爆肝整理,Python自动化测试-Pytest参数化实战封装,一篇打通...
目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
参数化?
通俗点理解就是,定义一个测试类或测试函数,可以传入不同测试用例对应的参数,从而执行多个测试用例。
例如:
对登录接口进行测试,假设有3条用例,正确账号正确密码登录、正确账号错误密码登录、错误账号正确密码登录,那么我们只需要定义一个登陆测试函数test_login(),然后使用这3条用例对应的参数去调用test_login()即可。
在unittest中可以使用ddt进行参数化,而pytest中也提供非常方便的参数化方式,即使用装饰器@pytest.mark.parametrize()。
一般写为pytest.mark.parametrize(“argnames”, argvalues)。
其中:
argnames为参数名称,可以是单个或多个,多个写法为"argname1, argname2, …";
argvalues为参数值,类型必须为list(单个参数时可以为元组,多个参数时必须为list,所以最好统一);
例如有下接口:
请求的登陆接口信息:
接口url:http://127.0.0.1:5000/login
请求方式:post
请求参数:
响应信息:
1、单个参数
只需要传入一个参数时,示例如下:
# 待测试函数
def sum(a):return a+1# 单个参数
data = [1, 2, 3, 4]
@pytest.mark.parametrize("item", data)
def test_add(item):actual = sum(item)print("\n{}".format(actual))# assert actual == 3if __name__ == '__main__':pytest.main()
注意:
@pytest.mark.parametrize()中的第一个参数,必须以字符串的形式来标识测试函数的入参,如上述示例中,定义的测试函数test_login()中传入的参数名为item,那么@pytest.mark.parametrize()的第一个参数则为"item"。
运行结果如下:
rootdir: E:\blog\python接口自动化\apiAutoTest, configfile: pytest.ini
plugins: html-2.1.1, metadata-1.10.0, ordering-0.6, rerunfailures-9.1.1
collecting ... collected 4 itemstest_case_2.py::test_add[1] PASSED [ 25%]
2test_case_2.py::test_add[2] PASSED [ 50%]
3test_case_2.py::test_add[3] PASSED [ 75%]
4test_case_2.py::test_add[4] PASSED [100%]
5============================== 4 passed in 0.02s ==============================
从结果可以看到,测试函数分别传入了data中的参数,总共执行了5次。
2、多个参数
测试用例需传入多个参数时,@pytest.mark.parametrize() 的第一个参数同样是字符串, 对应用例的多个参数用逗号分隔。
示例:
import pytest
import requests
import json# 列表嵌套元组
data = [("lilei", "123456"), ("hanmeimei", "888888")]
# 列表嵌套列表
# data = [["lilei", "123456"], ["hanmeimei", "888888"]]@pytest.mark.parametrize("username, password", data)
def test_login(username, password):headers = {"Content-Type": "application/json;charset=utf8"}url = "http://127.0.0.1:5000/login"_data = {"username": username,"password": password}res = requests.post(url=url, headers=headers, json=_data).textres = json.loads(res)assert res['code'] == 1000if __name__ == '__main__':pytest.main()
需要注意:
代码中data的格式,可以是列表嵌套列表,也可以是列表嵌套元组,列表中的每个列表或元组代表一组独立的请求参数。
"username, password"不能写成 “username”, “password”。
运行结果如下:
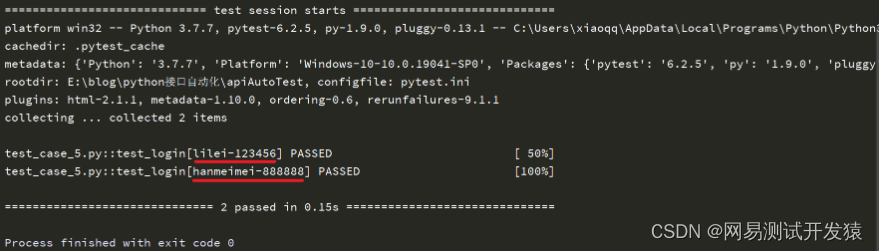
从结果中我们还可以看到每次执行传入的参数,如下划线所示部分。
这里所举示例是2个参数,传入3个或更多参数时,写法也同样如此,一定要注意它们之间一一对应的关系,如下图:
3、对测试类参数化
上面所举示例都是对测试函数进行参数化,那么对测试类怎么进行参数化呢?
其实,对测试类的参数化,就是对测试类中的测试方法进行参数化。
@pytest.mark.parametrize()中标识的参数个数,必须与类中的测试方法的参数一致。示例如下:
# 将登陆接口请求单独进行了封装,仅仅只是为了方便下面的示例
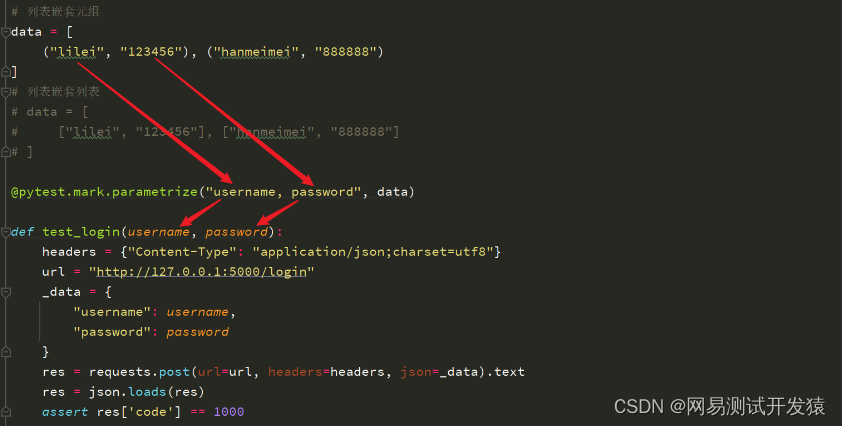
