基于YOLOv8模型和Caltech数据集的行人检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要
基于YOLOv8模型和Caltech数据集的行人检测系统可用于日常生活中检测与定位行人,利用深度学习算法可实现图片、视频、摄像头等方式的行人目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集,使用Pysdie6库来搭建前端页面展示系统。另外本系统支持的功能还包括训练模型的导入、初始化;检测置信分与检测后处理IOU阈值的调节;图像的上传、检测、可视化结果展示与检测结果导出;视频的上传、检测、可视化结果展示与检测结果导出;摄像头的图像输入、检测与可视化结果展示;已检测目标个数与列表、位置信息;前向推理用时等功能。本博文提供了完整的Python代码与安装和使用教程,适合新入门的朋友参考,部分重要代码部分都有注释,完整代码资源文件请转至文末的下载链接。

需要源码的朋友后台私信博主获取下载链接
基本介绍
近年来,机器学习和深度学习取得了较大的发展,深度学习方法在检测精度和速度方面与传统方法相比表现出更良好的性能。YOLOv8 是 Ultralytics 公司继 YOLOv5 算法之后开发的下一代算法模型,目前支持图像分类、物体检测和实例分割任务。YOLOv8 是一个 SOTA模型,它建立在之前YOLO 系列模型的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括:一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。因此本博文利用YOLOv8目标检测算法实现一种基于Caltech数据集的高精度行人检测模型,再使用Pyside6库搭建出界面系统,完成目标检测页面的开发。本博主之前发布过关于YOLOv5算法的相关模型与界面,需要的朋友可从我之前发布的博客查看。另外本博主计划将YOLOv5、YOLOv6、YOLOv7和YOLOv8一起联合发布,需要的朋友可以持续关注,欢迎朋友们关注收藏。
环境搭建
(1)打开项目目录,在搜索框内输入cmd打开终端

(2)新建一个虚拟环境(conda create -n yolo8 python=3.8)

(3)激活环境,安装ultralytics库(yolov8官方库),pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple

(4)注意到这种安装方式只会安装cpu版torch,如需安装gpu版torch,需在安装包之前先安装torch:pip install torch2.0.1+cu118 torchvision0.15.2+cu118 -f https://download.pytorch.org/whl/torch_stable.html;再,pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple

(5)安装图形化界面库pyside6:pip install pyside6 -i https://pypi.tuna.tsinghua.edu.cn/simple
界面及功能展示
下面给出本博文设计的软件界面,整体界面简洁大方,大体功能包括训练模型的导入、初始化;置信分与IOU阈值的调节、图像上传、检测、可视化结果展示、结果导出与结束检测;视频的上传、检测、可视化结果展示、结果导出与结束检测;已检测目标列表、位置信息;前向推理用时。初始界面如下图:

模型选择与初始化
用户可以点击模型权重选择按钮上传训练好的模型权重,训练权重格式可为.pt、.onnx以及engine等,之后再点击模型权重初始化按钮可实现已选择模型初始化的配置。

置信分与IOU的改变
在Confidence或IOU下方的输入框中改变值即可同步改变滑动条的进度,同时改变滑动条的进度值也可同步改变输入框的值;Confidence或IOU值的改变将同步到模型里的配置,将改变检测置信度阈值与IOU阈值。
图像选择、检测与导出
用户可以点击选择图像按钮上传单张图像进行检测与识别,上传成功后系统界面会同步显示输入图像。

再点击图像检测按钮可完成输入图像的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

再点击检测结果展示按钮可在系统左下方显示输入图像检测的结果,系统将显示识别出图片中的目标的类别、位置和置信度信息。

点击图像检测结果导出按钮即可导出检测后的图像,在保存栏里输入保存的图片名称及后缀即可实现检测结果图像的保存。

点击结束图像检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频,或者点击打开摄像头按钮来开启摄像头。
视频选择、检测与导出
用户点击选择视频按钮上传视频进行检测与识别,之后系统会将视频的第一帧输入到系统界面中显示。

