大语言模型控制生成的过程Trick:自定义LogitsProcessor实践
前言
在大模型的生成过程中,部分原生的大语言模型未经过特殊的对齐训练,往往会“胡说八道”的生成一些敏感词语等用户不想生成的词语,最简单粗暴的方式就是在大模型生成的文本之后,添加敏感词库等规则手段进行敏感词过滤,但是在生成过程中,生成敏感词仍然耗费了时间和算力成本。
本文以chatglm2-6B为例,通过自定义LogitsProcessor,实践大模型在生成过程中控制一些词语的生成。
LogitsProcessor
从下面代码可以看到,LogitsProcessor的作用就是在生成过程中修改score,改变模型输出的概率分布的工具。
class LogitsProcessor:"""Abstract base class for all logit processors that can be applied during generation."""@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:raise NotImplementedError(f"{self.__class__} is an abstract class. Only classes inheriting this class can be called.")class LogitsProcessorList(list):"""This class can be used to create a list of [`LogitsProcessor`] or [`LogitsWarper`] to subsequently process a`scores` input tensor. This class inherits from list and adds a specific *__call__* method to apply each[`LogitsProcessor`] or [`LogitsWarper`] to the inputs."""def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.FloatTensor:r"""Args:input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):Indices of input sequence tokens in the vocabulary. [What are input IDs?](../glossary#input-ids)scores (`torch.FloatTensor` of shape `(batch_size, config.vocab_size)`):Prediction scores of a language modeling head. These can be logits for each vocabulary when not usingbeam search or log softmax for each vocabulary token when using beam searchkwargs (`Dict[str, Any]`, *optional*):Additional kwargs that are specific to a logits processor.Return:`torch.FloatTensor` of shape `(batch_size, config.vocab_size)`:The processed prediction scores."""for processor in self:function_args = inspect.signature(processor.__call__).parametersif len(function_args) > 2:if not all(arg in kwargs for arg in list(function_args.keys())[2:]):raise ValueError(f"Make sure that all the required parameters: {list(function_args.keys())} for "f"{processor.__class__} are passed to the logits processor.")scores = processor(input_ids, scores, **kwargs)else:scores = processor(input_ids, scores)return scores自定义LogitsProcessor实践
回到正题,如何自定义LogitsProcessor控制大模型生成的过程呢?下面直接上实践代码:
class new_logits_processor(LogitsProcessor):def __init__(self, forbid_token_id_list: List[int] = None):self.forbid_token_id_list = forbid_token_id_listdef __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:for id_ in self.forbid_token_id_list:scores[:, id_] = -float('inf')return scores
forbid_token_id_list是不让模型生成词语的id映射列表,对于这些抑制生成的词语,在自定义logits_processor时将其概率推向负无穷大即可。
chatglm2-6B详细实践代码:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, TextStreamer
from transformers.generation.logits_process import LogitsProcessor, LogitsProcessorList
from typing import List
import torchclass new_logits_processor(LogitsProcessor):def __init__(self, forbid_token_id_list: List[int] = None):self.forbid_token_id_list = forbid_token_id_listdef __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:for id_ in self.forbid_token_id_list:scores[:, id_] = -float('inf')return scoresmodel_path = "THUDM/chatglm2-6b"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForSeq2SeqLM.from_pretrained(model_path, trust_remote_code=True).to('mps')def add_forbid_words():'''添加需要抑制的词语,这里简单添加了数字和几个词语进行对比:return:list'''forbid_words = []for i in range(10):forbid_words.append(tokenizer.convert_tokens_to_ids(str(i)))forbid_words.append(tokenizer.convert_tokens_to_ids("首先"))forbid_words.append(tokenizer.convert_tokens_to_ids("积极"))forbid_words.append(tokenizer.convert_tokens_to_ids("回答"))forbid_words.append(tokenizer.convert_tokens_to_ids("勇敢"))forbid_words.append(tokenizer.convert_tokens_to_ids("勇气"))return forbid_wordslogits_processor = LogitsProcessorList()
logits_processor.append(new_logits_processor(add_forbid_words()))streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)input = "列举出10个积极的词语:"outputs = model.generate(tokenizer(input, return_tensors='pt').input_ids.to("mps"),max_new_tokens=1024,logits_processor=logits_processor, # 不开启注释即可streamer=streamer
)
decode_text = tokenizer.batch_decode(outputs, streamer=streamer)[0]
print(decode_text)
抑制前输出:
1. 勇敢
2. 快乐
3. 成功
4. 努力
5. 积极
6. 乐观
7. 自信
8. 开朗
9. 团结
10. 奋斗
抑制后输出:
- 积极主动
- 乐观向上
- 自信
- 自律
- 诚实守信
- 乐于助人
- 勇于尝试
- 坚韧不拔
- 乐观开朗
- 团结一心
小结
本文通过自定义LogitsProcessor,简单的实践了大语言模型在生成过程中屏蔽生成用户自定义词语的trick。在现实场景中,根据特定场景探索如何灵活的利用LogitsProcessor进行有针对性的控制生成模型的生成过程非常重要。
参考文献
【1】https://github.com/huggingface/transformers/blob/v4.31.0/src/transformers/generation/logits_process.py
相关文章:

大语言模型控制生成的过程Trick:自定义LogitsProcessor实践
前言 在大模型的生成过程中,部分原生的大语言模型未经过特殊的对齐训练,往往会“胡说八道”的生成一些敏感词语等用户不想生成的词语,最简单粗暴的方式就是在大模型生成的文本之后,添加敏感词库等规则手段进行敏感词过滤…...
Docker容器:docker的资源控制及docker数据管理
文章目录 一.docker的资源控制1.CPU 资源控制1.1 资源控制工具1.2 cgroups有四大功能1.3 设置CPU使用率上限1.4 进行CPU压力测试1.5 设置50%的比例分配CPU使用时间上限1.6 设置CPU资源占用比(设置多个容器时才有效)1.6.1 两个容器测试cpu1.6.2 设置容器绑…...

从零开始打造家装预约咨询小程序
在如今互联网高度发达的时代,家装行业也逐渐意识到了线上渠道的重要性。为了更好地服务客户,提高用户体验,越来越多的家装公司开始寻找合适的小程序制作平台。本文将向大家介绍如何使用第三方制作平台,如乔拓云网,打造…...

es线上处理命令记录
常用命令 搜索 GET _search {"query": {"match_all": {}} }获取全部模版 GET _index_template GET _index_template/yst_crawler_template获取全部索引 GET /_cat/indices?v 获取当前mapping GET /yst_crawler/_mapping创建一个mapping PUT /yst_c…...
)
mysql 在nodejs中的简单使用(增删改查)
一 、封装SQL查询请求链接 const mysql require(mysql) //创建开发工具数据库链接池 const pool mysql.createPool({host: 192.168.1.133,user: user_name, password: 123456,database: database_name,port: 3306,connectionLimit: 50 // 限制连接数 });// sql:查…...

1.MySQL数据库的基本操作
数据库操作过程: 1.用户在客户端输入 SQL 2.客户端会把 SQL 通过网络发送给服务器 3.服务器执行这个 SQL,把结果返回给客户端 4.客户端收到结果,显示到界面上 数据库的操作 这里的数据库不是代表一个软件,而是代表一个数据集合。 显示当前的数据库 …...

Zabbix-6.4.4 邮箱告警SMS告警配置
目录 ------------------------- # 邮箱告警 ---------------------------------- 1.安装mailx与postfix软件包 2.修改mailx配置文件 3. 创建文件夹 4. 编写mail-send.sh脚本 5. 将该脚本赋予执行权限 6. 进入web界面进行设置—> Alerts —> Media Types 7. 添…...

网络安全 Day30-运维安全项目-容器架构上
容器架构上 1. 什么是容器2. 容器 vs 虚拟机(化) :star::star:3. Docker极速上手指南1)使用rpm包安装docker2) docker下载镜像加速的配置3) 载入镜像大礼包(老师资料包中有) 4. Docker使用案例1) 案例01::star::star::…...

深入理解设计模式-创建型之单例模式
为什么要使用单例 1、表示全局唯一 如果有些数据在系统中应该且只能保存一份,那就应该设计为单例类。 如:配置类:在系统中,我们只有一个配置文件,当配置文件被加载到内存之后,应该被映射为一个唯一的【配…...

Vue中路由缓存问题及解决方法
一.问题 Vue Router 允许你在你的应用中创建多个视图,并根据路由来动态切换这些视图。默认情况下,当你从一个路由切换到另一个路由时,Vue Router 会销毁前一个路由的组件实例并创建新的组件实例。然而,有时候你可能希望保持一些页…...