def login(username, password):headers = {"Content-Type": "application/json;charset=utf8"}url = "http://127.0.0.1:5000/login"_data = {"username": username,"password": password}res = requests.post(url=url, headers=headers, json=_data).textres = json.loads(res)return res# 测试类参数化
data = [("lilei", "123456"), ("hanmeimei", "888888")
]
@pytest.mark.parametrize("username, password", data)
class TestLogin:def test_login_01(self, username, password):res = login(username, password)assert res['code'] == 1000def test_login_02(self, username, password):res = login(username, password)assert res['msg'] == "登录成功!"if __name__ == '__main__':pytest.main(["-s"])
运行结果如下:
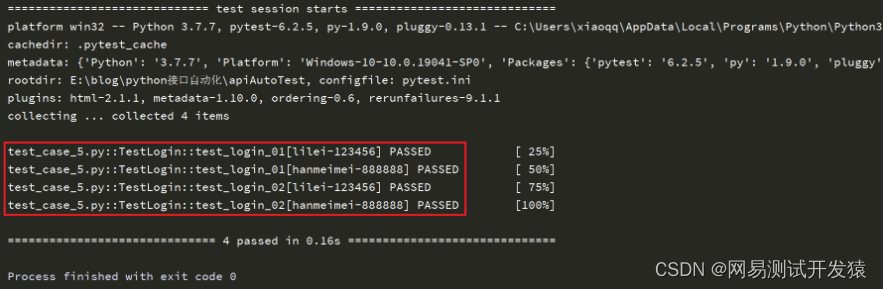
从结果中可以看出来,总共执行了4次,测试类中的每个测试方法都执行了2次,即每个测试方法都将data中的每一组参数都执行了一次。
注意:
这里还是要强调参数对应的关系,即@pytest.mark.parametrize()中的第一个参数,需要与测试类下面的测试方法的参数一一对应。
4、参数组合
在编写测试用例的过程中,有时候需要将参数组合进行接口请求,如示例的登录接口中username有 lilei、hanmeimei,password有 123456、888888,进行组合的话有下列四种情况:
{"username": "lilei", "password": "123456"}
{"username": "lilei", "password": "888888"}
{"username": "hanmeimei", "password": "123456"}
{"username": "hanmeimei", "password": "888888"}
在@pytest.mark.parametrize()也提供了这样的参数组合功能,编写格式示例如下:
import pytest
import requests
import jsonusername = ["lilei", "hanmeimei"]
password = ["123456", "888888"]@pytest.mark.parametrize("password", password)
@pytest.mark.parametrize("username", username)
def test_login(username, password):headers = {"Content-Type": "application/json;charset=utf8"}url = "http://127.0.0.1:5000/login"_data = {"username": username,"password": password}res = requests.post(url=url, headers=headers, json=_data).textres = json.loads(res)assert res['code'] == 1000if __name__ == '__main__':pytest.main()
运行结果如下:
rootdir: E:\blog\python接口自动化\apiAutoTest, configfile: pytest.ini
plugins: html-2.1.1, metadata-1.10.0, ordering-0.6, rerunfailures-9.1.1
collecting ... collected 4 itemstest_case_5.py::test_login[lilei-123456] PASSED [ 25%]
test_case_5.py::test_login[lilei-888888] FAILED [ 50%]
test_case_5.py::test_login[hanmeimei-123456] FAILED [ 75%]
test_case_5.py::test_login[hanmeimei-888888] PASSED [100%]
=========================== short test summary info ===========================
FAILED test_case_5.py::test_login[lilei-888888] - assert 1001 == 1000
FAILED test_case_5.py::test_login[hanmeimei-123456] - assert 1001 == 1000
========================= 2 failed, 2 passed in 0.18s =========================
从结果可以看出来,2个username、2个password 有4中组合方式,总执行了4次。如果是3个username、2个password,那么就有6中参数组合方式,依此类推。
注意:
