Quivr 基于GPT和开源LLMs构建本地知识库 (更新篇)
一、前言
自从大模型被炒的越来越火之后,似乎国内涌现出很多希望基于大模型构建本地知识库的需求,大概在5月底的时候,当时Quivr发布了第一个0.0.1版本,第一个版本仅仅只是使用LangChain技术结合OpenAI的GPT模型实现了一个最基本的架子,功能并不够完善,但可以研究研究思路,当时 Quivr 通过借助于GPT的模型能力,选择Supabase构建向量数据库来实现个人知识库还算是一个不错的选择,自此一直有在关注 Quivr 的进展,基本上Quivr的更新频率还是比较高的,5月底写了一篇关于如何在本地基于Quivr构建知识库的文章之后,陆陆续续基本上都有一些朋友私聊询问有关Quivr构建的一些问题,也有一些对于Quivr未来功能规划方向的建议和期望,如果Quivr发展的比较成熟,对于个人或者中小企业或许也是一个低成本的选择。
随着这两个多月的更新,Quivr已经陆续发布了五十多个版本,不管是对原来功能的改进,代码的重构,还是扩展了很多新功能,都让Quivr看起来没有原来那么弱小了,基础的功能基本上也覆盖到了。感兴趣的可以尝试一下。
对于原来发布的文章和视频,有感兴趣的可以从下面的链接进去,因为Quivr一直在更新,在部署方面可能有些许变化,如果想部署最新版本的Quivr,可以直接看这篇最新的升级篇即可。
[文章]Quivr 基于Supabase构建本地知识库
[视频]Quivr 基于Supabase构建本地知识库
二、功能特性
2.1、大脑扩展能力
从单个账号只支持一个大脑,到现在可以支持多个大脑(具体数量可以配置,默认为5个),这样部署一套Quivr系统就可以创建多个大脑来对知识库进行分开维护,减少数据的检索范围和数据权限隔离。
用户可以根据偏好来自定义知识库,比如针对产品的智能客服、针对交付的Q&A助理、产品经理助手等等。
2.2、大脑权限控制
支持对单个知识库根据[浏览]、[编辑]、[所有者]三个角色来设置对应的访问权限,同时也支持通过链接和邮件的方式分享个人大脑给其他用户。
这样就可以很方便的实现个人私有知识库,或者是公司团队共享的知识库,而避免了以前每个用户都需要重复上传相同的知识,导致Key的浪费和知识的冗余。
2.3、LLM扩展能力
原来的版本只支持集成GPT和Claude模型,现在扩展了对本地开源模型的支持,如GPT4All,后续还将支持更多的开源模型。
2.4、开放API接口
Quivr采用前后端分离的独立架构,Quivr 使用 FastAPI 为后端提供 RESTful API,后端服务可以独立使用,不需要前端应用程序,我们的第三方应用也可以很方便的通过API接口集成Quivr大脑的我们自己的产品中
三、基础环境准备
3.1、先决条件
为了减少部署过程中不必要的麻烦,建议操作系统选择Ubuntu 22或更高版本,至于服务器只要能正常访问OpenAI的接口都可以,我在GCP/AWS/阿里云上都安装过,主要解决网络问题,选对服务器所在区域即可。
系统内存:如果只是个人用来部署玩一下,建议不少于1GB,2GB比较合适,如果想用于正式环境,则需根据具体的业务访问量配置。
系统硬盘:仅仅部署演示,建议不少于30GB。
接下来将演示在 Ubuntu 22 版本上快速部署Quivr来构建本地知识库系统。
3.2、安装Docker & Docker-Compose
首先安装 Docker 和 Docker Compose ,可以按照以下步骤进行操作:
1、更新系统软件包列表:
sudo apt update
2、安装Docker依赖的软件包:
sudo apt install apt-transport-https ca-certificates curl software-properties-common
3、添加Docker官方的GPG密钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
4、添加Docker的软件源:
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
5、更新软件包列表:
sudo apt update
6、安装Docker Engine:
sudo apt install docker-ce docker-ce-cli containerd.io
7、验证Docker是否正确安装:
sudo docker run hello-world
8、安装Docker Compose:
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
9、添加执行权限:
sudo chmod +x /usr/local/bin/docker-compose
10、验证Docker Compose是否正确安装:
docker-compose --version
现在,您已经成功在Ubuntu上安装了Docker和Docker Compose。您可以使用这些命令来管理和运行容器化的应用程序。
错误:failed to update store for object type *libnetwork.endpointCnt: Key not found in store
Restart docker deamon would fix it.For ubuntu:sudo service docker restart
四、创建Supabase项目
Supabase是一个开源的Firebase替代品。使用 Postgres 数据库、身份验证、即时 API、边缘函数、实时订阅、存储和向量嵌入。一个免费账户可以创建2个项目。
1、注册账户
前往https://supabase.com/可以注册免费账户。
2、创建项目

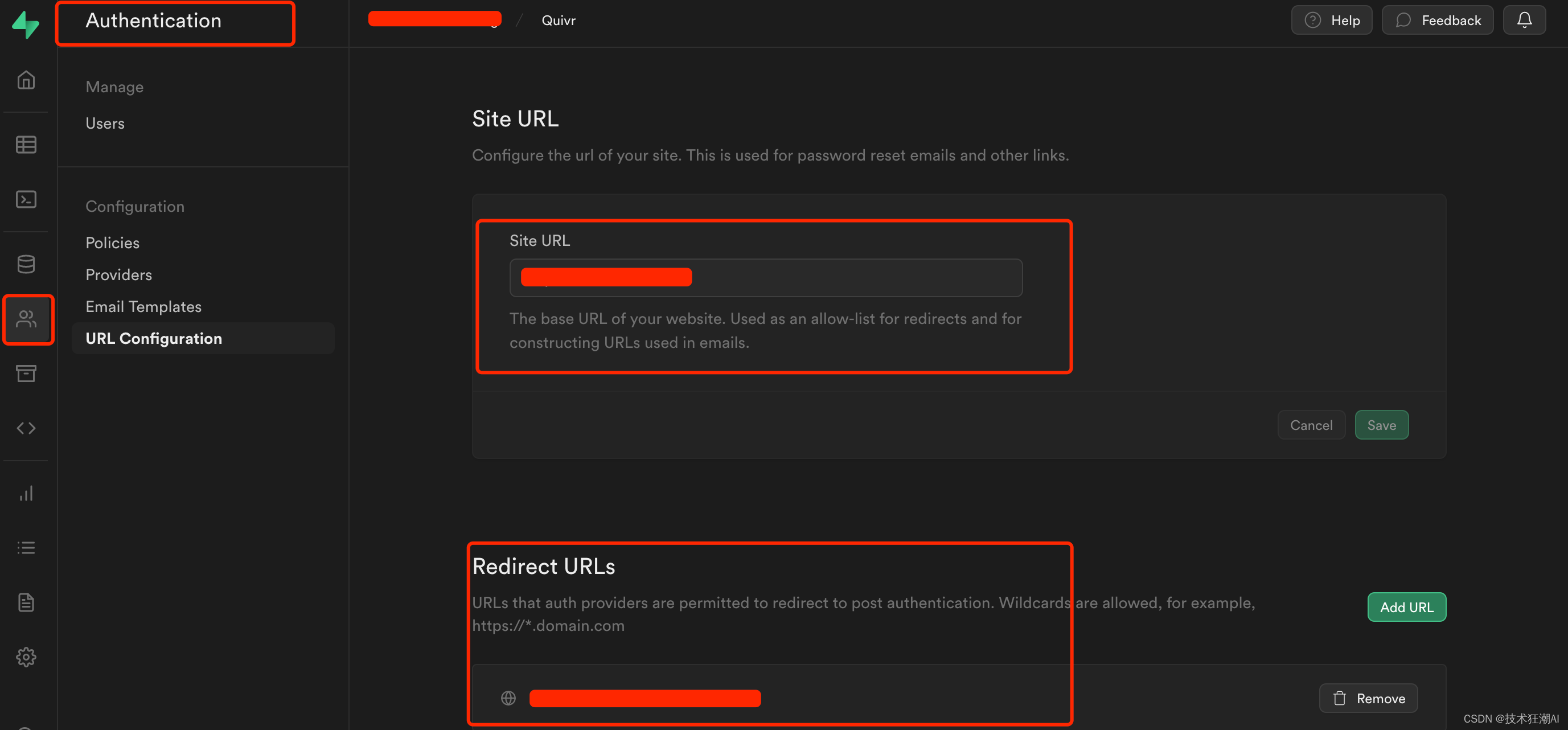
3、配置网站URL和重定向地址
主要用于密码重置和电子邮件重定向跳转链接。地址为系统前端访问地址:http://ip:3000
五、部署Quivr应用
5.1、克隆存储库
git clone https://github.com/StanGirard/Quivr.git && cd Quivr
- 可以使用 ls -alh 命令查看所有文件(包含隐藏文件)
一般Quivr每周都会在主分支更新新的内容,会存在一定未知的bug,建议选择一个最新的release稳定版本进行部署