Linux与bash(基础内容一)
一、常见的linux命令: 1、文件: (1)常见的文件命令: (2)文件属性: (3)修改文件属性: 查看文件的属性: ls -l 查看文件的属性 ls …...
NVIDIA Omniverse与GPT-4结合生成3D内容
全球各行业对 3D 世界和虚拟环境的需求呈指数级增长。3D 工作流程是工业数字化的核心,开发实时模拟来测试和验证自动驾驶车辆和机器人,操作数字孪生来优化工业制造,并为科学发现铺平新的道路。 如今,3D 设计和世界构建仍然是高度…...
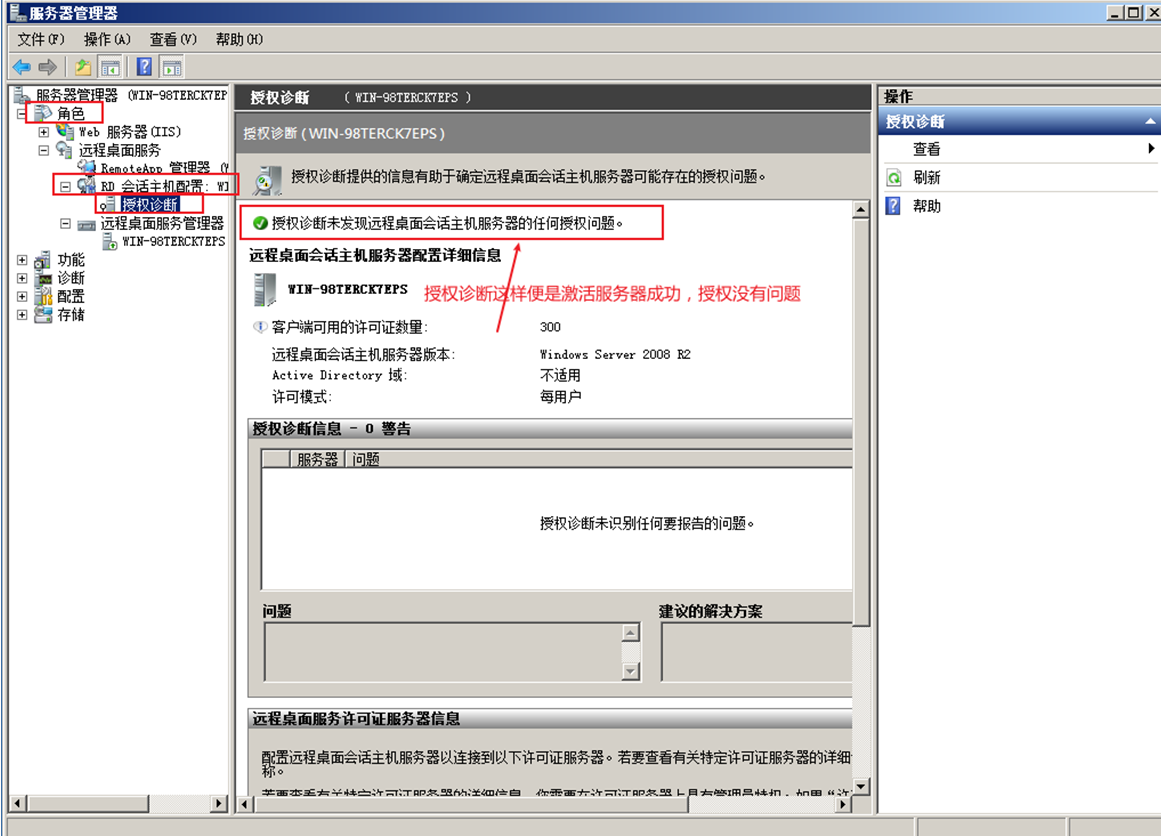
Windows Server --- RDP远程桌面服务器激活和RD授权
RDP远程桌面服务器激活和RD授权 一、激活服务器二、设置RD授权 系统:Window server 2008 R2 服务:远程桌面服务 注:该方法适合该远程桌面服务器没网络状态下(离线),激活服务器。 一、激活服务器 1.打开远…...