以上这些示例中的测试用例仅仅只是用于举例,实际项目中的登录接口测试脚本与测试数据会不一样。
5、增加测试结果可读性
从示例的运行结果中我们可以看到,为了区分参数化的运行结果,在结果中都会显示由参数组合而成的执行用例名称,很方便就能看出来执行了哪些参数组合的用例。
示例:
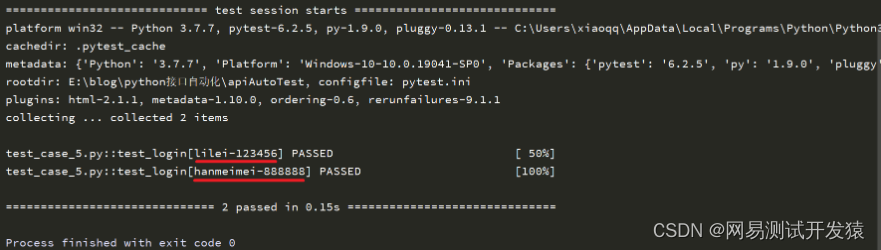
但这只是简单的展示,如果参数多且复杂的话,仅仅这样展示是不够清晰的,需要添加一些说明才能一目了然。
因此,在@pytest.mark.parametrize()中有两种方式来自定义上图中划线部分的显示结果,即使用@pytest.mark.parametrize()提供的参数 ids 自定义,或者使用pytest.param()中的参数id自定义。
ids(推荐)
ids使用方法示例如下:
import pytest
import requests
import jsondata = [("lilei", "123456"), ("hanmeimei", "888888")]
ids = ["username:{}-password:{}".format(username, password) for username, password in data]
@pytest.mark.parametrize("username, password", data, ids=ids)
def test_login(username, password):headers = {"Content-Type": "application/json;charset=utf8"}url = "http://127.0.0.1:5000/login"_data = {"username": username,"password": password}res = requests.post(url=url, headers=headers, json=_data).textres = json.loads(res)assert res['code'] == 1000if __name__ == '__main__':pytest.main()
从编写方式可以看出来,ids就是一个list,且它的长度与参数组合的分组数量一致。
运行结果如下:
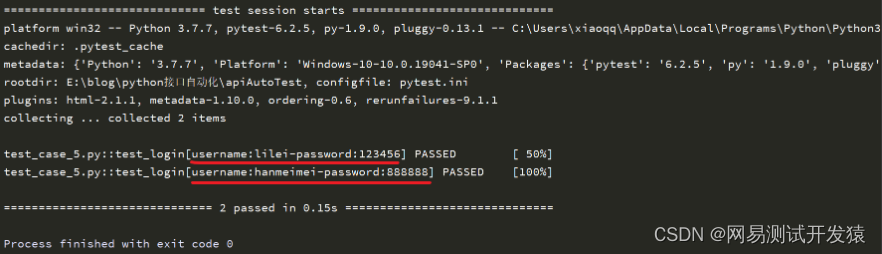
比较上面个执行结果,我们能看出ids自定义执行结果与默认执行结果展示的区别。使用过程中,需要根据实际情况来自定义。
id
使用方式示例如下:
import pytest
import requests
import jsondata = [pytest.param("lilei", "123456", id="correct username and correct password"),pytest.param("lilei", "111111", id="correct user name and wrong password")
]@pytest.mark.parametrize("username, password", data)
def test_login(username, password):headers = {"Content-Type": "application/json;charset=utf8"}url = "http://127.0.0.1:5000/login"_data = {"username": username,"password": password}res = requests.post(url=url, headers=headers, json=_data).textres = json.loads(res)assert res['code'] == 1000if __name__ == '__main__':pytest.main()
运行结果如下:
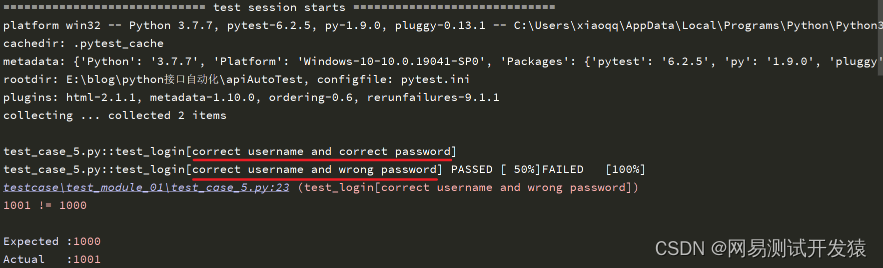
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
二、接口自动化项目实战
三、Web自动化项目实战
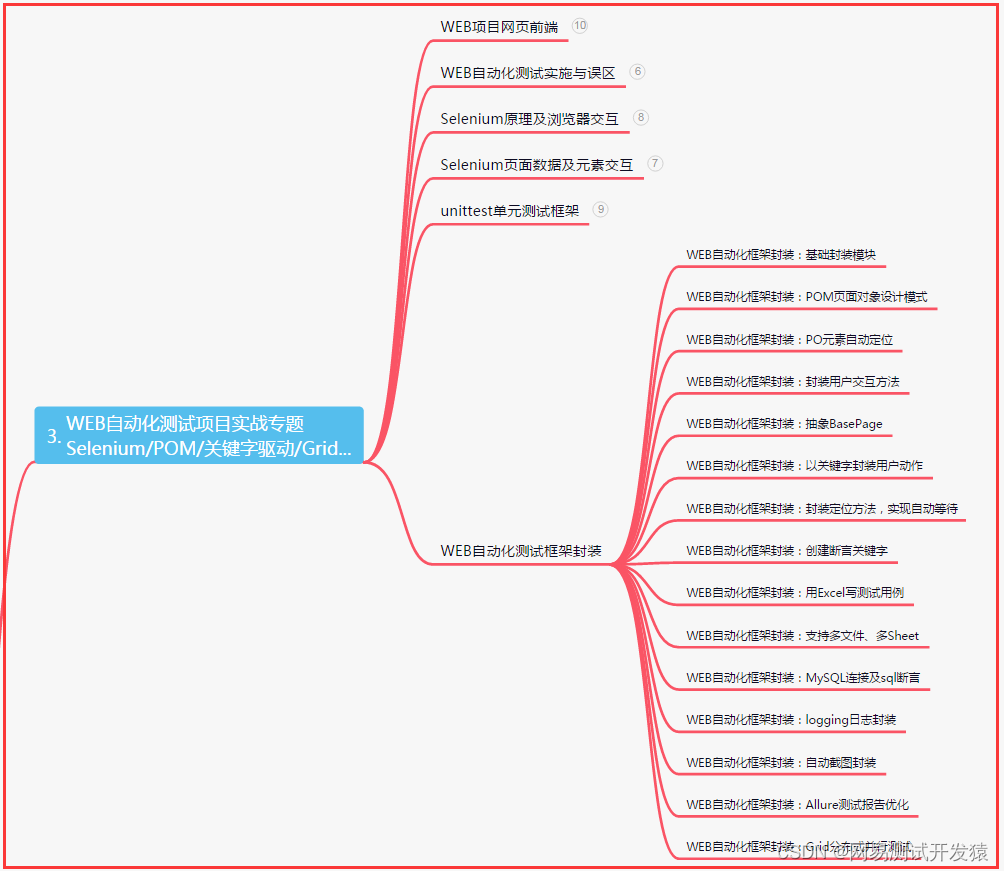
四、App自动化项目实战
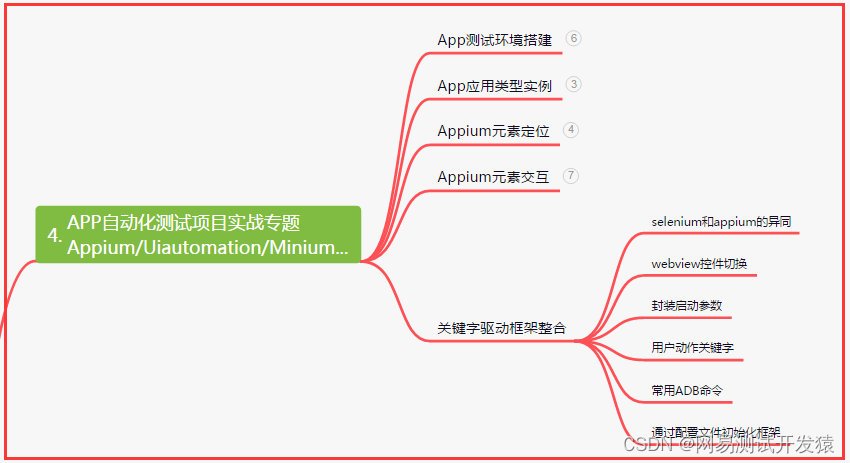
五、一线大厂简历
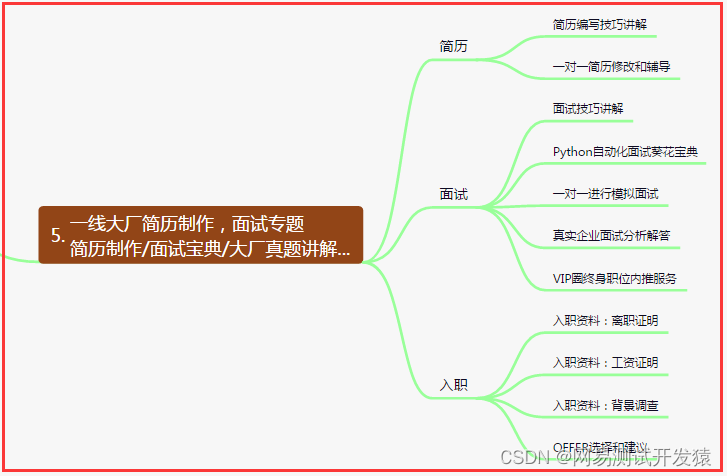
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试
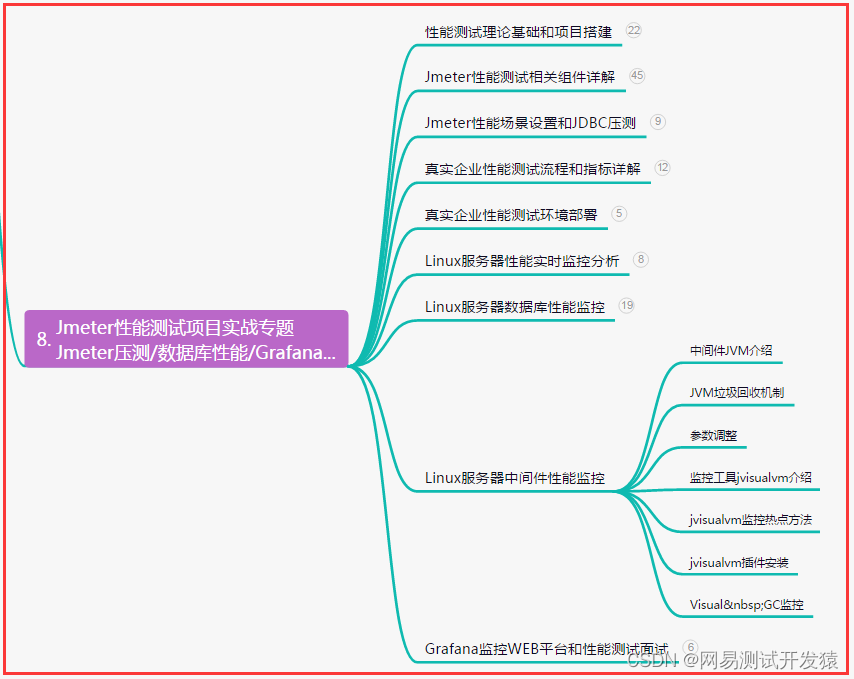
九、总结(尾部小惊喜)
奋斗是一段漫长的旅程,痛苦与磨难只是通往成功的试炼。不惧困难,坚守信念,用汗水浇灌梦想的花朵。相信自己,勇往直前,你将创造属于自己的辉煌,留下无悔的足迹!
执着的火焰燃烧内心,不屈的勇气驱散黑暗。放下畏惧,迎接挑战,奋斗的脚步不停歇。每一次努力铸就坚韧,每一次拼搏开启新篇章。勇往直前,追逐梦想。
人生的舞台,唯有奋斗才能谱写出绚丽的乐章。不要畏惧困难,要勇敢地迎接挑战。坚持努力,永不放弃,相信自己的力量,你将创造出意想不到的精彩人生!
相关文章:
爆肝整理,Python自动化测试-Pytest参数化实战封装,一篇打通...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 参数化࿱…...
)
西门子AI面试问答(STAR法则回答实例)
0.试题情况 0.未来三到五年的职业规划(不计入成绩,测试用); 1.一些基本问题,目前所在城市目标薪资意向工作城市(手动输入,非视频录制); 2.宝洁8大问的问题1个英文回答…...