再点击视频检测按钮可完成输入视频的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

点击暂停视频检测按钮即可实现输入视频的暂停,此时按钮变为继续视频检测,输入视频帧与帧检测结果会保留在系统界面,可点击下拉目标框选择已检测目标的坐标位置信息,再点击继续视频检测按钮即可实现输入视频的检测。
点击视频检测结果导出按钮即可导出检测后的视频,在保存栏里输入保存的图片名称及后缀即可实现检测结果视频的保存。

点击结束视频检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频,或者点击打开摄像头按钮来开启摄像头。
摄像头打开、检测与结束
用户可以点击打开摄像头按钮来打开摄像头设备进行检测与识别,之后系统会将摄像头图像输入到系统界面中显示。

再点击摄像头检测按钮可完成输入摄像头的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

点击结束视频检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频,或者点击打开摄像头按钮来开启摄像头。
算法原理介绍
本系统采用了基于深度学习的单阶段目标检测算法YOLOv8,相较于之前的YOLO系列目标检测算法,YOLOv8目标检测算法具有如下的几点优势:(1)更友好的安装/运行方式;(2)速度更快、准确率更高;(3)新的backbone,将YOLOv5中的C3更换为C2F;(4)YOLO系列第一次尝试使用anchor-free;(5)新的损失函数。YOLOv8模型的整体结构如下图所示,原图见mmyolo的官方仓库。

YOLOv8与YOLOv5模型最明显的差异是使用C2F模块替换了原来的C3模块,两个模块的结构如下图所示,原图见mmyolo的官方仓库。

另外Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。其结构对比如下图所示。

数据集介绍
本系统使用的Caltech行人数据集标注了行人这一个类别,数据集总计22935张图片。该数据集中类别都有大量的旋转和不同的光照条件,有助于训练出更加鲁棒的检测模型。本文实验的Caltech目标检测数据集包含训练集18569张图片,验证集4366张图片,选取部分数据部分样本数据集如下图所示。在训练阶段,由于YOLOv5算法对输入图片大小有限制,需要将所有图片调整为相同的大小。为了在不影响检测精度的情况下尽可能减小图片的失真,我们将所有图片调整为640x640的大小,并保持原有的宽高比例。此外,为了增强模型的泛化能力和鲁棒性,我们还使用了数据增强技术,包括随机旋转、缩放、裁剪和颜色变换等,以扩充数据集并减少过拟合风险。

关键代码解析
在训练阶段,我们使用了预训练模型作为初始模型进行训练,然后通过多次迭代优化网络参数,以达到更好的检测性能。在训练过程中,我们采用了学习率衰减和数据增强等技术,以增强模型的泛化能力和鲁棒性。一个简单的单卡模型训练命令如下。

在训练时也可指定更多的参数,大部分重要的参数如下所示:

在测试阶段,我们使用了训练好的模型来对新的图片和视频进行检测。通过设置阈值,将置信度低于阈值的检测框过滤掉,最终得到检测结果。同时,我们还可以将检测结果保存为图片或视频格式,以便进行后续分析和应用。本系统基于YOLOv8算法,使用PyTorch实现。代码中用到的主要库包括PyTorch、NumPy、OpenCV、Pyside6等。