关于游戏盾
游戏盾(Game Shield)是一种针对游戏行业特点的网络安全解决方案,主要针对游戏平台面临的各种网络攻击和安全威胁。以下是一些原因,说明为什么游戏平台需要加游戏盾: 1. DDoS攻击:游戏平台通常容易受到分布式…...

回归预测 | MATLAB实现基于SSA-KELM-Adaboost麻雀算法优化核极限学习机结合AdaBoost多输入单输出回归预测
回归预测 | MATLAB实现基于SSA-KELM-Adaboost麻雀算法优化核极限学习机结合AdaBoost多输入单输出回归预测 目录 回归预测 | MATLAB实现基于SSA-KELM-Adaboost麻雀算法优化核极限学习机结合AdaBoost多输入单输出回归预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本…...
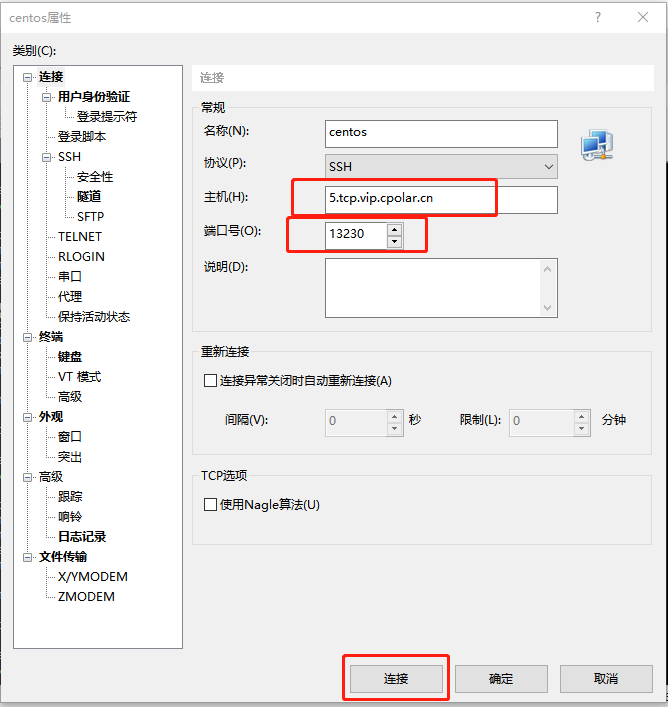
《cpolar内网穿透》外网SSH远程连接linux(CentOS)服务器
本次教程我们来实现如何在外公网环境下,SSH远程连接家里/公司的Linux CentOS服务器,无需公网IP,也不需要设置路由器。 视频教程 [video(video-jrpesBrv-1680147672481)(type-csdn)(url-CSDN直播https://live-file.csdnimg.cn/release/live/…...
IDEA启动报错【java.sql.SQLSyntaxErrorException: ORA-00904: “P“.“PRJ_NO“: 标识符无效】
IDEA报错如下: 2023-08-17 11:26:15.535 ERROR [egrant-biz,b48324d82fe23753,b48324d82fe23753,true] 24108 --- [ XNIO-1 task-1] c.i.c.l.c.RestExceptionController : 服务器异常org.springframework.jdbc.BadSqlGrammarException: ### Error queryin…...
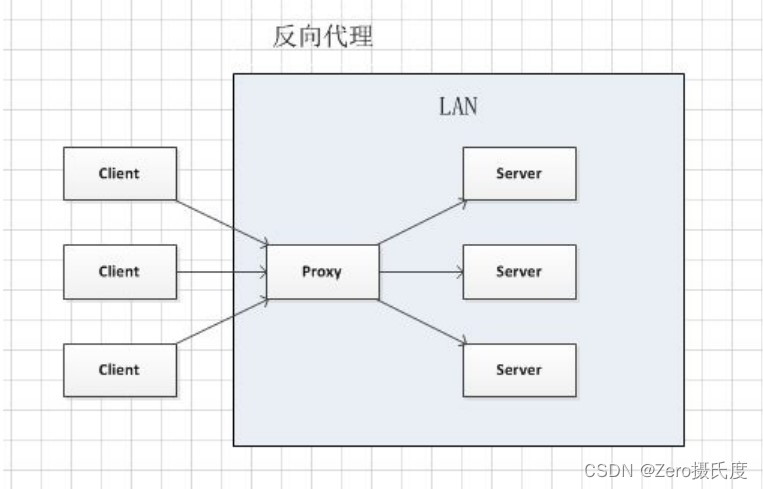
Nginx详解
1、高并发时代 单台tomcat在理想情况下可支持的最大并发数量在200~500之间,如果大于这个数量可能会造成响应缓慢甚至宕机。 解决方案是通过多台服务器分摊并发压力,这不仅需要有多台tomcat服务器,还需要一台服务器专门用来分配请求。这既是…...