中间平台工具 - graylog
graylog是非常好用的数据处理平台,可以对数据进行:streams分类、pipeline、正则匹配、统计汇总、定制化配置Alerts 等处理。 graylog的一些概念: 索引(消息存储的位置,默认indices default) streams(从inputs里面,通…...
VectorStyler for Mac: 让你的创意无限绽放的全新设计工具
VectorStyler for Mac是一款专为Mac用户打造的矢量设计工具,它结合了功能强大的矢量编辑器和创意无限的样式编辑器,让你的创意无限绽放。 VectorStyler for Mac拥有直观简洁的用户界面,让你能够轻松上手。它提供了丰富的矢量绘图工具&#x…...
轻松转换TS视频为MP4,实现优质视频剪辑体验
如果你是一个视频剪辑爱好者,你一定会遇到各种视频格式之间的转换问题,特别是将TS视频转换为MP4格式。别担心,我们的视频剪辑软件将为你提供最简单、高效的解决方案! 首先第一步,我们要进入媒体梦工厂主页面ÿ…...
IDEA关闭项目,但是后台程序没有关闭进程(解决方案)
最近遇到一个很奇怪的问题,idea关闭项目后,系统进程没有杀死进程,再次执行的时候会提示端口占用,并提示Process exited with an error: 1 (Exit value: 1) 错误原因:应用程序关闭后,进程不能同步关闭 解决方…...
github拉取自己的私有仓库(Token方式、本地秘钥方式)
github拉取自己的私有仓库(Token方式、本地秘钥方式) 问题背景 日常开发和学习过程中,经常碰到需要从GitHub或者其他类似网站,拉取私有仓代码的需求。本文将总结常用的两种方式,Token方式和本地秘钥方式,方便后续查阅和优化。 …...

