、机器学习在智慧工地的应用
智慧工地云平台是专为建筑施工领域所打造的一体化信息管理平台。通过大数据、云计算、人工智能、BIM、物联网和移动互联网等高科技技术手段,将施工区域各系统数据汇总,建立可视化数字工地。同时,围绕人、机、料、法、环等各方面关键因素&…...
使用python读Excel文件并写入另一个xls模版
效果如下: 原文件内容 转化后的内容 大致代码如下: 1. load_it.py #!/usr/bin/env python import re from datetime import datetime from io import BytesIO from pathlib import Path from typing import List, Unionfrom fastapi import HTTPExcep…...

债务人去世,债权人要求其妻女承担还款责任,法院支持吗
债务人去世,债权人要求其妻女承担还款责任,法院支持吗 2019年9月20日,老张以公司资金周转为由向好友任某先后借款合计40万。2022年8月27日老张出具还款承诺书,承诺2022年11月30日前归还本息(本息90万元)到…...
arcgis pro3.0-3.0.1-3.0.2安装教程大全及安装包下载
一. 产品介绍: ArcGIS Pro 这一功能强大的单桌面 GIS 应用程序是一款功能丰富的软件,采用 ArcGIS Pro 用户社区提供的增强功能和创意进行开发。 ArcGIS Pro 支持 2D、3D 和 4D 模式下的数据可视化、高级分析和权威数据维护。 支持通过 Web GIS 在一系列 …...
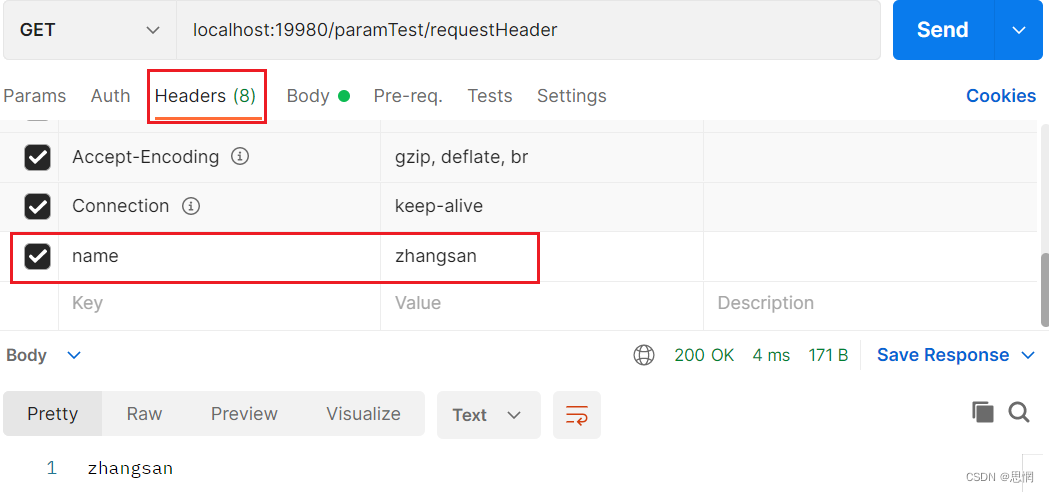
@RequestHeader使用
RequestHeader 请求头参数的设置 GetMapping("paramTest/requestHeader")public String requestHeaderTest(RequestHeader("name") String name){return name;} 在Postman的Headers中添加请求头参数,不过貌似不能加中文...
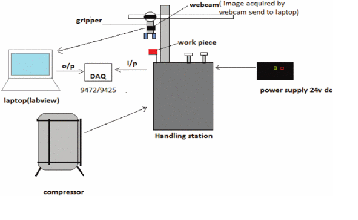
LabVIEW开发图像采集和基于颜色的隔离
LabVIEW开发图像采集和基于颜色的隔离 在当今的工业和工厂中,准确性和精度是决定特定行业生产力的两个重要关键点。为了优化生产力,各行各业正在从手动操作转向自动操作和控制。机器人技术在工业过程中的出现为人类提供了机械辅助。机器视觉在工业机器人…...