5.2、复制.XXXXX_env文件
新版本后端代码重构了,新的配置文件注意在backend/core/目录下面。
cp .backend_env.example backend/core/.env
cp .frontend_env.example frontend/.env
5.3、更新frontend/.env文件
NEXT_PUBLIC_ENV=local
NEXT_PUBLIC_BACKEND_URL=http://你的IP:5050/
NEXT_PUBLIC_SUPABASE_URL=your supabase project url
NEXT_PUBLIC_SUPABASE_ANON_KEY=your supabase api key
NEXT_PUBLIC_JUNE_API_KEY=your june api key请注意,如果Quivr部署在本机电脑,backend_url直接使用localhost,如果Quivr部署在本地服务器或者云服务器则需要将后端URL修改为你服务器的实际的IP地址。(很多人会忽略这个配置!)
关于NEXT_PUBLIC_JUNE_API_KEY属性的配置说明:
Quivr 集成了 June Analytics 提供的API接口,在集成了June Analytics 之后,你只需要在系统中配置正确的June API密钥(即June key),然后June网站会自动开始收集和跟踪系统的数据。
一旦数据开始被收集,你可以登录到June Analytics的仪表板,并在其中查看和分析收集到的数据。June仪表板提供了一个用户友好的界面,用于浏览各种报告、图表和指标,以便你了解用户行为、事件触发和其他关键指标。
通过June仪表板,你可以探索不同的分析视图,如用户活动、事件追踪、转化率等。你可以根据时间范围、特定用户或自定义事件来过滤和细化数据,以获取更具体的见解和洞察。
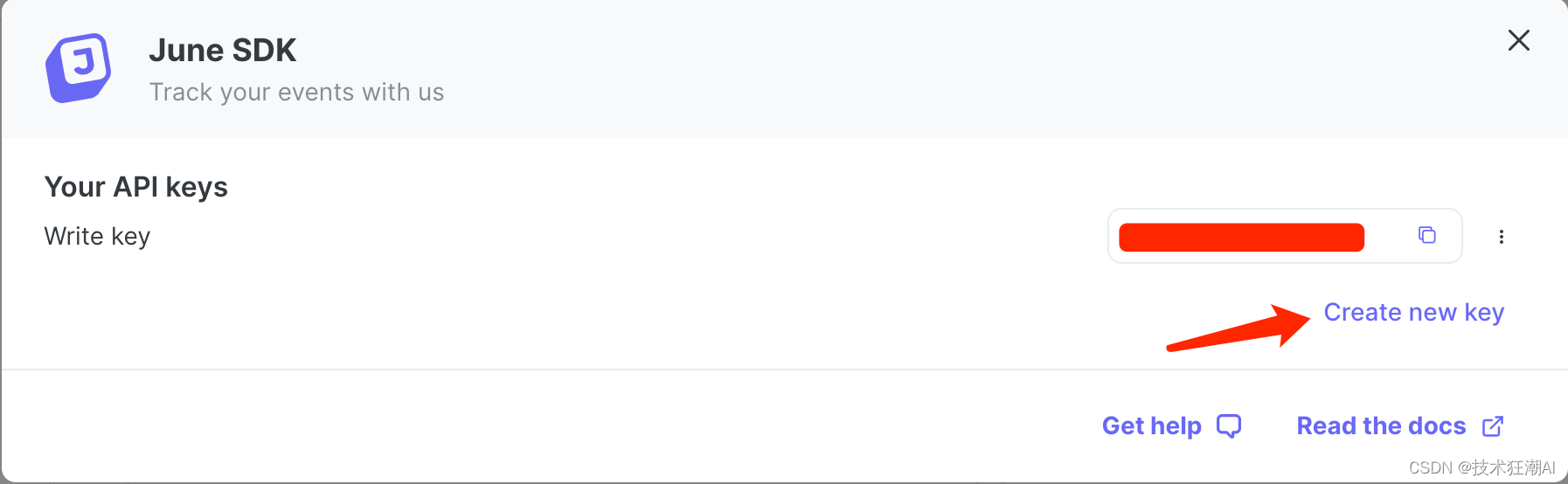
如果是正式上线的站点,可以按需选择接入,默认可以不用考虑设置此参数,如果需要收集和分析网站的数据,可以去注册June账号,申请一个June Key:
 5.4、更新backend/core/.env文件
5.4、更新backend/core/.env文件
SUPABASE_URL=your supabase project url
SUPABASE_SERVICE_KEY=your supabase api key
PG_DATABASE_URL=notimplementedyet
OPENAI_API_KEY=your openai api key
ANTHROPIC_API_KEY=null
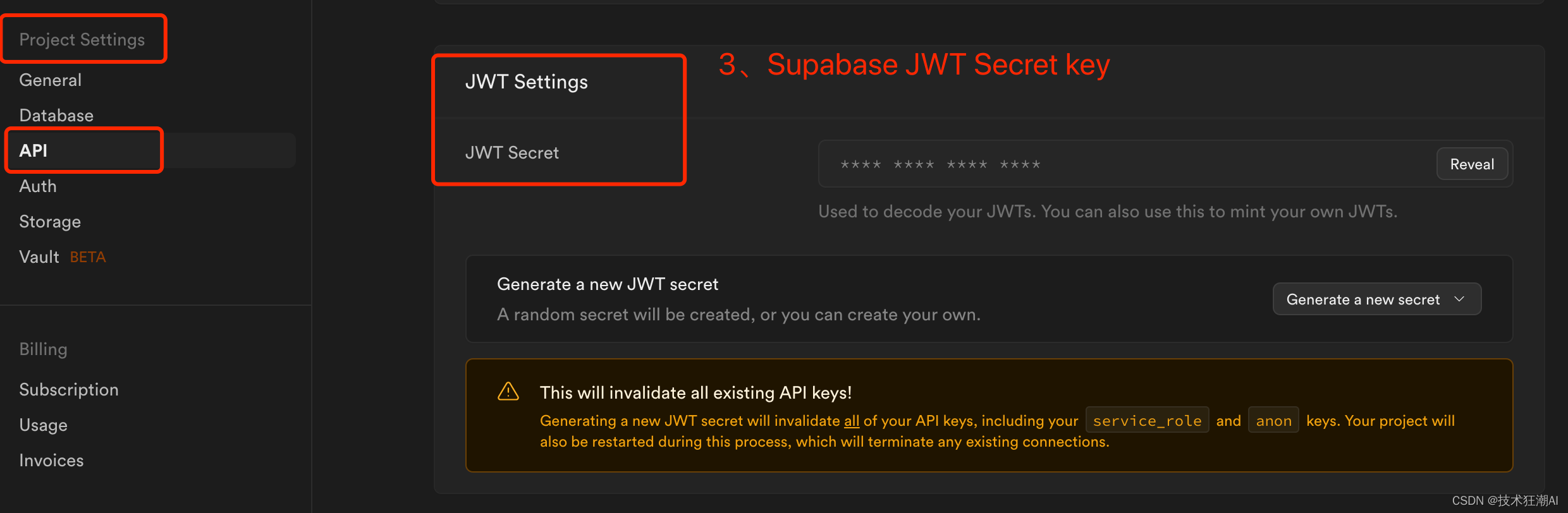
JWT_SECRET_KEY=your supabase jwt secret keyAUTHENTICATE=true
GOOGLE_APPLICATION_CREDENTIALS=<change-me>
GOOGLE_CLOUD_PROJECT=<change-me># 默认50M
MAX_BRAIN_SIZE=52428800.
MAX_REQUESTS_NUMBER=2000
MAX_BRAIN_PER_USER=100# Private LLM Variables
PRIVATE=False
MODEL_PATH=./local_models/ggml-gpt4all-j-v1.3-groovy.bin# RESEND
RESEND_API_KEY=your resend api key
RESEND_EMAIL_ADDRESS=your resend email address请注意,supabase_url在您的Supabase仪表板下的项目设置-> API中对应的Project URL,supabase_service_key在您的Supabase仪表板下的项目设置-> API中找到。使用“Project API keys”部分中找到的anon public键。您 JWT_SECRET_KEY可以在 Project Settings -> JWT Settings -> JWT Secret 下的 supabase 设置中找到。(注意ANTHROPIC_API_KEY可以不配置值,但key不能删除,否则构建会失败)