聊聊非科班转IT
我这算是妥妥的非科班转计算机的了,先介绍下自己的情况吧。 14年大专毕业,学的汽车运用专业。(什么?你说啥是汽车运用专业?那机械设计总知道吧,这个专业接本后就是机械设计了。) 毕业后服役&…...

NET域名的优势
NET域名是互联网上最常见的顶级域名之一,其开放使用日期远比其他主要顶级域名早,始于1985年。其作为商业网络服务提供者的域名,主要用于企业、组织和个人等在网络上建立自己的网站。本文将从以下三个方面介绍NET域名。 一、NET域名的历史 N…...
ZLMediaKit推流测试
推流测试 ZLMediaKit支持rtsp/rtmp/rtp推流,一般通常使用obs/ffmpeg推流测试,其中FFmpeg推流命令支持以下: 1、使用rtsp方式推流 # h264推流 ffmpeg -re -i "/path/to/test.mp4" -vcodec h264 -acodec aac -f rtsp -rtsp_transp…...

高防服务器的防御机制
高防服务器的防御机制 易受到GJ的网站选择接入高防服务更安全,大家对于这个都清楚!但是对于高防服务如何实现防御来保障安全的,又了解多少呢?今天壹基比小源(贰伍壹叁壹叁壹贰玖捌)就来说说高防服务实现防御的常规方法一般有以下…...
【PySide】QtWebEngine网页浏览器打开Flash网页
QWebEngineView 加载 flash插件,可成功显示Flash,如图 说明 QtWebEngine与Chromium版本对应关系 Chromium对Flash的支持 QtWebEngine模块 Qt WebEngine取代了Qt WebKit模块,后者基于WebKit项目,但自Qt 5.2以来没有主动与上游WebKit代码同步,并且在Qt 5.5中已被弃用。有…...
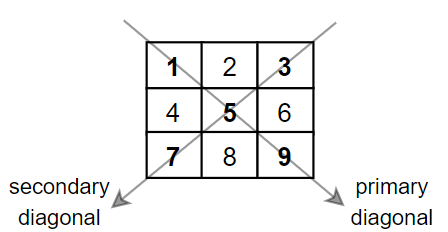
【力扣每日一题】1572. 矩阵对角线元素的和 8.11打卡
文章目录 题目思路代码 题目 1572. 矩阵对角线元素的和 难度: 简单 描述: 给你一个正方形矩阵 mat,请你返回矩阵对角线元素的和。 请你返回在矩阵主对角线上的元素和副对角线上且不在主对角线上元素的和。 返回合并后的二叉树。 注意…...

Wi-Fi 安全在学校中的重要性
Wi-Fi 是教育机构的基础设施,从在线家庭作业门户到虚拟教师会议,应有尽有。大多数 K-12 管理员对自己的 Wi-Fi 网络的安全性充满信心,并认为他们现有的网络安全措施已经足够。 不幸的是,这种信心往往是错误的。Wi-Fi 安全虽然经常…...