站长公益主机,免费主机➕免费域名➕博客申请➕论坛申请
站长公益主机,免费主机➕免费域名➕博客申请➕论坛申请 在出教程之前准备好久,测试搭建轻量论坛无压力 选用稳定免费域名➕免费主机分销给,可以套CDN使用 坚持免费时间是大厂不能媲美,刚开始做网站时用的是这个分销,独…...
【PRO-UPDATE】自动更新程序图形小记
大纲流程 设计流程 v0.1 v1.0...

flume系列之:监控Systemctl托管的flume agent组
flume系列之:监控Systemctl托管的flume agent组 一、需求背景二、相关技术博客三、远程登陆flume机器四、发送飞书告警五、监控flume agent组状态一、需求背景 flume接kafka集群,一个kafka集群对应一个flume agent组,会把一组flume agent用systemctl托管每接一个kafka集群会…...

16.3.1 【Linux】程序的观察
既然程序这么重要,那么我们如何查阅系统上面正在运行当中的程序呢?利用静态的 ps 或者是动态的 top,还能以 pstree 来查阅程序树之间的关系。 ps :将某个时间点的程序运行情况撷取下来 仅观察自己的 bash 相关程序: p…...

HarmonyOS 设置全屏NoTitleBar
这篇很有用:玩转HarmonyOS 状态栏&标题栏&导航栏相关操作方法整理 配置页面全屏显示(在config.json中配置): "metaData": {"customizeData": [{"name": "hwc-theme","value": "androi…...

Java 模块解耦的设计策略
Java 平台模块系统 (JPMS) 提供了更强的封装、更高的可靠性和更好的关注点分离,有些同学可能没注意到。 不过呢,也是有利有弊。由于模块化应用程序构建在依赖其他模块才能正常工作的模块网络上,因此在许多情况下,模块彼此紧密耦合…...
支持https访问
文章目录 1. 打开自己的云服务器的 80 和 443 端口2. 安装 nginx3. 安装 snapd4. 安装 certbot5. 生成证书6. 拷贝生成的证书到项目工作目录7. 修改 main.go 程序如下8. 编译程序9. 启动程序10. 使用 https 和端口 8081 访问页面成功11. 下面修改程序,支持 https 和…...

JavaScript 中常用简写技巧总结
平时我们写代码时最高级的境界是自己写的东西别人看不懂!哈哈哈!分享一些自己常用的js简写技巧,长期更新,会着重挑选一些实用的简写技巧,使自己的代码更简洁优雅~ 这里只会收集一些大多数人不知道的用法,但…...
第15集丨Vue 江湖 —— 组件
目录 一、为什么需要组件1.1 传统方式编写应用1.2 使用组件方式编写应用1.3 Vue的组件管理 二、Vue中的组件1.1 基本概念1.1.1 组件分类1.1.2 Vue中使用组件的三大步骤:1.1.3 如何定义一个组件1.1.4 如何注册组件1.1.5 如何使用组件 1.2 注意点1.2.1 关于组件名1.2.2 关于组件标…...
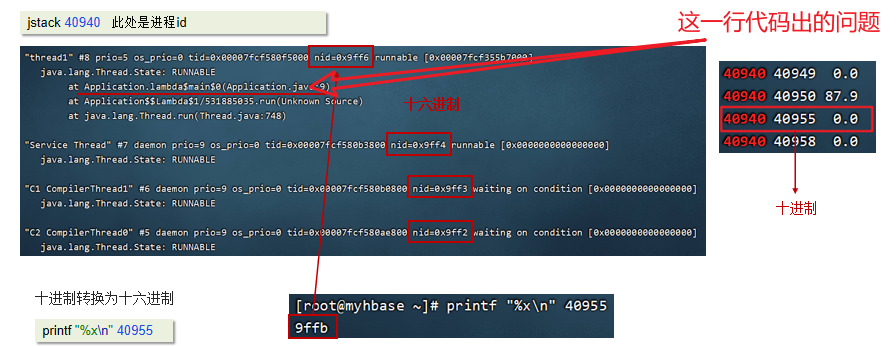
【JVM】CPU飙高排查方案与思路
文章目录 CPU飙高排查方案与思路 CPU飙高排查方案与思路 1.使用top命令查看占用cpu的情况 2.通过top命令查看后,可以查看是哪一个进程占用cpu较高,上图所示的进程为:40940 3.查看进程中的线程信息 4.可以根据进程 id 找到有问题的线程&a…...
使用公网访问内网IIS网站服务器【无需公网IP】
使用公网访问内网IIS网站服务器【无需公网IP】 文章目录 使用公网访问内网IIS网站服务器【无需公网IP】前言1. 注册并安装cpolar2. 创建隧道映射3. 获取公网地址 前言 这里介绍通过内网穿透,实现公网访问内网IIS网站服务器。 都知道,现在基本不会被分配…...