5.5、创建Supabase数据库和表
通过Web界面(SQL编辑器->“New Query”)在Supabase数据库上运行以下迁移脚本。
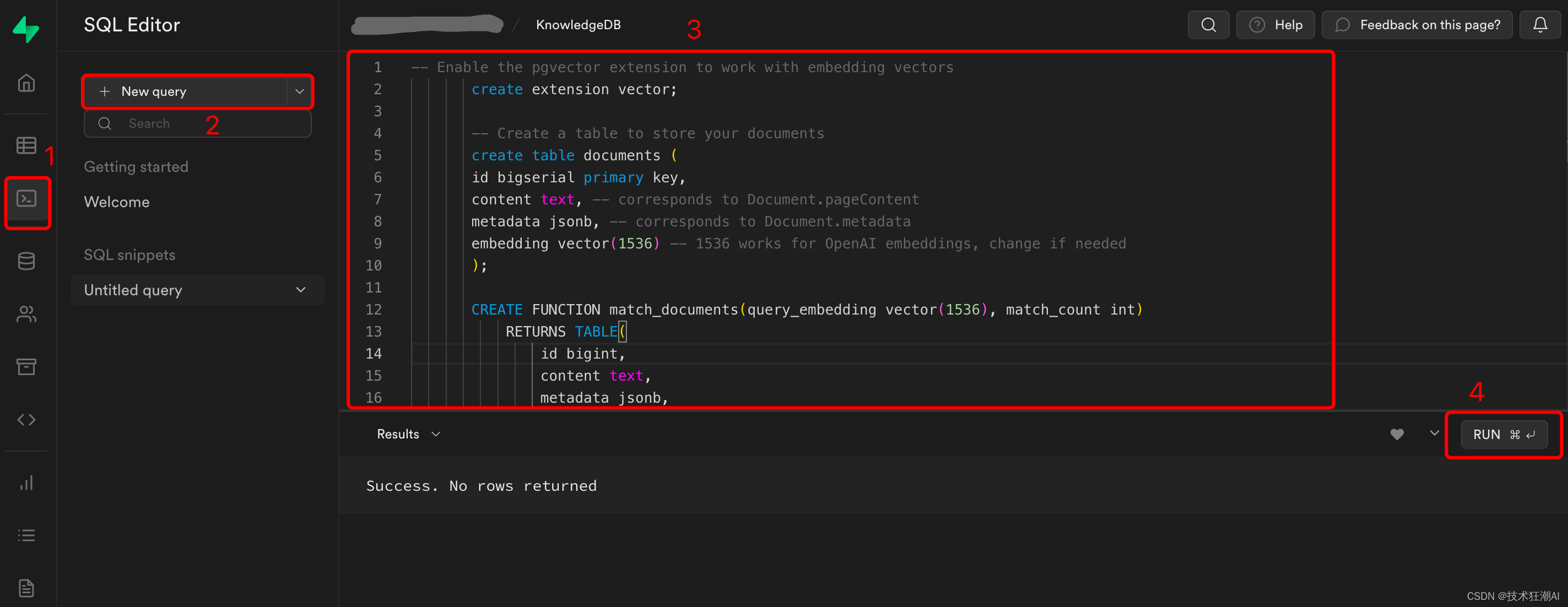
数据库脚本地址:
https://github.com/StanGirard/quivr/blob/main/scripts/tables.sql
-- Create users table
CREATE TABLE IF NOT EXISTS users(user_id UUID REFERENCES auth.users (id),email TEXT,date TEXT,requests_count INT,PRIMARY KEY (user_id, date)
);-- Create chats table
CREATE TABLE IF NOT EXISTS chats(chat_id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,user_id UUID REFERENCES auth.users (id),creation_time TIMESTAMP DEFAULT current_timestamp,history JSONB,chat_name TEXT
);-- Create vector extension
CREATE EXTENSION IF NOT EXISTS vector;-- Create vectors table
CREATE TABLE IF NOT EXISTS vectors (id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,content TEXT,metadata JSONB,embedding VECTOR(1536)
);-- Create function to match vectors
CREATE OR REPLACE FUNCTION match_vectors(query_embedding VECTOR(1536), match_count INT, p_brain_id UUID)
RETURNS TABLE(id UUID,brain_id UUID,content TEXT,metadata JSONB,embedding VECTOR(1536),similarity FLOAT
) LANGUAGE plpgsql AS $$
#variable_conflict use_column
BEGINRETURN QUERYSELECTvectors.id,brains_vectors.brain_id,vectors.content,vectors.metadata,vectors.embedding,1 - (vectors.embedding <=> query_embedding) AS similarityFROMvectorsINNER JOINbrains_vectors ON vectors.id = brains_vectors.vector_idWHERE brains_vectors.brain_id = p_brain_idORDER BYvectors.embedding <=> query_embeddingLIMIT match_count;
END;
$$;-- Create stats table
CREATE TABLE IF NOT EXISTS stats (time TIMESTAMP,chat BOOLEAN,embedding BOOLEAN,details TEXT,metadata JSONB,id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY
);-- Create summaries table
CREATE TABLE IF NOT EXISTS summaries (id BIGSERIAL PRIMARY KEY,document_id UUID REFERENCES vectors(id),content TEXT,metadata JSONB,embedding VECTOR(1536)
);-- Create function to match summaries
CREATE OR REPLACE FUNCTION match_summaries(query_embedding VECTOR(1536), match_count INT, match_threshold FLOAT)
RETURNS TABLE(id BIGINT,document_id UUID,content TEXT,metadata JSONB,embedding VECTOR(1536),similarity FLOAT
) LANGUAGE plpgsql AS $$
#variable_conflict use_column
BEGINRETURN QUERYSELECTid,document_id,content,metadata,embedding,1 - (summaries.embedding <=> query_embedding) AS similarityFROMsummariesWHERE 1 - (summaries.embedding <=> query_embedding) > match_thresholdORDER BYsummaries.embedding <=> query_embeddingLIMIT match_count;
END;
$$;-- Create api_keys table
CREATE TABLE IF NOT EXISTS api_keys(key_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,user_id UUID REFERENCES auth.users (id),api_key TEXT UNIQUE,creation_time TIMESTAMP DEFAULT current_timestamp,deleted_time TIMESTAMP,is_active BOOLEAN DEFAULT true
);--- Create prompts table
CREATE TABLE IF NOT EXISTS prompts (id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,title VARCHAR(255),content TEXT,status VARCHAR(255) DEFAULT 'private'
);--- Create brains table
CREATE TABLE IF NOT EXISTS brains (brain_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,name TEXT NOT NULL,status TEXT,description TEXT,model TEXT,max_tokens INT,temperature FLOAT,openai_api_key TEXT,prompt_id UUID REFERENCES prompts(id)
);-- Create chat_history table
CREATE TABLE IF NOT EXISTS chat_history (message_id UUID DEFAULT uuid_generate_v4(),chat_id UUID REFERENCES chats(chat_id),user_message TEXT,assistant TEXT,message_time TIMESTAMP DEFAULT current_timestamp,PRIMARY KEY (chat_id, message_id),prompt_id UUID REFERENCES prompts(id),brain_id UUID REFERENCES brains(brain_id)
);-- Create brains X users table
CREATE TABLE IF NOT EXISTS brains_users (brain_id UUID,user_id UUID,rights VARCHAR(255),default_brain BOOLEAN DEFAULT false,PRIMARY KEY (brain_id, user_id),FOREIGN KEY (user_id) REFERENCES auth.users (id),FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
);-- Create brains X vectors table
CREATE TABLE IF NOT EXISTS brains_vectors (brain_id UUID,vector_id UUID,file_sha1 TEXT,PRIMARY KEY (brain_id, vector_id),FOREIGN KEY (vector_id) REFERENCES vectors (id),FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
);-- Create brains X vectors table
CREATE TABLE IF NOT EXISTS brain_subscription_invitations (brain_id UUID,email VARCHAR(255),rights VARCHAR(255),PRIMARY KEY (brain_id, email),FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
);--- Create user_identity table
CREATE TABLE IF NOT EXISTS user_identity (user_id UUID PRIMARY KEY,openai_api_key VARCHAR(255)
);CREATE OR REPLACE FUNCTION public.get_user_email_by_user_id(user_id uuid)
RETURNS TABLE (email text)
SECURITY definer
AS $$
BEGINRETURN QUERY SELECT au.email::text FROM auth.users au WHERE au.id = user_id;
END;
$$ LANGUAGE plpgsql;CREATE OR REPLACE FUNCTION public.get_user_id_by_user_email(user_email text)
RETURNS TABLE (user_id uuid)
SECURITY DEFINER
AS $$
BEGINRETURN QUERY SELECT au.id::uuid FROM auth.users au WHERE au.email = user_email;
END;
$$ LANGUAGE plpgsql;CREATE TABLE IF NOT EXISTS migrations (name VARCHAR(255) PRIMARY KEY,executed_at TIMESTAMPTZ DEFAULT current_timestamp
);INSERT INTO migrations (name)
SELECT '20230809154300_add_prompt_id_brain_id_to_chat_history_table'
WHERE NOT EXISTS (SELECT 1 FROM migrations WHERE name = '20230809154300_add_prompt_id_brain_id_to_chat_history_table'
);数据库脚本执行完成后,在Table编辑器中可以看到已经创建完成的表。

