Elasticsearch复合查询之Boosting Query
前言
ES 里面有 5 种复合查询,分别是:
- Boolean Query
- Boosting Query
- Constant Score Query
- Disjunction Max Query
- Function Score Query
Boolean Query在之前已经介绍过了,今天来看一下 Boosting Query 用法,其实也非常简单,总结起来就一句话,对不期待的查询关键词进行相关性降分。
Boost 加权机制底层也是 Lucene 提供的能力,对重要的数据加权有两个时机,一个是在索引时,一个是在查询时,在索引时候加权查询性能会比较高但不灵活,所以都会选择在查询时加权,加权的方式也很简单,如:
title: china^20 OR content: china^20在 ES里面的大多数全文检索 单 Query 都支持 boost 加权,但想要实现降权却不行,因为 Lucene 底层不直接支持,需要使用 function score query来间接实现,boost 的数值必须是正数,当然也可以包括 0-1 之间的小数,所以在 ES 中就封装了 Boosting Query 来支持对某些关键词进行降权查询,却又不是不让其出现在查询结果中,只是让其排名靠后
写入测试数据
在 kibana 中的 dev_tools 的 console 中,直接使用下面的 POST 语句即可,需要注意,如果 ES
版本低于 7.x 的,在 PATH 里面要加上 type,否则会报错:
POST test01/doc/_bulk
{ "index" : { "_id" : "1" } }
{ "title" : "Collecting Service", "content": "Logstash" }
{ "index" : { "_id" : "2" } }
{ "title" : "Collecting Service", "content": "Beats" }
{ "index" : { "_id" : "3" } }
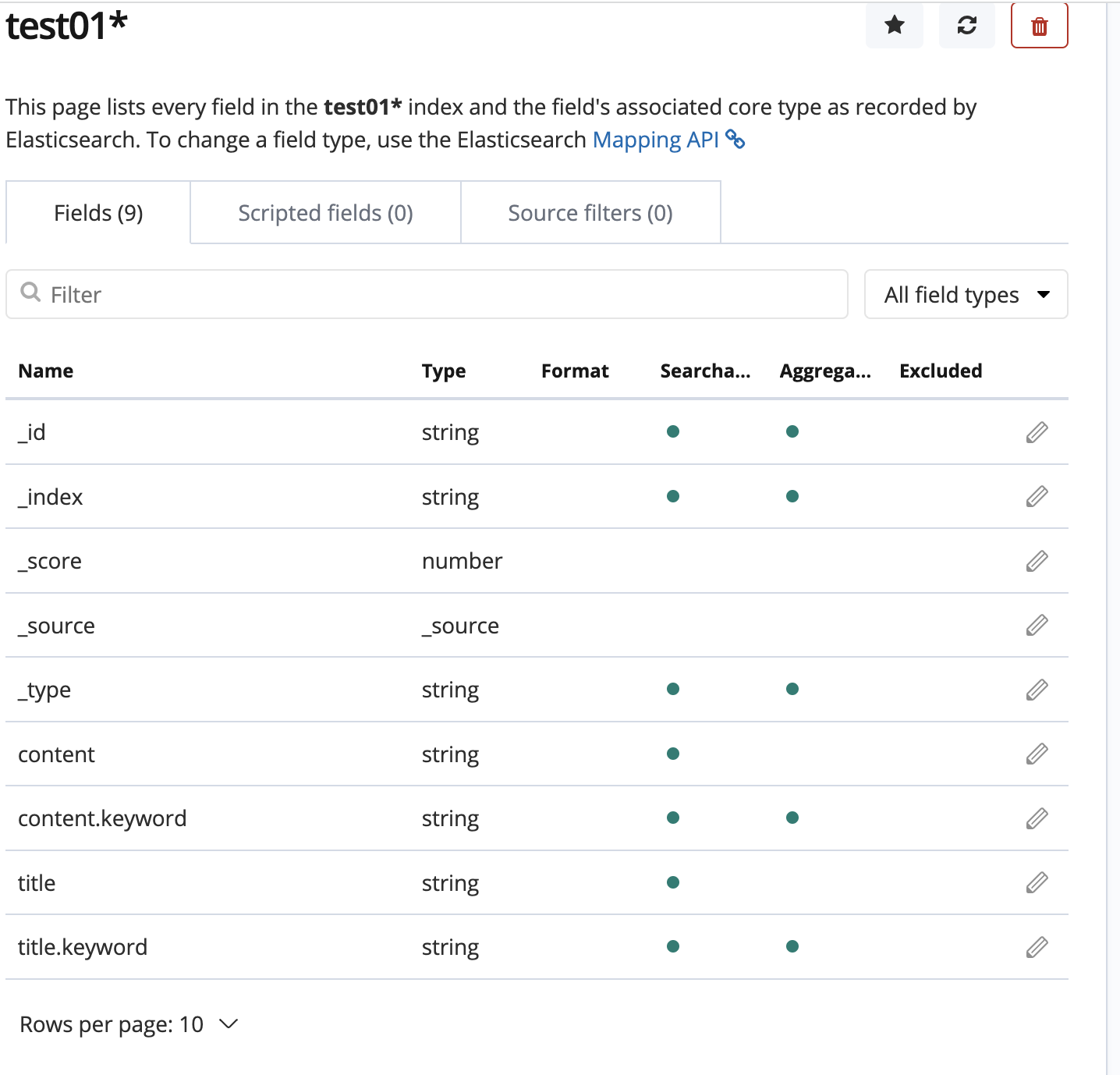
{ "title" : "Collecting Service", "content": "FLume" }写完之后,可以在 Management => Index patterns => Create Index Patterns 里面创建手动创建索引模板,可以看到生成了如下 mapping,需要注意的时,这里面自动推断的 mapping 字段并不能删减字段,因为我们是已经
将数据写入了 ES,如果想要控制字段的生成,比如不想要 content.keyword 字段,那么就要在写入数据前,提前定制 mapping 才可以
查询测试数据
GET test01/_search?
{"query": {"match": {"title": "Collecting"}}
}返回结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 6,"successful" : 6,"skipped" : 0,"failed" : 0},"hits" : {"total" : 3,"max_score" : 0.2876821,"hits" : [{"_index" : "test01","_type" : "doc","_id" : "3","_score" : 0.2876821,"_source" : {"title" : "Collecting Service","content" : "FLume"}},{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 0.2876821,"_source" : {"title" : "Collecting Service","content" : "Beats"}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 0.2876821,"_source" : {"title" : "Collecting Service","content" : "Logstash"}}]}
}