若依微服务集成CAS,实现单点登录
若依(RuoYi)微服务是一款基于Spring Cloud Alibaba开发的企业级微服务框架,采用前后端分离方式,使用了常用的微服务组件,如Feign、Nacos、Sentinel、Seata等,提供了丰富的微服务治理功能,如服务…...
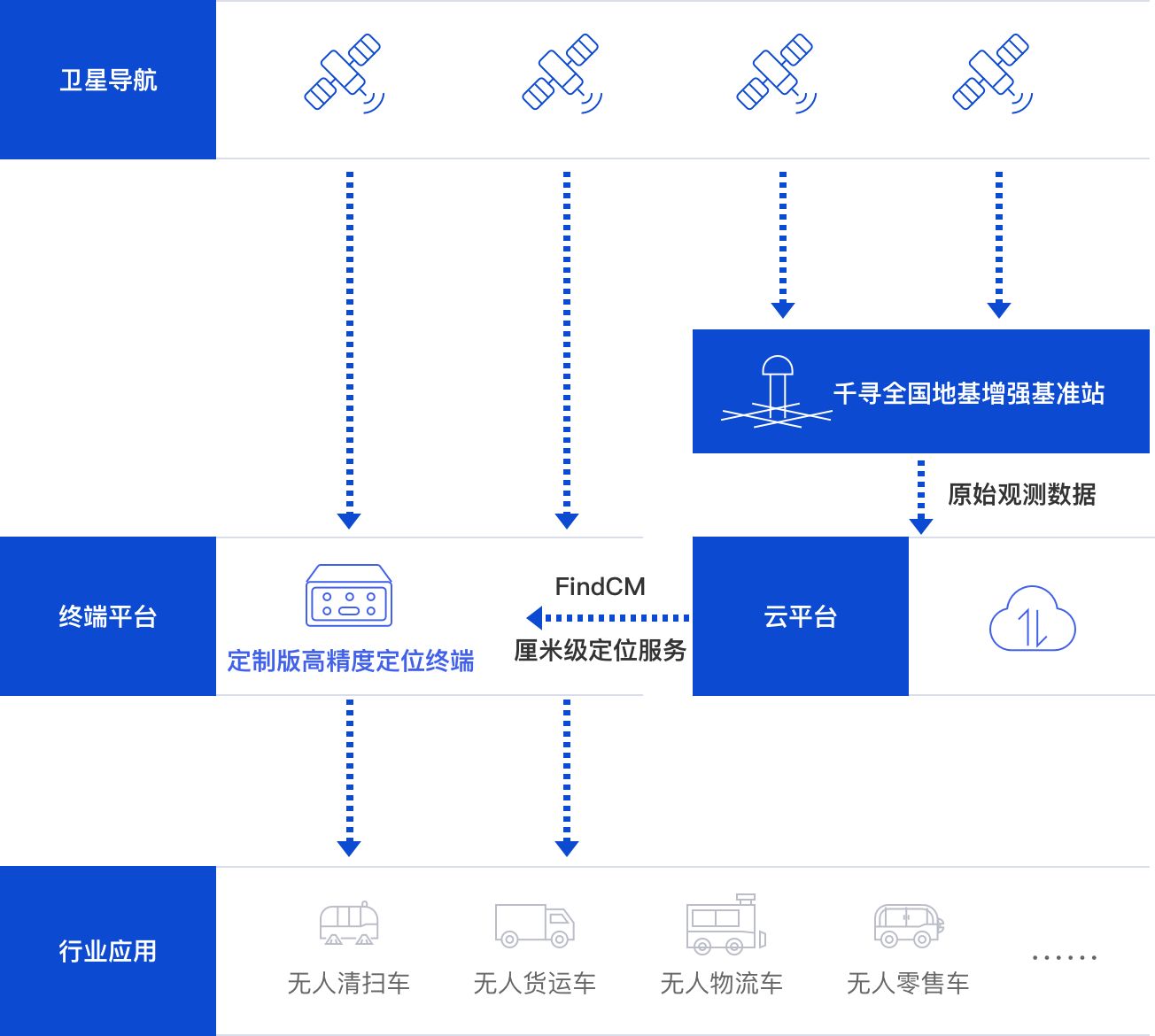
解锁园区交通新模式:园区低速自动驾驶
在当今科技飞速发展的时代,自动驾驶技术成为了备受关注的领域之一。尤其是在园区内部交通管理方面,自动驾驶技术的应用正在日益受到重视。 园区低速自动驾驶的实现需要多个技术领域的协同合作,包括自动驾驶技术、计算机视觉技术、通信技术、物…...
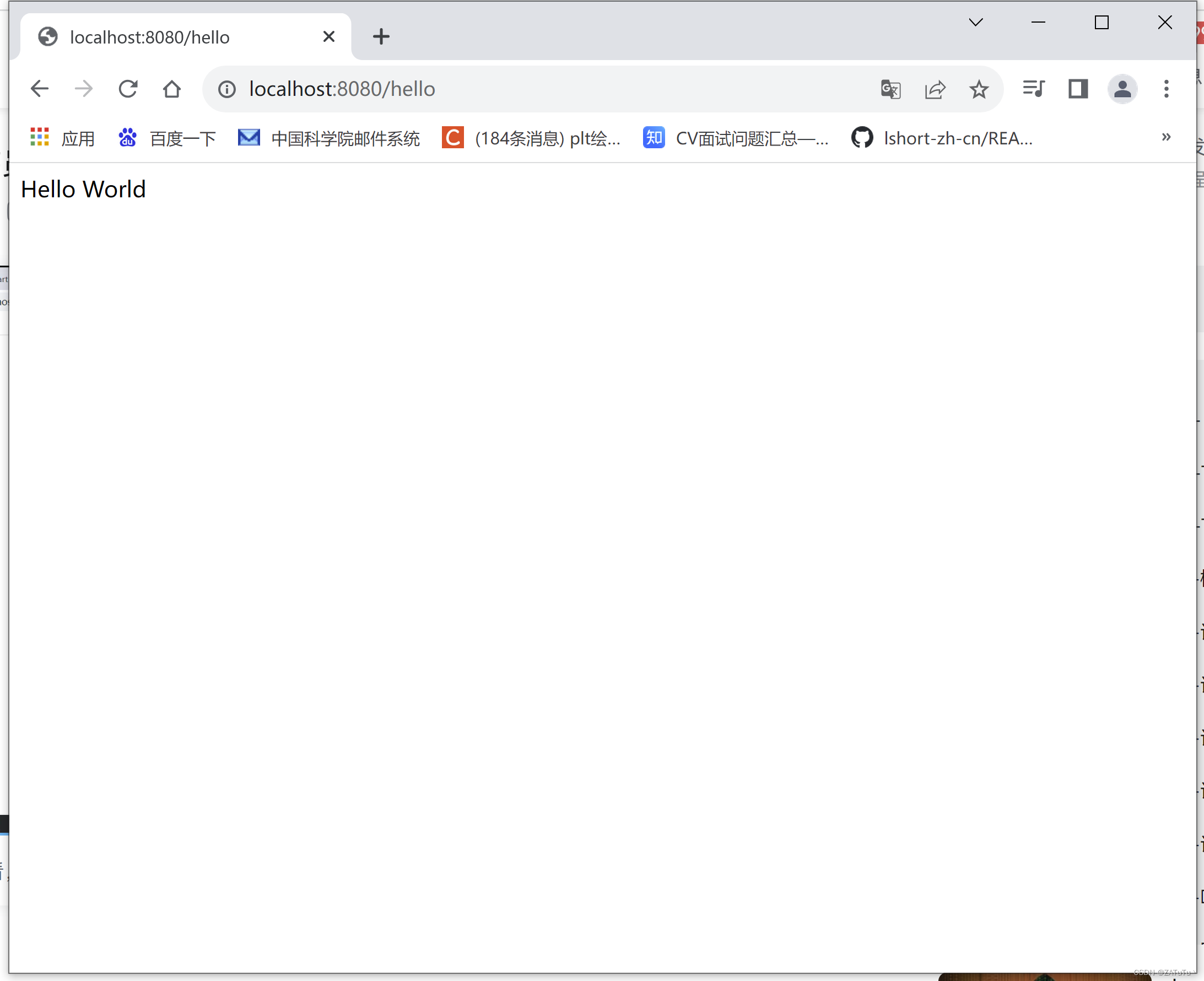
SpringBoot-Hello World
SpringBootWeb快速入门 创建Springboot工程,并勾选web开发相关依赖定义HelloController类,添加方法hello,并添加相关注释运行测试 创建新的SpringBoot项目 几个注意的点: Name:基本上不用管,会根据下面的Ar…...