Pyside6界面设计
PySide是一个Python的图形化界面(GUI)库,由C++版的Qt开发而来,在用法上基本与C++版没有特别大的差异。相对于其他Python GUI库来说,PySide开发较快,功能更完善,而且文档支持更好。在本博文中,我们使用Pyside6库创建一个图形化界面,为用户提供简单易用的交互界面,实现用户选择图片、视频进行目标检测。
我们使用Qt Designer设计图形界面,然后使用Pyside6将设计好的UI文件转换为Python代码。图形界面中包含多个UI控件,例如:标签、按钮、文本框、多选框等。通过Pyside6中的信号槽机制,可以使得UI控件与程序逻辑代码相互连接。
实验结果与分析
在实验结果与分析部分,我们使用精度和召回率等指标来评估模型的性能,还通过损失曲线和PR曲线来分析训练过程。在训练阶段,我们使用了前面介绍的Caltech行人数据集进行训练,使用了YOLOv8算法对数据集训练,总计训练了100个epochs。在训练过程中,我们使用tensorboard记录了模型在训练集和验证集上的损失曲线。从下图可以看出,随着训练次数的增加,模型的训练损失和验证损失都逐渐降低,说明模型不断地学习到更加精准的特征。在训练结束后,我们使用模型在数据集的验证集上进行了评估,得到了以下结果。

下图展示了我们训练的YOLOv8模型在验证集上的PR曲线,从图中可以看出,模型取得了较高的召回率和精确率,整体表现良好。

下图展示了本博文在使用YOLOv8模型对Caltech行人数据集进行训练时候的Mosaic数据增强图像。

综上,本博文训练得到的YOLOv8模型在数据集上表现良好,具有较高的检测精度和鲁棒性,可以在实际场景中应用。另外本博主对整个系统进行了详细测试,最终开发出一版流畅的高精度目标检测系统界面,就是本博文演示部分的展示,完整的UI界面、测试图片视频、代码文件等均已打包上传,感兴趣的朋友可以关注我私信获取。
其他基于深度学习的目标检测系统如西红柿、猫狗、山羊、野生目标、烟头、二维码、头盔、交警、野生动物、野外烟雾、人体摔倒识别、红外行人、家禽猪、苹果、推土机、蜜蜂、打电话、鸽子、足球、奶牛、人脸口罩、安全背心、烟雾检测系统等有需要的朋友关注我,从博主其他视频中获取下载链接。
完整项目目录如下所示:

相关文章:
基于YOLOv8模型和Caltech数据集的行人检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要 基于YOLOv8模型和Caltech数据集的行人检测系统可用于日常生活中检测与定位行人,利用深度学习算法可实现图片、视频、摄像头等方式的行人目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…...

Flutter 宽高自适应
在Flutter开发中也需要宽高自适应,手动写一个工具类,集成之后在像素后面直接使用 px或者 rpx即可。 工具类代码如下: import dart:ui;class HYSizeFit {static double screenWidth 0.0;static double screenHeight 0.0;static double phys…...
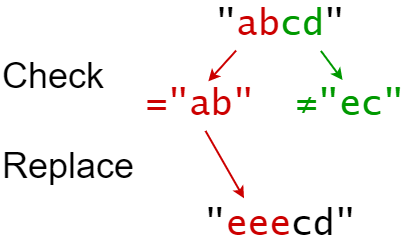
LeetCode 0833. 字符串中的查找与替换
【LetMeFly】833.字符串中的查找与替换 力扣题目链接:https://leetcode.cn/problems/find-and-replace-in-string/ 你会得到一个字符串 s (索引从 0 开始),你必须对它执行 k 个替换操作。替换操作以三个长度均为 k 的并行数组给出:indices,…...
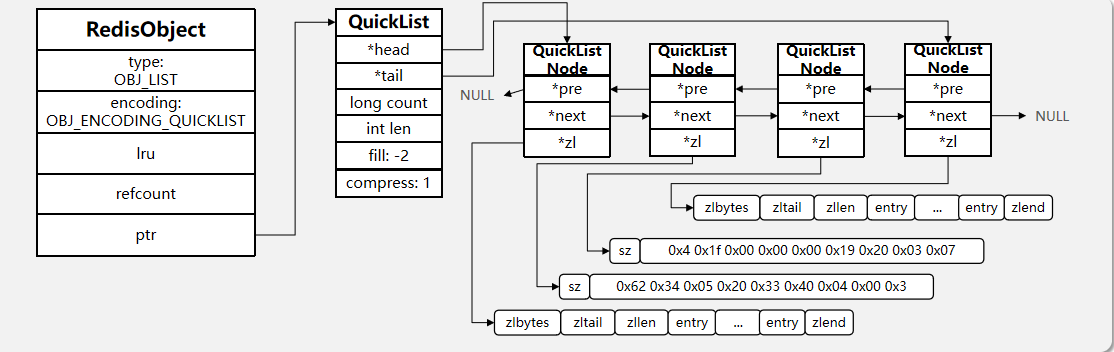
Redis对象和五种常用数据类型
Redisobject 对象 对象分为键对象和值对象 键对象一般是string类型 值对象可以是string,list,set,zset,hash q:redisobj的结构 typedef struct redisObject { //类型 unsigned type:4; //编码 unsigned encoding:4; //指向底层实现…...