可以看到评分都相等,这个时候如果我想要命中 logstash 的不优先展示,就可以使用 Boosting Query 了:
GET test01/_search?
{"query": {"boosting": {"positive": {"match": {"title": "Collecting Service"}},"negative": {"match": {"content": "Logstash"}},"negative_boost": 0.5}}
}结果展示:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 6,"successful" : 6,"skipped" : 0,"failed" : 0},"hits" : {"total" : 3,"max_score" : 0.5753642,"hits" : [{"_index" : "test01","_type" : "doc","_id" : "3","_score" : 0.5753642,"_source" : {"title" : "Collecting Service","content" : "FLume"}},{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 0.5753642,"_source" : {"title" : "Collecting Service","content" : "Beats"}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 0.2876821,"_source" : {"title" : "Collecting Service","content" : "Logstash"}}]}
}
Boosting Query原理
Positive Boosting:
这种形式用于增强具有特定条件的文档的得分。它由两个子查询组成:主查询(positive query)和副查询(boost query)。主查询用于匹配文档,而副查询用于对匹配到的文档进行权重调整。Boosting Query将副查询的分数与主查询的分数相乘,从而影响文档的最终得分。
Negative Boosting:
这种形式用于降低具有特定条件的文档的得分。它同样由两个子查询组成:主查询和副查询。在Negative Boosting中,主查询用于匹配文档,而副查询用于对不匹配的文档进行权重调整。Boosting Query将副查询的分数与主查询的分数相乘,并将结果从1中减去,以降低不匹配文档的得分。
Boosting Query的实现原理如下:
- 解析查询语句:Elasticsearch首先解析用户提供的Boosting Query语句,提取出主查询和副查询以及相应的权重。
- 执行查询:对索引中的文档进行主查询匹配,并为匹配到的文档计算得分。
- 计算副查询得分:对于每个匹配到的文档,执行副查询,并计算副查询的得分。
- 应用权重调整:根据Boosting Query的类型(Positive Boosting或Negative Boosting),将副查询的得分与主查询的得分相乘,或者从1中减去,从而调整文档的最终得分。
- 返回结果:根据得分对匹配的文档进行排序,将搜索结果返回给用户。
相关文章:
Elasticsearch复合查询之Boosting Query
前言 ES 里面有 5 种复合查询,分别是: Boolean QueryBoosting QueryConstant Score QueryDisjunction Max QueryFunction Score Query Boolean Query在之前已经介绍过了,今天来看一下 Boosting Query 用法,其实也非常简单&…...
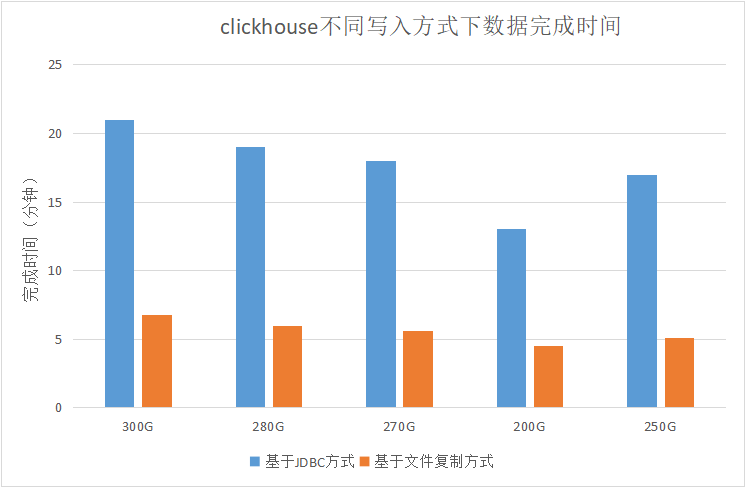
Clickhouse基于文件复制写入
背景 目前clickhouse社区对于数据的写入主要基于文件本地表、分布式表方式为主,但缺乏大批量快速写入场景下的数据写入方式,本文提供了一种基于clickhouse local 客户端工具分布式处理hdfs数据表文件,并将clickhouse以文件复制的方式完成写入…...