5.6、设置yarn的超时时间
在前端容器构建依赖阶段一般会比较慢,部分依赖可能由于网络原因长时间无法完成会导致yarn连接超时,旧版本可以在/frontend/Dockerfile文件中修改yarn install部分的脚本,增加网络超时参数,新版本已增加该参数可忽略此步骤。
RUN yarn install --network-timeout 1000000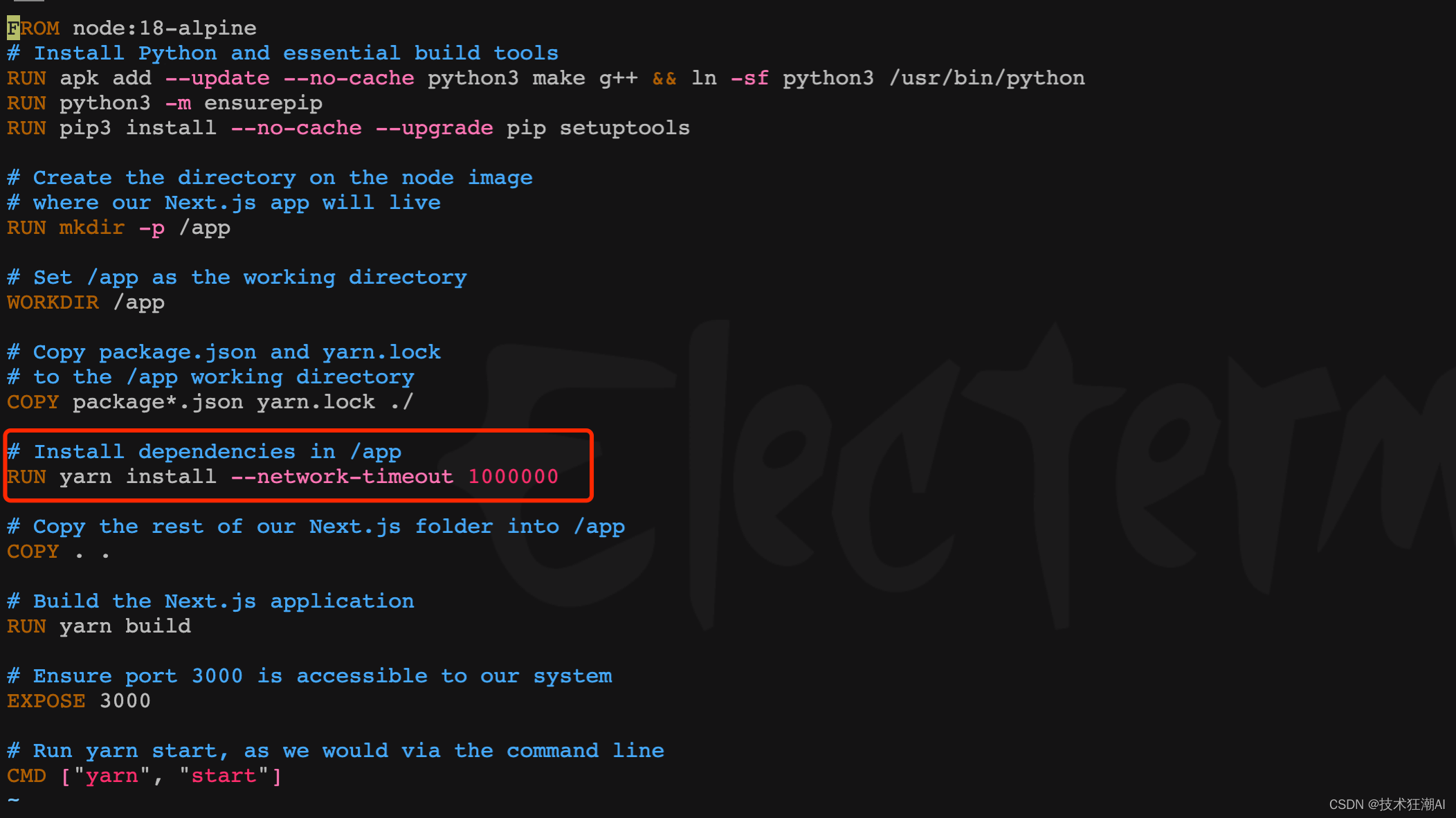
5.7、构建并启动Quivr
docker compose -f docker-compose.yml up --build -dQuivr构建完成启动后如下图所示:

六、访问Quivr
部署完成后,直接访问 http://ip:3000,第一次部署可以通过邮箱注册账号
6.1、添加新大脑
Quivr 有一个“大脑”的概念。它们是封闭的信息体,可用于为大型语言模型 (LLM) 提供上下文,以回答有关特定主题的问题。
LLM接受过各种各样的数据培训,但要回答有关特定主题的问题或用于围绕特定主题进行推论,需要向他们提供该主题的上下文。Quivr 使用大脑作为提供上下文的直观方式。
当在 Quivr 中选择大脑时,LLM将仅获得该大脑的上下文。这允许用户为特定主题构建大脑,然后用它们来回答有关该主题的问题。未来 Quivr 将会有与其他用户共享大脑的功能。
在Quivr新版本中,可以支持创新多个知识库大脑,实现知识库的内容检索隔离,同时还支持对支持库进行授权,只允许授权用户才能访问,也可以通过分享链接的方式共享知识库。比几个月前的版本功能更加完善。
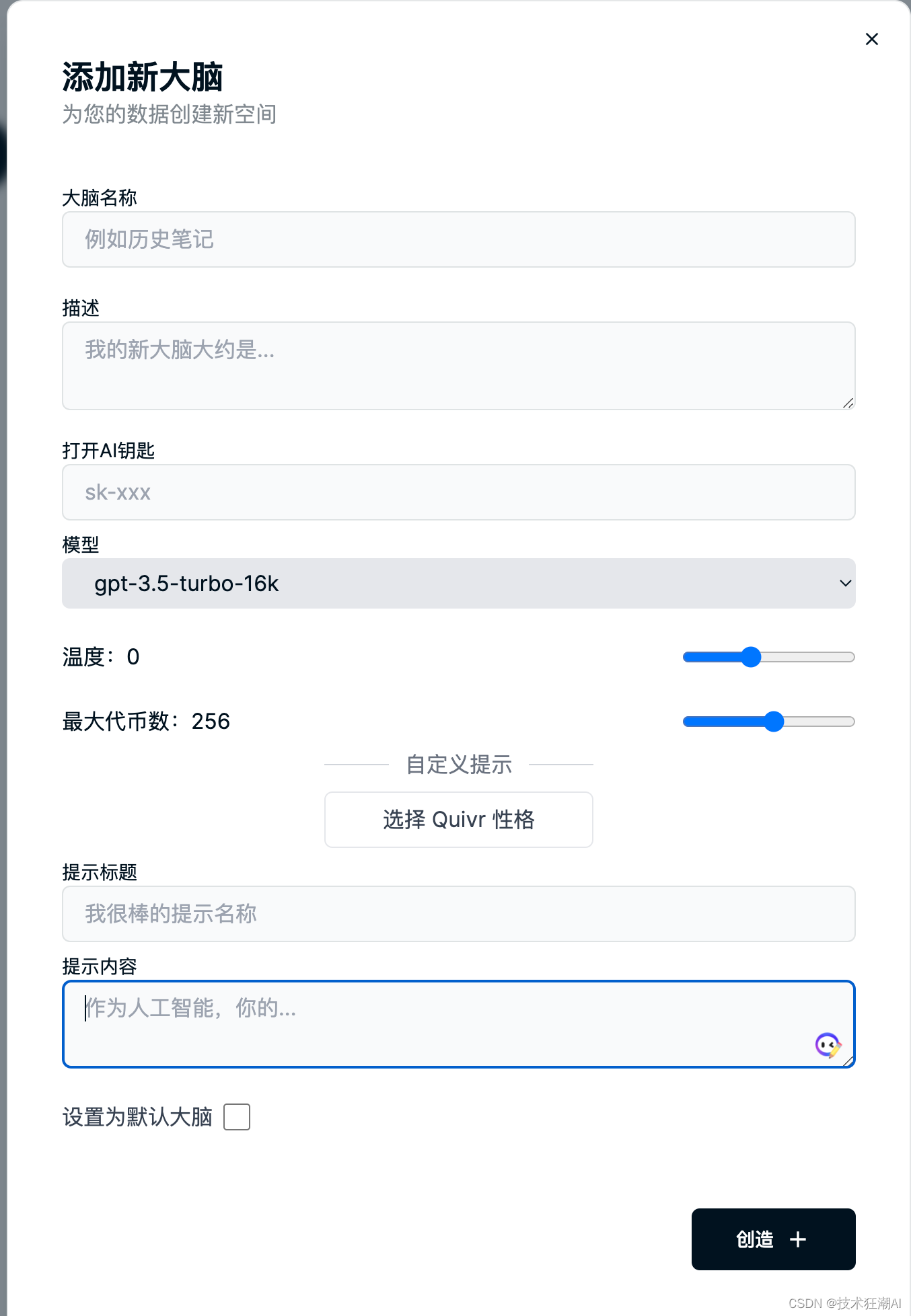
1)、要使用大脑,只需从 Quivr 界面右上角标题中的“使用大脑”图标中选择菜单即可。
2)、我们可以通过单击“创建大脑”按钮来创建一个新的大脑。系统将提示您输入大脑的名称。你也可以使用账户生成的默认大脑。
3)、要切换到不同的大脑,只需单击菜单中的大脑名称并选择您想要使用的大脑即可。
4)、如果你没有选择大脑,则你上传的任何文档都将添加到默认大脑中。
5)、在新建大脑知识库界面中,可以设置使用的模型和模型相关参数,同时也可以针对每个知识库大脑设置独有的Prompt以及所使用的OpenAI API Key,不设置则默认读取配置文件中配置的Key。
注意:如果在使用聊天功能时,需要从菜单中先选择一个大脑才能使用聊天功能。
6.2、共享知识库
在选择大脑界面,我们点击大脑后面的分享按钮,通过URL或者发邮件的方式分享或者邀请其它用户加入大脑,共享知识库。
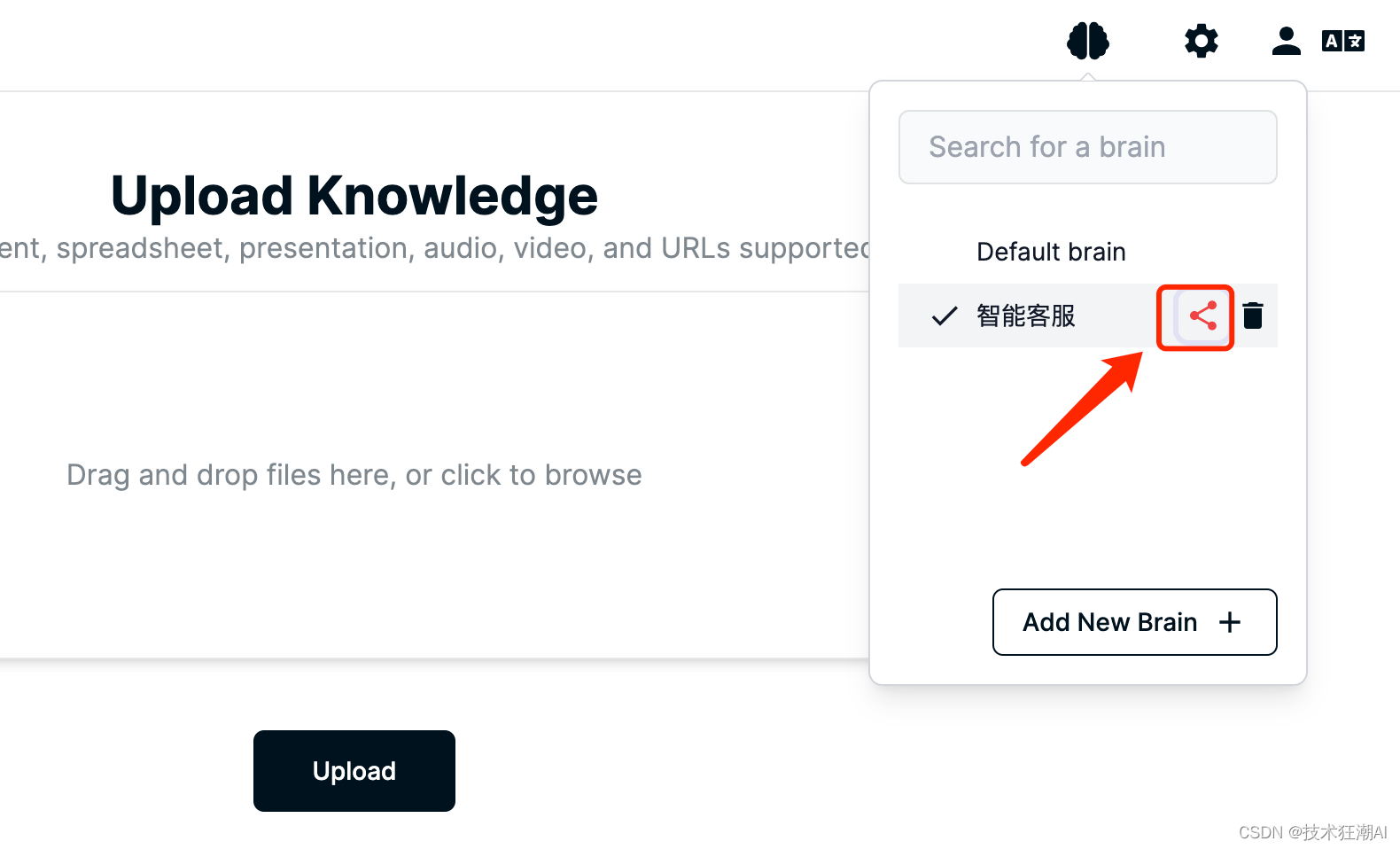