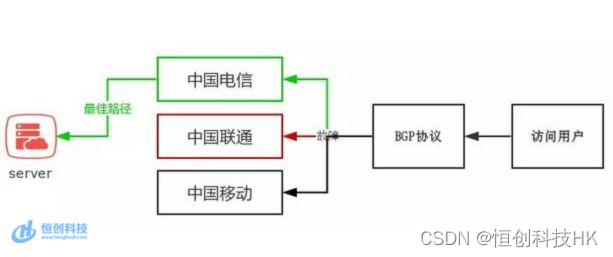
香港服务器三网直连内地线路什么意思?好用吗?
三网直连内地是指香港服务器可以直接连接中国内地的电信、联通和移动三大运营商网络,避免了中间网络干线的支持。这样可以实现直接、快速、稳定的网络访问,提高用户对网络访问的效率,减少网络访问问题和拥堵的现象。 香港服务器直连内地…...
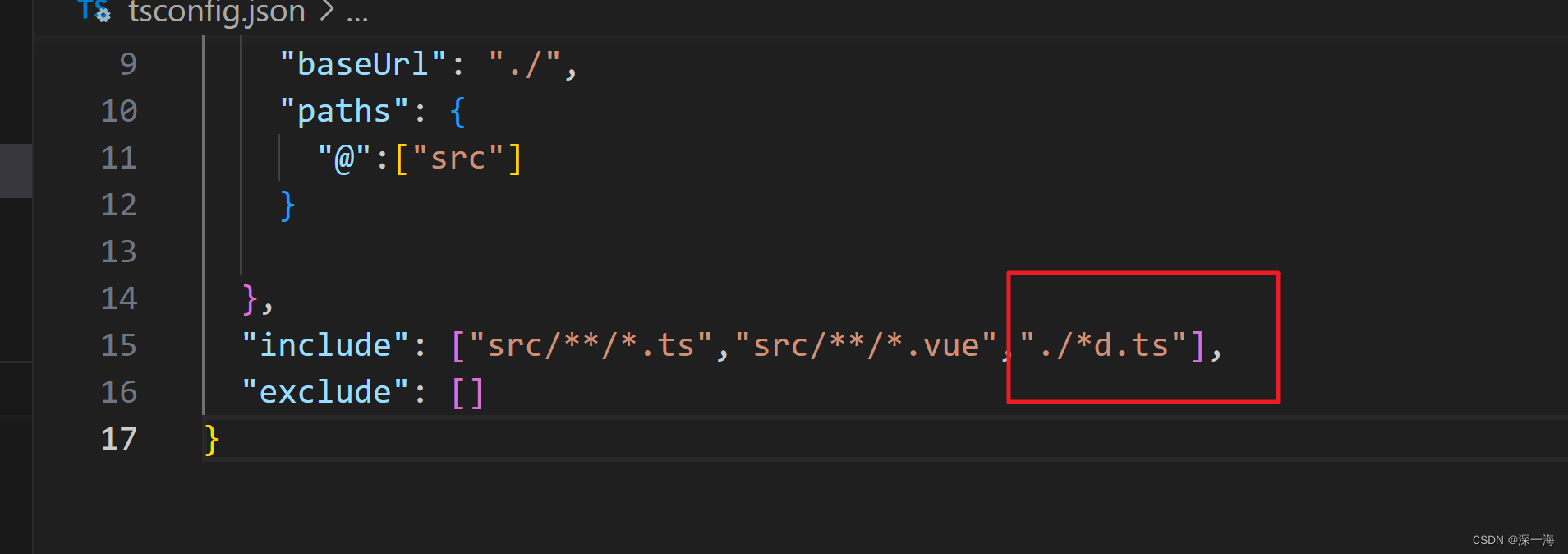
component:()=>import(“@/views/Home.vue“) 报错,ts说没有找到类型声明文件
1 没有写.vue文件的类型声明,要在env.d.ts文件中写.vue的类型声明文件 2 ts.config.josn的incluede字段中,没有把.d.ts文件的路径写对。 如果没写对,就会在项目启动的时候,找不到.d.ts文件。找不到类型声明文件...