梅赛德斯-奔驰将成为首家集成ChatGPT的汽车制造商
ChatGPT的受欢迎程度毋庸置疑。OpenAI这个基于人工智能的工具,每天能够吸引无数用户使用,已成为当下很受欢迎的技术热点。因此,有许多公司都在想方设法利用ChatGPT来提高产品吸引力,卖点以及性能。在汽车领域,梅赛德斯…...

QT-播放原始PCM音频流
QT multimedia audioplay.h /************************************************************************* 接口描述:原始音频播放类 拟制: 接口版本:V1.0 时间:20220922 说明: ********************************…...

【杂谈】聊聊我是如何从Java转入Web3的
我先说说我基本的一个情况吧: 我是之前是一位从业了传统web2行业三年的Java开发,在2018年尾才开始去关注区块链的,之前虽然也有混迹在币圈,但是没怎么关注到币圈的内在运行逻辑。 后面因为当时元宇宙和Web3的概念特别火&a…...

ArrayList
目录 1.ArrayList简介 2.ArrayList的构造 2.1ArrayList() 2.2ArrayList(Collection c) 2.3ArrayList(int initialCapacity) 3.ArrayList常见操作 4.ArrayList的遍历的遍历 1.ArrayList简介 在集合框架中, ArrayList 是一个普通的类,实现了 List…...