常用的Elasticsearch查询DSL
1.基本查询 GET /index_name/_search {"query": {"match": {"dispatchClass": "1"}} }2.多条件查询 GET /index_name/_search {"query": {"bool": {"must": [{"match": {"createUser&…...

计算机网络笔记
TCP有连接可靠服务 TCP特点: 1.TCP是面向连接的传输层协议; 2.每条TCP连接只能有两个端点,每条TCP连接是一对一的; 3.TCP提供可靠交付,保证传送数据无差错,不丢失,不重复且有序; 4.…...
高效反编译luac文件
对于游戏开发人员,有时候希望从一些游戏apk中反编译出源代码,进行学习,但是如果你触碰到法律边缘,那么你要非常小心。 这篇文章,我针对一些用lua写客户端或者服务器的编译过的luac文件进行反编译,获取其源代码的过程。 这里我不赘述如何反编译解压apk包的过程了,只说重点…...

密码湘军,融合创新!麒麟信安参展2023商用密码大会,铸牢数据安全坚固堡垒
2023年8月9日至11日,商用密码大会在郑州国际会展中心正式开幕。本次大会由国家密码管理局指导,中国密码学会支持,郑州市人民政府、河南省密码管理局主办,以“密码赋能美好发展”为主题,旨在推进商用密码创新驱动、前沿…...
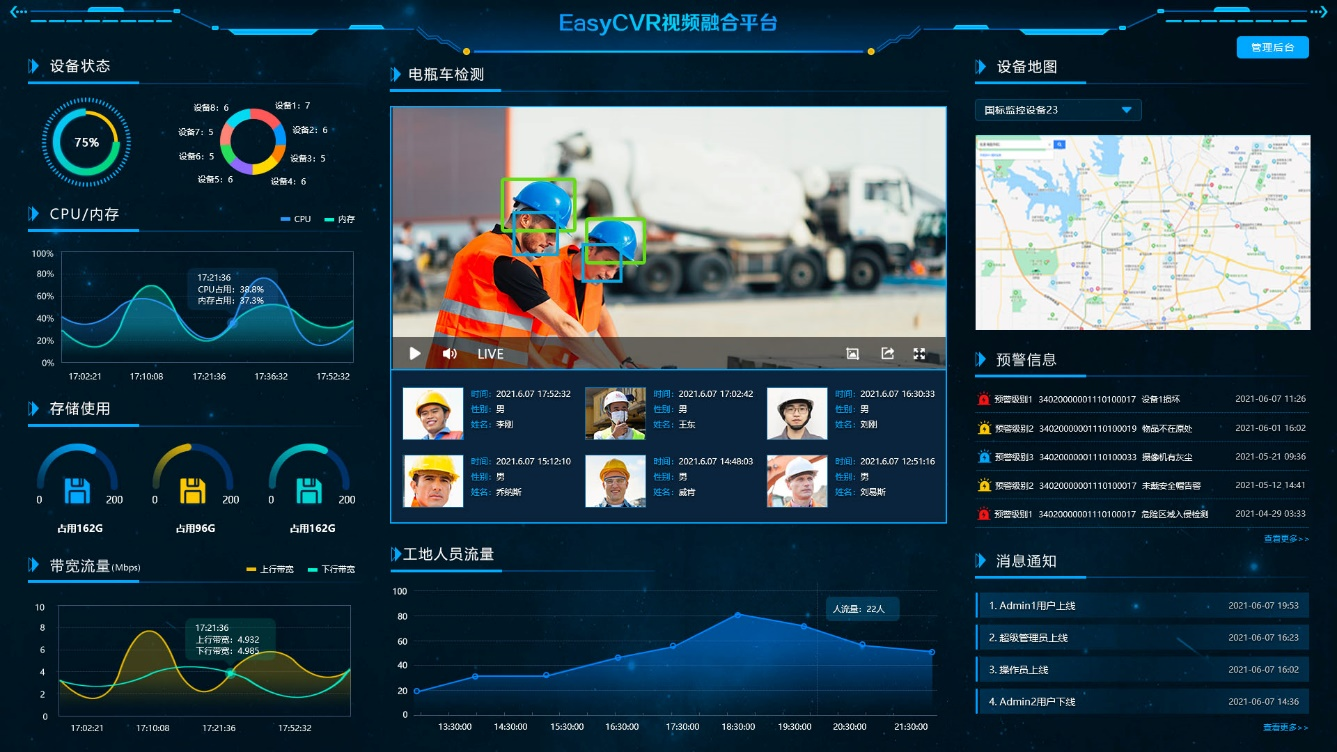
关于视频监控平台EasyCVR视频汇聚平台建设“明厨亮灶”具体实施方案以及应用
一、方案背景 近几年来,餐饮行业的食品安全、食品卫生等新闻频频发生,比如某火锅店、某网红奶茶,食材以次充好、后厨卫生被爆堪忧,种种问题引起大众关注和热议。这些负面新闻不仅让餐饮门店的品牌口碑暴跌,附带的连锁…...