摸清一下mysql授权语句的实际执行关系
样例 ---------------------------------------------------------------------- grant all PRIVILEGES on db1.* to test% identified by test1; grant all PRIVILEGES on db2.* to test% identified by test2; grant all PRIVILEGES on db3.* to test127.0.0.1 identified …...

sCrypt于8月12日在上海亮相BSV数字未来论坛
2023年8月12日,由上海可一澈科技有限公司(以下简称“可一科技”)、 临港国际科创研究院发起,携手美国sCrypt公司、福州博泉网络科技有限公司、复旦大学区块链协会,举办的BSV数字未来论坛在中国上海成功落下帷幕。 本次…...

2026学数据分析对就业能力提升的价值
一、行业需求与就业前景数据分析行业近年来的增长趋势和未来预测,2026年市场对数据分析师的需求量。不同行业(金融、医疗、电商等)对数据分析技能的具体需求。二、技能要求与学习路径数据分析岗位的核心技能(Python/R、SQL、统计学…...

5G网优路测数据分析方法:从数据采集到问题定位
路测(Drive Test)是5G网络优化最基础也是最关键的数据采集手段。本文从数据采集、分析方法、问题定位三个层面,系统讲解5G路测数据分析方法论。一、5G路测概述1.1 路测目的目的说明适用场景覆盖验证验证5G网络覆盖是否达标新站开通、优化后验…...

如何在卡片悬停时添加内边距而不引起布局偏移
本文详解如何通过 box-sizing: border-box、合理设置宽高约束及子元素尺寸策略,在卡片 hover 时安全添加 padding,避免因盒模型计算导致的布局抖动或相邻卡片位移。 本文详解如何通过 box-sizing: border-box、合理设置宽高约束及子元素尺寸策略&am…...

番茄小说下载器终极指南:3分钟掌握全平台电子书制作技巧 [特殊字符]
番茄小说下载器终极指南:3分钟掌握全平台电子书制作技巧 🚀 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 番茄小说下载器是一款基于Rust语言开发的专…...
)
linux内核源码内存管理(7)
一、 引言:冲破冯诺依曼瓶颈的壁障在传统的单处理器(UMA,Uniform Memory Access)架构中,所有CPU核心通过同一条总线平等地访问所有内存。这种对称性带来了编程模型的简洁,但也埋下了致命的可扩展性陷阱&…...

小学期学习报告-1
通过B站视频学习之后,我掌握冰设计出了555方波发生电路和低通滤波器,通过示波器可以看到,已经除了稳定的方波和正弦波 在这个过程中,根据公式T0.7*( R12R2)*C1,多次调整并得出稳定波形ÿ…...

长期使用Taotoken聚合服务在模型路由与容灾方面的实际体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务在模型路由与容灾方面的实际体感 在持续数月的项目开发过程中,我们团队将多个AI模型调用统一…...

面试题详解:GraphRAG 全面解析——知识图谱增强 RAG、Local Search、Global Search、社区摘要、工程落地与评估指标一次讲透
一、什么是 GraphRAG?1.1 先用一句话讲清楚GraphRAG 可以理解为:在传统 RAG 的基础上,把文档里的实体、关系、事件和主题组织成一张图,再利用这张图来增强检索和生成。普通 RAG 更像“在文档块里找相似内容”,GraphRAG…...

BGP EVPN Type2/3/5路由:VXLAN控制平面的三大支柱
1. 揭开BGP EVPN Type2/3/5路由的神秘面纱 第一次接触VXLAN控制平面时,我被各种路由类型搞得晕头转向。直到在数据中心网络改造项目中踩了几个坑,才真正理解BGP EVPN这三种核心路由就像乐高积木,各自独立却又完美拼合。想象一下,T…...

使用taotoken cli工具一键配置团队github仓库的开发环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken cli工具一键配置团队github仓库的开发环境 在团队协作开发中,确保每个成员使用统一的大模型API接入配置是…...