Quivr 中通过集成 Resend API,用于通过电子邮件邀请来处理共享大脑。
在 /backend/core/.env 文件中引入了两个环境变量来配置发送邮件的功能:
-
RESENDAPIKEY:这是 Resend 为我们的应用程序提供的唯一 API 密钥。它使我们能够以安全的方式与 Resend 平台进行通信。
-
RESENDEMAILADDRESS:这是我们通过重新发送发送电子邮件时用作发件人地址的电子邮件地址。
从环境变量中获取 Resend API 密钥和电子邮件地址后,我们使用它通过 resend.Emails.send 方法发送电子邮件。
6.2、上传知识库
新建完知识库大脑后,就可以选择对应的知识库,上传文档构建向量数据了,支持文档、音频、视频和网页链接,所有文件最终都会抽取文件中的文本内容通过调用大模型的API构建向量数据。
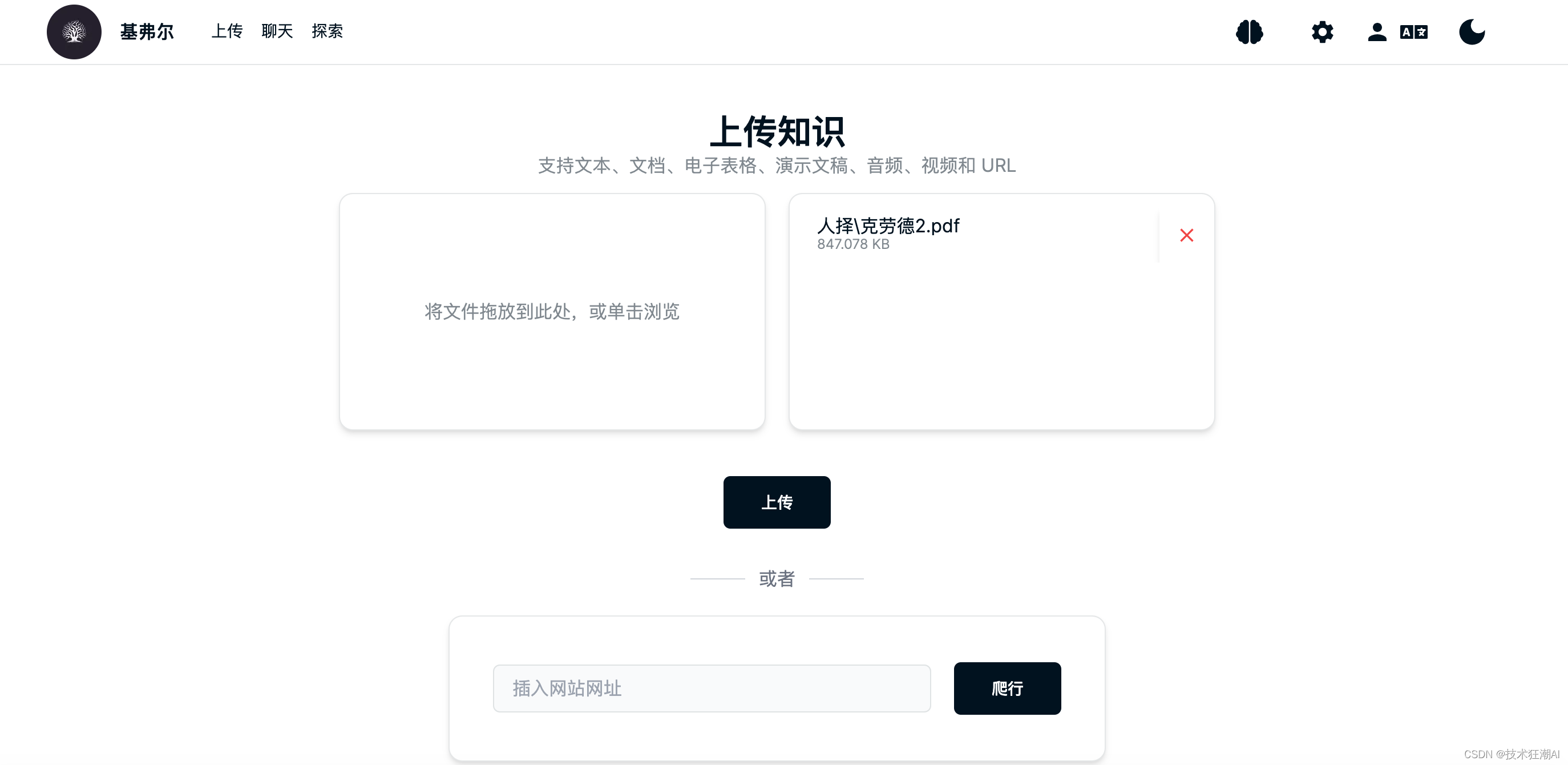
文件上传完成后,会有如下提示信息