区块链系统探索之路:私钥的压缩和WIF格式详解
在前面章节中,我们详细介绍了公钥的压缩,在比特币网络中,一个私钥可以对应两个地址,一个地址是由未压缩公钥所生成的地址,另一个就是由压缩公钥所创建的地址,从公钥到区块链地址的转换算法,我们…...

DiffusionDet: Diffusion Model for Object Detection
DiffusionDet: Diffusion Model for Object Detection 论文概述不同之处整体流程 论文题目:DiffusionDet: Diffusion Model for Object Detection 论文来源:arXiv preprint 2022 论文地址:https://arxiv.org/abs/2211.09788 论文代码…...

CH01_重构、第一个示例
概述 在这一章节,作者给出了一个戏剧演出团售票的示例:剧目有悲剧(tragedy)和喜剧(comedy);为了卖出更多的票,剧团则更具观众的数量来为下次演出打折扣(大致意思是这次的…...
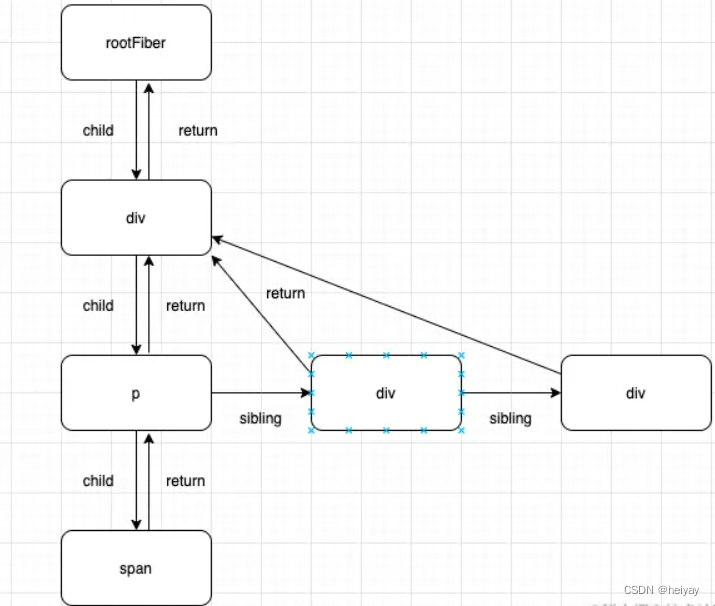
学习篇之React Fiber概念及原理
什么是React Fibber? React Fiber 是 React 框架的一种底层架构,为了改进 React 的渲染引擎,使其更加高效、灵活和可扩展。 传统上,React 使用一种称为堆栈调和递归算法来处理虚拟 DOM 的更新,这种方法在大型应用或者…...
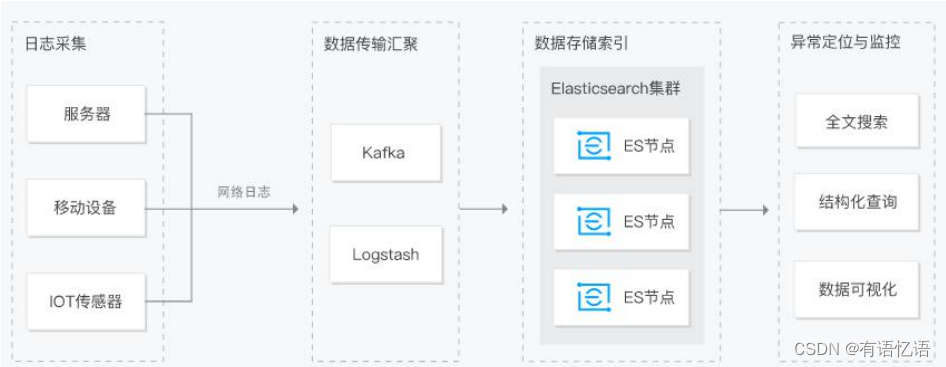
商城-学习整理-高级-全文检索-ES(九)