不重启Docker能添加自签SSL证书镜像仓库吗?
应用背景 在企业应用Docker规划初期配置非安全镜像仓库时,有时会遗漏一些仓库没配置,但此时应用程序已经在Docker平台上部署起来了,体量越大就越不会让人去直接重启Docker。 那么,不重启Docker能添加自签SSL证书镜像仓库吗&…...
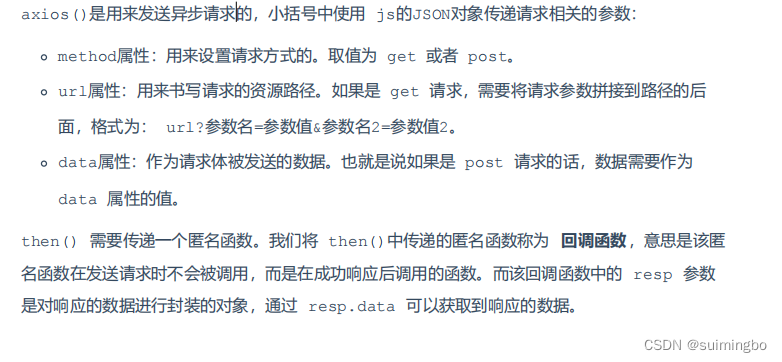
Ajax介绍
1.与服务器进行数据交换:通过 Ajax 可以给服务器发送请求,并获取服务器响应的数据。 2.异步交互:可以在 不重新加载整个页面 的情况下,与服务器交换数据并 更新部分网页 的技术,如: 搜索联想、用户名是否可…...

docker 学习--02 常用命令
docker 学习–02 常用命令 docker 学习-- 01 基础知识 docker 学习-- 03 环境安装(win10) 文章目录 docker 学习--02 常用命令1. 帮助启动类命令1.1启动docker1.2 停止docker1.3 重启docker1.4 查看docker1.5 设置开机自启1.6 查看docker概要信息1.7 查…...

socks5 保障网络安全与爬虫需求的完美融合
Socks5代理:跨足网络安全和爬虫领域的全能选手 Socks5代理作为一种通用的网络协议,为多种应用场景提供了强大的代理能力。它不仅支持TCP和UDP的数据传输,还具备更高级的安全特性,如用户身份验证和加密通信。在网络安全中…...

构建智能医疗未来:人工智能在线上问诊系统开发中的应用
随着人工智能技术的飞速发展,医疗领域也正在逐步迎来一场革命性的变革。其中,人工智能在在线上问诊系统开发中的应用,正为医疗产业带来全新的可能性。本文将深入探讨如何利用代码构建智能医疗未来,以提升线上问诊系统的效率、准确…...

css3-grid:grid 布局 / 基础使用
一、理解 grid 二、理解 css grid 布局 CSS Grid布局是一个二维的布局系统,它允许我们通过定义网格和网格中每个元素的位置和尺寸来进行页面布局。CSS Grid是一个非常强大的布局系统,它不仅可以用于构建网格布局,还可以用于定位元素…...
如何在windows电脑安装多个tomcat服务器和乱码问题
前提条件安装jdk 以17版本为例,将jdk8卸载干净 1.首先进入tomcat官网下载 tomcat网址 这里下载tomcat10为例子 1.1 这里选择方式一 下载解压版 2.解压后拷贝三份 分别命名为 8081、 8082、 8083 3.分别对每个tomcat执行以下操作 3.1 找到tomcat所在webapps文…...