6.3、查询知识库
知识库文档构建完成后,就可以对当前选择的知识库大脑进行内容检索了,这里我们以鲁迅先生在日本留学的老师藤野先生为例来测试一下Quivr是否正确识别了知识库文档的内容。 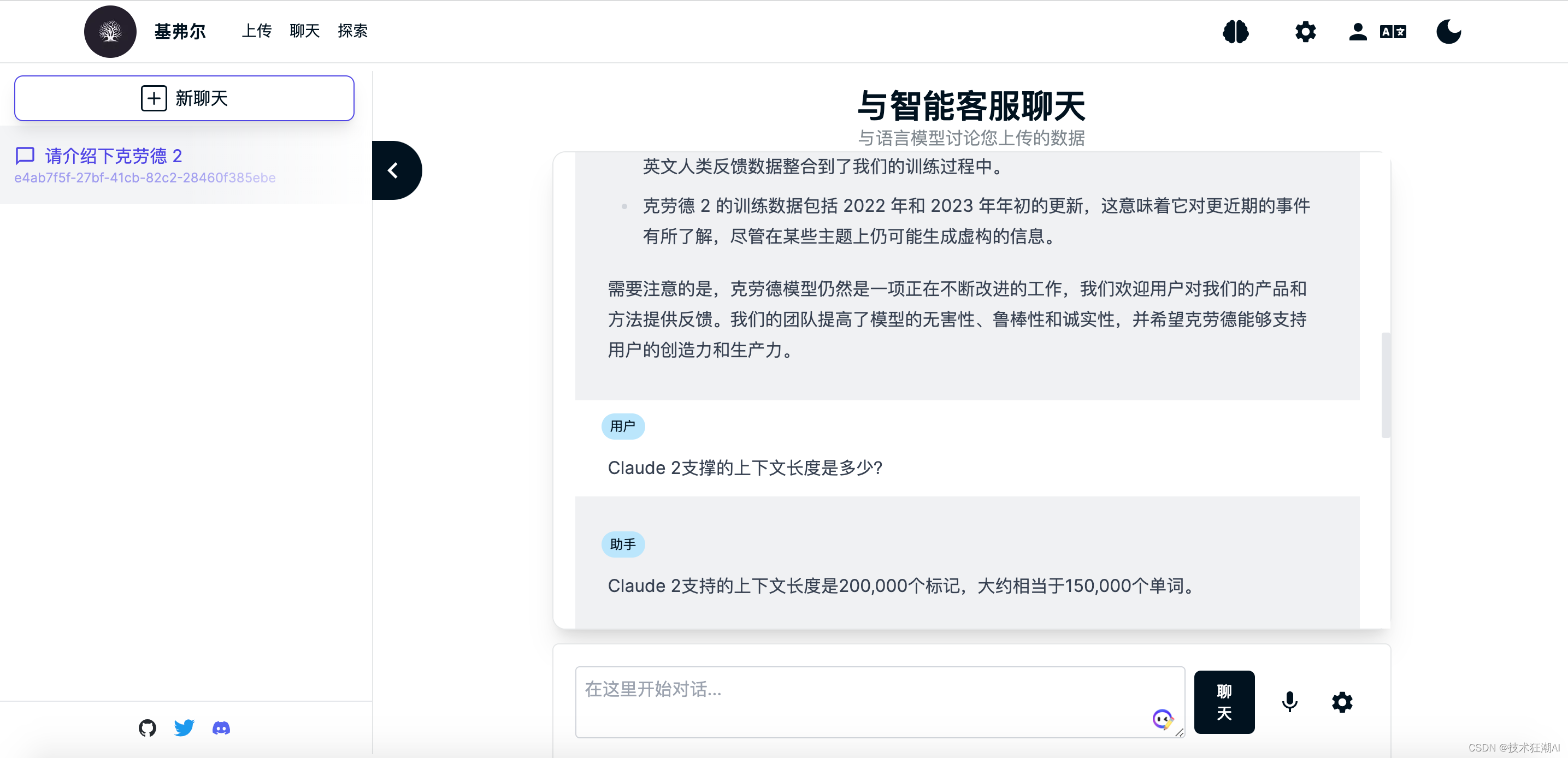
在没学习专有知识之前,GPT模型不知道鲁迅先生在日本学医的老师是谁,一般会胡乱给出一个日本人的名字,而且多次询问,人命还不一致。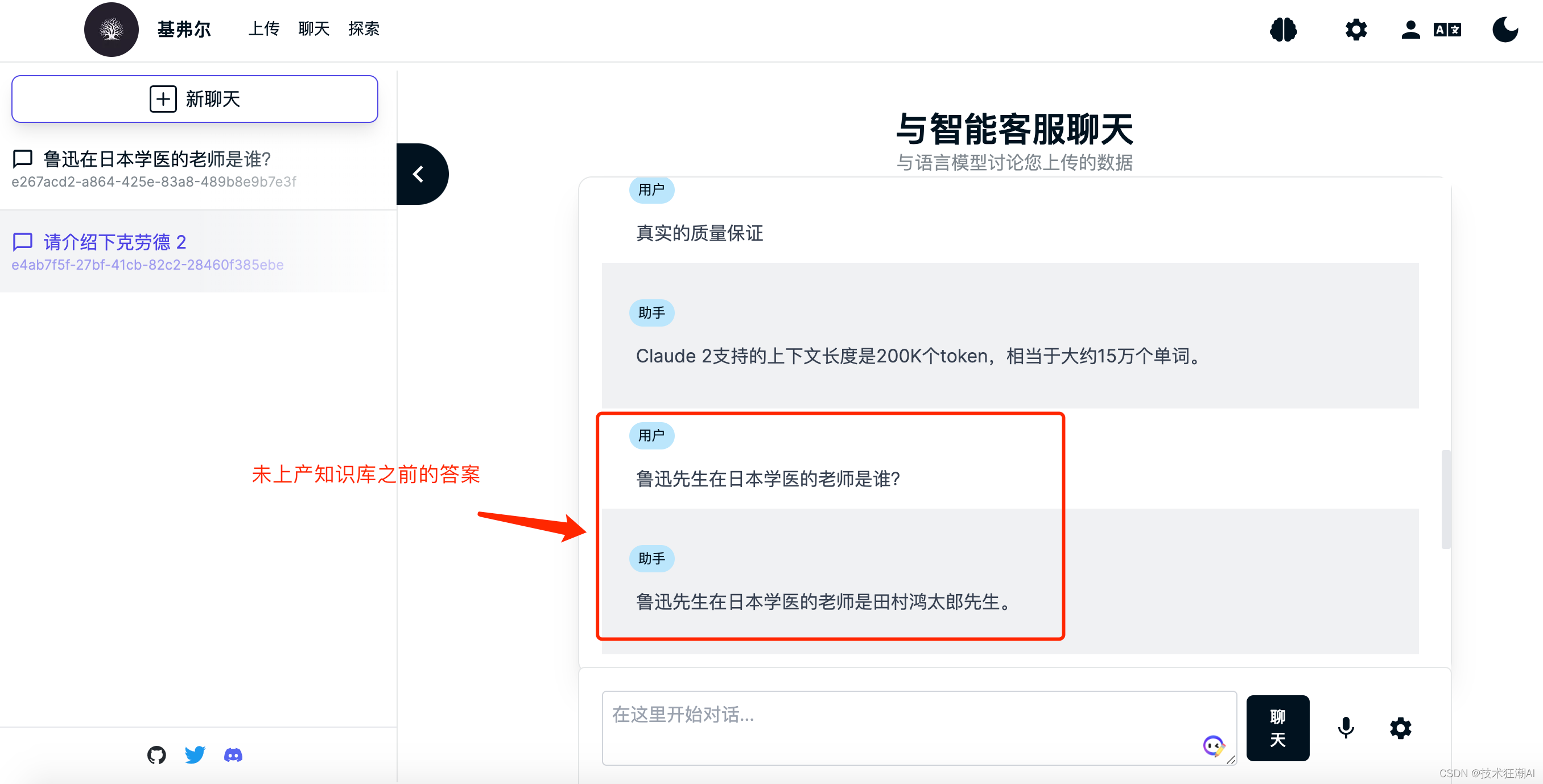 在上传完关于鲁迅先生写的《藤野先生》部分文章内容之后,我们再次询问发现可以成功检索正确的答案了。
在上传完关于鲁迅先生写的《藤野先生》部分文章内容之后,我们再次询问发现可以成功检索正确的答案了。 
七、本地化LLM支持
Quivr 在0.0.46版本可以正式支持接入本地LLM大模型,目前只支持由 GPT4All 提供支持的私有 LLM 模型(其他开源模型即将推出),基本上与 PrivateGPT 项目提供的功能类似。意味着你的数据永远存储在本地。LLM 将下载到服务器并在本地对你的问题运行推理。
7.1、使用方法
-
在 /backend/core/.env 文件中将“private”属性设置为 True。您还可以在 .env 文件中设置其他模型参数。
-
GPT4All 模型下载地址:https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin
将下载的 GPT4All 模型放在 /backend/local_models 文件夹中。
GPT4All 是一个开源软件生态系统,允许任何人在日常硬件上训练和部署强大且定制的大型语言模型 (LLM)。 Nomic AI 负责监督对开源生态系统的贡献,确保质量、安全性和可维护性。
GPT4All 软件生态系统与以下 Transformer 架构兼容:
-
Falcon -
LLaMA(includingOpenLLaMA) -
MPT(includingReplit) -
GPT-J -
Replit - 基于 Replit Inc. 的 Replit 架构
-
StarCoder - 基于 BigCode 的 StarCoder 架构
具体支持的模型型号列表可以从 GPT4All 的网站上查看详尽列表,或下载任何支持的模型。使用这些架构之一训练的任何模型都可以量化,并使用所有 GPT4All 绑定在本地运行,并在聊天客户端。您可以通过为 gpt4all 后端做出贡献来添加新变体。
7.2、未来计划
Quivr 计划在本地私有化 LLM 功能中添加更多模型。使用 Hugging Face 的本地嵌入模型来减少对 OpenAI API 的依赖。未来还将添加在前端和 API 中使用私有 LLM 模型的功能。目前的版本只有部署后端才能使用。
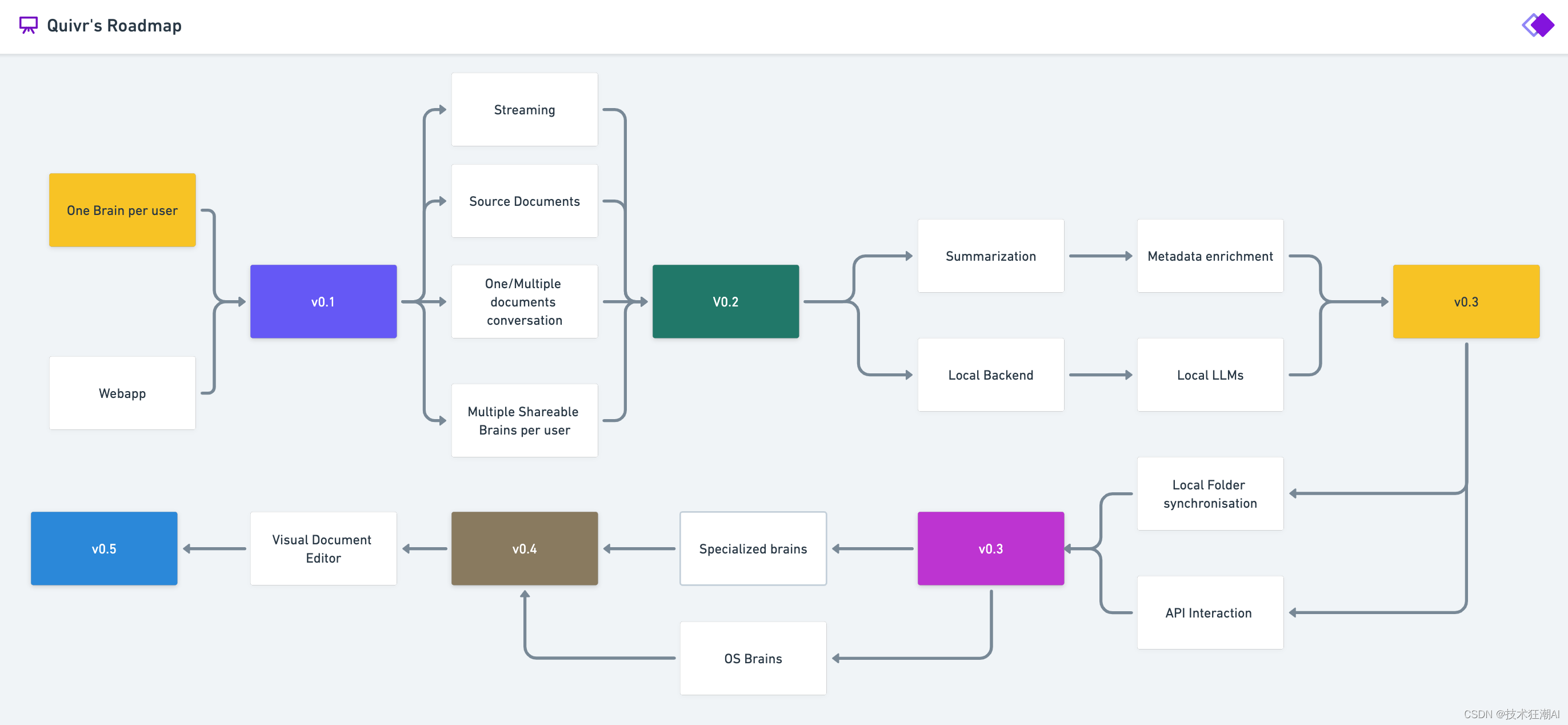
八、Quivr路线图
九、References
- Quivr GitHub
https://github.com/StanGirard/quivr
- Quivr FastAPI
https://api.quivr.app/docs
- Resend API
https://resend.com/overview
- June Analytics
https://analytics.june.so/
- GPT4All WebSite
https://gpt4all.io/index.html
- GPT4All Models
https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin
- GPT4All Supported Models
https://raw.githubusercontent.com/nomic-ai/gpt4all/main/gpt4all-chat/metadata/models.json
相关文章:
Quivr 基于GPT和开源LLMs构建本地知识库 (更新篇)
一、前言 自从大模型被炒的越来越火之后,似乎国内涌现出很多希望基于大模型构建本地知识库的需求,大概在5月底的时候,当时Quivr发布了第一个0.0.1版本,第一个版本仅仅只是使用LangChain技术结合OpenAI的GPT模型实现了一个最基本的…...