Windows字体自由:noMeiryoUI终极指南,轻松自定义系统界面字体
Windows字体自由:noMeiryoUI终极指南,轻松自定义系统界面字体 【免费下载链接】noMeiryoUI No!! MeiryoUI is Windows system font setting tool on Windows 8.1/10/11. 项目地址: https://gitcode.com/gh_mirrors/no/noMeiryoUI 你是否厌倦了Win…...

Linux内核平台设备深度盘点:从原理到实战的全面解析
1. 项目概述:一次对Linux内核“家底”的深度盘点在Linux内核开发的日常工作中,无论是为一块新的开发板适配驱动,还是排查一个诡异的硬件初始化问题,我们常常会面临一个基础却又关键的问题:当前系统里到底有哪些“平台设…...
阻塞机制解析:基于AQS与状态机的线程协作)
FutureTask.get()阻塞机制解析:基于AQS与状态机的线程协作
1. 项目概述:从异步编程的痛点说起在Java并发编程的日常开发中,我们经常遇到一个经典场景:主线程需要启动一个耗时的计算任务,但又不能干等着,希望在任务完成后能“拿到”那个结果。Thread类本身只负责执行,…...

Claude Code cli 以及vscode版本的各种命令参考手册
Claude Code 各种命令参考手册版本说明: 截至 2026 年 4 月,Claude Code 官方文档共收录超过 70 条内置命令与绑定技能。其中约一半为内置命令(行为由 CLI 代码实现),另一半为绑定技能(通过 Prompt 机制实现…...

集成SERDES+RGMII双接口:BCM54616SC0KFBG在背板与光纤应用中的灵活连接方案
BCM54616SC0KFBG:集成 SERDES 的低功耗单口千兆以太网 PHY在数据中心的服务器接入、企业级交换机上行链路以及工业自动化控制系统中,物理层芯片是实现网络通信的基石。随着网络设备向高密度、低功耗演进,传统的以太网 PHY 面临连接灵活性受限…...

从滑动变阻器到真实传感器:STM32CubeMX ADC单通道采集电压的校准与数据处理实战
从滑动变阻器到真实传感器:STM32CubeMX ADC单通道采集电压的校准与数据处理实战 在嵌入式开发中,ADC(模数转换器)是将模拟信号转换为数字信号的关键外设。许多开发者能够通过STM32CubeMX快速配置ADC并获取原始值,但当…...
全流程实操:从ONNX转换到INT8/FP16量化加速)
YOLOv8在Jetson上导出TensorRT引擎(.engine)全流程实操:从ONNX转换到INT8/FP16量化加速
YOLOv8在Jetson平台上的TensorRT引擎部署与量化加速实战指南 当目标检测模型需要部署到边缘计算设备时,性能优化往往成为最关键的技术挑战。本文将深入探讨如何将YOLOv8模型高效转换为Jetson平台专用的TensorRT引擎,并通过INT8/FP16量化技术实现推理速度…...

用Tableau分析酒店数据:手把手教你做地区均价条形图和价格等级饼图
用Tableau分析酒店数据:手把手教你做地区均价条形图和价格等级饼图 酒店行业的数据分析往往需要快速洞察不同地区的价格分布和消费层级特征。作为全球领先的商业智能工具,Tableau能以直观的可视化方式呈现这些关键指标。本文将带你从零开始,用…...

5分钟掌握Pearcleaner:macOS深度清理的终极免费方案
5分钟掌握Pearcleaner:macOS深度清理的终极免费方案 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 您是否曾为macOS上卸载应用后残留的配置文件…...

别再死记硬背了!用Python/JavaScript/C++对比理解‘整型变布尔’的底层逻辑
别再死记硬背了!用Python/JavaScript/C对比理解‘整型变布尔’的底层逻辑 在编程语言的学习过程中,类型系统是最基础也最容易被忽视的部分。特别是当开发者从一门动态类型语言转向静态类型语言时,经常会遇到一些"反直觉"的类型转换…...