flutter:webview_flutter的简单使用
前言 最近在研究如何在应用程序中嵌入Web视图,发现有两个库不错。 一个是官方维护、一个是第三方维护。因为没说特别的需求,就使用了官方库,实现一些简单功能是完全ok的 基本使用 官方文档 https://pub-web.flutter-io.cn/packages/webv…...
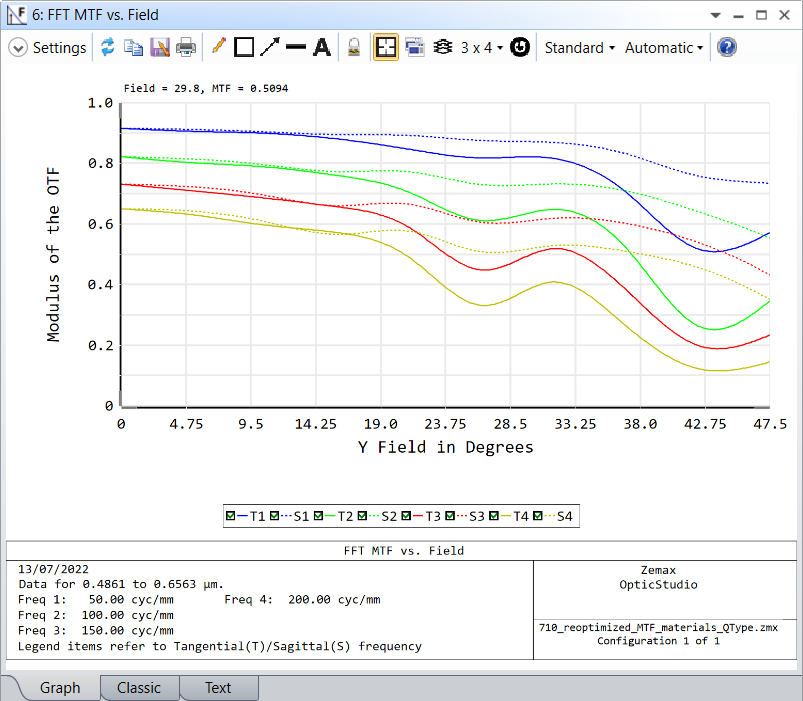
Ansys Zemax | 手机镜头设计 - 第 1 部分:光学设计
本文是 3 篇系列文章的一部分,该系列文章将讨论智能手机镜头模组设计的挑战,从概念、设计到制造和结构变形的分析。本文是三部分系列的第一部分,将专注于OpticStudio中镜头模组的设计、分析和可制造性评估。(联系我们获取文章附件…...

jvm从入门到精通
jvm 1.jvm与java体系结构...

[NLP]LLM 训练时GPU显存耗用量估计
以LLM中最常见的Adam fp16混合精度训练为例,分析其显存占用有以下四个部分: GPT-2含有1.5B个参数,如果用fp16格式,只需要1.5G*2Byte3GB显存, 但是模型状态实际上需要耗费1.5B*1624GB. 比如说有一个模型参数量是1M,在…...