Unity如何制作声音控制条(控制音量大小)
一:UGUI制作 1. 首先在【层级】下面创建UI里面的Slider组件。设置好它对应的宽度和高度。 2.调整Slider滑动条的填充颜色。一般声音颜色我黄色,所以我们也调成黄色。 我们尝试滑动Slider里面的value。 a.滑动前。 b.滑动一半。 c.滑动完。 从以上滑动va…...

非计算机科班如何顺利转行计算机领域?
文章目录 每日一句正能量前言如何规划才能实现转计算机?计算机岗位发展前景?现阶段转计算机的建议后记 每日一句正能量 改变思路,改变习惯,改变一种活的方式,往往会创造无限,风景无限! 前言 近年…...
Android音视频剪辑器自定义View实战!
Android音视频剪辑器自定义View实战! - 掘金 /*** Created by zhouxuming on 2023/3/30** descr 音视频剪辑器*/ public class AudioViewEditor extends View {//进度文本显示格式-数字格式public static final int HINT_FORMAT_NUMBER 0;//进度文本显示格式-时间…...

stm32_ADC电源、通道、工作模式
0、ADC功能框图 1、ADC的电源 1.1、工作电源 VSSAVSS,VDDAVDD,简单来说,通常stm32是3.3V,ADC的工作电源也是3.3V; 1.2、参考电压 VREF和VREF-并不一定引出,取决于封装,如果没有引出则VREF连接到…...

Vue编程式路由导航
目录 一、使用 一、使用 不使用<router-link>标签,利用$router中的api实现跳转,更灵活 <template><div><ul><li v-for"m in messageList" :key"m.id"><!-- 跳转路由并携带params参数,…...

LVS-DR模式
目录 1、概述 2、LVS-DR模式的工作原理: 3、在LVS-DR模式下,数据包的流向分析如下: 4、LVS-DR是一种用于构建高可用性负载均衡集群的技术模式。LVS-DR模式具有以下特点: 5、LVS-DR中的ARP问题 6、配置LVS-DR需要以下几个关键…...
 的原理和基于Pytorch源码的实现)
详细介绍生成对抗网络 (GAN) 的原理和基于Pytorch源码的实现
介绍 GAN 是一种使用 CNN(卷积神经网络)等深度学习方法进行生成建模的方法。生成建模是一种无监督学习方法,涉及自动发现和学习输入数据中的模式,以便该模型可用于从原始数据集中生成新示例。 GAN 是一种通过将问题构建为具有两个子模型的监督学习问题来训练生成模型的方…...

高性能数据处理选型
1、Redis(高性能) 2、Elasticsearch/HBase( 大数据 ) 3、MongoDB(海量数据)...

【深入理解C语言】-- 关键字2
🐇 🔥博客主页: 云曦 📋系列专栏:深入理解C语言 💨吾生也有涯,而知也无涯 💛 感谢大家👍点赞 😋关注📝评论 文章目录 前言一、关键字 - static&…...
Java进阶(3)——手动实现ArrayList 源码的初步理解分析 数组插入数据和删除数据的问题
目录 引出手动实现ArrayList定义接口MyList<T>写ArrayList的实现类增加元素删除元素 写测试类进行测试数组插入数据? 总结 引出 1.ArrayList的结构分析,可迭代接口,是List的实现; 2.数组增加元素和删除元素的分析,何时扩容…...