为什么hive会出现_HIVE_DEFAULT_PARTITION分区
问题: 为什么hive表中出现_HIVE_DEFAULT_PARTITION分区? 解答: 因为在业务sql中使用的是动态分区,并且hive启用动态分区时,对于指定的分区键如果存在空值时,会对空值部分创建一个默认分区用于存储该部分…...

5分钟掌握STDF-Viewer:半导体测试数据分析的图形化神器
5分钟掌握STDF-Viewer:半导体测试数据分析的图形化神器 【免费下载链接】STDF-Viewer A free GUI tool to visualize STDF (semiconductor Standard Test Data Format) data files. 项目地址: https://gitcode.com/gh_mirrors/st/STDF-Viewer STDF-Viewer是一…...

更换背景图用什么工具?8个月来我测试过50+款产品,这是真实体验分享
买了新手机,想给证件照换个背景;电商运营需要批量处理商品图;自媒体博主要给头像去个背景……这些场景下,"更换背景图用什么工具"可能是你Google搜索框里最常打的一句话。说实话,这个问题看似简单࿰…...

NotebookLM电影文献处理失效真相:92%研究者忽略的3类语义断层及修复方案
更多请点击: https://kaifayun.com 第一章:NotebookLM电影研究辅助 NotebookLM 是 Google 推出的基于 AI 的研究协作者,专为深度阅读与知识整合设计。在电影研究场景中,它能高效解析剧本、影评、导演访谈、学术论文等多源文本&am…...
——run with profiler查看我们所运行程序的描述、计算指标、内存、峰值内存和数量)
Google Earth Engine(GEE)——run with profiler查看我们所运行程序的描述、计算指标、内存、峰值内存和数量
分析器显示有关特定算法和计算的其他部分消耗的资源(CPU 时间、内存)的信息。这有助于诊断脚本运行缓慢或由于内存限制而失败的原因。要使用探查器,请单击“运行”按钮下拉菜单中的“使用探查器运行”选项。作为快捷方式,按住 Alt(或 Mac 上的 Option)并单击运行,或按 C…...

OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 [特殊字符]
OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 🔒 【免费下载链接】openupm OpenUPM - Open Source Unity Package Registry (UPM) 项目地址: https://gitcode.com/gh_mirrors/op/openupm OpenUPM作为开源Unity包管理器(UPM&…...

量子电路反编译技术:原理、实现与应用
1. 量子电路反编译技术概述量子计算领域近年来快速发展,但量子算法的可解释性始终是一个关键挑战。当我们面对一段量子汇编代码(QASM)时,往往难以直观理解其对应的算法逻辑。这就如同拿到一段机器码却不知道它实现的是什么功能。量子电路反编译技术正是为…...

Cursorify:构建AI驱动的深度集成开发环境框架
1. 项目概述:从“智能代码补全”到“深度集成开发环境”的跨越最近在开发者社区里,一个名为“Cursorify”的项目引起了不小的讨论。乍一看这个标题,很多人的第一反应可能是“哦,又一个基于Cursor的插件或者工具”。但当你真正深入…...

从零构建C语言静态库:工程实践与避坑指南
1. 项目概述:为什么我们需要亲手打造一个静态库?在C语言的开发世界里,尤其是当你从编写单个文件的小程序,过渡到管理一个包含数十上百个源文件的中大型项目时,一个绕不开的话题就是代码的组织与复用。你可能有过这样的…...

Windows Cleaner:拯救C盘爆红的终极免费解决方案
Windows Cleaner:拯救C盘爆红的终极免费解决方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 当你的电脑屏幕突然弹出"C盘空间不足"的红…...

实在Agent物流对账全流程自动化方案与落地案例:2026智享财务新标杆
在2026年5月这个生成式AI深度重构实体经济的关键周期,全球物流行业已全面跨入“智能体(Agent)常态化运营”时代。根据《2026年全球供应链数字化趋势报告》显示,超过65%的大型物流企业已部署了具备自主决策能力的智能体来替代传统的…...