目录 一、ES简介1、网址2、基本概念1、Index(索引)2、Type(类型)3、Document(文档)4、倒排索引机制4.1 正向索引和倒排索引4.2 正向索引4.3 倒排索引 3、相关软件及下载地址3.1 Kibana简介3.2 logstash简介…...

无人机跟随一维高度避障场景--逻辑分析
无人机跟随一维高度避障场景--逻辑分析 1. 源由2. 视频3. 问题3.1 思维发散3.2 问题收敛 4. 图示4.1 水平模式4.2 下坡模式4.3 上坡模式4.4 碰撞分析 5. 总结5.1 一维高度避障场景5.2 业界跟随产品5.3 APM集成跟随 6. 参考资料7. 补充资料 - 大疆智能跟随7.1 炸机7.2 成功 1. 源…...
Android Studio Giraffe控制台乱码
这几天在使用Android Studio Giraffe进行一个App的开发,在项目构建的时候,控制台输出中文都是乱码,看着很不爽,进行了两项配置,中文就可以正常输出了,看起来就爽多了。 第一个配置:点击Help菜单…...

云原生 envoy xDS 动态配置 java控制平面开发 支持restful grpc实现 EDS 动态endpoint配置
envoy xDS 动态配置 java控制平面开发 支持restful grpc 动态endpoint配置 大纲 基础概念Envoy 动态配置API配置方式动静结合的配置方式纯动态配置方式实战 基础概念 Envoy 的强大功能之一是支持动态配置,当使用动态配置时,我们不需要重新启动 Envoy…...
)
Linux--实用指令与方法(部分)
下文主要是一些工作中零碎的常用指令与方法 实用指令与方法(部分) linux长时间保持ssh连接 这个问题的原因是:设置检测时间太短,或者没有保持tcp长连接。 解决步骤: 步骤1:打开sshd配置文件࿰…...