若依前端npm run dev启动时报错
本文主要解决问题:若依前端npm run dev启动时报错,解决办法。 目录 1、第1种解决方案(亲测有效) 2、第2种解决方案(亲测有效) Error: error:0308010C:digital envelope routines::unsupportedat new Hash (node:internal/crypto/hash:67:19)at Object.createHash (node…...
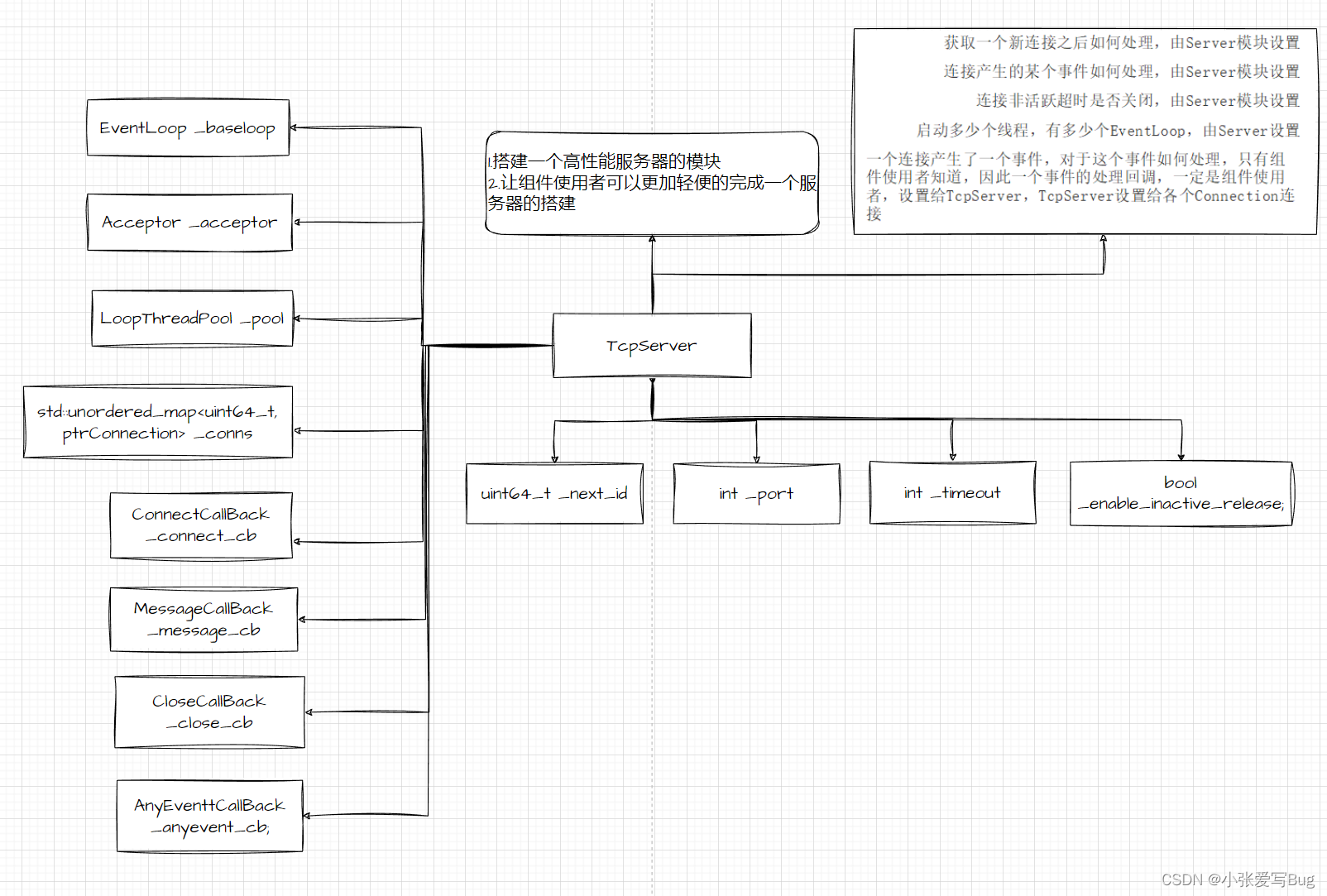
实战项目:基于主从Reactor模型实现高并发服务器
项目完整代码仿mudou库one thread one loop式并发服务器实现: 仿muduo库One Thread One Loop式主从Reactor模型实现⾼并发服务器:通过模拟实现的⾼并发服务器组件,可以简洁快速的完成⼀个⾼性能的服务器搭建。并且,通过组件内提供的不同应⽤层…...

iTOP-RK3568开发板ubuntu环境下安装Eclipse
eclipse 是使用 Java 语言开发的,一个 Java 应用程序,这意味着 eclipse 只能运行在 Java虚拟机上。倘若没有安装 JDK(Java Development Kit),即使在 ubuntu 上安装了 eclipse,也不能运行,所以要…...

大气热力学
大气稳定度 大气稳定度又称为大气层结稳定度(贺德馨,2006)。大气层结指的是大气温度和湿度在垂直方向上的分布,对大气中污染物的扩散起着重要的作用。在静止大气中,假定气团受到垂直方向的扰动后,有一个向上的微小位移,如果大气层…...

【RabbitMQ】消息队列-RabbitMQ篇章
文章目录 1、RabbitMQ是什么2、Dokcer安装RabbitMQ2.1安装Dokcer2.2安装rabbitmq 3、RabbitMQ入门案例 - Simple 简单模式4、RabbitMQ的核心组成部分4.1 RabbitMQ整体架构4.2RabbitMQ的运行流程 5、RabbitMQ的模式5.1 发布订阅模式--fanout 1、RabbitMQ是什么 RabbitMQ是一个开…...
W5100S-EVB-PICO 做UDP Server进行数据回环测试(七)
前言 前面我们用W5100S-EVB-PICO 开发板在TCP Client和TCP Server模式下,分别进行数据回环测试,本章我们将用开发板在UDP Server模式下进行数据回环测试。 UDP是什么?什么是UDP Server?能干什么? UDP (User Dataqram …...

Redis如何处理内存溢出的情况?
当Redis的内存使用达到上限时,会出现内存溢出的情况。Redis提供了几种处理内存溢出的机制: 内存淘汰策略:Redis提供了多种内存淘汰策略,用于在内存不足时选择要移除的键。常见的淘汰策略包括: LRU(Least Re…...
高效数据传输:轻松上手将Kafka实时数据接入CnosDB
本篇我们将主要介绍如何在 Ubuntu 22.04.2 LTS 环境下,实现一个KafkaTelegrafCnosDB 同步实时获取流数据并存储的方案。在本次操作中,CnosDB 版本是2.3.0,Kafka 版本是2.5.1,Telegraf 版本是1.27.1 随着越来越多的应用程序架构转…...

【探索Linux】—— 强大的命令行工具 P.3(Linux开发工具 vim)
阅读导航 前言vim简介概念特点 vim的相关指令vim命令模式(Normal mode)相关指令插入模式(Insert mode)相关指令末行模式(last line mode)相关指令 简单vim配置(附配置链接)温馨提示 前言 前面我们讲了C语言的基础知识,也了解了一些数据结构&…...
跑通你的量化筛选器?)
Qlib实战:如何用自定义数据(比如可转债)跑通你的量化筛选器?
Qlib实战:从可转债数据到动态筛选策略的全流程解析 在量化投资领域,标准化的股票数据往往难以满足专业投资者的特殊需求。当我们需要处理可转债、加密货币或其他另类资产时,如何将这些非标准数据整合到强大的量化框架中,成为许多开…...

vscode格式化插件
1、在vsocde里安装这个插件2、下载 clangllvm 适配 windows 链接地址:https://github.com/llvm/llvm-project/releases/tag/llvmorg-18.1.83、添加环境变量 将下载的安装报解压到 C:\Users\你的用户名\AppData\Local\Programs 复制C:\Users\你的用户名\AppData\Loca…...

电弧故障检测与定位片上系统【附程序】
✨ 长期致力于电弧故障采集、电弧故障检测、电弧故障定位、片上系统、全数字锁相环、逐次逼近型模数转换器、低功耗、低成本研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 &…...

避坑指南:STM32驱动LD3320语音模块,SPI通信和中断配置的那些‘坑’我都替你踩过了
STM32与LD3320语音模块深度避坑实战:从SPI配置到中断优化的完整指南 当第一次拿到LD3320语音识别模块时,大多数开发者都会为它的"即插即用"特性感到兴奋——理论上只需要简单的SPI连接和基础配置就能实现语音识别功能。然而在实际项目中&#…...

Cadence Allegro 16.6 环境设置保姆级教程:从绘图参数到自动保存,新手避坑指南
Cadence Allegro 16.6 环境设置实战指南:从零配置到高效设计 第一次打开Cadence Allegro 16.6时,满屏的菜单选项和参数设置可能会让新手感到无所适从。作为一款专业的PCB设计工具,Allegro提供了高度可定制的工作环境,但这也意味着…...

2026亲测10大论文降AI工具,免费好用的都在这了
说实话,咱们26届熬过初稿真的挺不容易,万一终审抽检没过就太冤了,谁都不想在最后关头被卡住。身边有不少同学试图手动去改,结果原格式全乱了,踩过坑才 知道找对工具到底有多重要。 提升内容原创度很关键,终…...

NoFences:彻底告别桌面混乱的免费开源分区管理工具
NoFences:彻底告别桌面混乱的免费开源分区管理工具 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否经常在杂乱无章的Windows桌面上花费大量时间寻找需要的文…...

Perplexity视频搜索不精准?揭秘4类常见误操作及实时修正方案
更多请点击: https://codechina.net 第一章:Perplexity视频搜索不精准?揭秘4类常见误操作及实时修正方案 Perplexity 的视频搜索功能依赖于跨模态语义理解,但用户常因输入方式或上下文设置不当导致结果偏离预期。以下四类高频误操…...

【亲测免费】 探索INA282:电流检测与测量的利器
探索INA282:电流检测与测量的利器 【下载地址】INA282电路图与使用说明 INA282电路图与使用说明本仓库提供了一个关于INA282的详细资源文件,包括电路图和使用说明 项目地址: https://gitcode.com/open-source-toolkit/9e96c 项目介绍 INA282是一…...

2025最权威的AI写作方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当人工智能技术于当下迅猛发展之际,对于企业来讲,核心挑战其中之一便…...