Unity引擎使用InteriorCubeMap采样制作假室内效果
Unity引擎制作假室内效果 大家好,我是阿赵。 这次来介绍一种使用CubeMap做假室内效果的方式。这种技术名叫InteriorCubeMap,是UE引擎自带的节点效果。我这里是在Unity引擎里面的实现。 一、效果展示 这个假室内效果,要动态看才能看出效…...
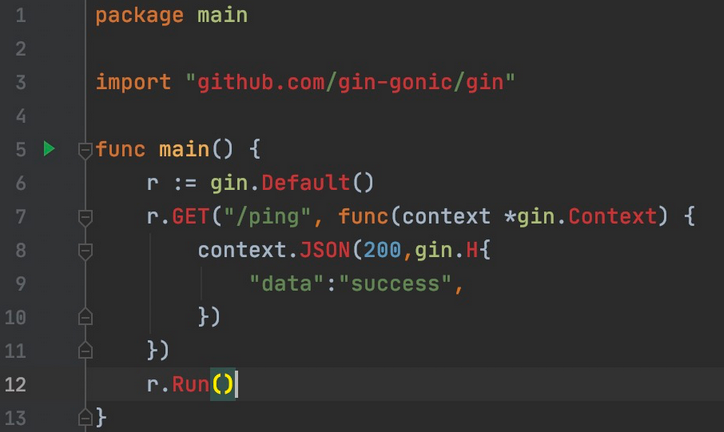
Gin安装解决国内go 与 热加载
get 方式安装超时问题,国内直接用官网推荐的下面这个命令大概率是安装不成功的 go get -u github.com/gin-gonic/gin 可以在你的项目目录下执行下面几个命令: 比如我的项目在E:\Oproject\zl cmd E:\Oproject\zl>就在目录下执行 go env -w GO111…...
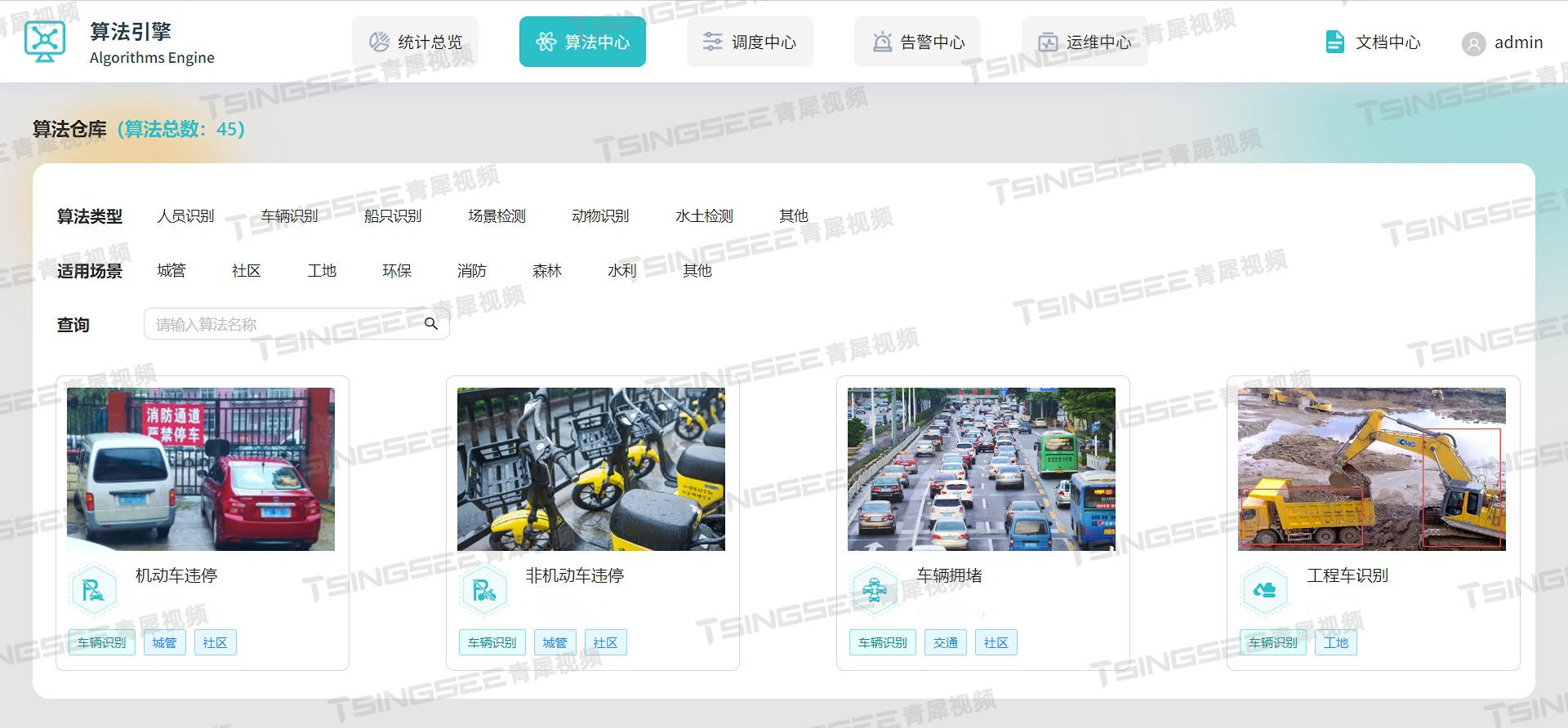
安防监控视频云存储平台EasyCVRH.265转码功能更新:新增分辨率配置
安防视频集中存储EasyCVR视频监控综合管理平台可以根据不同的场景需求,让平台在内网、专网、VPN、广域网、互联网等各种环境下进行音视频的采集、接入与多端分发。在视频能力上,视频云存储平台EasyCVR可实现视频实时直播、云端录像、视频云存储、视频存储…...