常见期权策略类型有哪些?
这几天在做一个期权策略类型的整理分类,怎么解释期权策略,期权策略是现代金融市场中运用非常广泛、变化非常丰富、结构非常精妙的金融衍生产品;同时也是一种更为复杂也更为灵活的投资工具,下文介绍常见期权策略类型有哪些…...
tomcat服务七层搭建动态页面查看
一个服务器多实例复制完成 配置tomcat多实例的环境变量 vim /etc/profile.d/tomcat.sh配置tomcat1和tomcat2的环境变量 进入tomcat1修改配置 测试通信端口是否正常 连接正常 toncat 2 配置修改 修改这三个 端口配置修改完成 修改tomcat1 shudown 分别把启动文件指向tomcat1…...

深度解析SacreBLEU:5个实战技巧提升机器翻译评估效率
深度解析SacreBLEU:5个实战技巧提升机器翻译评估效率 【免费下载链接】sacrebleu Reference BLEU implementation that auto-downloads test sets and reports a version string to facilitate cross-lab comparisons 项目地址: https://gitcode.com/gh_mirrors/s…...

Univer开源项目部署完整指南:从零到生产环境
Univer开源项目部署完整指南:从零到生产环境 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is driven dir…...

从零开始在Taotoken模型广场选择并测试最适合的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始在Taotoken模型广场选择并测试最适合的模型 当你开始使用大模型时,面对众多厂商和不同能力的模型,…...

Pandas 数据清洗与分析
第一部分:水果销售分析(入门篇)首先,我们有一个简单的水果销售列表。我们的任务是算出每种水果的总销量,以及每天的销售明细。1. 数据准备我们先造一点数据:import pandas as pd import numpy as npdata {…...
从屏幕取词到智能翻译:CuteTranslation如何重塑Linux用户的跨语言工作流
从屏幕取词到智能翻译:CuteTranslation如何重塑Linux用户的跨语言工作流 【免费下载链接】CuteTranslation Linux屏幕取词翻译软件 项目地址: https://gitcode.com/gh_mirrors/cu/CuteTranslation 在Linux生态系统中,多语言处理一直是个技术痛点—…...

MFAPC实战:如何为你的Arduino或树莓派项目添加智能自适应预测控制?
MFAPC实战:为嵌入式项目打造轻量级智能控制引擎 在创客空间和物联网实验室里,我们常看到这样的场景:一位开发者盯着反复震荡的智能小车摇头叹气,或是面对总也调不准的温室控制系统抓耳挠腮。传统PID控制在这些复杂动态系统中往往…...
)
从手机充电到电路板:一文搞懂Type-C的6P、16P、24P到底该怎么选(附实物图对比)
Type-C接口选型实战指南:6P/16P/24P的工程决策逻辑 当你在设计一款智能手表时,是否曾纠结过该用6P还是16P的Type-C接口?这个问题看似简单,却直接影响着产品的BOM成本、用户体验和市场竞争力。作为硬件开发者,我们每天都…...

YOLO模型如何训练救生衣检测数据集深度学习如何训练救生衣检测数据集
救生衣检测模型YOLO8-300n 提供训练好的模型文件(pt格式)、过程文件和验证图片,带对应的训练数据集10000张 1 111一、救生衣检测模型(YOLOv8-300n)完整方案1. 模型与数据集信息项目详情模型版本YOLOv8n(300…...

CentOS 8.5最小化安装实战:为什么我只选Minimal Install,以及后续必装的10个软件包
CentOS 8.5最小化安装实战:为什么我只选Minimal Install,以及后续必装的10个软件包 当你面对CentOS 8.5安装界面中那个看似简单的"Software Selection"选项时,是否曾犹豫过该选择哪个?作为一个经历过无数次系统安装的老…...

Windows热键冲突终结者:Hotkey Detective深度解析与实战指南
Windows热键冲突终结者:Hotkey Detective深度解析与实战指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 想…...