搞懂对数收益率:为什么金融圈都在悄悄用它?
搞懂对数收益率:为什么金融圈都在悄悄用它?如果你曾经被“涨10%再跌10%,怎么还亏了?”这个问题困扰过,那么读完这篇文章,你会豁然开朗。一、一个让你“感觉不对”的小实验 假设朋友向你推荐一只期货合约&am…...

C# 环境:深入解析与应用
C# 环境:深入解析与应用 引言 C#(读作“C Sharp”)是一种由微软开发的高级编程语言,广泛应用于Windows平台的应用程序开发。自从2002年推出以来,C#已经成为了全球开发者喜爱的编程语言之一。本文将深入解析C#环境,包括其特点、应用场景以及开发环境搭建等。 C#环境概述…...

正交张量、正定张量与材料稳定性:在有限元分析ABAQUS中的实际应用与参数设置
正交张量、正定张量与材料稳定性:在有限元分析ABAQUS中的实际应用与参数设置 当工程师在ABAQUS中遇到材料刚度矩阵非正定警告时,往往意味着仿真结果可能失去物理意义。这种警告背后隐藏着深刻的张量数学原理——正定张量的性质直接决定了材料本构模型的稳…...

华为BGP路由实战:从原理到策略调优的深度解析
1. 华为BGP路由技术入门指南 第一次接触华为BGP路由配置时,我被那些专业术语搞得晕头转向。经过多次实战后才发现,BGP就像互联网世界的邮局系统,负责在不同自治系统(AS)之间传递路由信息。华为设备的BGP实现特别适合企…...

加密货币交易的AI革命:awesome-deep-trading中的区块链量化策略终极指南 [特殊字符]
加密货币交易的AI革命:awesome-deep-trading中的区块链量化策略终极指南 🚀 【免费下载链接】awesome-deep-trading List of awesome resources for machine learning-based algorithmic trading 项目地址: https://gitcode.com/gh_mirrors/aw/awesome…...

Commit Mono版本管理指南:如何优雅地升级和回滚字体版本
Commit Mono版本管理指南:如何优雅地升级和回滚字体版本 【免费下载链接】commit-mono Commit Mono is an anonymous and neutral programming typeface. 项目地址: https://gitcode.com/gh_mirrors/co/commit-mono Commit Mono是一款匿名且中性的编程字体&a…...

ETime:高效推动你的时间
我做了一个开源时间工作台:ETime 如果你也试过很多时间管理工具,可能会遇到同一种疲惫:记录本身变成了另一件需要坚持的事。 ETime 想解决的不是“怎样把每一分钟都管起来”,而是更朴素的一件事:让开始更轻ÿ…...

汤姆供应链
1. 自营中泰专线渠道,泰国曼谷设有清关公司与海外仓,本地团队 24 小时响应;2. 与多家船公司签订特种柜舱位协议,旺季舱位有保障;3. 服务过机械制造、建材、跨境电商等行业客户,累计运输超 1000 票大件设备&…...

双足机器人推进系统建模与系统辨识技术解析
1. 双足机器人推进系统建模与验证概述在机器人动力学控制领域,系统辨识是建立精确数学模型的关键技术。本文以美国东北大学开发的Harpy v2双足机器人为研究对象,重点探讨其集成推进系统的推力与扭矩特性建模方法。这款机器人高约1.2米,重15公…...

普通人如何从零开始搭建自己的AI标题助手?低成本实战指南
就在今天,我刷到了一篇爆文,其标题乃是“用AI制作标题,短短3分钟就能产出100个爆款,而我的阅读量竟翻了5倍之多”,随后我点了进去,看过之后,又将其关掉,此时心里略微有那么点儿不是滋…...